

Recent Research Progress of Graph Neural Networks in Computer Vision


Abstract
1. Introduction
2. Development and Basic Concepts of Graph Neural Networks
2.1. Concept and Development of GNNs
2.2. Evolution and Progress of GNN Models
2.2.1. Graph Convolutional Networks (GCN)
2.2.2. Graph Sampling and Aggregation (GraphSAGE)
- (a)
- Sampling—random or stratified sampling is used to reduce computational complexity.
- (b)
- Feature Aggregation—the features of neighboring nodes are aggregated, with common methods including sum, average, and max pooling.
- (c)
- Message Function—the message passing process in GraphSAGE is given by Equation (3):
- (d)
- Update Function—the function for updating node features is given by Equation (4):
2.2.3. Graph Attention Networks (GAT)
2.2.4. Relational Graph Convolutional Networks (R-GCN)
2.2.5. Model Comparison
2.3. Spectral and Spatial Graph Neural Networks
2.3.1. Spectral Graph Neural Networks

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Features | Computational Complexity | Inference Time and Memory Consumption | Advantages | Limitations |
|---|---|---|---|---|---|
| GCN [24] | Approximate method based on spectral graph convolution, capturing local graph structure. | The inference time is fast, influenced by the number of edges E and the structure of the graph, with relatively low memory consumption. | Computationally efficient, suitable for large-scale graphs, easy to implement. | Only applicable to fixed-structure graphs, cannot handle dynamic graphs, and ignores global relationships during inference. | |
| GraphSAGE [16] | Generates node embeddings by sampling local neighborhood information. | The inference time is proportional to the number of edges E and the depth of neighborhood sampling K, with moderate memory consumption. | Supports inductive learning, capable of handling large-scale and dynamically changing graph data. | The aggregation function has high complexity and computational overhead. | |
| GAT [17] | Introduces self-attention mechanism, capable of handling irregular graphs, suitable for dynamic structures. | The inference time is influenced by the number of nodes V, edges E, and feature dimensions F, with higher computational complexity and lower memory consumption. | Introduces self-attention mechanism, adapts to irregular graphs, supports handling dynamic structures. | Attention computation is limited, unable to scale to large graphs, and inference speed is slow. | |
| R-GCN [22] | Designed specifically for handling multi-relational graph data, applied to knowledge graphs. | The inference time is higher, dependent on the number of edges E and feature dimensions F, with moderate memory consumption. | Capable of handling complex multi-relational graph data, suitable for knowledge graph tasks. | Requires a large number of parameters during training, with slower inference and higher model complexity. |
2.3.2. Spatial Graph Neural Networks
3. Applications of Graph Neural Networks in Computer Vision
3.1. Image Processing
3.1.1. Object Detection
3.1.2. Image Segmentation
3.2. Video Analysis
3.2.1. Video Action Recognition
3.2.2. Temporal Action Localization
3.3. Other Related Work: Cross-Media
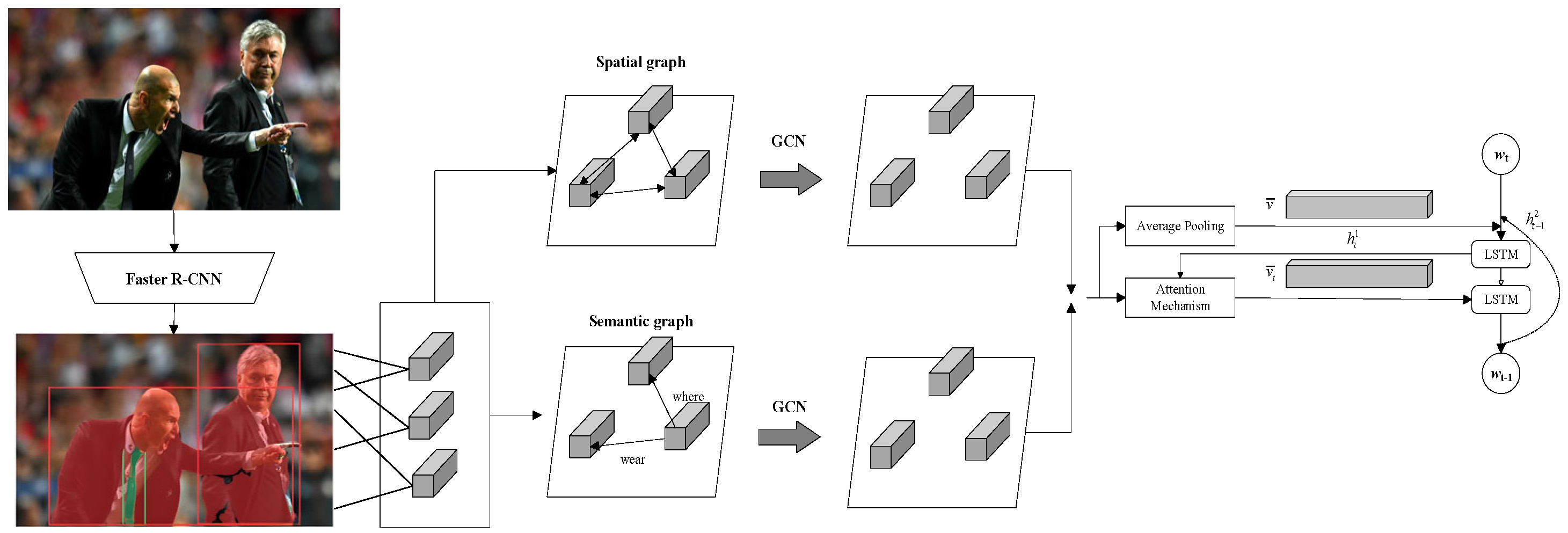
3.3.1. Visual Description
- (a)
- Extract the scene graph from the image and encode it using graph convolutional networks (GCN) to re-represent the image content, ultimately generating a natural language description;
- (b)
- Incorporate the scene graph into the description generation model, combining image and language information to generate the description.
