
Energy-Efficient Federated Learning-Driven Intelligent Traffic Monitoring: Bayesian Prediction and Incentive Mechanism Design


Abstract
1. Introduction
2. Related Works
3. System Model
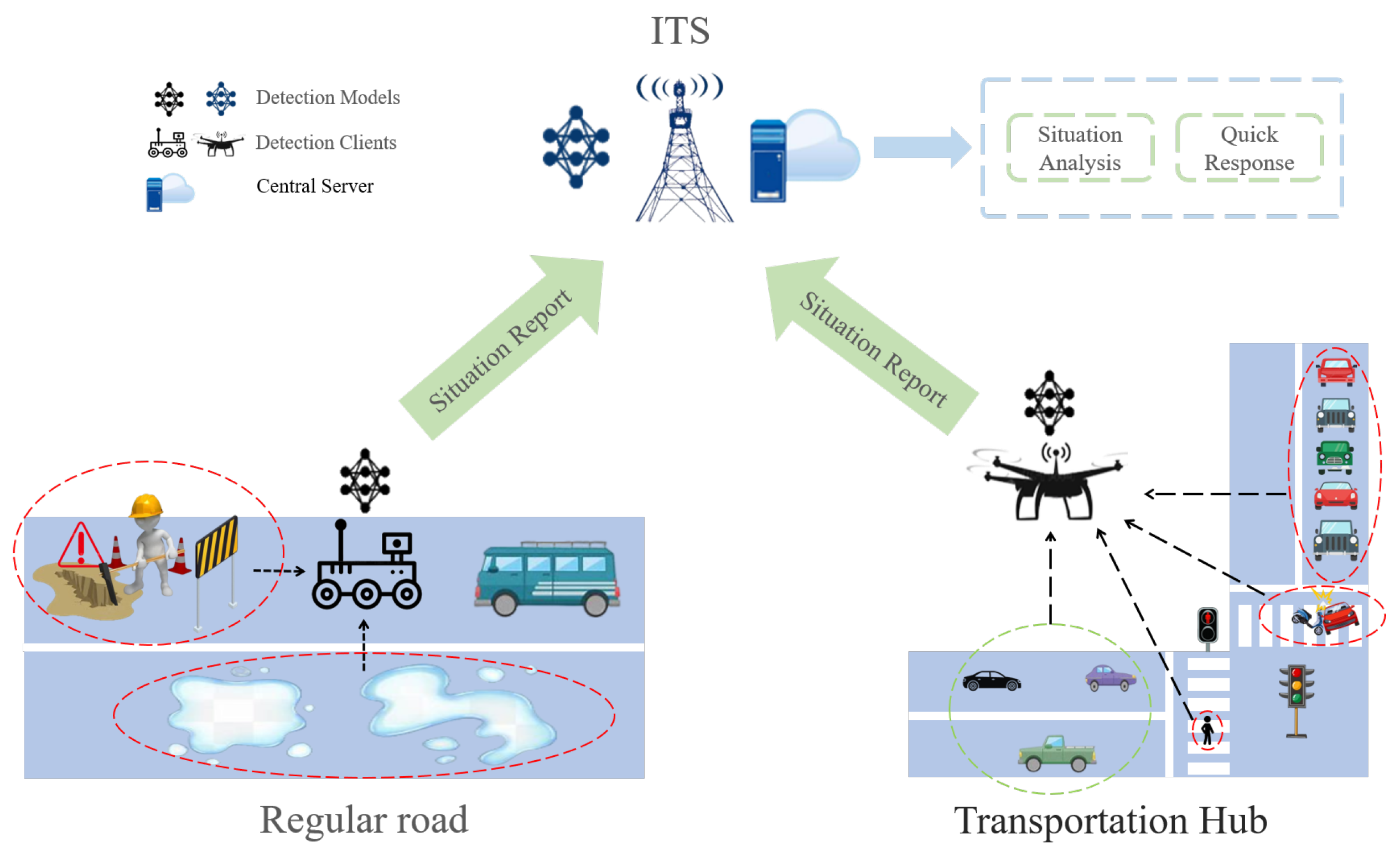
3.1. Scenario Description
3.1.1. Federated Learning Model
3.1.2. Communication Model
3.1.3. Computation Model
3.2. Optimization Problem Description
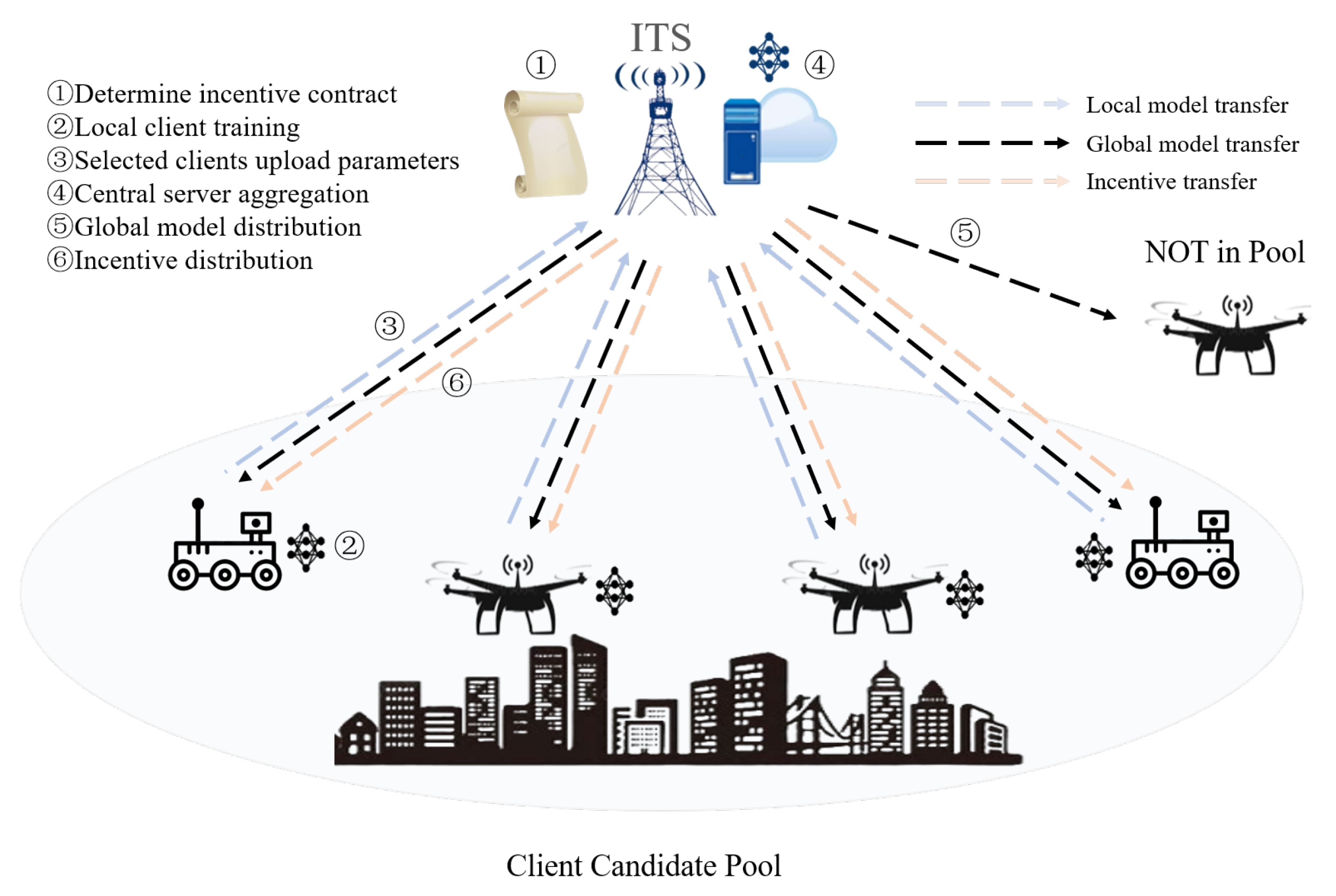
4. Client Selection and Incentive Algorithm Design Based on Bayesian Prediction
| Algorithm 1 Sequential Bayesian Federated Learning |
| Input Global model parameters |
| Client pool |
| Budget constraint , Energy constraint |
| Output Updated parameters |
| Initialize Build Gaussian prior |
| Step 1 Bayesian Client Selection |
| Initialize selected set , |
| Predict loss variation for : |
| for to K do |
| if : |
| Select (Equation (17)) |
| else: |
| Compute selection metric: (Equation (22)) |
| Select |
| endif |
| Update posterior: (Equation (18)) |
| end |
| Step 2 Targeted Parameter Distribution |
| Server sends to via OFDMA |
| Step 3 Client-side Local Training |
| for eachparallel |
| Compute via SGD |
| Calculate |
| Upload to server |
| end |
| Step 4 Server Aggregation |
| Aggregate updates: (Equation (3)) |
| Step 5 Incentive Allocation |
| for each |
| Assign incentive: |
| Validate: |
| end |
| Termination Repeat until |
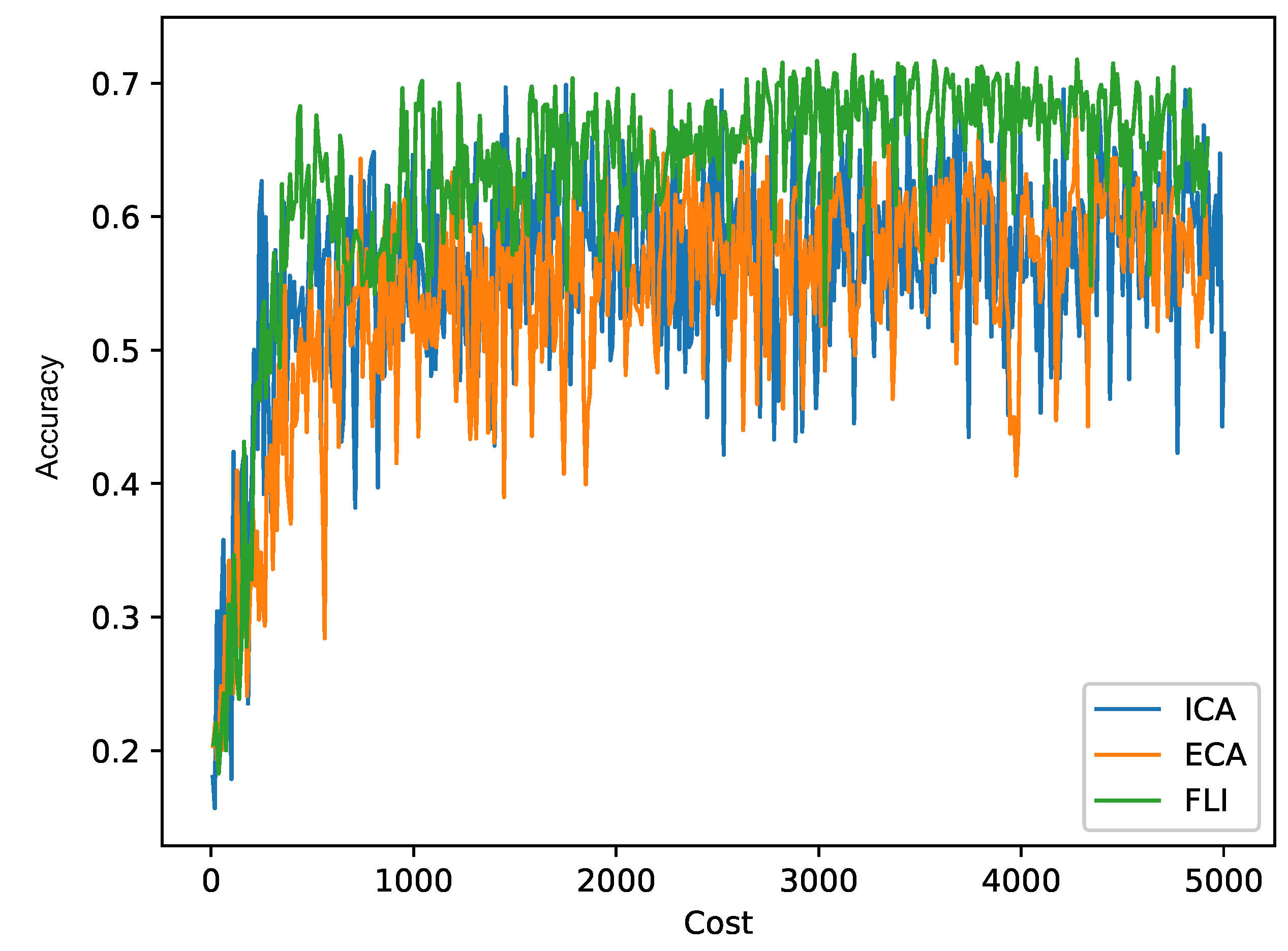
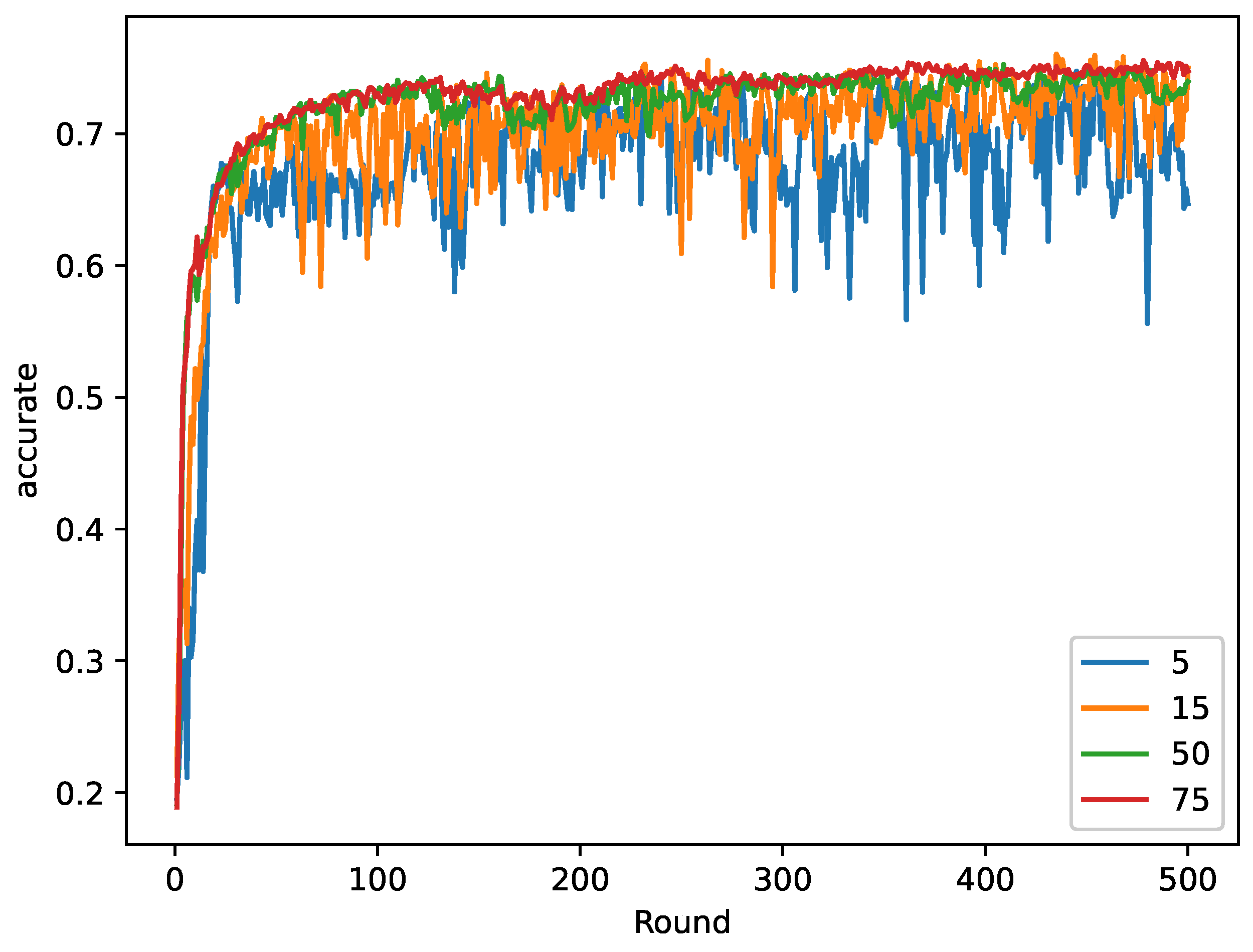
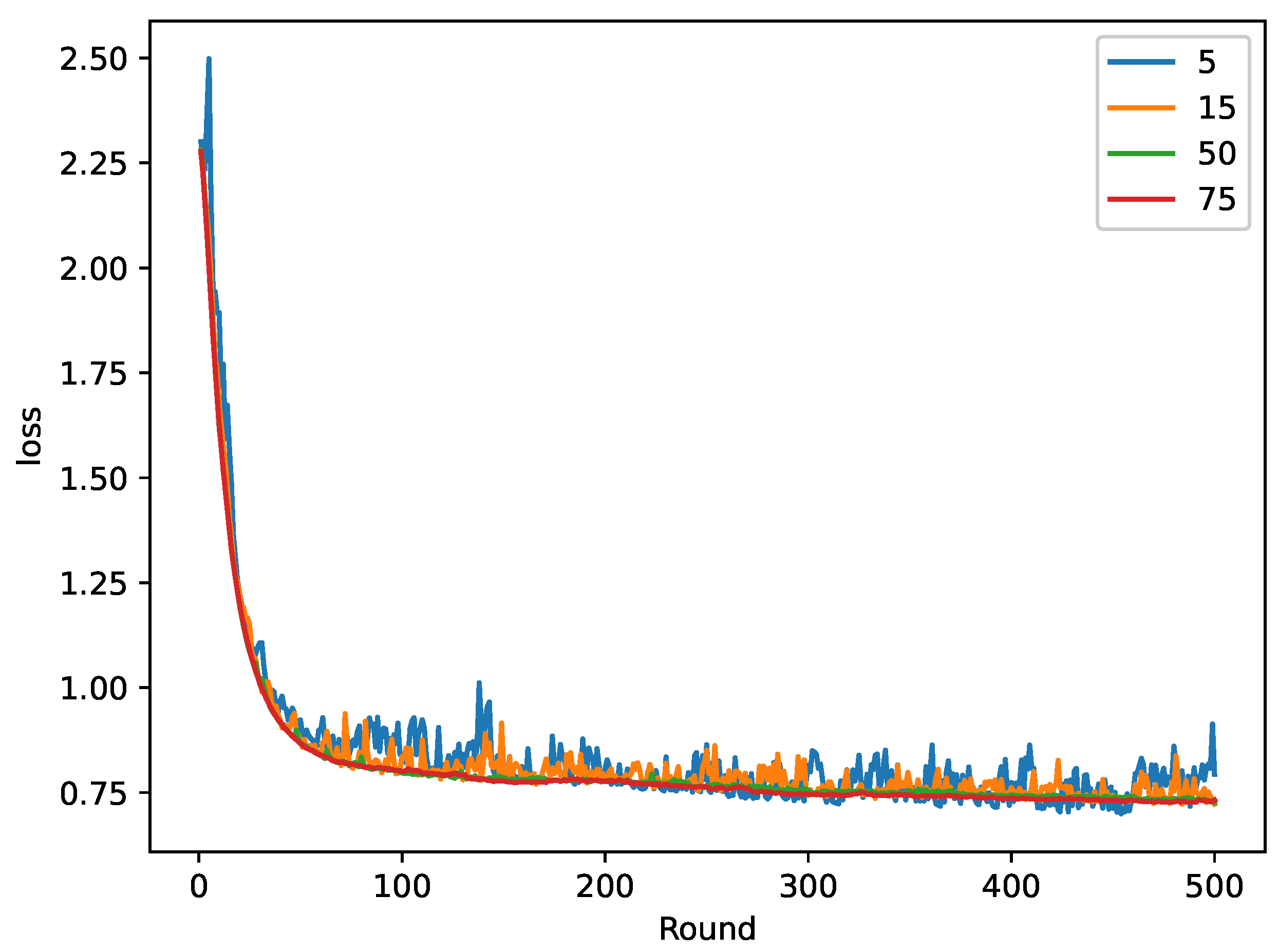
5. Experiments and Result Analysis
5.1. Experimental Setup
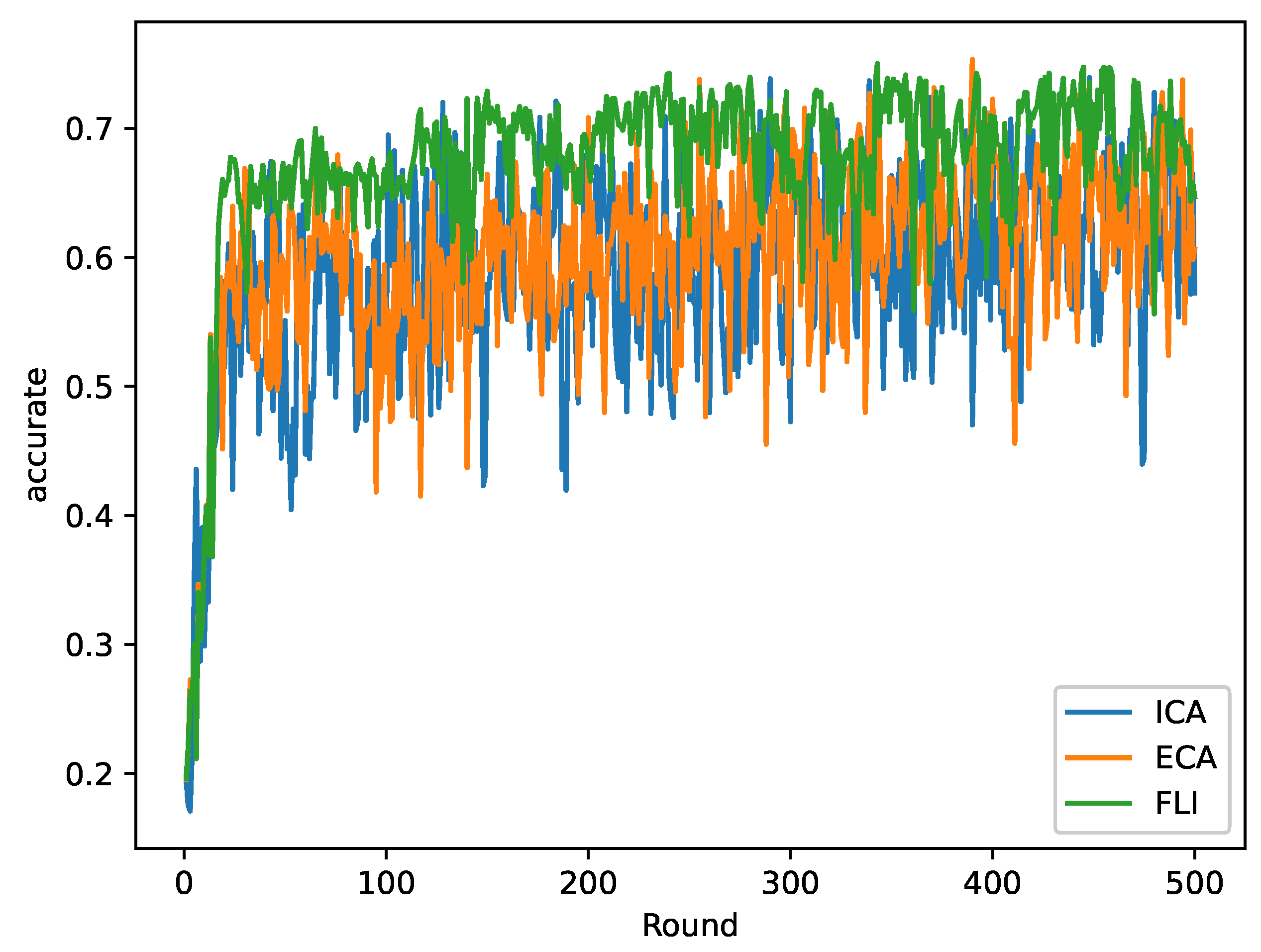
