
Advancing Secret Sharing in 3D Models Through Vertex Index Sharing


Abstract
1. Introduction
- This paper proposes a novel approach to secret sharing in 3D models by utilizing vertex indices instead of traditional vertex coordinates, significantly enhancing embedding capacity and security.
- This study introduces the use of random perturbation combined with modular arithmetic to improve the security of model shares, effectively mitigating risks of unauthorized reconstruction and increasing robustness against potential attacks.
- By leveraging the small remainders of the Chinese Remainder Theorem and integrating them with the leading zero count (LZC) prediction technique, this paper presents a novel reversible data hiding method that allows for efficient data embedding and precise model reconstruction.
- The algorithm achieves a 100% embedding rate and offers a substantial improvement in embedding capacity compared to previous methods, enabling practical applications across diverse 3D models.
2. Related Work
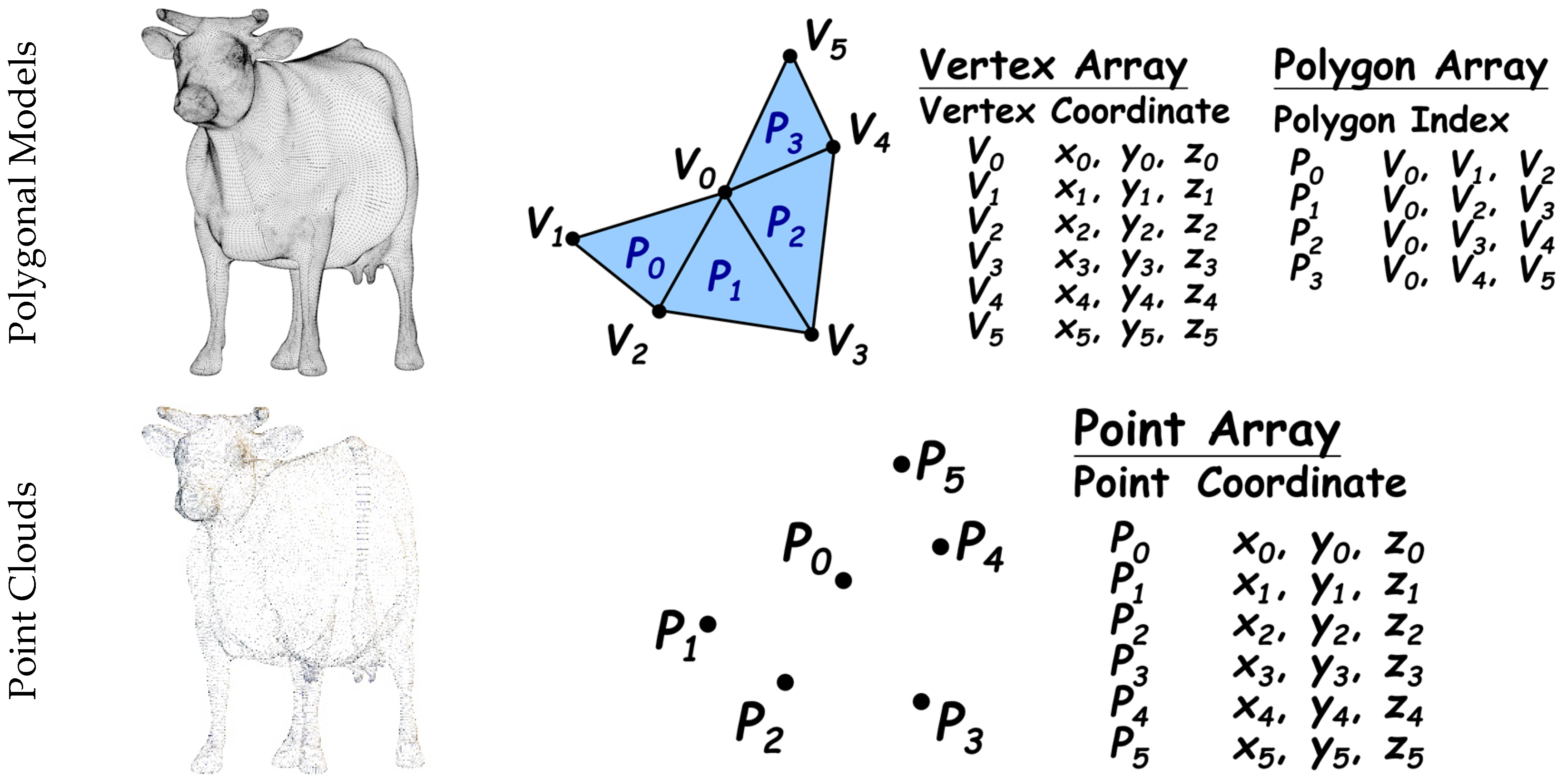
2.1. Three-Dimensional Model Representation
2.2. Secret Sharing Techniques Applied to 3D Models
2.3. Secret Sharing Based on the Chinese Remainder Theorem
2.4. Reversible Data Hiding in Encrypted Polygonal Faces Using Vertex Index Similarity
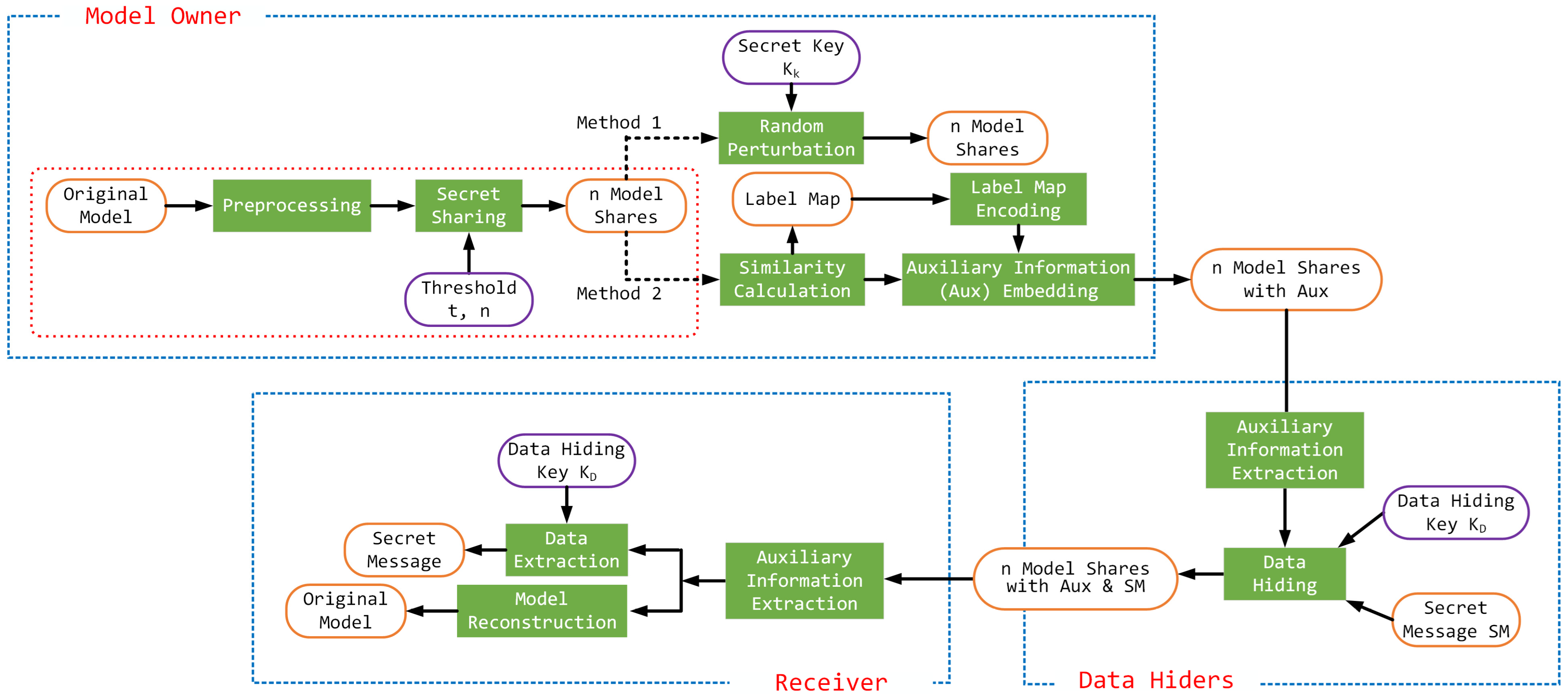
3. Proposed Algorithms
3.1. Vertex Index Value Sharing Technique Based on the Chinese Remainder Theorem
3.2. Vertex Index Sharing Technique with Enhanced Security
3.3. Reversible Data Hiding for Encrypted 3D Models with Enhanced Embedding Capacity
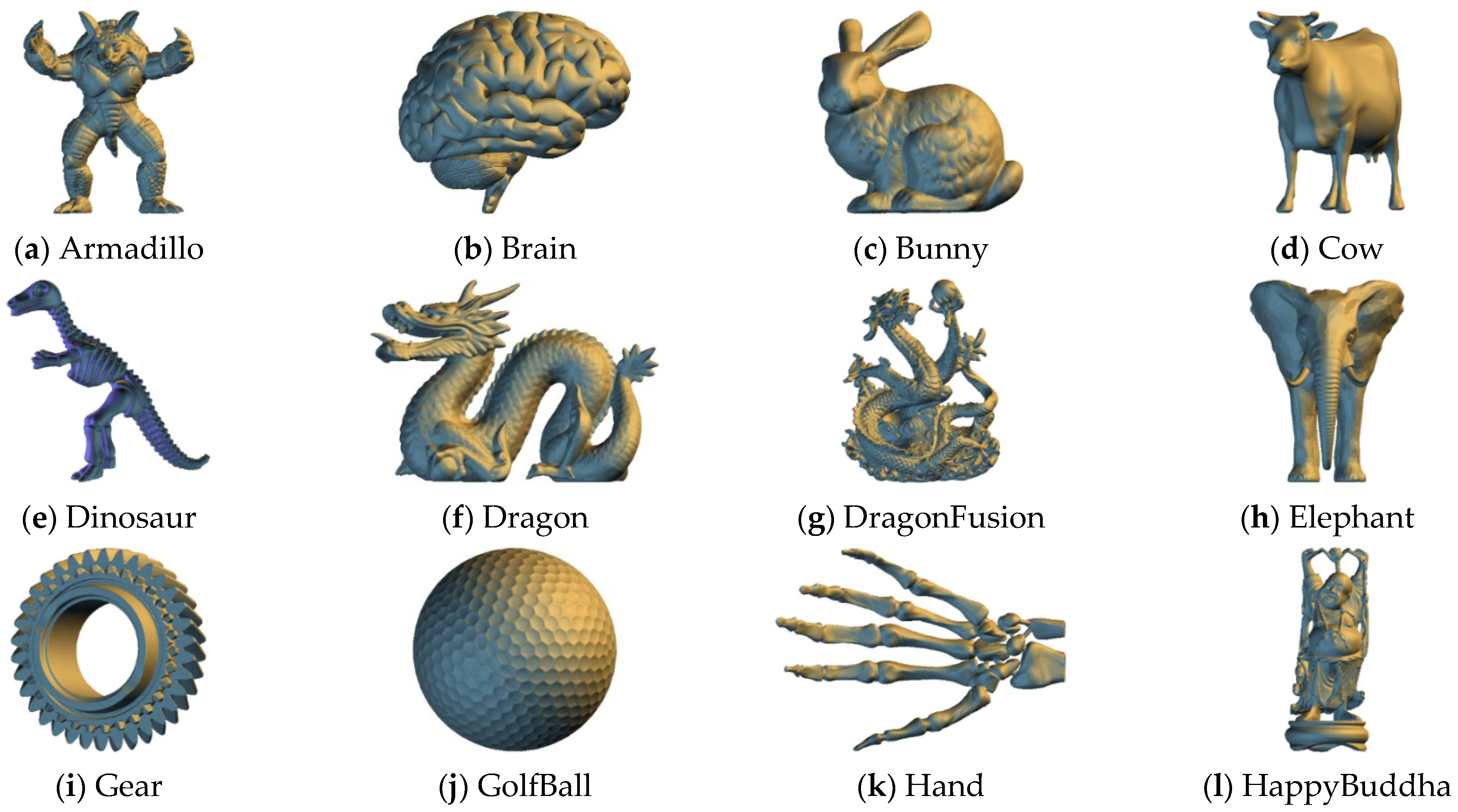
4. Experimental Results
4.1. Evaluation of Vertex Reference Before and After Index Adjustment
