Abstract
Secret sharing is a robust data protection technique that secures sensitive information by partitioning it into multiple shares, such that the original data can only be reconstructed when a sufficient number of shares are combined. While this method has seen remarkable progress in the realm of images, its exploration and application in 3D models remain in their early stages. Given the growing prominence of 3D models in multimedia applications, ensuring their security and privacy has emerged as a critical area of research. At present, secret sharing approaches for 3D models predominantly rely on the vertex coordinates of the model as the basis for embedding and reconstructing secret messages. However, due to the limited quantity of vertex coordinates, these methods face significant constraints in embedding capacity, thereby limiting the potential of 3D models in secure data sharing. In contrast, the vertex indices of polygons, characterized by higher information density and greater structural flexibility, present a promising alternative medium for embedding secret shares. Building on this premise, the present study investigates the feasibility of leveraging shared vertex indices as a foundation for message embedding. It highlights the advantages of this approach in enhancing both the embedding capacity and the overall security of 3D models. By integrating the Chinese Remainder Theorem into vertex index-based sharing, the proposed method strengthens existing algorithms, offering improved model protection and enhanced embedding security. Experimental evaluations reveal that, compared to traditional vertex coordinate-based methods, incorporating vertex indices into secret sharing techniques significantly increases embedding efficiency while bolstering the security of 3D models. This study not only introduces an innovative approach to safeguarding 3D model data but also paves the way for the broader application of secret sharing techniques in the future.
1. Introduction
With the rapid advancement of technology, the digital world has become intricately intertwined with our daily lives, making the exchange of information over the internet a cornerstone of modern communication. From social media and email to virtual meetings, the efficiency and convenience of digital information transmission have not only strengthened interpersonal connections but also significantly enhanced interactions in business and education. However, the internet is an open platform, where any data transmitted are susceptible to interception or tampering by third parties. Consequently, safeguarding confidential information against disclosure and misuse has become an urgent and essential priority.
Encryption algorithms transform information into a format that is difficult to decipher, ensuring that only recipients with the correct secret key can access the original content. This approach not only effectively prevents unauthorized access but also safeguards data against forgery and tampering during transmission, forming the cornerstone of confidentiality and data integrity. As highlighted, the secret key is an indispensable core element of encryption, playing a critical role in both the encryption and decryption processes to uphold the security of information. In symmetric encryption systems in particular, the confidentiality of the secret key is directly tied to the security of the entire mechanism. If the secret key is compromised, the encryption framework becomes ineffective. Thus, the secure generation, distribution, and storage of secret keys is a crucial area of research that demands focused attention.
Secret sharing [1,2] is an effective mechanism for safeguarding secret keys by dividing them into multiple shares, which are distributed among different participants. The complete secret key can only be reconstructed when enough shares are combined. This design minimizes the risk of a single key being rendered inoperable due to attacks; even if some shares are leaked or lost, the key remains resistant to compromise. Such a technique is particularly well suited for distributed systems and scenarios demanding high security. Beyond protecting cryptographic secret keys, secret sharing is also applicable to the decentralized storage of sensitive data, such as financial transaction records, medical data, or confidential corporate documents. By leveraging this technology, even if an attacker gains access to some shares, reconstructing the complete original data remains infeasible. Moreover, by integrating dynamic threshold management to adjust the number of required participants, the technique can adapt to evolving security needs, demonstrating exceptional flexibility and practicality.
Images, as a prevalent and significant form of digital media, often contain personal privacy or commercial secrets, necessitating stringent protective measures when required. In image applications, secret sharing technology [3,4,5,6] divides an image into multiple shares, where each share alone cannot reconstruct the original image. Only when the threshold number of shares is reached can the complete image be restored. This technique is widely employed in image encryption and privacy protection, such as by splitting and distributing images across multiple servers to enhance data security and reliability, or in image authentication by combining with fragile watermarking techniques to detect tampering. As a result, secret sharing effectively enhances the confidentiality of images while ensuring data integrity and availability. In recent years, with substantial advancements in software and hardware capabilities, 3D models have become widely used in fields such as virtual reality, augmented reality, architectural design, game development, medical imaging, and industrial manufacturing. Their high precision and visual characteristics allow complex data to be presented intuitively, greatly improving design and communication efficiency. However, the data within 3D models also face risks of leakage and misuse. Thus, developing effective methods [7,8,9,10,11,12,13] to safeguard the confidentiality and privacy of 3D models has emerged as a critical research challenge.
Existing secret sharing techniques applied to 3D models [14,15,16,17,18,19], including encrypted 3D models [20], primarily utilize vertex coordinate data to generate shares for implementing secret sharing applications. While these methods enhance the security of 3D models to a certain extent, their scope of application and data embedding capacity are significantly constrained by the limited quantity of vertex information. Typically, in polygon-based 3D models, the number of polygons far exceeds the number of vertices. Consequently, vertex indices, which form the structural foundation of polygons, offer greater potential as a new medium for secret sharing. Vertex indices [10] not only provide an extensive quantity of data but also exhibit stability and consistency within the structure of polygonal models. This characteristic enables them to preserve the integrity of the model while offering an expanded capacity for data embedding.
In light of this, the present study focuses on advancing the application of secret sharing techniques in 3D models by exploring the feasibility and advantages of utilizing vertex indices for secret sharing. As core elements that define the geometric structure of polygonal models, vertex indices are abundant and increase proportionally with the number of polygons, making them an ideal candidate for enhancing the data embedding capacity of secret sharing techniques. This paper proposes two effective vertex index sharing mechanisms based on the Chinese Remainder Theorem. One is to enhance the model security, and the other is to enhance the embedding capacity. Experimental results demonstrate that the proposed algorithms outperform traditional vertex-coordinate-based reversible data hiding techniques in multiple aspects. Specifically, the security-enhancing mechanism leverages the inherent modular arithmetic of the Chinese Remainder Theorem with random perturbation to introduce a higher level of robustness against unauthorized reconstruction, effectively mitigating potential security threats. Meanwhile, the embedding-capacity-enhancing mechanism exploits the abundance of vertex indices to achieve a significant increase in the amount of data that can be securely embedded without compromising the geometric integrity of the model. Comparative analysis highlights that the proposed methods not only provide superior performance in terms of embedding capacity and security but also maintain computational efficiency, making them highly practical for real-world applications. These findings underscore the potential of vertex index-based secret sharing as a transformative technique for advancing the state of the art in 3D data security.
