1. Introduction
Since Google introduced the concept of the knowledge graph in May 2012 [
1], technologies related to knowledge graphs have remained a prominent research focus. Today, knowledge graphs are not only used as data storage tools but also serve as the knowledge backbone for applications such as intelligent search [
2], recommendation systems [
3], and question-answering systems [
4], playing a crucial role in improving the efficiency and quality of public knowledge acquisition [
5]. A knowledge graph aims to describe concepts, entities, events, and their relationships in the real world. Essentially, it is a semantic network graph where entities and attributes serve as nodes, while semantic relationships between them form the edges [
6]. Named entity recognition (NER) and relation extraction (RE) are the two most critical tasks in the construction of knowledge graphs.
Specifically, named entity recognition aims to extract entities of specific types from unstructured text, while relation extraction seeks to determine the semantic relationships between these entities. Early research introduced rule-based approaches, followed by feature engineering and machine learning methods. More recently, deep learning has been widely applied to both tasks. Deep neural network models can automatically learn sentence features without requiring complex feature engineering, leading to significant advancements in NER and RE. However, existing models have yet to fully resolve the challenges of these tasks, primarily due to their excessive reliance on contextual associations in unstructured text. When dealing with incomplete or ambiguous descriptions, their performance tends to degrade. Additionally, these models struggle with polysemous words, often misclassifying them as different entities or failing to recognize the correct relationships between them. This issue is particularly evident in social media, where texts are typically short and often contain slang [
7]. As a result, models find it difficult to learn robust features from such limited textual data. Fortunately, with advancements in internet technology and information storage, data on the web has shifted from traditional text-only formats to multimodal representations. For example, social media content often includes images alongside text. In NER and RE tasks, leveraging textual content as the primary source while incorporating images as supplementary information can effectively address the limitations of short text. This necessity has led to the emergence of Multimodal Named Entity Recognition (MNER) and Multimodal Relation Extraction (MRE) tasks.
The core of MNER and MRE tasks lies in learning effective visual features and integrating them into text representations. Previous studies have demonstrated the effectiveness of incorporating visual modalities into knowledge graph construction tasks [
8]. For processing visual information, early research directly used entire images as global feature vectors to enhance text representations [
9] or focused on encoding visual objects [
10] by establishing explicit alignment relationships between objects and textual entities. While these approaches have made some progress, they fail to fully exploit fine-grained semantic correspondences between semantic units in sentence-image pairs. Subsequent researchers recognized that the ability of image encoders to represent rich image information is crucial [
11]. Radford et al. [
12] proposed the contrastive language-image pretraining model, CLIP. Although its direct application to MNER and MRE tasks was found to perform poorly, it provided valuable insights for later researchers. Following this, some researchers explored pretraining models better suited for MNER and MRE tasks, such as VisualBERT [
13], ViLBERT [
14], CLIP-ViL [
15], METER [
16], and X-VLM [
17]. With advancements in image encoders, researchers have adopted a transformer-based framework, segmenting an entire image into multiple regions and enabling their interaction with text sequences [
18]. For example, Zhang et al. [
19] aligned entities and objects within visual and textual graphs constructed from potential relationships between objects and words.
Despite their notable successes, these approaches still face two major challenges. The first challenge is modal noise. Vempala and Preoţiuc-Pietro [
20] found that approximately 33.8% of tweets lack textual content corresponding to images. This indicates that not all images provide complementary textual information; some are entirely unrelated to the text, introducing misleading noise that hampers prediction accuracy rather than contributing useful information. While RpBERT [
21] trains a classifier before the main task to determine the relevance between images and tweets, this method heavily relies on large-scale labeled image-text datasets and only considers the overall image, ignoring key objects within it. The second challenge is modal discrepancy. The distributional differences between textual and visual features significantly limit a model’s ability to effectively capture cross-modal semantic correlations. For example, in the text “Rocky is ready for snow season” (corresponding to
Figure 1), identifying the semantic relevance between the textual entity “Rocky” and the visual entity (a dog in the image) is particularly challenging.
Based on these two challenges, this paper integrates the strengths of existing MNER and MRE approaches and proposes a novel end-to-end model. The proposed method consists of five key components: visual feature extraction, visual feature adaptation, textual feature extraction, multimodal feature fusion, and task output. The main contributions of this work are as follows:
- (1)
Enhanced Visual Feature Representation: By incorporating group-level information during image encoding, the model selectively combines global and local visual features as an improved visual prefix for multimodal fusion. This approach not only reduces modal noise but also enhances data utilization.
- (2)
Feature Fusion within CorefBERT: The proposed model integrates feature fusion within CorefBERT, which effectively captures contextual information, understands inter-sentence relationships, and handles cross-sentence coreference and multi-referential chains. This not only mitigates modal discrepancies but also improves textual feature extraction.
- (3)
Comprehensive Evaluation and Ablation Studies: The proposed method is evaluated against baseline models on public benchmark datasets for MNER and MRE tasks, demonstrating its superior performance. Additionally, ablation studies validate the effectiveness of each module within the model.
2. Related Works
The following sections introduce the related work on the MNER and MRE tasks.