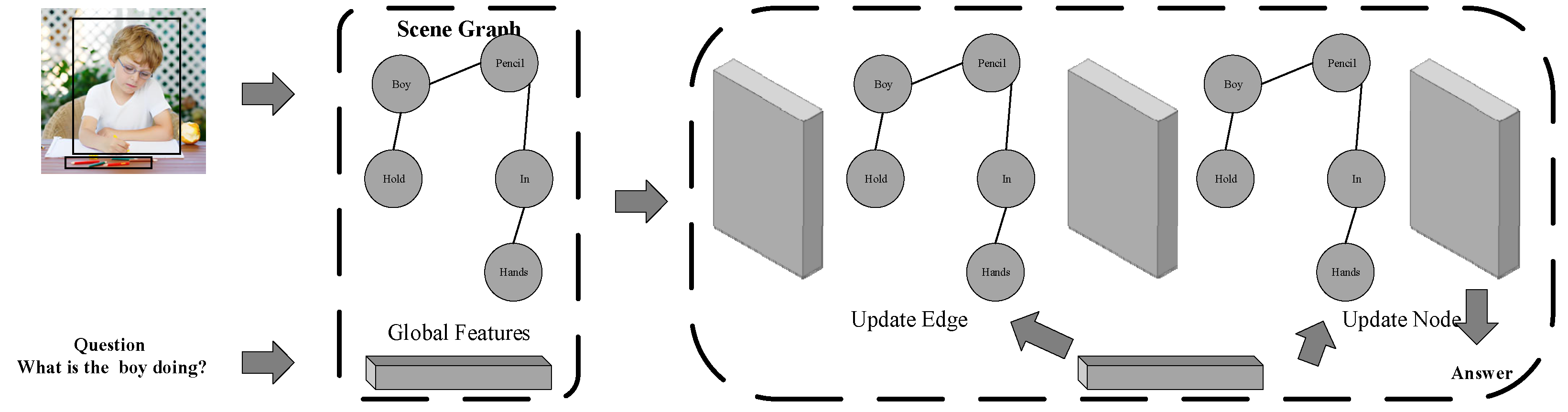
3.3.2. Visual Question Answering (VQA)
3.3.3. Cross-Media Retrieval
3.3.4. Applications in Different Fields
3.4. Frontier Issues of Graph Neural Networks in Computer Vision
3.4.1. Advanced Graph Neural Networks for Computer Vision
- (a)
- Person Feature Blocks: Yan et al. [114], Yang et al. [115], and Yan et al. [116] constructed spatial and temporal graphs for person re-identification (Re-ID) tasks. By horizontally dividing person feature maps into several small blocks, these blocks are treated as nodes, and graph convolutional networks (GCN) are used to model the relationships between body parts across frames.
- (b)
- Irregular Clustering Regions: Liu et al. [117] proposed a bipartite graph GNN for breast X-ray quality detection. Using k-nearest neighbors (kNN) forward mapping, the image feature map is divided into irregular regions, and the features of these regions are integrated as nodes. Nodes from images across different views represent geometric constraints and appearance similarities through the model.
- (c)
- Neural Architecture Search (NAS) Units: Lin et al. [118] introduced a graph-based neural architecture search algorithm (NAS), where operation units are represented as nodes, and GCNs are used to model the relationships between units, thus improving the efficiency and performance of network structure search.
3.4.2. Broader Applications of Graph Neural Networks in Computer Vision
4. Challenges and Future Directions
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- DiFilippo, N.M.; Jouaneh, M.K.; Jedson, A.D. Optimizing Automated Detection of Cross-Recessed Screws in Laptops Using a Neural Network. Appl. Sci. 2024, 14, 6301. [Google Scholar] [CrossRef]
- Zhang, Z.; Cui, P.; Zhu, W. Deep learning on graphs: A survey. IEEE Trans. Knowl. Data Eng. 2020, 34, 249–270. [Google Scholar] [CrossRef]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Yu, P.S. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4–24. [Google Scholar] [CrossRef]
- Li, A.; Xu, Z.; Li, W.; Chen, Y.; Pan, Y. Urban Signalized Intersection Traffic State Prediction: A Spatial-Temporal Graph Model Integrating the Cell Transmission Model and Transformer. SSRN. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5189471 (accessed on 10 April 2025).
- Zeng, R.; Huang, W.; Tan, M.; Rong, Y.; Zhao, P.; Huang, J.; Gan, C. Graph convolutional module for temporal action localization in videos. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 2028–2040. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Zhang, X.; Liu, Y. Towards efficient scene understanding via squeeze reasoning. IEEE Trans. Image Process. 2021, 30, 7050–7063. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Cui, G.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. Artif. Intell. 2020, 293, 103468. [Google Scholar] [CrossRef]
- Gori, M.; Monfardini, G.; Scarselli, F. A new model for learning in graph domains. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; IEEE: Piscataway, NJ, USA; Volume 2, pp. 729–734. [Google Scholar] [CrossRef]
- Dai, H.; Kozareva, Z.; Dai, B.; Smola, A.; Song, L. Learning steady-states of iterative algorithms over graphs. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 1106–1114. Available online: https://proceedings.mlr.press/v80/dai18a.html (accessed on 10 April 2025).
