
Temporal Map-Based Boundary Refinement Network for Video Moment Localization


Abstract
1. Introduction
- In this paper, a Temporal Map-based Boundary Refinement Network framework is proposed to handle VML tasks. Firstly, in addition to predicting the confidence scores for moment candidates, we introduce a boundary refinement network based on a temporal map to fine-tune the boundaries of these generated moment candidates. Then, to reduce the heavy computation burden, we leverage a multi-step sampling strategy to drop some redundant moment candidates.
- We innovatively design a weighted refinement loss function to guide the model to focus more on the boundary refinement process of those moment candidates closer to the ground truth, thereby further improving the model’s performance.
- Extensive experiments are conducted on two datasets, and the results demonstrate that our proposed model has outperformed the state-of-the-art methods.
2. Related Work
2.1. Text–Video Retrieval
2.2. Temporal Action Localization
2.3. Video Moment Localization
3. Proposed Approach
3.1. Problem Formulation
3.2. Feature Extraction
3.3. Cross-Modal Feature Fusion
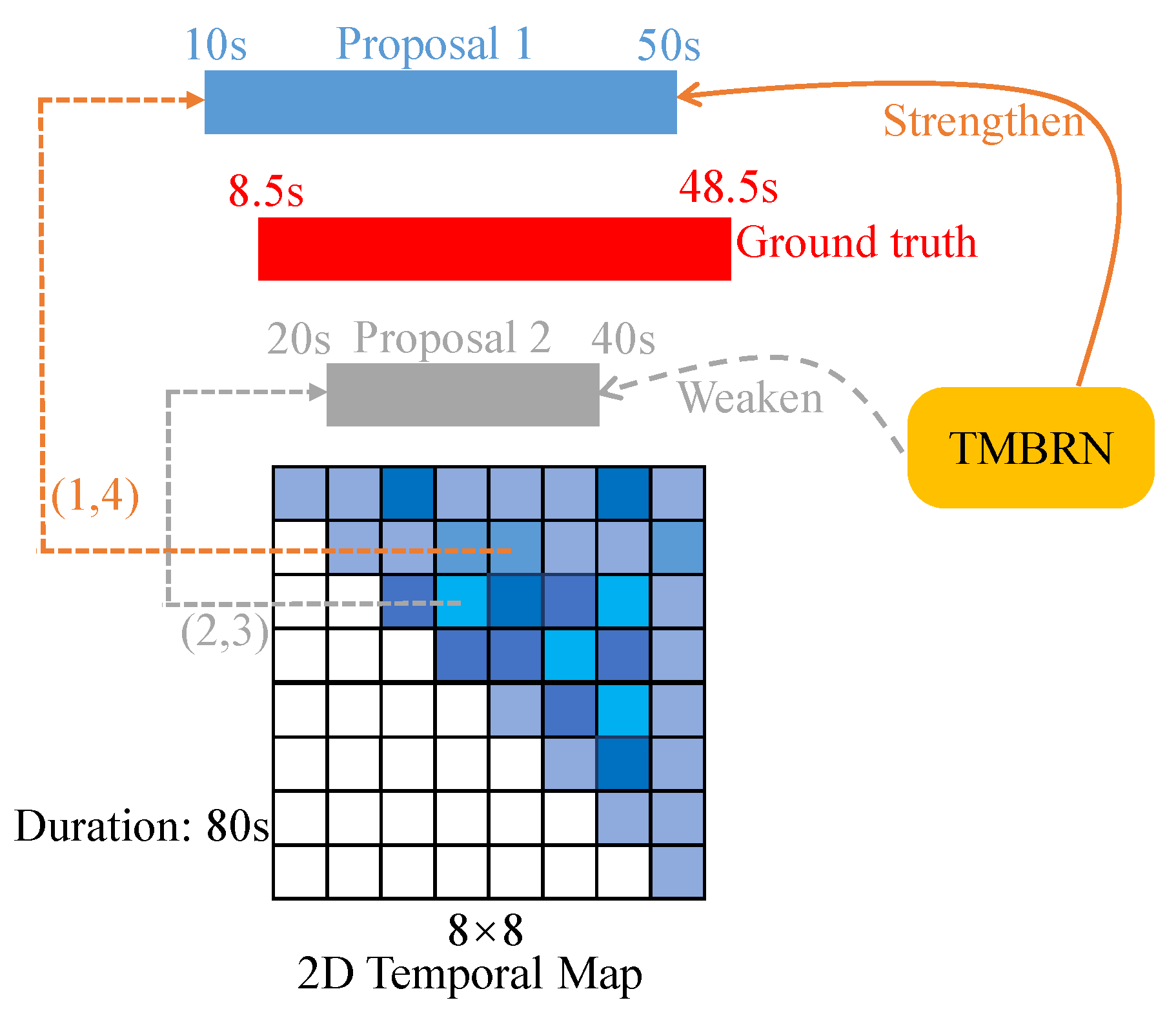
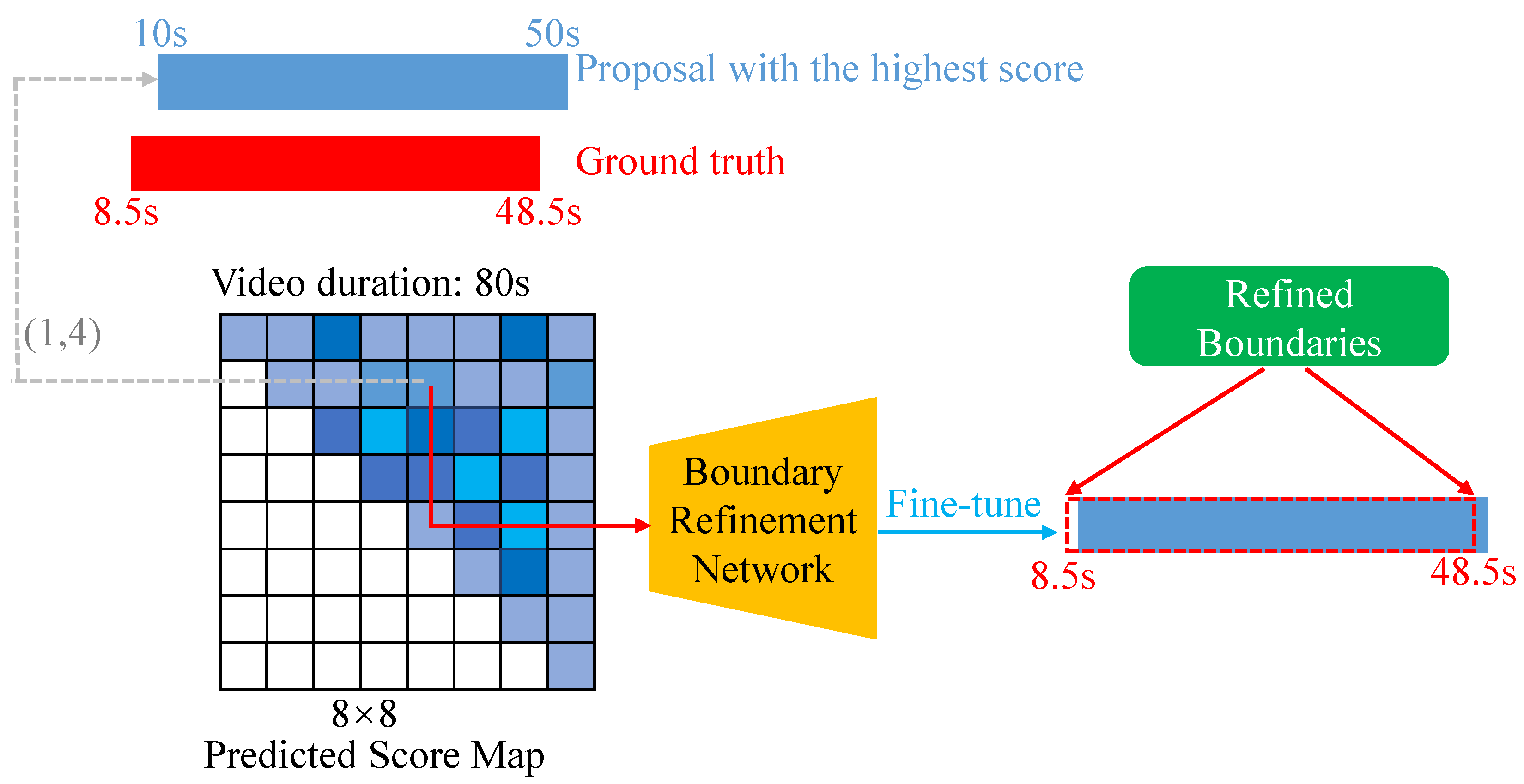
3.4. Boundary Refinement Network
3.5. Loss Function
3.5.1. Alignment Loss
3.5.2. Weighted Refinement Loss
4. Experiments
4.1. Datasets
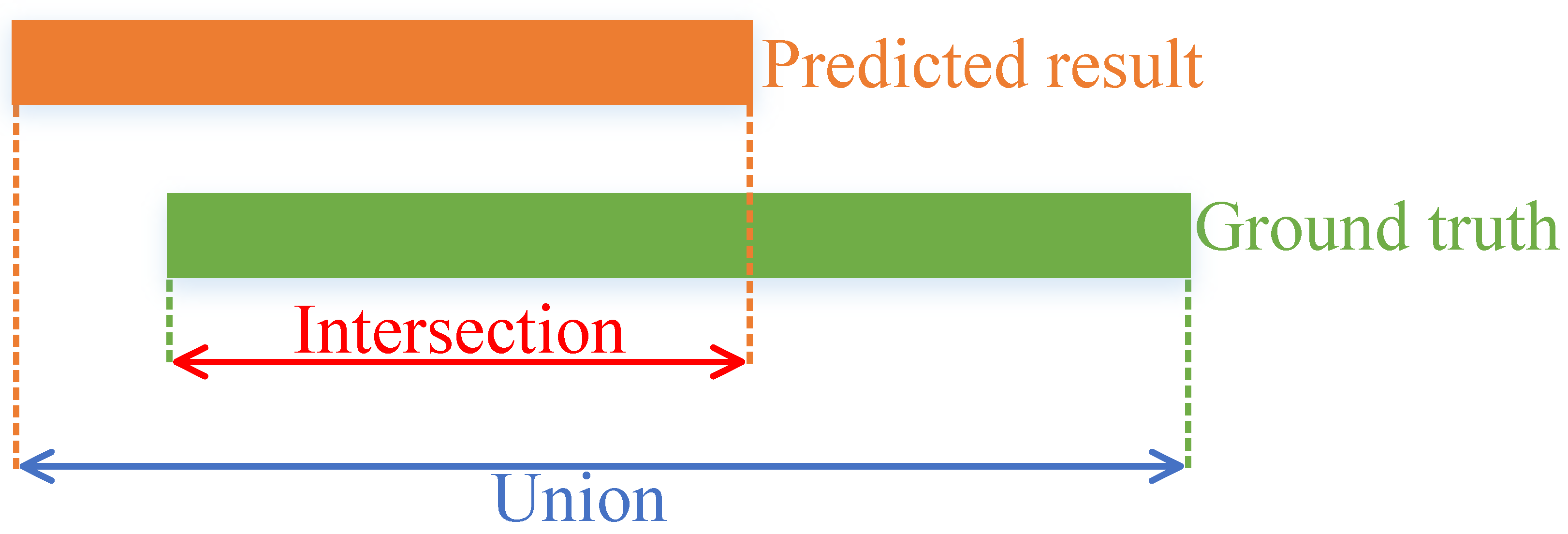
4.2. Evaluation Metrics
4.3. Implementation Details
4.4. Performance Comparison
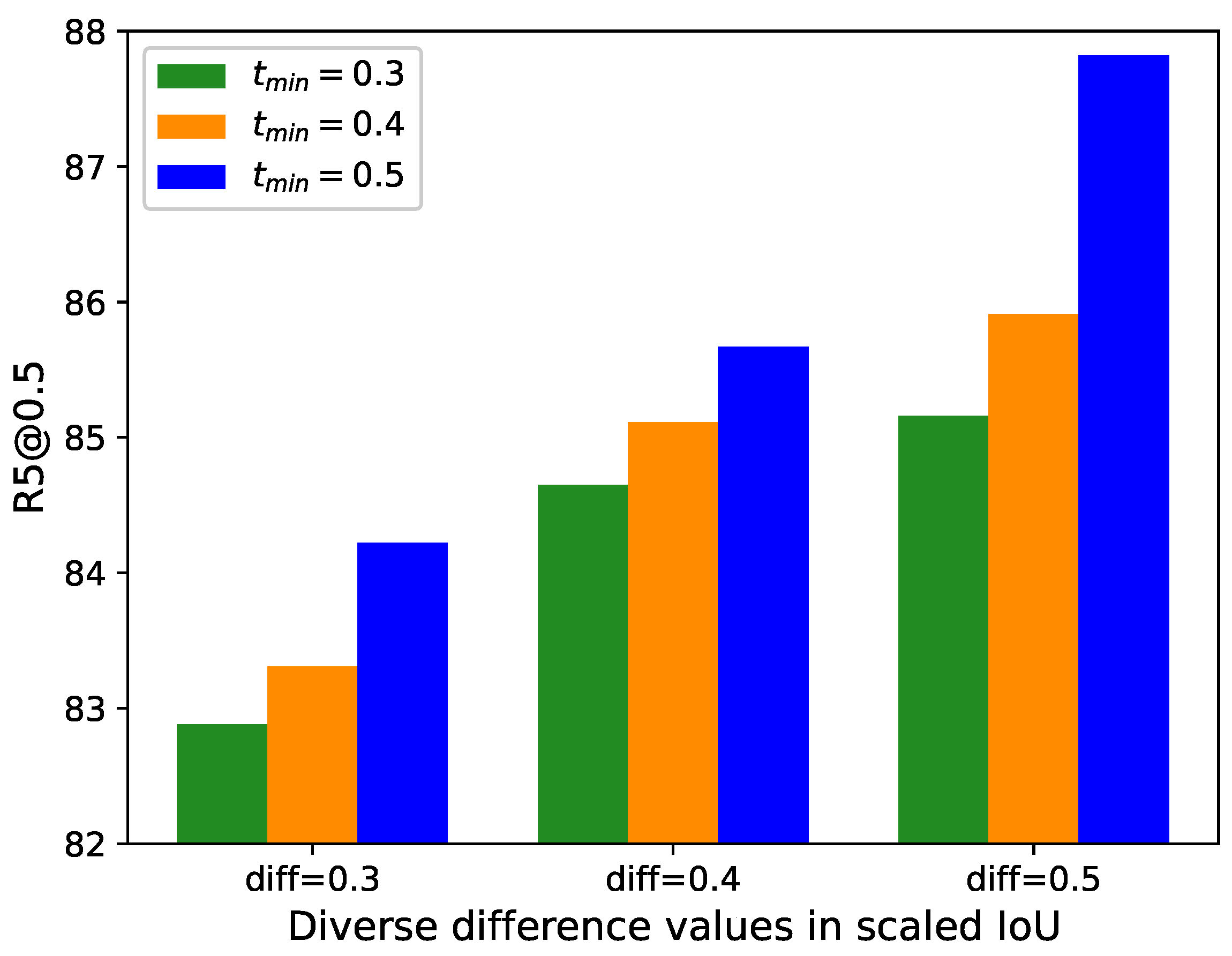
4.5. Ablation Studies
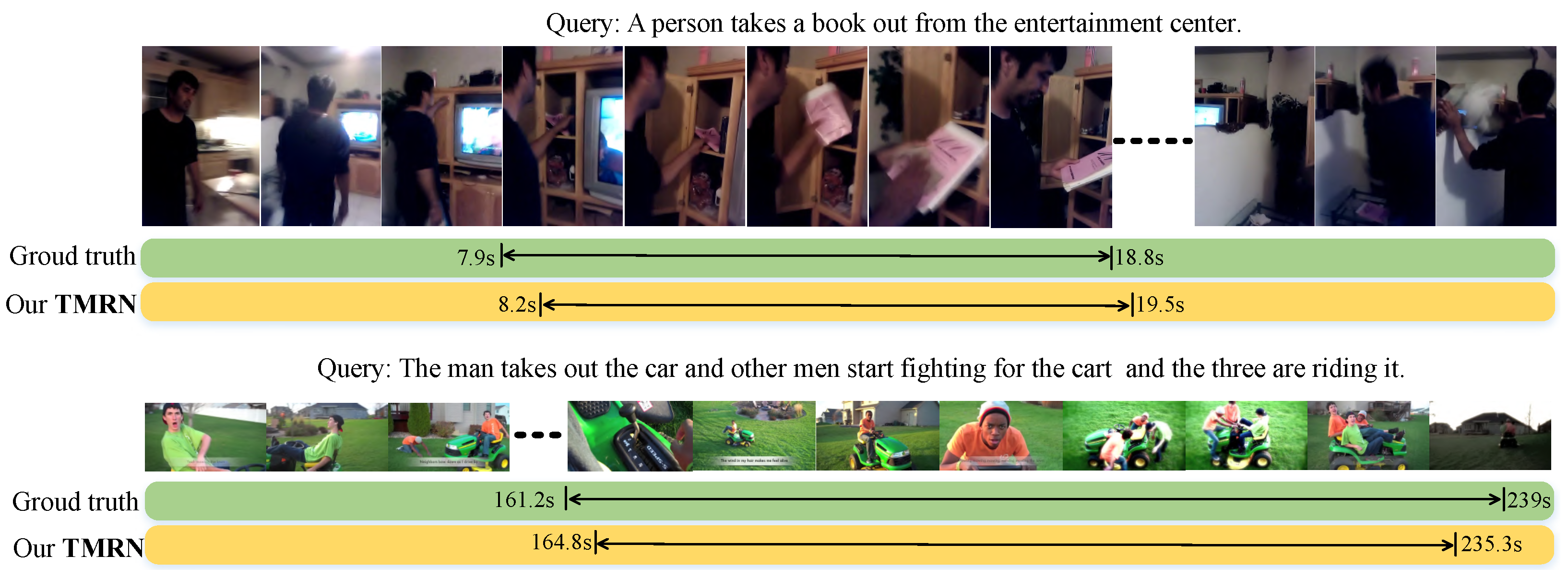
4.6. Visualization Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tian, C.; Zheng, M.; Li, B.; Zhang, Y.; Zhang, S.; Zhang, D. Perceptive self-supervised learning network for noisy image watermark removal. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7069–7079. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, B.; Zhang, W.; Miao, Q. Knowledge Translator: Cross-Lingual Course Video Text Style Transform via Imposed Sequential Attention Networks. Electronics 2025, 14, 1213. [Google Scholar] [CrossRef]
- Tian, C.; Zheng, M.; Zuo, W.; Zhang, S.; Zhang, Y.; Lin, C.W. A cross transformer for image denoising. Inf. Fusion 2024, 102, 102043. [Google Scholar] [CrossRef]
