1. Introduction
Speech enhancement (SE) has seen remarkable progress in recent years, evolving from traditional statistics-based methods to advanced deep learning techniques. This transition has significantly improved the ability to enhance speech intelligibility and quality in complex noisy environments. Deep Neural Networks (DNNs) have been at the forefront of this revolution, enabling models to learn intricate patterns from large datasets and outperform conventional approaches in separating speech from noise [
1,
2,
3,
4,
5,
6].
The field has witnessed several breakthrough innovations. Hybrid architectures, such as the TRAMBA model [
7], combine transformers and Mamba deep learning models to enhance both acoustic and bone conduction speech, achieving high-quality enhancement with a small memory footprint suitable for mobile devices. End-to-end systems have gained prominence, with frameworks like [
8] mapping noisy audio directly to enhanced audio without intermediate representations. Attention mechanisms have further refined SE performance by dynamically focusing on relevant input features [
9].
Innovative models like GaGNet [
10] and TaylorSENet [
11] have pushed the boundaries of the field by employing guided learning mechanisms and efficient gating structures for real-time processing. Mixed-domain approaches, combining time-domain and time–frequency-domain frameworks, have enhanced both magnitude and phase representations of speech signals, yielding superior results across various metrics.
To meet real-time demands, researchers have optimized DNN architectures for efficiency. For instance, [
12] introduced a lightweight network that maintains high performance while significantly reducing computational complexity, making it ideal for practical applications.
State-of-the-art deep learning SE techniques can be broadly categorized into several approaches:
Masking-based methods estimate time–frequency masks to suppress noise and enhance speech. Recent advancements include complex-valued masks for modifying both magnitude and phase [
13], attention mechanisms focusing on relevant time-frequency regions [
14], and multi-task learning to jointly optimize speech quality and intelligibility [
15].
Mapping-based techniques directly estimate clean speech features from noisy inputs. Modern approaches encompass end-to-end models operating on raw waveforms [
16], generative adversarial networks (GANs) for realistic speech reconstruction [
17], and self-supervised pre-training leveraging large unlabeled datasets [
18].
Advanced architectures pushing the state-of-the-art include Conformer-based models combining convolution and self-attention [
19], diffusion probabilistic models for high-quality speech generation [
20], and adaptive convolution networks that dynamically adjust to input characteristics [
21].
In particular, when using a complex-valued STFT spectrogram as the main feature for speech enhancement, a series of advanced frameworks have been presented recently. For example, CFTNet (Complex Frequency Transformation Network) [
22] leverages a complex-valued U-Net and frequency transformation blocks to capture contextual information, achieving significant improvements over state-of-the-art methods by effectively recovering speech from noisy spectrograms without creating musical artifacts. AERO [
23] (Audio Super-Resolution in the Spectral Domain) is an audio super-resolution model operating in the spectral domain. It uses an encoder–decoder architecture with U-Net-like skip connections to process complex-valued spectrograms. AERO optimizes performance with a combination of time- and frequency-domain loss functions, achieving superior results in speech and music enhancement across various sample rates. DCCTN (Deep Complex Convolution Transformer Network) [
24] is a speech enhancement framework designed to address challenges faced by cochlear implant (CI) users in noisy environments by jointly enhancing both magnitude and phase components of speech signals. DCCTN combines a complex-valued U-Net with a transformer-based bottleneck layer and frequency transformation blocks to capture harmonic correlations and contextual time–frequency details, enabling accurate reconstruction of clean speech from noisy inputs. Unlike conventional methods that focus solely on magnitude, DCCTN employs multi-task learning to optimize spectral accuracy and perceptual quality simultaneously.
