
Commonness and Inconsistency Learning with Structure Constrained Adaptive Loss Minimization for Multi-View Clustering


Abstract
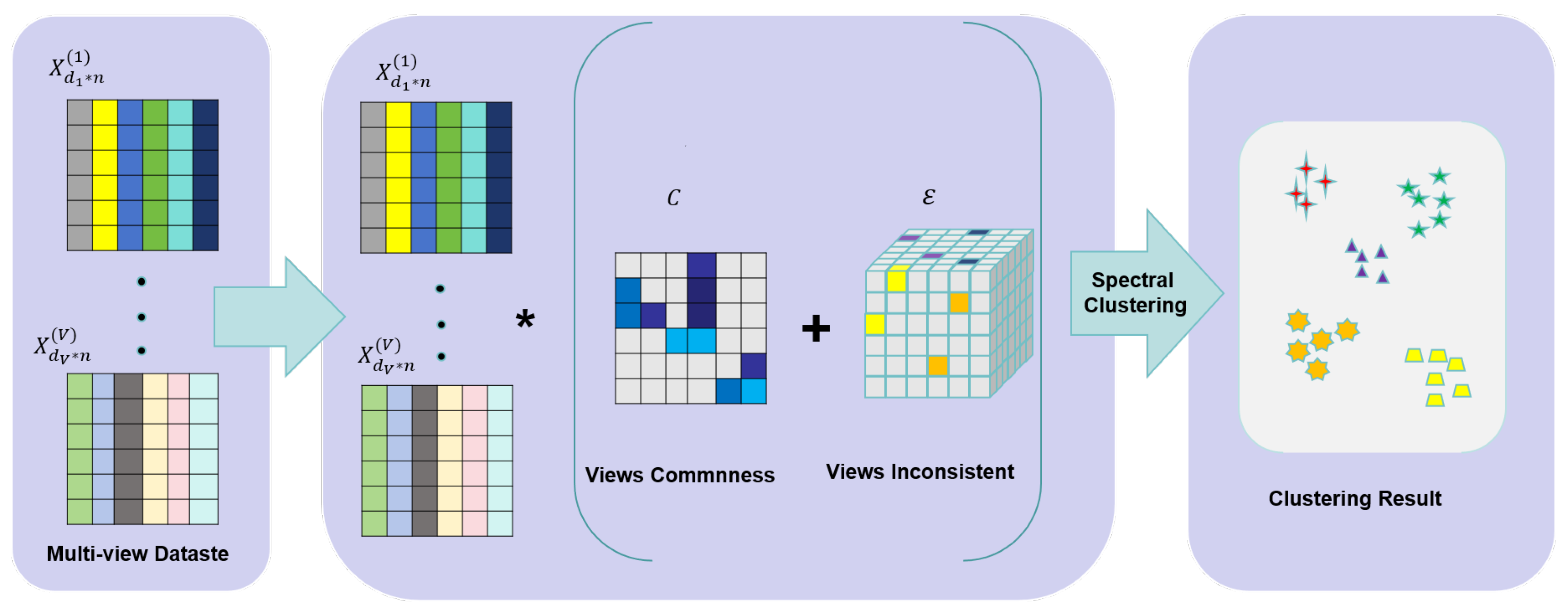
1. Introduction
2. Background Knowledge
3. Proposed Method
- 1.
- The norm is nonnegative and convex.
- 2.
- The norm is twice differentiable.
- 3.
- If , , then .
- 4.
- If , , then , where .
- 5.
- .
- 6.
- .
