This section presents the findings of our analysis, including urban activity classification, walkability assessment, and transit accessibility evaluation. The results provide insights into spatial disparities in accessibility, highlighting areas where improvements are needed to enhance urban mobility and connectivity.
5.1. Urban Activity Analysis
To understand the spatial patterns of urban activity, we analyzed how the density of POIs around bus stops in Ulaanbaatar influences passenger flow to optimize transit networks. The dataset contains POIs across Ulaanbaatar, each labeled with diverse textual information. To understand the distribution of top categories, we classify the textual metadata of POIs into 13 high-level categories, as described in [
14], using LLM as gpt-4o-mini. The distribution POI categories are shown in
Figure 1, where the
x-axis represents the POI category, and the
y-axis shows its percentage share among all POIs. This indicates that urban activity is heavily service-oriented. The commercial category has the highest representation, accounting for nearly 30% of all POIs. This is followed by other, residence, and food, each making up a significant portion. Categories like health and medicine, education, and service also hold noticeable shares, while bus stations, entertainment, and business contribute smaller percentages. The least represented categories include transportation and traveling, sporting, and outdoor parks. Since we collected all bus stations separately, we excluded the bus stations from POIs.
The bus stops and POIs were converted into geospatial data points. A 300 m buffer around each bus stop was then defined as a standard walking distance [
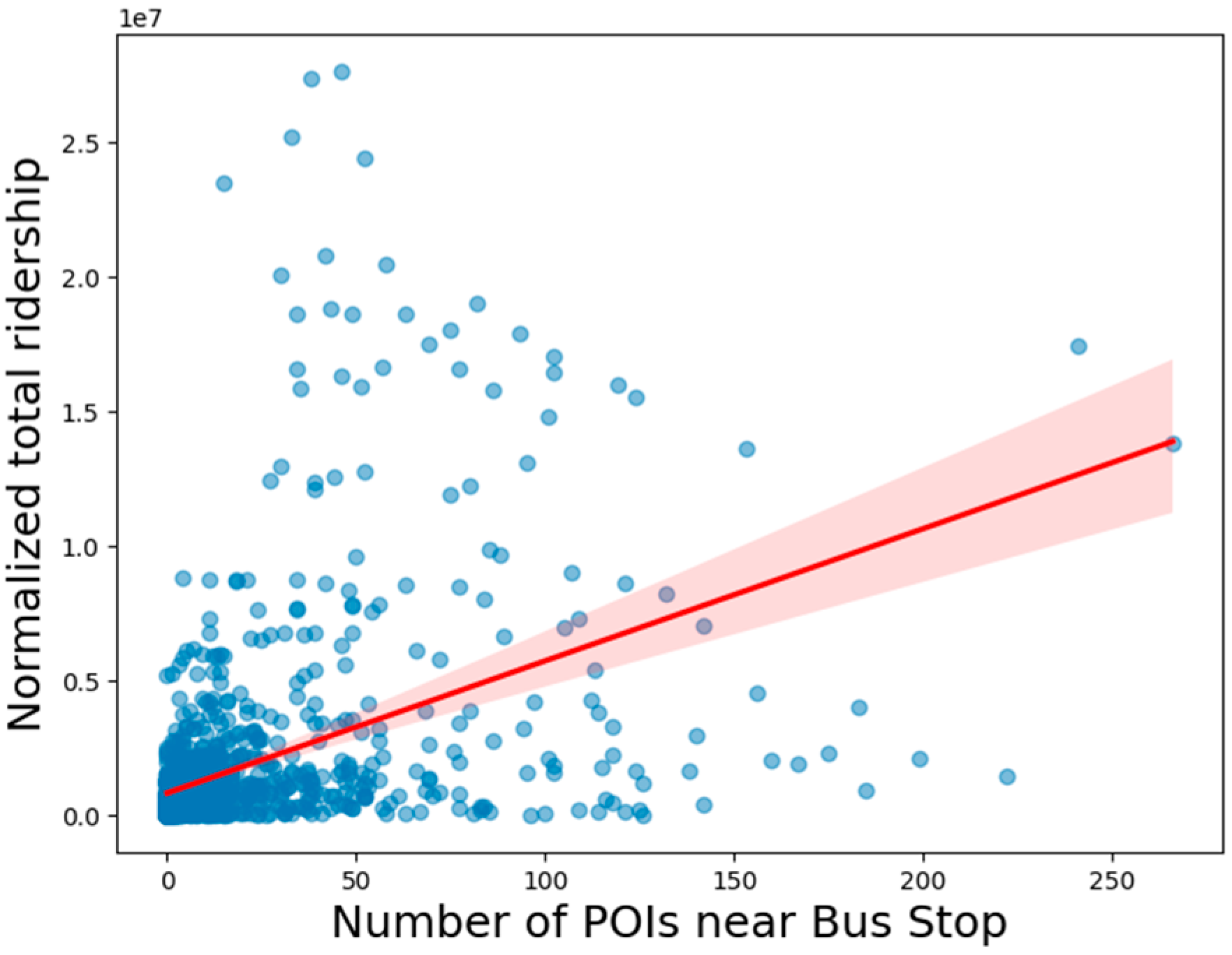
37] to account for the proximity of POIs, as we hypothesized that bus stops surrounded by more POIs might have higher ridership. For each bus stop, the number of POIs within this buffer zone was counted as POI density. To quantify this relationship, we used Pearson correlation analysis, which resulted in a correlation coefficient of 0.4408 with a
p-value of 0.0. This indicated a significant correlation among the different buffers of walking distance, as described in
Figure 2. This indicates the existence of a moderate positive correlation between POI density and ridership, meaning that bus stops located in areas with more POIs tend to have higher passenger activity. However, while this relationship is statistically significant, it is not the sole factor affecting ridership. Other variables, such as bus frequency, pedestrian accessibility, and population density, may also play a role in determining how many people use public transportation. Further, a linear regression model was applied to measure the direct impact of POI density on ridership. The regression coefficient of 49,087.97 suggests that for every additional POI within 300 m (at the maximum correlation) of a bus stop, the ridership at that stop increases by approximately 49,087 passengers. This strong association implies that transit planners could boost ridership by strategically placing bus stops near malls, universities, office buildings, and other key destinations. However, it is also possible that not all POIs contribute equally to ridership.
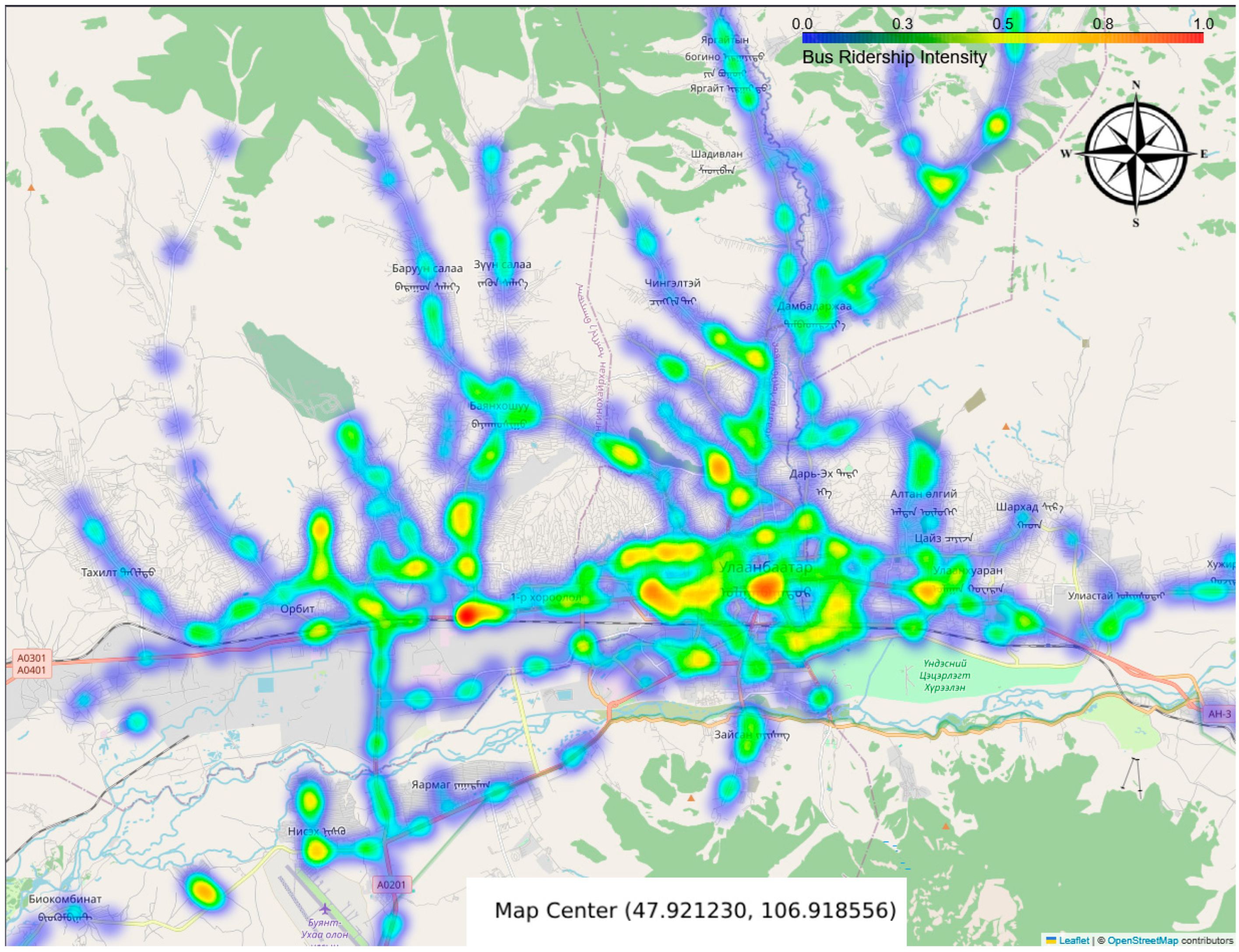
However, POI density is a reliable—but incomplete—proxy for ridership; we further explore whether POIs serve as proxies for ridership within areas that share similar profiles. By analyzing the distribution of POI categories and their spatial correlation with ridership patterns, we aim to determine if certain types of locations—such as commercial hubs, residential zones, or transit-oriented areas—exhibit a strong relationship with public transport usage. To estimate the impact of POIs on ridership, we calculate a 300 m buffer around each bus stop, representing the immediate area that might influence passenger flow. For each bus stop, we count how many POIs of each category fall within its buffer. This creates a profile of the surrounding environment for every bus stop. Simultaneously, we process the ridership dataset to calculate the total number of passengers boarding and alighting at each stop. These totals are merged into the bus stop data, giving us both spatial and usage information. We visualize the ridership patterns in
Figure 3, estimating betweenness centrality and total ridership on the map to ensure consistency in feature scales.