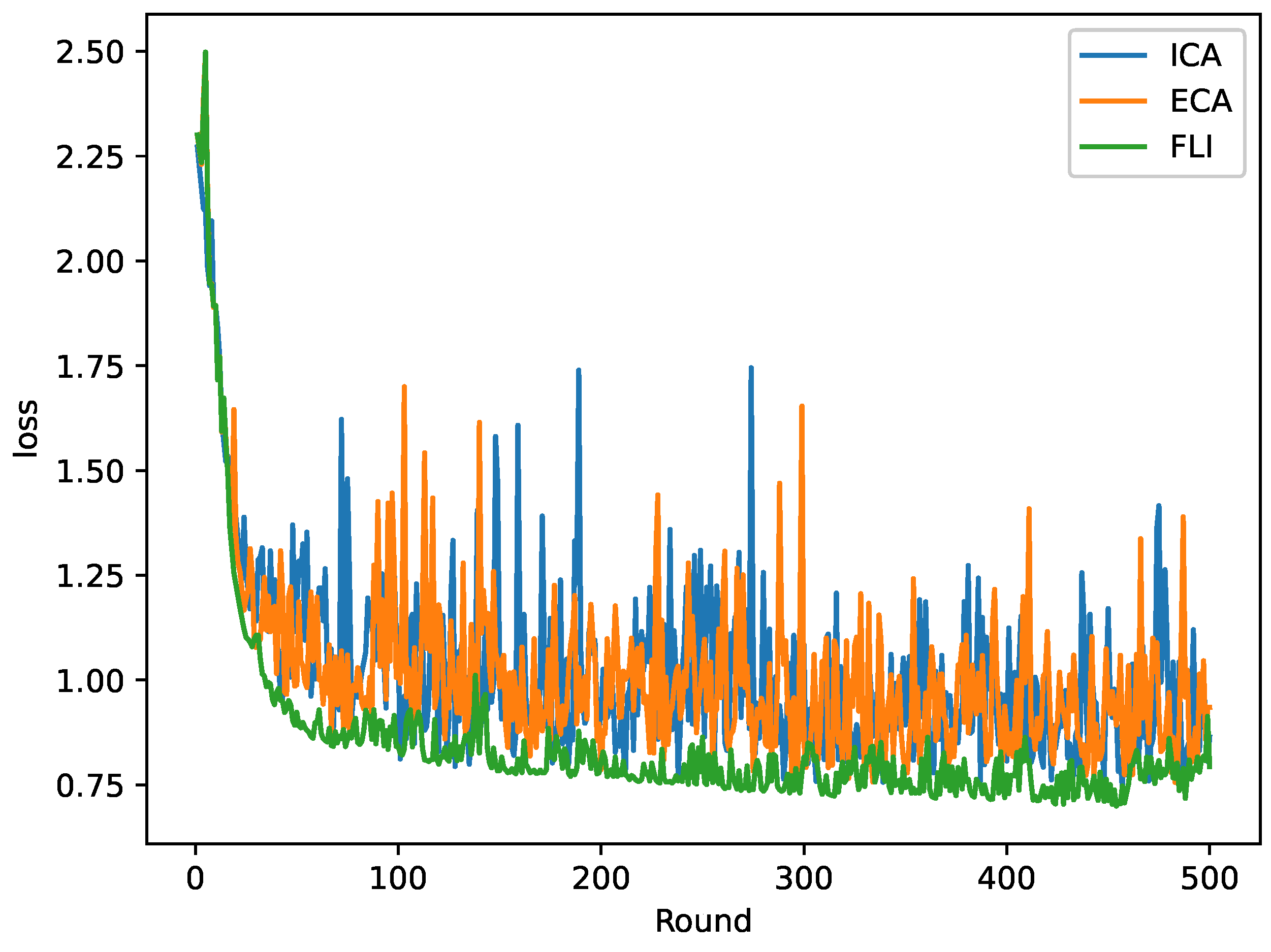
5.2. Results and Analysis
6. Discussion
7. Future Work
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kopetz, H.; Steiner, W. Internet of things. In Real-Time Systems: Design Principles for Distributed Embedded Applications; Springer: Cham, Switzerland, 2022; pp. 325–341. [Google Scholar]
- Bello, O.; Zeadally, S. Intelligent device-to-device communication in the internet of things. IEEE Syst. J. 2014, 10, 1172–1182. [Google Scholar] [CrossRef]
- Tien, J.M. Internet of things, real-time decision making, and artificial intelligence. Ann. Data Sci. 2017, 4, 149–178. [Google Scholar] [CrossRef]
- Motlagh, N.H.; Taleb, T.; Arouk, O. Low-altitude unmanned aerial vehicles-based internet of things services: Comprehensive survey and future perspectives. IEEE Internet Things J. 2016, 3, 899–922. [Google Scholar] [CrossRef]
- Qiu, J.; Grace, D.; Ding, G.; Zakaria, M.D.; Wu, Q. Air-ground heterogeneous networks for 5G and beyond via integrating high and low altitude platforms. IEEE Wirel. Commun. 2019, 26, 140–148. [Google Scholar] [CrossRef]
- Wang, J.; Shao, Y.; Ge, Y.; Yu, R. A survey of vehicle to everything (V2X) testing. Sensors 2019, 19, 334. [Google Scholar] [CrossRef]
- Tong, W.; Hussain, A.; Bo, W.X.; Maharjan, S. Artificial intelligence for vehicle-to-everything: A survey. IEEE Access 2019, 7, 10823–10843. [Google Scholar] [CrossRef]
- Seo, H.; Lee, K.D.; Yasukawa, S.; Peng, Y.; Sartori, P. LTE evolution for vehicle-to-everything services. IEEE Commun. Mag. 2016, 54, 22–28. [Google Scholar] [CrossRef]