4. Optimization
4.1. -Subproblem
4.2. -Subproblem
4.3. -Subproblem
4.4. -Subproblem
4.5. -Subproblem
4.6. -Subproblem
4.7. Updating of ,, , and μ
4.8. Time Complexity
5. Experiments
5.1. Methods in Comparison
5.2. Datasets
5.3. Clustering Performance
5.4. Ablation Study
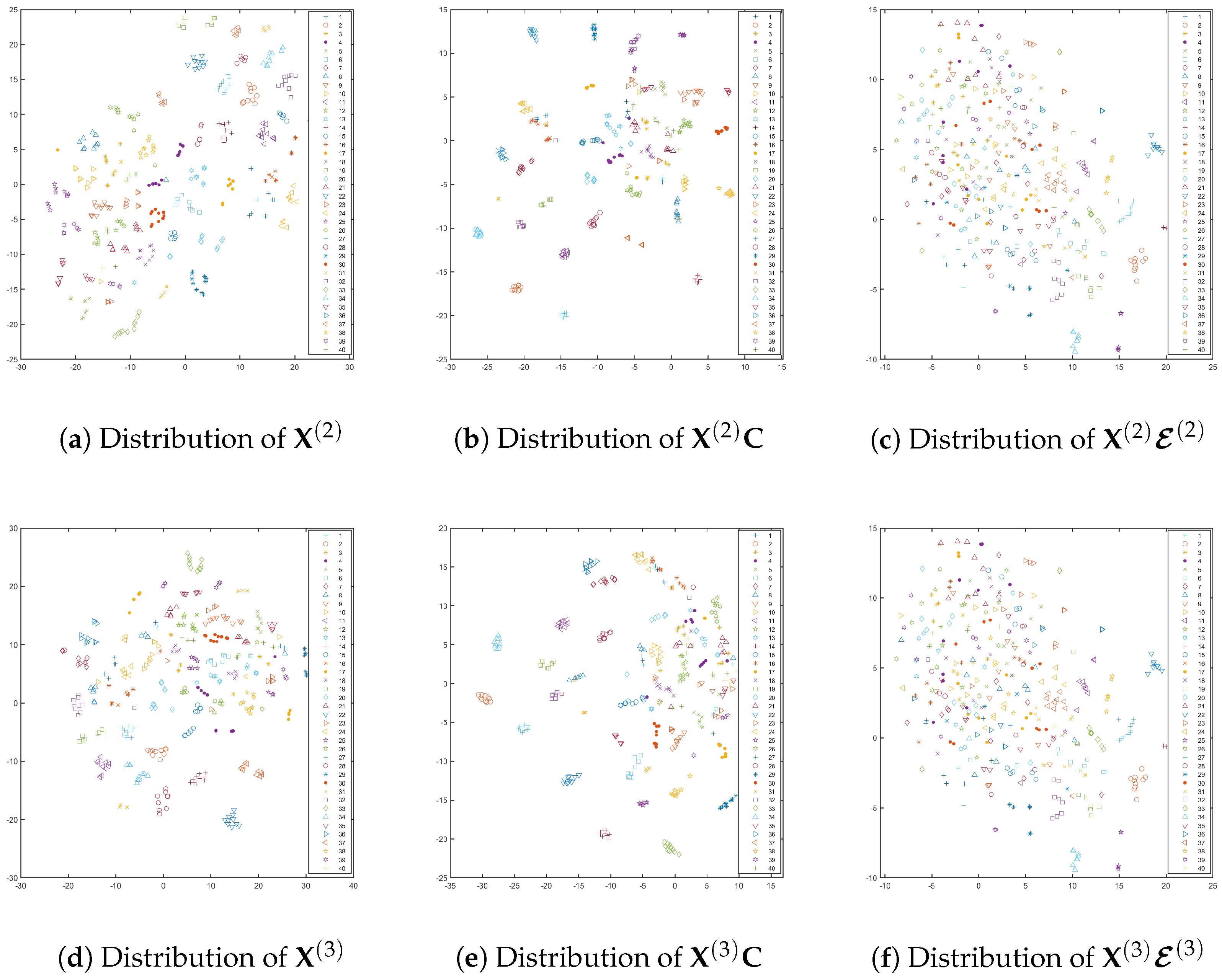
5.5. Visual Illustration of Data Distribution
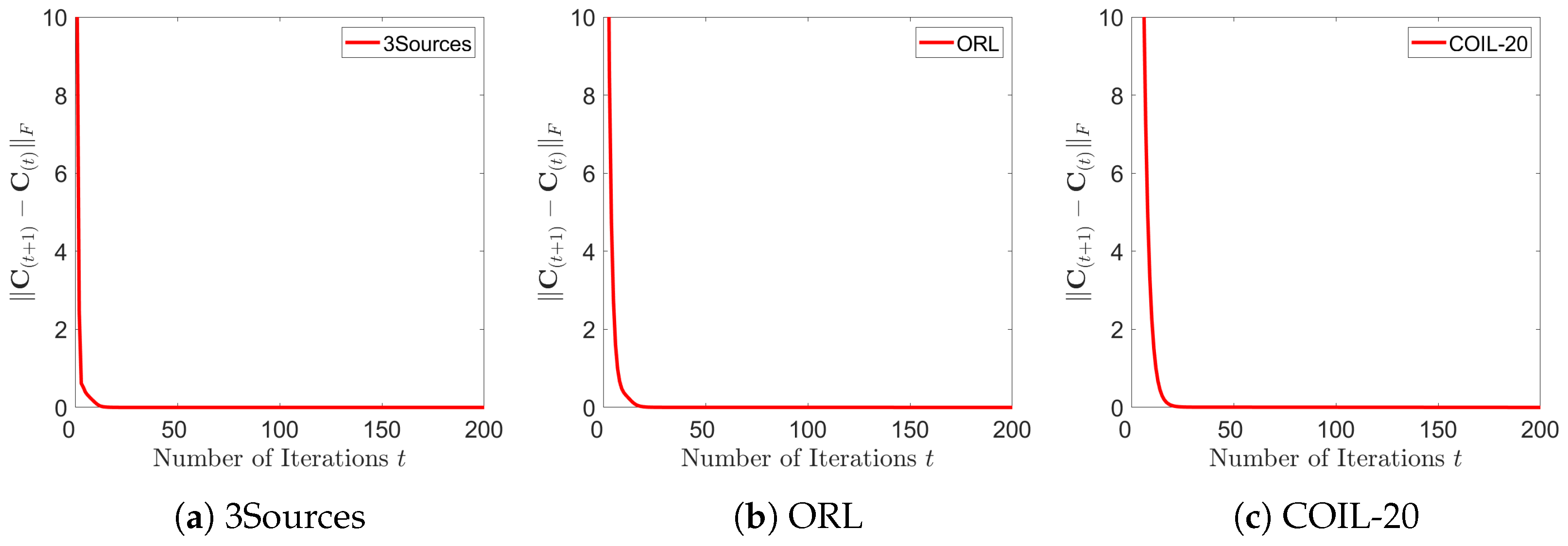
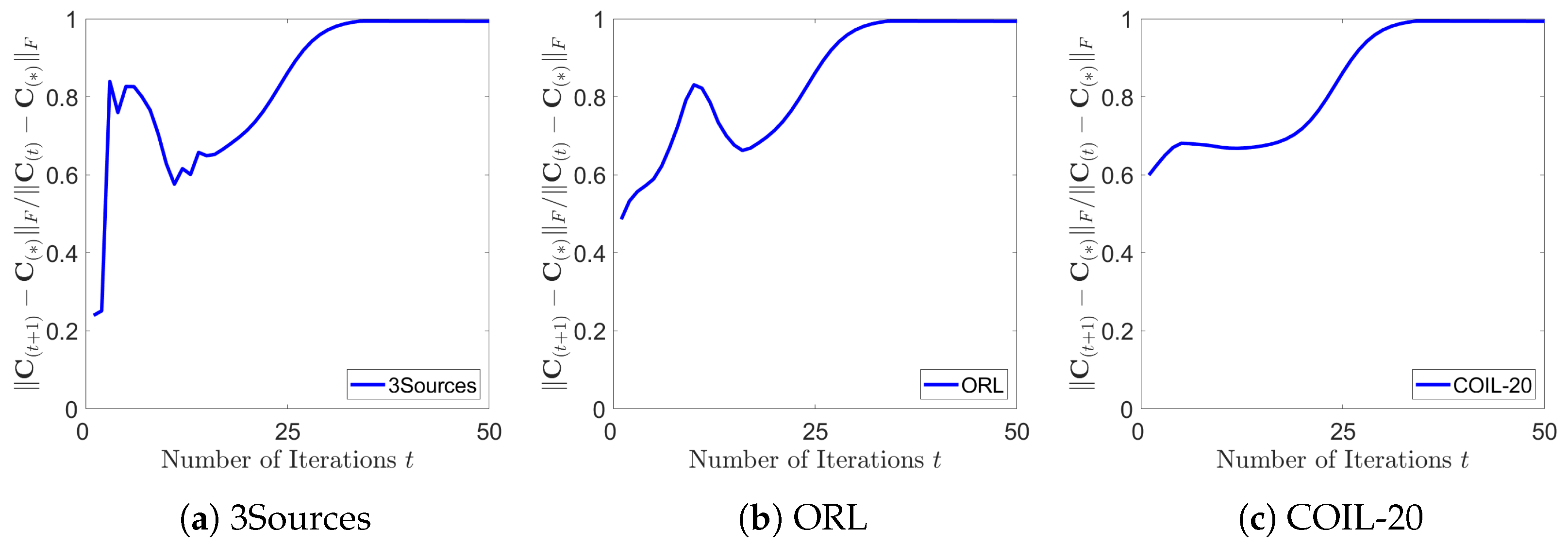
5.6. Convergence Analysis
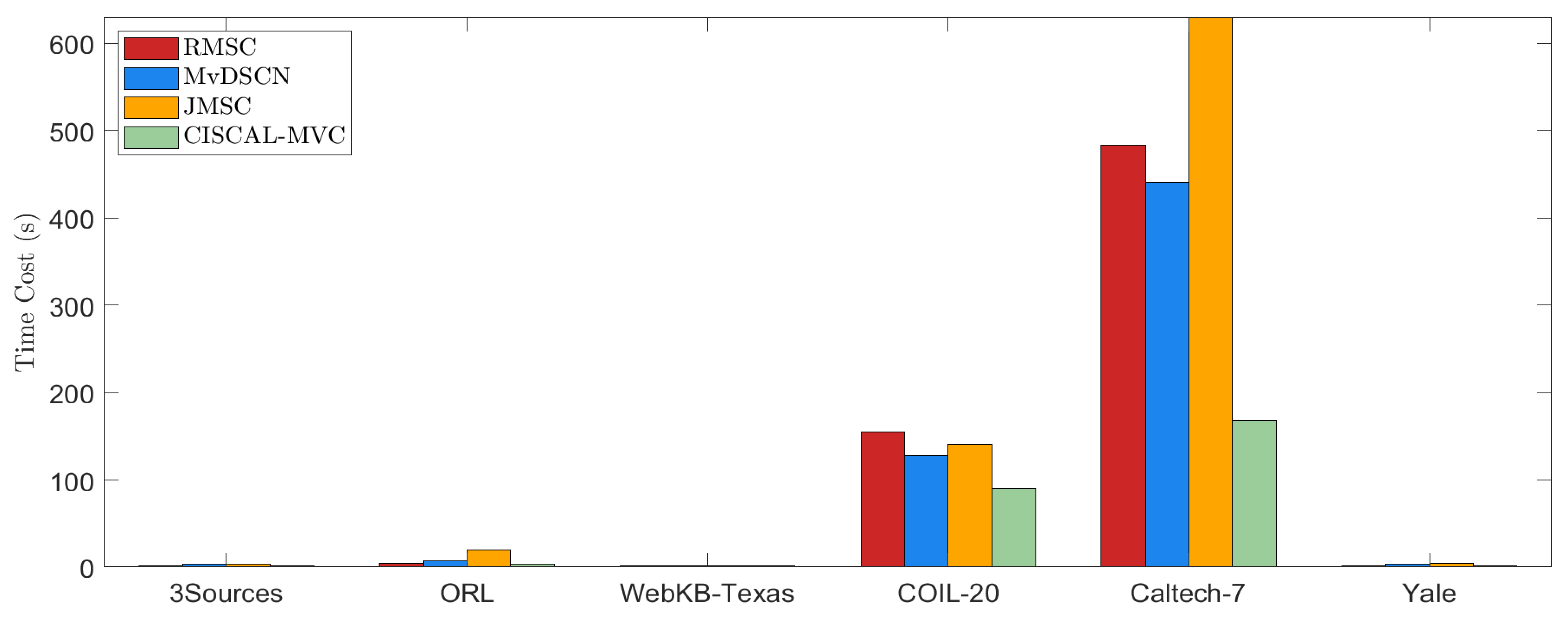
5.7. Comparison of Time Cost
5.8. Parametric Sensitivity
5.9. Data Reconstruction
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviation
| CISCAL-MVC | Commonness and Inconsistency Learning with Structure Constrained Adaptive Loss Minimization for Multi-view Clustering |
References
- Lei, T.; Liu, P.; Jia, X.; Zhang, X.; Meng, H.; Nandi, A.K. Automatic fuzzy clustering framework for image segmentation. IEEE Trans. Fuzzy Syst. 2019, 28, 2078–2092. [Google Scholar]
- Peng, C.; Zhang, J.; Chen, Y.; Xing, X.; Chen, C.; Kang, Z.; Guo, L.; Cheng, Q. Preserving bilateral view structural information for subspace clustering. Knowl.-Based Syst. 2022, 258, 109915. [Google Scholar] [CrossRef]
- Park, N.; Rossi, R.; Koh, E.; Burhanuddin, I.A.; Kim, S.; Du, F.; Ahmed, N.; Faloutsos, C. Cgc: Contrastive graph clustering forcommunity detection and tracking. In Proceedings of the ACM Web Conference 2022, Lyon, France, 25–29 April 2022; pp. 1115–1126. [Google Scholar]
- Gönen, M.; Margolin, A.A. Localized data fusion for kernel k-means clustering with application to cancer biology. In Proceedings of the Advances in Neural Information Processing Systems, Quebec, QC, Canada, 8–13 December 2014; pp. 1305–1313. [Google Scholar]
- Guan, R.; Zhang, H.; Liang, Y.; Giunchiglia, F.; Huang, L.; Feng, X. Deep feature-based text clustering and its explanation. IEEE Trans. Knowl. Data Eng. 2020, 34, 3669–3680. [Google Scholar]
- Peng, C.; Kang, Z.; Li, H.; Cheng, Q. Subspace clustering using logdeterminant rank approximation. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 925–934. [Google Scholar]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 171–184. [Google Scholar]
- Peng, C.; Zhang, Y.; Chen, Y.; Kang, Z.; Chen, C.; Cheng, Q. Log-based sparse nonnegative matrix factorization for data representation. Knowl.-Based Syst. 2022, 251, 109127. [Google Scholar]