4.2. A Performance Evaluation of the Reversible Data Hiding Algorithm
4.3. Security Analysis
4.4. Time Complexity and Space Complexity Analysis
4.5. Algorithm Performance Comparison with Existing Algorithms
4.6. The Limitations of the Proposed Algorithm
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Blakley, G.R. Safeguarding Cryptography Keys. In Proceedings of the International Workshop on Managing Requirements Knowledge, New York, NY, USA, 4–7 June 1979; pp. 313–318. [Google Scholar]
- Shamir, A. How to Share a Secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Chen, B.; Lu, W.; Huang, J.; Weng, J.; Zhou, Y. Secret Sharing Based Reversible Data Hiding in Encrypted Images with Multiple Data-hiders. IEEE Trans. Dependable Secur. Comput. 2022, 19, 978–991. [Google Scholar] [CrossRef]
- Wang, R.; Yang, G.; Yan, X.; Luo, S.; Han, Q. Secret Image Sharing in the Encrypted Domain. J. Vis. Commun. Image Represent. 2024, 98, 104013. [Google Scholar] [CrossRef]
- Xiong, L.; Han, X.; Yang, C.-N.; Shi, Y.-Q. Reversible Data Hiding in Shared Images with Separate Cover Image Reconstruction and Secret Extraction. IEEE Trans. Cloud Comput. 2024, 12, 186–199. [Google Scholar] [CrossRef]
- Xiong, L.; Ding, R.; Yang, C.-N.; Fu, Z. Invertible Secret Image Sharing with Authentication for Embedding Color Palette Image into True Color Image. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 10987–10999. [Google Scholar] [CrossRef]
- Hou, G.; Ou, B.; Long, M.; Peng, F. Separable Reversible Data Hiding for Encrypted 3D Mesh Models Based on Octree Subdivision and Multi-MSB Prediction. IEEE Trans. Multimed. 2024, 26, 2395–2407. [Google Scholar] [CrossRef]