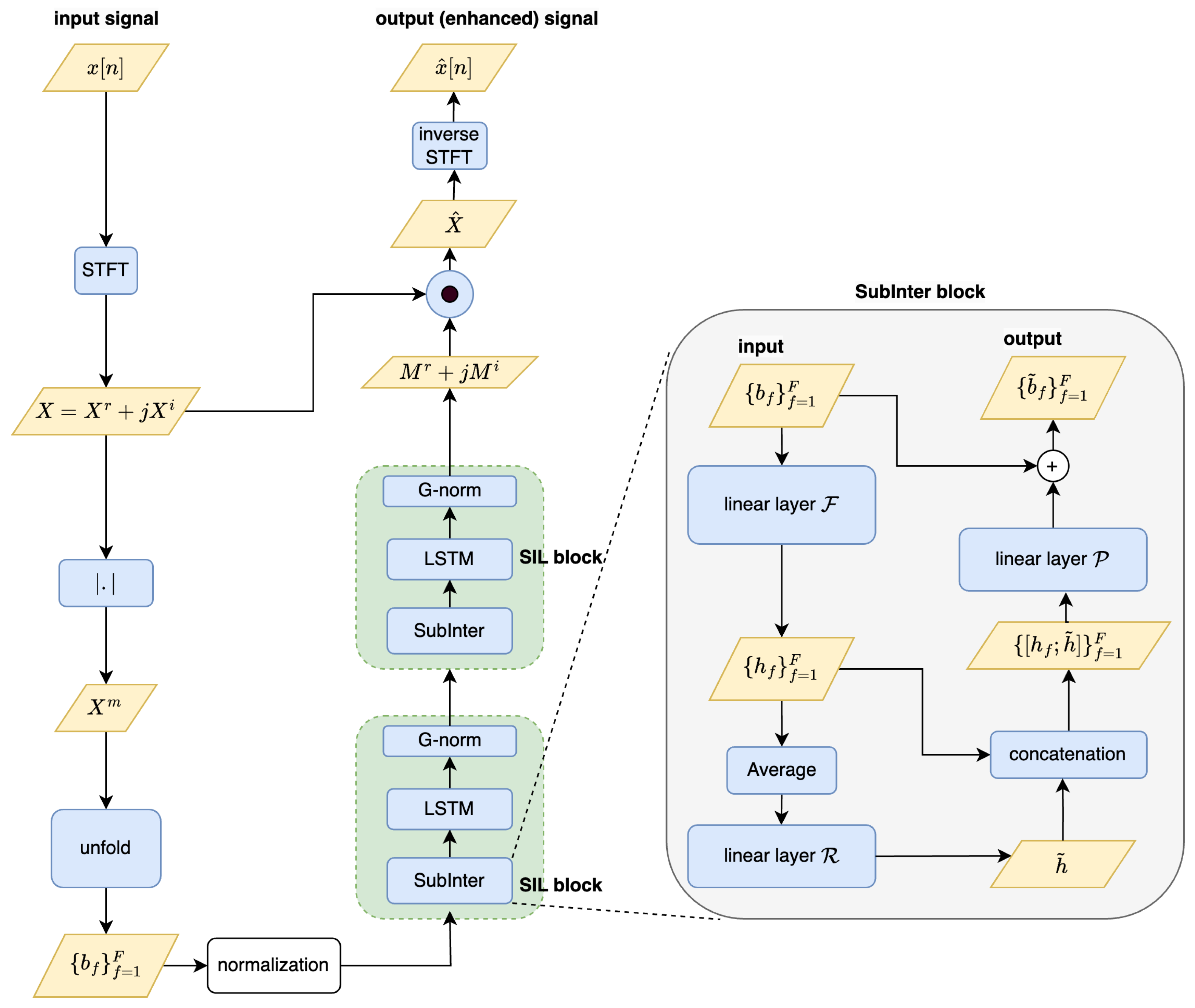
Among recent advancements in deep neural network-based speech enhancement systems, Inter-SubNet [
25] stands out for its innovative approach. This architecture refines and streamlines its predecessors, FullSubNet [
26] and FullSubNet+ [
27], achieving superior performance with a significantly smaller model size. Although it primarily uses magnitude spectrograms as input, Inter-SubNet is also a complex-valued speech enhancement network that effectively addresses phase reconstruction. This is made possible by its use of a complex ideal ratio mask (cIRM) [
13], which modifies both the magnitude and phase components of the original complex spectrogram. The cIRM is generated through a hierarchical process involving the SubInter modules and LSTM layers, which process the input magnitude spectrogram. By applying the cIRM to the complex spectrogram, Inter-SubNet enhances both the amplitude and temporal characteristics of the speech signal, showcasing its ability to handle phase reconstruction efficiently. This approach enables Inter-SubNet to benefit from complex-valued processing while maintaining a lightweight architecture suitable for real-time applications.
Inter-SubNet’s key innovation lies in balancing high-quality enhancement with reduced model complexity, addressing critical challenges in real-time processing and deployment on resource-constrained devices. Rigorous evaluations using the DNS Challenge dataset have consistently demonstrated Inter-SubNet’s superiority over other leading methods, including DCCRN-E [
28], Conv-TasNet [
16], PoCoNet [
29], DCCRN+ [
30], TRU-Net [
31], and CTS-Net [
32].
This study proposes enhancing Inter-SubNet by incorporating a Multi-view Attention (MA) network, a crucial element of the MANNER architecture [
33]. The MA module extracts and combines key information from input spectrograms across three dimensions: global time context, local spectral patterns, and channel-wise features. This comprehensive approach aims to enhance the model’s capacity to identify and maintain speech components while effectively reducing noise.
In particular, we introduce two integration strategies:
IS-IMA (Inter-SubNet with Internal MA): Incorporates the MA module at the initial stage of Inter-SubNet.
IS-EMA (Inter-SubNet with External MA): Positions the MA module at an intermediate stage of Inter-SubNet.
These enhanced models are expected to achieve more refined and precise speech enhancement by employing attention mechanisms designed to concentrate on the most significant spectrogram elements. This integration combines Inter-SubNet’s efficient structure with MA’s advanced feature extraction capabilities, potentially leading to improved performance in speech enhancement tasks.
To briefly sum up, the presented new framework in this study has the following key contributions:
Novel Integration Strategies: We propose two distinct approaches (IS-IMA and IS-EMA) for integrating the MA module into the Inter-SubNet framework, enhancing its speech enhancement capabilities.
Improved Performance: IS-IMA and IS-EMA demonstrate improvements over the baseline Inter-SubNet across various speech enhancement metrics, particularly in PESQ, STOI, and SI-SDR.
Efficient Architecture: The proposed models achieve performance gains with a relatively small increase in model parameters, maintaining computational efficiency.
Comprehensive Ablation Study: We conduct a detailed analysis of different attention configurations (channel-only, global-only, local-only) for both IS-IMA and IS-EMA, providing insights into the effectiveness of each attention mechanism.
Adaptability: The IS-EMA model, particularly, shows strong performance when isolating specific attention views, demonstrating its adaptability to different speech enhancement requirements.
The remainder of this paper is organized as follows:
Section 2 and
Section 3 provide a brief overview of the two backbone modules, Inter-SubNet and the MA block.
Section 4 introduces the two newly proposed architectures that integrate Inter-SubNet and MA. The experimental setup, results, and discussions regarding the comparison methods are presented in
Section 5 and
Section 6. Lastly,
Section 7 concludes the paper with a summary.