MNER was first explored in 2018 by Moon, Carvalho, et al. [
22]. Their proposed method encoded text using RNNs and the entire image using CNNs, implicitly interacting between the two modalities. This development paved the way for MNER’s potential applications across various social media platforms. Subsequently, researchers explored different strategies to integrate image features into text representations. Zhang et al. [
23] further investigated how to incorporate whole-image features into textual representations. Zheng et al. [
24] designed a gated bilinear attention network with an adversarial strategy to better extract fine-grained objects from images. Additionally, some studies introduced graph-based methods to enhance modality alignment. Zhao et al. [
25] and Yuan et al. [
26] proposed a heterogeneous graph network and an edge-enhanced graph neural network, respectively, to align objects and entities through structured alignment mechanisms. Zhang et al. [
27] introduced a multimodal fusion model based on a syntactic dependency text graph and a fully connected visual graph to explore fine-grained semantic alignment across modalities. Furthermore, some approaches with novel perspectives have been proposed. For instance, Xu et al. [
28] introduced a general data partitioning strategy, using reinforcement learning to train a data discriminator that categorizes data into unimodal and multimodal groups for separate recognition tasks. Lu et al. [
29] developed a multimodal interaction transformer with interaction position labels for unified representation and used transformers for both intra-modal and cross-modal connections. Wang et al. [
30] introduced scene graphs as structured representations of visual content to enhance semantic interaction. Xu et al. [
31] proposed a matching and alignment framework to improve the consistency of multimodal representations in MNER. Furthermore, Jia et al. [
32,
33] leveraged external knowledge to introduce MRC-MNER and MNER-QG, facilitating cross-modal interactive reasoning.
In 2021, Zheng et al. [
34] were the first to introduce the MRE task and constructed a social media-related dataset. Since then, researchers have proposed various methods to optimize the relation extraction process. Chen et al. [
35] proposed a hierarchical visual prefix fusion network that enhances text representation using image features. Kang et al. [
36] introduced a novel translation-supervised prototype network for multimodal social relation extraction to capture triplet features. Huang et al. [
37] designed an internal module to learn single-instance representations and an external module to focus on diverse sample relationships. Zhao et al. [
38] introduced a two-stage visual fusion network that applies multimodal fusion to improve relation extraction. Liu et al. [
39] proposed a multi-granularity cross-modal transformer to model complex interactions between text, global images, and local visual objects. Lastly, Hu et al. [
40] supplemented existing information by retrieving external textual and visual evidence and integrating it to infer relationships between entities across different modalities.
Noting that the aforementioned studies have overlooked the modeling of group-level features and the optimization of fusion strategies, this paper focuses on these two aspects and proposes a novel approach to further enhance the performance of multimodal entity relation extraction. To further highlight the contributions of this study,
Table 1 presents a comparative analysis of representative works on MNER and MRE tasks, focusing on aspects such as task coverage, core models, main contributions, and limitations. Since the data types, datasets, and evaluation metrics are consistent across the studies, they are not elaborated here. The comparison reveals that previous studies predominantly adopt ResNet or BERT as their backbone models, whereas our work leverages VIT and Coref-BERT, which are better aligned with the characteristics of the tasks. Furthermore, our approach introduces a novel perspective by modeling group-level semantics and optimizing their integration strategy—addressing a key gap that has often been overlooked in prior research.
3. Materials and Methods
The proposed model for MNER and MRE tasks is illustrated in
Figure 2. It consists of five main components: (1) Text Encoder: Responsible for processing input text. This corresponds to the “Text Encoder” module in the figure. The “Text” in the figure represents the textual data we need to process. (2) Image Feature Extraction: Extracts image information and converts it into feature vectors. This corresponds to the “VIT” (Vision Transformer) module in the figure. The “Images” in the figure represent the image data we need to process. (3) Adaptive Module: Extracts group-level information and progressively refines visual features. This corresponds to the “Adaptive” module in the figure. The specific structure is discussed in the following sections. (4) Multimodal Feature Fusion: Effectively integrates visual features as a prefix into textual representations. This corresponds to the “Fusion Encoder” module in the figure. On the right side of the figure, a self-attention mechanism module is displayed. We apply a set of linear transformations to project the visual features into the same embedding space as the textual representations, obtaining the prefixes
and
, which correspond to the peach-colored and purple sections. (5) Final Task Prediction: Utilizes the fused multimodal information for MNER and MRE tasks. This architecture ensures effective cross-modal interaction, enhancing the model’s ability to capture entity relationships in social media data.
3.1. Task Definition
MNER: This is a sequence labeling task. Given a short text and its corresponding image as input, the task aims to identify entities within the sentence and assign each token in the sentence a predefined label type , following the BIO tagging scheme.
MRE: This is a multi-class classification task. Given a short text and its corresponding image as input, the task aims to extract the relationship between two entities and within the text, where represents all explicitly annotated entities in the text, and denotes a predefined relationship type.
3.2. Text Encoder
This paper employs the BERT variant CorefBERT [
41] as the text encoder. CorefBERT removes the Next Sentence Prediction (NSP) task from BERT and is trained solely on the Mention Reference Prediction (MRP) task. This allows it to focus more on learning contextual information and enhances its language representation capabilities. Additionally, CorefBERT incorporates enhanced designs in input embeddings and task-specific processing, particularly for entity and coreference information, making it well-suited for MNER and MRE tasks. Each input sentence is prepended with a [CLS] token and appended with a [SEP] token, represented as:
where
and
are inserted [CLS] and [SEP] tokens., and
to
represent the text sequence. Inspired by [
42], the first four layers of CorefBERT are initialized as the text encoder, processing
to obtain its final representation. The remaining eight layers of CorefBERT are dedicated to multimodal feature fusion, which is discussed in detail in
Section 3.5.
3.3. Image Feature Extraction
The images associated with the textual information consist of global images, which contain local image regions that provide relevant information about target entities. The global image serves as the background for local images, helping to recognize abstract expressions and acting as a weak learning signal.