- Xie, Y.; Yao, C.; Gong, M.; Chen, C.; Qin, A.K. Graph convolutional networks with multi-level coarsening for graph classification. Knowl.-Based Syst. 2020, 194, 105578. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, S.; Aggarwal, C.C.; Tang, J. Graph convolutional networks with eigen pooling. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 723–731. [Google Scholar] [CrossRef]
- Ran, X.J.; Suyaroj, N.; Tepsan, W.; Ma, J.H.; Zhou, X.B.; Deng, W. A hybrid genetic-fuzzy ant colony optimization algorithm for automatic K-means clustering in urban global positioning system. Eng. Appl. Artif. Intell. 2024, 137, 109237. [Google Scholar] [CrossRef]
- Li, Q.; Han, Z.; Wu, X.-M. Deeper insights into graph convolutional networks for semi-supervised learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef]
- Bruna, J.; Zaremba, W.; Szlam, A.; LeCun, Y. Spectral networks and locally connected networks on graphs. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2014), Banff, AB, Canada, 14–16 April 2014; Available online: https://openreview.net/forum?id=DQNsQf-UsoDBa (accessed on 10 April 2025).
- Hamilton, W.; Ying, Z.; Leskovec, J. Inductive representation learning on large graphs. Adv. Neural Inf. Process. Syst. 2017, 30, 1024–1034. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Liò, P.; Bengio, Y. Graph Attention Networks. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018; Available online: https://openreview.net/forum?id=rJXMpikCZ (accessed on 10 April 2025).
- Zhang, J.; Shi, X.; Xie, J.; Ma, H.; King, I.; Yeung, D.Y. GAAN: Gated attention networks for learning on large and spatiotemporal graphs. arXiv 2018, arXiv:1803.07294. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 974–983. [Google Scholar] [CrossRef]
- Ding, Y.; Zhang, Z.; Hu, H.; He, F.; Cheng, S.; Zhang, Y. Graph sample and aggregate-attention network for hyperspectral image classification. In Graph Neural Network for Feature Extraction and Classification of Hyperspectral Remote Sensing Images; Springer: Singapore, 2021; pp. 29–41. Available online: https://link.springer.com/chapter/10.1007/978-981-97-8009-9_2 (accessed on 10 April 2025).
- Liu, Z.; Zhou, J. Graph attention networks. In Introduction to Graph Neural Networks; Synthesis Lectures on Artificial Intelligence and Machine Learning. Morgan & Claypool; Springer: Berlin/Heidelberg, Germany, 2022; pp. 39–41. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; van den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the European Semantic Web Conference, Heraklion, Crete, Greece, 3–7 June 2018; Springer: Cham, Switzerland; pp. 1–15. [Google Scholar] [CrossRef]
- Henaff, M.; Bruna, J.; LeCun, Y. Deep convolutional networks on graph-structured data. arXiv 2015, arXiv:1506.05163. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vanderhgheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. In Proceedings of the 30th International Conference on Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3844–3852. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2017, arXiv:1609.02907. [Google Scholar]
- Li, Y.; Tarlow, D.; Brockschmidt, M.; Zemel, R. Gated graph sequence neural networks. arXiv 2016, arXiv:1511.05493. [Google Scholar]
- Gilmer, J.; Schoenholz, S.S.; Riley, P.F.; Vinyals, O.; Dahl, G.E. Neural message passing for quantum chemistry. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1263–1272. [Google Scholar]
- Xu, K.; Hu, W.; Leskovec, J.; Jegelka, S. How powerful are graph neural networks? arXiv 2018, arXiv:1810.00826. [Google Scholar]
- Poli, M.; Massaroli, S.; Park, J.; Yamashita, A.; Asama, H.; Park, J. Graph neural ordinary differential equations. arXiv 2020, arXiv:2006.10637. [Google Scholar]
- Yun, S.; Jeong, M.; Kim, R.; Kang, J.; Kim, H.J. Graph Transformer Networks. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019; Available online: https://proceedings.neurips.cc/paper/2019/file/9d63484abb477c97640154d40595a3bb-Paper.pdf (accessed on 10 April 2025).
- Rossi, E.; Chamberlain, B.; Frasca, F.; Eynard, D.; Monti, F.; Bronstein, M. Temporal graph networks for deep learning on dynamic graphs. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Hu, Y.; You, H.; Wang, Z.; Wang, Z.; Zhou, E.; Gao, Y. Graph-MLP: Node classification without message passing in graph. arXiv 2021, arXiv:2106.04051. [Google Scholar]
- Li, J.; Deng, W.; Dang, X.J.; Zhao, H.M. Fault diagnosis with maximum classifier discrepancy and deep feature alignment for cross-domain adaptation under variable working conditions. IEEE T. Reliab. 2025, in press. [Google Scholar]
- Cantürk, S.; Liu, R.; Lapointe-Gagné, O.; Létourneau, V.; Wolf, G.; Beaini, D.; Rampášek, L. Graph positional and structural encoder. arXiv 2023, arXiv:2307.07107. [Google Scholar] [CrossRef]
- Zhuang, Y.; Jain, R.; Gao, W.; Ren, L.; Aizawa, K. Panel: Cross-media intelligence. In Proceedings of the Web Conference 2021, ACM, WWW ’21, 25th ACM International Conference on Multimedia, Montreal, QC, Canada, 11–15 April 2016; p. 1173. [Google Scholar]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep learning for generic object detection: A survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Xu, H.; Jiang, C.; Liang, X.; Li, Z. Spatial-aware graph relation network for large-scale object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 9290–9299. [Google Scholar] [CrossRef]
- Hu, H.; Gu, J.; Zhang, Z.; Dai, J.; Wei, Y. Relation networks for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; Volume 2018, pp. 3588–3597. [Google Scholar] [CrossRef]
- Chi, C.; Wei, F.; Hu, H. RelationNet++: Bridging visual representations for object detection via transformer decoder. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 33, pp. 13564–13574. [Google Scholar]
- Li, Z.; Du, X.; Cao, Y. GAR: Graph assisted reasoning for object detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 1295–1304. [Google Scholar] [CrossRef]
- Zhao, G.; Ge, W.; Yu, Y. GraphFPN: Graph feature pyramid network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 2743–2752. [Google Scholar] [CrossRef]
- Lin, T.Y.; Ma, L.; Belongie, S. Microsoft COCO: Common objects in context. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 1–20. [Google Scholar]
- Chen, C.; Li, J.; Zheng, Z.; Huang, Y.; Ding, X.; Yu, Y. Dual bipartite graph learning: A general approach for domain adaptive object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 2683–2692. [Google Scholar] [CrossRef]
- Li, W.; Liu, X.; Yuan, Y. SIGMA: Semantic-complete graph matching for domain adaptive object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 5281–5290. [Google Scholar] [CrossRef]
- Zhu, C.; Chen, F.; Ahmed, U.; Shen, Z.; Savvides, M. Semantic relation reasoning for shot-stable few-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8778–8787. [Google Scholar] [CrossRef]
- Chen, C.; Li, J.; Zhou, H.-Y.; Han, X.; Huang, Y.; Ding, X.; Yu, Y. Relation matters: Foreground-aware graph-based relational reasoning for domain adaptive object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 3677–3694. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar] [CrossRef]
- Satorras, V.G.; Estrach, J.B. Few-Shot Learning with Graph Neural Networks. In International Conference on Learning Representations. 2018. Available online: https://openreview.net/forum?id=BJj6qGbRW (accessed on 10 April 2025).