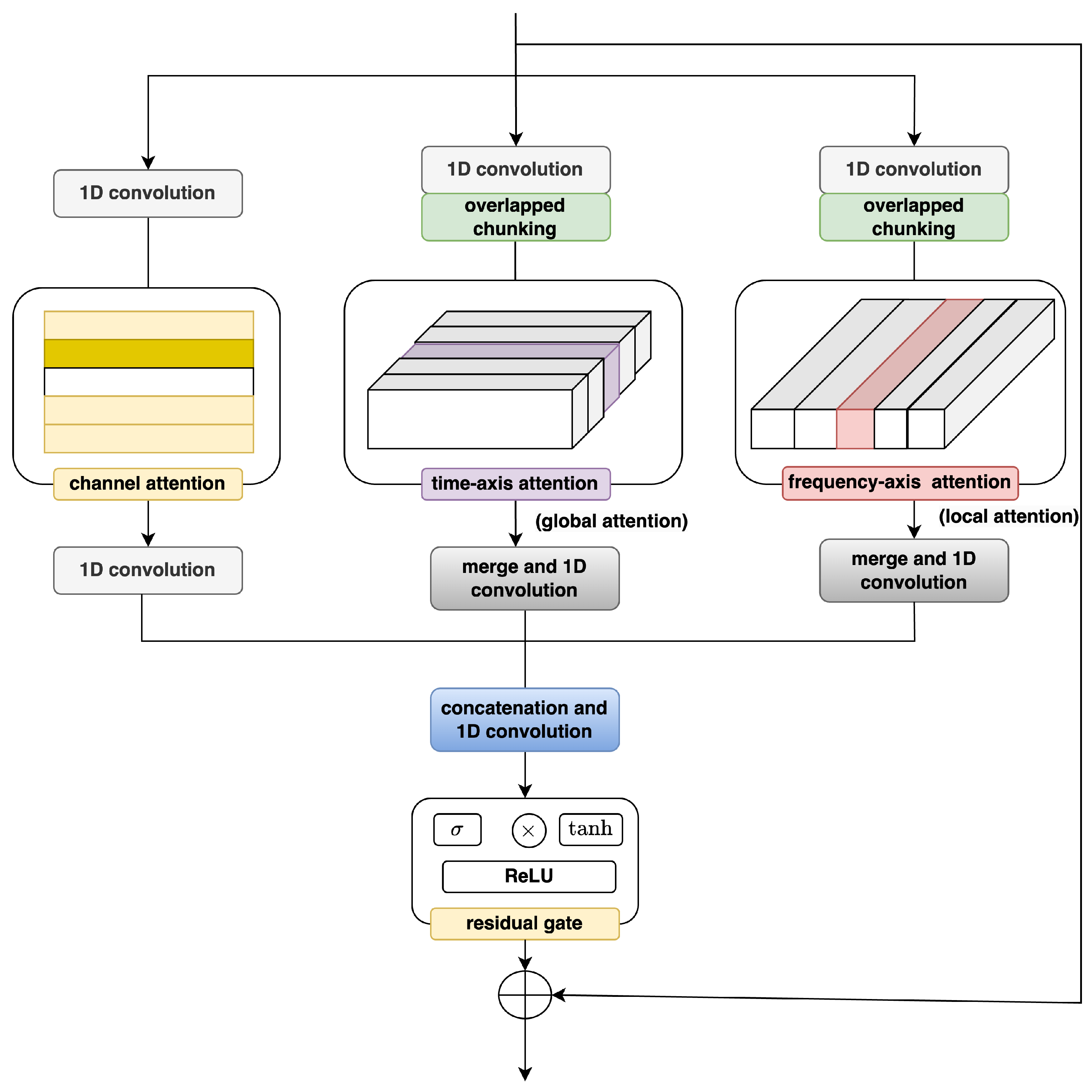
3. Multi-View Attention Module
The Multi-view Attention (MA) block, a key component of the MANNER speech enhancement framework [
33], operates within a convolutional encoder–decoder framework. Its primary function is to extract and process three distinct perspectives of the noisy speech signal: channel view, global view, and local view.
By leveraging attention mechanisms across these multiple viewpoints, the MA block highlights critical features, resulting in a more comprehensive and precise representation of the speech signal. Specifically, channel attention enhances representations derived from compressed channels, while a dual-path mechanism incorporating both global and local attention effectively captures extended sequential features. This multi-faceted approach allows the MA block to synthesize a rich, context-aware representation of the speech signal, potentially leading to more effective noise suppression and speech enhancement. The structure and operation of the MA block are visually depicted in
Figure 2.
The MA block in the MANNER framework [
33] transforms latent representations through three parallel processing pathways. The input signal first undergoes channel reduction through convolutional layers that compress the channel dimension from
C to
in each pathway. For global and local processing streams, the reduced features are partitioned into overlapping chunks through a
overlap operation, reformatting the input as
where
P denotes chunk size and
S the number of chunks. This structural separation enables efficient handling of both extended temporal patterns and localized spectral features.
The channel attention pathway enhances compressed channel representations through dual pooling operations. For input
, average and max pooling generate aggregated descriptors
and
. These descriptors are processed through a dense network with
hidden nodes and sigmoid activation to compute attention weights:
where
and
represent network parameters. The resulting weights are broadcast temporally and applied to the original features to produce refined channel representations
.
The global attention pathway employs Transformer-based multi-head self-attention on chunked inputs
. The mechanism computes the following:
where the
Q,
K, and
V matrices derive from linear projections of the input, enabling cross-chunk dependency modeling through scaled dot-product attention.
