1. Introduction
Object detection is a pivotal task in computer vision, integral to a wide range of applications including autonomous vehicles [
1], robotics [
2], surveillance [
3], and various fields like medicine [
4] and agriculture [
5]. Specifically, YOLO models have been successfully applied in medicine for tasks such as the localization and segmentation of lumbar spine vertebrae deformities [
6] and detection of breast lesions [
7]. In agriculture, YOLO has been employed for roadside monitoring and the detection of invasive alien plant species [
8], as well as the real-time detection of invasive weed seedlings like Solanum rostratum Dunal [
9]. Among the numerous algorithms developed for real-time object detection, YOLO (You Only Look Once) stands out due to its exceptional balance between accuracy and speed. Introduced by Redmon et al. [
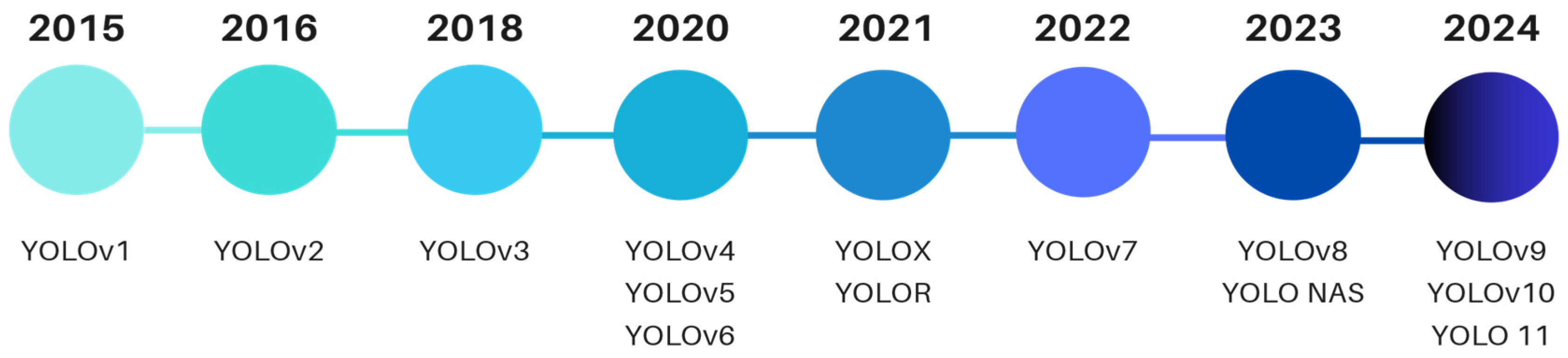
10] in 2015, YOLOv1 marked a significant advancement in the field. Since then, the YOLO algorithm has undergone continuous evolution, with new versions being released almost annually, culminating in the latest iteration, YOLOv11 (
Figure 1).
Apart from YOLO, various object detectors have been proposed in recent years. R-CNN (region-based convolutional neural network) [
11] is a pioneering model that uses selective search to propose regions and then classifies each region using a convolutional neural network. Fast R-CNN [
12] is an improved version of R-CNN that integrates region proposal and classification into a single network, significantly speeding up the detection process. Furthermore, Faster R-CNN [
13] advances Fast R-CNN by introducing a region proposal network (RPN) that shares features with the detection network, enabling end-to-end training and real-time performance. Another significant object detector is SSD (Single Shot MultiBox Detector) [
14], which predicts bounding boxes and class scores for multiple objects in a single forward pass, facilitating real-time detection. Additionally, EfficientDet [
15] is a family of object detection models that use EfficientNet [
16] as the backbone and employ a compound scaling method to achieve a balance between accuracy and efficiency. Lastly, DETR (Detection Transformer) [
17] is a novel model that leverages transformers for end-to-end object detection, eliminating the need for traditional components like region proposal networks and non-maximum suppression, and achieving competitive accuracy with a simpler architecture.
Modern deep neural networks (DNNs) are integral to the success of the aforementioned algorithms. However, numerous studies have shown that DNNs are susceptible to adversarial attacks involving imperceptible perturbations and noisy data [
18,
19,
20]. This vulnerability poses a significant challenge to the deployment of object detectors in real-world conditions, potentially compromising their reliability and effectiveness. Adversarial attacks, which involve adding subtle perturbations to input images, can significantly degrade the performance of deep learning models, leading to incorrect predictions. These attacks exploit the vulnerabilities inherent in deep networks, raising critical concerns about the security of YOLO models in safety-sensitive applications. Alongside adversarial attacks, real-world image corruptions—such as noise, blur, and weather-induced distortions—further impact model performance. As such, robustness to these disruptions is crucial for deploying YOLO models in environments where pristine images are not guaranteed.
Several reviews on YOLO models exist, including [
21,
22,
23], yet none have thoroughly examined their effectiveness under noisy data and adversarial examples. This work aims to address this gap by evaluating the robustness of YOLO model series under Fast Gradient Sign Method (FGSM) [
24] and Projected Gradient Descent (PGD) [
25] attacks, along with other image corruption techniques, to test their resilience. By analyzing the behavior of these models across different scenarios, we seek to identify the strengths and weaknesses of each YOLO variant. Our findings provide insights into the vulnerabilities of YOLO models, guiding future research towards more resilient object detection systems and informing practitioners on model suitability under challenging real-world conditions.