- Jiang, R.; Zhou, H.; Zhang, W.; Yu, N. Reversible Data Hiding in Encrypted Three-Dimensional Mesh Models. IEEE Trans. Multimed. 2018, 20, 55–67. [Google Scholar] [CrossRef]
- Lyu, W.-L.; Cheng, L.; Yin, Z. High-Capacity Reversible Data Hiding in Encrypted 3D Mesh Models Based on Multi-MSB Prediction. Signal Process. 2022, 201, 108686. [Google Scholar] [CrossRef]
- Tsai, Y.-Y. Reversible Data Hiding in Encrypted Polygonal Faces Using Vertex Index Similarity. IEEE Trans. Multimed. 2025. Accepted. [Google Scholar]
- Tsai, Y.-Y.; Jao, W.-T.; Lin, A.; Wang, S.-Y. Advanced Octree-based Reversible Data Hiding in Encrypted Point Clouds. J. Inf. Secur. Appl. 2025, 89, 104006. [Google Scholar] [CrossRef]
- Xu, N.; Tang, J.; Luo, B.; Yin, Z. Separable Reversible Data Hiding Based on Integer Mapping and MSB Prediction for Encrypted 3D Mesh Models. Cogn. Comput. 2022, 14, 1172–1181. [Google Scholar] [CrossRef]
- Yin, Z.; Xu, N.; Wang, F.; Cheng, L.; Luo, B. Separable Reversible Data Hiding Based on Integer Mapping and Multi-MSB Prediction for Encrypted 3D Mesh Models. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision, Beijing, China, 29 October–1 November 2021; pp. 336–348. [Google Scholar] [CrossRef]
- Beugnon, S.; Puech, W.; Pedeboy, J.-P. Format-Compliant Selective Secret 3-D Object Sharing Scheme. IEEE Trans. Multimed. 2019, 21, 2171–2183. [Google Scholar] [CrossRef]
- del Rey, A.M. A Multi-secret Sharing Scheme for 3D Solid Objects. Expert Syst. Appl. 2015, 42, 2114–2120. [Google Scholar] [CrossRef]
- Elsheh, E.; Hamza, A.B. Robust Approaches to 3D Object Secret Sharing. In Proceedings of the International Conference on Image Analysis and Recognition, Póvoa de Varzin, Portugal, 21–23 June 2010; pp. 326–335. [Google Scholar] [CrossRef]