The principal contributions of this paper are multifaceted:
- This paper proposes a novel approach to secret sharing in 3D models by utilizing vertex indices instead of traditional vertex coordinates, significantly enhancing embedding capacity and security.
- This study introduces the use of random perturbation combined with modular arithmetic to improve the security of model shares, effectively mitigating risks of unauthorized reconstruction and increasing robustness against potential attacks.
- By leveraging the small remainders of the Chinese Remainder Theorem and integrating them with the leading zero count (LZC) prediction technique, this paper presents a novel reversible data hiding method that allows for efficient data embedding and precise model reconstruction.
- The algorithm achieves a 100% embedding rate and offers a substantial improvement in embedding capacity compared to previous methods, enabling practical applications across diverse 3D models.
This paper is organized as follows: Section 2 provides a thorough review of the literature to frame the research context. Section 3 delves into the methodology of the proposed algorithm. Section 4 presents the experimental results and analyzes the performance. Section 5 concludes this paper with a summary of the findings and suggestions for future research.
2. Related Work
This section presents the fundamental knowledge required to accomplish this study, including the representation methods of 3D models, the current state of development of secret sharing techniques applied to 3D models, and secret sharing based on the Chinese Remainder Theorem. Finally, the first and only reversible data hiding in encrypted polygonal faces is introduced.
2.1. Three-Dimensional Model Representation
Three-dimensional models are digital representations of the geometric shape of objects, widely used in various fields such as virtual reality, augmented reality, game design, industrial design, medical imaging, geographic information systems, and autonomous driving. Common methods of representing 3D models mainly include polygonal models and point clouds, each with their own characteristics suited to different scenarios and requirements.
Polygonal models are the most commonly used representation in 3D modeling. They consist of vertices and polygons, typically expressed as triangular meshes that represent the surface of an object. Polygonal models are highly structured, capable of accurately describing an object’s geometry, and support operations like texture mapping, lighting calculations, and physical simulations. Their high rendering efficiency makes them the primary choice for applications such as game design, film animation, industrial design, and architectural visualization. Moreover, polygonal models are supported by various editing and processing tools, such as Blender, 3ds Max, and Maya, as well as rendering engines like Unity and Unreal Engine, enabling the creation of sophisticated 3D scenes.
Point clouds, on the other hand, are composed of a large number of discrete points scattered in 3D space. Each point carries geometric position information and sometimes additional attributes, such as color or normal vectors. Point clouds are typically generated by laser scanning devices or depth cameras, capturing the real-world geometry of objects or scenes with high precision. They are particularly suitable for tasks like digital preservation and 3D reconstruction. The distinctive feature of point clouds lies in their ability to represent raw, high-accuracy data, though their large data size and lack of structured organization pose challenges for subsequent processing. As a result, point clouds are extensively applied in fields requiring precise measurement and analysis, such as terrain mapping, archaeology, medical imaging, and autonomous driving, in which they support tasks like environment sensing and obstacle detection.
Polygonal models and point clouds each have their strengths and challenges. Polygonal models dominate in applications focused on visual effects and interactivity, owing to their well-established tools and structured nature, while point clouds excel in fields requiring detailed measurements and high precision. With advances in computer graphics and artificial intelligence, the integration and transformation between these two representations are becoming increasingly common. For instance, converting point clouds to polygonal meshes enhances rendering effects, while generating point cloud data from polygonal models facilitates tasks like measurement and analysis. This interplay broadens the scope of applications for both representations, creating new opportunities across multiple domains. Their structural differences and visual representations are illustrated in Figure 1.
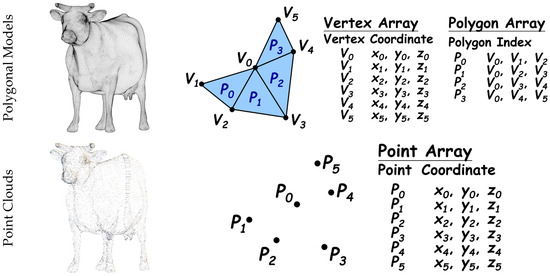
Figure 1.
Representations for polygonal models and point clouds.
2.2. Secret Sharing Techniques Applied to 3D Models
Elsheh and Hamza [16] extended the secret sharing techniques proposed by Shamir and Blakley to applications involving 3D models. Their approach begins by compressing 3D models using two lossless compression methods: Huffman coding and ZLIB. The authors extract values sequentially from the compressed data to replace the coefficients of each term in the polynomial equations used in the -threshold secret sharing mechanism. These coefficients are then used to calculate shares, which are distributed among participants, thus completing the sharing process. For decryption, any shares are sufficient to reconstruct the original polynomial coefficients using Lagrange interpolation. The resulting coefficients restore the compressed version of the 3D model, which is subsequently decompressed to retrieve the original model. Blakley’s secret sharing method [17], also a -threshold scheme, employs a different interpretation. It operates within a -dimensional space, where any non-parallel hyperplanes from a total of hyperplanes () intersect at a single point, which represents the secret. Elsheh and Hamza [18] adapted this approach by incorporating vertex and polygonal data from 3D models into the equations defining the hyperplanes. After computing hyperplanes, they distribute them among the participants. For decryption, collecting any non-parallel hyperplanes is sufficient to solve for their intersection point, thereby extracting secret information.
De Rey [15] proposed a secret sharing scheme designed for the sharing of multiple physical objects, utilizing a specific type of finite state machine—3D cellular automata—based on an -threshold mechanism, where all participants are required to reconstruct the shared secret. This method is particularly notable for its application to physical 3D objects rather than polygonal models, providing a more practical solution for industries that demand precise dimensional representation, such as medical imaging and manufacturing. The secret sharing process consists of three phases. During the setup phase, the initial configuration of the system is established. In the sharing phase, secret shares are generated and distributed to the participants. Finally, in the reconstruction phase, the participants collaborate to reconstruct the shared secret. Experimental results confirmed the robustness of this technique, as statistical analysis and differential attack tests demonstrated a low correlation between neighboring positions and a balanced distribution of state changes. These attributes significantly enhance the system’s resistance to potential cryptographic attacks, making it a reliable and secure approach for precise 3D data sharing.
