
Gate-Level Hardware Trojan Detection Method Based on K-Hypergraph


Abstract
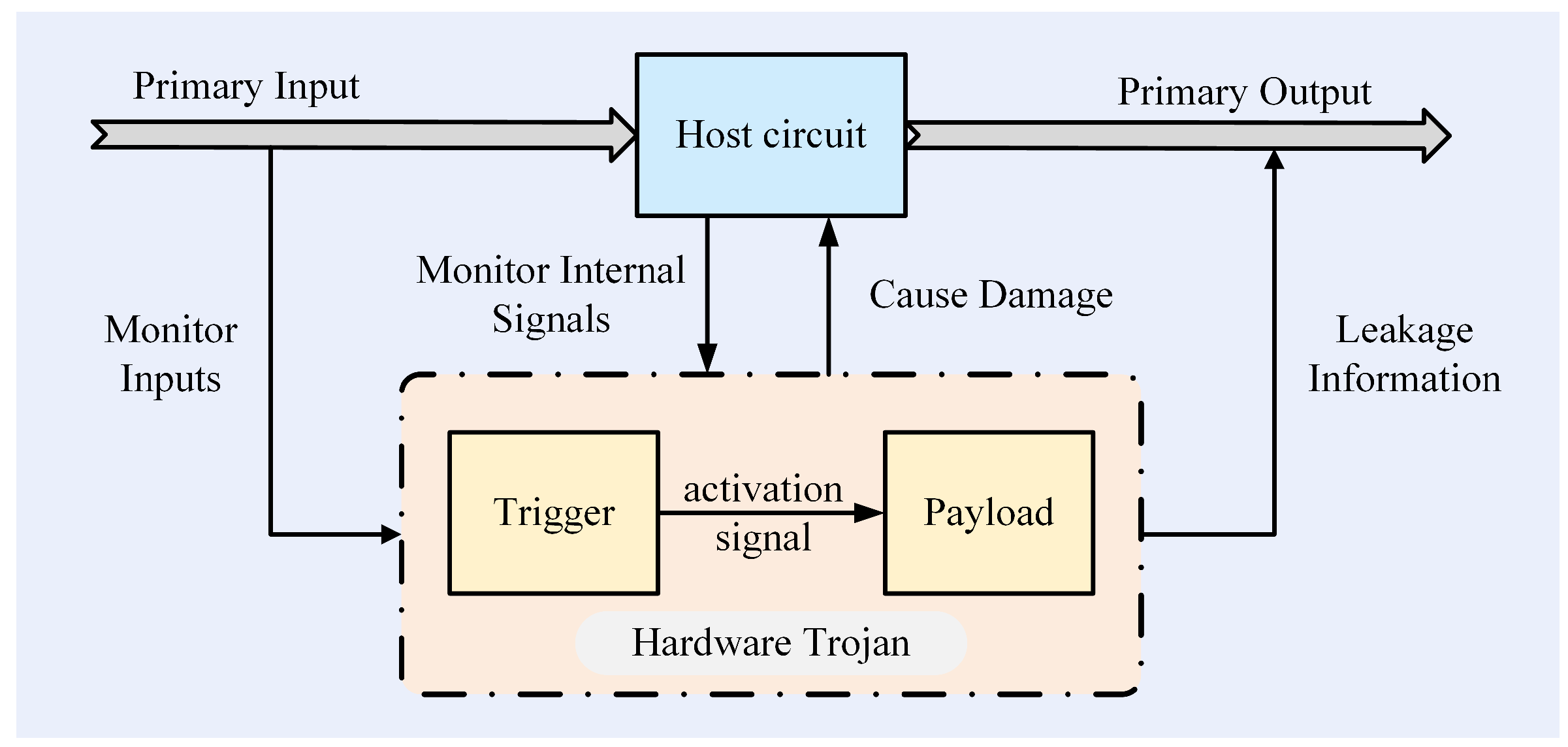
1. Introduction
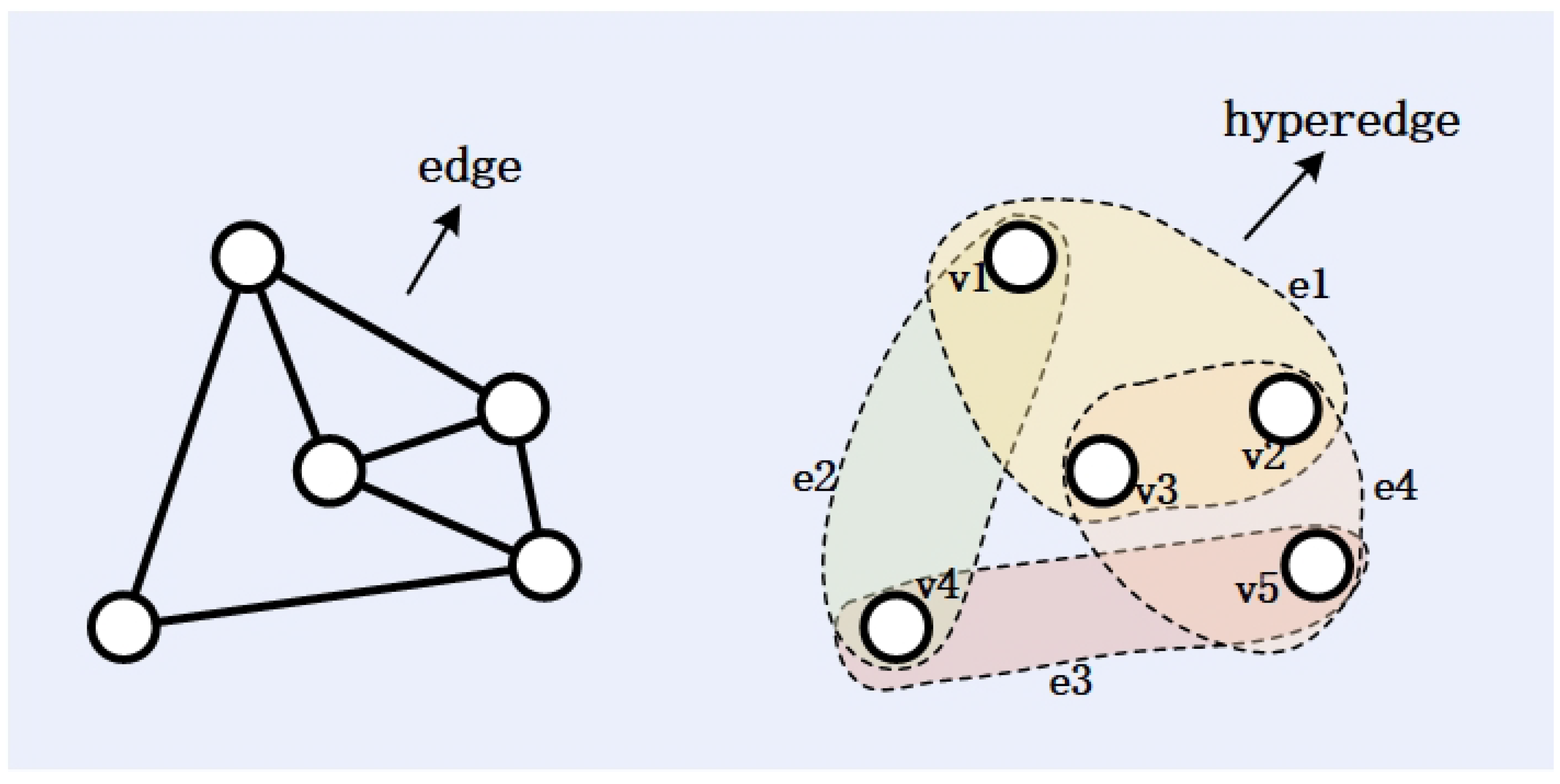
- This paper proposes a K-Hypergraph model construction method focused on the abstraction of hardware Trojan characteristics. Unlike traditional gate-level netlist hypergraph models (where gates are nodes and nets are hyperedges), the proposed method dynamically adjusts the structure of the hypergraph based on the features, independently of the original circuit structure. This approach allows the K-Hypergraph model to place greater emphasis on the functional characteristics of the circuit, rather than relying solely on the structural information described by the hardware.