- Vidal, R.; Ma, Y.; Sastry, S. Generalized principal component analysis (gpca). IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1945–1959. [Google Scholar] [CrossRef]
- Rao, S.; Tron, R.; Vidal, R.; Ma, Y. Motion segmentation in the presence of outlying, incomplete, or corrupted trajectories. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1832–1845. [Google Scholar]
- Sun, M.; Zhang, P.; Wang, S.; Zhou, S.; Tu, W.; Liu, X.; Zhu, E.; Wang, C. Scalable multi-view subspace clustering with unified anchors. In Proceedings of the 29th ACM International Conference on Multimedia, Chengdu, China, 20–24 October 2021; pp. 3528–3536. [Google Scholar]
- Peng, C.; Kang, Z.; Cheng, Q. Subspace clustering via variance regularized ridge regression. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2931–2940. [Google Scholar]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar]
- Wang, F.; Chen, C.; Peng, C. Essential low-rank sample learning for group-Aware subspace clustering. IEEE Signal Process. Lett. 2023, 30, 1537–1541. [Google Scholar]
- Zhang, C.; Fu, H.; Hu, Q.; Cao, X.; Xie, Y.; Tao, D.; Xu, D. Generalized latent multi-view subspace clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 86–99. [Google Scholar]
- Wang, H.; Yang, Y.; Liu, B. Gmc: Graph-based multi-view clustering. IEEE Trans. Knowl. Data Eng. 2019, 32, 1116–1129. [Google Scholar] [CrossRef]
- Zhan, K.; Zhang, C.; Guan, J.; Wang, J. Graph learning for multiview clustering. IEEE Trans. Cybern. 2017, 48, 288–2895. [Google Scholar] [CrossRef]
- Kumar, A.; Rai, P.; Daume, H. Co-regularized multi-view spectral clustering. In Proceedings of the Advances in Neural Information Processing Systems, Granada, Spain, 12–17 December 2011; pp. 1413–1421. [Google Scholar]
- Wang, X.; Guo, X.; Lei, Z.; Zhang, C.; Li, S.Z. Exclusivity-consistency regularized multi-view subspace clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 923–931. [Google Scholar]
- Bai, R.; Huang, R.; Qin, Y.; Chen, Y.; Xu, Y. A structural consensus representation learning framework for multi-view clustering. Knowl.-Based Syst. 2024, 283, 111132. [Google Scholar] [CrossRef]
- Wu, J.; Lin, Z.; Zha, H. Essential tensor learning for multi-view spectral clustering. IEEE Trans. Image Process. 2019, 28, 5910–5922. [Google Scholar] [PubMed]
- Xia, R.; Pan, Y.; Du, L.; Yin, J. Robust multi-view spectral clustering via low-rank and sparse decomposition. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec, QC, Canada, 27–31 July 2014; pp. 2149–2155. [Google Scholar]