- Zhang, L.; Li, X.; Arnab, A.; Yang, K.; Tong, Y.; Torr, P.H.S. Dual graph convolutional network for semantic segmentation. arXiv 2020, arXiv:1909.06121. [Google Scholar]
- Chen, Y.; Rohrbach, M.; Yan, Z.; Shuicheng, Y.; Feng, J.; Kalantidis, Y. Graph-based global reasoning networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2019, Long Beach, CA, USA, 15–20 June 2019; pp. 433–442. [Google Scholar] [CrossRef]
- Zhang, L.; Xu, D.; Arnab, A.; Torr, P.H. Dynamic graph message passing networks. arXiv 2019, arXiv:1908.06955. [Google Scholar]
- Yu, C.; Liu, Y.; Gao, C.; Shen, C.; Sang, N. Representative graph neural network. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 379–396. [Google Scholar] [CrossRef]
- Li, X.; Yang, Y.; Zhao, Q.; Shen, T.; Lin, Z.; Liu, H. Spatial pyramid based graph reasoning for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8950–8959. [Google Scholar] [CrossRef]
- Hu, H.; Ji, D.; Gan, W.; Bai, S.; Wu, W.; Yan, J. Class-wise dynamic graph convolution for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 1–17. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Zhang, C.; Lin, G.; Liu, F.; Guo, J.; Wu, Q.; Yao, R. Pyramid graph networks with connection attentions for region-based one-shot semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9586–9594. [Google Scholar] [CrossRef]
- Xie, G.-S.; Liu, J.; Xiong, H.; Shao, L. Scale-Aware Graph Neural Network for Few-Shot Semantic Segmentation. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 19–25 June 2021; pp. 5471–5480. [Google Scholar] [CrossRef]
- Zhang, B.; Xiao, J.; Jiao, J.; Wei, Y.; Zhao, Y. Affinity Attention Graph Neural Network for Weakly Supervised Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 3000–3015. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Zhang, G.; Gao, Y.; Deng, X.; Gong, K.; Liang, X.; Lin, L. Bidirectional graph reasoning network for panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7794–7803. [Google Scholar] [CrossRef]
- Hsu, P.M. One-Shot Object Detection Using Multi-Functional Attention Mechanism. Master’s Thesis, National Taiwan University, Taipei Taiwan, China, 2020. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the IEEE International Conference on Computer Vision, Sydney, Australia, 1–8 December 2013; pp. 3551–3558. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. Adv. Neural Inf. Process. Syst. 2014, 27, 568–576. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3D convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; Volume 2015, pp. 4489–4497. [Google Scholar] [CrossRef]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? A new model and the kinetics dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4724–4733. [Google Scholar] [CrossRef]
- Donahue, J.; Hendricks, L.A.; Guadarrama, S.; Rohrbach, M.; Venugopalan, S.; Saenko, K.; Darrell, T. Long-term recurrent convolutional networks for visual recognition and description. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 2625–2634. [Google Scholar] [CrossRef]
- Herzig, R.; Levi, E.; Xu, H.; Gao, H.; Brosh, E.; Wang, X.; Globerson, A.; Darrell, T. Spatio-temporal networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; pp. 2347–2356. [Google Scholar] [CrossRef]
- Wang, X.; Gupta, A. Videos as space-time region graphs. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 399–417. [Google Scholar] [CrossRef]
- Ou, Y.; Mi, L.; Chen, Z. Object-relation reasoning graph for action recognition. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 20101–20110. [Google Scholar] [CrossRef]
- Zhang, J.; Shen, F.; Xu, X.; Shen, H.T. Temporal reasoning graph for activity recognition. IEEE Trans. Image Process 2020, 29, 5491–5506. [Google Scholar] [CrossRef]
- Shou, Z.; Chan, J.; Zareian, A.; Miyazawa, K.; Chang, S.F. CDC: Convolutional-de-convolutional networks for precise temporal action localization in untrimmed videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 21–26 June 2017; pp. 5734–5743. [Google Scholar]
- Zeng, R.; Huang, W.; Tan, M.; Rong, Y.; Zhao, P.; Huang, J.; Gan, C. Graph convolutional networks for temporal action localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7094–7103. Available online: https://openaccess.thecvf.com/content_ICCV_2019/html/Zeng_Graph_Convolutional_Networks_for_Temporal_Action_Localization_ICCV_2019_paper.html (accessed on 10 April 2025).
