
Multi-Scale Edge-Guided Image Forgery Detection via Improved Self-Supervision and Self-Adversarial Training


Abstract
1. Introduction
- We propose an iterative self-supervised forgery image generation approach that produces various forged images by iteratively applying random splicing, copy-move, or inpainting forgeries. This approach not only increases the forged samples, mitigating the issue of pixel-level label imbalance where forged pixels are far fewer than real ones, but also enriches the diversity of forged samples by applying single and multiple tampering.
- We design a simple yet effective multi-scale edge-guided artifacts capturing (MEAC) module to characterize forgery artifacts at the edges of image content. The basic idea is that the transition zones between authentic and forged regions exhibit inconsistent artifacts closely near each other, whose sharp contrast aids in more easily revealing forgery traces. Based on this idea, we first use an edge extractor such as the Laplacian operator to generate multi-scale edge maps of the image. These maps guide the use of shallow stacked convolutional layers to capture the forgery artifacts. The parameters of the MEAC modules are optimized using a multi-scale edge loss.
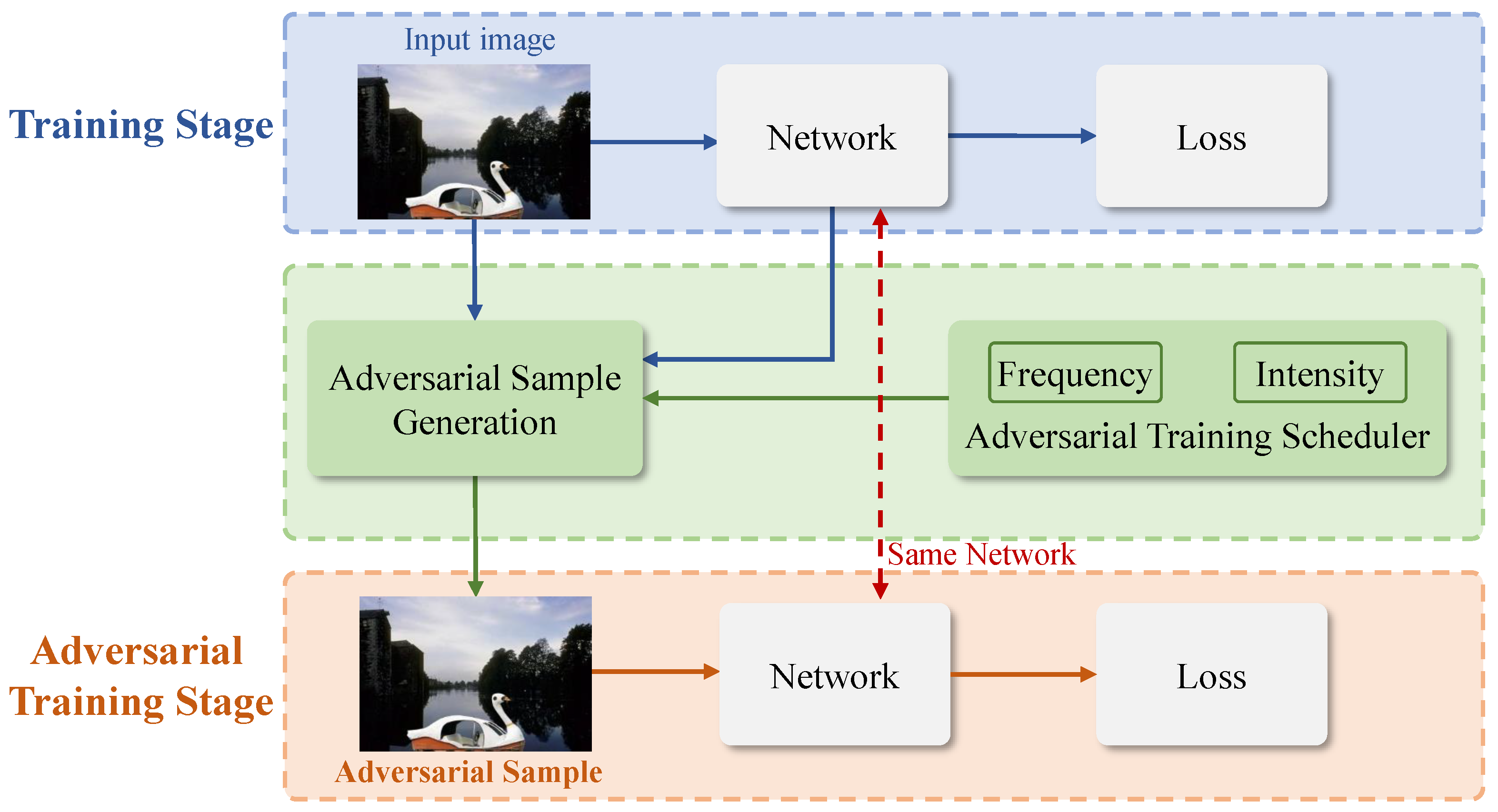
- We propose a progressive self-adversarial training strategy that intersperses the adversarial training stage within the standard training stage. This approach mitigates the issue of forgery detectors excessively focusing on specific traces, which can impair detection accuracy. The frequency and intensity of adversarial training gradually increase: in the early stages, when the detector’s capability is limited, both frequency and intensity are low, allowing the detector to focus on learning forgery traces. As the detector’s capabilities improve, both the frequency and intensity of the adversarial training are gradually raised, enabling the detector to learn from more difficult adversarial samples and thereby facilitating the learning of implicit forgery traces, enhancing detection performance. Unlike the self-adversarial training in [11], which fixes a high frequency for self-adversarial training and thus incurs an extremely high computational cost, our progressive self-adversarial strategy allows for more flexible adjustments of adversarial frequency and intensity, with a lower computational cost.