- Liu, J.; Liu, W.; Han, K. MNv3-MFAE: A Lightweight Network for Video Action Recognition. Electronics 2025, 14, 981. [Google Scholar] [CrossRef]
- Zhang, H.; Li, Z.; Yang, J.; Wang, X.; Guo, C.; Feng, C. Revisiting Hard Negative Mining in Contrastive Learning for Visual Understanding. Electronics 2023, 12, 4884. [Google Scholar] [CrossRef]
- Tian, C.; Zhang, X.; Liang, X.; Li, B.; Sun, Y.; Zhang, S. Knowledge distillation with fast CNN for license plate detection. IEEE Trans. Intell. Veh. 2023, 1–7. [Google Scholar] [CrossRef]
- Tian, C.; Xiao, J.; Zhang, B.; Zuo, W.; Zhang, Y.; Lin, C.W. A self-supervised network for image denoising and watermark removal. Neural Netw. 2024, 174, 106218. [Google Scholar] [CrossRef] [PubMed]
- Matsumori, S.; Shingyouchi, K.; Abe, Y.; Fukuchi, Y.; Sugiura, K.; Imai, M. Unified questioner transformer for descriptive question generation in goal-oriented visual dialogue. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1898–1907. [Google Scholar]
- Song, J.; Guo, Y.; Gao, L.; Li, X.; Hanjalic, A.; Shen, H.T. From deterministic to generative: Multimodal stochastic RNNs for video captioning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 3047–3058. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Yang, Y.; Ye, O. Video Captioning Method Based on Semantic Topic Association. Electronics 2025, 14, 905. [Google Scholar] [CrossRef]
- Wang, B.; Yang, Y.; Xu, X.; Hanjalic, A.; Shen, H.T. Adversarial cross-modal retrieval. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; pp. 154–162. [Google Scholar]
- Xu, X.; Wang, T.; Yang, Y.; Zuo, L.; Shen, F.; Shen, H.T. Cross-modal attention with semantic consistence for image–text matching. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 5412–5425. [Google Scholar] [CrossRef] [PubMed]
- Shen, H.T.; Liu, L.; Yang, Y.; Xu, X.; Huang, Z.; Shen, F.; Hong, R. Exploiting subspace relation in semantic labels for cross-modal hashing. IEEE Trans. Knowl. Data Eng. 2020, 33, 3351–3365. [Google Scholar] [CrossRef]
- Wu, G.; Han, J.; Guo, Y.; Liu, L.; Ding, G.; Ni, Q.; Shao, L. Unsupervised deep video hashing via balanced code for large-scale video retrieval. IEEE Trans. Image Process. 2018, 28, 1993–2007. [Google Scholar] [CrossRef] [PubMed]
- Dong, J.; Li, X.; Xu, C.; Ji, S.; He, Y.; Yang, G.; Wang, X. Dual encoding for zero-example video retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9346–9355. [Google Scholar]