- Yin, Y.; Liu, M.; Gui, G.; Gacanin, H.; Sari, H. Minimizing delay for MIMO-NOMA resource allocation in UAV-assisted caching networks. IEEE Trans. Veh. Technol. 2022, 72, 4728–4732. [Google Scholar] [CrossRef]
- Nellore, K.; Hancke, G.P. A survey on urban traffic management system using wireless sensor networks. Sensors 2016, 16, 157. [Google Scholar] [CrossRef]
- Liu, J.; Shi, Y.; Fadlullah, Z.M.; Kato, N. Space-air-ground integrated network: A survey. IEEE Commun. Surv. Tutor. 2018, 20, 2714–2741. [Google Scholar] [CrossRef]
- Yin, Y.; Gui, G.; Liu, M.; Gacanin, H.; Sari, H.; Adachi, F. Joint User pairing and resource allocation in air-to-ground communication-caching-charging integrated network based on NOMA. IEEE Trans. Veh. Technol. 2023, 72, 15819–15828. [Google Scholar] [CrossRef]
- Chen, Q.; Meng, W.; Li, S.; Li, C.; Chen, H.H. Civil aircrafts augmented space–air–ground-integrated vehicular networks: Motivation, breakthrough, and challenges. IEEE Internet Things J. 2021, 9, 5670–5683. [Google Scholar] [CrossRef]
- Cheng, N.; Xu, W.; Shi, W.; Zhou, Y.; Lu, N.; Zhou, H.; Shen, X. Air-ground integrated mobile edge networks: Architecture, challenges, and opportunities. IEEE Commun. Mag. 2018, 56, 26–32. [Google Scholar] [CrossRef]
- Buch, N.; Velastin, S.A.; Orwell, J. A review of computer vision techniques for the analysis of urban traffic. IEEE Trans. Intell. Transp. Syst. 2011, 12, 920–939. [Google Scholar] [CrossRef]