Tsai [19] proposed a secret sharing technique for 3D point clouds based on spatial partition, extending its application to reversible data hiding. This technique begins by reading all the vertices of the point clouds and identifying its boundary vertices to establish a bounding volume. Each vertex’s coordinate values are then encoded into a series of integers. Additionally, the number of vertices required in the cover model for embedding the secret point cloud is calculated. Using these encoded values as parameters, they replace the coefficients in a -degree polynomial used for secret sharing, generating shares for each participant. During the cover model expansion phase, surface reconstruction and sampling techniques are applied to increase the vertex number and complexity of the cover model, enabling the embedding of the shares. Finally, the shares are embedded into the corresponding cover model, creating disguised models for each participant. This technique simplifies the processing of vertex coordinate values from real number operations to integer operations through spatial partitioning-based encoding, significantly reducing computational complexity. By integrating data-hiding algorithms, this technique enhances the confidentiality of the shares. Furthermore, the use of surface reconstruction and sampling methods effectively increases the vertex number of the cover model. The final layer of encoding in the cover model is retained, enabling reversibility and demonstrating the innovative value and practical potential of combining point cloud secret sharing with data hiding techniques.
Beugnon et al. [14] proposed an innovative format-compliant selective secret sharing mechanism for 3D objects, which allows the data to retain its original file format even after processing or modification. This mechanism employs selective encryption techniques, encrypting only the critical parts of a 3D object. This approach protects sensitive information while preserving the openness of other parts of the data, enabling quick access and real-time processing. By precisely modifying specific bits of the vertices in the 3D object, this method not only effectively safeguards visual content but also introduces controllable geometric distortions. The extent of these distortions is adjusted by a degradation level set during the initial stages of the sharing process. To reconstruct the original 3D object, at least out of shared 3D objects must be combined. This process eliminates the geometric distortions introduced by encryption and restores the object to its original 3D form.
To enhance the robustness of encrypted 3D models, Gao et al. [20] integrated a secret sharing technique with various innovative methods, significantly improving embedding rates and embedding capacity. The authors first adopted an adaptive vertex clustering strategy, grouping vertices based on their spatial structure. This effectively reduced the reliance on reference vertices, increasing the number of embeddable vertices. By applying a multiple most significant bit (multi-MSB) prediction technique, they maximized the embedding capacity for each embeddable vertex while recording the auxiliary information necessary for data extraction and model reconstruction. To minimize the amount of auxiliary information transmission, the authors further compressed the auxiliary information using Huffman coding, creating additional space for subsequent data embedding. To safeguard the confidentiality of the model content, the technique incorporated secret sharing based on Galois fields, dividing the compressed coordinate values into multiple encrypted shares. This ensured that the model could still be reconstructed even if some shares were lost. Experimental results demonstrated that this method outperformed existing techniques in both embedding rate and embedding capacity, offering an efficient and robust solution for data hiding and protection in encrypted 3D models.
2.3. Secret Sharing Based on the Chinese Remainder Theorem
The Chinese Remainder Theorem is a classical mathematical principle used to solve systems of simultaneous congruences in modular arithmetic. The essence of the theorem lies in the condition that if a set of moduli , , …, are pairwise coprime, as specified in (1), then for any given set of remainders , , …, , there exists a unique integer satisfying the congruences in (2). This is the unique modulo . This implies that by dividing a piece of data into remainders under different moduli, the original data can be reconstructed without any loss of information.
Traditional secret sharing techniques rely on secret sharing polynomials, where the secret is treated as the constant term of the polynomial, and the interpolation properties of polynomials are used to reconstruct the secret. However, such polynomial-based approaches often involve complex mathematical operations, particularly requiring the selection and manipulation of finite fields to ensure security and correctness in certain cases. In contrast, the Chinese Remainder Theorem offers an alternative implementation for secret sharing. By leveraging the properties of integer modular arithmetic, it divides the secret into remainders under different moduli. This approach eliminates the need for polynomial operations in finite fields, simplifying the reconstruction process. The secret can be efficiently restored using modular arithmetic and linear combinations. Moreover, secret sharing based on the Chinese Remainder Theorem provides inherent fault tolerance and flexibility, making it particularly suitable for applications involving integer or modular structures. This characteristic enhances its practicality in scenarios requiring efficient and robust data sharing and recovery.
Assume there are four participants in a secret sharing scheme, and at least three participants’ shares are required to reconstruct the secret, with the secret being . Four pairwise coprime moduli are chosen: , , , and . The remainders are calculated as , , , and . Therefore, the shares for the four participants are , , , and . If the first three participants collaborate to reconstruct the secret, the system of congruences to be solved is , , and . Using the Chinese Remainder Theorem, the total modulus is calculated as . For each modulus , the corresponding and the modular multiplicative inverse are computed: , ; , ; and , . Finally, the secret is reconstructed using (3) with participants involved in the secret reconstruction process and , which yields .
2.4. Reversible Data Hiding in Encrypted Polygonal Faces Using Vertex Index Similarity
Tsai [10] proposed a reversible data hiding technique for encrypted polygonal faces that leverages vertex index similarity to address the limitations of traditional methods, which embed secret messages exclusively through vertex coordinate modifications. This method first introduces a right circular shifting operation, repositioning the smallest vertex index of each triangular face as the first index. This not only preserves the normal vector orientation of each polygon but also creates more favorable conditions for subsequent embedding operations. Next, the polygons are reordered based on the value of their vertex indices, effectively increasing the embedding capacity of the first vertex index.
In the polygon classification process, a threshold is introduced to divide polygons into homogeneous or heterogeneous categories based on the distribution of their vertex indices. For similarity calculation, the first vertex index of each polygon is compared to the first vertex index of the preceding polygon using an LZC prediction technique. The first polygon’s index is compared with 0, while the -th polygon’s index is compared with , where , and represents the total number of vertices. Here, is the polygon number when the first index exceeds . Since the polygons have been reordered by index value, subsequent indices are guaranteed to be larger and highly similar, enabling substantial embedding capacity in the first index. However, for the remaining two index values of each reordered polygonal face, the approach depends on whether the polygonal face is classified as homogeneous or heterogeneous. If the face is homogeneous, the author directly applies the LZC prediction between the residual two index values and the first index value to obtain their similarity values, denoted as labels. For heterogeneous faces, either the LZC or the multi-MSB prediction is used to determine similarity values based on the relationship between the processing index value and its surrounding vertex indices.