- Li, R.; Zhang, C.; Fu, H.; Peng, X.; Zhou, T.; Hu, Q. Reciprocal multi-layer subspace learning for multi-view clustering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 8172–8180. [Google Scholar]
- Zhang, C.; Fu, H.; Liu, S.; Liu, G.; Cao, X. Low-rank tensor constrained multiview subspace clustering. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1582–1590. [Google Scholar]
- Luo, S.; Zhang, C.; Zhang, W.; Cao, X. Consistent and specific multi-view subspace clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3730–3737. [Google Scholar]
- Chen, J.; Yang, S.; Mao, H.; Fahy, C. Multiview subspace clustering using low-rank representation. IEEE Trans. Cybern. 2021, 52, 12364–12378. [Google Scholar] [CrossRef]
- Li, D.; Wang, T.; Chen, J.; Lian, C.; Zeng, Z. Multi-view class incremental learning. Inf. Fusion 2024, 102, 102021. [Google Scholar] [CrossRef]
- Liu, S.; Wang, S.; Zhang, P.; Xu, K.; Liu, X.; Zhang, C.; Gao, F. Efficient One-Pass Multi-View Subspace Clustering with Consensus Anchors. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; pp. 7576–7584. [Google Scholar]
- Nie, F.; Wang, H.; Huang, H.; Ding, C. Adaptive loss minimization for semisupervised elastic embedding. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 1565–1571. [Google Scholar]
- Cai, X.; Huang, D.; Zhang, G.Y.; Wang, C.D. Seeking commonness and inconsistencies: A jointly smoothed approach to multi-view subspace clustering. Inf. Fusion. 2023, 91, 364–375. [Google Scholar]
- Cai, D.; He, X.; Han, J. Graph regularized nonnegative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1548–1560. [Google Scholar]
- Lu, C.; Feng, J.; Lin, Z.; Mei, T.; Yan, S. Subspace clustering by block diagonal representation. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 48–501. [Google Scholar] [CrossRef]
- Dattorro, J. Convex Optimization & Euclidean Distance Geometry, 2nd ed.; Meboo Publishing: Palo Alto, CA, USA, 2018. [Google Scholar]
- Bartels, R.H.; Stewart, G.W. Solution of the matrix equation AX + XB = C. Commun. ACM 1972, 15, 820–826. [Google Scholar] [CrossRef]
- Golub, G.; Nash, S.; Van, C. A Hessenberg-Schur method for the problem AX + XB= C. IEEE Trans. Autom. Control. 1979, 24, 909–913. [Google Scholar]
- Xie, X.; Guo, X.; Liu, G.; Wang, J. Implicit block diagonal low-rank representation. IEEE Trans. Image Process. 2017, 27, 477–489. [Google Scholar] [CrossRef] [PubMed]
