
Multi-Knowledge-Enhanced Model for Korean Abstractive Text Summarization


Abstract
1. Introduction
- The proposed internal knowledge extraction method utilizes a Bidirectional Encoder Representations from Transformer (BERT)-based PLM to extract diverse and consistent knowledge from a text while considering the semantic context;
- By employing an attention mechanism that simultaneously considers various types of internal knowledge, the proposed approach aims to consistently preserve critical information from the input text in the summary, thereby mitigating distortion issues;
- The proposed method demonstrates that the knowledge-enhanced approach, which integrates multiple types of knowledge, outperforms PLMs that only use the original document as input and those that are enhanced with a single type of knowledge in the task of Korean ATS.
2. Related Work
2.1. Abstractive Text Summarization
2.2. Knowledge-Enhanced Model
2.3. Piror Work on Internal Knowledge Extraction Method
3. Background: Knowledge-Enhanced Model
3.1. Generative Knowledge Models
3.2. Multiple Knowledge Integration
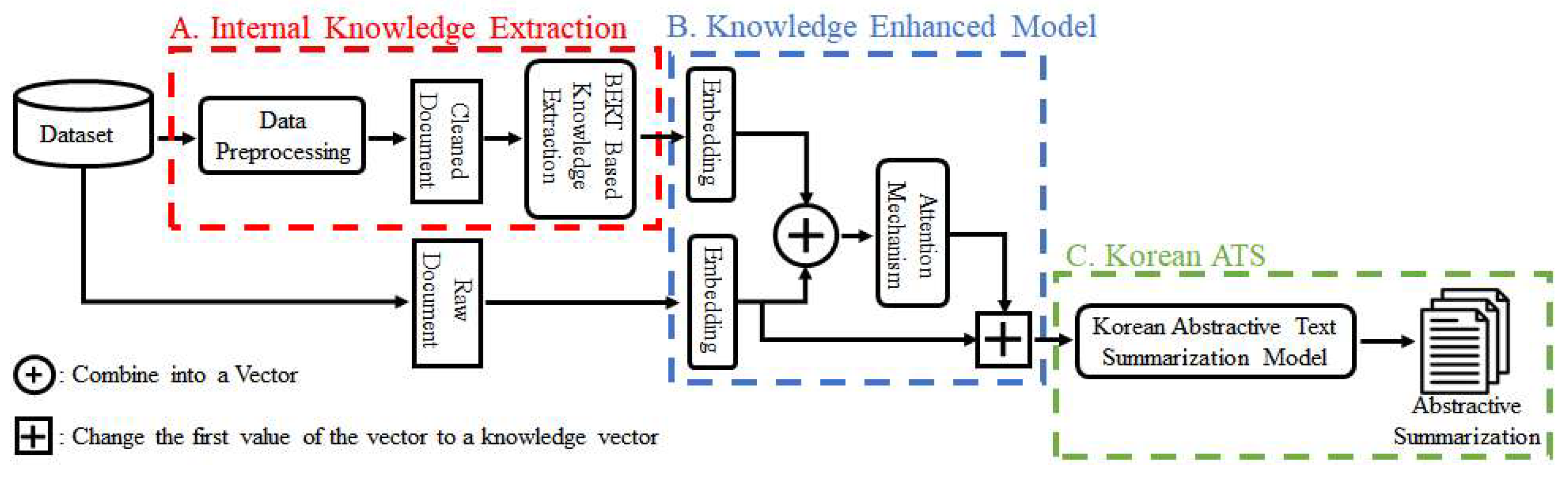
4. Proposed Method
4.1. Internal Knowledge Extraction
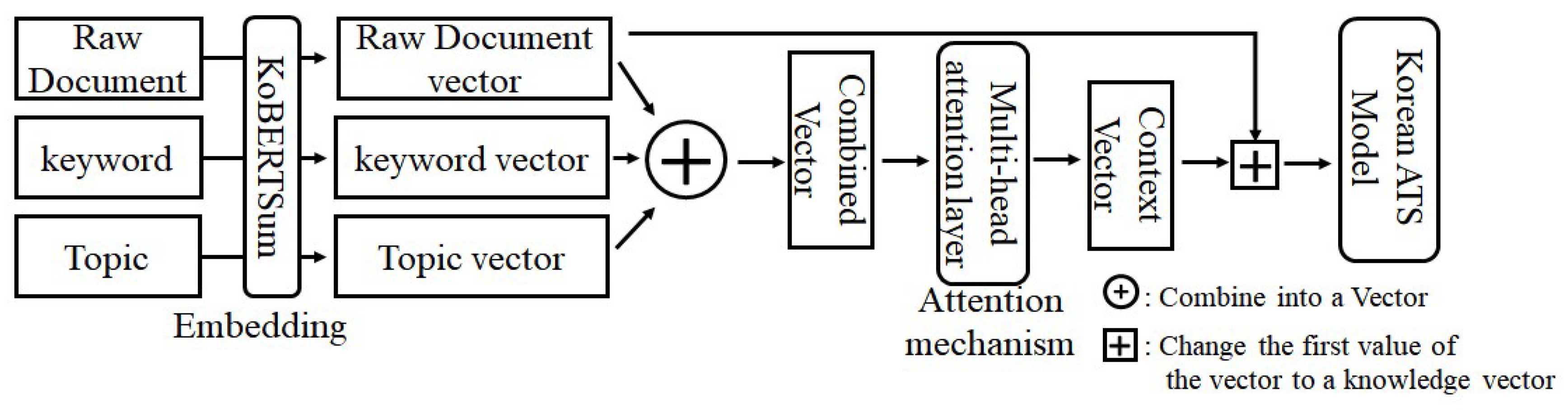
4.2. Multi-Knowledge-Enhanced Model
4.3. Korean ATS Model
5. Result
5.1. Datasets
5.2. Research Environment
5.3. Automatic Evaluation
5.4. Baselines
5.5. Quantitative Evaluation of the Proposed Method
5.6. Ablation Study
5.6.1. Analysis of Extracted Knowledge on the News Dataset
5.6.2. Comparison with LLM
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| RNN | Recurrent Neural Network |
| PLMs | Pre-trained Language Models |
| NLG | Natural Language Generation |
| LDA | Latent Dirichlet Allocation |
| ATS | Abstractive Text Summarization |
| BERT | Bidirectional Encoder Representations from Transformer |
| GPT | Generative Pre-trained Models |
| TF-IDF | Term Frequency-Inverse Document Frequency |
| LLMs | Large Language Models |
| RoBERTa | Robustly Optimized BERT approach |
| UMAP | Uniform Manifold Approximation and Projection |
| HDBSCAN | Hierarchical density based clustering |
| Okt | Open Korean Text |
| KoBERTSum | Korean BERT Summarization |
| MHA | Multi-Head Attention |
| KoROUGE | Korean Recall-Oriented Understudy for Gisting Evaluation |
References
- Sharma, G.; Sharma, D. Automatic text summarization methods: A comprehensive review. SN Comput. Sci. 2022, 4, 33. [Google Scholar] [CrossRef]