- Elsheh, E.; Hamza, A.B. Secret Sharing of 3D Models Using Blakely Scheme. In Proceedings of the 25th Biennial Symposium on Communications, Kingston, ON, Canada, 12–14 May 2010; pp. 92–95. [Google Scholar] [CrossRef]
- Elsheh, E.; Hamza, A.B. Secret Sharing Approaches for 3D Object Encryption. Expert Syst. Appl. 2011, 38, 13906–13911. [Google Scholar] [CrossRef]
- Tsai, Y.-Y. A Secret 3D Model Sharing Scheme with Reversible Data Hiding Based on Space Subdivision. 3D Res. 2016, 7, 1. [Google Scholar] [CrossRef]
- Gao, K.; Horng, J.-H.; Chang, C.-C. Reversible Data Hiding for Encrypted 3D Mesh Models with Secret Sharing over Galois Field. IEEE Trans. Multimed. 2024, 26, 5499–5510. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Original Index Value | Moduli | Shared Index Value | Random Perturbation | Adjusted Index Value |
|---|---|---|---|---|
| 2897 | 67 | 16 | 3235 | 43,787 |
| 34,572 | 0 | 153,545 | 82,049 | |
| 154,925 | 21 | 98,496 | 26,241 |
| Shared Index Value | Moduli | Difference | Binary Representation | |
|---|---|---|---|---|
| 16 | 67 | 50 | 00000000000110010 | 11 |
| 0 | 66 | 00000000001000010 | 10 | |
| 21 | 45 | 00000000000101101 | 11 |
| Model Name | Length | Width | Height | Moduli 1 | Moduli 2 | Moduli 3 | Moduli 4 | ||
|---|---|---|---|---|---|---|---|---|---|
| Armadillo | 172,974 | 345,944 | 127.0002 | 151.3219 | 115.4285 | 59 | 61 | 67 | 71 |
| Brain | 294,012 | 588,032 | 641.227 | 560.885 | 529.196 | 71 | 73 | 79 | 83 |
| Bunny | 34,834 | 69,451 | 15.5699 | 15.43336 | 12.06733 | 37 | 41 | 43 | 47 |
| Cow | 46,433 | 92,864 | 11.49294 | 14.97753 | 23.9384 | 37 | 41 | 43 | 47 |
| Dinosaur | 56,194 | 112,384 | 11.6532 | 29.4042 | 34.7688 | 41 | 43 | 47 | 53 |
| Dragon | 437,645 | 871,414 | 409.7804 | 288.887 | 183.2436 | 79 | 83 | 89 | 97 |