- McCoy, M.B.; Tropp, J.A. Two proposals for robust pca using semidefinite programming. Electron. J. Stat. 2010, 5, 1123–1160. [Google Scholar] [CrossRef]
- Wang, H.; Li, H.; Fu, X. Auto-weighted mutli-view sparse reconstructive embedding. Multimed. Tools Appl. 2019, 78, 30959–30973. [Google Scholar] [CrossRef]
- Hu, Z.; Nie, F.; Wang, R.; Li, X. Multi-view spectral clustering via integrating nonnegative embedding and spectral embedding. Inf. Fusion 2020, 55, 251–259. [Google Scholar] [CrossRef]
- Craven, M.; DiPasquo, D.; Freitag, D.; McCallum, A.; Mitchell, T.; Nigam, K.; Slattery, S. Learning to extract symbolic knowledge from the world wide web. In Proceedings of the AAAI Conference on Artificial Intelligence, Madison, WI, USA, 26–30 July 1998; pp. 509–516. [Google Scholar]
- Nene, S.A.; Nayar, S.K.; Murase, H. Columbia Object Image Library (Coil-20); Department of Computer Science, Columbia University: New York, NY, USA, 1996. [Google Scholar]
- Li, F.-F.; Fergus, R.; Perona, P. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; p. 178. [Google Scholar]
- Chen, M.S.; Huang, L.; Wang, C.D.; Huang, D.; Lai, J.H. Relaxed multiview clustering in latent embedding space. Inf. Fusion 2021, 68, 8–21. [Google Scholar] [CrossRef]
- Liu, X.; Zhu, X.; Li, M.; Wang, L.; Tang, C.; Yin, J.; Shen, D.; Wang, H.; Gao, W. Late fusion incomplete multi-view clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 2410–2423. [Google Scholar] [CrossRef]
- Strehl, A.; Ghosh, J. Cluster ensembles—A knowledge reuse framework for combining multiple partitions. J. Mach. Learn. Res. 2002, 3, 583–617. [Google Scholar]
- Zhang, Z.; Liu, L.; Shen, F.; Shen, H.T.; Shao, L. Binary multi-view clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1774–1782. [Google Scholar] [CrossRef]
- Huang, D.; Wang, C.D.; Peng, H.; Lai, J.; Kwoh, C.K. Enhanced ensemble clustering via fast propagation of cluster-wise similarities. IEEE Trans. Syst. Man. Cybern. Syst. 2018, 51, 508–520. [Google Scholar] [CrossRef]
- Sharma, K.; Seal, A.; Yazidi, A.; Krejcar, O. S-Divergence-Based Internal Clustering Validation Index. Int. J. Interact. Multimedia Artif. Intell. 2023, 8, 127–139. [Google Scholar]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2001; pp. 849–856. [Google Scholar]
- Tzortzis, G.; Likas, A. Kernel-based weighted multi-view clustering. In Proceedings of the 2012 IEEE 12th international conference on data mining, Brussels, Belgium, 10–13 December 2012; pp. 675–684. [Google Scholar]