- Cao, D.; Yu, Z.; Zhang, H.; Fang, J.; Nie, L.; Tian, Q. Video-based cross-modal recipe retrieval. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1685–1693. [Google Scholar]
- Chen, S.; Zhao, Y.; Jin, Q.; Wu, Q. Fine-grained video-text retrieval with hierarchical graph reasoning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10638–10647. [Google Scholar]
- Yang, X.; Dong, J.; Cao, Y.; Wang, X.; Wang, M.; Chua, T.S. Tree-augmented cross-modal encoding for complex-query video retrieval. In Proceedings of the 43rd international ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual Event, 25–30 July 2020; pp. 1339–1348. [Google Scholar]
- Shou, Z.; Wang, D.; Chang, S.F. Temporal action localization in untrimmed videos via multi-stage cnns. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1049–1058. [Google Scholar]
- Buch, S.; Escorcia, V.; Shen, C.; Ghanem, B.; Carlos Niebles, J. Sst: Single-stream temporal action proposals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2911–2920. [Google Scholar]
- Zeng, R.; Huang, W.; Tan, M.; Rong, Y.; Zhao, P.; Huang, J.; Gan, C. Graph convolutional networks for temporal action localization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7094–7103. [Google Scholar]
- Chen, J.; Chen, X.; Ma, L.; Jie, Z.; Chua, T.S. Temporally grounding natural sentence in video. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 162–171. [Google Scholar]
- Zhang, Z.; Lin, Z.; Zhao, Z.; Xiao, Z. Cross-modal interaction networks for query-based moment retrieval in videos. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 655–664. [Google Scholar]
- Xu, H.; He, K.; Plummer, B.A.; Sigal, L.; Sclaroff, S.; Saenko, K. Multilevel language and vision integration for text-to-clip retrieval. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9062–9069. [Google Scholar]
- Gao, J.; Xu, C. Fast video moment retrieval. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1523–1532. [Google Scholar]
- Yuan, Y.; Mei, T.; Zhu, W. To find where you talk: Temporal sentence localization in video with attention based location regression. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9159–9166. [Google Scholar]
- Lu, C.; Chen, L.; Tan, C.; Li, X.; Xiao, J. Debug: A dense bottom-up grounding approach for natural language video localization. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; pp. 5144–5153. [Google Scholar]