The remainder of this paper is organized as follows:
Section 2 presents an overview of existing works that address robustness in YOLO algorithms, highlighting key approaches and gaps in the current literature.
Section 3 provides a detailed overview of the dataset, experimental setup, and methodologies applied to evaluate the robustness of YOLO models against adversarial attacks and image corruptions. In
Section 4, we discuss the evolution of the YOLO architectures, highlighting key advancements and innovations across each version.
Section 5 presents our experimental results, analyzing the robustness of YOLO models under adversarial perturbations and image corruptions. In
Section 6, we provide a comparative discussion of the findings and insights into the models’ resilience. Finally,
Section 7 concludes the paper by summarizing our contributions and suggesting future research directions.
4. YOLO Model Series
YOLO (You Only Look Once) [
10] is a real-time object detection method that frames object detection as a single regression problem rather than a series of region-based proposals. Unlike other approaches that generate multiple region proposals and classify each, YOLO directly predicts bounding boxes and class probabilities from entire images in one evaluation. This makes it highly efficient for applications requiring fast processing speeds.
YOLO divides an input image into an S×S grid, where each grid cell is responsible for predicting a fixed number of bounding boxes and their confidence scores, along with class probabilities for each box. Each prediction includes the bounding box coordinates (center x, center y, width, height), the confidence score that indicates the likelihood of the box containing an object, and the class probabilities for the detected object. The confidence score is a product of the IoU (Intersection over Union) between the predicted box and the ground truth, and the probability of the object’s presence in the box.
In the YOLO framework, multiple bounding boxes are predicted for each grid cell. During training, only one bounding box predictor is assigned to be responsible for detecting a particular object. This assignment is based on which predicted box has the highest Intersection over Union (IoU) with the ground truth box. This process allows each bounding box predictor to specialize, focusing on different object sizes, aspect ratios, or classes, which helps improve the model’s recall and detection accuracy.
A crucial technique used in YOLO models is Non-Maximum Suppression (NMS). NMS is a post-processing method that enhances the accuracy and efficiency of object detection by addressing the issue of multiple overlapping bounding boxes for the same object. When several predicted boxes overlap and represent the same object, NMS selects the box with the highest confidence score and removes others that are deemed redundant. This process ensures that each object is represented by a single, most accurate bounding box, improving the clarity of detection results.
4.1. YOLO v1
YOLO v1 consists of 24 convolutional layers followed by two fully connected layers. The first 20 convolutional layers were pre-trained on the ImageNet at a resolution of 224 × 224 pixels size. The architecture of YOLO v1 is inspired by GoogleNet [
38] and Network in Network [
39] which use a 1 × 1 convolutional layer to decrease the number of feature maps and keep the number of parameters low. Also, all layers employed a Leaky Rectified Linear Unit (LReLU), apart from the last layer that uses a linear activation function. The model was fine-tuned in PASCAL VOC 2007 and 2012 at a resolution of 448 × 448 pixels. The Darknet framework was used for training.
4.2. YOLO v2
The architecture of YOLOv2 [
40], named darknet-19, is similar to the VGG [
41] concept and consists of 19 convolutional layers and five max pooling layers. Building upon YOLOv1, YOLOv2 introduces some new advancements.
Batch normalization (BN) is implemented to alleviate the Internal Covariate Shift and to improve convergence.
High Resolution Classifier. In YOLOv2, the classifier was pre-trained in ImageNet like YOLOv1 at the resolution of 224 × 224 pixels. However, in the last 10 epochs of training, the resolution becomes 448 × 448 pixels.
Anchor Boxes. YOLOv2 uses anchor boxes (or prior boxes) to predict bounding boxes. These anchor boxes represent different shapes and aspect ratios, and they are used as reference templates for the objects that the model might detect. In YOLOv2, five anchor boxes were used. The width and height of the anchor boxes should match the common object of the training set. For that purpose, the authors used k-means clustering to choose the proper size of them.
Direct Location Prediction. Instead of predicting bounding box coordinates directly (as in YOLOv1), YOLOv2 predicts adjustments relative to these anchor boxes for each grid cell.
Fine Grained Features. YOLOv2 combines features from earlier and deeper layers to deal with the detection of small objects. This is carried out by using a passthrough layer that concatenates the higher-resolution features with the lower-resolution features.
Multi-Scale Training. Since YOLOv2 uses only convolutional and pooling layers, it can handle multiple sizes of images, making it more robust to different image sizes and to work well in a variety of input dimensions. For that reason, during training, every 10 batches, the network chooses a different image size.