Local feature processing utilizes depthwise convolution with
kernels on chunked inputs
. Concatenated average and max pooling outputs feed into a convolutional layer generating attention weights:
These weights modulate the original features through element-wise multiplication:
Final integration occurs through concatenation of all pathway outputs followed by convolutional blending. A residual gating mechanism combining sigmoid, tanh, and ReLU activations refines the combined features before residual summation with the original input completes the transformation. This multi-view architecture enables simultaneous exploitation of channel-wise relationships, global temporal dependencies, and local spectral patterns for comprehensive speech representation learning.
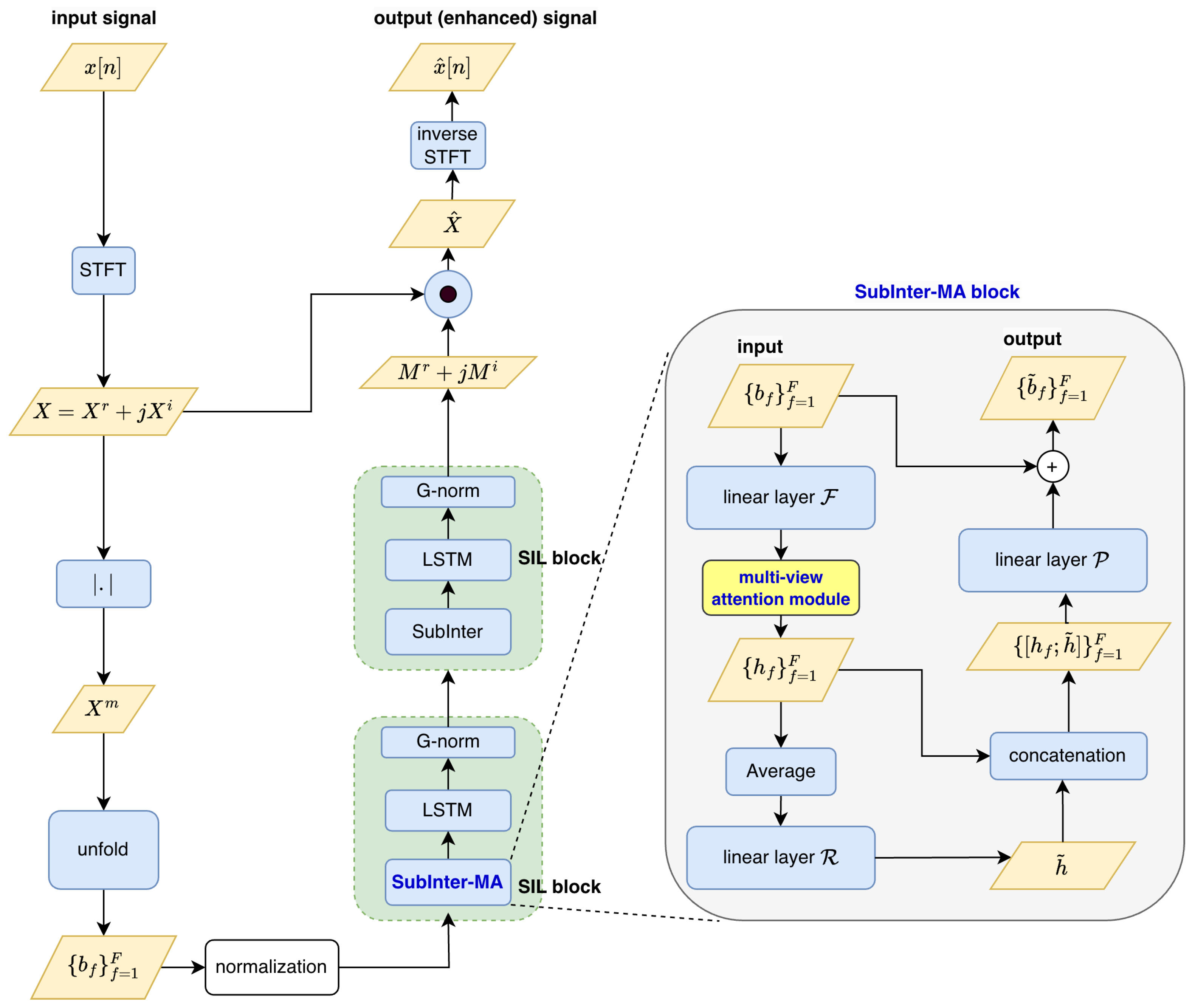
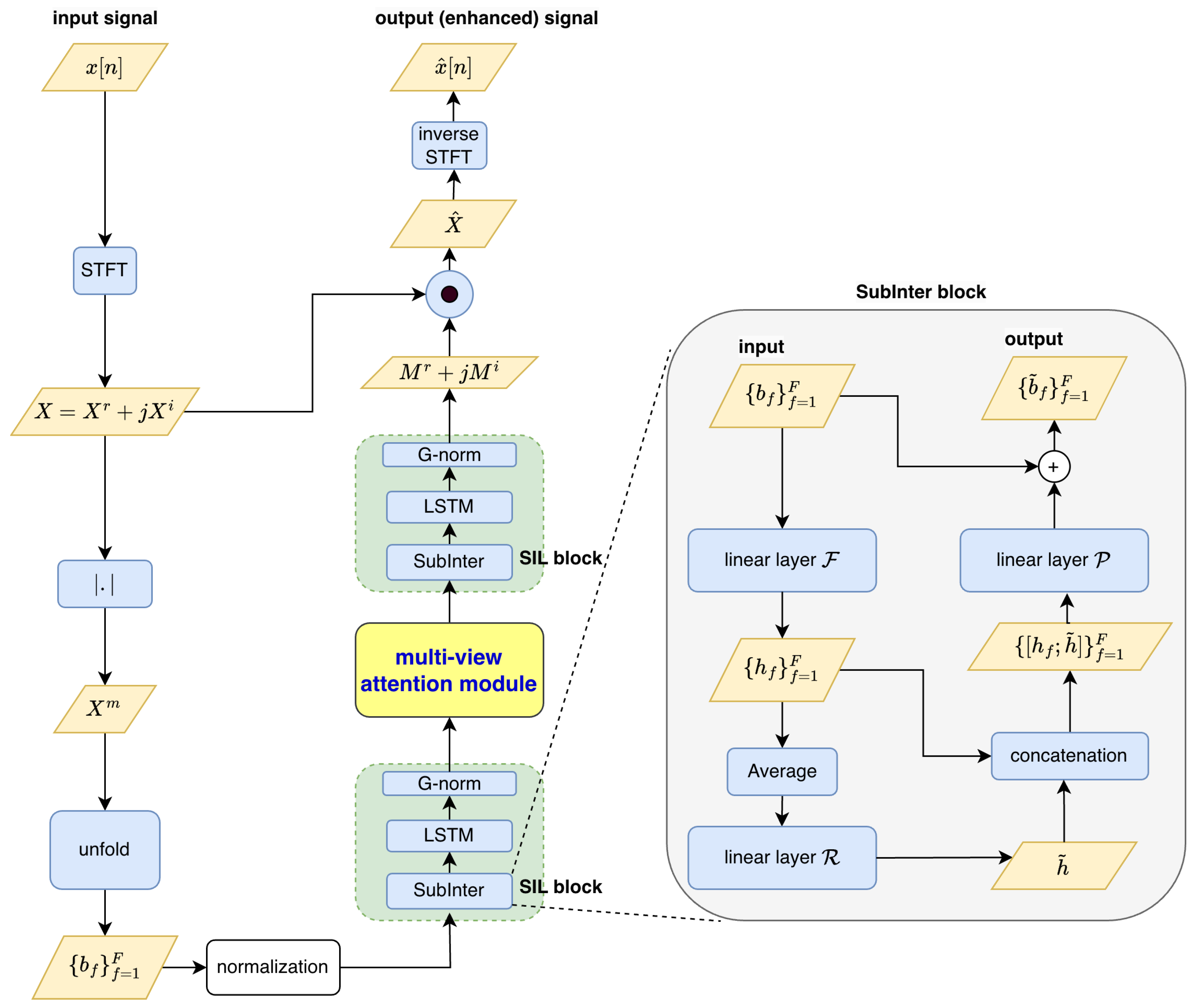
4. Presented Method: MA-Equipped Inter-SubNet
In this work, we propose integrating the MA module into Inter-SubNet to achieve improved speech enhancement performance. Two integration strategies are designed, as illustrated in
Figure 3 and
Figure 4, and are described as follows:
The strategies for integrating MA mechanisms into the InterSubnet framework show key differences that affect how they process information. These differences mainly relate to where the attention mechanism is placed in the signal pathway and how they handle features:
The first major difference is where the MA module is located in relation to feature transformations. In the IS-IMA approach, the MA block works right after the linear transformation of sub-channel features, meaning it processes pure sub-band features. In contrast, IS-EMA waits until after the first SIL block to apply MA, which means it deals with features that already include both sub-band details and global spectral patterns.
The second difference is how they interact with residual pathways. IS-IMA uses a parallel processing method where the original sub-band features skip the MA-enhanced main pathway through residual connections. On the other hand, IS-EMA places its MA module before the second SIL block, allowing both main and residual pathways to be influenced by attention-modified features.
These structural differences lead to different learning behaviors during model training. IS-IMA’s approach keeps raw sub-band features in residual paths, which might improve gradient flow and maintain high-frequency details. Meanwhile, IS-EMA’s use of MA could enable more complex interactions between features but may also increase complexity. Testing these approaches would help understand their trade-offs across various applications and datasets.