- Li, Y.; Nie, F.; Huang, H.; Huang, J. Large-scale multi-view spectral clustering via bipartite graph. In Proceedings of the AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2750–2756. [Google Scholar]
- Wang, S.; Liu, X.; Zhu, X.; Zhang, P.; Zhang, Y.; Gao, F.; Zhu, E. Fast parameter-free multi-view subspace clustering with consensus anchor guidance. IEEE Trans. Image Process. 2021, 31, 556–568. [Google Scholar] [CrossRef] [PubMed]
- Zhu, P.; Yao, X.; Wang, Y.; Hui, B.; Du, D.; Hu, Q. Multiview deep subspace clustering networks. IEEE Trans. Cybern. 2024, 54, 4280–4293. [Google Scholar]
- Peng, C.; Kang, K.; Chen, Y. Fine-grained essential tensor learning for robust multi-view spectral clustering. IEEE Trans. Image Process. 2024, 33, 3145–3160. [Google Scholar]
- Peng, C.; Zhang, K.; Chen, Y. Cross-view diversity embedded consensus learning for multi-view clustering. In Proceedings of the the Thirty-Third International Joint Conference on Artificial Intelligence, Jeju Island, Republic of Korea, 3–9 August 2024; pp. 4788–4796. [Google Scholar]
- Wen, J.; Zhang, Z.; Zhang, B.; Xu, Y.; Zhang, Z. A Survey on Incomplete Multiview Clustering. IEEE Trans. Cybern. 2023, 53, 1136–1149. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | k | V | n | Dim. of Each View () | ||
|---|---|---|---|---|---|---|
| View 1 | View 2 | View 3 | ||||
| 3Sources | 6 | 3 | 169 | 3068 | 3631 | 3560 |
| ORL | 40 | 3 | 400 | 4096 | 6750 | 3304 |
| WebKB-Texas | 4 | 2 | 187 | 187 | 1703 | |
| COIL-20 | 20 | 3 | 1440 | 1024 | 3304 | 6750 |
| Caltech-7 | 7 | 3 | 1474 | 512 | 1984 | 928 |
| Yale | 15 | 3 | 165 | 4096 | 3304 | 6750 |
| Dataset | 3Sources | ORL | WebKB-Texas | |||||||||
| Method | ACC | NMI | ARI | PUR | ACC | NMI | ARI | PUR | ACC | NMI | ARI | PUR |
| SC | 48.52 | 38.69 | 20.81 | 59.17 | 77.25 | 89.12 | 69.75 | 80.00 | 57.75 | 29.36 | 23.91 | 69.52 |
| MVSpec | 25.44 | 6.610 | 00.85 | 39.64 | 19.50 | 39.42 | 1.980 | 21.25 | 32.09 | 10.15 | −4.640 | 55.08 |
| RMSC | 62.54 | 58.56 | 48.87 | 76.33 | 70.23 | 84.79 | 61.42 | 74.31 | 48.64 | 26.01 | 18.51 | 68.80 |
| MVGL | 35.50 | 8.070 | −0.720 | 40.24 | 72.00 | 82.96 | 38.79 | 77.75 | 51.87 | 6.550 | 2.480 | 57.22 |
| BMVC | 65.68 | 58.69 | 54.32 | 73.37 | 16.75 | 39.29 | 00.61 | 18.00 | 56.68 | 24.73 | 25.18 | 68.98 |
| SMVSC | 31.36 | 8.920 | 4.000 | 44.38 | 56.25 | 75.26 | 42.39 | 60.25 | 56.25 | 21.42 | 29.01 | 67.91 |