- Mun, J.; Cho, M.; Han, B. Local-global video-text interactions for temporal grounding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10810–10819. [Google Scholar]
- Li, K.; Guo, D.; Wang, M. Proposal-free video grounding with contextual pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 19–21 May 2021; Volume 35, pp. 1902–1910. [Google Scholar]
- He, D.; Zhao, X.; Huang, J.; Li, F.; Liu, X.; Wen, S. Read, watch, and move: Reinforcement learning for temporally grounding natural language descriptions in videos. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8393–8400. [Google Scholar]
- Wu, J.; Li, G.; Liu, S.; Lin, L. Tree-structured policy based progressive reinforcement learning for temporally language grounding in video. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12386–12393. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo vadis, action recognition? a new model and the kinetics dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6299–6308. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Tian, C.; Zheng, M.; Lin, C.W.; Li, Z.; Zhang, D. Heterogeneous window transformer for image denoising. IEEE Trans. Syst. Man Cybern. Syst. 2024, 54, 6621–6632. [Google Scholar] [CrossRef]
- Xiong, C.; Zhong, V.; Socher, R. Dynamic Coattention Networks For Question Answering. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Yu, A.W.; Dohan, D.; Le, Q.; Luong, T.; Zhao, R.; Chen, K. Fast and accurate reading comprehension by combining self-attention and convolution. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018; Volume 2. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional Attention Flow for Machine Comprehension. In Proceedings of the International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Tian, C.; Zheng, M.; Jiao, T.; Zuo, W.; Zhang, Y.; Lin, C.W. A self-supervised CNN for image watermark removal. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7566–7576. [Google Scholar] [CrossRef]
- Gao, J.; Sun, C.; Yang, Z.; Nevatia, R. Tall: Temporal activity localization via language query. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5267–5275. [Google Scholar]
- Krishna, R.; Hata, K.; Ren, F.; Fei-Fei, L.; Carlos Niebles, J. Dense-captioning events in videos. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 706–715. [Google Scholar]
