
An Effective Mixed-Precision Quantization Method for Joint Image Deblurring and Edge Detection


Abstract
1. Introduction
- A fine-grained mixed-precision quantization method is introduced, enabling the dynamic adjustment of quantization precision across different regions of input feature maps;
- To ensure efficient computation when the input feature map is sparse, a zero-skipping computation strategy is proposed for model deployment;
- The quantized model is deployed on an FPGA platform, demonstrating both improved inference speed and high accuracy in comparative experiments, thus validating the effectiveness of the proposed method.
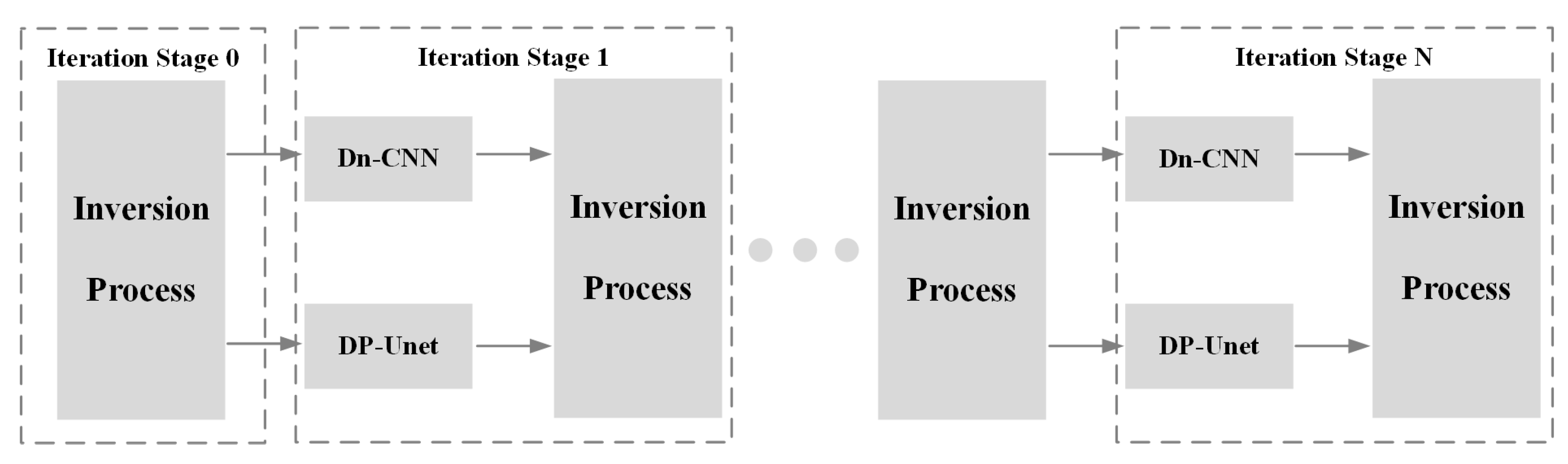
2. Methods
2.1. Quantization Method Based on Edge Neighborhood
2.2. Workflow for Model Deployment
2.3. Zero-Skipping Computation
3. Experiments
3.1. Experiments for Zero-Skipping Computation
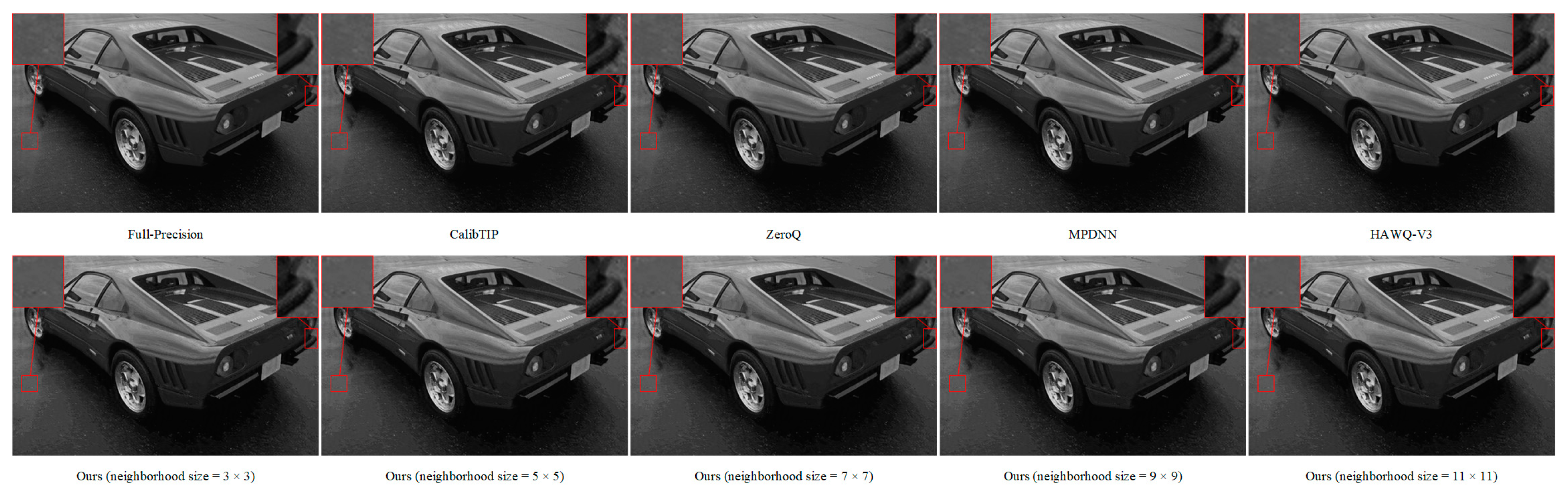
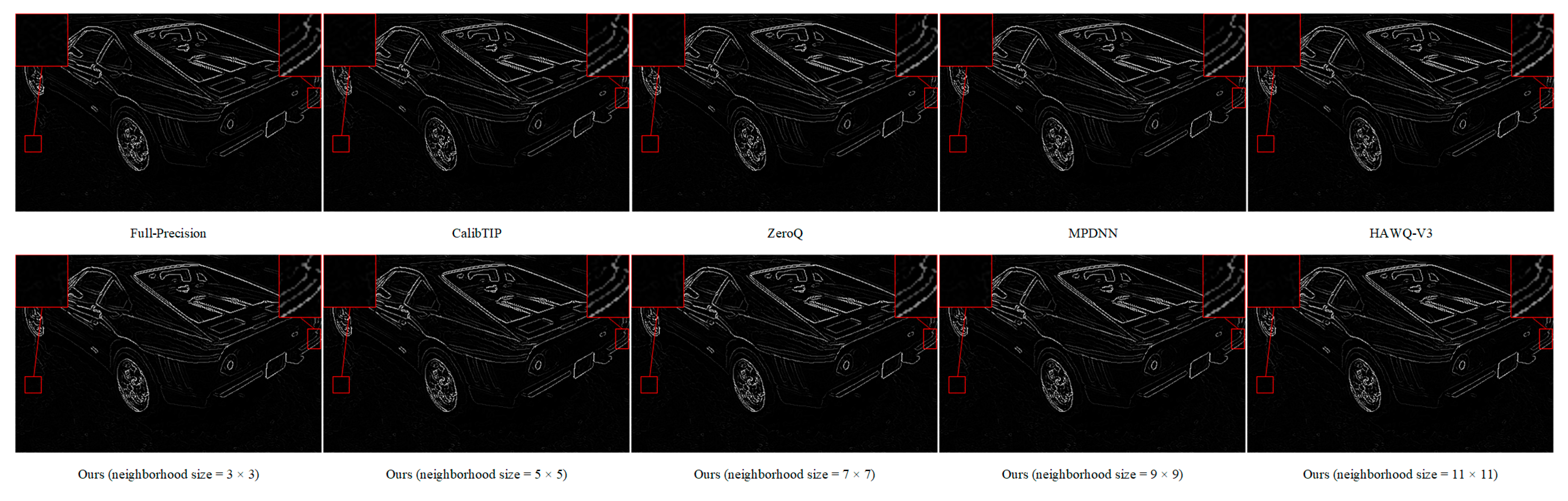
3.2. Experiments for Joint Image Deblurring and Edge Detection
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| DNNs | Deploying deep neural networks |
| FPGA | Field-programmable gate array |
| QAT | Quantization-aware training |
| QONNX | Quantized Open Neural Network Exchange |
| HDL | Hardware description language |
| HLS | High-level synthesis |
| PE | Processing element |
| SIMD | Single instruction multiple data |
| CNNs | Convolutional neural networks |
| Im2Col | Image to column |
| MatMul | Matrix multiplication |
| ODS | Optimal dataset scale |
| MAC | Multiply–accumulate |
References
- Olson, C.F.; Huttenlocher, D.P. Automatic target recognition by matching oriented edge pixels. IEEE Trans. Image Process. 1997, 6, 103–113. [Google Scholar] [CrossRef] [PubMed]
- Aquino, A.; Gegúndez-Arias, M.E.; Marín, D. Detecting the Optic Disc Boundary in Digital Fundus Images Using Morphological, Edge Detection, and Feature Extraction Techniques. IEEE Trans. Med. Imaging 2010, 29, 1860–1869. [Google Scholar] [CrossRef] [PubMed]
- Mohan, K.; Seal, A.; Krejcar, O.; Yazidi, A. Facial Expression Recognition Using Local Gravitational Force Descriptor-Based Deep Convolution Neural Networks. IEEE Trans. Instrum. Meas. 2021, 70, 5003512. [Google Scholar] [CrossRef]
