
FedHSQA: Robust Aggregation in Hierarchical Federated Learning via Anomaly Scoring-Based Adaptive Quantization for IoV


Abstract
1. Introduction
- We propose a three-layer HFL framework for IoV, called FedHSQA, which integrates GQ and anomaly detection for vehicle nodes.
- We propose a secure aggregation algorithm based on anomaly scoring, called ASA, which adopts KL divergence as the loss function to improve the robustness of the aggregation process against anomalous vehicle nodes.
- We propose an anomaly score-based GQ method, called ASQ, which resolves the impact of anomalous data on the global model by calculating the JS distance and mapping it to adaptive quantization levels.
- We validate the effectiveness of FedHSQA under various parameter settings on several datasets. Experimental results show that compared to the classical aggregation algorithms and quantization methods, FedHSQA exhibits strong robustness to anomalous vehicle nodes under the HFL framework for IoV.
2. Related Work
2.1. Hierarchical Federated Learning
2.2. Gradient Quantization
2.3. Secure Aggregation for IoV
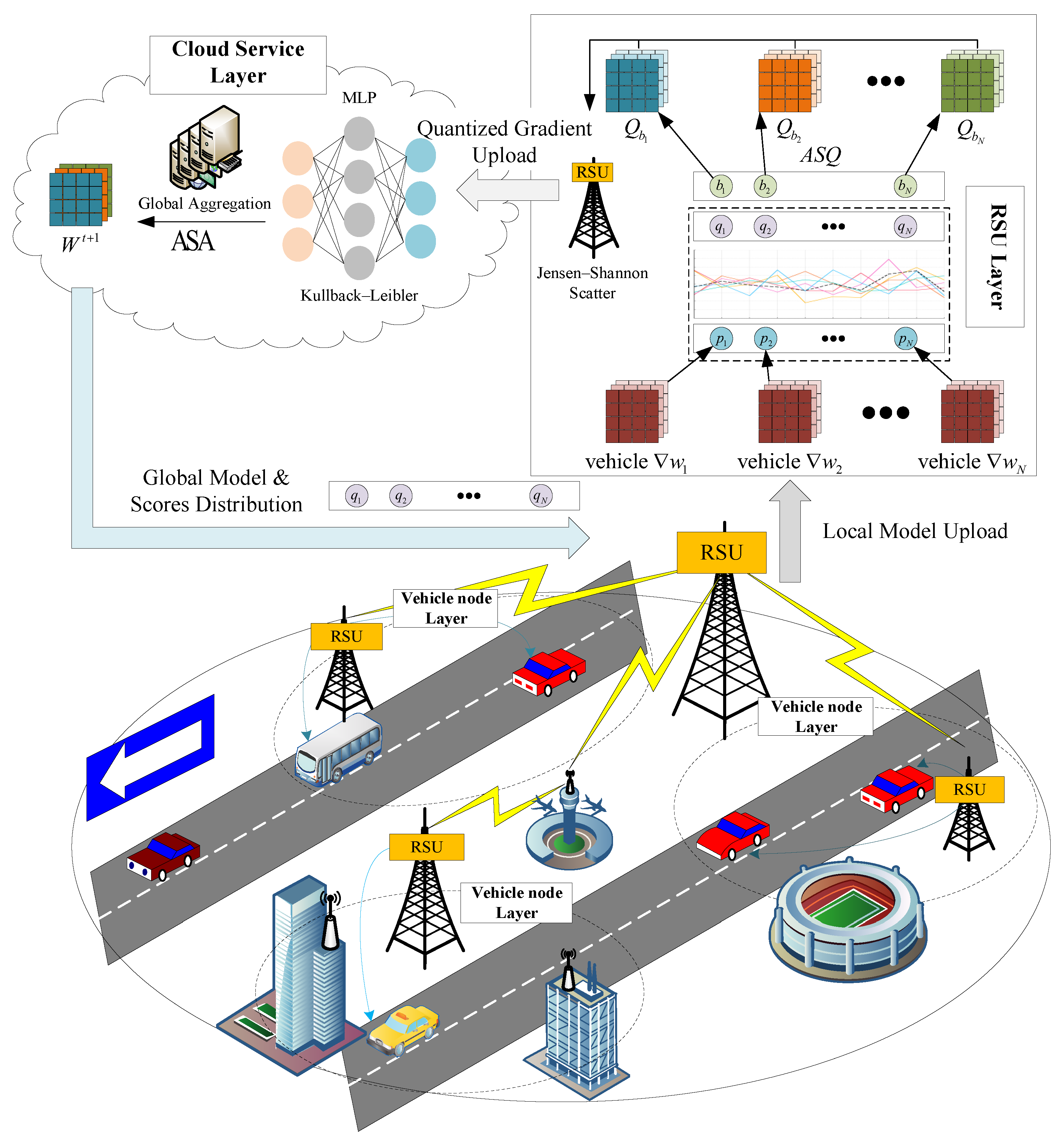
3. Model System
3.1. Global Models Distribution
3.2. Local Model Training
3.3. Adaptive Gradient Quantization
3.4. Model Secure Aggregation
4. Scheme Design
4.1. Anomaly Scoring-Based Security Aggregation
4.1.1. Calculating Anomaly Score
4.1.2. Anomaly Probability Distribution
4.1.3. Designing Target Distribution
4.1.4. Training the MLP Model
4.1.5. Calculating Aggregation Weight
4.2. Anomaly Scoring-Based Adaptive Quantization
4.2.1. Designing Anomaly Distribution
4.2.2. Calculating Anomaly Metric
4.2.3. Calculating Quantization Level
4.2.4. Adaptive Gradient Quantization
| Algorithm 1 FedHSQA—The Hierarchical Three-Layer Federated Learning Framework for IoV |
|
5. Experiment
5.1. Experimental Setup
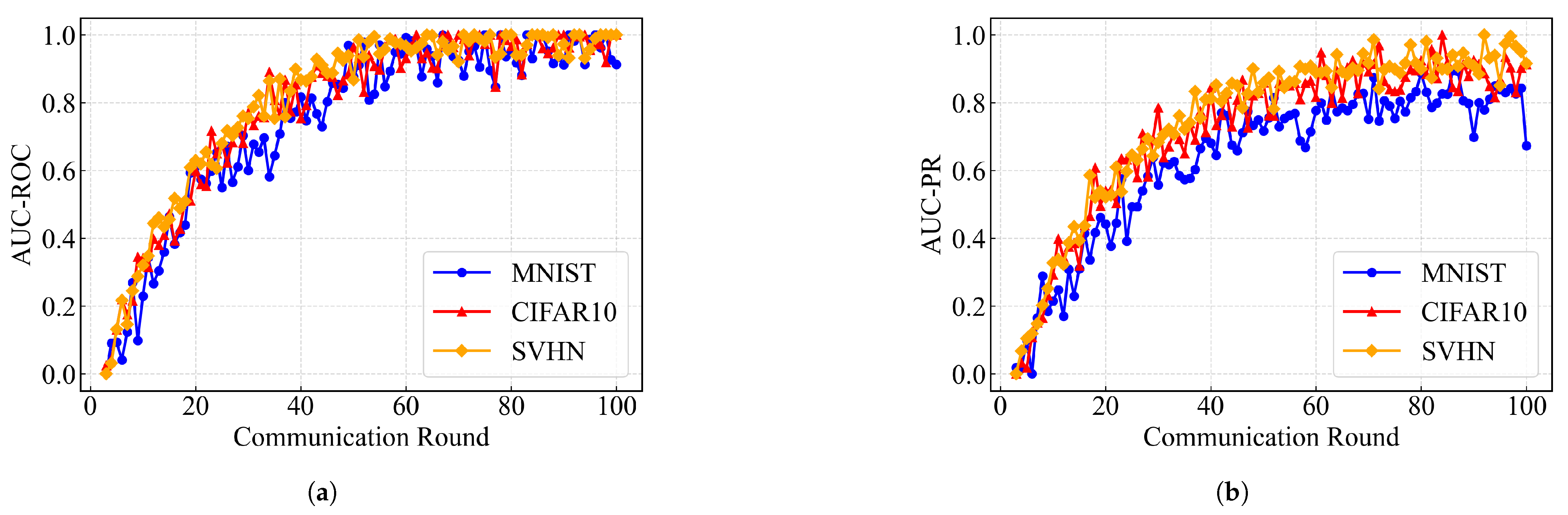
5.2. Framework Feasibility Analysis