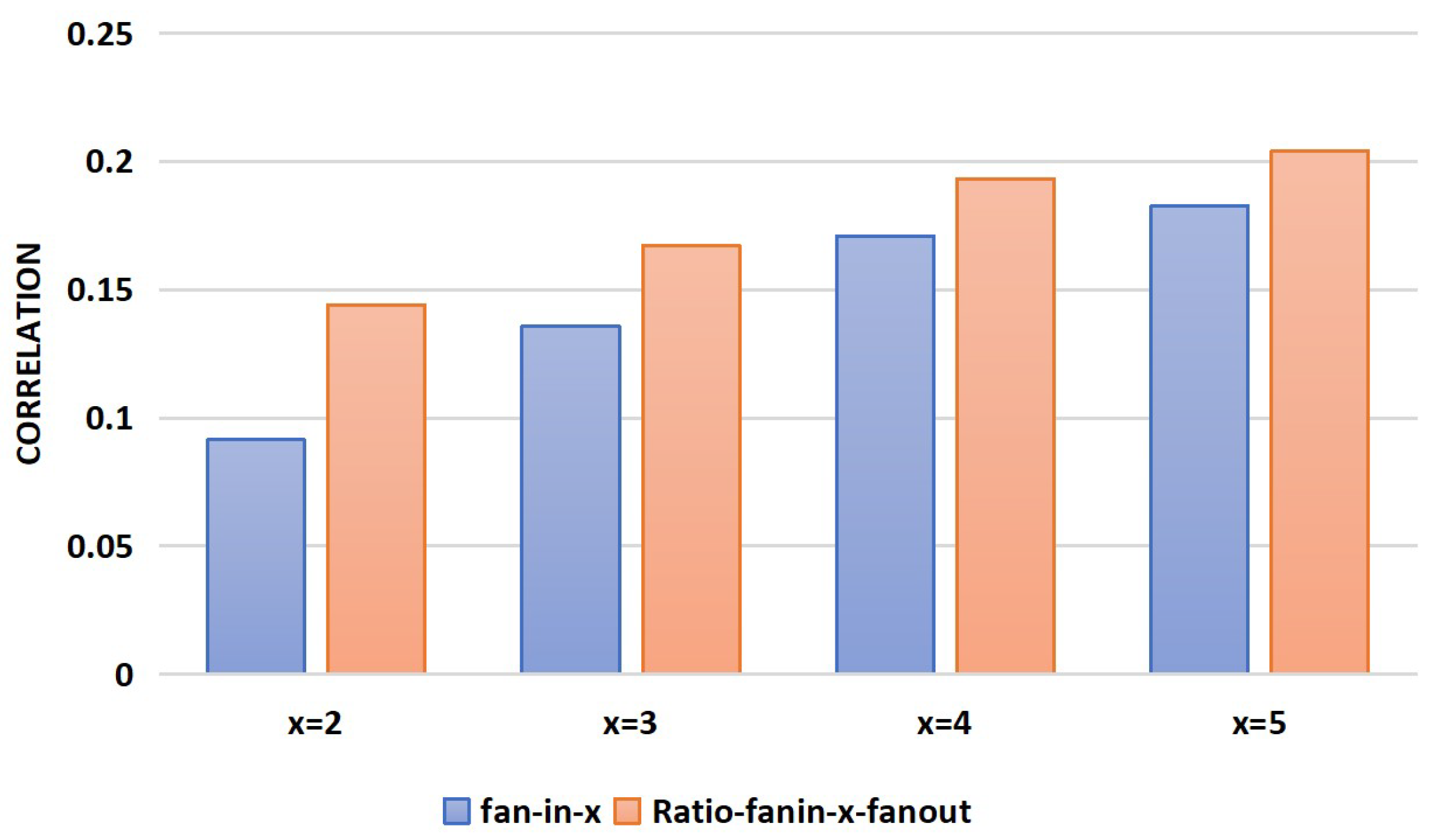
- This paper improves upon the commonly used fan-in count feature by dividing it by the fan-out count, using the resulting ratio as a new structural feature. A correlation analysis is conducted between the features before and after the improvements, revealing that the correlation of the improved features and the node labels is increased by up to 50%.