The red and yellow regions indicate the highest concentration of activity, while green and blue areas show lower activity levels. We compare the overlap to identify how many high-ridership areas match with high-POI-density locations. To compare the two clusters, we calculate the centroids for each of the clusters. We convert all geographical coordinates from degrees into radians. This step is necessary because the Haversine Formula described in Formula 1, which is used to calculate distances between two points on the Earth’s surface, requires input values in radians. To find the nearest ridership cluster for each POI, we identify the ridership centroid with the minimum distance from each POI centroid. We conduct correlation analysis between the number of nearby POIs (by category) and the total ridership at each stop. Specifically, we use Pearson correlation to assess whether the presence of certain types of POIs is associated with higher or lower bus usage. Finally, we visualize the results, using a bar chart in
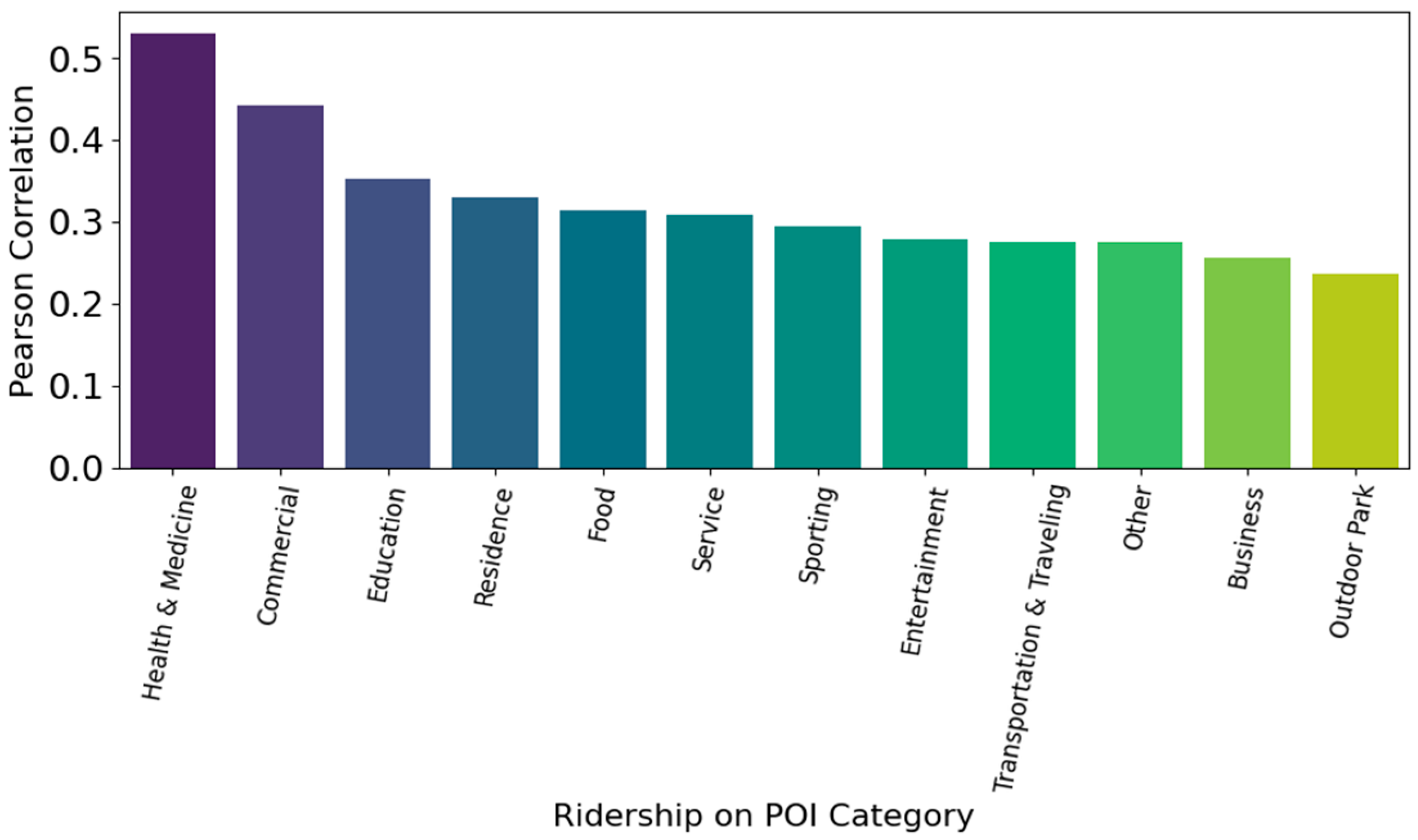
Figure 4 to highlight which POI categories are most strongly correlated with ridership. This allows us to identify areas, such as those with high concentrations of commercial or medical facilities, where POIs may serve as reliable proxies for public transport demand.
The category of health and medicine (r = 0.53) shows the strongest positive correlation with ridership. This suggests that areas near hospitals, clinics, and pharmacies tend to have high public transport usage, possibly due to accessibility needs and regular visits. Commercial (r = 0.44) zones—such as markets, malls, and retail stores—are also highly correlated with ridership. These areas likely act as economic hubs that attract large numbers of passengers. Education (r = 0.35) and residence (r = 0.33) follow closely, indicating that schools and residential areas also influence transit demand, reflecting daily commuting behavior. These results strongly demonstrate that specific types of amenities drive demand. Food, service, sporting, and entertainment categories exhibit moderate correlations (r ≈ 0.28–0.31), suggesting they contribute meaningfully to local transit needs, particularly in mixed-use or leisure-focused zones. The category of transportation and traveling (r = 0.27) is positively correlated with ridership. This is expected, as areas with transport hubs (excluding bus stations) tend to attract more riders. The category of outdoor park (r = 0.24) shows a weaker yet significant correlation, potentially reflecting lower-frequency but still relevant ridership patterns linked to recreational areas. This investigation helps assess whether clusters of specific POI types can reliably predict high or low ridership levels, providing insights for urban planning, transit optimization, and service placement. We constructed a stacked regression model composed of three diverse base learners: a Random Forest Regressor with 200 estimators, a Support Vector Regressor with epsilon = 0.2, C = 10, and a Gradient Boosting Regressor with 100 estimators. These base models were selected to capture different types of patterns and relationships within the data. A Ridge regression model was chosen as the meta-learner to combine the predictions of the base models, providing a robust final prediction. The R2 score was 0.2563, suggesting that the stacking model captures some variability in bus stop ridership. In this case, about 24.63% of the variance in ridership is explained by the neighborhood POIs, while the remaining 75.37% is due to other factors not captured by the model. For instance, certain bus stations may have been placed without adequately considering pedestrian accessibility to nearby POIs within a standard walking distance. Deep learning stacking explains 25.6% of ridership variance, confirming that service frequency, pedestrian quality, and socioeconomics must also be modelled. Bus stations are inconveniently located in residential areas. Such factors may encourage greater dependence on private vehicles for daily commutes, thereby exacerbating traffic congestion. While some areas exhibit very similar ridership patterns within a 0.3 km threshold, a significant portion of areas do not share these patterns. The ridership prediction of 31.58% at the 0.5 km threshold indicates that increasing the threshold allows a larger proportion of areas with POIs to be considered in close proximity to ridership. At a 1 km threshold, the ridership prediction rises to 57.89%, suggesting that over half of the areas are within 1 km of ridership. This is a notable increase compared to the 0.3 km and 0.5 km thresholds, showing that expanding the threshold captures a greater proportion of POIs closely associated with ridership behavior. This approach could be valuable for identifying areas where ridership coverage is insufficient in relation to POIs or for optimizing ridership routes.