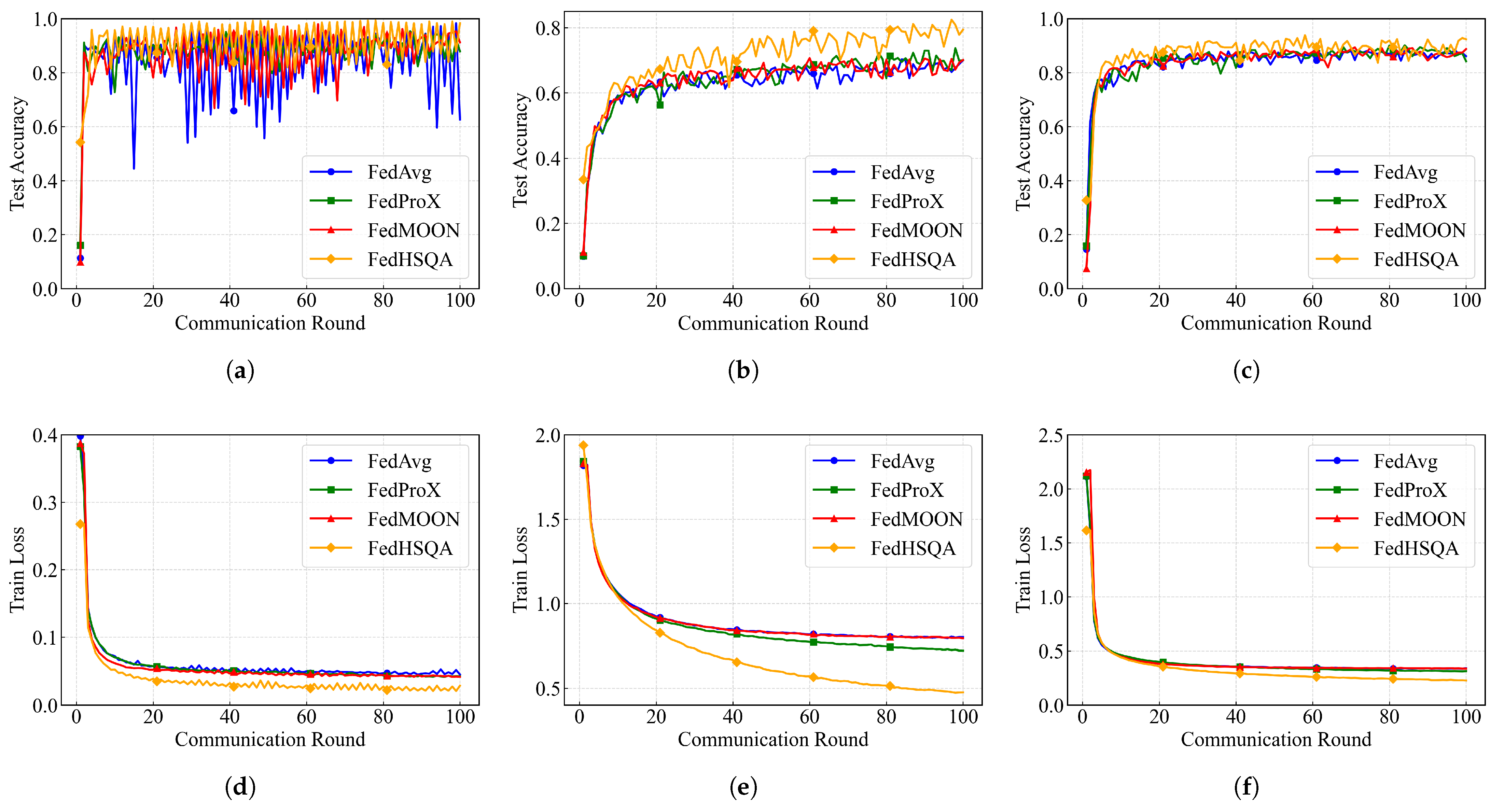
5.3. Model Performance Analysis
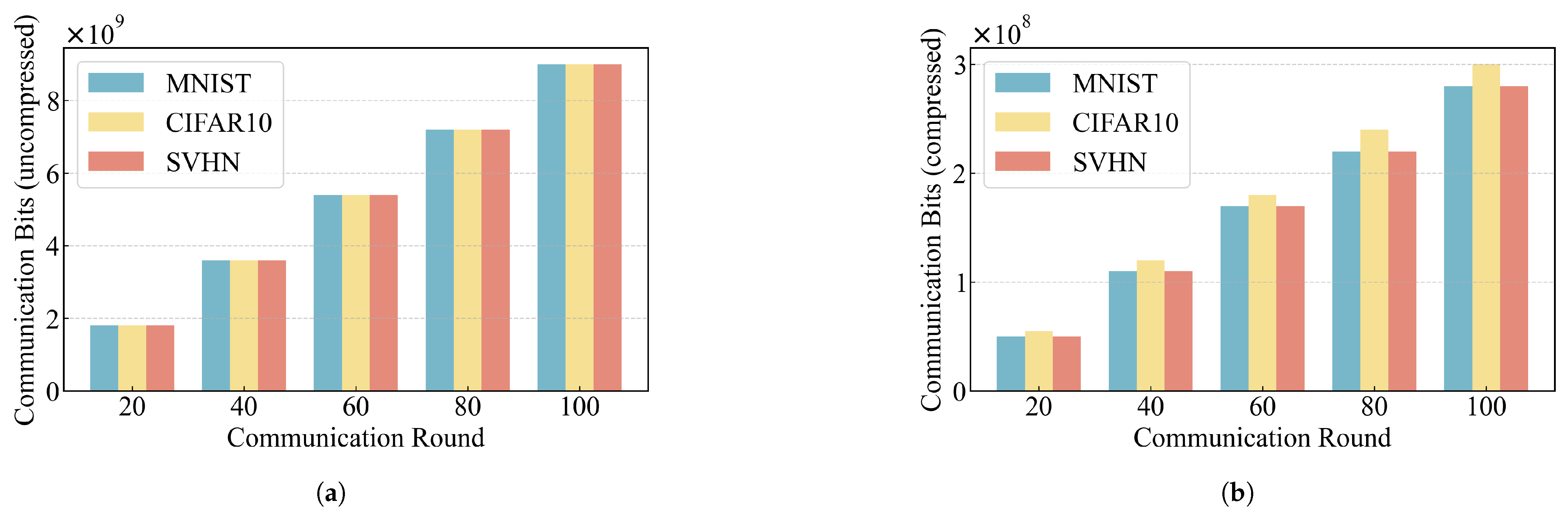
5.4. Quantization Effectiveness Analysis
5.5. Ablation Experiments
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Khezri, E.; Hassanzadeh, H.; Yahya, R.O.; Mir, M. Security challenges in internet of vehicles (IoV) for ITS: A survey. Tsinghua Sci. Technol. 2025, 30, 1700–1723. [Google Scholar] [CrossRef]
- Ali, E.S.; Hasan, M.K.; Hassan, R.; Saeed, R.A.; Hassan, M.B.; Islam, S.; Nafi, N.S.; Bevinakoppa, S. Machine learning technologies for secure vehicular communication in internet of vehicles: Recent advances and applications. Secur. Commun. Networks 2021, 2021, 8868355. [Google Scholar] [CrossRef]
- Taslimasa, H.; Dadkhah, S.; Neto, E.C.P.; Xiong, P.; Ray, S.; Ghorbani, A.A. Security issues in Internet of Vehicles (IoV): A comprehensive survey. Internet Things 2023, 22, 100809. [Google Scholar] [CrossRef]
- Sharma, S.; Kaushik, B. A survey on internet of vehicles: Applications, security issues & solutions. Veh. Commun. 2019, 20, 100182. [Google Scholar]
- Agbaje, P.; Anjum, A.; Mitra, A.; Oseghale, E.; Bloom, G.; Olufowobi, H. Survey of interoperability challenges in the internet of vehicles. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22838–22861. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, J.; Song, S.; Letaief, K.B. Client-edge-cloud hierarchical federated learning. In Proceedings of the ICC 2020–2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Abad, M.S.H.; Ozfatura, E.; Gunduz, D.; Ercetin, O. Hierarchical federated learning across heterogeneous cellular networks. In Proceedings of the ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 8866–8870. [Google Scholar]
- Zhou, H.; Zheng, Y.; Huang, H.; Shu, J.; Jia, X. Toward robust hierarchical federated learning in internet of vehicles. IEEE Trans. Intell. Transp. Syst. 2023, 24, 5600–5614. [Google Scholar] [CrossRef]