- Zhao, D.; Dai, Y.; Zhang, Z. Computational intelligence in urban traffic signal control: A survey. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2011, 42, 485–494. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, D.; Wang, S.; Tian, L. A promising trend for field information collection: An air-ground multi-sensor monitoring system. Inf. Process. Agric. 2018, 5, 224–233. [Google Scholar] [CrossRef]
- Barrado, C.; Messeguer, R.; López, J.; Pastor, E.; Santamaria, E.; Royo, P. Wildfire monitoring using a mixed air-ground mobile network. IEEE Pervasive Comput. 2010, 9, 24–32. [Google Scholar] [CrossRef]
- Valente, J.; Sanz, D.; Barrientos, A.; Del Cerro, J.; Ribeiro, Á.; Rossi, C. An air-ground wireless sensor network for crop monitoring. Sensors 2011, 11, 6088–6108. [Google Scholar] [CrossRef]
- Nigam, N.; Singh, D.P.; Choudhary, J. A review of different components of the intelligent traffic management system (ITMS). Symmetry 2023, 15, 583. [Google Scholar] [CrossRef]
- Latif, S.; Afzaal, H.; Zafar, N.A. Intelligent traffic monitoring and guidance system for smart city. In Proceedings of the 2018 International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 3–4 March 2018; pp. 1–6. [Google Scholar]
- Jordan, S.; Moore, J.; Hovet, S.; Box, J.; Perry, J.; Kirsche, K.; Lewis, D.; Tse, Z.T.H. State-of-the-art technologies for UAV inspections. IET Radar Sonar Navig. 2018, 12, 151–164. [Google Scholar] [CrossRef]
- Mentsiev, A.U.; Guzueva, E.R.; Magomaev, T.R. Security challenges of the Industry 4.0. J. Phys. Conf. Ser. 2020, 1515, 032074. [Google Scholar] [CrossRef]