- Sigurdsson, G.A.; Varol, G.; Wang, X.; Farhadi, A.; Laptev, I.; Gupta, A. Hollywood in homes: Crowdsourcing data collection for activity understanding. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 510–526. [Google Scholar]
- Caba Heilbron, F.; Escorcia, V.; Ghanem, B.; Carlos Niebles, J. ActivityNet: A Large-Scale Video Benchmark for Human Activity Understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 961–970. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- Anne Hendricks, L.; Wang, O.; Shechtman, E.; Sivic, J.; Darrell, T.; Russell, B. Localizing moments in video with natural language. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5803–5812. [Google Scholar]
- Liu, M.; Wang, X.; Nie, L.; He, X.; Chen, B.; Chua, T.S. Attentive moment retrieval in videos. In Proceedings of the 41st international ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 15–24. [Google Scholar]
- Liu, M.; Wang, X.; Nie, L.; Tian, Q.; Chen, B.; Chua, T.S. Cross-modal moment localization in videos. In Proceedings of the 26th ACM international Conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 843–851. [Google Scholar]
- Ge, R.; Gao, J.; Chen, K.; Nevatia, R. Mac: Mining activity concepts for language-based temporal localization. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 7–11 January 2019; pp. 245–253. [Google Scholar]
- Chen, S.; Jiang, Y.G. Semantic proposal for activity localization in videos via sentence query. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 8199–8206. [Google Scholar]
- Yuan, Y.; Ma, L.; Wang, J.; Liu, W.; Zhu, W. Semantic conditioned dynamic modulation for temporal sentence grounding in videos. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Peng, H.; Fu, J.; Luo, J. Learning 2d temporal adjacent networks for moment localization with natural language. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12870–12877. [Google Scholar]
- Wang, J.; Ma, L.; Jiang, W. Temporally grounding language queries in videos by contextual boundary-aware prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12168–12175. [Google Scholar]
- Xiao, S.; Chen, L.; Zhang, S.; Ji, W.; Shao, J.; Ye, L.; Xiao, J. Boundary proposal network for two-stage natural language video localization. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtually, 19–21 May 2021; Volume 35, pp. 2986–2994. [Google Scholar]
