1. Introduction
The foundational principle of stochastic computing is the representation of a number
as a
process, which is an infinite sequence of statistically independent bits where
p is the probability that any given bit is ‘1’. The representation is motivated by the facts that arithmetical operations on such bit streams are typically very hardware- and power-efficient, and the represented values are highly tolerant of bit-flip errors [
1,
2,
3,
4,
5,
6]. Potential future applications of SC include extremely low power edge processing, sensor conditioning for embedded/wearable thin-film devices, molecular computing, and sensing/telemetry in extreme environments where errors are frequent. Even without specifying specific applications, which may be yet to be discovered, the motivation for the ability to model arbitrary mathematical functions is self-evident.
The goal is to closely approximate a real function
f over some domain
using stochastic computing methods. Approximation using partial sums of basis functions
is considered,
which converges at least pointwise to
f, i.e.,
The function
f is then completely defined by the set of coefficients
. In
Section 4, Chebyshev polynomials are employed as the basis functions of interest.
The method developed in the paper is compared to the Bernstein polynomial approach of [
7,
8], which is the only existing method of arbitrary function approximation using stochastic computing. Performance results show that our approach is much more accurate as a function of complexity.
In order to extend the available mathematical machinery, the ability to represent negative numbers is required. A bipolar value
x can be represented using a
process as follows. Given a parameter
and the constraint that
, the representation may be achieved by the following linear transformation [
9]:
The inverse transform is
In the remainder of the work, the shorthand notation is used to refer to a process.
The paper is organised as follows. In
Section 2, prior approaches to stochastic computing-based function approximation are reviewed. In
Section 3, an algorithm that implements the inner product of two vectors is presented, namely the stochastic dot product (SDP). The SDP is generally useful; however, in the context of this work, it is employed as a building block of the more general function approximation design, presented in detail in
Section 4. Having defined the algorithm,
Section 5 is used to demonstrate the utility of the design, investigate its behaviour in various situations, and compare its performance with existing methods.
Section 6 is a discussion comparing the relative merit of this work with the Bernstein polynomial approach, and
Section 7 concludes the work.
3. Stochastic Dot Product
In this section, an algorithm to compute the vector dot product
is described, where
is a length-
K vector of pre-defined integers, and
is an arbitrary length-
K vector with the constraint that
. The constraint on
allows for implementation as a bipolar stochastic circuit, with output
defined as
In other words,
is the desired dot product saturated at
, as imposed by the stochastic bipolar representation. Note that the integers
are unconstrained; only
is required. A special case of the SDP is the integer scaling of a single bipolar bit stream, enabled by setting
.
We allow a deviation from classical stochastic computing techniques by introducing some deterministic operations, the most complex of which is a sum of two integers.
The SDP requires selection of an even sample period . At each time within the sample period, an output is the bit , and an input is a set of K bits , with bit being drawn from .
The SDP has a delay of
M samples, where a set of
M outputs is computed based on the previous
M inputs. The SDP works for a general
M; however, as will be shown in
Section 3.6, the architecture benefits greatly in terms of efficiency if
M is as large as possible, and also if
M is selected to be a power of 2.
As a reference for the detailed description of each algorithm component in the remainder of the section, the complete SDP algorithm is listed in Algorithm 1.
| Algorithm 1: Stochastic Dot Product Algorithm |
![Electronics 14 01845 i001]() |
3.1. Output Bit Stream
The output bit stream is required to be a process. In order to approximate the correct distribution after receiving M inputs, a distribution is imposed on the subsequent M output bits. Parameter is the local empirical estimate of , with the constraint that is an integer. The output is given the desired distribution using one of the following options.
Option 1: Emit
M samples from a
distribution. For
, this rule becomes
where
is a sample from a uniform binary distribution.
Option 2: Emit for each of the first outputs and for the remaining outputs.
In this work, we exclusively used Option 2, which has a simpler implementation, being deterministic given . The drawback of Option 2 is the introduction of correlations into the output bit sequence.
3.2. Empirical Distribution
It remains to determine or, equivalently, .
At the beginning of each
M-input period, initialise integer
, where
which is a constant that can be computed offline and stored at circuit creation. At each input time
, for each of the
K inputs
, update
according to
i.e., increment
by the constant
when the input bit corresponding to
is 1.
After receiving
M inputs, the mean
is precisely the quantity of interest, namely
M times the unipolar representation of the dot product (
6). To verify, expand the mean as
The corresponding bipolar output is
where the substitution from (
3) in the last line yields the desired result.