- Zhou, Z.; Zhang, C.; Xu, C.; Xiong, F.; Zhang, Y.; Umer, T. Energy-efficient industrial internet of UAVs for power line inspection in smart grid. IEEE Trans. Ind. Inform. 2018, 14, 2705–2714. [Google Scholar] [CrossRef]
- Zhang, C.; Xie, Y.; Bai, H.; Yu, B.; Li, W.; Gao, Y. A survey on federated learning. Knowl.-Based Syst. 2021, 216, 106775. [Google Scholar] [CrossRef]
- Liu, M.; Xia, Y.; Zhao, H.; Guo, L.; Shi, Z.; Zhu, H. Federated Learning Technologies for 6G Industrial Internet of Things: From Requirements, Vision to Challenges, Opportunities. J. Electron. Inf. Technol. 2024, 46, 4335–4353. [Google Scholar]
- Bonawitz, K.; Eichner, H.; Grieskamp, W.; Huba, D.; Ingerman, A.; Ivanov, V.; Kiddon, C.; Konečnỳ, J.; Mazzocchi, S.; McMahan, B.; et al. Towards federated learning at scale: System design. Proc. Mach. Learn. Syst. 2019, 1, 374–388. [Google Scholar]
- Zhao, H.; Shi, Y.; Liu, M.; Zhu, H.; Xun, W. Fairness Can Save Lives: A MAB based Client Selection Strategy for Federated Learning towards IoV assisted ITS. IEEE Trans. Veh. Technol. 2024, 74, 5430–5441. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Zhan, Y.; Zhang, J.; Hong, Z.; Wu, L.; Li, P.; Guo, S. A survey of incentive mechanism design for federated learning. IEEE Trans. Emerg. Top. Comput. 2021, 10, 1035–1044. [Google Scholar] [CrossRef]
- Zhao, H.; Sui, M.; Liu, M.; Zhu, C.; Xun, W.; Xu, B.; Zhu, H. Are You Diligent, Inefficient, or Malicious? A Self-Safeguarding Incentive Mechanism for Large Scale-Federated Industrial Maintenance Based on Double Layer Reinforcement Learning. IEEE Internet Things J. 2024, 11, 19988–20001. [Google Scholar] [CrossRef]