Since the multi-scale visual features obtained from ResNet are relatively coarse and require pooling operations to align with transformer-based feature fusion, this paper adopts Vision Transformer (VIT) as the visual encoder. VIT stacks multiple layers of attention to learn high-dimensional features, allowing it to directly model relationships between any two regions within an image. This enables richer global semantic information extraction, making it advantageous for global feature representation.
However, due to its design, VIT initially struggles to focus on local features. To address this, this paper utilizes a Faster R-CNN model [
43] to extract the top m most salient local visual objects
. Next, both the global image
and the local images
are standardized to 224 × 224 pixels before being fed into VIT. These images are divided into 49 patches, and VIT processes them through 12 transformer blocks. Each block outputs a vector representation with different levels of semantic intensity, producing a hierarchical visual feature list
, as illustrated in
Figure 2. In this hierarchy, lower-indexed vectors (i.e., smaller
in
) capture high-resolution, spatially rich, but semantically weaker visual features. Conversely, higher-indexed vectors (larger
in
) capture low-resolution but semantically stronger visual features. The
specific representation is given as:
, where
is [CLS] token that represents the separator of all image information of each layer.
3.4. Adaptive Module
The adaptive module aims to obtain hierarchically matched visual features, which serve as input for multimodal feature fusion, enabling the model to understand multimodal data more effectively and accurately. This module consists of two key components: Group-Level Feature Extraction and Dynamic Gating Mechanism. As illustrated in
Figure 3, these components work together to refine and adapt the extracted visual features, ensuring they align properly with the text representations before fusion.
This paper maps the hierarchical visual feature list
to
as follows:
where
denotes the concatenation operation. The reshaping operation
transforms the concatenated hierarchical features into a tensor. Specifically, the 12-layer visual features are divided into 4 groups, where each group contains a mix of 3 layers of feature vectors, corresponding to a row in the reshaped tensor. Next,
layer is applied to reduce the dimensionality of the tensor, obtaining the final visual feature representation
,
is split into a group-level visual feature list:
, where
represents the visual feature of the
group.
Next, a dynamic gating mechanism is employed to map both hierarchical and group-level visual features onto the multimodal feature fusion module. The mapping weights are dynamically adjusted based on the visual features of the image. The dynamic gating module can be viewed as a path decision process, where the goal is to predict a normalized vector that represents the contribution of each visual feature block.
In the dynamic gating mechanism,
denotes the path probability from the
visual block to the
transformer layer. First, the gating signal
is generated as follows:
where:
is the
activation function,
is the
trainable weight matrix for the
layer,
represents the global average pooling function.
denotes the total number of visual feature blocks, which is 16 in this paper.
is the
visual feature block, specifically one of the global and m local features extracted from each transformer layer and group Specifically, one of the global features and m local features of each layer and each group
.
The probability vector for the
transformer layer
is then computed as follows:
Based on the probability vector
, the final weighted visual feature
is obtained through a weighted
sum of the visual features:
In summary, the final visual representation for the
transformer layer,
is constructed by combining both global and local features as follows:
3.5. Multi-Modal Feature Fusion
The visual features obtained in
Section 3.4 are incorporated as visual prefixes into each attention layer of CorefBERT’s text sequence, as shown on the right side of
Figure 2.
For the transformer layer, the visual gated feature and the transformer output serve as inputs. Here, the output of the transformer is denoted as , while the first transformer layer takes the text sequence as .
Given an input sequence
, the context representation
is projected into query (
Q), key (
K), and value (
V) vectors as follows:
where
,
, and
are the attention mapping parameters, which have the same dimensions as
.
,
, and
represent the query, key, and value vectors of the
layer, respectively.
Regarding the visual feature prefix, for the
transformer layer, a set of linear transformations
is applied to map them into the same embedding space as the text representations. The visual prompts
are defined as follows:
where
represents the length of the visual sequence, and
also denotes the number of detected visual objects.
Based on the visual prefix, the attention computation is defined as:
3.6. Classifier
In the multi-modal feature fusion module, we obtain the final hidden layer vector from the CorefBERT model. Let denote the attention operation based on the visual prefix. This paper uses different classifier layers for MNER and MRE tasks.
For MNER, we input the hidden representation into a CRF model to predict the probability of each token belonging to different label categories, resulting in the final prediction sequence
. The probability of a given label sequence
is computed as follows:
where
represents the length of the input text sequence,
is a potential function used to compute the path score,
denotes the label value at position
in the observation sequence, and
represents the predefined label set following the BIO tagging scheme.
The loss function is computed based on the probability of the predicted label sequence. The model parameters are optimized by minimizing the negative log-likelihood loss using maximum likelihood estimation:
where
is the number of samples,
represents the correct label sequence for the
sample,
is the final hidden layer vector obtained from the multi-modal feature fusion module for the
sample.
For MRE, we predict the relationship
between the head entity
and the tail entity
in sequence
. The final hidden layer representations of these two entities are denoted as
and
, respectively. The probability distribution over
relationship classes is computed as follows:
where
and
are trainable fine-tuning parameters.
4. Results and Discussions
4.1. Dataset
This paper conducts MNER experiments on the Twitter-2017 dataset [
9], which includes four entity types: Person (PER), Location (LOC), Organization (ORG), and Miscellaneous (MISC). The number of samples in the training, development, and test sets, as well as the distribution of each entity type, is shown in
Table 2.