- The learning process for hypergraph structures involves iteratively updating the weights of the hypergraph based on the residuals between predicted labels and actual labels until the weights converge or the maximum number of iterations is reached, ultimately identifying HTs. Experimental results show that, compared with existing methods, this method can effectively and accurately identify most HT nodes.
2. Related Works
3. Proposed Method
3.1. Dataset
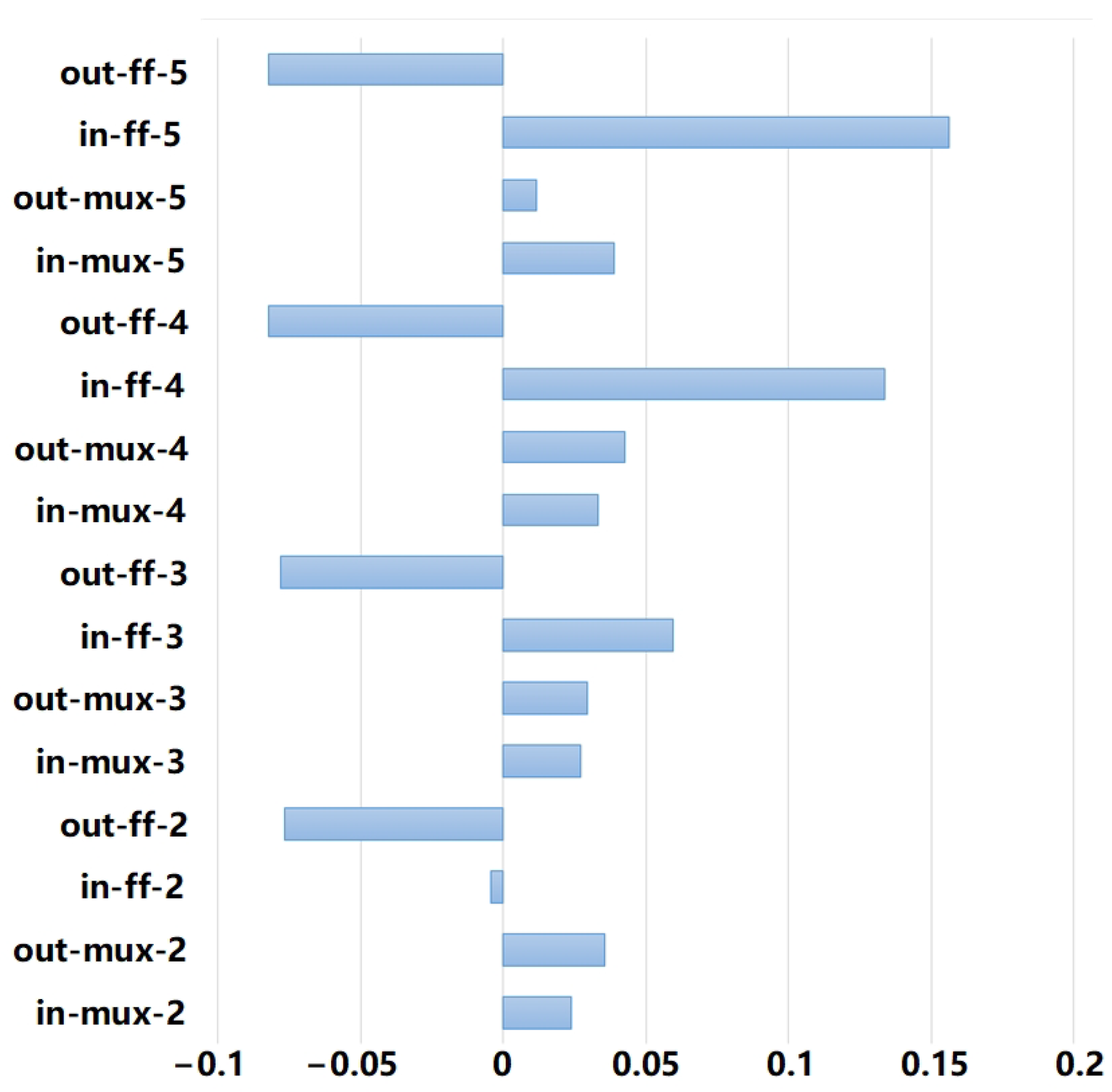
3.2. Feature Extraction
3.3. Construction of K-Hypergraph
- a.