- Bao, P.; Mu, Y. Learning Sample Importance for Cross-Scenario Video Temporal Grounding. In Proceedings of the 2022 International Conference on Multimedia Retrieval, Newark, NJ, USA, 27–30 June 2022; pp. 322–329. [Google Scholar]
- Li, J.; Zhang, F.; Lin, S.; Zhou, F.; Wang, R. Mim: Lightweight multi-modal interaction model for joint video moment retrieval and highlight detection. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; pp. 1961–1966. [Google Scholar]
- Chen, L.; Lu, C.; Tang, S.; Xiao, J.; Zhang, D.; Tan, C.; Li, X. Rethinking the bottom-up framework for query-based video localization. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10551–10558. [Google Scholar]
- Chen, S.; Jiang, W.; Liu, W.; Jiang, Y.G. Learning modality interaction for temporal sentence localization and event captioning in videos. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 333–351. [Google Scholar]
- Li, S.; Li, C.; Zheng, M.; Liu, Y. Phrase-level Prediction for Video Temporal Localization. In Proceedings of the 2022 International Conference on Multimedia Retrieval, Newark, NJ, USA, 27–30 June 2022; pp. 360–368. [Google Scholar]
- Lv, Z.; Su, B. Temporal-enhanced Cross-modality Fusion Network for Video Sentence Grounding. In Proceedings of the 2023 IEEE International Conference on Multimedia and Expo (ICME), Brisbane, Australia, 10–14 July 2023; pp. 1487–1492. [Google Scholar]
- Wang, Y.; Li, K.; Chen, G.; Zhang, Y.; Guo, D.; Wang, M. Spatiotemporal contrastive modeling for video moment retrieval. World Wide Web 2023, 26, 1525–1544. [Google Scholar] [CrossRef]
- Shi, M.; Su, Y.; Lin, X.; Zao, B.; Kong, S.; Tan, M. Frame as Video Clip: Proposal-Free Moment Retrieval by Semantic Aligned Frames. IEEE Trans. Ind. Inform. 2024, 20, 13158–13168. [Google Scholar] [CrossRef]
- Wang, W.; Huang, Y.; Wang, L. Language-driven temporal activity localization: A semantic matching reinforcement learning model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 334–343. [Google Scholar]
- Hahn, M.; Kadav, A.; Rehg, J.M.; Graf, H.P. Tripping through time: Efficient localization of activities in videos. arXiv 2019, arXiv:1904.09936. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method Types | Methods | Feature | r1@0.5 | r1@0.7 | r5@0.5 | r5@0.7 |