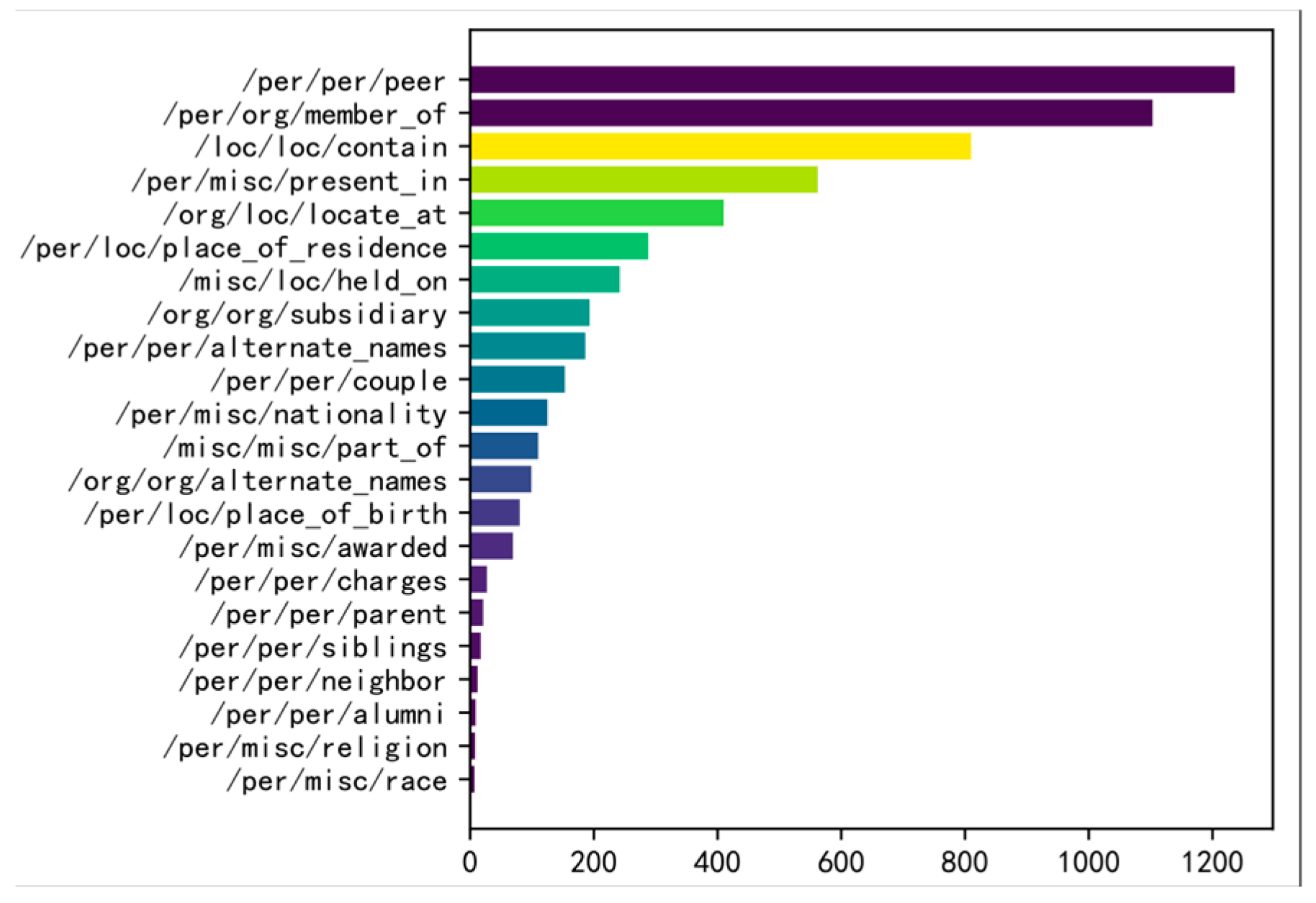
For the MRE experiment, we use the MNRE dataset [
34], which contains 23 relationship categories. The detailed distribution is shown in
Figure 4. The dataset is divided into 12,247 samples for training, 1624 for development, and 1614 for testing. Additional statistical information is provided in
Table 3.
Both datasets were collected from the Twitter social media platform, with each text segment corresponding to an image. However, it is important to note that not every image contains valid entity or relationship cues. The preprocessing steps for the Twitter-2017 and MNRE datasets in this paper consist of two main aspects. For text data: special characters were removed, abbreviations were expanded, and standard tokenization tools were used for word segmentation. For image data: all images were resized to a resolution of 224 × 224 and underwent normalization.
4.2. Experimental Setup and Evaluation Index
The proposed method was implemented using PyTorch 1.8.1 on an NVIDIA RTX 4090 GPU, with clip-vit-base-patch32 and coref-bert-base as encoders, where the hidden representation size was set to 768. The AdamW optimizer was employed for training. During the first 10% of gradient updates, the learning rate was gradually increased to its peak value using a linear warm-up strategy, followed by a linear decay for the remainder of the training process, with a decay rate set to 0.01. The batch size was set to 16, and the number of image objects was fixed at 3. For the MNER task, experiments were conducted with different learning rates in the range of [1 × 10−5, 3 × 10−5], with a maximum input sentence length of 128 and a total of 30 training epochs. For the MRE task, a fixed learning rate of 1 × 10−5 was used, with a maximum input sentence length of 80 and a total of 20 training epochs. The evaluation metrics employed in this study included Precision (P), Recall (R), and F1-score to ensure consistency with the evaluation criteria used in baseline methods.