We demonstrated that the Spectral clustering approach (k = 10, gamma = 1.0) using Formula 3, when applied to bus stations characterized by POIs and enhanced with ridership data, outperformed other clustering algorithms, as evaluated by the Silhouette score. The optimal parameters were determined by tuning them through grid search, and the neighborhood POI categories were embedded using a LLM—specifically BERT. Each POI category (such as “education”, “health and medicine”, etc.) was converted into a high-dimensional vector. The embeddings were aggregated (summed) for each bus stop based on its associated POI categories. If a bus stop had multiple POI categories, the embeddings for each category were summed together to form a single vector representation. We estimated the performance of the clustering methods by evaluating the ARI, which measures the similarity between two clustering results of the POIs and ridership. The ARI score was 0.3, suggesting a moderate positive agreement between the clustering of bus stops based on POI profiles and clustering based on ridership. This result highlights how similar areas in terms of POI characterization share similar ridership patterns in terms of health and medicine and commercial areas.
We further analyze optimal bus station allocation, which plays a key role in improving accessibility. Well-placed bus stops reduce travel time, enhance convenience, and encourage public transit use. Strategic planning ensures that stops serve high-demand areas while minimizing redundancy. In urban areas, bus stops are typically spaced between 300 and 500 m apart, ensuring easy access for passengers with a walking distance of 5–10 min. This distance is generally considered optimal for high-density areas, balancing coverage and efficiency [
28]. In suburban areas, where population density is lower, bus stops are typically spaced 800 m to 2 km apart. This reduces the number of stops, optimizing the system’s efficiency without compromising service [
37]. For express or high-speed routes, bus stops are spaced 2 to 5 km apart. These routes are designed to minimize travel time, often running on highways or major corridors with high ridership [
28]. In rural areas, where the population is more dispersed, bus stops are generally spaced 5 to 20 km apart, reflecting the longer distances between key locations [
38]. To ensure the optimal locations are selected for bus stations, we apply a quadtree partitioning approach, Quad-Bus partitioning using Formula 2 to the outer bounding box of the Ulaanbaatar city with following coordinates:
Longitude range—the westernmost boundary is located at 106.4919°, and the easternmost boundary is at 107.2829°;
Latitude Range—the southernmost boundary lies at 47.7412°, while the northernmost boundary is at 48.1881°.
The resulting spatial partitions were observed to be 847 based on the POI distribution in the outer bounding box. Each sub area represents a specific spatial partition, representing area characterization in terms of POI densities, and the size of these sub areas varies based on the distribution of POIs. The quadtree partitioning method adapts the size of the subareas, ensuring that each partition contains at least 10 POIs, with the smallest area of 300 m (walking distance).
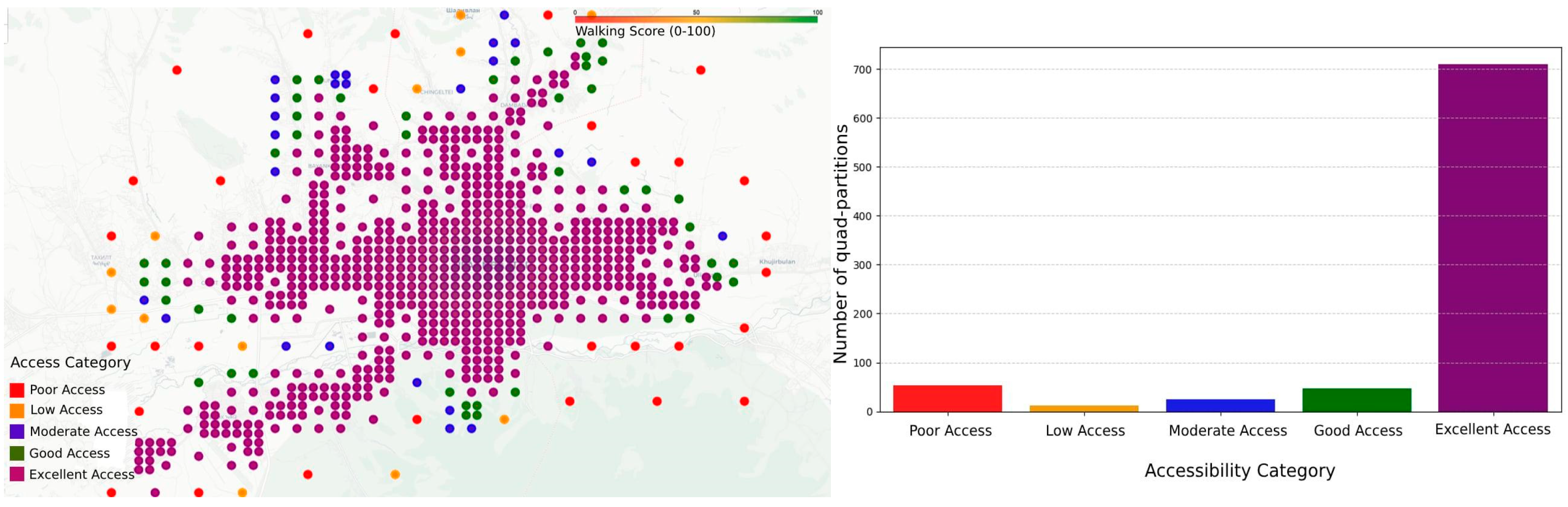
Figure 5 represents the subareas with a POI distribution by quadtree spatial partitioning.
Suburban areas tend to have larger partitions, with a lower density of POIs. In contrast, urban areas that correspond to urban centers typically have smaller partitions with a higher density of POIs, reflecting greater accessibility and mixed land use.
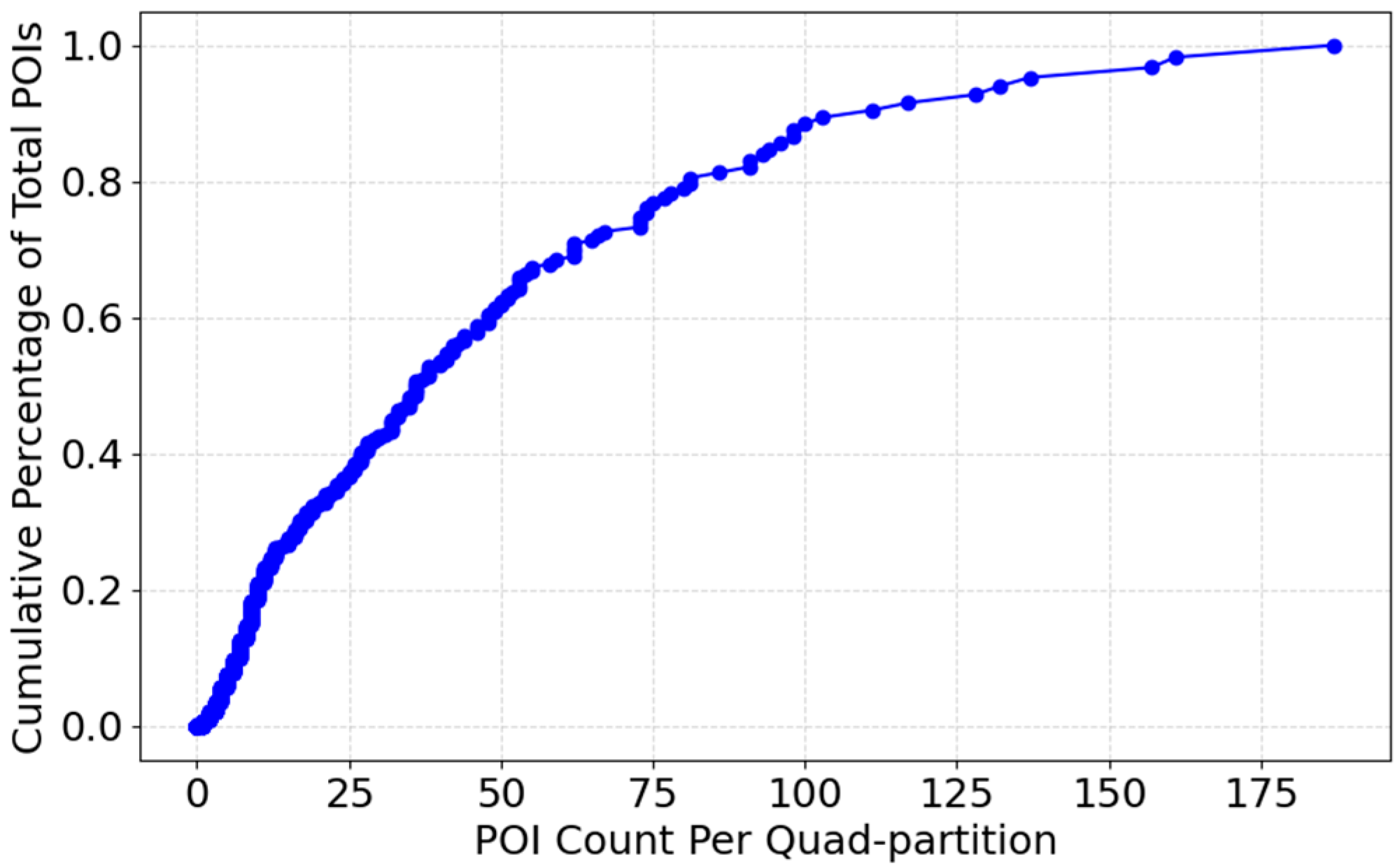
The cumulative distribution plot represented in
Figure 6 illustrates how POIs are distributed across various subareas. The
x-axis represents the number of POIs per partition, while the
y-axis shows the cumulative percentage of total POIs. As the curve progresses, it highlights the density variations in different areas, revealing whether POIs are concentrated in specific locations or evenly spread across the region. A steep initial slope denotes many low-activity partitions, while the flatter tail denotes a few high-activity hubs. At the lower end of the
x-axis, the steep incline suggests that a significant number of subregions contain only a small fraction of the total POIs. This indicates that many areas have relatively low activity or sparse development. As we move towards the middle, the curve becomes more gradual, signifying that certain subregions have a moderate and more consistent distribution of POIs. Towards the higher end, the curve flattens, showing that a few high-density areas account for a large portion of the total POIs.