After collecting all labels for each vertex index, the model owner compresses the label data using Huffman encoding, embedding both the encoded labels and the Huffman tree structure into the encrypted vertex indices. Vertex index encryption is performed using XOR-based encryption, ensuring the encrypted indices remain within their original range to facilitate accurate restoration. Upon receiving the encrypted 3D model with embedded labels, the data hider extracts the labels and embeds secret messages into the available space after encryption. Finally, the receiver, using their private key, can retrieve the hidden messages or restore the original vertex indices based on the labels.
3. Proposed Algorithms
This section introduces the proposed vertex index value sharing technique based on the Chinese Remainder Theorem, as highlighted within the red block of the flowchart in Figure 2. Although the processes of this method are relatively straightforward, its integration with existing techniques extends its functionality, enabling not only enhanced security of the sharing model but also an increased capacity for data embedding, showcasing its potential for practical applications. Figure 3 and Figure 4 present the pseudocode for the two proposed methods. Figure 3 corresponds to Method 1, which describes the secure vertex index sharing process using the Chinese Remainder Theorem. Figure 4 illustrates Method 2, which outlines the reversible data hiding framework, including the roles of the model owner, data hiders, and receiver.
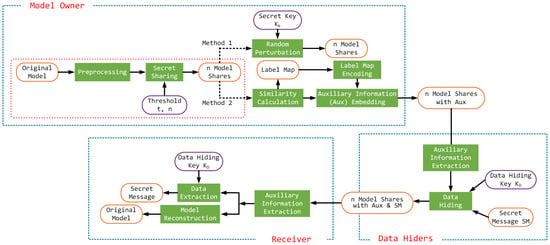
Figure 2.
Proposed algorithm framework based on vertex index value sharing technique.

Figure 3.
The pseudo code of the vertex index-based secret sharing algorithm with enhanced security.

Figure 4.
The pseudo code of the vertex index-based secret sharing algorithm with enhanced embedding capacity.
3.1. Vertex Index Value Sharing Technique Based on the Chinese Remainder Theorem
In the preprocessing step, after reading the input model, the number of vertices and the number of polygons in the model can be determined. Additionally, the range of vertex index values for the polygons is identified as . In a 3D model, each vertex can be defined as , where ranges from 0 to . Each polygon is defined as , where ranges from 0 to , and , , and all fall within the range .
For each vertex index value, this technique utilizes the Chinese Remainder Theorem to compute its shared values. First, based on the input threshold , pairwise coprime moduli are generated, where each modulus is a prime number. This ensures that the Chinese Remainder Theorem can be applied for secret reconstruction. To guarantee reconstruction accuracy, the product of any moduli must be greater than or equal to , satisfying the requirement of (4). Next, for each vertex index value, the remainders are computed using the generated moduli . For each polygon , the shared values are calculated as , where ranges from 1 to . These remainders constitute the shared values for each vertex index. When reconstruction is required, at least distinct shared values , corresponding to different moduli, are collected. Using the inverse modulus operation and the formula for modular multiplicative inverses in the Chinese Remainder Theorem, the original vertex index values can be accurately reconstructed.
Taking the Armadillo model as an example, the model contains vertices and polygons, with each polygon formed by three vertices. The vertex indices range from 0 to 172,973. Table 1 illustrates the process of sharing and reconstructing the polygon vertex indices under a (3, 4) threshold scheme. Assume a polygon has vertex indices (2897, 34,572, 154,925), and the moduli used by the four participants are (67, 71, 73, 79). Based on the Chinese Remainder Theorem, the remainders of each vertex index are computed for each modulus . For moduli 67, 71, 73, and 79, the corresponding shared values are , , and , respectively. During the reconstruction process, any three participants’ shared values are sufficient to restore the original vertex indices. For instance, selecting Participants 1, 2, and 3, the original vertex indices (2897, 34,572, 154,925) can be accurately reconstructed with their shared values using the Chinese Remainder Theorem.

Table 1.
Example of shared index value calculation and adjustment operations.
3.2. Vertex Index Sharing Technique with Enhanced Security
Traditional secret sharing primarily focuses on the sharing of vertex coordinate values. However, this technique introduces a vertex index value sharing mechanism to enhance the overall security of the sharing model. As described in Section 3.1, the output of the shared values depends on the moduli chosen by the participants, causing all polygon shared values to fall within the range . In polygon models with a large number of vertices, however, the distribution of original vertex index values is typically not concentrated in such a narrow range. This characteristic may draw attention and reduce security.
To address this issue, a secret key is employed to generate a series of random numbers , where the range of the random numbers is set as (where , and corresponds to the three vertex indices of a polygon). Using these random numbers, the shared values are adjusted via (5), making their distribution closer to that of the original vertex index values. During the reconstruction of the vertex index values, the same secret key is used to generate an identical sequence of random numbers . These random numbers are then applied to reverse the adjusted shared values through (6), restoring the original shared values for each participant. Subsequently, the original vertex index values can be reconstructed using the Chinese Remainder Theorem. Using Table 1 as an example, assume the secret key generates three random numbers: 3235, 153,545, and 98,496. Applying these random numbers and adjusting the shared values via (5), the corrected vertex index values become (43,787, 82,049, 26,241).
3.3. Reversible Data Hiding for Encrypted 3D Models with Enhanced Embedding Capacity
As described in Section 3.1, the output range of the shared values is influenced by the moduli chosen by the participants, resulting in all shared vertex values being distributed within the interval . However, this characteristic provides an excellent opportunity for data embedding. Since the distribution of shared index values closely resembles that of the original index values, it offers a substantial capacity for message embedding. Based on this principle, when the model owner obtains model shares through the secret sharing technique, they can embed additional information into the model shares by following the steps outlined in the flowchart in Figure 2. This design not only preserves the security of the index values of the input model but also leverages their characteristics to develop algorithms with high embedding capacity. This enhancement enriches the functionality and value of model shares, extending their potential applications.
In the similarity calculation process, we first calculate the difference between each shared index value and the maximum shared index value. Specifically, for each shared index value , the difference is computed as . This difference is then converted into its binary representation, ensuring its length is bits. Following the principles of the LZC prediction technique, starting from the most significant bit (MSB) of the binary representation, each bit is inspected sequentially until the first bit with a value of 1 is encountered. The number of consecutive 0s preceding this bit defines the label of the shared index value. Based on this label, the embedding length is defined as , where corresponds to the position of the first bit with a value of 1. Since the bit at position is guaranteed to be 1, this bit and all the preceding consecutive 0 bits can be safely used for message embedding. Once the embedding is complete, the embedded bits can be restored to their original state by referring to the label . The bit at position can be restored to 1, and the leading zeros can be restored to 0 based on the recorded label . The restored value is then added back to , recovering the original shared index value. This approach ensures that the embedding process is reversible while maintaining the integrity of the shared index values.