4.3. YOLO v3
YOLOv3 was introduced by Redmon et al. [
42] in 2018 and proposed some important changes over YOLOv2. First of all, YOLOv3 uses a bigger backbone named Darknet-53 which consists of 53 convolutional layers with 3 × 3 and 1 × 1 convolutional filters with residual connections. Also, max-pooling layers were replaced by strided convolutions. Moreover, in YOLOv3, binary cross entropy is used for classification instead of softmax. This allows for multiple label assignments in the same box. In YOLOv3, the objects are detected at three different stages/layers of the network. Assuming the input to the network is 416 × 416 pixels, the three feature vectors we obtain are 52 × 52, 26 × 26, and 13 × 13 pixels, responsible for detecting small, medium, and large objects, respectively. The network extracts features from each of the three scales using a similar concept to Feature Pyramid Networks or FPNs. Upsampling and concatenating features with different scales allow the network to learn more fine-grained information from the earlier feature maps and more meaningful semantic information from the upsampled later layer feature maps. Similarly to YOLOv2, for choosing the precise anchor boxes, the authors use k-means clustering in YOLOv3. But instead of five, in YOLOv3, nine clusters are selected, dividing them evenly across the three scales, which means three anchors for each scale per grid cell.
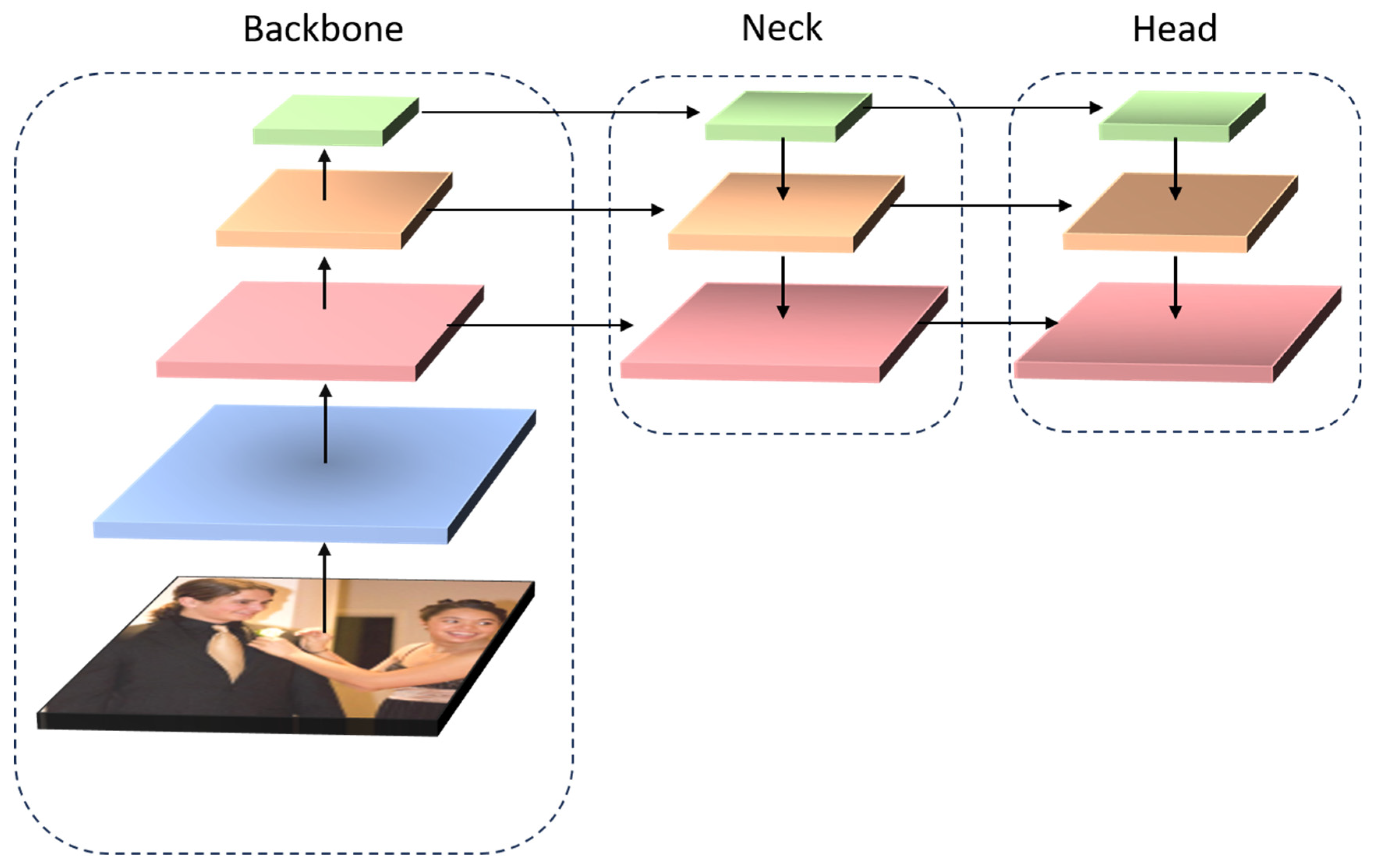
4.4. The Structure of Object Detectors
Henceforward, the architecture of modern object detectors is divided into three parts, the backbone, the neck, and the head, as shown in
Figure 6.