- Pu, M.Y.; Huang, Y.P.; Liu, Y.M.; Guan, Q.J.; Ling, H.B. EDTER: Edge Detection with Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Soria, X.; Sappa, A.; Humanante, P.; Akbarinia, A. Dense extreme inception network for edge detection. Pattern Recognit. 2023, 139, 109461. [Google Scholar] [CrossRef]
- Schuler, C.J.; Hirsch, M.; Harmeling, S.; Schölkopf, B. Learning to Deblur. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 1439–1451. [Google Scholar] [CrossRef]
- Zhang, J.W.; Pan, J.S.; Ren, J.; Song, Y.B.; Bao, L.C.; Lau, R.W.H.; Yang, M.H. Dynamic Scene Deblurring Using Spatially Variant Recurrent Neural Networks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Kupyn, O.; Budzan, V.; Mykhailych, M.; Mishkin, D.; Matas, J. DeblurGAN: Blind Motion Deblurring Using Conditional Adversarial Networks. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Jiang, Z.; Zhang, Y.; Zou, D.Q.; Ren, J.; Lv, J.C.; Liu, Y.B. Learning Event-Based Motion Deblurring. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Tsai, F.J.; Peng, Y.T.; Lin, Y.Y.; Tsai, C.C.; Lin, C.W. Stripformer: Strip Transformer for Fast Image Deblurring. In Proceedings of the 17th European Conference on Computer Vision (ECCV), Tel Aviv, Israel, 23–27 October 2022. [Google Scholar]
- Li, Z.; Gao, Z.; Yi, H.; Fu, Y.; Chen, B. Image deblurring with image blurring. IEEE Trans. Image Process. 2023, 32, 5595–5609. [Google Scholar] [CrossRef] [PubMed]
- Gao, Y.; Lin, J.Q.; Xie, J.; Ning, Z.L. A Real-Time Defect Detection Method for Digital Signal Processing of Inspection Applications. IEEE Trans. Ind. Inform. 2021, 17, 3450–3459. [Google Scholar] [CrossRef]
- Kousik, S.; Vaskov, S.; Bu, F.; Johnson-Roberson, M.; Vasudevan, R. Bridging the gap between safety and real-time performance in receding-horizon trajectory design for mobile robots. Int. J. Robot. Res. 2020, 39, 1419–1469. [Google Scholar] [CrossRef]
- Lee, D.H.; Liu, J.L. End-to-end deep learning of lane detection and path prediction for real-time autonomous driving. Signal Image Video Process. 2023, 17, 199–205. [Google Scholar] [CrossRef]
- Cai, H.; Lin, J.; Lin, Y.J.; Liu, Z.J.; Tang, H.T.; Wang, H.R.; Zhu, L.G.; Han, S. Enable Deep Learning on Mobile Devices: Methods, Systems, and Applications. Acm. Trans. Des. Autom. Electron. Syst. 2022, 27, 20. [Google Scholar] [CrossRef]
- Kim, Y.-D.; Park, E.; Yoo, S.; Choi, T.; Yang, L.; Shin, D. Compression of deep convolutional neural networks for fast and low power mobile applications. arXiv 2015, arXiv:1511.06530. [Google Scholar]