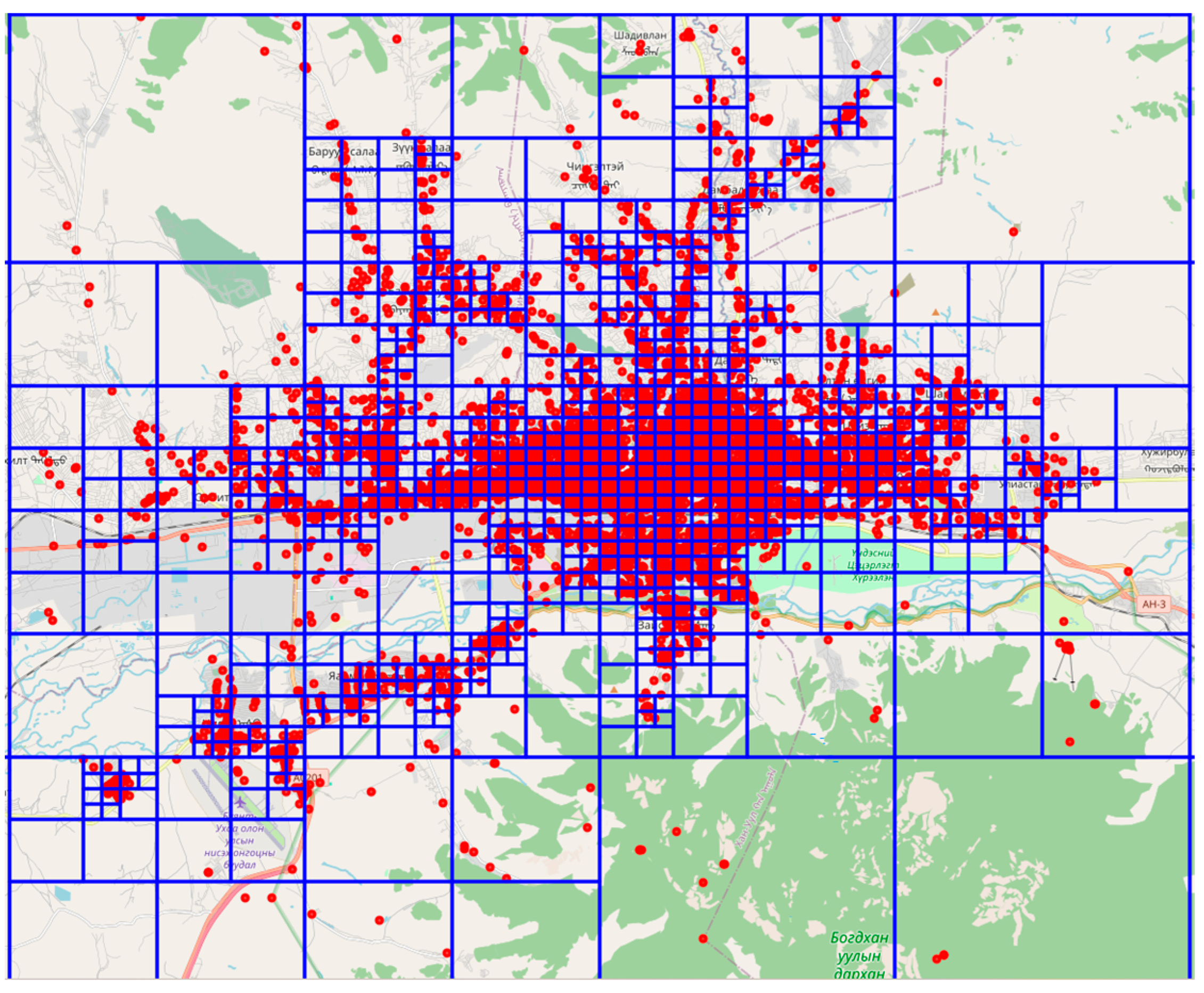
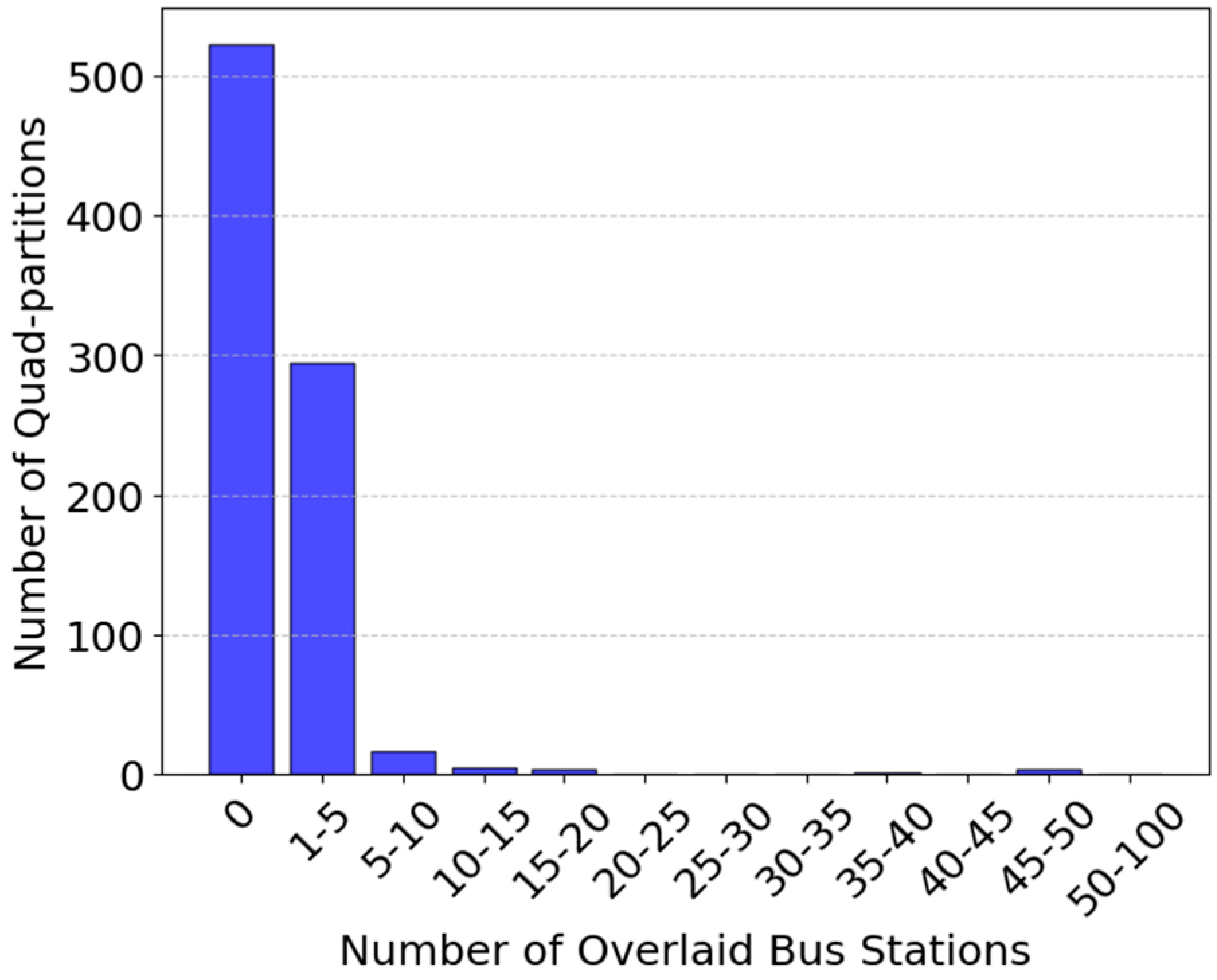
To assess the optimal geographic placement of bus stations based on the distribution density of POIs, we count the number of bus stations located within each subarea (partition) generated by the quadtree.