3.3. Bit Stream Correlations
Note that the order of summation in (
8) does not affect the result, making the SDP impervious to correlations in each
M-input bit sequence. In
Section 4, we cascade an arbitrary number of SDPs in series; this observation allows the output bit stream of each to be assigned according to Option 2 in
Section 3.1. The output of the final SDP can be assigned according to Option 1 if downstream correlations need to be avoided.
3.4. Averaging Across Sample Periods
Recall that
is the local estimate of the output distribution. In practice, the circuit measures
, which is an unconstrained estimate that may not actually be implementable unless
. This unconstrained estimate
is computed as
where the integer
t is defined below. Using the clamping function (defined strictly for
)
an implementable value can be obtained using
The truncated value
is then used to generate the desired output distribution according to
Section 3.1.
Finally, in order to account for the nonlinearity of the clamping function, the SDP maintains an accumulator
which is updated after each measurement of
.
The rationale for the accumulator is that if an instantaneous value of cannot be represented explicitly, the “excess” value is stored until it can be represented in the output bit stream at some point in the future. Considering the ratio of total ‘1’s to total ‘0’s over many samples of , the accumulator t ensures that the overall output distribution is correct, even if it is locally skewed by the clamping function. Each time t crosses zero, the distribution of all previous outputs in totality is just the unbiased empirical estimate of .
3.5. Accumulator Stability
It is instructive to consider the accumulator behaviour when
. In this case,
and
and, hence,
t increases over time at a rate proportional to
while the condition remains true. Similarly, if
, then
and
which decreases over time. This negative feedback ensures that the value of
t will always eventually return to zero.
While the accumulator is stable in expectation, the zeroing effect is relatively slow and the accumulator is prone to large local perturbations if the variance of is significantly greater than M. The effect on t of a large sample where will take a minimum of sample periods to remove, during which time the output bit stream will be all ‘1’s.
The variance can be quantified as
which is maximized when the values of
are all equal to
(equivalently
. Assuming the values of
are uniformly distributed, their influence can be averaged out to obtain
The above expression demonstrates that when algorithms are designed with the SDP as a building block, the magnitude of constants
critically affects the stability of the circuit.
3.6. SDP Complexity
If an SC architecture such as the SDP finds widespread practical utility, it will likely be associated with a newer and more novel technology than classical CMOS. Rather than introducing various assumptions required to compute die area and gate counts, the complexity discussion will remain as general as possible.
In the main algorithm implementation presented in
Section 4, the elements of vector
are small constant integers (
), and as such the increment (
8) has an efficient hardware implementation.
If
M is chosen as a power of 2, Equation (
14) is trivial when
and, otherwise, is performed by simply flipping bits from bit
towards the most-significant bit (MSB) until a ‘1’ is found (where
). Similarly, the function (
13) has a very simple implementation.
The bulk of the hardware complexity resides in the general addition (
11), which is performed once every
M input samples. Notwithstanding the discussion in
Section 3.4 regarding the accumulator behaviour, the magnitude of
t (and, hence, the size of the register required to contain
) is theoretically unbounded. For the simulations in
Section 5, 16 bits was more than enough to safely represent
, and further optimization is likely possible.
Finally, given that the operations discussed here are only performed once every M bits, it is prudent to consider using larger values of M. Experiments showed that M could be varied between 2 and 1024 without affecting the accuracy or precision.
3.7. Alternative Dot-Product Methods
While the SDP was developed specifically for the application described in
Section 4, other dot-product approaches, or techniques that could be applied to such, have been described in the literature [
12,
14,
17,
18,
19,
20,
21]. These were not considered here for the following reasons.
In our application, one of the dot product inputs is a vector of integers, which is known at circuit creation. We wish to exploit this fact in order to reduce noise.
It is unclear how to adapt existing methods to represent unconstrained integer inputs, or to produce a bipolar output .
On the other hand, a drawback of the proposed SDP is the use of deterministic binary additions. An attempt to adapt existing dot-product methods to this application in order to eliminate additions would be a worthwhile future endeavour.
4. Chebyshev Function Approximation
The goal is to approximate an arbitrary function
on
as the partial sum
where
is the
nth Chebyshev polynomial of the first kind [
22,
23]. Chebyshev polynomials are an excellent basis for function approximation due to their simplicity and low error for a given
N, and as such, they are frequently applied in numerical computing applications [
24,
25]. The computation of the coefficients
was performed offline and is not considered here [
26].