The embedding length can be further divided into two components: the basic embedding length and the prediction embedding length , such that . Since each shared index value lies within the range , the difference must also fall within the same range. This ensures that the first bits in the binary representation of are guaranteed to be 0. These zero bits form the basic embedding length . The remaining bits, which vary due to the similarity between the shared index value and , define the prediction embedding length . This prediction component reflects the variable capacity for data embedding that arises from the specific characteristics of the shared index values. For example, consider Table 2, in which the total bit length of the shared index values is bits. Using the above method, the label and the embedding length for each shared index value can be calculated. This enables effective message embedding and recovery operations, ensuring both the flexibility and accuracy of the embedding process. By leveraging the division into and , this technique optimizes the use of the bit capacity for information embedding, providing a balance between security, efficiency, and adaptability.
Table 2.
Example of label calculation for shared index values.
After completing the similarity calculation for all shared index values, the model owner collects these labels and generates a label map, which records the embedding capacity for each shared index value. Since these labels are calculated by the model owner, they must be communicated to the data hiders to ensure the correct embedding process. However, to minimize the transmission size of the label map, a Huffman coding technique is employed during the label map encoding process. This compresses the label map into a Huffman coding tree structure and its corresponding encoded results, effectively reducing the size of the auxiliary information.
In the auxiliary information embedding process, the Huffman coding tree structure and the encoded label map are embedded into the basic embedding length of the shared index values. If the available space in the basic embedding length is insufficient, the remaining auxiliary information is further embedded into the prediction embedding length of the shared index values. This ensures that the auxiliary information is fully embedded into the model shares. In the final output process, to make the distribution of shared index values with embedded auxiliary information appear more natural, a random offset of is added to shared index values smaller than . This adjustment evenly redistributes the final shared index values within the range , ensuring a uniform and natural appearance. These processing steps not only enhance the security and confidentiality of the shared model but also ensure that the embedding and transmission of auxiliary information achieve a balance between resource utilization and security. This approach provides a robust technical foundation for the practical application of model shares, ensuring both functionality and data protection.
When each data hider receives the model share containing the auxiliary information, the first step is to extract the embedded auxiliary information. For index values greater than , the embedder subtracts the offset from these values to restore the original index value range. Next, the Huffman tree structure is extracted from the basic embedding length of the index values. This tree structure is then used to decode the encoded label map, providing the embedding length information for each vertex index value. To enhance the security of the secret message, the data hider uses the embedding key to generate a sequence of random binary values. This sequence is XORed with a secret message to encrypt it. Once encrypted, the secret message is embedded into the remaining available space of each vertex index value using a bit substitution method. This process ensures that the secret message is securely embedded while fully utilizing the available capacity of the vertex index values, maintaining the confidentiality of the embedded data and the integrity of the model.
When the receiver obtains the model share containing both auxiliary information and the secret message, they can perform model reconstruction and message extraction. If they have the data hiding key , they can extract the encrypted secret message from the MSBs of each vertex index value, decrypt it using a bitwise XOR operation with a random binary sequence generated by , and recover the original secret message. Furthermore, the receiver can also proceed to recover the original index values. For each index value, the embedded bits are first reset to their original state by setting the most significant bits used for embedding to 0 and restoring the next significant bit to 1, thereby reconstructing the original binary difference. The shared index value is then recovered by adding this reconstructed difference to . Once valid model shares are collected, the receiver applies the Chinese Remainder Theorem to the corresponding sets of shared index values, enabling the accurate reconstruction of the original polygonal vertex indices of the 3D model.
4. Experimental Results
To thoroughly evaluate the performance and generalizability of the proposed algorithm, we conducted a series of extensive experiments using twenty diverse 3D models. Table 3 summarizes the key characteristics of these models, including the number of vertices (), which reflects geometric complexity and influences the range of vertex index values; the number of polygons (), which indicates structural density and affects the number of available index triples for data embedding; and the model dimensions (Length, Width, Height), which demonstrate diversity in shape and scale. Additionally, we list the four pairwise coprime integers used as moduli in the (3, 4)-threshold Chinese Remainder Theorem scheme, selected such that the product of any three moduli exceeds the maximum vertex index to ensure accurate reconstruction. Figure 5 provides visual representations of each test model. It is important to note that the experimental results collection did not take into account the specific vertex coordinates. The experiments were conducted on a desktop system running Windows 11 Pro, equipped with an Intel Core i7-14700K CPU (3.4 GHz, 20 cores), 64 GB of DDR5 RAM, and a 2TB PCIe 4.0 NVMe M.2 SSD. The algorithm was implemented and tested in MATLAB R2023b, using built-in functions along with custom scripts. All experiments were performed in a single-threaded environment unless otherwise specified, and no GPU acceleration was used.
Table 3.
Characteristics of different test models.
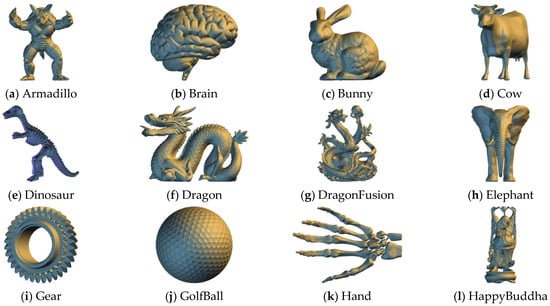

Figure 5.
Test models used in our experiments.
This section begins with a visual comparison of the model shares before and after vertex index adjustment, followed by an evaluation of vertex reference ratios to illustrate the improvement in structural integrity. We then assess the performance of the proposed reversible data hiding algorithm using metrics such as total embedding capacity, auxiliary information size, and pure embedding capacity. To evaluate robustness, a dedicated security analysis is conducted, including key space estimation and normalized vertex similarity (NVS) to quantify geometric distortion. Additionally, time and space complexity are analyzed to demonstrate computational scalability. Finally, a comparative study with existing algorithms highlights the strengths of our method in embedding capacity, security, and multi-party support, while the limitations of the proposed design are also discussed.