- Zeng, R.; Zeng, C.; Wang, X.; Li, B.; Chu, X. A comprehensive survey of incentive mechanism for federated learning. arXiv 2021, arXiv:2106.15406. [Google Scholar]
- Asad, M.; Moustafa, A.; Rabhi, F.A.; Aslam, M. THF: 3-way hierarchical framework for efficient client selection and resource management in federated learning. IEEE Internet Things J. 2021, 9, 11085–11097. [Google Scholar] [CrossRef]
- Qu, Z.; Duan, R.; Chen, L.; Xu, J.; Lu, Z.; Liu, Y. Context-aware online client selection for hierarchical federated learning. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 4353–4367. [Google Scholar] [CrossRef]
- Wang, Y.; Su, Z.; Luan, T.H.; Li, R.; Zhang, K. Federated learning with fair incentives and robust aggregation for UAV-aided crowdsensing. IEEE Trans. Netw. Sci. Eng. 2021, 9, 3179–3196. [Google Scholar] [CrossRef]
- Chen, C.; Gong, S.; Zhang, W.; Zheng, Y.; Kiat, Y.C. DRL-based contract incentive for wireless-powered and UAV-assisted backscattering MEC system. IEEE Trans. Cloud Comput. 2024, 12, 264–276. [Google Scholar] [CrossRef]
- Xie, L.; Su, Z.; Chen, N.; Xu, Q. Secure data sharing in UAV-assisted crowdsensing: Integration of blockchain and reputation incentive. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar]
- Kang, J.; Xiong, Z.; Niyato, D.; Xie, S.; Zhang, J. Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory. IEEE Internet Things J. 2019, 6, 10700–10714. [Google Scholar] [CrossRef]
- Chabrol, M.; Sarramia, D.; Tchernev, N. Urban traffic systems modelling methodology. Int. J. Prod. Econ. 2006, 99, 156–176. [Google Scholar] [CrossRef]