- He, X.; Sun, Z. ActivityNet: A large-scale video benchmark for human activity understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 961–970. [Google Scholar] [CrossRef]
- Li, L.; Tang, S.; Deng, L.; Zhang, Y.; Tian, Q. Image caption with global-local attention. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. Available online: https://ojs.aaai.org/index.php/AAAI/article/view/11236 (accessed on 10 April 2025).
- Yao, T.; Pan, Y.; Li, Y.; Mei, T. Exploring visual relationship for image captioning. In Computer Vision–ECCV 2018; Springer: Berlin/Heidelberg, Germany, 2018; Volume 11218, pp. 711–727. [Google Scholar] [CrossRef]
- Yang, X.; Tang, K.; Zhang, H.; Cai, J. Autoencoding scene graphs for image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10685–10694. Available online: https://openaccess.thecvf.com/content_CVPR_2019/html/Yang_Auto-Encoding_Scene_Graphs_for_Image_Captioning_CVPR_2019_paper.html (accessed on 10 April 2025).
- Shah, M.; Chen, X.; Rohrbach, M.; Parikh, D. Cycle-consistency for robust visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 6642–6651. [Google Scholar] [CrossRef]
- Zhang, C.; Chao, W.L.; Xuan, D. An empirical study on leveraging scene graphs for visual question answering. arXiv 2019, arXiv:1907.12133. [Google Scholar]
- Teney, D.; Liu, L.; van den Hengel, A. Graph-structured representations for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 3239–3247. [Google Scholar] [CrossRef]
- Li, L.; Gan, Z.; Cheng, Y.; Liu, J. Relation-aware graph attention network for visual question answering. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10312–10321. [Google Scholar] [CrossRef]
- Goyal, Y.; Khot, T.; Summers-Stay, D.; Batra, D.; Parikh, D. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. arXiv 2016, arXiv:1612.00837. [Google Scholar]
- Faghri, F.; Fleet, D.J.; Kiros, J.R.; Fidler, S. VSE++: Improving visual-semantic embeddings with hard negatives. arXiv 2017, arXiv:1707.05612. [Google Scholar]
- Yu, J.; Lu, Y.; Qin, Z.; Zhang, W.; Liu, Y.; Tan, J.; Guo, L. Modeling text with graph convolutional network for cross-modal information retrieval. In Advances in Multimedia Information Processing–PCM 2018; Hong, R., Cheng, W.H., Yamasaki, T., Wang, M., Ngo, C.W., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11164, pp. 223–234. [Google Scholar] [CrossRef]
- Wang, S.; Wang, R.; Yao, Z.; Shan, S.; Chen, X. Cross-modal scene graph matching for relationship-aware image-text retrieval. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020; pp. 1497–1506. [Google Scholar] [CrossRef]
- Young, P.; Lai, A.; Hodosh, M.; Hockenmaier, J. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Trans. Assoc. Comput. Linguist. 2014, 2, 67–78. [Google Scholar] [CrossRef]
- Cucurull, G.; Taslakian, P.; Vazquez, D. Context-aware visual compatibility prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 12609–12618. [Google Scholar] [CrossRef]
- Alhatemi, R.A.J.; Savaş, S. A weighted ensemble approach with multiple pre-trained deep learning models for classification of stroke. Medinformatics 2023, 2023, 10–19. [Google Scholar] [CrossRef]
- Zheng, J.; Liang, P.; Zhao, H.; Deng, W. A broad sparse fine-grained image classification model based on dictionary selection strategy. IEEE Trans. Reliab. 2024, 73, 576–588. [Google Scholar] [CrossRef]
- Chen, H.; Sun, Y.; Li, X.; Zheng, B.; Chen, T. Dual-Scale Complementary Spatial-Spectral Joint Model for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2025, 18, 6772–6789. [Google Scholar] [CrossRef]
- Chattopadhyay, S. Decoding Medical Diagnosis with Machine Learning Classifiers. Medinformatics 2024. Online First. [Google Scholar] [CrossRef]
- Zhao, H.; Wu, Y.; Deng, W. Fuzzy Broad Neuroevolution Networks via Multiobjective Evolutionary Algorithms: Balancing Structural Simplification and Performance. IEEE Trans. Instrum. Meas. 2025, 74, 2505910. [Google Scholar] [CrossRef]
- Li, M.; Li, J.; Chen, Y.; Hu, B. Stress Severity Detection in College Students Using Emotional Pulse Signals and Deep Learning. IEEE Trans. Affect. Comput. 2025. early access. [Google Scholar] [CrossRef]
- Aher, C.N. Enhancing Heart Disease Detection Using Political Deer Hunting Optimization-Based Deep Q-Network with High Accuracy and Sensitivity. Medinformatics 2023. Online First. [Google Scholar] [CrossRef]
- Long, H.; Chen, T.; Chen, H.; Zhou, X.; Deng, W. Principal space approximation ensemble discriminative marginalized least-squares regression for hyperspectral image classification. Eng. Appl. Artif. Intell. 2024, 133, 108031. [Google Scholar] [CrossRef]
- Deng, W.; Shen, J.; Ding, J.; Zhao, H. Robust Dual-Model Collaborative Broad Learning System for Classification Under Label Noise Environments. IEEE Internet Things J. 2025. early access. [Google Scholar] [CrossRef]