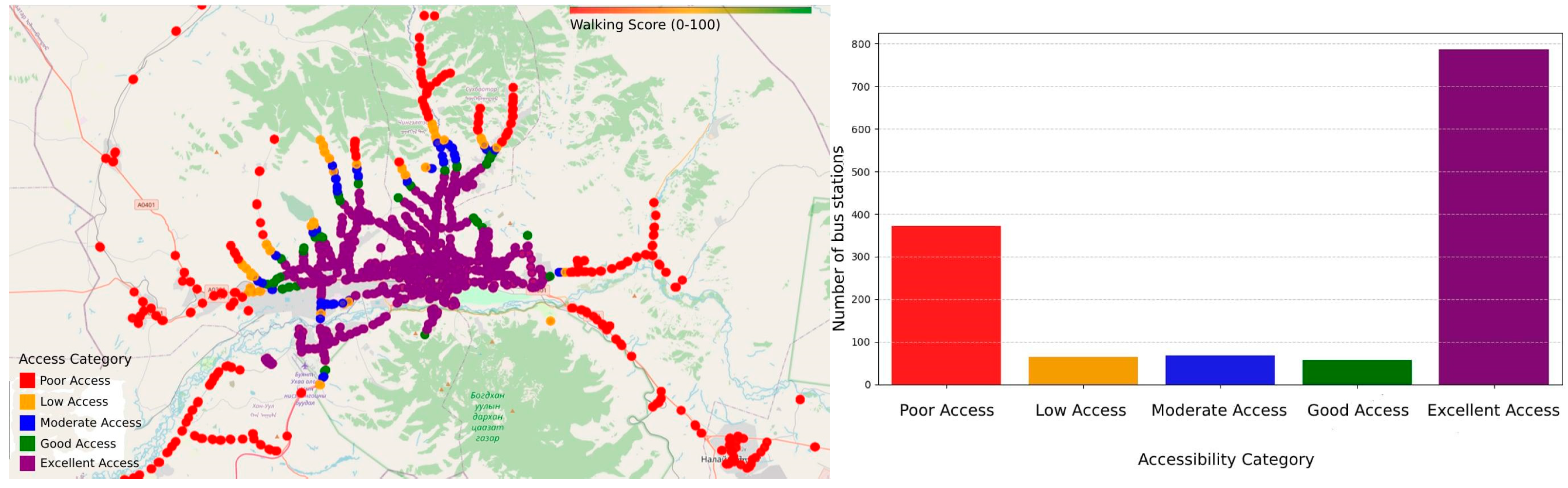
Figure 7 visualizes the spatial distribution of actual bus stations overlaid on the quadtree partitions.
Most partitions (over 500 subareas) have 0 bus stations. This suggests that the high-density activity urban areas have no coverage. A significant number of partitions, approximately 300 subregions, have 1 to 5 bus stations. Very few partitions contain 50+ bus stations. This highlights the uneven distribution of public transport infrastructure between urban and suburban areas, which in turn reduces overall ridership accessibility.
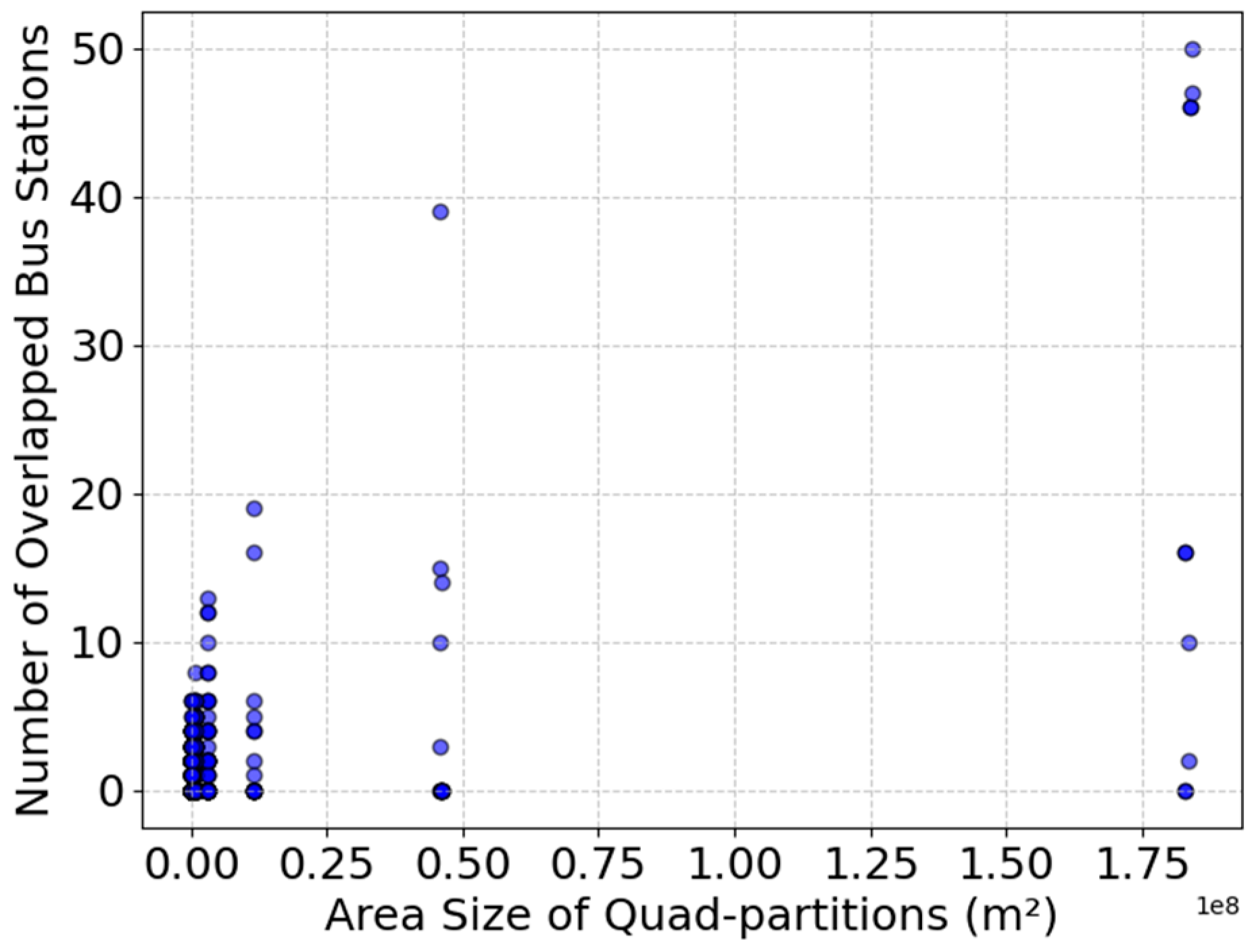
Figure 8 visualizes the relationship between quadtree partition size (in square meters) and the number of bus stations, highlighting how station density varies across different partition scales. Interestingly, smaller quadtree partitions contain between 0 and 10 bus stations per subarea. In contrast, larger quadtree partitions tend to encompass more bus stations per subarea, indicating that rural or suburban regions may have an overabundance of bus stations, or that the use of POI data collected from these areas may be insufficient.
This suggests that bus stations are sparsely distributed, and many of the quadtree subareas do not cover any bus stations. This indicates that bus stations are likely spread out across these low-activity zones, possibly covering larger areas or servicing multiple regions with fewer stations per partition. There are a few outliers where large quadtree sub areas overlap with higher bus station counts. This highlights that bus stations are poorly distributed, with high-density activity areas lacking any stations, while low-density areas have an abundance.
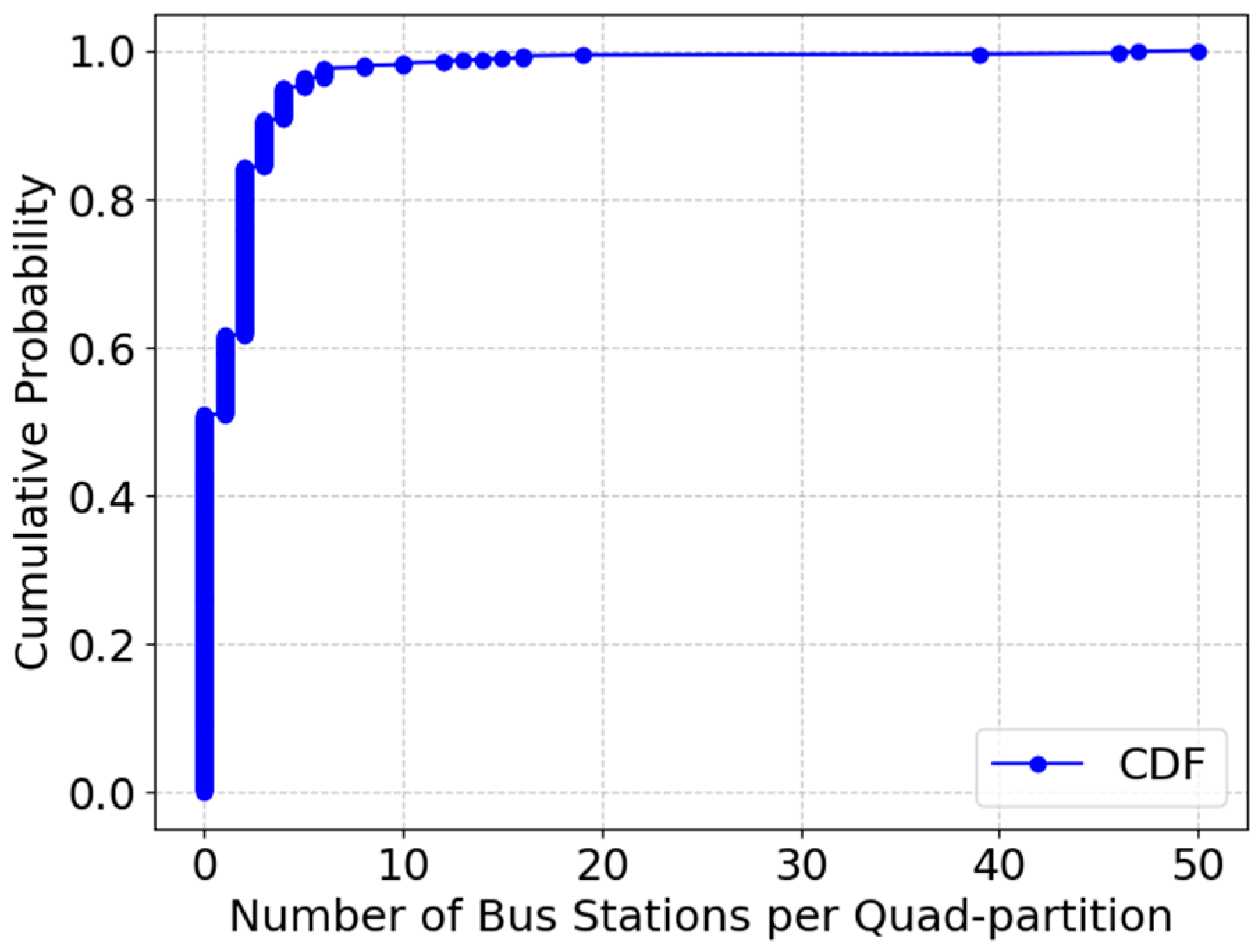
We describe the cumulative distribution of the bus stations per partition in
Figure 9, which reveals that over 500 urban partitions lack bus stops, meaning many neighborhoods are underserved by transit networks. The curve climbs steeply at the outset, revealing that half of the partitions contain no bus stations.. A large proportion of partitions (probably over 80%) contain fewer than 5 bus stations. Only a few partitions contain a high number of bus stations. This suggests that bus stations may be unevenly distributed, or that we were unable to identify high-activity areas due to the insufficient collection of POIs. A small number of partitions contain 50+ bus stops, indicating a highly uneven distribution of transit services. These findings suggest that bus stop placement strategies need optimization to serve high-demand areas more effectively.