The
backbone part is responsible for extracting rich feature representations from the input image. It is typically a convolutional neural network (CNN) that is pre-trained on large-scale image classification datasets like ImageNet. Popular backbones include ResNet [
43], VGG, Darknet-53, and more. The backbone’s purpose is to generate a feature map that encodes various spatial and semantic information about objects within the image.
The
neck part further refines and processes these feature maps, often focusing on multi-scale feature aggregation. Techniques like Feature Pyramid Networks (FPNs) [
44] or Path Aggregation Networks (PANet) [
45] are commonly used to enhance feature maps by combining high resolution details (earlier layers) with deeper, semantically rich information (deeper layers). This multi-scale processing is crucial for detecting objects of varying sizes in an image, as it helps maintain both fine details and high-level context across different layers.
The head part is responsible for producing the final detection outputs from the processed feature maps. It includes layers that predict object bounding boxes, classify detected objects, and calculate objectness scores, indicating the presence of an object. The head often employs convolutional layers with regression for bounding box predictions and logistic regression for class probabilities. For models like YOLO and Faster R-CNN, the head generates bounding boxes and class scores for each anchor box at every spatial location in the feature map, allowing for the efficient detection of multiple objects.
4.5. YOLO v4
YOLOv4 was published by Bochkovskiy et al. [
46] in 2020 by different authors from the previous versions. However, the main features and the philosophy remain the same. YOLOv4 introduces several new features that are divided into two main categories, Bag-of-Freebies and Bag-of-Specials. Bag-of-Freebies affect only the training procedure, increasing the training cost but without affecting inference time. On the other hand, Bag-of-Specials have an impact on inference by slightly increasing the inference cost but with an important improvement in accuracy.
The Bag-of-Specials lead to the following architecture. The authors tried several CNN architectures for the backbone like ResNeXt50 [
47], EfficientNet-B3 [
16], and Darknet-53. They finally chose a variation in Darknet-53 with cross-stage spatial connections (CSPNet) [
48] with Mish activation function. CSP connections decrease the computation cost while preserving high accuracy. After the backbone, YOLOv4 uses spatial pyramid pooling (SPP) [
49] which allows multi-scale prediction and increases the receptive fields of the network. Also, a spatial attention module (SAM) [
50] block was also added. SAM assists the model in emphasizing important spatial regions. SPP and SAM along with a variation in PANet for the feature aggregation constitute the neck of YOLOv4. The original PANet algorithm adds the aggregated features, while the modified version concatenates them. As a head, YOLOv4 uses the same as YOLOv3 and anchor-based detection.
The implementation of bag-of-freebies includes several steps. Strong data augmentation techniques such as mosaic and cutmix [
51] were applied along with typical techniques like random brightness, contrast, scaling, cropping, flipping, and rotation. Also, class label smoothing and DropBlock [
52] were used for regularization. Furthermore, at the detection stage, CIoU [
53] and cross-mini-batch normalization were used. Finally, self-adversarial training was applied to make the model robust under adversarial attacks and perturbations.
4.6. YOLO v5
YOLOv5 [
54] was introduced by Glen Jocher in 2020. It is the first YOLO model that was not developed in the Darknet framework but in Pytorch. It has many similarities with YOLOv4. A modified CSPDarknet53 is used as the backbone. The authors added the Stem layer, which is a strided convolution layer with a large window size to reduce the computational cost. The architecture of the neck uses a spatial pyramid pooling fast (SPPF) layer with a modified CSP-PAN. The SPPF layer is designed to accelerate network processing by merging features from different scales into a uniform-size feature map, enhancing computational efficiency. The head is similar to the YOLOv3 head.
Moreover, YOLOv5 uses a plethora of data augmentation techniques such as Mosaic, Copy-Paste, random affine transformations, MixUp, Albumentations, HSV, and random horizontal flip. In YOLOv5, various training strategies are implemented to enhance model performance and efficiency. Multi-scale training is utilized, where input images are randomly resized between 0.5 and 1.5 times their original size during training, enabling the model to adapt to objects of different scales. The AutoAnchor mechanism optimizes anchor boxes to better align with the characteristics of ground truth boxes in the training data, improving detection accuracy. Additionally, a warmup and cosine learning rate scheduler gradually adjusts the learning rate, helping to stabilize the training process and improve convergence. To ensure more stable model updates and reduce generalization error, an Exponential Moving Average (EMA) of model parameters was employed. Mixed precision training further contributes to faster training by performing computations in half-precision, leading to reduced memory usage. Finally, hyperparameter evolution automatically adjusts hyperparameters through an evolutionary approach, finding optimal configurations for better performance. These strategies collectively contribute to YOLOv5’s efficient training and accurate detection capabilities.
4.7. YOLOR
In 2021, YOLOR (You Only Learn One Representation) was introduced by Wang et al. [
55]. YOLOR emerged as one of the most advanced YOLO models, introducing a multi-task learning approach, as the model was trained to perform classification, detection, and pose estimation simultaneously. The authors combined explicit and implicit knowledge to achieve joint learning. Explicit knowledge is gained by training a model in a supervised manner for a specific task, while implicit knowledge simulates subconscious learning, similar to how humans gain latent background knowledge without direct supervision. Even though joint learning usually leads to poor feature generation, the combination of implicit and explicit knowledge presents improvements in all tasks. The authors proposed three ways to integrate implicit with explicit knowledge.