- Chai, H.; Leng, S.; Chen, Y.; Zhang, K. A hierarchical blockchain-enabled federated learning algorithm for knowledge sharing in internet of vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 22, 3975–3986. [Google Scholar] [CrossRef]
- Hammoud, A.; Otrok, H.; Mourad, A.; Dziong, Z. On demand fog federations for horizontal federated learning in IoV. IEEE Trans. Netw. Serv. Manag. 2022, 19, 3062–3075. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, X.; Wu, D.; Wang, R.; Zhang, P.; Wu, Y. Efficient asynchronous federated learning research in the internet of vehicles. IEEE Internet Things J. 2022, 10, 7737–7748. [Google Scholar] [CrossRef]
- Liu, S.; Liu, Z.; Xu, Z.; Liu, W.; Tian, J. Hierarchical decentralized federated learning framework with adaptive clustering: Bloom-filter-based companions choice for learning non-iid data in iov. Electronics 2023, 12, 3811. [Google Scholar] [CrossRef]
- Yu, X.; Cherkasova, L.; Vardhan, H.; Zhao, Q.; Ekaireb, E.; Zhang, X.; Mazumdar, A.; Rosing, T. Async-HFL: Efficient and robust asynchronous federated learning in hierarchical IoT networks. In Proceedings of the 8th ACM/IEEE Conference on Internet of Things Design and Implementation, San Antonio, TX, USA, 9–12 May 2023; pp. 236–248. [Google Scholar]
- Khan, L.U.; Guizani, M.; Al-Fuqaha, A.; Hong, C.S.; Niyato, D.; Han, Z. A joint communication and learning framework for hierarchical split federated learning. IEEE Internet Things J. 2023, 11, 268–282. [Google Scholar] [CrossRef]
- Lim, W.Y.B.; Ng, J.S.; Xiong, Z.; Niyato, D.; Miao, C.; Kim, D.I. Dynamic edge association and resource allocation in self-organizing hierarchical federated learning networks. IEEE J. Sel. Areas Commun. 2021, 39, 3640–3653. [Google Scholar] [CrossRef]
- Xing, L.; Zhao, P.; Gao, J.; Wu, H.; Ma, H.; Zhang, X. Federated Learning for IoV Adaptive Vehicle Clusters: A Dynamic Gradient Compression Strategy. IEEE Internet Things J. 2025. [Google Scholar] [CrossRef]