Since
can be expressed as a degree-
n polynomial in
x with integer coefficients, in principle, it could be computed directly using the SDP along with a circuit that raises
x to an integer power (a sequence of
n XNOR gates in series implements
). Unfortunately, the coefficients of
increase rapidly in magnitude with
n, leading to large accumulator excursions in the SDP implementation. To illustrate, the variance (
16) for the SDP implementation of
is approximately
.
4.1. Stochastic Clenshaw Algorithm
To obtain a more stable and efficient implementation, the Clenshaw algorithm [
27] can be applied to compute (
17). Stating the algorithm directly, the partial sum can be expressed as
where the
are defined by the recurrence relation
initialised by
The algorithm suggests a direct stochastic implementation as
cascaded repeating circuit stages, with each circuit implementing one stage of the recurrence (
19).
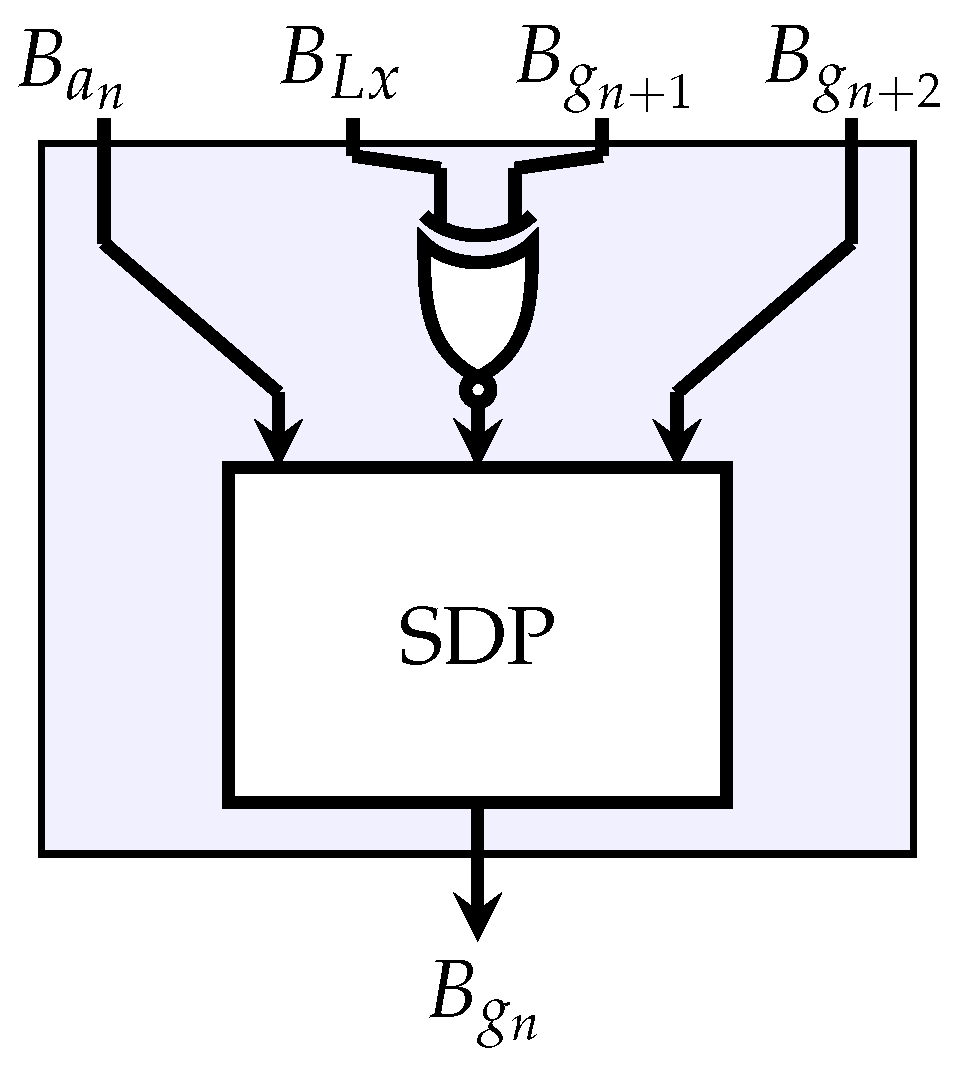
4.1.1. Clenshaw Stage
Equation (
19) can expressed as the dot product of vectors
and
, which immediately suggests the use of an SDP. The stochastic representation of the product
can be computed with an XNOR gate on the output of
and
, which yields the bipolar representation of
[
9,
28]. The combined circuit representing one stage of the stochastic Clenshaw algorithm is shown in
Figure 1.