In the following, we further investigate the potential advantage and limitation of the presented two strategies:
Strategy I places the MA block before the first SIL block in Inter-SubNet, enabling it to preprocess input features. This early placement helps the MA block emphasize important features and filter out irrelevant ones, providing SIL blocks with cleaner inputs, which can improve performance in noisy conditions.
However, this approach has drawbacks. Since the MA block processes raw input, it may miss out on the refined sub-band features produced by the initial SIL block. As a result, it might focus on less useful or noisy elements, reducing its effectiveness and causing weaker interaction with later SIL blocks, limiting performance improvements.
Strategy II places the MA module between the two SIL blocks in Inter-SubNet, refining intermediate features by processing the structured subband representations from the first SIL block. This helps the MA module focus on both local and global spectral information, aligning enhanced features with the speech enhancement task before passing them to the second SIL block, potentially improving performance.
However, since it skips raw input features and processes only intermediate outputs, Strategy II may have reduced effectiveness in refining low-level features and could introduce inefficiencies in the processing pipeline.
5. Experimental Setup
To assess the effectiveness of the proposed method, we utilize the VoiceBank-DEMAND dataset [
34,
35], which combines speech from VoiceBank with noise from the DEMAND database. The training set consists of 11,572 utterances from 28 speakers, while the test set includes 824 utterances from 2 speakers. The training data are corrupted with ten types of DEMAND noise at four signal-to-noise ratios (SNRs): 0, 5, 10, and 15 dB. The test set uses five different DEMAND noises at SNRs of 2.5, 7.5, 12.5, and 17.5 dB, with approximately 200 utterances reserved for validation.
For the Inter-SubNet framework, we set the following parameters: a Hanning window of 32 ms frame size with a 16 ms frame shift is used to generate spectrograms; the sub-band unit consists of frequency bins; the input–target sequence length during training is frames; the first SIL block has 102 hidden units in the SubInter module and 384 hidden units in the LSTM; the second SIL block has 307 hidden units in the SubInter module and 384 hidden units in the LSTM; and the batch size is reduced to two due to GPU limitations.