- Yao, R.; Zhao, H.; Zhao, Z.; Guo, C.; Deng, W. Parallel convolutional transfer network for bearing fault diagnosis under varying operation states. IEEE Trans. Instrum. Meas. 2024, 73, 3540713. [Google Scholar] [CrossRef]
- Li, M.; Chen, Y.; Lu, Z.; Ding, F.; Hu, B. ADED: Method and Device for Automatically Detecting Early Depression Using Multimodal Physiological Signals Evoked and Perceived via Various Emotional Scenes in Virtual Reality. IEEE Trans. Instrum. Meas. 2025, 74, 2524016. [Google Scholar] [CrossRef]
- Guo, D.; Zhang, Z.; Yang, B.; Zhang, J.; Yang, H.; Lin, Y. Integrating spoken instructions into flight trajectory prediction to optimize automation in air traffic control. Nat. Commun. 2024, 15, 9662. [Google Scholar] [CrossRef] [PubMed]
- Deng, W.; Feng, J.; Zhao, H. Autonomous Path Planning via Sand Cat Swarm Optimization with Multi-Strategy Mechanism for Un-manned Aerial Vehicles in Dynamic Environment. IEEE Internet Things J. 2025. early access. [Google Scholar] [CrossRef]
- Lin, Y.; Ruan, M.; Cai, K.; Li, D.; Zeng, Z.; Li, F.; Yang, B. Identifying and managing risks of AI-driven operations: A case study of auto-matic speech recognition for improving air traffic safety. Chin. J. Aeronaut. 2023, 36, 366–386. [Google Scholar] [CrossRef]
- Zhu, Z.; Li, X.; Chen, H.; Zhou, X.; Deng, W. An effective and robust genetic algorithm with hybrid multi-strategy and mechanism for airport gate allocation. Inf. Sci. 2024, 654, 119892. [Google Scholar] [CrossRef]
- Huang, C.; Ma, H.; Zhou, X.; Deng, W. Cooperative Path Planning of Multiple Unmanned Aerial Vehicles Using Cylinder Vector Particle Swarm Optimization with Gene Targeting. IEEE Sens. J. 2025, 25, 8470–8480. [Google Scholar] [CrossRef]
- Li, X.; Zhao, H.; Xu, J.; Zhu, G.; Deng, W. APDPFL: Anti-Poisoning Attack Decentralized Privacy Enhanced Federated Learning Scheme for Flight Operation Data Sharing. IEEE Trans. Wirel. Commun. 2024, 23, 19098–19109. [Google Scholar] [CrossRef]
- Deng, W.; Wang, J.; Guo, A.; Zhao, H. Quantum differential evolutionary algorithm with quantum-adaptive mutation strategy and population state evaluation framework for high-dimensional problems. Inf. Sci. 2024, 676, 120787. [Google Scholar] [CrossRef]
- Huang, C.; Song, Y.; Ma, H.; Zhou, X.; Deng, W. A multiple level competitive swarm optimizer based on dual evaluation criteria and global optimization for large-scale optimization problem. Inf. Sci. 2025, 708, 122068. [Google Scholar] [CrossRef]
- Chen, Y.; Ding, Y.; Hu, Z.-Z.; Ren, Z. Geometrized Task Scheduling and Adaptive Resource Allocation for Large-Scale Edge Computing in Smart Cities. IEEE Internet Things J. 2025. early access. [Google Scholar] [CrossRef]
- Huang, C.; Wu, D.; Zhou, X.; Song, Y.; Chen, H.; Deng, W. Competitive swarm optimizer with dynamic multi-competitions and convergence accelerator for large-scale optimization problems. Appl. Soft Comput. 2024, 167, 112252. [Google Scholar] [CrossRef]
- Ma, C.; Zhang, T.; Jiang, Z.; Ren, Z. Dynamic analysis of lowering operations during floating offshore wind turbine assembly mating. Renew. Energy 2025, 243, 122528. [Google Scholar] [CrossRef]
- Deng, W.; Li, X.; Xu, J.; Li, W.; Zhu, G.; Zhao, H. BFKD: Blockchain-Based Federated Knowledge Distillation for Aviation Internet of Things. IEEE Trans. Reliab. 2024. early access. [Google Scholar] [CrossRef]
- Yan, Y.; Zhang, Q.; Ni, B.; Zhang, W.; Xu, M.; Yang, X. Learning context graph for person search. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2153–2162. [Google Scholar] [CrossRef]
- Yang, J.; Zheng, W.-S.; Yang, Q.; Chen, Y.-C.; Tian, Q. Spatial-temporal graph convolutional network for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3286–3296. [Google Scholar] [CrossRef]
- Yan, Y.; Zhang, Q.; Ni, B.; Zhang, W.; Xu, M.; Yang, X. Learning multi-granular hypergraphs for video-based person re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 2896–2905. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, F.; Zhang, Q.; Wang, S.; Wang, Y.; Yu, Y. Cross-view correspondence reasoning based on bipartite graph convolutional network for mammogram mass detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3811–3821. [Google Scholar] [CrossRef]
- Lin, P.; Sun, P.; Cheng, G.; Xie, S.; Li, X.; Shi, J. Graph-guided architecture search for real-time semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4202–4211. [Google Scholar] [CrossRef]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep learning on point sets for 3D classification and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Yan, Y.; Mao, Y.; Li, B. SECOND: Sparsely Embedded Convolutional Detection. Sensors 2018, 18, 3337. [Google Scholar] [CrossRef]
- Zhou, Y.; Tuzel, O. VoxelNet: End-to-end learning for point cloud based 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4490–4499. [Google Scholar]