- El-Kassas, W.S.; Salama, C.R.; Rafea, A.A.; Mohamed, H.K. Automatic text summarization: A comprehensive survey. Expert Syst. Appl. 2021, 165, 113679. [Google Scholar] [CrossRef]
- Widyassari, A.P.; Rustad, S.; Shidik, G.F.; Noersasongko, E.; Syukur, A.; Affandy, A.; Setiadi, D.R.I.M. Review of automatic text summarization techniques & methods. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 1029–1046. [Google Scholar]
- Shakil, H.; Farooq, A.; Kalita, J. Abstractive text summarization: State of the art, challenges, and improvements. Neurocomputing 2024, 603, 128255. [Google Scholar] [CrossRef]
- Feng, X.; Feng, X.; Qin, L.; Qin, B.; Liu, T. Language model as an annotator: Exploring DialoGPT for dialogue summarization. arXiv 2021, arXiv:2105.12544. [Google Scholar]
- Chintagunta, B.; Katariya, N.; Amatriain, X.; Kannan, A. Medically aware GPT-3 as a data generator for medical dialogue summarization. In Proceedings of the Machine Learning for Healthcare Conference, Online, 6–7 August 2021; pp. 354–372. [Google Scholar]
- Bani-Almarjeh, M.; Kurdy, M.-B. Arabic abstractive text summarization using RNN-based and transformer-based architectures. Inf. Process. Manag. 2023, 60, 103227. [Google Scholar] [CrossRef]
- Hájek, A.; Horák, A. Czegpt-2–training new model for czech generative text processing evaluated with the summarization task. IEEE Access 2024, 12, 34570–34581. [Google Scholar] [CrossRef]
- Yu, W.; Zhu, C.; Li, Z.; Hu, Z.; Wang, Q.; Ji, H.; Jiang, M. A survey of knowledge-enhanced text generation. ACM Comput. Surv. 2022, 54, 1–38. [Google Scholar] [CrossRef]
- Narayan, S.; Cohen, S.B.; Lapata, M. Don’t give me the details, just the summary! topic-aware convolutional neural networks for extreme summarization. arXiv 2018, arXiv:1808.08745. [Google Scholar]
- Fu, X.; Wang, J.; Zhang, J.; Wei, J.; Yang, Z. Document summarization with vhtm: Variational hierarchical topic-aware mechanism. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 7740–7747. [Google Scholar]
- Lee, S.; Park, C.; Jung, D.; Moon, H.; Seo, J.; Eo, S.; Lim, H.-S. Leveraging Pre-existing Resources for Data-Efficient Counter-Narrative Generation in Korean. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), Torino, Italy, 20–25 May 2024; pp. 10380–10392. [Google Scholar]
- Raza, A.; Soomro, M.H.; Shahzad, I.; Batool, S. Abstractive Text Summarization for Urdu Language. J. Comput. Biomed. Inform. 2024, 7, 1–19. [Google Scholar]
- Shin, Y. Multi-encoder transformer for Korean abstractive text summarization. IEEE Access 2023, 11, 48768–48782. [Google Scholar] [CrossRef]