- Choose the distance metric. Firstly, it is necessary to determine a suitable distance metric standard to calculate the similarity or distance between data points. Common metrics include the Euclidean distance, Manhattan distance, etc. This paper calculates the Euclidean distance between every two nodes using node features, as shown in step 2 of Algorithm 1.
- b.
- Construct hyperedges. For each node i, find its k + 1 nearest neighbors (including itself). Since the netlist is relatively small, we will choose k values from 1 to 10 and evaluate the performance to select the optimal k value. Form a hyperedge consisting of node i and its k nearest neighbors and add this hyperedge to the set of hyperedges E, as shown in steps 4∼8 of Algorithm 1.
- c.
- Calculate the connection weights between nodes and hyperedges. For each neighbor j of node i, compute the Gaussian weight and store it in the weight matrix W. These weights are used to construct the sparse matrix H. The weights reflect the similarity between samples, with closer samples having larger weights, as shown in steps 11∼17 of Algorithm 1.
- d.
- Initialize the global weights of hyperedges. Assign a global weight w to each hyperedge, initially set to 1, which will be iteratively optimized in the subsequent learning process, as shown in steps 18∼21 of Algorithm 1.
| Algorithm 1 Generate K-Hypergraph |
|
3.4. Traning of K-Hypergraph
- a.
- Initialization.
- Input Data: K-Hypergraph structure, partially known labels y (unlabeled nodes are marked with −1), and regularization parameter .
- Indices of Known and Unknown Nodes:
- b.
- Label Propagation
- Initialize Label Matrix: Convert the partially known labels y into a one-hot encoded matrix Y.
- Compute the Matrix: The matrix represents the relationships between nodes and is computed based on the hypergraph structure and weights:Here, indicates whether node i belongs to hyperedge e, and is the weight of hyperedge e.
- Compute the Laplacian Matrix L: A Laplacian matrix is used to capture the similarities and differences between nodes. The equation is as follows:where is the identity matrix and is the regularization parameter.
- Compute the Label Propagation Matrix F: Calculate the label propagation matrix , which is used to propagate known label information to unlabeled nodes. The equation is as follows:Here, is the inverse of the Laplacian matrix.
- Predict Labels for Unknown Nodes: For each node i, select the category corresponding to the maximum value in the i-th row of as the prediction label, which is the classification result. The formula is as follows:For each unknown node, the predicted label is the index of the maximum value in the corresponding row of .
- c.
- Weight Update
- Compute Residuals: Compute residuals only for unknown nodes:Here, represents the true labels of the unknown nodes (initially -1), and denotes the predicted labels.
- Update Weights:Here, denotes the absolute value, and is the transpose of the incidence matrix. Check Convergence: If the difference between the new and old weights is less than a threshold (e.g., ), stop the iteration:
- d.
- Iteration: Repeat steps 2 and 3 until the maximum number of iterations is reached or convergence is achieved.
- e.
- Output: The final output includes the predicted labels for the unknown nodes and the updated hypergraph weights w.