- Chen, J.; Lei, B.; Song, Q.; Ying, H.; Chen, D.Z.; Wu, J. A hierarchical graph network for 3D object detection on point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 389–398. [Google Scholar] [CrossRef]
- Lin, Z.-H.; Huang, S.-Y.; Wang, Y.-C.F. Convolution in the cloud: Learning deformable kernels in 3D graph convolution networks for point cloud analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1797–1806. [Google Scholar] [CrossRef]
- Xu, Q.; Sun, X.; Wu, C.-Y.; Wang, P.; Neumann, U. Grid-GCN for fast and scalable point cloud learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5660–5669. [Google Scholar] [CrossRef]
- Shi, W.; Rajkumar, R. Point-GNN: Graph neural network for 3D object detection in a point cloud. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1708–1716. [Google Scholar] [CrossRef]
- Dai, A.; Chang, A.X.; Savva, M.; Halber, M.; Funkhouser, T.; Nießner, M. ScanNet: Richly-annotated 3D reconstructions of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2432–2443. [Google Scholar] [CrossRef]
- Wang, X.; Ye, Y.; Gupta, A. Zero-shot recognition via semantic embeddings and knowledge graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6857–6866. [Google Scholar] [CrossRef]
- Kampffmeyer, M.; Chen, Y.; Liang, X.; Wang, H.; Zhang, Y.; Xing, E.P. Rethinking knowledge graph propagation for zero-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11479–11488. [Google Scholar] [CrossRef]
- Garcia, V.; Bruna, J. Few-shot learning with graph neural networks. arXiv 2017, arXiv:1711.04043. [Google Scholar]
- Liu, Y.; Lee, J.; Park, M.; Kim, S.; Yang, E.; Hwang, S.J.; Yang, Y. Learning to propagate labels: Transductive propagation network for few-shot learning. arXiv 2018, arXiv:1805.10002. [Google Scholar]
- Kim, J.; Kim, T.; Kim, S.; Yoo, C.D. Edge-labeling graph neural network for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 11–20. [Google Scholar] [CrossRef]
- Wang, Z.; Zheng, L.; Li, Y.; Wang, S. Linkage based face clustering via graph convolution network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 1117–1125. [Google Scholar] [CrossRef]
- Yang, L.; Zhan, X.; Chen, D.; Yan, J.; Loy, C.C.; Lin, D. Learning to cluster faces on an affinity graph. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2293–2301. [Google Scholar] [CrossRef]
- Zhang, N.; Deng, S.; Li, J.; Chen, X.; Zhang, W.; Chen, H. Summarizing Chinese medical answer with graph convolution networks and question-focused dual attention. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online, 16–20 November 2020; Cohn, T., He, Y., Liu, Y., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 15–24. [Google Scholar] [CrossRef]
- Wei, X.; Yu, R.; Sun, J. View-GCN: View-based graph convolutional network for 3D shape analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1847–1856. [Google Scholar] [CrossRef]
- Wald, J.; Dhamo, H.; Navab, N.; Tombari, F. Learning 3D semantic scene graphs from 3D indoor reconstructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 3960–3969. [Google Scholar] [CrossRef]
- Ulutan, O.; Iftekhar, A.S.M.; Manjunath, B.S. VSGNet: Spatial attention network for detecting human-object interactions using graph convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 13614–13623. [Google Scholar] [CrossRef]
- Sun, J.; Jiang, Q.; Lu, C. Recursive social behavior graph for trajectory prediction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 657–666. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, X.E.; Tang, S.; Shi, H.; Shi, H.; Xiao, J.; Zhuang, Y.; Wang, W.Y. Relational graph learning for grounded video description generation. In Proceedings of the 28th ACM International Conference on Multimedia (MM ‘20), Seattle, WA, USA, 12–16 October 2020; pp. 3807–3828. [Google Scholar] [CrossRef]
- Chen, J.; Ma, T.; Xiao, C. FastGCN: Fast learning with graph convolutional networks via importance sampling. arXiv 2018, arXiv:1801.10247. [Google Scholar] [CrossRef]
- Zhou, K.; Huang, X.; Song, Q.; Chen, R.; Hu, X. Auto-GNN: Neural architecture search of graph neural networks. Front. Big Data 2022, 5, 1029307. [Google Scholar] [CrossRef]
- Dwivedi, V.P.; Rampášek, L.; Galkin, M.; Parviz, A.; Wolf, G.; Luu, A.T.; Beaini, D. Long range graph benchmark. Adv. Neural Inf. Process. Syst. 2022, 35, 22326–22340. [Google Scholar]
- Srinivasa, R.S.; Xiao, C.; Glass, L.; Romberg, J.; Sun, J. Fast graph attention networks using effective resistance based graph sparsification. arXiv 2020, arXiv:2006.08796. [Google Scholar] [CrossRef]
- Tang, J.; Yang, Y.; Wei, W.; Shi, L.; Xia, L.; Yin, D.; Huang, C. HiGPT: Heterogeneous graph language model. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 2842–2853. [Google Scholar] [CrossRef]
- Ying, Z.; Bourgeois, D.; You, J.; Zitnik, M.; Leskovec, J. GNNExplainer: Generating explanations for graph neural networks. Adv. Neural Inf. Process. Syst. 2019, 32, 9240–9251. [Google Scholar]