Vector/Matrix/Tensor (z): Direct use of a vector z (or higher-dimensional tensor) as implicit knowledge. Simple but effective for tasks where prior knowledge can be directly applied.
Neural Network (Wz): Transforms the implicit knowledge vector using a neural network to allow for more complex, task-specific interaction with explicit features.
Matrix Factorization (ZTc): Combines multiple vectors of implicit knowledge through factorization, enabling a rich, flexible combination of implicit knowledge with explicit learning.
4.8. YOLOX
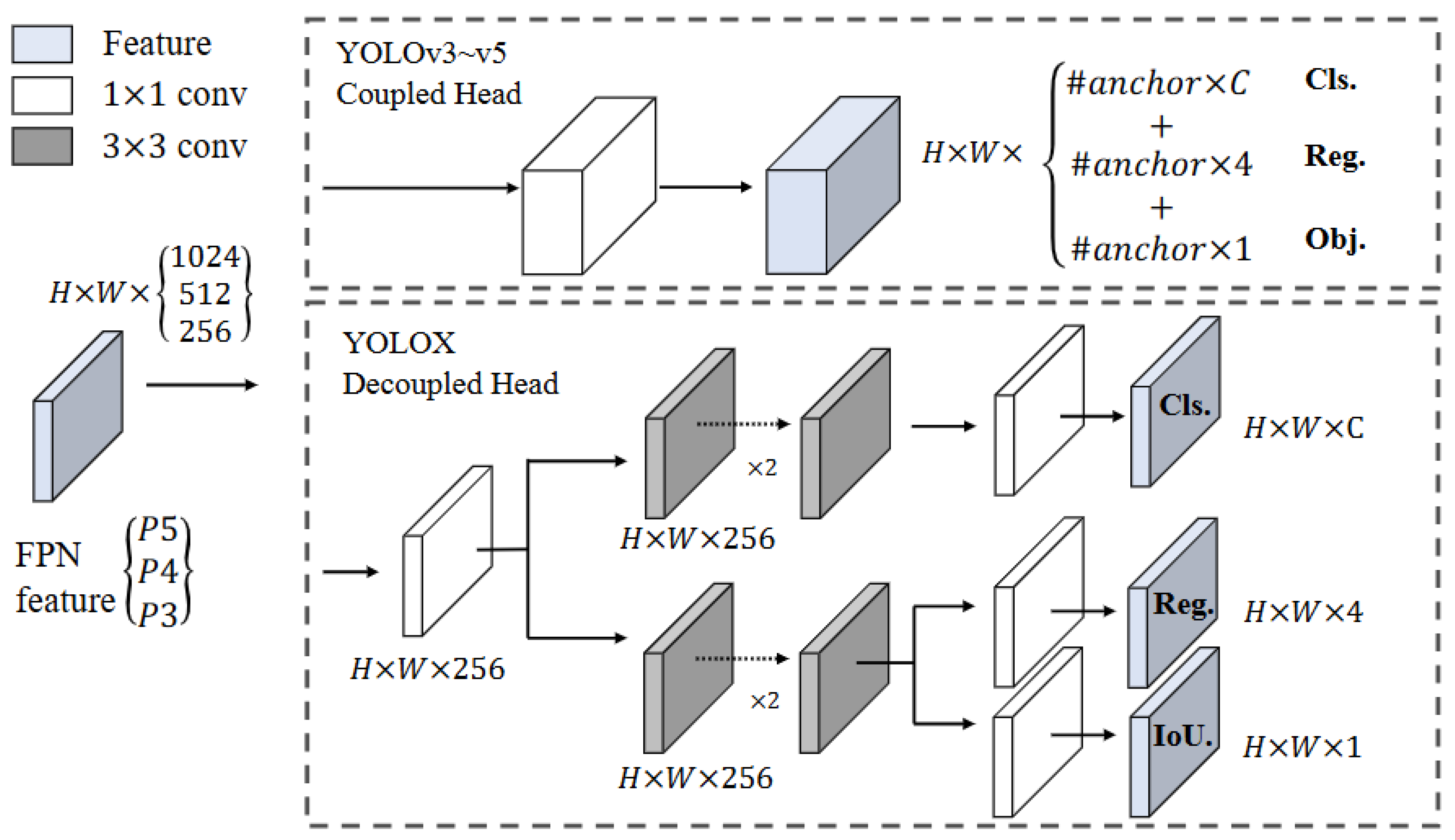
In 2021, Zheng Ge et al. from Megvii Technology released YOLOX [
56]. The authors used YOLOv3 as a baseline for Darknet53 and the SPP layer with FPN. However, they introduced five key modifications.
Decoupled head: In the previous YOLO versions, the head was responsible for the classification and the regression task for bounding boxes. However, YOLOX uses a decoupled head where two different branches of the head are responsible for classification and regression tasks independently (
Figure 7).