5.2. Walkability Assessment
Walking Score using Formula 5 is a metric used to evaluate how accessible an area is for pedestrians based on the availability of essential services within a reasonable walking distance. It plays a crucial role in the 20 minute city concept, which envisions urban areas where residents can reach essential amenities—such as grocery stores, schools, healthcare facilities, and workplaces—within a 20 min walk. The maximum walking distance is calculated based on an average walking speed of 1.39 m per second (approximately 5 km/h) and a time limit of 20 min. This results in a maximum reachable distance of around 1668 m. Higher walking scores indicate more pedestrian-friendly environments, while lower scores suggest a reliance on vehicles for daily activities. The walking score was computed based on proximity to amenities (within 1600 m buffer zones), street connectivity and pedestrian infrastructure, and the availability of crosswalks, sidewalks, and pedestrian zones. A higher density of POIs within this distance indicates greater walkability. This normalization ensures comparability across regions. We classify walking scores into five categories [
4,
31] as presented in
Table 1.
A score between 90 and 100 indicates an extremely walkable area, while a score below 30 suggests strong dependence on vehicles. We estimate the walking score for both bus stations and quad partitions based on the number of POIs located within a 1600 m buffer, representing an approximate 20 min walking distance. This distance threshold reflects typical pedestrian accessibility standards in urban studies.
Figure 10 represents the distribution of walking scores for each bus station. The majority of bus stations fall into the “Excellent Access” category. This suggests that many bus stations are well-connected to POIs within a walkable distance. It indicates the need for an efficient urban planning design where public transport hubs are located near essential services (e.g., shopping centers, offices, schools, or healthcare facilities). In contrast, a significant number of bus stations have “Poor Access”. Many bus stations are in areas with limited POIs within walking distance. This could imply poor urban planning, lower density areas, or suburban locations where additional infrastructure is needed. The categories “Low, Moderate, Good” represent transitional areas, meaning some stations provide moderate accessibility but might still need improvements.
Figure 11 presents the walking score distribution across quad partitions. However, the proportion is much larger in the quad-partition chart, indicating that many geographical areas (quad partitions) have good accessibility or “Excellent Access”. The quad partitions have relatively small “Poor Access”. “Low, Moderate, Good” categories have relatively fewer entries. This consistency indicates that urban planning has created strong contrasts between well-connected and poorly connected areas, with fewer “middle-ground” locations. Quad partitions reflect the overall urban accessibility landscape well. The disparity in terms of poor access suggests that there are many transit hubs in low-accessibility areas, potentially leading to inefficient ridership patterns. The dominance of excellent access in quad partitions suggests that despite a high number of well-connected areas, some bus stations remain underutilized due to poor integration with the POI network.
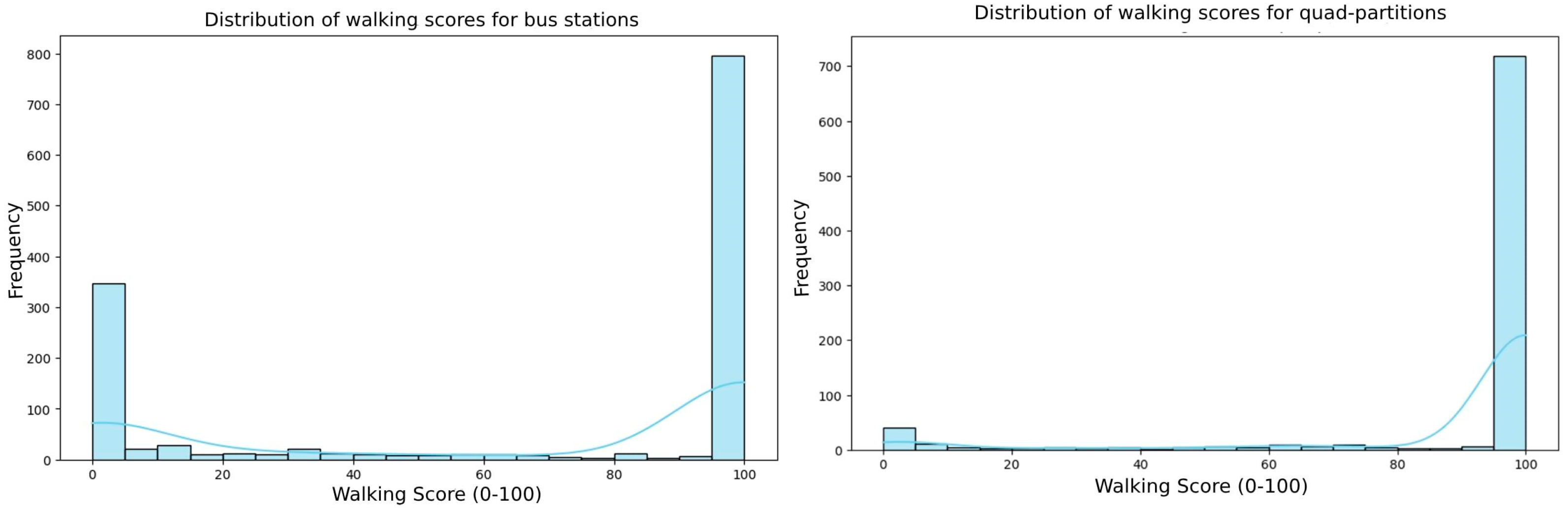
Figure 12 represents the walking score distribution compared to the walking scores for bus stations and quad partitions. POI accessibility within a 20 min walking distance is very limited across most areas. The urban parts of Ulaanbaatar seem highly dependent on transit for access to amenities. Central areas are likely to have better scores; peripheral regions remain underserviced. The histogram indicates that many bus stations have poor access to surrounding POIs within 1600 m. There is a rise at 95–100, showing that certain bus stations are located in highly dense and accessible urban areas. There is a huge spike at 100, indicating that many quad partitions (likely in the city center) have maximum walkability. There is a smaller spike at 0–5, indicating grid cells with almost no reachable POIs. There is a sparse distribution between 5 and 90—very few cells have moderate walking scores. However, the quad partitions in the initial analysis were constrained to have a minimum spatial extent of 300 m and were required to contain at least 10 POIs within their boundaries. While this ensures a baseline level of urban activity and comparability across partitions, these thresholds inevitably shape the resulting distribution of walking scores. To further explore the sensitivity of our findings, we extend the analysis by tuning these thresholds to vary both the minimum partition size and the minimum required number of POIs in order to better understand their impact on walking score patterns and urban spatial structure.