The MA block parameters include a channel count (CM) of 512, four attention heads, attention dimensions of 256, and an attention dropout rate of 0.1.
To assess the SE performance of the comparison models, several objective metrics are used:
Perceptual Evaluation of Speech Quality (PESQ) [
36]: This metric measures the quality difference between enhanced and clean speech signals, ranging from
to 4.5, with higher values indicating better quality.
Short-time objective intelligibility (STOI) [
37]: STOI evaluates the intelligibility of short-time time–frequency regions in an utterance using discrete-time Fourier transform (DFT). It ranges from 0 to 1, where higher scores indicate better intelligibility.
Scale-invariant signal-to-distortion ratio (SI-SNR) [
38]: This metric quantifies the distortion between the processed utterance
and its clean counterpart
. It is calculated as follows:
where
with
being the inner product of
and
.
Composite Measure for Overall Quality (COVL) [
39]: COVL predicts the Mean Opinion Score (MOS) for overall speech quality, ranging from 0 to 5. Higher scores reflect better perceived quality by listeners.
Composite Measure for Signal Distortion (CSIG): [
37]: CSIG predicts MOS for signal distortion, also ranging from 0 to 5. Higher scores indicate less distortion and better preservation of the original speech signal during enhancement.
6. Results and Discussions
6.1. Overall Performance Evaluation
Table 1 presents the performance comparison of three models: Inter-SubNet (baseline), IS-IMA, and IS-EMA, across various metrics commonly used in speech enhancement (SE) tasks. Below is an analysis and discussion of the results:
In terms of PESQ, which measures perceived speech quality, both IS-IMA and IS-EMA demonstrate slight improvements over the baseline, achieving a score of 3.590 compared to 3.584. Although the improvement is marginal, it indicates progress in enhancing the perceived quality of speech.
For STOI, a metric that evaluates speech intelligibility, both proposed models outperform the baseline, with IS-IMA scoring 0.942 and IS-EMA achieving the highest score of 0.946. This suggests that IS-EMA significantly enhances intelligibility compared to both the baseline and IS-IMA. However, when it comes to SI-SDR, which measures signal reconstruction accuracy, the results are mixed. While IS-IMA slightly underperforms relative to the baseline (18.504 versus 18.646), IS-EMA surpasses both with a score of 18.782, indicating its superior capability in reconstructing signals.
The COVL metric, which reflects overall quality, presents a different trend. IS-IMA improves upon the baseline score of 3.429 by reaching 3.469, but IS-EMA experiences a decline to 3.286, suggesting a trade-off in overall quality for other performance gains. Similarly, for CSIG, which evaluates signal distortion, IS-IMA achieves the best score at 4.058, surpassing both the baseline (4.012) and IS-EMA (3.959). This highlights IS-IMA’s strength in handling signal distortion effectively.
The placement of the MA module significantly affects performance. IS-EMA’s late-stage MA integration enhances speech patterns critical for intelligibility (STOI) by refining intermediate features. In contrast, IS-IMA’s early MA placement focuses on raw feature filtering, effectively reducing noise but potentially limiting later refinements, which improves distortion reduction (CSIG).
The MA placement also influences how each model processes spectral information. IS-EMA’s ability to refine structured features aligns with the need for clear speech patterns in low-SNR conditions, improving intelligibility. IS-IMA’s early attention maintains overall quality by reducing noise early on, though it may not capture nuanced speech details as effectively as IS-EMA.
In terms of model complexity, as measured by the number of parameters (#Para.), Inter-SubNet is the most lightweight with only 2.29M parameters. However, this simplicity comes at the cost of lower performance in most metrics compared to the proposed models. IS-IMA increases complexity to 3.06M parameters, while IS-EMA has the highest parameter count at 3.81M. This increase in complexity correlates with improved performance in some areas but also raises computational demands.
In summary, while both IS-IMA and IS-EMA outperform Inter-SubNet in various aspects, their strengths differ depending on the metric considered. IS-EMA excels in intelligibility (STOI) and signal reconstruction (SI-SDR), whereas IS-IMA demonstrates stronger performance in overall quality (COVL) and reduced signal distortion (CSIG). These results highlight trade-offs between different performance metrics and model complexity across the three approaches.
6.2. Performance Evaluation Across Individual SNR Conditions and Low-SNR Scenarios
We present a comprehensive evaluation of the proposed IS-IMA and IS-EMA models under individual SNR conditions ranging from 17.5 dB to 2.5 dB using the standard test set. To ensure clarity and readability, we report results for the key metrics—PESQ, STOI, and SI-SDR—summarized in
Table 2,
Table 3 and
Table 4, respectively.
To further evaluate the robustness of the proposed methods, additional experiments were conducted using manually prepared noisy test sets at 0 dB and −5 dB SNR levels. These results are also included in
Table 2,
Table 3 and
Table 4.
From these tables, we have the following findings:
Performance under standard SNR conditions:
PESQ:
- (a)
High SNR (17.5 dB and 12.5 dB): IS-IMA achieves PESQ scores comparable to Inter-SubNet, indicating minimal degradation in clean conditions. For instance, at 17.5 dB, IS-IMA scores 3.904 versus the baseline’s 3.910.
- (b)
Mid SNR (7.5 dB): Both IS-IMA and IS-EMA exhibit improvements over the baseline, with IS-IMA achieving the highest PESQ score of 3.530, reflecting its ability to enhance perceptual quality in moderately noisy environments.