Anchor-free: YOLOX proposes an anchor-free mechanism since it simplifies the training and decoding phase. Also, the anchor-free mechanism leads to a decreased complexity of detection heads and an increase in predictions in the image.
Multi-positives: In contrast to previous YOLO models, which selected only one positive sample per object, YOLOX assigns multiple predictions as positives, assuming that the predicted center is close to the center of the ground truth. Specifically, positive samples are those that their center fall within a 3 × 3 area around the ground truth center.
SimOTA: It is a key technique used in YOLOX to improve how the model assigns positive samples during training. It is based on the Optimal Transport Assignment (OTA) [
57] algorithm and it aims to minimize the matching cost between predictions and ground truth objects, allowing the model to focus on the most promising predictions. By adopting SimOTA, YOLOX enhances its training efficiency, reduces the positive–negative imbalance, and ultimately improves detection accuracy.
Strong augmentations: YOLOX used the MixUP and Mosaic data augmentations and disabled them for the last 15 epochs. Also, the authors concluded that when using these augmentation techniques, the impact of pre-training is no longer as substantial.
4.9. YOLO v6
In 2022, YOLOv6 was released by Chuyi Li et al. [
58], presenting improvements in both accuracy and inference speed. The development of this new version is driven by the need to address the practical challenges often encountered in industrial applications. The advancements of YOLOv6 are summarized as follows.
Network Design: The authors explored the RepVGG [
59] architecture as the backbone, determining that it is well suited for small networks due to its ability to provide rich feature representations. Consequently, the smaller versions of YOLOv6 utilize RepBlock as their building block. However, in larger networks, RepBlock significantly increases computational costs, leading the authors to adopt an optimized CSP block, referred to as the CSPStackRep Block. Additionally, an enhanced PAN algorithm is employed as the neck, incorporating both RepBlocks and CSPStackRep Blocks. Finally, YOLOv6 features a decoupled head.
Label Assignment: YOLOv6 employs an advanced label assignment technique similar to YOLOX, as it is also anchor-free. The authors experimented with various label assignment methods, including SimOTA, and ultimately adopted TAL (Task-Aligned Labeling), which was introduced in TOOD [
60].
Loss Function: The authors experimented with several loss functions for classification, box regression, and object loss choosing VariFocal Loss [
61] and SIoU [
62]/GIoU [
63] for classification and regression, respectively.
Industry-handy improvements: YOLOv6 incorporates practical enhancements like self-distillation and extended training epochs to boost model performance. Additionally, a cosine decay strategy adjusts the balance between soft and hard labels during training, helping the student model adapt throughout different training phases.
Quantization and deployment: For quantization and deployment, YOLOv6 uses RepOptimizer to produce Post-Training Quantization (PTQ)-friendly weights and combines quantization-aware training (QAT) with channel-wise distillation and graph optimization.
4.10. YOLO v7
In 2022, Wang et al. [
64] published YOLO v7, which presents significant improvements in both accuracy and speed. The authors proposed several changes which are divided into architectural and trainable bag-of-freebies.
Architecture
- 1.
E-ELAN: The authors introduced the E-ELAN block. ELAN [
65] is a specific computational block designed to improve gradient flow by enabling more direct gradient paths and optimizing the way information is combined across layers. E-ELAN extends this concept, allowing for even better learning by structuring the network in a way that maintains a balance between model depth and the ability of gradients to travel through the network.
- 2.
Model scaling for concatenation-based models: Model scaling in concatenation-based models is challenging because performing depth scaling causes width scaling too, which can lead to inefficiencies in terms of computational cost and memory usage. The authors introduced a new method for scaling concatenation-based models using a uniform factor, ensuring that the scaling happens in a more balanced way, keeping the network’s complexity under control while maintaining its capacity for learning.
4.11. YOLO v8
In 2023, Ultralytics introduced YOLOv8 [
66], which shares many similarities with YOLOv5, as both models were developed by the same company. YOLOv8 uses CSPDarknet as a backbone, like YOLOv5, but with a different module named C2f, which is a cross-stage partial bottleneck with two convolutions, replacing C3 in YOLOv5.
Another difference between these models is the fact that YOLOv8 is an anchor-free model since it does not use prior anchor boxes. Furthermore, a decoupled head was employed to process objectness score, classification, and regression independently. Finally, BCE was used for classification loss, while CIoU and DFL functions were used for bounding-box predictions. During the training process of YOLOv8, the mosaic data augmentation technique is employed, but it is deactivated during the final 10 epochs of training.
4.12. YOLO NAS
YOLO-NAS [
67] is an advanced object detection architecture developed by Deci-AI using Automated Neural Architecture Construction (AutoNAC), which automates the design and optimization of deep neural networks. It delivers state-of-the-art performance in tasks like object detection by balancing speed, accuracy, and computational efficiency. Key features of YOLO-NAS include its adaptability for edge devices through hybrid quantization, which selectively reduces the precision of different parts of the neural network, ensuring smaller model size and lower power consumption without sacrificing significant accuracy. In addition to quantization, YOLO-NAS incorporates advanced machine learning techniques such as Post-Training Quantization (PTQ) and quantization-aware training (QAT). PTQ reduces the model’s precision after training, enabling faster inference and lower resource consumption, while QAT trains the network to adapt to quantization effects, maintaining high accuracy even after reducing the model size. Furthermore, YOLO-NAS integrates Distribution Focal Loss (DFL), a loss function that improves the detection of objects of varying sizes, making it highly adaptable to different object detection tasks, from small-scale object recognition to large-scale scenarios.