| DragonFusion | 450,227 | 900,490 | 139.3779 | 178.9935 | 131.0554 | 79 | 83 | 89 | 97 |
| Elephant | 19,753 | 39,290 | 54.6444 | 71.66026 | 113.1929 | 29 | 31 | 37 | 41 |
| Gear | 250,000 | 500,000 | 93.4989 | 97.69596 | 58.25269 | 67 | 71 | 73 | 79 |
| GolfBall | 122,882 | 245,760 | 998.982 | 999.058 | 999.734 | 53 | 59 | 61 | 67 |
| Hand | 327,323 | 654,666 | 132.5423 | 92.84962 | 45.5031 | 71 | 73 | 79 | 83 |
| HappyBuddha | 543,652 | 1,087,716 | 203.305 | 495.0573 | 203.5445 | 83 | 89 | 97 | 101 |
| Horse | 48,485 | 96,966 | 8.4006 | 18.3342 | 15.2836 | 41 | 43 | 47 | 53 |
| Lion | 183,408 | 367,277 | 117.9447 | 64.13302 | 47.84499 | 59 | 61 | 67 | 71 |
| Rabbit | 67,038 | 134,074 | 29.724 | 34.754 | 70.7 | 43 | 47 | 53 | 59 |
| RockerArm | 40,177 | 80,354 | 40.396 | 23.816 | 78.464 | 37 | 41 | 43 | 47 |
| Screw | 44,511 | 89,018 | 41.35089 | 101.6667 | 91.5195 | 37 | 41 | 43 | 47 |
| Teeth | 116,604 | 233,204 | 35.452 | 13.579 | 26.054 | 53 | 59 | 61 | 67 |
| VenusBody | 19,847 | 43,357 | 131.7964 | 456.6276 | 132.3554 | 29 | 31 | 37 | 41 |
| VenusHead | 134,345 | 268,686 | 13.8224 | 19.8152 | 19.8676 | 53 | 59 | 61 | 67 |
| Model Name | Before Adjustment | After Adjustment | ||||||
|---|---|---|---|---|---|---|---|---|
| Share 1 | Share 2 | Share 3 | Share 4 | Share 1 | Share 2 | Share 3 | Share 4 | |
| Armadillo | 0.25% | 0.24% | 0.26% | 0.24% | 99.97% | 99.97% | 99.96% | 99.96% |
| Brain | 0.24% | 0.24% | 0.24% | 0.25% | 99.98% | 99.98% | 99.97% | 99.97% |
| Bunny | 0.29% | 0.23% | 0.29% | 0.26% | 99.90% | 99.89% | 99.88% | 99.87% |
| Cow | 0.25% | 0.24% | 0.24% | 0.26% | 99.92% | 99.91% | 99.91% | 99.90% |
| Dinosaur | 0.27% | 0.23% | 0.27% | 0.26% | 99.93% | 99.93% | 99.92% | 99.91% |