- We conduct extensive experiments including ablation studies and comparisons in both image-level and pixel-level forgery detection, validating the effectiveness and superiority of the proposed method over the compared methods in both detection accuracy and robustness against post-processing.
2. Related Works
2.1. Specialized Forgery Detection
2.2. Universal Forgery Detection
3. Proposed Method
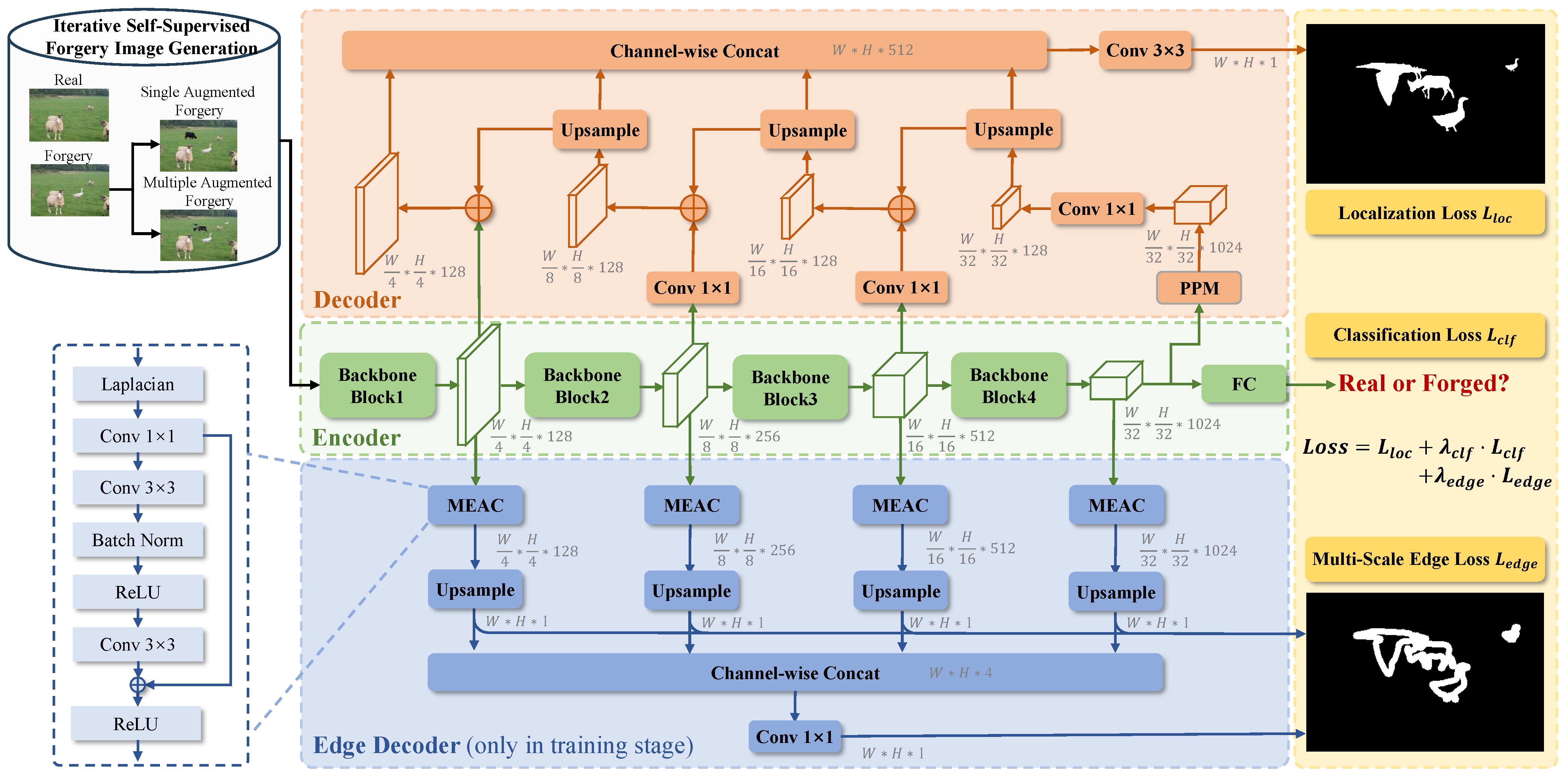
3.1. The Overall Framework
3.2. Iterative Self-Supervised Forgery Image Generation
| Algorithm 1 Iterative Self-Supervised Forgery Image Generation |
| Require: A forgery image I, the step k of iteration Ensure: The generated forgery image
|
3.3. Multi-Scale Edge Artifact Capturing Module
3.4. Progressive Self-Adversarial Training
- Stage 0 (Epoch 0–4): (meaning that insert 1 self-adversarial training every 5 standard training batches);
- Stage 1 (Epoch 5–9): ;
- Stage 2 (Epoch 10–14): ;
- Stage 3 (Epoch 15–19): .