- (c)
Low SNR (2.5 dB): IS-EMA slightly outperforms IS-IMA and the baseline, achieving a PESQ score of 3.210 compared to Inter-SubNet’s 3.198. This suggests that IS-EMA is better suited for handling challenging noise conditions while preserving speech quality.
STOI:
IS-EMA consistently outperforms both IS-IMA and Inter-SubNet across all standard SNR levels in terms of STOI, achieving the highest intelligibility scores in nearly every condition:
- (a)
At 17.5 dB, IS-EMA achieves an STOI score of 0.970 compared to Inter-SubNet’s 0.967, showcasing its ability to maintain intelligibility even in clean conditions.
- (b)
At 7.5 dB, IS-EMA reaches an STOI score of 0.947, surpassing both IS-IMA (0.942) and the baseline (0.943). This demonstrates its robustness in moderately noisy scenarios where clarity is critical.
SI-SDR:
IS-EMA achieves higher SI-SDR scores than both Inter-SubNet and IS-IMA across most standard SNR levels, with notable differences at mid-to-low SNRs:
- (a)
At 12.5 dB, IS-EMA achieves an SI-SDR of 19.866 compared to Inter-SubNet’s 19.759, reflecting its ability to reconstruct high-fidelity signals under moderate noise conditions.
- (b)
At 7.5 dB, IS-EMA achieves an SI-SDR of 18.246 versus the baseline’s 18.056, indicating its robustness in preserving speech signal fidelity under noisy environments.
Performance under extra-low-SNR conditions:
Both IS-IMA and IS-EMA demonstrate measurable improvements over the baseline at critical low-SNR conditions:
PESQ:
- (a)
At 0 dB SNR, IS-IMA achieves a PESQ of 3.065 (+0.042 over baseline 3.023), demonstrating superior perceptual quality in moderate noise, while IS-EMA matches the baseline (3.023). This highlights IS-IMA’s early MA integration effectively filters raw subband features, enhancing speech quality prior to downstream processing.
- (b)
At −5 dB SNR, IS-EMA slightly outperforms the baseline (2.788 vs. 2.773), but IS-IMA achieves a higher PESQ of 2.819 (+1.7% relative improvement). This underscores IS-IMA’s robustness in extreme noise, leveraging early MA integration to preserve perceptual quality under severe acoustic challenges.
STOI:
IS-EMA consistently achieves superior STOI scores over IS-IMA and Inter-SubNet in low-SNR conditions, demonstrating robust speech intelligibility preservation even under heavy noise. This stems from its late-stage MA module integration, which refines intermediate features enriched by the initial SIL block’s local–global spectral analysis.
SI-SDR:
Similarly, IS-EMA demonstrates superior SI-SDR performance compared to both Inter-SubNet and IS-IMA at 0 dB and −5 dB SNR levels. This highlights its ability to effectively handle signal distortion in challenging noise environments. By leveraging its late-stage MA integration, IS-EMA refines intermediate features, ensuring robust reconstruction of speech signals even under severe acoustic interference, making it highly effective in low-SNR scenarios.
6.3. Ablation Analysis of Attention Mechanisms
The ablation study evaluates the performance of IS-IMA and IS-EMA under different view attention configurations in their MA blocks.
- –
The baseline model achieves balanced performance across the following metrics: PESQ (3.590), STOI (0.942), SI-SDR (18.504), and COVL (3.469), with 3.06k parameters.
- –
Channel-only attention slightly improves PESQ (3.586 → 3.592) and SI-SDR (18.504 → 18.569), with a small increase in CSIG (4.058 → 4.075).
- –
Global-only attention achieves the highest PESQ (3.592) and SI-SDR (18.616) but reduces STOI and CSIG slightly.
- –
Local-only attention delivers the highest SI-SDR (18.625) but performs worse in PESQ (3.535), STOI (0.939), and COVL (3.296).
- –
The baseline model achieves strong performance across the following metrics: PESQ (3.590), STOI (0.946), SI-SDR (18.787), COVL (3.386), and CSIG (3.959), with 3.82k parameters.
- –
Channel-only attention improves PESQ to 3.624 and SI-SDR to 18.801 while maintaining STOI at 0.946; COVL and CSIG also increase to 3.549 and 4.138, respectively.
- –
Global-only attention achieves a similar PESQ score (3.623) but lowers STOI to 0.941 and SI-SDR to 18.177, though it slightly improves COVL to 3.449.
- –
Local-only attention produces the highest PESQ (3.637) and improves CSIG to 4.143 but slightly reduces SI-SDR to 18.552.
Overall, isolating specific views in IS-EMA delivers better results than in IS-IMA, with stronger improvements across key metrics like PESQ, SI-SDR, and CSIG:
Channel-only attention in IS-EMA achieves a PESQ of 3.624 and SI-SDR of 18.801 while maintaining STOI at 0.946, outperforming IS-IMA in similar setups.
Local-only attention in IS-EMA excels with the highest PESQ (3.637) and CSIG (4.143), demonstrating its ability to enhance speech quality and reduce distortion.
In contrast, isolating views in IS-IMA shows limited improvements with greater trade-offs:
Global-only attention achieves the highest PESQ (3.592) and SI-SDR (18.616) but reduces STOI and CSIG compared to the baseline.
Local-only attention performs poorly in PESQ (3.535) and COVL (3.296), highlighting its limitations.
Thus, while integrating all three views ensures balanced performance for both models, IS-EMA’s isolated configurations demonstrate greater adaptability and effectiveness, making it a stronger choice for tasks requiring specific attention mechanisms.
Table 5.
Ablation study: the various SE performance scores of IS-IMA with different assignments of view attention in the MA block.