- Liang, Z.; Yang, P.; Zhang, C.; Lyu, X. Secure and efficient hierarchical Decentralized learning for Internet of Vehicles. IEEE Open J. Commun. Soc. 2023, 4, 1417–1429. [Google Scholar] [CrossRef]
- Liu, S.; Yu, G.; Yin, R.; Yuan, J.; Qu, F. Communication and computation efficient federated learning for Internet of vehicles with a constrained latency. IEEE Trans. Veh. Technol. 2023, 73, 1038–1052. [Google Scholar] [CrossRef]
- Luo, P.; Yu, F.R.; Chen, J.; Li, J.; Leung, V.C. A novel adaptive gradient compression scheme: Reducing the communication overhead for distributed deep learning in the Internet of Things. IEEE Internet Things J. 2021, 8, 11476–11486. [Google Scholar] [CrossRef]
- Xue, Y.; Su, L.; Lau, V.K. FedOComp: Two-timescale online gradient compression for over-the-air federated learning. IEEE Internet Things J. 2022, 9, 19330–19345. [Google Scholar] [CrossRef]
- Zhang, D.; Gong, C.; Zhang, T.; Zhang, J.; Piao, M. A new algorithm of clustering AODV based on edge computing strategy in IOV. Wirel. Netw. 2021, 27, 2891–2908. [Google Scholar] [CrossRef]
- Scott, C.; Khan, M.S.; Paranjothi, A.; Li, J.Q. Decentralized cluster head selection in iov using federated deep reinforcement learning. In Proceedings of the 2024 IEEE 21st Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 6–9 January 2024; pp. 1–7. [Google Scholar]
- Hu, Z.; Li, Y.; Tang, S. Efficient Caching and Spreading of Traffic Videos by Optimized Topology in IoV. IEEE Trans. Veh. Technol. 2024, 73, 11821–11833. [Google Scholar] [CrossRef]
- Mahmood, A.; Siddiqui, S.A.; Sheng, Q.Z.; Zhang, W.E.; Suzuki, H.; Ni, W. Trust on wheels: Towards secure and resource efficient IoV networks. Computing 2022, 104, 1337–1358. [Google Scholar] [CrossRef]
- Sun, Y.; Wu, L.; Wu, S.; Li, S.; Zhang, T.; Zhang, L.; Xu, J.; Xiong, Y.; Cui, X. Attacks and countermeasures in the internet of vehicles. Ann. Telecommun. 2017, 72, 283–295. [Google Scholar] [CrossRef]