| MVSC | 75.85 | 66.48 | 58.38 | 80.89 | 72.36 | 84.69 | 56.59 | 77.05 | 55.13 | 1.980 | 0.190 | 56.10 |
| FPMVS-CAG | 26.04 | 6.590 | 42.60 | 1.010 | 56.00 | 74.63 | 39.99 | 60.00 | 57.75 | 22.76 | 29.81 | 65.78 |
| JSMC | 77.51 | 69.52 | 65.17 | 82.25 | 82.00 | 91.46 | 77.79 | 84.50 | 73.33 | 38.04 | 32.26 | 70.05 |
| MvDSCN | 77.24 | 68.29 | 61.35 | 81.21 | 87.25 | 1.01 | 82.98 | 81.06 | 57.62 | 28.14 | 28.19 | 68.86 |
| CISCAL-MVC | 78.70 | 72.06 | 65.90 | 85.21 | 89.25 | 93.59 | 83.58 | 90.50 | 77.83 | 42.24 | 44.84 | 77.83 |
| Dataset | COIL-20 | Caltech-7 | Yale | |||||||||
| Method | ACC | NMI | ARI | PUR | ACC | NMI | ARI | PUR | ACC | NMI | ARI | PUR |
| SC | 72.36 | 80.80 | 66.79 | 74.72 | 46.40 | 38.24 | 30.55 | 82.29 | 63.64 | 64.94 | 45.06 | 62.24 |
| MVSpec | 15.76 | 24.36 | 4.480 | 13.19 | 38.87 | 10.79 | −1.73 | 55.16 | 21.82 | 25.14 | 0.260 | 22.42 |
| RMSC | 70.84 | 80.42 | 66.14 | 72.51 | 40.39 | 42.11 | 32.05 | 48.13 | 61.21 | 66.36 | 45.65 | 62.36 |
| MVGL | 81.39 | 93.80 | 78.21 | 86.25 | 66.28 | 55.98 | 41.99 | 85.53 | 64.85 | 67.15 | 41.53 | 64.85 |
| BMVC | 40.63 | 50.69 | 27.83 | 40.76 | 47.15 | 47.29 | 36.34 | 84.94 | 22.42 | 27.57 | 1.770 | 24.24 |
| SMVSC | 60.56 | 73.48 | 51.14 | 61.67 | 46.68 | 47.79 | 38.21 | 87.31 | 56.97 | 61.68 | 37.56 | 56.97 |
| MVSC | 61.66 | 75.68 | 51.95 | 64.69 | 63.68 | 54.46 | 47.92 | 82.91 | 59.03 | 64.10 | 40.15 | 60.33 |
| FPMVS-CAG | 63.75 | 74.63 | 53.21 | 65.42 | 54.55 | 47.32 | 41.34 | 68.74 | 44.24 | 49.76 | 25.30 | 46.67 |
| JSMC | 83.96 | 92.98 | 81.28 | 88.68 | 70.90 | 63.20 | 60.10 | 92.06 | 73.33 | 76.38 | 57.58 | 73.94 |
| MvDSCN | 81.06 | 89.26 | 80.72 | 85.98 | 68.45 | 51.28 | 40.34 | 80.87 | 75.47 | 74.23 | 54.63 | 72.51 |
| CISCAL-MVC | 100.0 | 100.0 | 100.0 | 100.0 | 80.69 | 63.60 | 68.70 | 92.59 | 74.24 | 75.87 | 56.29 | 74.72 |
| method | ours vs. SC | ours vs. MVspec | ours vs. RMSC | ours vs. MVGL | ours vs. BMVC |
| p-value | 1.82 | 1.82 | 1.82 | 1.82 | 1.82 |
| method | ours vs. SMVSC | ours vs. MVSC | ours vs. FPMVS-CAG | ours vs. JSMC | ours vs. MvDSCN |
| p-value | 1.82 | 1.82 | 1.82 | 4.97 | 3.88 |
| Dataset | ACC | NMI | ||||||
| our | our | |||||||
| 3sources | 78.70 | 46.98 +31.72 | 51.36 +27.34 | 62.18 +16.52 | 72.06 | 46.46 +25.60 | 38.24 +33.82 | 57.42 +14.64 |
| ORL | 89.25 | 82.47 +6.780 | 80.17 +9.08 | 82.48 +6.765 | 93.59 | 92.42 +1.169 | 91.47 +2.111 | 92.31 +1.276 |