In order to account for the
scale factor introduced by the XNOR gate, the corresponding SDP constant could be scaled as
(assuming
is an integer). Given the expression for variance (
16), however, and the fact that many such stages will be cascaded, scaling the constant in this way significantly increases the noise level. Since
x is only defined within
, a better solution is to scale the input by
L. This could be performed as part of generating the input Bernoulli process or online via a single-term SDP with
.
4.1.2. Complete Clenshaw Circuit
Having defined a single stage, the entire algorithm can be implemented using
stages in series, connected as shown in
Figure 2. This is a direct implementation of Equations (
18)–(
20).
Noting the edge cases in the algorithm definition, the constant vector
for the SDP in stage
n is defined as follows:
so the output of stage
is the desired partial sum (
17).
Once an
-stage dedicated circuit implementing
Figure 2 is created, it can model any function
f with an order-
N partial sum simply by providing the appropriate input processes
.
One useful optimization is that in the case
, the process
can be ignored, or equivalently the integer
can be set to zero. This is useful to reduce the variance (
16) when modelling odd or even functions, in which case
for every other
n.
Parallel implementations of the Clenshaw algorithm are known [
29]; however, in this application, the serial implementation can be fully pipelined with no loss of throughput. Each unbiased output sample from the algorithm requires only a single sample from
, along with a single sample from each of the
.
5. Numerical Investigation
For each of the experimental results presented in this section,
input bits were presented to the stochastic circuit in order to obtain the measurement at the output. The output estimator measures
, which can be implemented using techniques in, e.g., [
18]. The variance of this estimator scales as
. While
is almost certainly impractically large in real applications, for the purposes of
Section 5, we seek to investigate systematic errors and biases which might otherwise be obscured by sampling noise if a smaller
S were used.
Axis labels are omitted from plots in order to preserve page space; the horizontal axis always represents the independent variable x, and the vertical axis represents .
5.1. Examples
Some selected examples of simple modelled functions are shown in
Figure 3 along with the stochastic circuit simulation results. The function definitions are listed in the caption along with the number of terms
N in the partial sum.
In
Figure 3a,b is shown the degree-3 polynomials in the examples from [
13] and [
7], respectively, extended into the bipolar domain. Since any degree-
d polynomial can always be represented exactly as the sum (
17) with
[
22], only four stochastic Clenshaw stages are required in each case.
Figure 3c shows a tanh function modelled with 12 Clenshaw stages. This is the curve from Example 3 of [
12], shifted and scaled to be centred in the bipolar regime. In this case, the partial sum is not an exact representation but a truncated infinite sum. This represents an alternative implementation of an activation function for artificial neural networks, given recent interest in using SC for such applications [
30,
31].
The final subplot of
Figure 3 shows the sum of two Chebyshev polynomials. This is an exact representation with only two non-zero terms appearing in (
17).
Further examples are presented in
Figure 4, this time for general functions with no limitation on complexity.
Figure 4a,b show selected oscillatory functions with 21 terms. These are examples of transcendental functions that are complicated to implement using traditional logic.
Figure 4c shows a
function modelled with
. The Gibbs phenomenon can be seen causing oscillations due to the nonlinearity at the step. Even with 51 stochastic Clenshaw stages configured in series, however, the stochastic circuit faithfully models the partial sum with low noise.
Finally,
Figure 4d shows an extreme example where the method fails. The Gamma function is modelled with 61 terms over a domain containing multiple singularities and discontinuities. The right-hand side of the plot shows a somewhat accurate approximation (albeit with some oscillation), but in the left-hand side of the plot, the approximation completely breaks down due to noise propagation through the Clenshaw stages.
5.2. Choosing the Scale Parameter
The setting of parameter
L in the bipolar representation (
3) is a design decision to be addressed. The representation is limited to
, so
L should be at least as large as the expected largest value, including any intermediate values within the Clenshaw stages. If
L is much larger than necessary, however, the domain of interest is mapped via (
4) onto only a portion of the available unipolar space. For example, if
x is in
and
, the inverse map (
4) restricts
p to the interval
, ignoring 90% of the available range of values. The experiment shown in
Figure 5 explores this effect.
In the top left sub-figure, the scale is set to . The noise appears quite small; however, the stochastic circuit is completely unable to represent for . The reason is that intermediate values within the Clenshaw stages violate the condition . These intermediate values are clipped before propagating through the circuit, and as a result, the final value of is inaccurate.