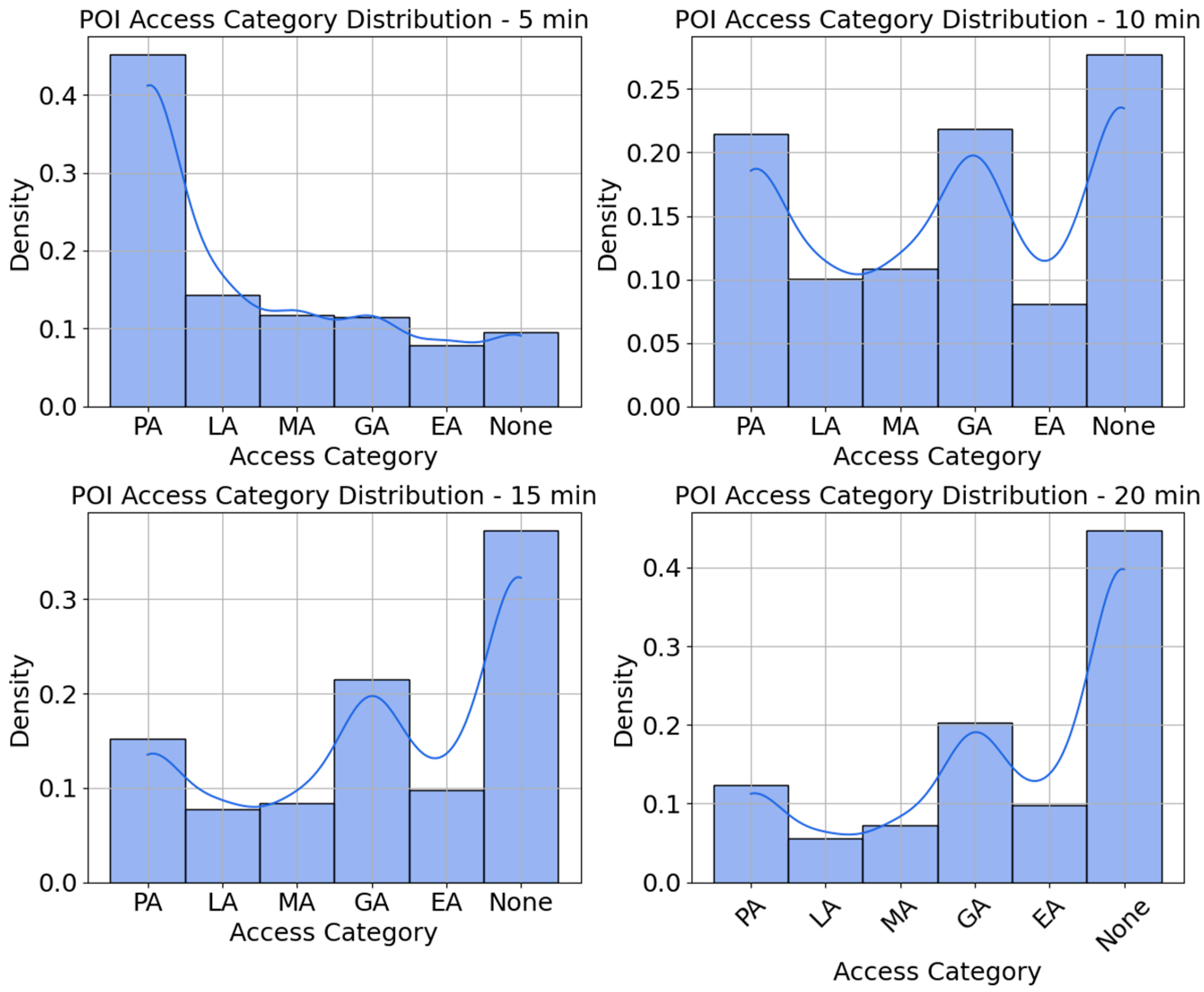
In
Figure 13, each panel shows the distribution of walking scores—the raw count of POIs that can be reached from every quad-partition centroid—given a different walking-time threshold (5, 10, 15, and 20 min). The
x-axis is the walking score itself; the
y-axis is the number of POIs that fall into each score bin. As the walking time increases from 5 min to 20 min, the distribution shifts towards better access categories, with excellent access (EA) becoming the most prominent at the 20 min interval. For shorter intervals (5 and 10 min), the access distribution is skewed toward poor access (PA), meaning that many POIs are not easily accessible in a short walk. However, as the interval increases, the access categories become more balanced, with better access spreading across the dataset. The KDE curve helps in visualizing the smooth distribution of POIs across the categories, indicating areas of higher and lower concentrations of accessible POIs. In the 10 min walking radius, the access distribution becomes more spread out, with poor access (PA) still having a prominent peak, but Low Access (LA) starts to show higher counts compared to the 5 min interval. The 15 min interval sees more balance in the distribution of access categories. Moderate access (MA) starts to show a significant increase, and good access (GA) and excellent access (EA) also begin to appear more prominently. The results highlight the importance of walking distance in determining accessibility to POIs and emphasize the increasing availability of accessible locations as the walking radius expands.
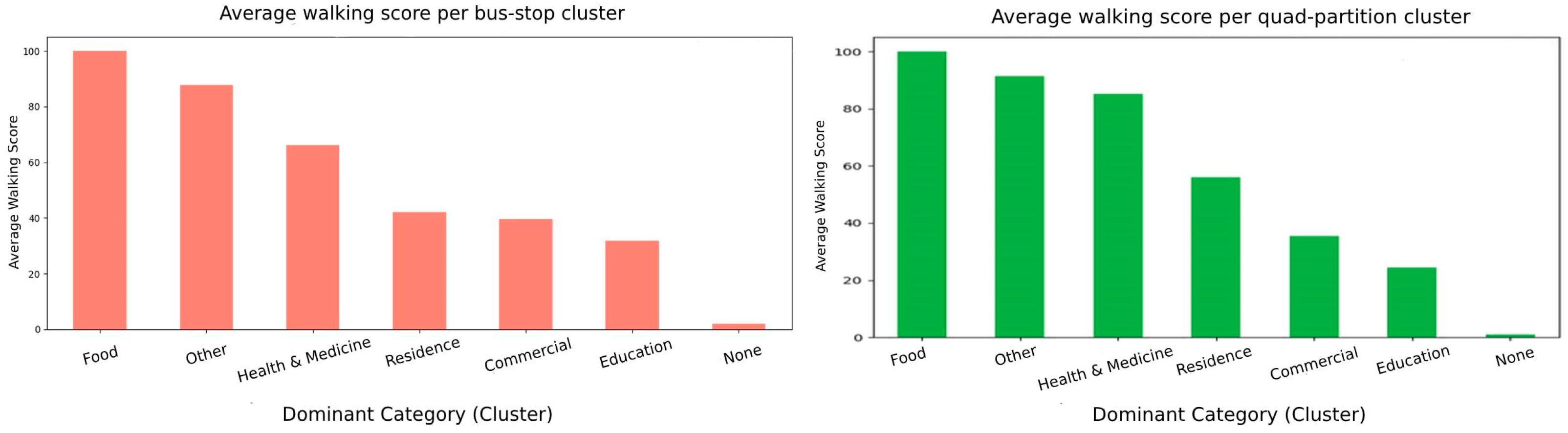
We further explore the walking accessibility for POI-category-specific areas. We use semi-supervised clustering Label Propagation with an Radial Basis Function (RBF) kernel. We feed the clustering with a full category histogram per quad partition as a feature vector. The supervision came from the dominant categories: any category that appeared in at least eight different quad partitions was treated as a seed class, providing a handful of labelled examples for the algorithm to propagate across the feature space. The clusters that emerged were ranked by their average walking score.
Figure 14, the
x-axis of which is labelled with each cluster’s dominant category, makes it easy to see which kinds of areas offer the richest mix of nearby amenities. In a typical run, the café- and restaurant-dominated clusters rose to the top, with average scores in the mid-eighties, whereas clusters dominated by industrial or sparse residential categories languished near the bottom, with averages barely above ten. Even a coarse measure such as an unweighted POI count, when combined with semi-supervised learning, can already separate highly walkable micro-areas from less attractive ones.
Quad partitions benefit campuses and hospital complexes, whose POIs are spread across several adjacent stops. The none category is a mixed category without a dominant aspect. At the bus stop clusters, the food and other clusters are already strong regarding walkability. In contrast, none, residence, and parts of commercial/education are “doubly disadvantaged” zones that would benefit most from either new local amenities or better last-mile connections. Food- and health-dominated cells average Walk Scores ≈ 100 and 92, respectively, while residence and mixed “none” clusters have scores falling below 30, indicating that they have both few amenities and weak transit. Food (walking score ≈ 100)-specific quad partitions, whose 20 min walking catchment is dominated by restaurants, cafés, and grocery shops, score almost the theoretical maximum. Health and medicine (walking score ≈ 92)-specific quad partitions, anchored by hospitals, clinics, or pharmacies, are also highly walkable. Besides medical facilities, these catchments typically contain convenience stores and eateries, boosting the score. Purely residential districts tend to be mono-functional. Housing blocks are plentiful, but ground-floor retail or services are sparse, and so walkability drops.