- Sakiz, F.; Sen, S. A survey of attacks and detection mechanisms on intelligent transportation systems: VANETs and IoV. Ad Hoc Netw. 2017, 61, 33–50. [Google Scholar] [CrossRef]
- Hershey, J.R.; Olsen, P.A. Approximating the Kullback Leibler divergence between Gaussian mixture models. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; Volume 4, p. IV-317. [Google Scholar]
- Nielsen, F. On the Jensen–Shannon symmetrization of distances relying on abstract means. Entropy 2019, 21, 485. [Google Scholar] [CrossRef] [PubMed]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Fang, W.; Han, D.J.; Chen, E.; Wang, S.; Brinton, C. Hierarchical federated learning with multi-timescale gradient correction. Adv. Neural Inf. Process. Syst. 2024, 37, 78863–78904. [Google Scholar]
- Zhang, T.; Lam, K.Y.; Zhao, J. Device scheduling and assignment in hierarchical federated learning for internet of things. IEEE Internet Things J. 2024, 11, 18449–18462. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Ni, W.; Wang, X.; Zhang, S.; Sun, Y.; Xu, S.; Pei, Q. Towards dynamic resource allocation and client scheduling in hierarchical federated learning: A two-phase deep reinforcement learning approach. IEEE Trans. Commun. 2024, 72, 7798–7813. [Google Scholar] [CrossRef]
- Kou, W.B.; Lin, Q.; Tang, M.; Ye, R.; Wang, S.; Zhu, G.; Wu, Y.C. Fast-convergent and communication-alleviated heterogeneous hierarchical federated learning in autonomous driving. IEEE Trans. Intell. Transp. Syst. 2025, 1–16. [Google Scholar] [CrossRef]
- Sun, H.; Tang, X.; Yang, C.; Yu, Z.; Wang, X.; Ding, Q.; Li, Z.; Yu, H. HiFi-Gas: Hierarchical federated learning incentive mechanism enhanced gas usage estimation. In Proceedings of the Proceedings of the AAAI Conference on Artificial Intelligence; Vancouver, BC, Canada, 26–27 February 2024, Volume 38, pp. 22824–22832.