4.3. Experimental Baseline and Results
To ensure a comprehensive comparison, this study selects previous state-of-the-art methods as baselines, categorized into three groups. The first category includes models that consider only textual input, such as BERT-CRF, CNN-BiLSTM-CRF [
44], PCNN [
45], and MTB [
10]. Specifically, CNN-BiLSTM-CRF utilizes BiLSTM and CNN for word- and character-level representations in named entity recognition, PCNN applies convolutional networks with piecewise pooling for relation extraction, and MTB is a BERT-based pre-trained model designed for relation extraction. The second category consists of large language models, including ChatGPT3.5 and GPT4. The third category includes multimodal input models, such as AdapCoAtt, UMT [
18], UMGF [
27], VisualBERT [
13], MEGA [
34], HVPNeT [
35], MAF [
31], ITA [
46], MRC-MNER [
32], MNER-QG [
33], and MKGformer [
8]. Among them, AdapCoAtt designs an adaptive co-attention network to explore visual information, UMT introduces a multimodal interaction module to obtain image-aware word representations, and UMGF constructs multimodal graphs for semantic alignment. VisualBERT leverages pre-trained multimodal models for text-image encoding and fusion, while MEGA develops a dual graph network for semantic consistency. HVPNeT mitigates the noise of irrelevant visual objects by exploring hierarchical visual features as insertable visual prefixes. MAF employs contrastive learning to achieve consistent representation, and ITA aligns image features to the text representation space so that the image modality primarily aids in disambiguation. MRC-MNER and MNER-QG incorporate machine reading comprehension queries to retrieve relevant visual information in the linguistic context. Finally, MKGformer utilizes a relevance-aware fusion module to reduce noisy information.
Table 4 presents all experimental results of this study compared with the baselines.
In
Table 4, it is evident that the overall performance of multimodal methods significantly outperforms text-based approaches. This further validates the necessity of incorporating image information into social media data. Social media texts are often short and contain a lot of omitted information, making it difficult for text-based features alone to fully express entities and their relationships. Images, however, provide additional contextual information, aiding the model in more accurately identifying entity types and inferring relationship types. Furthermore, from the trend in the F1 score improvement, it is clear that image information contributes more significantly to the relation extraction task, while the improvement in named entity recognition is more limited. This suggests that images primarily play a role in relation modeling, while text remains the primary source of information for entity recognition.
Additionally, although large-scale pretrained language models (PLMs) have shown excellent performance in natural language processing tasks, the experimental results indicate that directly using these large models yields only moderate results. This may be because PLMs are primarily trained for general text understanding and are not optimized for NER and RE tasks, especially lacking specific designs for cross-modal alignment. This further underscores the value of purpose-built multimodal models. Our approach better integrates image information through a hierarchical visual prefix, ensuring more consistent representations across modalities, thus improving the overall task performance.
Our method achieves the best performance on most metrics across both datasets, although it did not reach the highest accuracy. This phenomenon may be due to the query mechanism based on machine reading comprehension (MRC-MNER and MNER-QG), which allows for more precise localization of visual regions, thereby improving both cross-modal and within-modal relationship modeling. However, in terms of the F1 score, our method shows a 0.3% improvement on the MNER task and a 2.2% improvement on the MRE task, further validating the effectiveness of our approach. We attribute the successful results to factors such as group-level features, improvements in fusion methods, and the role of CorefBERT in text modeling. A detailed analysis is presented in the ablation study. In future improvements, the focus is on optimizing the multimodal fusion mechanism.
4.4. Ablation Experiment
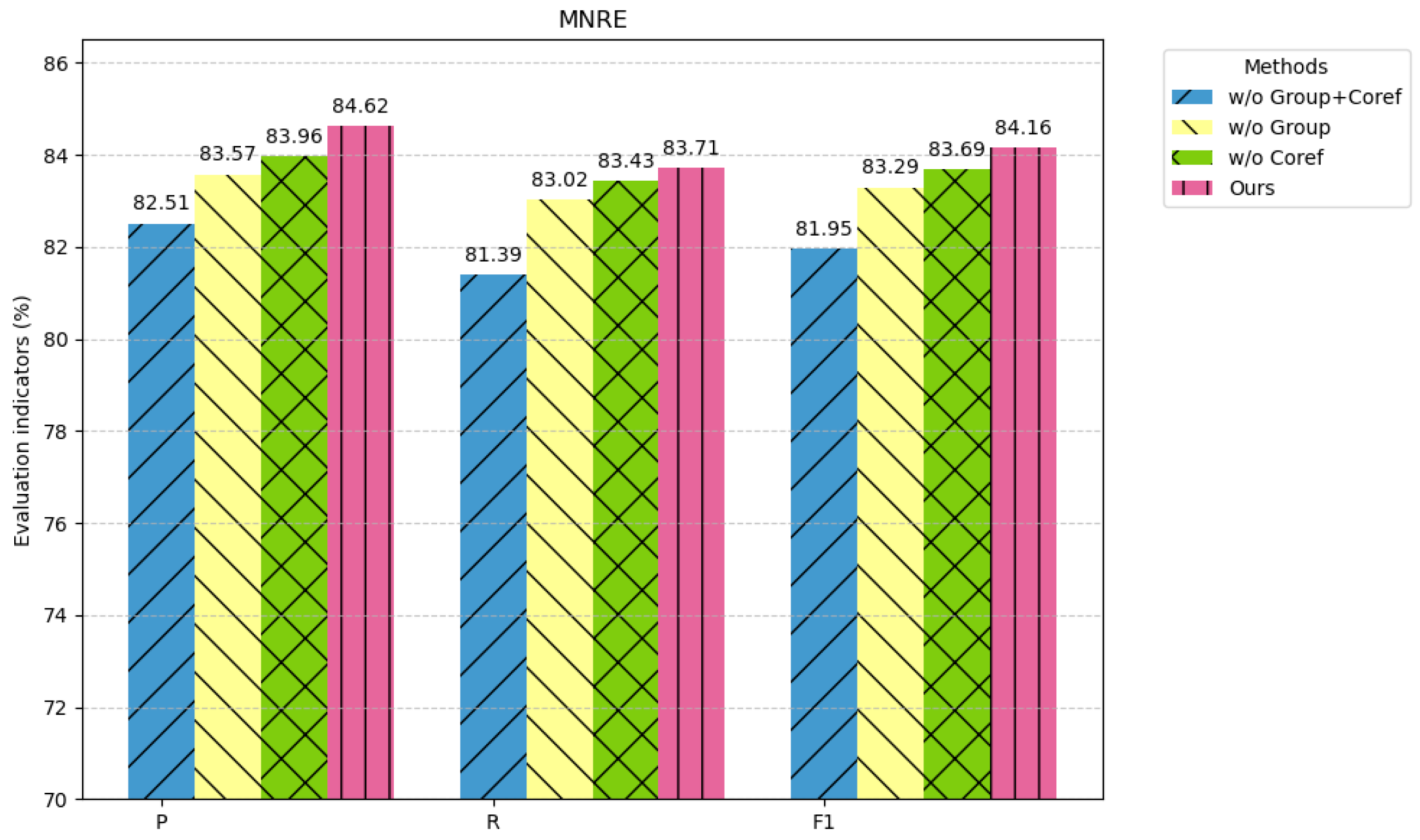
To validate the effectiveness of each module, three ablation experiments were conducted on the MNRE dataset, as illustrated in
Figure 5.