| WebKB-Texas | 74.83 | 63.30 +11.53 | 40.54 +34.29 | 60.39 +14.44 | 38.90 | 24.28 +14.62 | 14.65 +24.25 | 28.47 +10.43 |
| COIL-20 | 100.0 | 83.89 +16.11 | 49.76 +50.24 | 84.73 +15.27 | 100.0 | 93.93 +6.070 | 67.48 +32.52 | 94.82 +5.177 |
| Caltech-7 | 80.64 | 56.69 +23.95 | 55.63 +25.01 | 59.97 +20.67 | 63.60 | 59.88 +3.716 | 44.70 +18.90 | 60.01 +3.585 |
| Yale | 74.11 | 70.60 +3.504 | 67.57 +6.535 | 73.69 +0.413 | 74.87 | 73.03 +1.835 | 68.95 +5.918 | 74.30 +0.565 |
| Avg.score | 82.91 | 67.32 +15.59 | 57.50 +25.41 | 70.57 +12.34 | 73.83 | 65.00 +8.835 | 54.24 +19.59 | 67.89 +5.945 |
| Dataset | PUR | ARI | ||||||
| our | our | |||||||
| 3sources | 85.21 | 43.33 +41.88 | 43.76 +41.45 | 62.73 +22.48 | 65.90 | 26.29 +39.61 | 31.18 +34.72 | 48.09 +17.81 |
| ORL | 90.50 | 74.93 +15.57 | 69.52 +20.98 | 73.28 +11.22 | 83.58 | 78.19 +5.393 | 74.31 +9.275 | 77.07 +6.516 |
| WebKB-Texas | 77.34 | 63.28 +14.06 | 41.62 +35.72 | 61.18 +16.16 | 41.64 | 33.88 +7.7754 | 12.56 +29.08 | 30.36 +11.28 |
| COIL-20 | 100.0 | 75.07 +24.93 | 34.26 +65.74 | 73.99 +26.01 | 100.0 | 81.37 +18.63 | 39.03 +60.97 | 81.72 +18.28 |
| Caltech-7 | 92.59 | 83.32 +9.264 | 68.20 +24.39 | 84.39 +8.193 | 58.28 | 41.39 +16.89 | 38.38 +19.90 | 42.53 +15.75 |
| Yale | 74.70 | 52.07 +22.63 | 44.52 +30.18 | 44.47 +30.23 | 52.29 | 50.37 +1.912 | 44.72 +7.568 | 47.27 +5.012 |
| Avg.score | 86.76 | 65.33 +21.27 | 50.31 +36.29 | 66.67 +19.93 | 66.95 | 51.91 +15.04 | 40.03 +26.91 | 54.51 +12.44 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, K.; Kang, K.; Bai, Y.; Peng, C. Commonness and Inconsistency Learning with Structure Constrained Adaptive Loss Minimization for Multi-View Clustering. Electronics 2025, 14, 1847. https://doi.org/10.3390/electronics14091847
Zhang K, Kang K, Bai Y, Peng C. Commonness and Inconsistency Learning with Structure Constrained Adaptive Loss Minimization for Multi-View Clustering. Electronics. 2025; 14(9):1847. https://doi.org/10.3390/electronics14091847
Chicago/Turabian StyleZhang, Kai, Kehan Kang, Yang Bai, and Chong Peng. 2025. "Commonness and Inconsistency Learning with Structure Constrained Adaptive Loss Minimization for Multi-View Clustering" Electronics 14, no. 9: 1847. https://doi.org/10.3390/electronics14091847
APA StyleZhang, K., Kang, K., Bai, Y., & Peng, C. (2025). Commonness and Inconsistency Learning with Structure Constrained Adaptive Loss Minimization for Multi-View Clustering. Electronics, 14(9), 1847. https://doi.org/10.3390/electronics14091847