- Chandrasekaran, V.; Banerjee, S.; Perino, D.; Kourtellis, N. Hierarchical federated learning with privacy. In Proceedings of the 2024 IEEE International Conference on Big Data (BigData), Washington, DC, USA, 15–18 December 2024; pp. 1516–1525. [Google Scholar]
- Fang, W.; Han, D.J.; Brinton, C.G. Federated Learning Over Hierarchical Wireless Networks: Training Latency Minimization via Submodel Partitioning. IEEE Trans. Netw. 2025, 1–16. [Google Scholar] [CrossRef]
- Alistarh, D.; Grubic, D.; Li, J.; Tomioka, R.; Vojnovic, M. QSGD: Communication-efficient SGD via gradient quantization and encoding. Adv. Neural Inf. Process. Syst. 2017, 30, 1707–1718. [Google Scholar]
- Zhang, C.; Zhang, W.; Wu, Q.; Fan, P.; Fan, Q.; Wang, J.; Letaief, K.B. Distributed deep reinforcement learning based gradient quantization for federated learning enabled vehicle edge computing. IEEE Internet Things J. 2024, 12, 4899–4913. [Google Scholar] [CrossRef]
- Liu, P.; Jiang, J.; Zhu, G.; Cheng, L.; Jiang, W.; Luo, W.; Du, Y.; Wang, Z. Training time minimization for federated edge learning with optimized gradient quantization and bandwidth allocation. Front. Inf. Technol. Electron. Eng. 2022, 23, 1247–1263. [Google Scholar] [CrossRef]
- Qu, L.; Song, S.; Tsui, C.Y. FedDQ: Communication-efficient federated learning with descending quantization. In Proceedings of the GLOBECOM 2022–2022 IEEE Global Communications Conference, Rio de Janeiro, Brazil, 4–8 December 2022; pp. 281–286. [Google Scholar]
- Fereidooni, H.; Marchal, S.; Miettinen, M.; Mirhoseini, A.; Möllering, H.; Nguyen, T.D.; Rieger, P.; Sadeghi, A.R.; Schneider, T.; Yalame, H.; et al. SAFELearn: Secure aggregation for private federated learning. In Proceedings of the 2021 IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 27 May 2021; pp. 56–62. [Google Scholar]
- So, J.; He, C.; Yang, C.S.; Li, S.; Yu, Q.; E Ali, R.; Guler, B.; Avestimehr, S. Lightsecagg: A lightweight and versatile design for secure aggregation in federated learning. Proc. Mach. Learn. Syst. 2022, 4, 694–720. [Google Scholar]
- Mun, H.; Han, K.; Damiani, E.; Kim, T.Y.; Yeun, H.K.; Puthal, D.; Yeun, C.Y. Privacy enhanced data aggregation based on federated learning in internet of vehicles (IoV). Comput. Commun. 2024, 223, 15–25. [Google Scholar] [CrossRef]
- Liu, R.; Pan, J. Schnorr Approval-Based Secure and Privacy-Preserving IoV Data Aggregation. IEEE Trans. Veh. Technol. 2025, 1–15. [Google Scholar] [CrossRef]
- Lu, X.; Xiao, L.; Xiao, Y.; Wang, W.; Qi, N.; Wang, Q. Risk-Aware Federated Reinforcement Learning-Based Secure IoV Communications. IEEE Trans. Mob. Comput. 2024, 23, 14656–14671. [Google Scholar] [CrossRef]
- Boualouache, A.; Ghamri-Doudane, Y. Zero-x: A blockchain-enabled open-set federated learning framework for zero-day attack detection in iov. IEEE Trans. Veh. Technol. 2024, 73, 12399–12414. [Google Scholar]
- Aketi, S.A.; Kodge, S.; Roy, K. Low precision decentralized distributed training over IID and non-IID data. Neural Networks 2022, 155, 451–460. [Google Scholar] [CrossRef]