w/o Group: We removed the group-level information module and observed a significant decline in model performance. This indicates that the module plays a crucial role in enhancing image feature extraction efficiency and optimizing the utilization of visual information. Theoretically, the group-level information module helps capture higher-level semantic features from images, making visual representations more context-aware and semantically enriched. Its absence leads to a decreased ability to distinguish positive samples, ultimately affecting the recall rate. This phenomenon suggests that simple, single-source visual features may be insufficient for precise relation extraction. In contrast, the aggregation mechanism of group-level information can effectively reduce noise and improve the model’s discriminative capability.
w/o Coref: When we replaced Coref-BERT-Base with BERT-Base, the F1 score dropped by 0.47%. This result suggests that Coref-BERT exhibits greater robustness and adaptability in extracting textual features from social media data. The primary advantage of Coref-BERT lies in its ability to effectively model coreference resolution, thereby enhancing cross-sentence information capture. Social media text is often short and contains numerous coreference phenomena, such as pronouns (he/she/it) or omitted entity references. BERT-Base may struggle to establish global context across sentences when processing such data, whereas Coref-BERT, by strengthening coreference resolution capabilities, enables the model to more accurately understand relational structures within the text.
w/o Group + Coref: When both the group-level information module and CorefBERT were removed simultaneously, the precision (P) dropped by 2.11%, recall (R) decreased by 2.32%, and the F1 score declined by 2.21%. Such a severe performance degradation highlights the critical role of these two modules in the model. Moreover, their ability to collaborate effectively ensures optimal task performance.
4.5. Low Resource Scenario
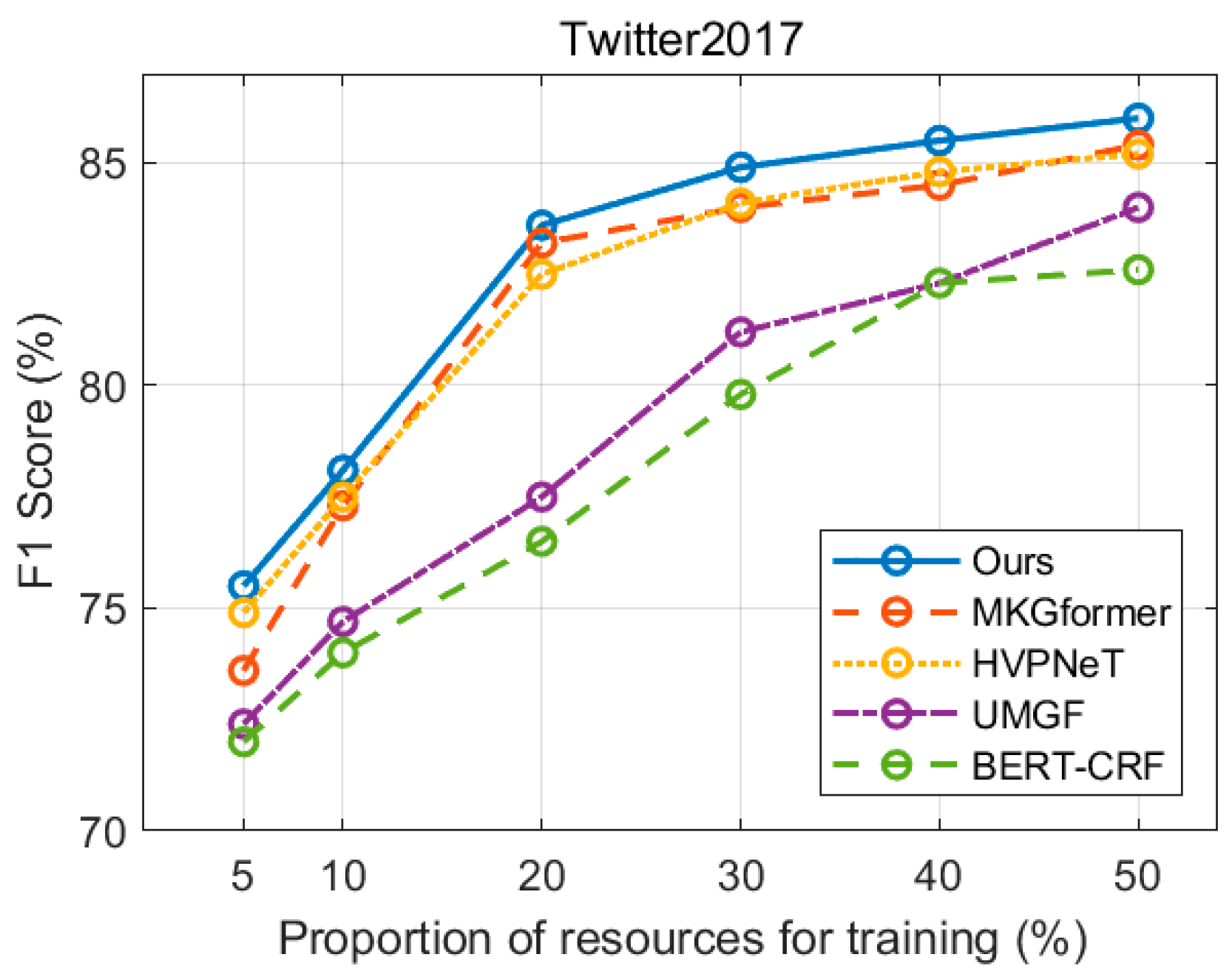
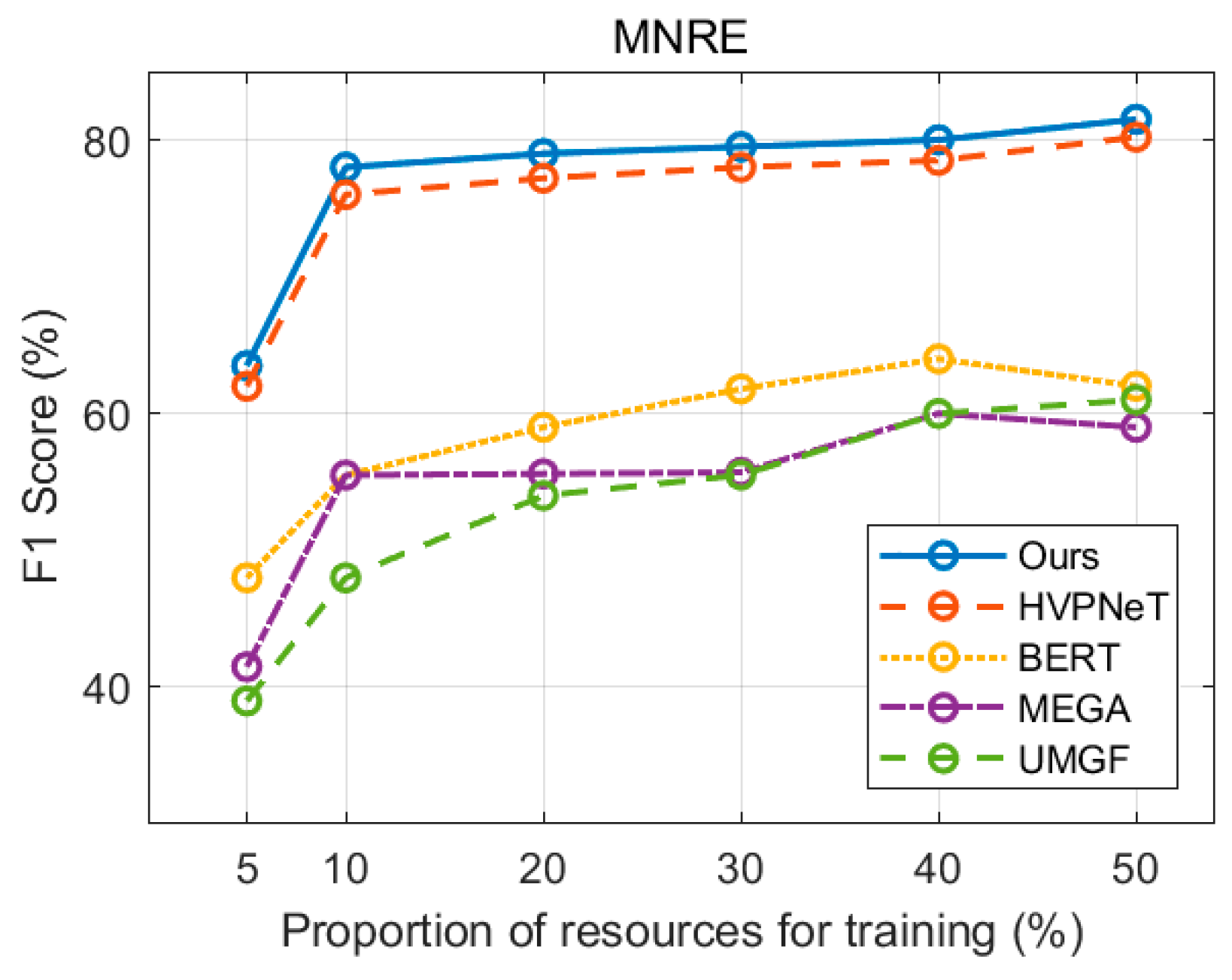
This section further evaluates the model’s performance in low-resource environments by randomly sampling between 5% and 50% of the original training data to create low-resource training sets.
Figure 6 presents the performance comparison of the proposed method with other baselines on the MNER task, while
Figure 7 illustrates the comparison on the MRE task.
First, it is evident that in low-resource scenarios, multimodal models consistently outperform text-only models, confirming that incorporating image information is beneficial for both named entity recognition and relation extraction tasks. Second, in the MRE task, the proposed method achieves a significant improvement over the HVPNeT model. This substantial performance boost is attributed to the approach of integrating visual information as a prefix into the transformer, which effectively mitigates modality differences. Finally, the results demonstrate that the proposed method outperforms other baselines across different low-resource settings. This further validates its effectiveness in leveraging multimodal data while reducing modality noise, ensuring more robust performance even with limited training samples.