- Zhong, Q.; Ding, L.; Liu, J.; Du, B.; Tao, D. Can chatgpt understand too? A comparative study on chatgpt and fine-tuned bert. arXiv 2023, arXiv:2302.10198. [Google Scholar]
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A review on large language models: Architectures, applications, taxonomies, open issues and challenges. IEEE Access 2024, 12, 26839–26874. [Google Scholar] [CrossRef]
- Ali, M.; Panda, S.; Shen, Q.; Wick, M.; Kobren, A. Understanding the interplay of scale, data, and bias in language models: A case study with bert. arXiv 2024, arXiv:2407.21058. [Google Scholar]
- Jiang, M.; Liu, K.Z.; Zhong, M.; Schaeffer, R.; Ouyang, S.; Han, J.; Koyejo, S. Investigating data contamination for pre-training language models. arXiv 2024, arXiv:2401.06059. [Google Scholar]
- Li, C.; Xu, W.; Li, S.; Gao, S. Guiding generation for abstractive text summarization based on key information guide network. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 2, pp. 55–60. [Google Scholar]
- Hu, L.; Liu, Z.; Zhao, Z.; Hou, L.; Nie, L.; Li, J. A survey of knowledge enhanced pre-trained language models. IEEE Trans. Knowl. Data Eng. 2023, 36, 1413–1430. [Google Scholar] [CrossRef]
- Yang, J.; Hu, X.; Xiao, G.; Shen, Y. A survey of knowledge enhanced pre-trained language models. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2024. [Google Scholar] [CrossRef]
- Grootendorst, M. BERTopic: Neural topic modeling with a class-based TF-IDF procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Kim, S.-E.; Lee, J.-B.; Park, G.-M.; Sohn, S.-M.; Park, S.-B. RoBERTa-Based Keyword Extraction from Small Number of Korean Documents. Electronics 2023, 12, 4560. [Google Scholar] [CrossRef]
- Wang, S.; Ma, H.; Zhang, Y.; Ma, J.; He, L. Enhancing Abstractive Dialogue Summarization with Internal Knowledge. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–8. [Google Scholar]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Li, J.; Wang, X.; Tu, Z.; Lyu, M.R. On the diversity of multi-head attention. Neurocomputing 2021, 454, 14–24. [Google Scholar] [CrossRef]
- Baek, D.; Kim, J.; Lee, H. VATMAN: Integrating Video-Audio-Text for Multimodal Abstractive SummarizatioN via Crossmodal Multi-Head Attention Fusion. IEEE Access 2024, 12, 119174–119184. [Google Scholar] [CrossRef]
- Spikeekips. Stopwords-ko.txt. 2016. Available online: https://gist.github.com/spikeekips/40eea22ef4a89f629abd87eed535ac6a#file-stopwords-ko-txt (accessed on 26 March 2025).