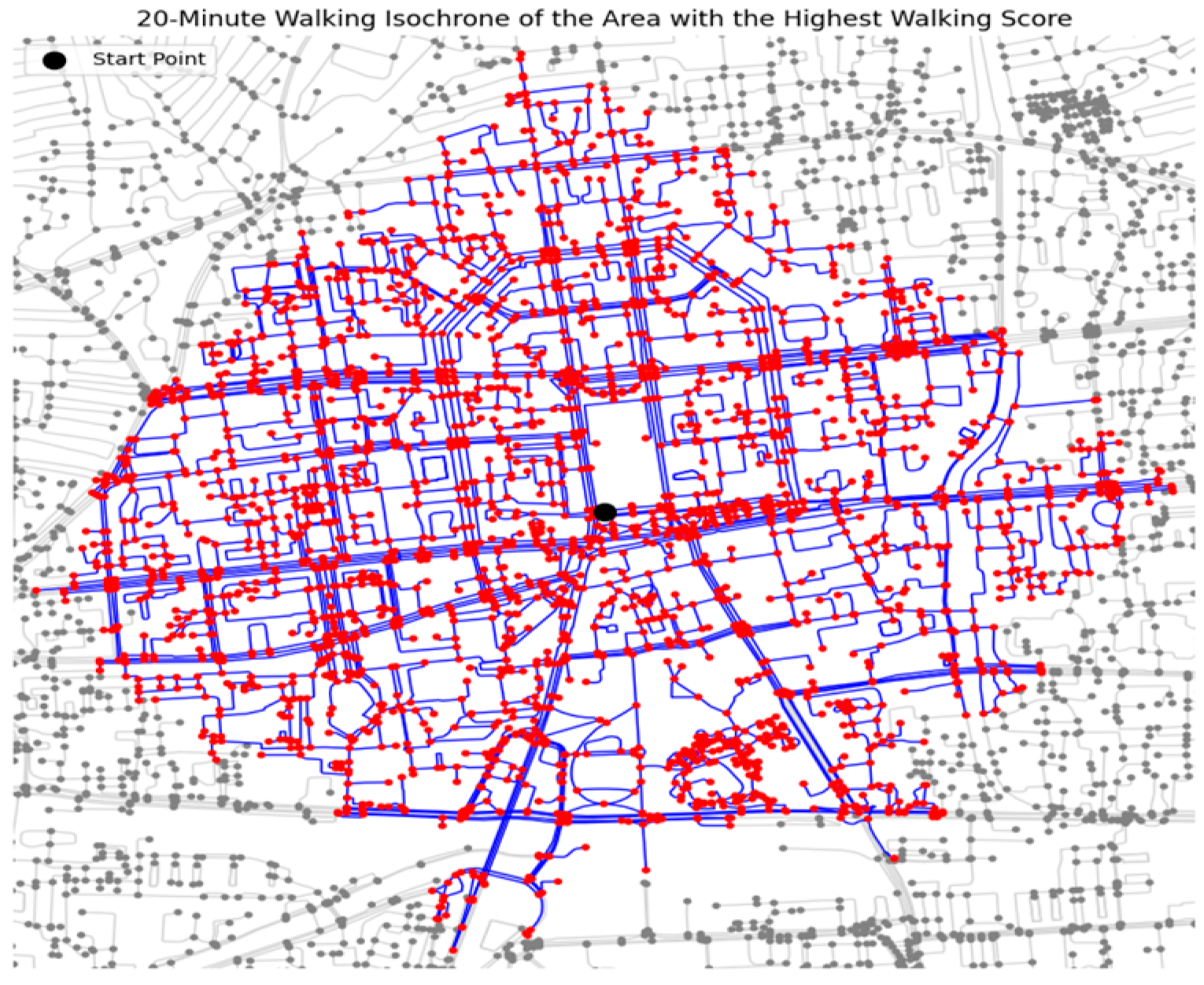
To further explore walkability in pedestrians, we generated walking isochrones using Formula 4, at 20 min walking intervals for a given quad partition (the centroid lat = 47.918, lon = 106.917) with the highest walking score. A walking isochrone represents the area that can be reached within a given time by walking from a specific location. The isochrones illustrate how far pedestrians can travel within a set time, considering road networks and pedestrian barriers.
To generate a 20 min walking isochrone as
Figure 15, we extract a pedestrian-friendly road network from OSMusing the OSMnx library. The network is then converted into an undirected graph, ensuring that movement is unrestricted in any direction. We identify the nearest node to a given starting point, which serves as the center of the isochrone analysis. Using NetworkX, we extract all nodes within this distance using an ego graph, which represents the subgraph of all nodes reachable from the center within the specified limit. The figure shows the full road network in gray, overlays the 20 min isochrone in blue, and marks the starting point in red. The blue lines represent the street network that is walkable within the 20 min time frame. The red nodes indicate reachable locations (intersections or important points along the street network) within the isochrone. Gray nodes and streets represent the broader road network beyond the walkable range. The density and connectivity of the blue lines and red nodes suggest that this is a highly walkable area, meaning many locations can be reached within the 20 min window. If the blue network is sparse or disconnected, it may indicate barriers such as wide roads, highways, or missing pedestrian pathways that reduce accessibility.
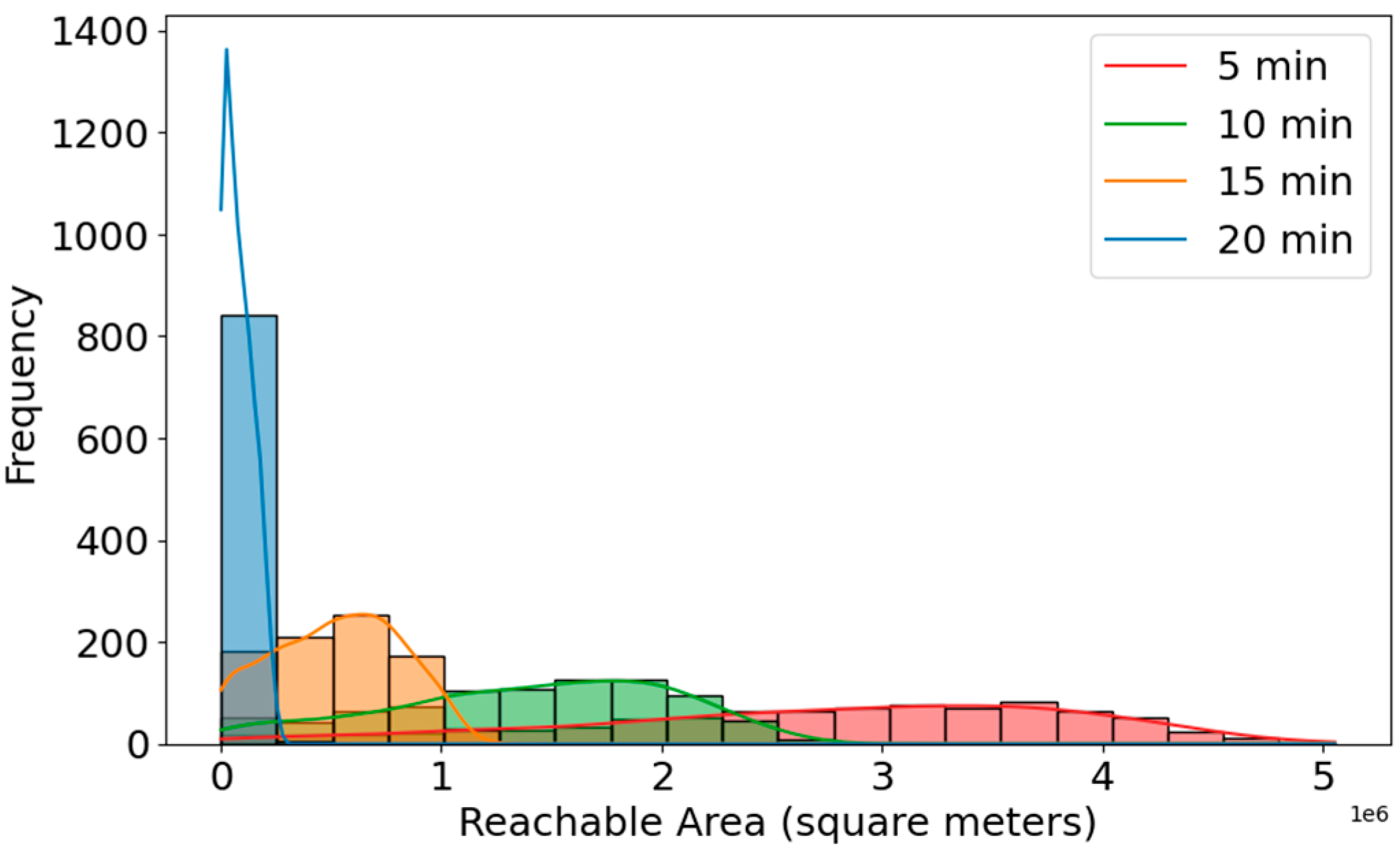
Figure 16 illustrates distribution of reachable areas (walking isochrone) across quad-partition centroids, for different time intervals. We use Universal Transverse Mercator (UTM) projection to obtain accurate isochrone areas in square meters. The
X-axis is a reachable area in square meters. The
Y-axis is frequency. A large number of centroids have small reachable areas, even when considering 20 min of walking. This suggests that there is limited connectivity in the pedestrian network or physical/urban barriers (e.g., large blocks, rivers, highways, poor infrastructure). A higher bar means more locations are reachable from an area. Blue (20 min): Many locations have a very small area reachable within 20 min. The distribution is heavily skewed to the left, suggesting the existence of obstacles like road design, natural barriers, or disconnected paths. Orange (15 min) and green (10 min): as walking time decreases, fewer locations have very high accessibility, but the area increases gradually. Red (5 min): Expectedly, this color covers smaller areas, but they are more spread out, suggesting that some locations are highly walkable, even in just 5 min. With 10, 15, and 20 min, the accessible area gradually increases, showing that longer walking times provide access to a wider range of areas, but the frequency decreases as areas grow larger. All distributions are right-skewed—meaning most locations have relatively a low reachable walking area, while a few have very high walkable access. These findings emphasize that while central districts support pedestrian mobility, many outer neighborhoods lack adequate pedestrian infrastructure, reinforcing the need for investment in walkways, street crossings, and urban design improvements.


 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}