4.13. YOLO v9
In 2024, YOLOv9 was released by Wang et al. [
68], introducing two important innovations, the Programmable Gradient Information (PGI) and the Generalized Efficient Layer Aggregation Network (GELAN).
PGI: Programmable Gradient Information (PGI) is introduced to mitigate the Information Bottleneck (IB) phenomenon, which often occurs in deep neural networks. PGI consists of three key components: (1) the main branch: the architecture responsible for inference; (2) the Auxiliary Reversible Branch: used only during the training phase, this branch ensures the preservation of reliable gradients through the use of reversible functions; and (3) Multi-Level Auxiliary Information: a mechanism that provides multiple levels of supervision, guiding the learning process in the main branch by supervising intermediate layers.
GELAN: Inspired by CSPNet and ELAN, the authors proposed the GELAN architecture, optimized for low complexity, fast inference, and high accuracy. GELAN enhances ELAN’s ability to stack multiple convolutional blocks by enabling the stacking of any computational block. In YOLOv9, CSPNet and the planned RepConv blocks are used as computational units to further improve the model’s performance.
4.14. YOLO v10
YOLOv10 was published by Wang et al. [
69] and it is built on the Ultralytics package. The proposed model introduced several advancements improving both accuracy and computational cost and can be divided into three categories: Consistent Dual Assignments for NMS-free Training, efficiency-driven model design, and accuracy-driven model design.
Consistent Dual Assignments for NMS-free Training: Previous YOLO models used one-to-many label assignment strategies, meaning that multiple predicted bounding boxes could be assigned to a single ground truth object. While this approach allows the model to learn richer features and representations, it requires the use of a post-processing method, Non-Maximum Suppression (NMS), which increases computational cost. On the other hand, one-to-one label assignment is more computationally efficient but does not provide the same level of representation learning. YOLOv10 combines these methods to leverage the benefits of both. During training, both the one-to-one and one-to-many heads are optimized, but at inference, the one-to-many head is discarded, reducing the need for NMS. To ensure optimal training, a consistent matching metric is applied to align the one-to-one head’s supervision with the learning objectives of the one-to-many head.
Efficiency-Driven Model Design: YOLOv10 employed efficiency-driven changes in the head, downsampling layers and in stages with basic building blocks. The authors stated that regression error carries more impactful information for the classification task. That is why they introduced a lightweight architecture in the classification head without sacrificing significant performance. Typical YOLO architectures use convolutions with stride 2 for spatial downsampling while also doubling the number of channels. Instead, in YOLOv10, this procedure consists of two stages. Firstly, pointwise convolution is applied to change the channels and then depthwise convolution for spatial downsampling. Finally, YOLOv10 introduces a rank-guided block design to enhance computational efficiency and optimize stage-specific architecture. By conducting intrinsic rank analysis, the team identified redundancies in using uniform blocks across all stages. To address this, they developed the Compact Inverted Block (CIB), combining depthwise and pointwise convolutions for spatial and channel mixing, respectively, and integrated it into the Efficient Layer Aggregation Network (ELAN) for improved efficiency in object detection.
Accuracy-Driven model Design: YOLOv10 introduces large kernel convolution, which enhances the receptive field and as a consequence the capability of the model. Nevertheless, large kernels have a negative impact on small object detection. That is why the authors use large kernels (7 × 7 instead of 3 × 3) only in deeper stages in the CIB. They further apply structural reparameterization [
70] to introduce an additional 3 × 3 depthwise convolution branch, helping to address optimization challenges without adding inference overhead. Furthermore, YOLOv10 enhances global feature modeling with Partial Self-Attention (PSA). Channels are split post-1 × 1 convolution, applying self-attention to only one subset, then recombining them with another 1 × 1 convolution. The query and key dimensions in MHSA are halved, and PSA is placed only after Stage 4 to reduce computational costs.
4.15. YOLO v11
YOLOv11 is the latest model at this time and it was released by Ultralytics [
71] who also released YOLOv8 and YOLOv5. YOLOv11 introduces several advancements in its backbone, neck, and head parts to enhance object detection efficiency and accuracy. The backbone employs a new C3k2 block, replacing the older C2f block from YOLOv8, which optimizes feature extraction with two smaller convolutions, improving computational efficiency. The SPPF block is retained, and a new Cross Stage Partial with Spatial Attention (C2PSA) block is added to enhance spatial attention, allowing the model to focus on important regions. In the neck, C3k2 improves feature aggregation, further enhancing speed and processing efficiency. The head utilizes multiple C3k2 and CBS (Convolution-BatchNorm-Silu) blocks, with C3k2 modules adaptable for different convolutional sizes to refine multi-scale features. The final detect layer produces bounding boxes and class scores, leveraging these innovations for faster and more precise object localization and classification.