In contrast, when (shown in the bottom right sub-figure), the output shows no evidence of clipping, but the high level of noise produces a poor approximation.
In general, for optimal performance,
L should be set as small as possible, but large enough that any clipping is avoided. The appropriate value of
L can be quickly investigated offline using a floating-point version of the Clenshaw algorithm as the maximum absolute intermediate value recorded. For the function shown in
Figure 5, the optimal value of
L is evidently between 2 and 4.
5.3. Comparison with Bernstein Approximation
Of the various function approximation methods introduced in
Section 2, only the Bernstein approximation [
7,
8] is capable of representing general functions.
Figure 6 shows the measured squared error between a given function and the two universal approximators, as a function of the number of stages
N. The squared error is averaged over 200 values of
x, evenly spaced across the domain of interest. The very long sequences of input bits (
) minimises sampling noise and allows for an investigation of the inherent error for each design.
In
Figure 6a, the function modelled in
Figure 4b is reinvestigated. As shown in
Figure 4, the Chebyshev approximation gives a good fit with
terms, corresponding to a mean squared error of roughly
in
Figure 6a. In contrast, even with
stages, the Bernstein approximation cannot reach this level of accuracy.
In
Figure 6b, a much more complicated function is modelled, as specified in the figure caption. The Chebyshev approximator requires around
stages to achieve a good fit. In contrast, the Bernstein approximator requires
to even approach this level of accuracy.
The examples discussed above were not cherry-picked; the relative difference in the required number of stages seems consistent for all functions of interest.
Interestingly, for very small values of
N, the Bernstein architecture outperforms the proposed method in terms of accuracy, as can be seen in
Figure 6. For such small values of
N, however, the approximation remains very poor for both architectures.
6. Discussion
The examples in
Section 5 clearly demonstrate the utility and performance of the proposed function approximation circuit. Some of the limitations and drawbacks are in turn discussed here.
The most notable drawback is the complexity of the
SDPs. The deterministic operations discussed in
Section 3.6 are performed
times per output bit, the most significant of which is a signed integer addition. Noting from
Section 5 that the most complicated functions can require
, and setting
, the signed addition is required around once every 20 output bits in the worst case.
Another source of complexity is the
Bernoulli source processes representing the coefficients
. Whether consumed from some high-entropy source or pseudo-randomly produced within the circuit itself, the Bernoulli processes represent significant resources. The Chebyshev circuit is not unique in this regard; the Bernstein circuit also requires
such processes representing the coefficients, and in that case,
N can be at least an order of magnitude larger as observed in
Section 5.3.
In the following, we refer to the circuit proposed in this work as “Chebyshev” and the circuit proposed in [
7] as “Bernstein”. It is not possible to definitively rank the two circuit designs without considering the application, the technology used to implement the circuit, and the design constraints.
If the application is rate-limited, where the maximum number of output samples is required in a given time as much as possible, Chebyshev is clearly the best.
In a power-limited scenario where the source processes must be generated or conditioned in some way, Chebyshev likely consumes less power due to the greatly reduced number of Bernoulli processes representing coefficients. This will be offset somewhat by the relatively expensive processing required by Chebychev every inputs.
If the goal is to minimise the circuit size, the answer, again, depends on the availability of the source processes and is similarly murky. The SDPs used to implement Chebyshev obviously requires more logic gates than the simple 1-bit adders composing Bernstein. However, the smallest overall circuit depends on the relative size of the source processes and the fact that Bernstein requires so many more of them.
In requiring some deterministic addition operations, both approximations lose some of the tolerance to bit-flip errors characteristic of stochastic computing. For example, an error in the MSB of the integer in one of the SDPs would be far more damaging to accuracy than an error in one of the input bits. If the circuit were to be used in an environment or application where bit-flip errors are common, the deterministic portions of the circuit may require additional protection of some kind.
7. Conclusions
In this work, a new stochastic computing architecture for function approximation is proposed based on a partial sum Chebyshev expansion. The method can model arbitrarily complicated functions on with high accuracy using relatively few terms in the partial sum. Unlike other proposals in the literature, the method extends the domain over the negative numbers and has an adjustable range. The architecture is full-rate, in that an output sample is produced for every input sample.
As a core building block of the new architecture, a stochastic circuit is presented that computes the dot product of a bipolar vector with an arbitrary constant integer vector. This dot-product core has useful applications in and of itself.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}