3.5. Loss Function
- The image-level loss is to drive the detector to accurately classify real and fake images. We use the binary cross-entropy loss for image-level loss, denoted by .
- The pixel-level loss is to measure the goodness of forgery localization performance. It is formulated as a combination of the Dice Loss [27] and the binary cross-entropy loss:where serves an auxiliary role, and thus is set to .
- The edge-level loss measures the effectiveness of edge prediction at various scales and their combined version, similar in form to pixel-level loss, but includes terms for different scales and a fusion term:where , indicating that we have four edge maps corresponding to four scales, respectively.
4. Experimental Evaluation
4.1. Experiment Setup
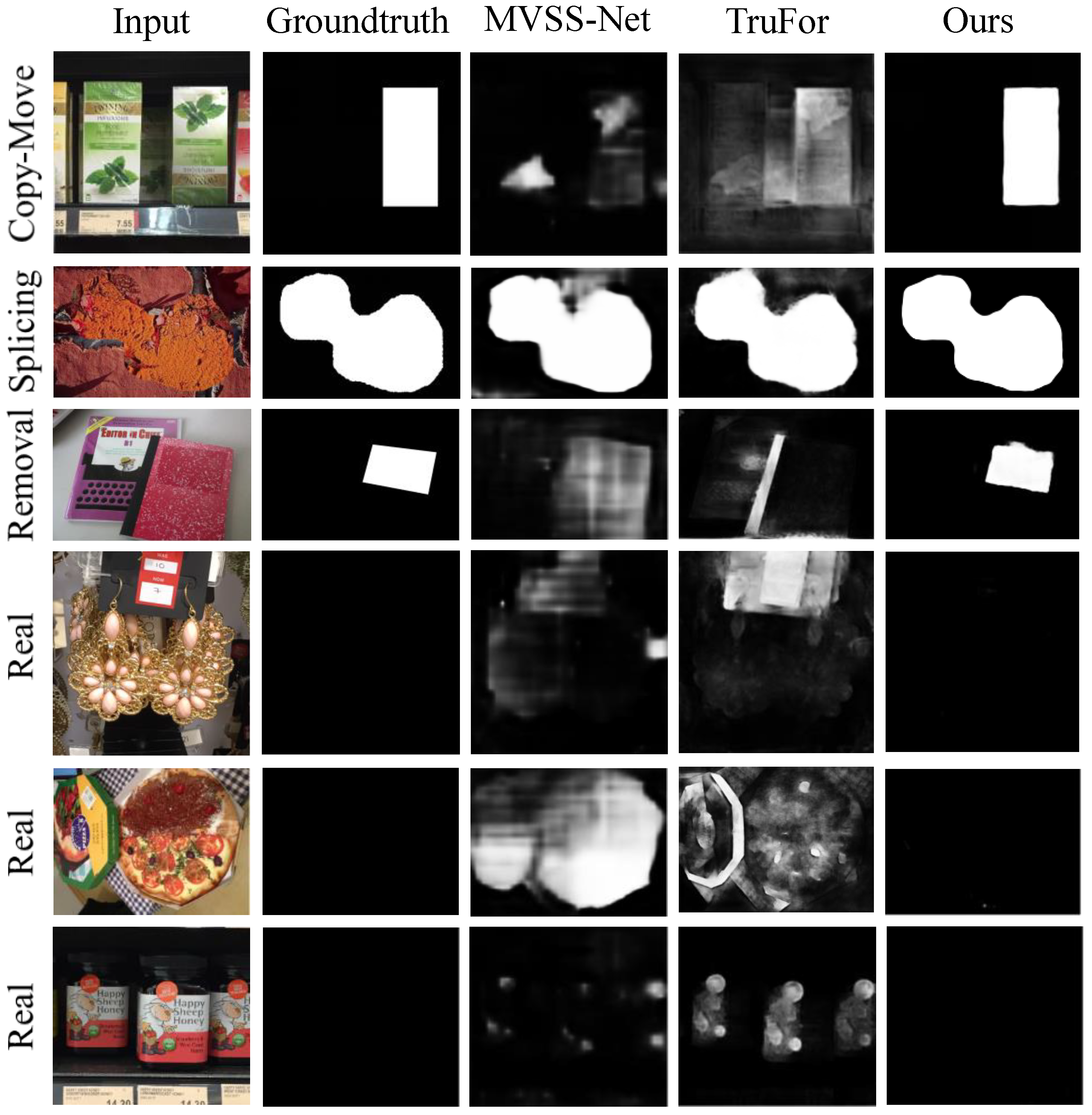
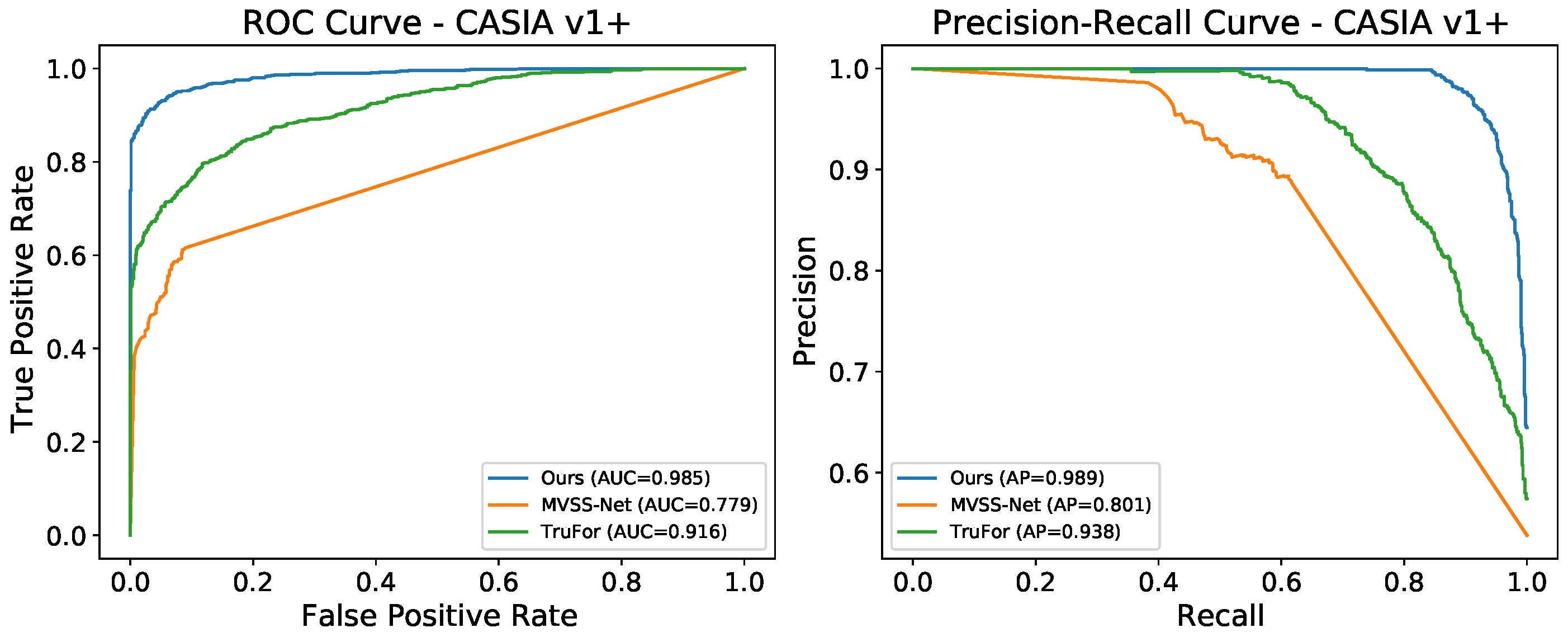
4.2. Performance Comparison with Existing Methods
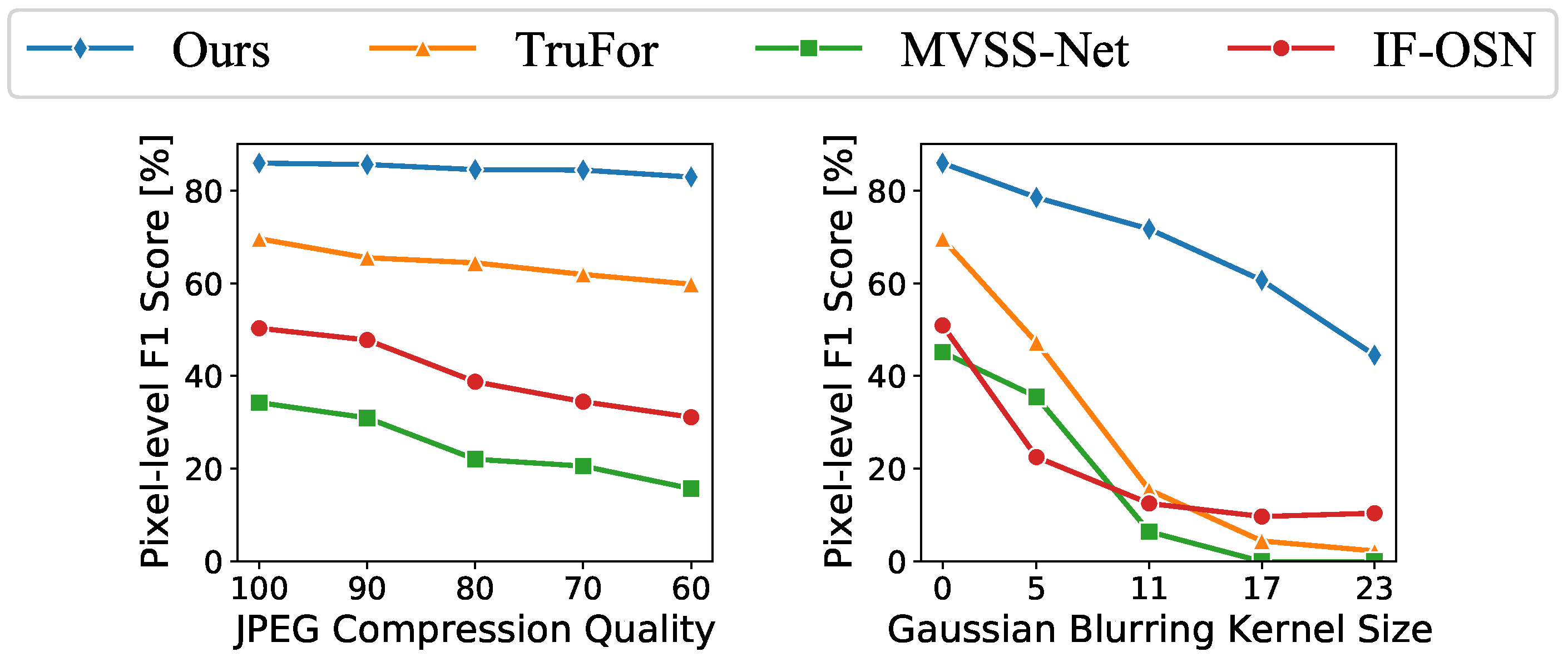
4.3. Robustness Study
4.4. Ablation Study
5. Conclusions
5.1. Limitations
5.2. Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Test Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sample Number | Forgery Type | Forged Pixel Percentage | ||||
|---|---|---|---|---|---|---|
| Authentic | Forged | Splicing | Copy-Move | Inpainting | ||
| NIST | 0 | 564 | ✓ | ✓ | ✓ | 7.5% |
| NIST+ | 160 | 160 | ✓ | ✓ | ✓ | 6.2% |
| Coverage | 100 | 100 | ✗ | ✓ | ✗ | 11.3% |
| Columbia | 183 | 180 | ✓ | ✗ | ✗ | 26.4% |
| CASIA v1+ | 800 | 920 | ✓ | ✓ | ✗ | 8.7% |
Appendix B. Ablation Study on Loss Functions (Image-Level Forgery Detection)
| NIST+ | Coverage | Columbia | CASIA v1+ | Mean | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC | ACC | AUC | ACC | AUC | ACC | AUC | ACC | AUC | ACC | |||
| ✓ | ✗ | ✗ | 0.718 | 0.659 | 0.787 | 0.695 | 0.994 | 0.967 | 0.986 | 0.922 | 0.871 | 0.811 |
| ✗ | ✓ | ✗ | 0.693 | 0.656 | 0.737 | 0.685 | 0.990 | 0.956 | 0.987 | 0.927 | 0.852 | 0.806 |
| ✗ | ✓ | ✓ | 0.759 | 0.688 | 0.786 | 0.700 | 0.997 | 0.981 | 0.981 | 0.934 | 0.880 | 0.826 |
Appendix C. Ablation Study on Training Methods (Image-Level Forgery Detection)
| + | + | +Self-sup. | +Self-adv. | NIST+ | Coverage | Columbia | CASIA v1+ | Mean | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AUC | ACC | AUC | ACC | AUC | ACC | AUC | ACC | AUC | ACC | ||||
| ✗ | ✗ | ✗ | ✗ | 0.517 | 0.497 | 0.445 | 0.500 | 0.068 | 0.154 | 0.498 | 0.645 | 0.382 | 0.404 |