| Dragon | 0.25% | 0.25% | 0.26% | 0.26% | 99.98% | 99.98% | 99.98% | 99.98% |
| DragonFusion | 0.26% | 0.24% | 0.25% | 0.25% | 99.98% | 99.98% | 99.98% | 99.98% |
| Elephant | 0.27% | 0.26% | 0.29% | 0.23% | 99.86% | 99.85% | 99.82% | 99.80% |
| Gear | 0.24% | 0.25% | 0.26% | 0.26% | 99.97% | 99.97% | 99.97% | 99.97% |
| GolfBall | 0.24% | 0.23% | 0.23% | 0.27% | 99.96% | 99.95% | 99.95% | 99.95% |
| Hand | 0.26% | 0.24% | 0.25% | 0.25% | 99.98% | 99.98% | 99.98% | 99.97% |
| HappyBuddha | 0.24% | 0.25% | 0.25% | 0.25% | 99.98% | 99.98% | 99.98% | 99.98% |
| Horse | 0.21% | 0.24% | 0.26% | 0.24% | 99.92% | 99.91% | 99.91% | 99.89% |
| Lion | 0.23% | 0.25% | 0.23% | 0.23% | 99.97% | 99.97% | 99.96% | 99.96% |
| Rabbit | 0.23% | 0.27% | 0.23% | 0.23% | 99.94% | 99.93% | 99.92% | 99.91% |
| RockerArm | 0.30% | 0.20% | 0.26% | 0.23% | 99.91% | 99.90% | 99.90% | 99.89% |
| Screw | 0.27% | 0.23% | 0.27% | 0.27% | 99.92% | 99.91% | 99.91% | 99.90% |
| Teeth | 0.23% | 0.24% | 0.24% | 0.24% | 99.96% | 99.95% | 99.95% | 99.94% |
| VenusBody | 0.17% | 0.18% | 0.13% | 0.19% | 99.86% | 99.85% | 99.82% | 99.80% |
| VenusHead | 0.24% | 0.25% | 0.24% | 0.26% | 99.96% | 99.96% | 99.96% | 99.95% |
| Average | 0.25% | 0.24% | 0.25% | 0.25% | 99.94% | 99.94% | 99.93% | 99.92% |
| Model Name | TEC | AUX | ATEC | AAUX | APEC | |
|---|---|---|---|---|---|---|
| ER | Tree | |||||
| Armadillo | 13,419,623 | 2,208,627 | 149 | 38.79 | 6.38 | 32.41 |
| Brain | 24,085,626 | 4,112,443 | 167 | 40.96 | 6.99 | 33.97 |
| Bunny | 2,393,290 | 482,329 | 125 | 34.46 | 6.95 | 27.51 |
| Cow | 3,200,166 | 644,962 | 125 | 34.46 | 6.95 | 27.51 |
| Dinosaur | 3,830,170 | 769,799 | 125 | 34.08 | 6.85 | 27.23 |