- Zhou, X.C.; Duan, Y.M.; Ding, R.; Wang, Q.C.; Wang, Q.; Qin, J.; Liu, H.J. Bit-Weight Adjustment for Bridging Uniform and Non-Uniform Quantization to Build Efficient Image Classifiers. Electronics 2023, 12, 5043. [Google Scholar] [CrossRef]
- Courbariaux, M.; Bengio, Y.; David, J.P. BinaryConnect: Training Deep Neural Networks with binary weights during propagations. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Lin, X.F.; Zhao, C.; Pan, W. Towards Accurate Binary Convolutional Neural Network. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Li, F.; Liu, B.; Wang, X.; Zhang, B.; Yan, J. Ternary weight networks. arXiv 2016, arXiv:1605.04711. [Google Scholar]
- Zhu, C.; Han, S.; Mao, H.; Dally, W.J. Trained ternary quantization. arXiv 2016, arXiv:1612.01064. [Google Scholar]
- Wang, K.; Liu, Z.; Lin, Y.; Lin, J.; Han, S. HAQ: Hardware-aware automated quantization with mixed precision. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Bichen, W.; Yanghan, W.; Peizhao, Z.; Yuandong, T.; Vajda, P.; Keutzer, K. Mixed Precision Quantization of ConvNets via Differentiable Neural Architecture Search. arXiv 2018, arXiv:1812.00090. [Google Scholar]
- Dong, Z.; Yao, Z.W.; Gholami, A.; Mahoney, M.W.; Keutzer, K. HAWQ: Hessian AWare Quantization of Neural Networks with Mixed-Precision. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Yao, Z.W.; Gholami, A.; Keutzer, K.; Mahoney, M. PYHESSIAN: Neural Networks Through the Lens of the Hessian. In Proceedings of the 8th IEEE International Conference on Big Data (Big Data), Electr Network, Virtual, 10–13 December 2020. [Google Scholar]
- Shen, S.; Dong, Z.; Ye, J.Y.; Ma, L.J.; Yao, Z.W.; Gholami, A.; Mahoney, M.W.; Keutzer, K.; Assoc Advancement Artificial, I. Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT. In Proceedings of the 34th AAAI Conference on Artificial Intelligence/32nd Innovative Applications of Artificial Intelligence Conference/10th AAAI Symposium on Educational Advances in Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Bau, D.; Zhou, B.L.; Khosla, A.; Oliva, A.; Torralba, A. Network Dissection: Quantifying Interpretability of Deep Visual Representations. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef]