| ✓ | ✗ | ✗ | ✗ | 0.633 | 0.572 | 0.478 | 0.490 | 0.896 | 0.777 | 0.712 | 0.661 | 0.680 | 0.625 |
| ✓ | ✓ | ✗ | ✗ | 0.772 | 0.659 | 0.669 | 0.605 | 0.995 | 0.984 | 0.959 | 0.897 | 0.849 | 0.786 |
| ✓ | ✓ | ✓ | ✗ | 0.693 | 0.656 | 0.737 | 0.685 | 0.990 | 0.956 | 0.987 | 0.927 | 0.852 | 0.806 |
| ✓ | ✓ | ✓ | ✓ | 0.705 | 0.641 | 0.733 | 0.670 | 0.990 | 0.948 | 0.992 | 0.934 | 0.855 | 0.798 |
References
- Wang, C.; Huang, Z.; Qi, S.; Yu, Y.; Shen, G.; Zhang, Y. Shrinking the semantic gap: Spatial pooling of local moment invariants for copy-move forgery detection. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1064–1079. [Google Scholar] [CrossRef]
- Liu, Y.; Xia, C.; Zhu, X.; Xu, S. Two-stage copy-move forgery detection with self deep matching and proposal superglue. IEEE Trans. Image Process. 2021, 31, 541–555. [Google Scholar] [CrossRef] [PubMed]
- Tan, Y.; Li, Y.; Zeng, L.; Ye, J.; Wang, W.; Li, X. Multi-scale Target-Aware Framework for Constrained Splicing Detection and Localization. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 8790–8798. [Google Scholar]
- Hadwiger, B.C.; Riess, C. Deep metric color embeddings for splicing localization in severely degraded images. IEEE Trans. Inf. Forensics Secur. 2022, 17, 2614–2627. [Google Scholar] [CrossRef]
- Wu, H.; Zhou, J. IID-Net: Image Inpainting Detection Network via Neural Architecture Search and Attention. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 1172–1185. [Google Scholar] [CrossRef]
- Zhang, Y.; Fu, Z.; Qi, S.; Xue, M.; Cao, X.; Xiang, Y. PS-Net: A Learning Strategy for Accurately Exposing the Professional Photoshop Inpainting. IEEE Trans. Neural Networks Learn. Syst. 2023, 35, 13874–13886. [Google Scholar] [CrossRef] [PubMed]
- Kwon, M.J.; Nam, S.H.; Yu, I.J.; Lee, H.K.; Kim, C. Learning JPEG Compression Artifacts for Image Manipulation Detection and Localization. Int. J. Comput. Vis. 2022, 130, 1875–1895. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Chen, J.; Liu, X. PSCC-Net: Progressive Spatio-Channel Correlation Network for Image Manipulation Detection and Localization. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7505–7517. [Google Scholar] [CrossRef]
- Yang, C.; Li, H.; Lin, F.; Jiang, B.; Zhao, H. Constrained R-CNN: A general image manipulation detection model. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020. [Google Scholar]
- Cozzolino, D.; Verdoliva, L. Noiseprint: A CNN-based camera model fingerprint. arXiv 2018, arXiv:1808.08396. [Google Scholar] [CrossRef]