- Deng, L. The mnist database of handwritten digit images for machine learning research [best of the web]. IEEE Signal Process. Mag. 2012, 29, 141–142. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1106–1114. [Google Scholar] [CrossRef]
- Netzer, Y.; Wang, T.; Coates, A.; Bissacco, A.; Wu, B.; Ng, A.Y. Reading digits in natural images with unsupervised feature learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, Granada, Spain, 12–15 December 2011; Volume 2011, p. 4. [Google Scholar]
- Li, T.; Sahu, A.K.; Zaheer, M.; Sanjabi, M.; Talwalkar, A.; Smith, V. Federated optimization in heterogeneous networks. Proc. Mach. Learn. Syst. 2020, 2, 429–450. [Google Scholar]
- Li, Q.; He, B.; Song, D. Model-contrastive federated learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10713–10722. [Google Scholar]
- Bernstein, J.; Wang, Y.X.; Azizzadenesheli, K.; Anandkumar, A. signSGD: Compressed optimisation for non-convex problems. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 560–569. [Google Scholar]
- Wen, W.; Xu, C.; Yan, F.; Wu, C.; Wang, Y.; Chen, Y.; Li, H. Terngrad: Ternary gradients to reduce communication in distributed deep learning. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Dataset | 20 | 40 | 60 | 80 | 100 | Peak |
|---|---|---|---|---|---|---|---|
| AUC-ROC | MNIST | 0.6132 | 0.7473 | 0.9924 | 0.9519 | 0.9135 | 75 |
| CIFAR10 | 0.5993 | 0.7535 | 0.9662 | 0.9661 | 0.9951 | 62 | |
| SVHN | 0.6297 | 0.8645 | 0.9673 | 0.9938 | 0.9895 | 64 | |
| AUC-PR | MNIST | 0.4422 | 0.6451 | 0.7773 | 0.8880 | 0.6728 | 86 |
| CIFAR10 | 0.5403 | 0.8438 | 0.9480 | 0.9243 | 0.9132 | 84 | |
| SVHN | 0.5220 | 0.8528 | 0.8898 | 0.9812 | 0.9156 | 92 |
| Dataset | Method | 20 (Acc/Loss) | 40 (Acc/Loss) | 60 (Acc/Loss) | 80 (Acc/Loss) | 100 (Acc/Loss) |
|---|---|---|---|---|---|---|
| MNIST | FedAvg | 0.9032/0.0573 | 0.9429/0.0526 | 0.9528/0.0500 | 0.8363/0.0472 | 0.6263/0.0452 |
| FedProX | 0.9014/0.0574 | 0.8971/0.0501 | 0.8943/0.0461 | 0.9142/0.0437 | 0.8789/0.0424 | |
| FedMOON | 0.7819/0.0523 | 0.8045/0.0467 | 0.8349/0.0445 | 0.8994/0.0443 | 0.9118/0.0417 | |
| FedHSQA | 0.9700/0.0389 | 0.9781/0.0325 | 0.9821/0.0292 | 0.9847/0.0272 | 0.9833/0.0286 | |
| CIFAR10 | FedAvg | 0.6106/0.9238 | 0.6460/0.8465 | 0.6581/0.8177 | 0.6753/0.8015 | 0.7000/0.8005 |
| FedProX | 0.6074/0.9095 | 0.6669/0.8157 | 0.6762/0.7731 | 0.6446/0.7461 | 0.7001/0.7212 | |
| FedMOON | 0.6167/0.9193 | 0.6384/0.8417 | 0.7065/0.8135 | 0.7020/0.8043 | 0.7008/0.7937 | |
| FedHSQA | 0.6702/0.8412 | 0.7152/0.6662 | 0.7580/0.5702 | 0.7396/0.5155 | 0.7935/0.4748 | |
| SVHN | FedAvg | 0.8246/0.3911 | 0.8716/0.3555 | 0.8642/0.3459 | 0.8690/0.3388 | 0.8609/0.3399 |
| FedProX | 0.8264/0.3991 | 0.8176/0.3544 | 0.8703/0.3334 | 0.9004/0.3198 | 0.8423/0.3135 | |
| FedMOON | 0.8470/0.3820 | 0.8757/0.3529 | 0.8771/0.3436 | 0.8647/0.3417 | 0.8874/0.3369 | |
| FedHSQA | 0.8994/0.3485 | 0.9108/0.2937 | 0.9091/0.2604 | 0.9187/0.2436 | 0.9236/0.2272 |
| Dataset | Method | 20 (ROC/PR) | 40 (ROC/PR) | 60 (ROC/PR) | 80 (ROC/PR) | 100 (ROC/PR) |
|---|---|---|---|---|---|---|
| MNIST | QSGD | 0.4896/0.4134 | 0.6545/0.7126 | 0.8592/0.7032 | 0.9344/0.8258 | 0.9647/0.8236 |