- Zhang, L.; Zhang, Z.; Song, R.; Cheng, J.; Liu, Y.; Chen, X. Knowledge-infused graph neural networks for medical diagnosis. Sci. Rep. 2021, 11, 53042. [Google Scholar]
- Zhang, H.; Wu, B.; Yuan, X.; Pan, S.; Tong, H.; Pei, J. Trustworthy graph neural networks: Aspects, methods, and trends. Proc. IEEE 2024, 112, 97–139. [Google Scholar] [CrossRef]
- Wang, X.; Wu, Y.; Zhang, A.; Wang, H. GOODAT: Graph out-of-distribution anomaly detection for autonomous driving. IEEE Trans. Intell. Transp. Syst. 2022, 23, 11234–11247. [Google Scholar]
- Zhu, Z.; Wang, P.; Hu, Q.; Li, G.; Liang, X.; Cheng, J. FastGL: A GPU-efficient framework for accelerating sampling-based GNN training at large scale. arXiv 2023, arXiv:2409.14939. [Google Scholar]
- Magister, L.C.; Kazhdan, D.; Singh, V.; Liò, P. GCExplainer: Human-in-the-loop concept-based explanations for graph neural networks. arXiv 2021, arXiv:2107.11889. [Google Scholar] [CrossRef]
- Chai, Z.; Zhang, T.; Wu, L.; Han, K.; Hu, X.; Huang, X.; Yang, Y. GraphLLM: Boosting graph reasoning ability of large language model. arXiv 2023, arXiv:2310.05845. [Google Scholar] [CrossRef]




| Symbol | Meaning |
|---|---|
| v | Current node |
| u | Neighboring node |
| N(v) | Neighbor set of node v |
| Feature representation of node v at layer l | |
| Feature representation of neighboring node u at layer l | |
| W(l) | Learnable weight matrix at layer l |
| σ | Activation function (e.g., ReLU) |
| Message received by node v at layer l | |
| Feature representation of node v at layer l + 1 |
| Method | mAP Accuracy | Inference Speed (FPS) | Memory Consumption |
|---|---|---|---|
| Faster R-CNN [37] | 36.2% | 5 fps | 200 MB |
| YOLO [38] | 57.9% | 40+ fps | 250 MB |
| Mask R-CNN [39] | 37.1% | 10 fps | 300 MB |
| SGRN [40] | 38.3% | 15 fps | 320 MB |
| RelationNet++ [42] | 45.2% | 12 fps | 350 MB |
| GraphFPN [44] | 46.2% | 13 fps | 370 MB |
| Model | mIoU (%) | Parameter Count (M) | Key Innovation |
|---|---|---|---|
| Dual GCN [51] | 78.5 | 28.1 | Spatial-Channel Dual Graph Modeling |
| GRN [52] | 76.2 | 45.3 | Global Relationship Reasoning Unit |
| CDGC [56] | 80.1 | 29.5 | Category Dynamic Graph Convolution |
| Model | mIoU (%) | Key Innovation |
|---|---|---|
| PGAM [57] | 56.3 | Pyramid Graph Attention |
| Scale-Aware GNN [58] | 61.7 | Cross-Scale Node Collaboration |
| Model | Top-1 Acc (%) | Parameter Count (M) | Key Innovation |
|---|---|---|---|
| Region Graphs [72] | 76.3 | 23.5 | Spatio-Temporal Region Graph Reasoning |
| Object-Relation [73] | 78.1 | 32.7 | Participant-Centric Object-Level Graph |
| Temporal Reasoning [74] | 77.5 | 28.4 | Multi-Scale Temporal Graph Reasoning |
| Model | mAP@0.5 (%) | mAP@0.75 (%) | Key Innovation |
|---|---|---|---|
| CDC [75] | 45.3 | 26.1 | Deconvolutional Temporal Localization |
| P-GCN [76] | 48.3 | 27.5 | Candidate Graph Reasoning |
| Model | BLEU-4 | METEOR | CIDEr |
|---|---|---|---|
| Global–Local [78] | 36.5 | 27.7 | 108.2 |
| GCN-LSTM [79] | 38.2 | 28.3 | 112.5 |
| SGAE [80] | 39.1 | 28.9 | 114.8 |
| Model | Accuracy (%) | Key Innovation |
|---|---|---|
| Cycle-Consistency [81] | 68.5 | Cycle Consistency Constraint for Enhanced Cross-Modal Alignment |
| ReGAT [84] | 70.2 | Question-Adaptive Graph Attention Mechanism |
| Model | Image→Text R@1 | Text→Image R@1 | Key Innovation |
|---|---|---|---|
| VSE++ [87] | 52.9 | 39.6 | Hard Negative Sample Mining for Optimized Embedding Space |
| Dual-Channel GNN [89] | 58.3 | 42.7 | Graph Convolutional Network Coupling Multimodal Features |
| SGM [90] | 62.1 | 46.9 | Scene Graph Hierarchical Matching |
| Model | mAP@0.5 | Speed (FPS) | Key Innovation |
|---|---|---|---|
| VoxelNet [120] | 53.1 | 4.2 | Voxelization + 3D CNN |
| PointNet++ [119] | 58.3 | 12.4 | Hierarchical Point Set Feature Learning |
| Point-GNN [125] | 64.7 | 8.6 | End-to-End Graph Neural Network Detection |
| Grid-GCN [124] | 63.9 | 15.3 | Efficient Grid Context Aggregation |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, Z.; Wang, C.; Wang, Y.; Gao, X.; Li, B.; Yin, L.; Chen, H. Recent Research Progress of Graph Neural Networks in Computer Vision. Electronics 2025, 14, 1742. https://doi.org/10.3390/electronics14091742
Jia Z, Wang C, Wang Y, Gao X, Li B, Yin L, Chen H. Recent Research Progress of Graph Neural Networks in Computer Vision. Electronics. 2025; 14(9):1742. https://doi.org/10.3390/electronics14091742
Chicago/Turabian StyleJia, Zhiyong, Chuang Wang, Yang Wang, Xinrui Gao, Bingtao Li, Lifeng Yin, and Huayue Chen. 2025. "Recent Research Progress of Graph Neural Networks in Computer Vision" Electronics 14, no. 9: 1742. https://doi.org/10.3390/electronics14091742
APA StyleJia, Z., Wang, C., Wang, Y., Gao, X., Li, B., Yin, L., & Chen, H. (2025). Recent Research Progress of Graph Neural Networks in Computer Vision. Electronics, 14(9), 1742. https://doi.org/10.3390/electronics14091742