4.1. Evaluation of Vertex Reference Before and After Index Adjustment
Table 3 presents the moduli used for each test model in the collection of experimental results for (3, 4)-threshold secret sharing based on the Chinese Remainder Theorem. The moduli are arranged to ensure that the product of the first three smallest moduli exceeds the maximum vertex index, allowing the original index to be accurately reconstructed. However, smaller moduli lead to smaller sharing indices in each sharing model. Table 4 illustrates the vertex reference ratio of the sharing models before and after the vertex index adjustment. Notably, prior to index adjustment with the low moduli, the reference ratio is merely 0.25%, resulting in visual effects, as shown in Figure 6, that appear highly irregular, with only small portions displaying shading. After applying the proposed index adjustment, the vertex reference ratio improves significantly, reaching nearly 100% with a value of 99.93%. The corresponding visual effects, however, appear unremarkable, merely reflecting the standard shading results of the secret sharing process.
Table 4.
The vertex reference ratio of the sharing models before and after the vertex index adjustment.

Figure 6.
The visual difference between the sharing models before and after the vertex index adjustment.
4.2. A Performance Evaluation of the Reversible Data Hiding Algorithm
To evaluate the performance of the proposed reversible data hiding algorithm, we adopted several quantitative metrics: total embedding capacity (TEC), representing the total number of secret bits embedded into the shared model; encoding result (ER), indicating the encoded size of the label map after Huffman encoding; Huffman tree size (Tree), denoting the size of the tree structure used for decoding; average TEC per polygon (ATEC), which normalizes TEC by the polygon number to enable fair comparison across models; average auxiliary information size per polygon (AAUX), calculated by normalizing ER and Tree by the polygon number; and average pure embedding capacity per polygon (APEC), defined as the difference between ATEC and AAUX. Table 5 summarizes the algorithm’s performance across various 3D models using these metrics. TEC varies significantly—from 1,272,673 bits (Elephant) to 36,353,170 bits (Dragon)—reflecting differences in model complexity and polygon counts. Auxiliary information size (ER + Tree) also scales with model size, with larger models like Dragon requiring more storage than smaller ones like Bunny. ATEC generally trends higher for complex models, such as HappyBuddha with 43.11 bits per polygon (bppo), while simpler models like Elephant exhibit lower values (32.39). Although AAUX remains relatively stable across models due to consistent encoding strategies, APEC highlights differences in effective embedding performance: the models with higher TECs, such as DragonFusion and Brain, achieve better results, while the smaller models like Teeth and Elephant show lower APEC values. On average, the algorithm achieves an ATEC of 37.02 bppo, an AAUX of 6.73 bppo, and an APEC of 30.29 bppo, demonstrating both efficiency and scalability across diverse 3D models.
Table 5.
The algorithm performance for performing reversible data hiding on sharing models.
4.3. Security Analysis
To evaluate the robustness of the proposed scheme from both security and perceptual standpoints, this section provides an analysis of its key space security and its ability to disrupt geometric structures in 3D models. These properties jointly ensure protection against brute-force reconstruction and visual inference.
The proposed method includes two independent security layers. The first safeguards the 3D model’s structure using random perturbations derived from a secret key. Assuming 16-bit pseudorandom values are applied to three vertex indices per polygon, the total key space reaches . For instance, in a model with 100,000 polygons, the key space exceeds , rendering brute-force reconstruction computationally infeasible. The second layer protects the secret message embedded in the model shares. Before embedding, the message is encrypted using a symmetric bitwise XOR operation with a key-generated pseudorandom sequence. If a 128-bit or 256-bit key is used, the key space expands to or , respectively. As a result, unauthorized access to the embedded message is effectively prevented, even if the embedding region is exposed.
In addition to cryptographic protections, the proposed scheme introduces significant geometric perturbation, which enhances visual obfuscation and resists structural inference. This effect is quantitatively assessed using the NVS metric [10], defined in (7) and (8). For each vertex , the method computes the average pairwise cosine similarity between the normal vectors of its adjacent polygons, , and then averages these across all vertices to yield a global similarity score. As shown in Table 6, the original models exhibit a high degree of geometric coherence, with an average NVS of 0.9789. After applying Method 1 (index-adjusted secret sharing), the NVS drops sharply to an average of 0.0171, indicating that although the encrypted vertex indices remain numerically valid, their redistribution significantly disrupts local surface continuity. With Method 2 (embedding applied), the NVS increases slightly to 0.0475 due to the influence of data hiding strategies yet still represents a substantial deviation from the original surface geometry. These results confirm that the proposed algorithm effectively masks original geometric patterns while preserving reversibility. The significant reduction in normal vector similarity prevents attackers from visually or analytically correlating the processed model with its original form, thereby strengthening the scheme’s spatial obfuscation capabilities.
Table 6.
Normalized vertex similarity metric evaluation for proposed algorithm.
4.4. Time Complexity and Space Complexity Analysis
To better understand the efficiency and scalability of the proposed framework, this subsection presents a detailed computational complexity analysis for both proposed methods. We analyze the time and space requirements from the perspective of different roles involved in the pipeline, including the model owner, the data hiders, and the receiver. The following analysis estimates the cost of each key operation in terms of theoretical asymptotic complexity and complements it with empirical observations to assess the method’s practicality across a range of 3D model sizes.
For Method 1, which focuses on secure secret sharing based on vertex index values and modular arithmetic, the basic algorithm operates on a 3D model with vertices and polygons and produces model shares using distinct moduli. Reading the model and determining the vertex index range is a linear operation with a complexity of . The primary computational load comes from computing remainders for each of the three indices per polygon under all moduli, resulting in a time complexity of . Each random perturbation applied to a vertex index is a constant-time operation involving pseudo-random number generation and a modular addition. Since each polygon consists of three indices and the operation is repeated across n shares, the total number of perturbation steps is , resulting in an overall linear time complexity of . Therefore, the total time complexity of Method 1 from the model owner’s perspective is . In terms of space complexity, the algorithm stores the original model and generates model shares, each containing both the full vertex list and the shared polygon index data . Hence, the total space complexity is .