- Kim, D. Naver News Summarization Dataset (Korean). 2024. Available online: https://huggingface.co/datasets/daekeun-ml/naver-news-summarization-ko (accessed on 6 January 2025).
- Kim, H. Korouge. 2023. Available online: https://github.com/HeegyuKim/korouge (accessed on 26 March 2025).
- Jiang, S.; Suriawinata, A.A.; Hassanpour, S. MHAttnSurv: Multi-head attention for survival prediction using whole-slide pathology images. Comput. Biol. Med. 2023, 158, 106883. [Google Scholar] [CrossRef]
- Hrycej, T.; Bermeitinger, B.; Handschuh, S. Number of Attention Heads vs. Number of Transformer-Encoders in Computer Vision. arXiv 2022, arXiv:2209.07221. [Google Scholar]
- Yeajinmin. NER-NewsBI-150142-e3b4 2025. Available online: https://huggingface.co/yeajinmin/NER-NewsBI-150142-e3b4 (accessed on 26 March 2025).
- Bai, J.; Yan, Z.; Zhang, S.; Yang, J.; Guo, H.; Li, Z. Infusing internalized knowledge of language models into hybrid prompts for knowledgeable dialogue generation. Knowl. Based Syst. 2024, 296, 111874. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Original Document | Reference Summary | |||||
|---|---|---|---|---|---|---|---|
| Word | Sentence | Length | Word | Sentence | Length | ||
| News | Train | 421.32 | 17.33 | 1045.7 | 72.24 | 1.35 | 181.87 |
| Validation | 452.46 | 18.64 | 1122.5 | 72.18 | 1.32 | 180.75 | |
| Test | 431.91 | 17.86 | 1071.1 | 71.79 | 1.42 | 180.1 | |
| Law | Train | 297.85 | 4.66 | 659.43 | 88.56 | 2.1 | 201.75 |
| Validation | 278.19 | 5.14 | 615.29 | 91.02 | 2.08 | 207.17 | |
| Test | 276.58 | 4.1 | 612.16 | 88.09 | 2.1 | 200.79 | |
| Method | KE | Description | ROUGE-1 | ROUGE-2 | ROUGE-L | BERTScore |
|---|---|---|---|---|---|---|
| Raw | Only original document | 0.473789 | 0.390143 | 0.432548 | 0.815607 | |
| M1 | Topic | Context-agnostic TF-IDF/LDA knowledge | 0.488053 | 0.401502 | 0.442997 | 0.820140 |
| Keyword | 0.487946 | 0.401369 | 0.442775 | 0.820177 | ||
| Topic and Keyword | 0.488094 | 0.401496 | 0.442955 | 0.820160 | ||
| M2 | Topic | Contextual knowledge + standard attention | 0.488743 | 0.402308 | 0.443648 | 0.820815 |
| Keyword | 0.488743 | 0.402308 | 0.443648 | 0.820815 | ||
| Topic and Keyword | 0.488711 | 0.402271 | 0.443607 | 0.820813 | ||
| M3 | Topic | Contextual knowledge + multi-head attention (single type) | 0.488016 | 0.401413 | 0.442902 | 0.82047 |
| Keyword | 0.488109 | 0.401566 | 0.443011 | 0.820453 | ||
| Ours | Contextual knowledge + multi-head attention (multi-type) | 0.509174 | 0.42441 | 0.462577 | 0.827523 | |
| KE | Heads | ROUGE-1 | ROUGE-2 | ROUGE-L | BERTScore |
|---|---|---|---|---|---|
| Topic | 4 | 0.411584 | 0.293716 | 0.387074 | 0.816412 |
| 8 | 0.411502 | 0.29363 | 0.387042 | 0.816463 | |
| Keyword | 4 | 0.410621 | 0.292594 | 0.386091 | 0.816252 |
| 8 | 0.411374 | 0.293458 | 0.386896 | 0.816372 | |
| Ours | 4 | 0.433614 | 0.293803 | 0.411424 | 0.826701 |
| 8 | 0.411638 | 0.293729 | 0.387123 | 0.816508 |