- Zhuo, L.; Tan, S.; Li, B.; Huang, J. Self-Adversarial Training Incorporating Forgery Attention for Image Forgery Localization. IEEE Trans. Inf. Forensics Secur. 2022, 17, 819–834. [Google Scholar] [CrossRef]
- Hu, X.; Zhang, Z.; Jiang, Z.; Chaudhuri, S.; Yang, Z.; Nevatia, R. SPAN: Spatial Pyramid Attention Network forImage Manipulation Localization. In Computer Vision–ECCV 2020, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2020; pp. 312–328. [Google Scholar]
- Dong, C.; Chen, X.; Hu, R.; Cao, J.; Li, X. MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection. arXiv 2021, arXiv:2112.08935. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wu, Z.; Chen, J.; Han, X.; Shrivastava, A.; Lim, S.N.; Jiang, Y.G. ObjectFormer for Image Manipulation Detection and Localization. arXiv 2022, arXiv:2203.14681. [Google Scholar]
- Wu, Y.; AbdAlmageed, W.; Natarajan, P. ManTra-Net: Manipulation Tracing Network for Detection and Localization of Image Forgeries With Anomalous Features. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wu, H.; Zhou, J.; Tian, J.; Liu, J.; Qiao, Y. Robust Image Forgery Detection against Transmission over Online Social Networks. IEEE Trans. Inf. Forensics Secur. 2022, 17, 443–456. [Google Scholar] [CrossRef]
- Guillaro, F.; Cozzolino, D.; Sud, A.; Dufour, N.; Verdoliva, L. TruFor: Leveraging all-round clues for trustworthy image forgery detection and localization. arXiv 2022, arXiv:2212.10957. [Google Scholar]
- He, Y.; Li, Y.; Chen, C.; Li, X. Image Copy-Move Forgery Detection via Deep Cross-Scale PatchMatch. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; pp. 2327–2332. [Google Scholar]
- Islam, A.; Long, C.; Basharat, A.; Hoogs, A. DOA-GAN: Dual-Order Attentive Generative Adversarial Network for Image Copy-Move Forgery Detection and Localization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Ma, X.; Du, B.; Liu, X.; Hammadi, A.; Zhou, J. IML-ViT: Image Manipulation Localization by Vision Transformer. arXiv 2023, arXiv:2307.14863. [Google Scholar]
- Fridrich, J.; Kodovsky, J. Rich Models for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Bayar, B.; Stamm, M.C. Constrained Convolutional Neural Networks: A New Approach Towards General Purpose Image Manipulation Detection. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2691–2706. [Google Scholar] [CrossRef]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.; Xie, S.; Ai, M. ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders. arXiv 2023, arXiv:2301.00808. [Google Scholar]