- Abbasi, M.; Shahraki, A.; Taherkordi, A. Deep learning for network traffic monitoring and analysis (NTMA): A survey. Comput. Commun. 2021, 170, 19–41. [Google Scholar] [CrossRef]
- Liu, M.; Lin, W.; Wang, Q.; Gui, G. Survey on Data Heterogeneity Problems and Personalization Based Solutions of Federated Learning in Internet of Vehicles. J. Commun. 2024, 45, 207–224. [Google Scholar]
- Zhao, Y.; Li, M.; Lai, L.; Suda, N.; Civin, D.; Chandra, V. Federated learning with non-iid data. arXiv 2018, arXiv:1806.00582. [Google Scholar] [CrossRef]
- Wu, Q.; Zhang, R. Common throughput maximization in UAV-enabled OFDMA systems with delay consideration. IEEE Trans. Commun. 2018, 66, 6614–6627. [Google Scholar] [CrossRef]
- Albaseer, A.; Abdallah, M.; Al-Fuqaha, A.; Erbad, A. Client Selection Approach in Support of Clustered Federated Learning over Wireless Edge Networks. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Tang, M.; Ning, X.; Wang, Y.; Sun, J.; Wang, Y.; Li, H.; Chen, Y. FedCor: Correlation-based active client selection strategy for heterogeneous federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10102–10111. [Google Scholar]
- Sheng, Y.; Zeng, L.; Cao, S.; Dai, Q.; Yang, S.; Lu, J. FedBoost: Bayesian Estimation Based Client Selection for Federated Learning. IEEE Access 2024, 12, 52255–52266. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics. PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Shi, Y.; Yu, H.; Leung, C. Towards Fairness-Aware Federated Learning. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 11922–11938. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Chen, T.; Teng, S. A comprehensive survey on client selection strategies in federated learning. Comput. Netw. 2024, 251, 110663. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Value |