4. Implementation and Evaluation
4.1. Evaluation Metrics
4.2. Performance Evaluation
4.3. Experimental Analysis and Comparison

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| TPR (%) | TNR (%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Benchmark | This Paper | [21] | [22] | [24] | [15] | This Paper | [21] | [22] | [24] | [15] |
| RS232-T1000 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 84.36 | 99 | 99.7 |
| RS232-T1100 | 100 | 100 | 100 | 100 | 100 | 99.51 | 100 | 84.3 | 100 | 100 |
| RS232-T1200 | 92.86 | 100 | 100 | 100 | 100 | 99.51 | 100 | 84.77 | 99.7 | 100 |
| RS232-T1300 | 100 | 85.7 | 100 | 100 | 100 | 99.51 | 100 | 84.36 | 99.7 | 100 |
| RS232-T1400 | 100 | 100 | 100 | 100 | 100 | 100 | 100 | 84.36 | 99.7 | 100 |
| RS232-T1500 | 100 | 100 | 100 | 100 | 100 | 100 | 99.7 | 84.77 | 99.7 | 99.4 |
| RS232-T1600 | 91.67 | 77.8 | 100 | 100 | 88.9 | 92.16 | 99 | 84.02 | 99.4 | 99.7 |
| S15850-T100 | 85.19 | 7.7 | 100 | 92.3 | 69.2 | 53.02 | 100 | 80.93 | 99.9 | 100 |
| S35932-T100 | 93.33 | 7.7 | 100 | 30.8 | 84.6 | 99.27 | 100 | 80.19 | 100 | 100 |
| S35932-T200 | 83.33 | 8.3 | 70.59 | 25 | 8.3 | 98.71 | 100 | 80.13 | 100 | 100 |
| S35932-T300 | 77.78 | 91.9 | 100 | 97.3 | 91.9 | 89.29 | 100 | 80.45 | 100 | 100 |
| S38417-T100 | 83.33 | 9.1 | 91.67 | 72.7 | 81.8 | 92.02 | 100 | 80.15 | 100 | 100 |
| S38417-T200 | 93.33 | 9.1 | 100 | 72.7 | 27.3 | 87.13 | 100 | 80.20 | 100 | 100 |
| S38584-T100 | 88.89 | 16.7 | 68.42 | 16.7 | 16.7 | 53.14 | 100 | 80.13 | 100 | 100 |
| Average | 92.12 | 58.14 | 95.05 | 79.11 | 76.34 | 90.23 | 99.91 | 82.28 | 99.79 | 99.91 |
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bhunia, S.; Hsiao, M.S.; Banga, M.; Narasimhan, S. Hardware Trojan attacks: Threat analysis and countermeasures. Proc. IEEE 2014, 102, 1229–1247. [Google Scholar] [CrossRef]
- Tehranipoor, M.; Koushanfar, F. A survey of hardware Trojan taxonomy and detection. IEEE Des. Test Comput. 2010, 27, 10–25. [Google Scholar] [CrossRef]
- Chakraborty, R.S.; Narasimhan, S.; Bhunia, S. Hardware Trojan: Threats and emerging solutions. In Proceedings of the 2009 IEEE International High Level Design Validation and Test Workshop, San Francisco, CA, USA, 4–6 November 2009; pp. 166–171. [Google Scholar]
- Wu, T.F.; Ganesan, K.; Hu, Y.A.; Wong, H.S.P.; Wong, S.; Mitra, S. TPAD: Hardware Trojan prevention and detection for trusted integrated circuits. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2016, 35, 521–534. [Google Scholar] [CrossRef]
- Bhunia, S.; Abramovici, M.; Agrawal, D.; Bradley, P.; Hsiao, M.S.; Plusquellic, J.; Tehranipoor, M. Protection Against Hardware Trojan Attacks: Towards a Comprehensive Solution. IEEE Des. Test 2013, 30, 6–17. [Google Scholar] [CrossRef]
- Landwehr, C.E.; Bull, A.R.; McDermott, J.P.; Choi, W.S. A taxonomy of computer program security flaws. Acm Comput. Surv. 1994, 26, 211–254. [Google Scholar] [CrossRef]
- Iranfar, P.; Amirany, A.; Moaiyeri, M.H. Power Attack-Immune Spintronic-Based AES Hardware Accelerator for Secure and High-Performance PiM Architectures. IEEE Trans. Magn. 2025, 61, 3400612. [Google Scholar] [CrossRef]
- Oya, M.; Shi, Y.; Yanagisawa, M.; Togawa, N. A score-based classification method for identifying hardware-trojans at gate-level netlists. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition, Grenoble, France, 9–13 March 2015; ACM: New York, NY, USA, 2015; pp. 465–470. [Google Scholar]
- Gao, Y.; Feng, Y.; Ji, S.; Ji, R. HGNN+: General Hypergraph Neural Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3181–3199. [Google Scholar] [CrossRef] [PubMed]