Table 5.
Ablation study: the various SE performance scores of IS-IMA with different assignments of view attention in the MA block.
| IS-IMA | PESQ | STOI | SI-SDR | COVL | CSIG | # Para. (M) |
|---|
| all three views (baseline) | 3.590 | 0.942 | 18.504 | 3.469 | 4.058 | 3.06 |
| channel only | 3.586 | 0.942 | 18.569 | 3.488 | 4.075 | 2.82 |
| global only | 3.592 | 0.941 | 18.616 | 3.449 | 4.003 | 2.84 |
| local only | 3.535 | 0.939 | 18.625 | 3.296 | 3.842 | 2.81 |
Table 6.
Ablation study: the various SE performance scores of IS-EMA with different assignments of view attention in the MA block.
Table 6.
Ablation study: the various SE performance scores of IS-EMA with different assignments of view attention in the MA block.
| IS-EMA | PESQ | STOI | SI-SDR | COVL | CSIG | # Para. (M) |
|---|
| all three views (baseline) | 3.590 | 0.946 | 18.787 | 3.386 | 3.959 | 3.82 |
| channel only | 3.624 | 0.946 | 18.801 | 3.549 | 4.138 | 3.81 |
| global only | 3.623 | 0.941 | 18.177 | 3.449 | 4.008 | 3.81 |
| local only | 3.637 | 0.946 | 18.552 | 3.549 | 4.143 | 3.78 |
Results of Ablation Study for Each SNR Level
Following the methodology outlined in
Section 6.2, we conducted an ablation study evaluating IS-IMA and IS-EMA under isolated attention views across individual SNR conditions. These results, presented in
Table 7,
Table 8 and
Table 9, reveal the following key findings:
These findings underscore the importance of MA placement and attention view selection, with IS-EMA demonstrating superior adaptability to challenging noise conditions compared to IS-IMA. The late-stage MA integration in IS-EMA enables effective refinement of structured spectral features, particularly under low-SNR scenarios, while IS-IMA’s early integration prioritizes raw feature filtering with inherent noise robustness limitations.
6.4. Comparison with Some State-of-the-Art SE Methods
Finally, we compare the presented IS-IMA and IS-EMA variants with several state-of-the-art speech enhancement frameworks, including FullSubNet [
26] and WaveUNet [
40,
41], which uses frequency- and time-domain features as input, respectively, SEGAN [
17], CMGAN [
42], and MP-SENet [
43], which primarily utilize generative adversarial networks (GANs), along with MANNER [
33] and SE-Conformer [
44], which mainly employ attention mechanisms.
The results, as presented in
Table 10, are based on the PESQ and STOI metrics obtained from the VoiceBank-DEMAND dataset, as reported in the literature. The findings indicate that IS-IMA and IS-EMA achieve the highest PESQ scores (3.59 and 3.64, respectively) among all evaluated methods, showcasing their superior speech quality enhancement capabilities. While STOI scores are generally comparable across most methods, FullSubNet, CMGAN, and MP-SENet achieve the highest STOI score of 0.96. Nevertheless, our proposed models demonstrate a strong balance between speech quality (PESQ) and intelligibility (STOI), highlighting their effectiveness in advancing speech enhancement performance.
These findings confirm that our methods perform better than or are competitive with state-of-the-art techniques, making them highly suitable for real-world applications. Notably, resource-intensive models like DCCTN [
24] (10.1M parameters) are excluded from this comparison due to hardware constraints—our lab infrastructure cannot support the computational demands of such large architectures. In contrast, IS-IMA (3.06M parameters) and IS-EMA (3.81M parameters) emphasize parameter efficiency while retaining competitive enhancement quality, making them uniquely suited for real-time deployment in resource-limited settings.
7. Conclusions and Future Work
This study focuses on improving Inter-SubNet, a leading speech enhancement framework, by integrating a Multi-view Attention (MA) module. Experiments on the VoiceBank-DEMAND dataset show that the proposed IS-IMA and IS-EMA models significantly enhance Inter-SubNet’s performance across various metrics. Notably, isolating individual view attentions in IS-EMA achieves near-optimal results in multiple SE metrics, highlighting the effectiveness of the proposed model.
Furthermore, building on the insights from this study, we have several promising directions for future research:
Dual-MA Architecture: As suggested, integrating Multi-view Attention (MA) modules at both early and late stages of the Inter-SubNet framework could combine the strengths of IS-IMA (noise suppression) and IS-EMA (intelligibility enhancement). While this dual-MA configuration may introduce computational overhead, a targeted ablation study could evaluate whether the performance gains in distortion reduction and speech quality justify the increased complexity. This approach might better balance feature filtering and refinement across the processing pipeline.
Layer-Specific Attention Mechanisms: Exploring the strategic placement of different attention types (channel, global, local) at specific layers could optimize feature extraction. For instance, local attention in early layers might capture fine-grained phonetic details (e.g., formants, harmonics), while global attention in later layers could ensure temporal coherence of enhanced speech. Channel attention could be dynamically weighted across layers to emphasize critical frequency bands. Such a structured approach could yield more targeted enhancements while maintaining computational efficiency.
Dynamic Attention Allocation: Beyond static configurations, future work could investigate adaptive mechanisms where attention types are dynamically selected based on input SNR or spectral characteristics. For example, local attention might dominate in high-noise conditions, while global attention could activate in cleaner speech scenarios. This adaptability could further improve robustness across diverse acoustic environments.
These directions aim to advance the flexibility and efficacy of attention-based speech enhancement while addressing practical constraints such as computational cost and real-time applicability.




{kind=link}
{kind=link}
{kind=link}
{kind=link}