- Lou, Q.; Guo, F.; Liu, L.; Kim, M.; Jiang, L. Autoq: Automated kernel-wise neural network quantization. arXiv 2019, arXiv:1902.05690. [Google Scholar]
- Song, Z.R.; Fu, B.Q.; Wu, F.Y.; Jiang, Z.M.; Jiang, L.; Jing, N.F.; Liang, X.Y. DRQ: Dynamic Region-based Quantization for Deep Neural Network Acceleration. In Proceedings of the 47th ACM/IEEE Annual International Symposium on Computer Architecture (ISCA), Electr Network, Virtual, 30 May–3 June 2020. [Google Scholar]
- Canny, J. A computational approach to edge detection. IEEE Trans. Pattern Anal. Mach. Intell. 1986, 8, 679–698. [Google Scholar] [CrossRef]
- Blott, M.; Preusser, T.B.; Fraser, N.J.; Gambardella, G.; O’Brien, K.; Umuroglu, Y.; Leeser, M.; Vissers, K. FINN-R: An End-to-End Deep-Learning Framework for Fast Exploration of Quantized Neural Networks. ACM T. Reconfigurable Technol. Syst. 2018, 11, 16. [Google Scholar] [CrossRef]
- Pappalardo, A.; Umuroglu, Y.; Blott, M.; Mitrevski, J.; Hawks, B.; Tran, N.; Loncar, V.; Summers, S.; Borras, H.; Muhizi, J. Qonnx: Representing Arbitrary-Precision Quantized Neural Networks. arXiv 2022, arXiv:2206.07527. [Google Scholar]
- Zhang, K.; Zuo, W.M.; Chen, Y.J.; Meng, D.Y.; Zhang, L. Beyond a Gaussian Denoiser: Residual Learning of Deep CNN for Image Denoising. IEEE Trans. Image Process. 2017, 26, 3142–3155. [Google Scholar] [CrossRef] [PubMed]
- Tian, L.; Qiu, K.P.; Zhao, Y.F.; Wang, P. Edge Detection of Motion-Blurred Images Aided by Inertial Sensors. Sensors 2023, 23, 7187. [Google Scholar] [CrossRef]
- Nan, Y.S.; Ji, H. Deep Learning for Handling Kernel/model Uncertainty in Image Deconvolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Arbeláez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour Detection and Hierarchical Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Hubara, I.; Nahshan, Y.; Hanani, Y.; Banner, R.; Soudry, D. Improving post training neural quantization: Layer-wise calibration and integer programming. arXiv 2022, arXiv:2006.10518. [Google Scholar]
- Cai, Y.H.; Yao, Z.W.; Dong, Z.; Gholami, A.; Mahoney, M.W.; Keutzer, K. ZeroQ: A Novel Zero Shot Quantization Framework. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Electr Network, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Uhlich, S.; Mauch, L.; Cardinaux, F.; Yoshiyama, K.; Garcia, J.A.; Tiedemann, S.; Kemp, T.; Nakamura, A. Mixed precision dnns: All you need is a good parametrization. arXiv 2019, arXiv:1905.11452. [Google Scholar]