- Salmani, H. COTD: Reference-Free Hardware Trojan Detection and Recovery Based on Controllability and Observability in Gate-Level Netlist. IEEE Trans. Inf. Forensics Secur. 2017, 12, 338–350. [Google Scholar] [CrossRef]
- Hasegawa, K.; Yanagisawa, M.; Togawa, N. A hardware-classification method utilizing boundary net structures. In Proceedings of the 2018 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 12–14 January 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Hasegawa, K.; Oya, M.; Yanagisawa, M.; Togawa, N. Hardware trojans classification for gate-level netlists based on machine learning. In Proceedings of the 2016 IEEE 22nd International Symposium on On-Line Testing and Robust System Design (IOLTS), Sant Feliu de Guixols, Spain, 4–6 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 203–206. [Google Scholar]
- Liakos, K.G.; Georgakilas, G.K.; Plessas, F.C.; Kitsos, P. Gainesis: Generative artificial intelligence netlists synthesis. Electronics 2022, 11, 245. [Google Scholar] [CrossRef]
- Sharma, R.; Valivati, N.K.; Sharma, G.K.; Pattanaik, M. A New Hardware Trojan Detection Technique using Class Weighted XGBoost Classifier. In Proceedings of the 2020 24th International Symposium on VLSI Design and Test (VDAT), Bhubaneswar, India, 23–25 July 2020. [Google Scholar]
- Negishi, R.; Kurihara, T.; Togawa, N. Hardware-Trojan Detection at Gate-level Netlists using Gradient Boosting Decision Tree Models. In Proceedings of the 2022 IEEE 12th International Conference on Consumer Electronics (ICCE-Berlin), Berlin, Germany, 2–6 September 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Roopa, S.N.; Sathya, D.; Sudha, V. Label Propagation from Laplacian Score for Semi-Supervised Attribute Selection. In Proceedings of the 2021 International Conference on Artificial Intelligence and Smart Systems (ICAIS), Coimbatore, India, 25–27 March 2021; pp. 537–542. [Google Scholar] [CrossRef]
- Trust-Hub.org. (n.d.). Available online: https://www.trust-hub.org/ (accessed on 12 March 2025).
- Hashemi, M.; Momeni, A.; Pashrashid, A.; Mohammadi, S. Graph Centrality Algorithms for Hardware Trojan Detection at Gate-Level Netlists. IJE 2022, 35, 1375–1387. [Google Scholar] [CrossRef]
- Zhou, D.; Huang, J.; Schölkopf, B. Learning with hypergraphs: Clustering, classification, and embedding. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2006; Volume 19. [Google Scholar]
- Hasegawa, K.; Yamashita, K.; Hidano, S.; Fukushima, K.; Hashimoto, K.; Togawa, N. Node-wise Hardware Trojan Detection Based on Graph Learning. TC 2023, 74, 749–761. [Google Scholar] [CrossRef]
- Kurihara, T.; Togawa, N. Hardware-Trojan Classification based on the Structure of Trigger Circuits Utilizing Random Forests. In Proceedings of the 2021 IEEE 27th International Symposium on On-Line Testing and Robust System Design (IOLTS), Torino, Italy, 28–30 June 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Imangholi, A.; Hashemi, M.; Momeni, A.; Mohammadi, S.; Carlson, T.E. FAST-GO: Fast, Accurate, and Scalable Hardware Trojan Detection using Graph Convolutional Networks. In Proceedings of the 2024 25th International Symposium on Quality Electronic Design (ISQED), San Francisco, CA, USA, 3–5 April 2024; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, J.; Zhai, G.; Gao, H.; Xu, L.; Li, X.; Li, Z.; Huang, Z.; Xie, C. A Hardware Trojan Detection and Diagnosis Method for Gate-Level Netlists Based on Machine Learning and Graph Theory. Electronics 2024, 13, 59. [Google Scholar] [CrossRef]
- Negishi, R.; Togawa, N. Evaluation of Ensemble Learning Models for Hardware-Trojan Identification at Gate-level Netlists. In Proceedings of the 2024 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 6–8 January 2024; pp. 1–6. [Google Scholar] [CrossRef]