| TernGrad | 0.5073/0.4948 | 0.7604/0.6413 | 0.8468/0.6791 | 0.8999/0.7793 | 0.9740/0.7761 | |
| SignSGD | 0.4796/0.4094 | 0.6445/0.7086 | 0.8492/0.6992 | 0.9032/0.8218 | 0.9547/0.8196 | |
| ASQ | 0.6132/0.4422 | 0.8169/0.6813 | 0.9924/0.7773 | 0.9519/0.8880 | 0.9135/0.6728 | |
| CIFAR10 | QSGD | 0.5478/0.4198 | 0.6678/0.8063 | 0.9160/0.7399 | 0.9180/0.8627 | 0.9928/0.8540 |
| TernGrad | 0.4927/0.4414 | 0.8614/0.6421 | 0.9349/0.6853 | 0.9099/0.8414 | 0.9238/0.7920 | |
| SignSGD | 0.5699/0.4101 | 0.8542/0.7522 | 0.8525/0.8055 | 0.9657/0.8741 | 0.9968/0.8898 | |
| ASQ | 0.5993/0.5403 | 0.7535/0.8438 | 0.9315/0.8166 | 0.9661/0.9243 | 0.9725/0.9132 | |
| SVHN | QSGD | 0.6074/0.5740 | 0.5740/0.7910 | 0.8982/0.8564 | 0.9508/0.8645 | 0.9186/0.9515 |
| TernGrad | 0.5376/0.3436 | 0.7899/0.6661 | 0.9224/0.6955 | 0.9549/0.7405 | 0.9728/0.8279 | |
| SignSGD | 0.5676/0.5056 | 0.7788/0.7721 | 0.9462/0.9462 | 0.9256/0.8260 | 0.9999/0.9961 | |
| ASQ | 0.6297/0.5220 | 0.8675/0.8119 | 0.9673/0.8898 | 0.9704/0.9311 | 0.9995/0.9667 |
| Metric | Dataset | 20 | 40 | 60 | 80 | 100 |
|---|---|---|---|---|---|---|
| Uncompressed | MNIST | |||||
| CIFAR10 | ||||||
| SVHN | ||||||
| Compressed | MNIST | |||||
| CIFAR10 | ||||||
| SVHN |
| Dataset | Range | Highest Accuracy | Compression Degree | Communication Overhead (Bit) | Average Quantization Bit |
|---|---|---|---|---|---|
| MNIST | (2, 8) | 95.08% | 0.46 | 38,116,540 | 7.00 |
| (4, 8) | 95.98% | 0.46 | 38,116,540 | 7.00 | |
| (6, 8) | 98.63% | 0.40 | 38,661,060 | 8.00 | |
| (1, 16) | 99.33% | 0.25 | 70,787,860 | 13.00 | |
| CIFAR10 | (2, 8) | 82.37% | 0.46 | 38,156,860 | 7.00 |
| (4, 8) | 82.85% | 0.46 | 38,156,860 | 7.00 | |
| (6, 8) | 85.58% | 0.40 | 43,607,840 | 8.00 | |
| (1, 16) | 87.89% | 0.25 | 70,862,740 | 13.00 | |
| SVHN | (2, 8) | 90.69% | 0.46 | 38,156,860 | 7.00 |
| (4, 8) | 90.87% | 0.46 | 38,156,860 | 7.00 | |
| (6, 8) | 92.25% | 0.40 | 43,607,840 | 8.00 | |
| (1, 16) | 95.97% | 0.25 | 79,584,308 | 13.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xing, L.; Luo, Z.; Deng, K.; Wu, H.; Ma, H.; Lu, X. FedHSQA: Robust Aggregation in Hierarchical Federated Learning via Anomaly Scoring-Based Adaptive Quantization for IoV. Electronics 2025, 14, 1661. https://doi.org/10.3390/electronics14081661
Xing L, Luo Z, Deng K, Wu H, Ma H, Lu X. FedHSQA: Robust Aggregation in Hierarchical Federated Learning via Anomaly Scoring-Based Adaptive Quantization for IoV. Electronics. 2025; 14(8):1661. https://doi.org/10.3390/electronics14081661
Chicago/Turabian StyleXing, Ling, Zhaocheng Luo, Kaikai Deng, Honghai Wu, Huahong Ma, and Xiaoying Lu. 2025. "FedHSQA: Robust Aggregation in Hierarchical Federated Learning via Anomaly Scoring-Based Adaptive Quantization for IoV" Electronics 14, no. 8: 1661. https://doi.org/10.3390/electronics14081661
APA StyleXing, L., Luo, Z., Deng, K., Wu, H., Ma, H., & Lu, X. (2025). FedHSQA: Robust Aggregation in Hierarchical Federated Learning via Anomaly Scoring-Based Adaptive Quantization for IoV. Electronics, 14(8), 1661. https://doi.org/10.3390/electronics14081661