| Dragon | 36,353,170 | 6,324,203 | 167 | 40.37 | 7.02 | 33.35 |
| DragonFusion | 35,179,424 | 6,119,943 | 167 | 40.37 | 7.02 | 33.35 |
| Elephant | 1,272,673 | 254,591 | 110 | 32.39 | 6.48 | 25.91 |
| Gear | 19,115,847 | 3,422,898 | 159 | 38.23 | 6.85 | 31.39 |
| GolfBall | 8,868,737 | 1,548,243 | 137 | 36.09 | 6.30 | 29.79 |
| Hand | 26,815,355 | 4,578,896 | 167 | 40.96 | 6.99 | 33.97 |
| HappyBuddha | 46,891,136 | 7,541,505 | 175 | 43.11 | 6.93 | 36.18 |
| Horse | 3,304,680 | 664,150 | 125 | 34.08 | 6.85 | 27.23 |
| Lion | 14,247,253 | 2,344,883 | 149 | 38.79 | 6.38 | 32.41 |
| Rabbit | 4,925,408 | 889,300 | 132 | 36.74 | 6.63 | 30.10 |
| RockerArm | 2,769,093 | 558,169 | 125 | 34.46 | 6.95 | 27.51 |
| Screw | 3,067,731 | 618,326 | 125 | 34.46 | 6.95 | 27.51 |
| Teeth | 8,415,358 | 1,468,935 | 137 | 36.09 | 6.30 | 29.79 |
| VenusBody | 1,404,520 | 281,270 | 110 | 32.39 | 6.49 | 25.90 |
| VenusHead | 10,502,198 | 1,692,781 | 144 | 39.09 | 6.30 | 32.79 |
| Average | 13,503,073 | 2,326,313 | 141 | 37.02 | 6.73 | 30.29 |
| Model Name | Original Model | Method 1 | Method 2 |
|---|---|---|---|
| Adjusted Sharing Model | Data-Embedded Sharing Model | ||
| Armadillo | 0.9815 | 0.0169 | 0.0463 |
| Brain | 0.9665 | 0.0174 | 0.0434 |
| Bunny | 0.9821 | 0.0197 | 0.0528 |
| Cow | 0.9926 | 0.0175 | 0.0541 |
| Dinosaur | 0.9705 | 0.0175 | 0.0511 |
| Dragon | 0.9896 | 0.0175 | 0.0505 |
| DragonFusion | 0.9628 | 0.0164 | 0.0524 |
| Elephant | 0.9419 | 0.0191 | 0.0501 |
| Gear | 0.9814 | 0.0169 | 0.0371 |
| GolfBall | 0.9979 | 0.0168 | 0.0386 |
| Hand | 0.9905 | 0.0173 | 0.0410 |
| HappyBuddha | 0.9805 | 0.0172 | 0.0572 |
| Horse | 0.9851 | 0.0174 | 0.0596 |
| Lion | 0.9769 | 0.0160 | 0.0468 |
| Rabbit | 0.9941 | 0.0168 | 0.0516 |