- Yao, Z.W.; Dong, Z.; Zheng, Z.C.; Gholami, A.; Yu, J.L.; Tan, E.R.; Wang, L.Y.; Huang, Q.J.; Wang, Y.D.; Mahoney, M.W.; et al. HAWQ-V3: Dyadic Neural Network Quantization. In Proceedings of the International Conference on Machine Learning (ICML), Electr Network, Virtual, 18–24 July 2021. [Google Scholar]
- Zhang, R.H.; Xu, L.X.; Yu, Z.Y.; Shi, Y.; Mu, C.P.; Xu, M. Deep-IRTarget: An Automatic Target Detector in Infrared Imagery Using Dual-Domain Feature Extraction and Allocation. IEEE Trans. Multimed. 2022, 24, 1735–1749. [Google Scholar] [CrossRef]
- Zhang, R.H.; Yang, B.W.; Xu, L.X.; Huang, Y.; Xu, X.F.; Zhang, Q.; Jiang, Z.Z.; Liu, Y. A Benchmark and Frequency Compression Method for Infrared Few-Shot Object Detection. IEEE Trans. Geosci. Remote Sens. 2025, 63, 5001711. [Google Scholar] [CrossRef]
- Zhang, R.H.; Liu, G.Y.; Zhang, Q.; Lu, X.K.; Dian, R.; Yang, Y.; Xu, L.X. Detail-Aware Network for Infrared Image Enhancement. IEEE Trans. Geosci. Remote Sens. 2024, 63, 5000314. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | ODS F-Measure (% of Baseline) | Computation Time (s) |
|---|---|---|
| ZeroQ | 94.55 | 0.0175 |
| CalibTIP | 95.72 | 0.0154 |
| MPDNN | 95.82 | 0.0163 |
| HAWQ-V3 | 96.84 | 0.0168 |
| Ours (3 × 3) | 97.54 | 0.0145 |
| Ours (5 × 5) | 97.91 | 0.0151 |
| Ours (7 × 7) | 98.11 | 0.0164 |
| Ours (9 × 9) | 98.18 | 0.0185 |
| Ours (11 × 11) | 98.23 | 0.0216 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tian, L.; Wang, P. An Effective Mixed-Precision Quantization Method for Joint Image Deblurring and Edge Detection. Electronics 2025, 14, 1767. https://doi.org/10.3390/electronics14091767
Tian L, Wang P. An Effective Mixed-Precision Quantization Method for Joint Image Deblurring and Edge Detection. Electronics. 2025; 14(9):1767. https://doi.org/10.3390/electronics14091767
Chicago/Turabian StyleTian, Luo, and Peng Wang. 2025. "An Effective Mixed-Precision Quantization Method for Joint Image Deblurring and Edge Detection" Electronics 14, no. 9: 1767. https://doi.org/10.3390/electronics14091767
APA StyleTian, L., & Wang, P. (2025). An Effective Mixed-Precision Quantization Method for Joint Image Deblurring and Edge Detection. Electronics, 14(9), 1767. https://doi.org/10.3390/electronics14091767