- Xiao, T.; Liu, Y.; Zhou, B.; Jiang, Y.; Sun, J. Unified Perceptual Parsing for Scene Understanding. In Computer Vision–ECCV 2018, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; pp. 432–448. [Google Scholar]
- Salazar, A.; Vergara, L.; Vidal, E. A proxy learning curve for the bayes classifier. Pattern Recognit. 2023, 136, 109240. [Google Scholar] [CrossRef]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar] [CrossRef]
- Wen, B.; Zhu, Y.; Subramanian, R.; Ng, T.T.; Shen, X.; Winkler, S. COVERAGE—A novel database for copy-move forgery detection. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Hsu, Y.F.; Chang, S.F. Detecting Image Splicing using Geometry Invariants and Camera Characteristics Consistency. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006. [Google Scholar]
- Guan, H.; Kozak, M.; Robertson, E.; Lee, Y.; Yates, A.N.; Delgado, A.; Zhou, D.; Kheyrkhah, T.; Smith, J.; Fiscus, J. MFC Datasets: Large-Scale Benchmark Datasets for Media Forensic Challenge Evaluation. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Waikoloa Village, HI, USA, 7–11 January 2019. [Google Scholar]
- Dong, J.; Wang, W.; Tan, T. CASIA Image Tampering Detection Evaluation Database. In Proceedings of the 2013 IEEE China Summit and International Conference on Signal and Information Processing, Beijing, China, 6–10 July 2013. [Google Scholar]

| Method | Journal Conference | with Real Images | Self-sup. | Self-adv. | Loss Term(s) | Forensic Tasks | |||
|---|---|---|---|---|---|---|---|---|---|
| Image | Edge | Pixel | Detection | Localization | |||||
| Mantra-Net [15] | CVPR 2019 | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| SPAN [12] | ECCV 2020 | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| CR-CNN [9] | ICME 2020 | ✗ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| MVSS-Net [13] | ICCV 2021 | ✓ | ✓ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
| PSCC-Net [8] | TCSVT 2022 | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| SATFL [11] | TIFS 2022 | ✗ | ✗ | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ |
| CAT-Net v2 [7] | IJCV 2022 | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| IF-OSN [16] | TIFS 2022 | ✓ | ✗ | ✗ | ✗ | ✗ | ✓ | ✗ | ✓ |
| ObjectFormer [14] | CVPR 2022 | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ |
| TruFor [17] | CVPR 2023 | ✓ | ✗ | ✗ | ✓ | ✗ | ✓ | ✓ | ✓ |
| IML-ViT [20] | AAAI 2024 | ✓ | ✓ | ✗ | ✗ | ✓ | ✓ | ✗ | ✓ |
| Ours | - | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Method | NIST | Coverage | Columbia | CASIA v1+ | Mean | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | AUC | IOU | F1 | AUC | IOU | F1 | AUC | IOU | F1 | AUC | IOU | F1 | AUC | IOU | |
| PSCC [8] | 0.013 | 0.585 | 0.010 | 0.446 | 0.863 | 0.339 | 0.597 | 0.852 | 0.463 | 0.463 | 0.873 | 0.410 | 0.380 | 0.793 | 0.306 |
| ObjectFormer [14] | 0.151 | 0.604 | 0.075 | 0.194 | 0.518 | 0.112 | 0.334 | 0.438 | 0.258 | 0.154 | 0.522 | 0.087 | 0.208 | 0.521 | 0.133 |
| MVSS-Net [13] | 0.293 | 0.792 | 0.239 | 0.453 | 0.873 | 0.386 | 0.665 | 0.818 | 0.573 | 0.451 | 0.845 | 0.397 | 0.466 | 0.832 | 0.399 |
| IF-OSN [16] | 0.325 | 0.782 | 0.246 | 0.264 | 0.772 | 0.179 | 0.710 | 0.861 | 0.610 | 0.509 | 0.873 | 0.465 | 0.452 | 0.822 | 0.375 |
| CAT-Net v2 [7] | 0.295 | 0.726 | 0.227 | 0.291 | 0.832 | 0.231 | 0.796 | 0.946 | 0.744 | 0.715 | 0.959 | 0.643 | 0.524 | 0.866 | 0.461 |
| TruFor [17] | 0.342 | 0.830 | 0.261 | 0.525 | 0.920 | 0.451 | 0.799 | 0.896 | 0.735 | 0.696 | 0.949 | 0.633 | 0.591 | 0.899 | 0.520 |
| Ours | 0.488 | 0.869 | 0.418 | 0.673 | 0.945 | 0.613 | 0.947 | 0.976 | 0.927 | 0.863 | 0.979 | 0.806 | 0.743 | 0.942 | 0.691 |
| Method | NIST+ | Coverage | Columbia | CASIA v1+ | Mean | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | AUC | ACC | F1 | AUC | ACC | F1 | AUC | ACC | F1 | AUC | ACC | F1 | AUC | ACC | |
| PSCC [8] | 0.428 | 0.481 | 0.481 | 0.297 | 0.550 | 0.550 | 0.667 | 0.508 | 0.504 | 0.534 | 0.677 | 0.656 | 0.482 | 0.554 | 0.548 |
| ObjectFormer [14] | 0.144 | 0.449 | 0.453 | 0.183 | 0.497 | 0.485 | 0.260 | 0.530 | 0.521 | 0.341 | 0.472 | 0.491 | 0.232 | 0.487 | 0.488 |
| MVSS-Net [13] | 0.665 | 0.582 | 0.541 | 0.632 | 0.500 | 0.500 | 0.747 | 0.984 | 0.664 | 0.759 | 0.806 | 0.790 | 0.701 | 0.718 | 0.624 |
| IF-OSN [16] | 0.688 | 0.522 | 0.522 | 0.643 | 0.490 | 0.490 | 0.673 | 0.522 | 0.518 | 0.697 | 0.639 | 0.647 | 0.676 | 0.543 | 0.544 |
| CAT-Net v2 [7] | 0.648 | 0.648 | 0.528 | 0.629 | 0.607 | 0.570 | 0.876 | 0.963 | 0.865 | 0.800 | 0.875 | 0.770 | 0.738 | 0.773 | 0.683 |
| TruFor [17] | 0.496 | 0.652 | 0.606 | 0.451 | 0.500 | 0.500 | 0.983 | 0.996 | 0.983 | 0.801 | 0.916 | 0.815 | 0.683 | 0.766 | 0.726 |