4.6. Cross-Task Scenario
Table 5 presents a comparison of the generalization ability of the proposed method with other models in cross-task scenarios. The first section, Twitter2017-MNRE, refers to models trained on Twitter-2017 that are subsequently trained and tested on MNRE. The second section, MNRE-Twitter2017, indicates models trained on MNRE that are then further trained and tested on Twitter-2017.
From the second column, it can be observed that the proposed method achieves the highest F1 scores, with minimal fluctuation after cross-task adaptation, and even exhibits slight improvements. This is mainly because both datasets originate from the same source, and the MNER task not only enhances the model’s ability to represent entities but also leverages multimodal data to better locate entities. This, in turn, improves contextual understanding and reasoning, benefiting the subsequent MRE task.
In contrast, the third column shows a decline in performance after cross-task adaptation, though the results remain competitive. This decline occurs because MRE training is more focused on global relation modeling, which weakens the model’s ability to finely recognize entity boundaries and categories, leading to a performance drop when transferred to MNER.
Despite these variations, the proposed method consistently achieves strong F1 scores with minimal fluctuations in both transfer settings, demonstrating its robustness and effectiveness in cross-task adaptation.
4.7. Training Cost
To analyze computational complexity and extraction speed, we conducted statistical tests on the classic HVPNET model and the proposed method. The FLOPs of HVPNET are 33.4 GFLOPs, and the number of parameters is 138 M. The FLOPs of the proposed model are 60.5 GFLOPs, and the number of parameters is 203 M. Compared to HVPNET, our model has increased computational complexity and a higher parameter count, mainly due to the choice of visual encoder. HVPNET employs ResNet, which is based on a convolutional neural network with FLOPs of 4.1 GFLOPs. In contrast, our model utilizes VIT, which relies on a multi-head self-attention mechanism with approximately 17 GFLOPs, which results in significantly higher computational overhead. Additionally, ResNet has 25.6 M parameters, whereas VIT has 88 M, which increases the computational load for each forward and backward pass, thereby extending the training time.
Table 6 presents the training time for both models on the Twitter-2017 and MNRE datasets. Experimental results show that the average training time of our method is approximately 2.45 times that of HVPNET. Although the computational cost has increased, the model achieves improvements in accuracy and expressiveness, allowing it to better handle complex linguistic structures and diverse relationship types, thereby offering greater practical value and application potential.
4.8. Case Study
To provide a more intuitive comparison of the experimental results from different methods, this section selects several case studies from the MNER and MRE tasks for testing, as shown in
Table 7. The methods compared include the pure text method BERT-CRF, the latest high-performance multimodal method MEGA, and the proposed method.
In the MNER case, all three methods successfully recognized Entity 2, but only the proposed method was able to identify Entity 1, which can be attributed to the effectiveness of the group-level feature approach in utilizing image data.
In the first MRE case, it is evident that images can complement the textual information. The results show that the pure text method predicted the wrong relationship category, while both multimodal methods predicted it correctly, highlighting the necessity of adding image information for this task.
In the second MRE case, it is notable that the textual and image correlation is minimal. The pure text method correctly predicted the relationship semantically, but the MEGA method processed the image information as noise, interfering with the correct prediction of the relationship. However, the proposed method correctly predicted the relationship, further demonstrating its improvement in addressing modal noise and modality gaps.
5. Conclusions
To address the two major challenges of modality noise and modality gaps in existing methods for MNER and MRE tasks, this paper proposes a new model. The model efficiently performs image semantic representation and integrates both image and text information, thereby compensating for the limitations of traditional methods in terms of missing information and improving the accuracy of entity relation extraction results. However, a limitation of this method is its relatively high training cost. The model is based on the image encoder VIT from the CLIP model, which is trained on large-scale image-text pairs, and introduces group-level information to fully leverage image data and enhance the richness of spatial features. Through an adaptive module, the image information is incorporated as a prefix in each self-attention layer of the CorefBERT model, effectively reducing modality noise and simplifying the difficulty of cross-modal information fusion. This paper validates the effectiveness of the proposed method through ablation experiments and comparisons with standard datasets and other baseline models.
This method improves the accuracy of multimodal named entity recognition and multimodal relation extraction, thereby facilitating the automatic construction and optimization of knowledge graphs. In practical applications, the social media knowledge graph built based on this method can provide more precise semantic understanding and knowledge support for tasks such as public opinion analysis, public safety monitoring, and social recommendations. For example, in public opinion analysis, this method can more accurately identify key entities and their relationships in trending events, helping governments and businesses stay informed about public sentiment in real time and make timely decisions. In public safety monitoring, this method can detect abnormal behavior patterns on social platforms, assisting in tasks such as fraud warning and online violence management. In social recommendations, the method can uncover potential interest groups based on multimodal relationships between users and optimize information delivery strategies. Thus, this method holds significant potential value for practical applications.
For future work, we plan to explore and refine the model using datasets from other domains, with a focus on enhancing its adaptability to complex tasks. Additionally, we aim to extend this approach to knowledge graph construction and related areas, investigating the potential of cross-modal learning for building more comprehensive knowledge representations. This will contribute to the advancement of artificial intelligence in a broader range of applications. Furthermore, given the computational complexity of the model, we will explore strategies to optimize resource efficiency, such as model pruning, quantization, and knowledge distillation, to reduce training and inference costs. These optimizations will improve the model’s efficiency and feasibility for real-world deployment.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