| RockerArm | 0.9880 | 0.0208 | 0.0500 |
| Screw | 0.9854 | 0.0159 | 0.0524 |
| Teeth | 0.9888 | 0.0171 | 0.0402 |
| VenusBody | 0.9284 | 0.0109 | 0.0368 |
| VenusHead | 0.9930 | 0.0165 | 0.0385 |
| Average | 0.9789 | 0.0171 | 0.0475 |
| Algorithms | [20] | [7] | [9] | [13] | [11] | [10] | Proposed |
|---|---|---|---|---|---|---|---|
| Embedding Elements | Vertex | Polygon | |||||
| Embedding Method | multi-MSB Prediction Bit Substitution | LZC and multi-MSB Prediction Bit Substitution | LZC Prediction Bit Substitution | ||||
| Embedding Rate | 70.16% | 98.56% (Ts = 2, 4, 6) 92.38% (Ts = 8) | 49.65% | 27.48% | 100% | 100% | 100% |
| Embedding Capacity | 30.18 bpv | 30.68 (Ts = 2, 4, 6) 35.10 (Ts = 8) bpp | 21.31 bpv | 7.82 bpv | 31.54 (Ts = 2, 4, 6) 39.76 (Ts = 8) bpp | 32.63 bppo | 30.29 bppo |
| Number of Data Hiders | Multiple | One | One | One | One | One | Multiple |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, Y.-Y.; Jhou, J.-Y.; You, T.-Y.; Lu, C.-T. Advancing Secret Sharing in 3D Models Through Vertex Index Sharing. Electronics 2025, 14, 1675. https://doi.org/10.3390/electronics14081675
Tsai Y-Y, Jhou J-Y, You T-Y, Lu C-T. Advancing Secret Sharing in 3D Models Through Vertex Index Sharing. Electronics. 2025; 14(8):1675. https://doi.org/10.3390/electronics14081675
Chicago/Turabian StyleTsai, Yuan-Yu, Jyun-Yu Jhou, Tz-Yi You, and Ching-Ta Lu. 2025. "Advancing Secret Sharing in 3D Models Through Vertex Index Sharing" Electronics 14, no. 8: 1675. https://doi.org/10.3390/electronics14081675
APA StyleTsai, Y.-Y., Jhou, J.-Y., You, T.-Y., & Lu, C.-T. (2025). Advancing Secret Sharing in 3D Models Through Vertex Index Sharing. Electronics, 14(8), 1675. https://doi.org/10.3390/electronics14081675