|---|---|
| Learning Rate | 0.005 |
| Local Training Epochs | 3 |
| Batch Size | 64 |
| Incentive Budget | 10,000 |
| CPU Frequency | 2 GHz |
| contribution adjustment coefficient | 0.01 |
| Communication Time and Energy | [0.3, 0.5], [0.3, 0.5] |
| 0.75 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Sui, M.; Xia, T.; Liu, M.; Yang, J.; Zhao, H. Energy-Efficient Federated Learning-Driven Intelligent Traffic Monitoring: Bayesian Prediction and Incentive Mechanism Design. Electronics 2025, 14, 1891. https://doi.org/10.3390/electronics14091891
Wang Y, Sui M, Xia T, Liu M, Yang J, Zhao H. Energy-Efficient Federated Learning-Driven Intelligent Traffic Monitoring: Bayesian Prediction and Incentive Mechanism Design. Electronics. 2025; 14(9):1891. https://doi.org/10.3390/electronics14091891
Chicago/Turabian StyleWang, Ye, Mengqi Sui, Tianle Xia, Miao Liu, Jie Yang, and Haitao Zhao. 2025. "Energy-Efficient Federated Learning-Driven Intelligent Traffic Monitoring: Bayesian Prediction and Incentive Mechanism Design" Electronics 14, no. 9: 1891. https://doi.org/10.3390/electronics14091891
APA StyleWang, Y., Sui, M., Xia, T., Liu, M., Yang, J., & Zhao, H. (2025). Energy-Efficient Federated Learning-Driven Intelligent Traffic Monitoring: Bayesian Prediction and Incentive Mechanism Design. Electronics, 14(9), 1891. https://doi.org/10.3390/electronics14091891