| Benchmarks | Trigger Structure | Trigger Probability or Condition | Effects |
|---|---|---|---|
| RS232-T1000 | Combination comparator | Change function | |
| RS232-T1100 | Timing comparator | Change function | |
| RS232-T1200 | Timing comparator | Change function | |
| RS232-T1300 | Combination comparator | Change function | |
| RS232-T1400 | Timing comparator | Change function | |
| RS232-T1500 | Timing comparator | Change function | |
| RS232-T1600 | Timing comparator | Change function | |
| S15850-T100 | Combination comparator | Triggered only in functional mode | Change function, refuse service |
| S35932-T100 | Comparator | Triggered only in functional mode | Change function, leak information |
| S35932-T200 | Comparator | Triggered only in functional mode | Denial of service |
| S35932-T300 | Comparator | Triggered only in functional mode | Denial of service, reduced performance |
| S38417-T100 | Comparator | Change function, refuse service | |
| S38417-T200 | Comparator | Change function, refuse service | |
| S38584-T100 | Comparator | Triggered only in functional mode | Change function, refuse service |
| Feature () | Description |
|---|---|
| fan-in-x | the number of fan-ins up to x-level away from net n |
| in-ff-x (out-ff-x) | the number of flip-flops up to x-level away from the input (output) side of net n |
| in-mux-x (out-mux-x) | the number of multiplexers up to x-level away from the input side and output side of net n |
| in-nearestff (out-nearestff) | the levels of the nearest flip-flops from the input (output) side of net n |
| in-nearestmux (out-nearestmux) | the level of the nearest multiplexers from the input side and output side of net n |
| in-nearestPI (out-nearestPO) | the minimum levels from net n to any primary inputs (PI) (primary outputs (PO)) |
| Feature () | Description |
|---|---|
| Ratio-fan-in-x-fan-out | the ratio of the number of x-level fan inputs to the number of 1-level fan outputs of a node |
| In-ff-x | the number of flip-flops up to x-level away from the input side of gate n |
| In (Out)-mux-x | the number of multiplexers up to x-level away from the input side and output side of gate n |
| In (Out)-inv-x | the number of inverters up to x-level away from the input side and output side of gate n |
| In-nearestPI | the minimum levels from gate n to any PI |
| Out-nearestPO | the minimum levels from gate n to any PO |
| Benchmark | TPR/% | TNR/% |
|---|---|---|
| RS232-T1000 | 100 | 100 |
| RS232-T1100 | 100 | 99.51 |
| RS232-T1200 | 92.86 | 99.51 |
| RS232-T1300 | 100 | 99.51 |
| RS232-T1400 | 100 | 100 |
| RS232-T1500 | 100 | 100 |
| RS232-T1600 | 91.67 | 92.16 |
| S15850-T100 | 85.19 | 53.02 |
| S35932-T100 | 93.33 | 99.27 |
| S35932-T200 | 83.33 | 98.71 |
| S35932-T300 | 77.78 | 89.29 |
| S38417-T100 | 83.33 | 92.02 |
| S38417-T200 | 93.33 | 87.13 |
| S38584-T100 | 88.89 | 53.14 |
| Average | 92.12 | 90.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, J.; Lin, B.; Zhang, Q.; Zhao, Y. Gate-Level Hardware Trojan Detection Method Based on K-Hypergraph. Electronics 2025, 14, 1902. https://doi.org/10.3390/electronics14091902
He J, Lin B, Zhang Q, Zhao Y. Gate-Level Hardware Trojan Detection Method Based on K-Hypergraph. Electronics. 2025; 14(9):1902. https://doi.org/10.3390/electronics14091902
Chicago/Turabian StyleHe, Jiaji, Bingxin Lin, Qizhi Zhang, and Yiqiang Zhao. 2025. "Gate-Level Hardware Trojan Detection Method Based on K-Hypergraph" Electronics 14, no. 9: 1902. https://doi.org/10.3390/electronics14091902
APA StyleHe, J., Lin, B., Zhang, Q., & Zhao, Y. (2025). Gate-Level Hardware Trojan Detection Method Based on K-Hypergraph. Electronics, 14(9), 1902. https://doi.org/10.3390/electronics14091902