| Ours | 0.614 | 0.747 | 0.697 | 0.737 | 0.821 | 0.750 | 0.937 | 0.994 | 0.934 | 0.928 | 0.986 | 0.920 | 0.804 | 0.887 | 0.825 |
| NIST+ | Coverage | Columbia | CASIA v1+ | Mean | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | IOU | F1 | IOU | F1 | IOU | F1 | IOU | F1 | IOU | |||
| ✓ | ✗ | ✗ | 0.178 | 0.098 | 0.433 | 0.276 | 0.560 | 0.389 | 0.351 | 0.213 | 0.380 | 0.244 |
| ✗ | ✓ | ✗ | 0.420 | 0.266 | 0.626 | 0.455 | 0.885 | 0.794 | 0.717 | 0.559 | 0.662 | 0.518 |
| ✗ | ✓ | ✓ | 0.454 | 0.294 | 0.639 | 0.469 | 0.937 | 0.881 | 0.817 | 0.691 | 0.712 | 0.584 |
| + | + | +Self-sup. | +Self-adv. | NIST+ | Coverage | Columbia | CASIA v1+ | Mean | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| F1 | IOU | F1 | IOU | F1 | IOU | F1 | IOU | F1 | IOU | ||||
| ✗ | ✗ | ✗ | ✗ | 0.355 | 0.215 | 0.464 | 0.302 | 0.752 | 0.602 | 0.533 | 0.364 | 0.526 | 0.371 |
| ✓ | ✗ | ✗ | ✗ | 0.428 | 0.272 | 0.512 | 0.344 | 0.878 | 0.782 | 0.660 | 0.492 | 0.619 | 0.473 |
| ✓ | ✓ | ✗ | ✗ | 0.447 | 0.288 | 0.525 | 0.356 | 0.850 | 0.738 | 0.698 | 0.536 | 0.630 | 0.480 |
| ✓ | ✓ | ✓ | ✗ | 0.420 | 0.266 | 0.626 | 0.455 | 0.885 | 0.794 | 0.717 | 0.559 | 0.662 | 0.518 |
| ✓ | ✓ | ✓ | ✓ | 0.414 | 0.320 | 0.665 | 0.498 | 0.887 | 0.797 | 0.730 | 0.575 | 0.674 | 0.548 |
| Iteration Count | CoCoGlide | InTheWild | Korus | DSO | Mean |
|---|---|---|---|---|---|
| No Self-sup. | 0.337 | 0.529 | 0.305 | 0.485 | 0.414 |
| Self-sup. | 0.343 | 0.548 | 0.293 | 0.488 | 0.418 |
| Self-sup. | 0.400 | 0.554 | 0.313 | 0.494 | 0.435 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Zeng, J.; Yang, J. Multi-Scale Edge-Guided Image Forgery Detection via Improved Self-Supervision and Self-Adversarial Training. Electronics 2025, 14, 1877. https://doi.org/10.3390/electronics14091877
Zhang H, Zeng J, Yang J. Multi-Scale Edge-Guided Image Forgery Detection via Improved Self-Supervision and Self-Adversarial Training. Electronics. 2025; 14(9):1877. https://doi.org/10.3390/electronics14091877
Chicago/Turabian StyleZhang, Huacong, Jishen Zeng, and Jianquan Yang. 2025. "Multi-Scale Edge-Guided Image Forgery Detection via Improved Self-Supervision and Self-Adversarial Training" Electronics 14, no. 9: 1877. https://doi.org/10.3390/electronics14091877
APA StyleZhang, H., Zeng, J., & Yang, J. (2025). Multi-Scale Edge-Guided Image Forgery Detection via Improved Self-Supervision and Self-Adversarial Training. Electronics, 14(9), 1877. https://doi.org/10.3390/electronics14091877