For Method 2, which introduces reversible data hiding into the model shares, the model owner performs additional steps, including similarity calculation, label map encoding, and auxiliary information embedding. The similarity calculation, which involves computing the difference between shared index values and the maximum index, binary conversion, and leading zero counting, introduces a logarithmic factor relative to the vertex index range. This results in a time complexity of . Huffman encoding of the label map introduces another factor, while the embedding of auxiliary information remains linear. Therefore, the model owner’s total time complexity for Method 2 becomes , including the time complexity for reading the model , and space complexity remains , including label maps and encoded auxiliary data. On the side of the data hider, the auxiliary information (i.e., Huffman tree and encoded label map) must be extracted to determine embedding lengths. This decoding process has a time complexity of . Subsequently, the secret message is encrypted using a symmetric key and embedded bit-by-bit into the embeddable regions, which takes time. Here, denotes the length (in bits) of the secret message to be embedded. This term appears in both time and space complexity, as encryption and bitwise embedding require one operation per bit. Therefore, the overall time complexity for the data hiders is , and the space complexity is also . For the receiver, who must recover both the secret message and the original model, the decoding of auxiliary information mirrors the data hider’s process, resulting in a time complexity of . Decrypting the embedded message incurs an additional cost. To reconstruct the model, the receiver must recover the original shared index values and apply the Chinese Remainder Theorem using any t of the available n shares. This reconstruction involves modular inverses and summation over t moduli, yielding a complexity of , where is the largest modulus used. Here, arises from computing modular inverses involved in the Chinese Remainder Theorem. Thus, the receiver’s total time complexity is , and the space complexity is .
In summary, although the theoretical complexity analysis includes logarithmic and modular computations—particularly in similarity calculation, label map encoding, and Chinese Remainder Theorem-based reconstruction—the practical performance is efficient and consistent with the analysis. For Method 1, the Elephant model completed processing in approximately 0.27 s, while the more complex HappyBuddha model required only 7.66 s. For Method 2, which involves additional steps for reversible data hiding, the HappyBuddha model was processed in about one minute. These results confirm that the proposed algorithms can be executed within a reasonable time, even for large-scale models. The computational cost remains acceptable, and no unusual resources are required aside from storing the model shares and associated auxiliary information. Overall, the proposed methods strike a practical balance between computational efficiency and the advanced functionalities they offer, such as high-capacity embedding, security enhancement, and support for multi-party secret sharing.
4.5. Algorithm Performance Comparison with Existing Algorithms
Table 7 offers an in-depth comparison between the proposed and existing up-to-date algorithms. This table evaluates several critical aspects of each algorithm, including the type of embedding elements utilized (Vertex or Polygon), and the specific embedding methods, such as multi-MSB prediction and LZC prediction with a bit substitution mechanism. Notably, the table also examines the embedding rates, which reflect the percentage of data successfully embedded, and the embedding capacities, which are quantified in bits per vertex (bpv), bits per point (bpp), and bits per polygon (bppo) demonstrating the average pure embedding capacity each algorithm can achieve. Additionally, the role of data hiders is considered, with Gao et al.’s [20] and our proposed method supporting multiple data hiders, unlike most existing algorithms that support only one. This feature enhances the versatility and application scope of our approach. The embedding rate for our proposed algorithm reaches 100%, indicating perfect embedding efficiency, with a competitive embedding capacity of 30.29 bppo, underscoring its potential for robust and efficient data embedding in complex 3D models.
Table 7.
Comparisons between the proposed and existing algorithms.
4.6. The Limitations of the Proposed Algorithm
While the proposed method demonstrates a superior embedding capacity and security performance compared to the existing approaches, several limitations should be acknowledged. First, the method assumes that the polygon structure of the 3D model remains intact during transmission or storage. Any modification, such as remeshing or reordering of polygons, may affect the integrity of the shared index values and compromise recovery. Second, although the method achieves high embedding efficiency, its performance may vary depending on the geometric complexity and index distribution of the model. Third, the current framework requires accurate synchronization of shared moduli and auxiliary information across all participants, which may pose implementation challenges in distributed environments. Addressing these issues, such as improving robustness against structural transformations or designing error-resilient embedding schemes, is a promising direction for future research.
5. Conclusions
This study has successfully demonstrated the feasibility and advantages of utilizing vertex indices—rather than traditional vertex coordinates—for secret sharing in 3D models. By leveraging the modular arithmetic properties of the Chinese Remainder Theorem, the proposed method achieves a secure and efficient sharing mechanism that supports high-capacity reversible data hiding. Experimental evaluations across 20 benchmark 3D models showed that our algorithm consistently achieved a 100% embedding rate with an average pure embedding capacity of 30.29 bits per polygon, outperforming previous techniques, which often struggled with lower embedding efficiency due to coordinate-based constraints. These improvements in capacity and security are particularly significant given the growing demand for secure and high-performance data protection in 3D modeling applications.
To further enhance the practicality and adaptability of the proposed framework, future research will focus on several directions. Robustness to geometric transformations—such as remeshing, simplification, and polygon reordering—will be explored to ensure reliable performance in dynamic 3D pipelines. Computational optimizations will also be investigated to support real-time applications such as AR/VR model editors and interactive design environments. Moreover, the method’s ability to support multi-party sharing makes it particularly promising for collaborative systems and distributed security scenarios. Real-world applications include digital rights management in 3D content creation, secure model distribution in medical imaging and CAD, authenticity verification in forensic and cultural preservation, and the protection of interactive 3D assets in AR/VR. In addition to these directions, the issue of secure key exchange will be further addressed to improve the overall robustness of the framework. While the current implementation assumes a securely pre-shared key for generating random perturbation values and guiding auxiliary information embedding and extraction, we recognize that key management is a fundamental component of encryption-based secret sharing systems. Future work will investigate practical solutions such as public key cryptography (e.g., RSA or ECC) to securely transmit the secret key from the model owner to data hiders or receivers, as well as key agreement protocols like Diffie–Hellman for decentralized environments where synchronized key generation is needed without centralized control. These enhancements aim to establish a complete and secure protocol for key management that ensures end-to-end confidentiality and scalability. Integrating the proposed secret sharing framework with blockchain technology could further strengthen its practical value. Blockchain’s decentralized and immutable ledger can be leveraged to manage shared models across multiple nodes, enhancing fault tolerance and eliminating single points of failure. Smart contracts can enforce access control policies and validate reconstruction conditions (e.g., verifying the presence of a valid combination of out of participants), ensuring secure and transparent share usage without relying on centralized authorities. Furthermore, blockchain enables tamper detection by immutably logging each transaction related to share generation, modification, or access. Time-stamping and version control features also facilitate collaborative model design and forensic applications by preserving traceable change histories. Beyond polygonal models, future extensions to point clouds and hybrid formats will broaden the framework’s applicability to areas such as LiDAR mapping, autonomous navigation, and digital twin systems. Additionally, more comprehensive evaluation criteria will be considered. While the current experiments balance embedding efficiency and an auxiliary overhead across a diverse set of 3D models, further metrics—such as surface curvature variation, polygon quality (e.g., aspect ratio), and topological connectivity—may offer deeper insights into robustness under varied geometries. Practical factors such as execution time, memory consumption, and resilience to geometric distortions will also be incorporated to provide a more holistic assessment of the algorithm’s real-world applicability. These expanded directions will contribute to a more complete understanding of the proposed method’s strengths, limitations, and future potential.