|---|---|---|---|---|---|---|
| Reinforcement learning | RWM | C3D | 34.12 | 13.74 | - | - |
| TripNet | 38.29 | 16.07 | - | - | ||
| TSP-PRL | 37.39 | 17.69 | - | - | ||
| Proposal-free | DEBUG | C3D | 37.39 | 17.69 | - | - |
| GDP | 39.47 | 18.49 | - | - | ||
| PMI | 39.73 | 19.27 | - | - | ||
| STCNet | 38.44 | 20.73 | - | - | ||
| FVC | 41.56 | 22.61 | - | - | ||
| Proposal-based | CTRL | C3D | 23.63 | 8.89 | 58.92 | 29.52 |
| ACRN | 20.26 | 7.64 | 71.99 | 27.79 | ||
| ROLE | 12.12 | - | 40.59 | - | ||
| MAC | 30.48 | 12.2 | 64.84 | 35.13 | ||
| QSPN | 35.6 | 15.8 | 79.4 | 45.4 | ||
| CBP | 36.8 | 18.87 | 70.94 | 50.19 | ||
| BPNet | 38.25 | 20.51 | - | - | ||
| FVMR | 38.16 | 18.22 | 82.18 | 44.96 | ||
| TMBRN | 42.33 | 23.28 | 87.82 | 52.2 | ||
| Reinforcement learning | SM-RL | VGG | 24.36 | 11.17 | 61.25 | 32.08 |
| Proposal-free | ABLR | VGG | 24.36 | 9.01 | - | - |
| PLPNet | 41.88 | 20.56 | - | - | ||
| Proposal-based | MCN | VGG | 17.46 | 8.01 | 48.22 | 26.73 |
| SAP | 27.42 | 13.36 | 66.37 | 38.15 | ||
| 2D-TAN | 39.70 | 23.31 | 80.32 | 51.26 | ||
| MIM | 43.92 | 25.89 | 87.07 | 52.26 | ||
| TMBRN | 45.14 | 27.03 | 88.49 | 53.31 |
| Method Types | Methods | Feature | R1@0.3 | R1@0.5 | R1@0.7 | R5@0.3 | R5@0.5 | R5@0.7 |
|---|---|---|---|---|---|---|---|---|
| Reinforcement learning | RWM | C3D | - | 36.9 | - | - | - | - |
| TripNet | 48.42 | 32.19 | 13.93 | - | - | - | ||
| TSP-PRL | 56.08 | 38.76 | - | - | - | - | ||
| Proposal-free | DEBUG | C3D | 55.91 | 39.72 | - | - | - | - |
| ABLR | 55.67 | 36.79 | - | - | - | - | ||
| GDP | 56.17 | 39.27 | - | - | - | - | ||
| LGI | 58.52 | 41.51 | 23.07 | - | - | - | ||
| PMI | 59.69 | 38.28 | 17.83 | - | - | - | ||
| CPNet | - | 40.56 | 21.63 | - | - | - | ||
| PLPNet | 56.92 | 39.20 | 20.91 | - | - | - | ||
| TCFN | 56.81 | 40.58 | 24.73 | 67.87 | 55.51 | 39.42 | ||
| STCNet | - | 40.15 | 21.85 | - | - | - | ||
| FVC | 63.59 | 46.32 | 26.01 | - | - | - | ||
| Proposal-based | CTRL | C3D | 47.43 | 29.01 | 10.34 | 75.32 | 59.17 | 37.54 |
| MCN | 39.35 | 21.36 | 6.43 | 68.12 | 53.23 | 29.70 | ||
| ACRN | 49.70 | 31.67 | 11.25 | 76.50 | 60.34 | 38.57 | ||
| TGN | 43.81 | 27.93 | - | 54.56 | 44.20 | - | ||
| SCDM | 54.80 | 36.75 | 19.86 | 77.29 | 64.99 | 41.53 | ||
| QSPN | 52.13 | 33.26 | 13.43 | 77.72 | 62.39 | 40.78 | ||
| 2D-TAN | 59.45 | 44.51 | 26.54 | 85.53 | 77.13 | 61.96 | ||