| Data | Model | BERTScore Precision | BERTScore Recall | BERTScore F1 Score |
|---|---|---|---|---|
| Law | Shin [14] | 78.25 | 79.08 | 78.61 |
| T5 | 73.74 | 80.77 | 77.04 | |
| BART | 80.78 | 77.35 | 78.62 | |
| Ours | 81.68 | 83.82 | 82.67 | |
| News | T5 | 83.79 | 76.75 | 80.04 |
| BART | 72.15 | 82.61 | 76.97 | |
| Ours | 82.36 | 83.26 | 82.75 |
| Knowledge | Method | Extracted Knowledge | Romanized |
|---|---|---|---|
| Topic | LDA | ., 는, 은, 한, 수 | ., neun, eun, han, su |
| BERTopic | 했다, 하는, 기업, 하고, 이다 | haessda, haneun, gieob, hago, ida | |
| Keyword | TextRank | 장관, 서울, 대응, 대외, 가격 | jang-gwan, seoul, daeeung, daeoe, gagyeog |
| KeyBERT | 기획재정부 장관 3일, 추경호 부총리 기획재정부, 하고 부총리 물류, 하겠다고 밝혔다, 3일 | gihoegjaejeongbu jang-gwan 3il, chugyeongho buchongli gihoegjaejeongbu, hago buchongli mullyu, hagessdago balghyeossda, 3il |
| KE | Type | Refer Summary | Gen Summary | After KE |
|---|---|---|---|---|
| Keyword | Whole | 5192 | 2938 | 7 |
| Part | 11,867 | 9800 | 178 | |
| Topic | 279 | 435 | 0 | |
| Ours | Keyword (Whole) | 5483 | 3262 | 24 |
| Keyword (Part) | 12,188 | 10,117 | 586 | |
| Topic | 278 | 442 | 0 | |
| Method | Person | Organization | Date/Time | Location | Quantity | Others |
|---|---|---|---|---|---|---|
| Topic | 185 | 452 | 774 | 346 | 795 | 2552 |
| Keyword | 186 | 452 | 775 | 346 | 792 | 2551 |
| Ours | 149 | 487 | 833 | 351 | 903 | 2723 |
| Method | KE | ROUGE-1 | ROUGE-2 | ROUGE-L | BERTScore |
|---|---|---|---|---|---|
| Gemma2 | News | 0.075616 | 0.04518 | 0.071917 | 0.576962 |
| Law | 0.068125 | 0.035259 | 0.064892 | 0.606618 | |
| Ours | News | 0.509174 | 0.42441 | 0.462577 | 0.827523 |
| Law | 0.433614 | 0.293803 | 0.411424 | 0.826701 |
| Method | KE | ROUGE-1 | ROUGE-2 | ROUGE-L | BERTScore |
|---|---|---|---|---|---|
| ChatGPT 4 | News(Raw) | 0.272996 | 0.123478 | 0.216829 | 0.761404 |
| News(KE) | 0.270483 | 0.129607 | 0.230195 | 0.766662 | |
| Law(Raw) | 0.301239 | 0.154458 | 0.290327 | 0.79321 | |
| Law(KE) | 0.294528 | 0.133702 | 0.270598 | 0.791059 | |
| Ours | News | 0.50673 | 0.410506 | 0.46537 | 0.831302 |
| Law | 0.362707 | 0.274607 | 0.357966 | 0.787268 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oh, K.; Lee, Y.; Woo, H. Multi-Knowledge-Enhanced Model for Korean Abstractive Text Summarization. Electronics 2025, 14, 1813. https://doi.org/10.3390/electronics14091813
Oh K, Lee Y, Woo H. Multi-Knowledge-Enhanced Model for Korean Abstractive Text Summarization. Electronics. 2025; 14(9):1813. https://doi.org/10.3390/electronics14091813
Chicago/Turabian StyleOh, Kyoungsu, Youngho Lee, and Hyekyung Woo. 2025. "Multi-Knowledge-Enhanced Model for Korean Abstractive Text Summarization" Electronics 14, no. 9: 1813. https://doi.org/10.3390/electronics14091813
APA StyleOh, K., Lee, Y., & Woo, H. (2025). Multi-Knowledge-Enhanced Model for Korean Abstractive Text Summarization. Electronics, 14(9), 1813. https://doi.org/10.3390/electronics14091813