Author Contributions
Conceptualization, Y.-Y.T., J.-Y.J. and C.-T.L.; funding acquisition, Y.-Y.T. and C.-T.L.; methodology, Y.-Y.T., J.-Y.J. and C.-T.L.; software, Y.-Y.T. and C.-T.L.; validation, J.-Y.J. and T.-Y.Y.; data curation, J.-Y.J. and T.-Y.Y.; writing—original draft preparation, Y.-Y.T.; writing—review and editing, Y.-Y.T. and C.-T.L.; supervision, Y.-Y.T. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the National Science and Technology Council of Taiwan under the grant numbers NSTC 113-2221-E-035-058 and NSTC 111-2410-H-035-059-MY3.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors on request.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Blakley, G.R. Safeguarding Cryptography Keys. In Proceedings of the International Workshop on Managing Requirements Knowledge, New York, NY, USA, 4–7 June 1979; pp. 313–318. [Google Scholar]
- Shamir, A. How to Share a Secret. Commun. ACM 1979, 22, 612–613. [Google Scholar] [CrossRef]
- Chen, B.; Lu, W.; Huang, J.; Weng, J.; Zhou, Y. Secret Sharing Based Reversible Data Hiding in Encrypted Images with Multiple Data-hiders. IEEE Trans. Dependable Secur. Comput. 2022, 19, 978–991. [Google Scholar] [CrossRef]
- Wang, R.; Yang, G.; Yan, X.; Luo, S.; Han, Q. Secret Image Sharing in the Encrypted Domain. J. Vis. Commun. Image Represent. 2024, 98, 104013. [Google Scholar] [CrossRef]
- Xiong, L.; Han, X.; Yang, C.-N.; Shi, Y.-Q. Reversible Data Hiding in Shared Images with Separate Cover Image Reconstruction and Secret Extraction. IEEE Trans. Cloud Comput. 2024, 12, 186–199. [Google Scholar] [CrossRef]
- Xiong, L.; Ding, R.; Yang, C.-N.; Fu, Z. Invertible Secret Image Sharing with Authentication for Embedding Color Palette Image into True Color Image. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 10987–10999. [Google Scholar] [CrossRef]
- Hou, G.; Ou, B.; Long, M.; Peng, F. Separable Reversible Data Hiding for Encrypted 3D Mesh Models Based on Octree Subdivision and Multi-MSB Prediction. IEEE Trans. Multimed. 2024, 26, 2395–2407. [Google Scholar] [CrossRef]
- Jiang, R.; Zhou, H.; Zhang, W.; Yu, N. Reversible Data Hiding in Encrypted Three-Dimensional Mesh Models. IEEE Trans. Multimed. 2018, 20, 55–67. [Google Scholar] [CrossRef]
- Lyu, W.-L.; Cheng, L.; Yin, Z. High-Capacity Reversible Data Hiding in Encrypted 3D Mesh Models Based on Multi-MSB Prediction. Signal Process. 2022, 201, 108686. [Google Scholar] [CrossRef]
- Tsai, Y.-Y. Reversible Data Hiding in Encrypted Polygonal Faces Using Vertex Index Similarity. IEEE Trans. Multimed. 2025. Accepted. [Google Scholar]
- Tsai, Y.-Y.; Jao, W.-T.; Lin, A.; Wang, S.-Y. Advanced Octree-based Reversible Data Hiding in Encrypted Point Clouds. J. Inf. Secur. Appl. 2025, 89, 104006. [Google Scholar] [CrossRef]
- Xu, N.; Tang, J.; Luo, B.; Yin, Z. Separable Reversible Data Hiding Based on Integer Mapping and MSB Prediction for Encrypted 3D Mesh Models. Cogn. Comput. 2022, 14, 1172–1181. [Google Scholar] [CrossRef]
- Yin, Z.; Xu, N.; Wang, F.; Cheng, L.; Luo, B. Separable Reversible Data Hiding Based on Integer Mapping and Multi-MSB Prediction for Encrypted 3D Mesh Models. In Proceedings of the Chinese Conference on Pattern Recognition and Computer Vision, Beijing, China, 29 October–1 November 2021; pp. 336–348. [Google Scholar] [CrossRef]
- Beugnon, S.; Puech, W.; Pedeboy, J.-P. Format-Compliant Selective Secret 3-D Object Sharing Scheme. IEEE Trans. Multimed. 2019, 21, 2171–2183. [Google Scholar] [CrossRef]
- del Rey, A.M. A Multi-secret Sharing Scheme for 3D Solid Objects. Expert Syst. Appl. 2015, 42, 2114–2120. [Google Scholar] [CrossRef]
- Elsheh, E.; Hamza, A.B. Robust Approaches to 3D Object Secret Sharing. In Proceedings of the International Conference on Image Analysis and Recognition, Póvoa de Varzin, Portugal, 21–23 June 2010; pp. 326–335. [Google Scholar] [CrossRef]
- Elsheh, E.; Hamza, A.B. Secret Sharing of 3D Models Using Blakely Scheme. In Proceedings of the 25th Biennial Symposium on Communications, Kingston, ON, Canada, 12–14 May 2010; pp. 92–95. [Google Scholar] [CrossRef]
- Elsheh, E.; Hamza, A.B. Secret Sharing Approaches for 3D Object Encryption. Expert Syst. Appl. 2011, 38, 13906–13911. [Google Scholar] [CrossRef]
- Tsai, Y.-Y. A Secret 3D Model Sharing Scheme with Reversible Data Hiding Based on Space Subdivision. 3D Res. 2016, 7, 1. [Google Scholar] [CrossRef]
- Gao, K.; Horng, J.-H.; Chang, C.-C. Reversible Data Hiding for Encrypted 3D Mesh Models with Secret Sharing over Galois Field. IEEE Trans. Multimed. 2024, 26, 5499–5510. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).