| CBP | 54.30 | 35.76 | 17.80 | 77.63 | 65.89 | 46.20 | ||
| BPNet | 58.98 | 42.07 | 24.69 | - | - | - | ||
| TLL | - | 44.24 | 27.01 | - | 75.22 | 60.23 | ||
| TMBRN | 64.51 | 47.02 | 28.26 | 85.89 | 77.22 | 62.32 |
| Method | R1@0.5 | R1@0.7 | R5@0.5 | R5@0.7 |
|---|---|---|---|---|
| TMBRN w/o WF | 32.12 | 15.46 | 38.68 | 18.92 |
| TMBRN w/ WF(OIoU) | 36.34 | 19.11 | 82.50 | 44.33 |
| TMBRN | 42.33 | 23.28 | 87.82 | 52.2 |
| Method | R1@0.3 | R1@0.5 | R1@0.7 | R5@0.3 | R5@0.5 | R5@0.7 |
|---|---|---|---|---|---|---|
| TMBRN w/o WF | 52.60 | 35.54 | 17.63 | 65.07 | 49.64 | 29.39 |
| TMBRN w/ WF(OIoU) | 54.68 | 40.11 | 23.21 | 82.90 | 72.17 | 53.36 |
| TMBRN | 64.51 | 47.02 | 28.26 | 85.89 | 77.22 | 62.32 |
| Method | R1@0.5 | R1@0.7 | R5@0.5 | R5@0.7 |
|---|---|---|---|---|
| TMBRN w/o scaled IoU | 34.70 | 17.39 | 75.22 | 40.51 |
| TMBRN | 42.33 | 23.28 | 87.82 | 52.2 |
| Method | R1@0.3 | R1@0.5 | R1@0.7 | R5@0.3 | R5@0.5 | R5@0.7 |
|---|---|---|---|---|---|---|
| TMBRN w/o scaled IoU | 53.83 | 38.58 | 20.51 | 78.18 | 67.24 | 49.95 |
| TMBRN | 64.51 | 47.02 | 28.26 | 85.89 | 77.22 | 62.32 |
| Method | R1@0.3 | R1@0.5 | R1@0.7 | R5@0.3 | R5@0.5 | R5@0.7 |
|---|---|---|---|---|---|---|
| TMBRN w/ CTRL | 56.30 | 41.07 | 24.91 | 83.19 | 72.48 | 53.91 |
| TMBRN w/ CA | 56.89 | 42.47 | 26.13 | 83.40 | 74.02 | 57.69 |
| TMBRN | 64.51 | 47.02 | 28.26 | 85.89 | 77.22 | 62.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lyu, L.; Liu, D.; Zhang, C.; Zhang, Y.; Ruan, H.; Zhu, L. Temporal Map-Based Boundary Refinement Network for Video Moment Localization. Electronics 2025, 14, 1657. https://doi.org/10.3390/electronics14081657
Lyu L, Liu D, Zhang C, Zhang Y, Ruan H, Zhu L. Temporal Map-Based Boundary Refinement Network for Video Moment Localization. Electronics. 2025; 14(8):1657. https://doi.org/10.3390/electronics14081657
Chicago/Turabian StyleLyu, Liang, Deyin Liu, Chengyuan Zhang, Yilin Zhang, Haoyu Ruan, and Lei Zhu. 2025. "Temporal Map-Based Boundary Refinement Network for Video Moment Localization" Electronics 14, no. 8: 1657. https://doi.org/10.3390/electronics14081657
APA StyleLyu, L., Liu, D., Zhang, C., Zhang, Y., Ruan, H., & Zhu, L. (2025). Temporal Map-Based Boundary Refinement Network for Video Moment Localization. Electronics, 14(8), 1657. https://doi.org/10.3390/electronics14081657