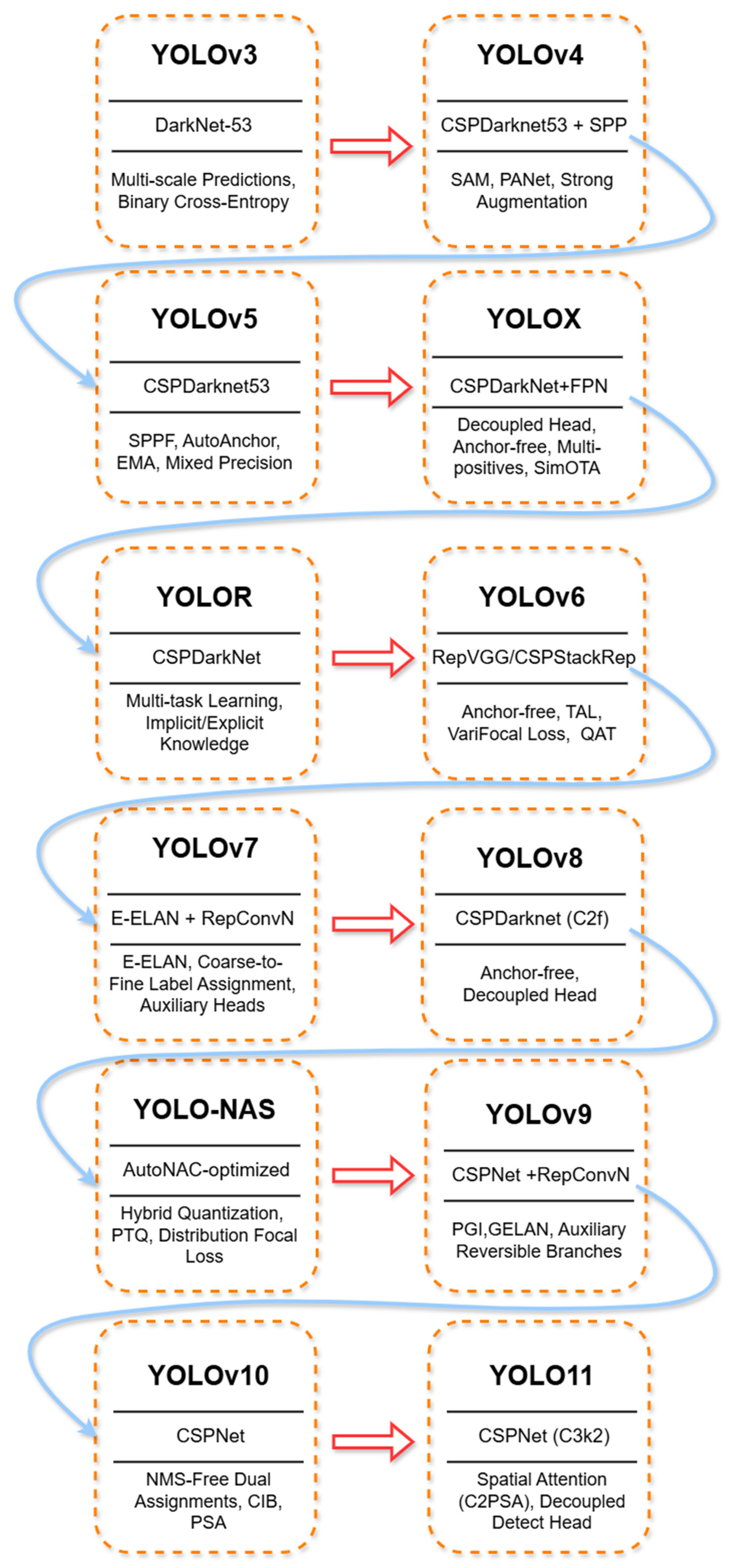
Figure 8 represents the evolution of YOLO object detection architectures, from YOLOv3 to YOLOv11. Each block represents a specific YOLO version, highlighting its backbone network, architectural improvements, and key innovations.
6. Discussion
Robustness in object detectors is crucial since they are used in critical domains such as autonomous driving, surveillance, etc. This study highlights the relative robustness of different YOLO model versions when exposed to adversarial attacks, such as FGSM, PGD, and image corruptions like fog, pixelate, gaussian noise, impulse noise, defocus blur, and motion blur. This section discusses the results of the conducted simulations and analyzes the behavior of the models under attack.
Specifically, under the FGSM attack, the X-Large YOLOX model demonstrated the highest robustness. While the large versions of YOLOv5 and YOLOv8 maintained their accuracy under attack with an epsilon value of 0.01, they experienced greater degradation than YOLOX at higher epsilon values. Following YOLOX, the YOLOv4, YOLOv3, and YOLO 11x models, demonstrated a notable degree of robustness. A similar pattern is observed under PGD attacks. The large YOLOv5 model maintains its accuracy at an epsilon value of 0.01; however, YOLOX models exhibit lower degradation across the remaining epsilon values. Following YOLOX, YOLOv3, YOLO 11x, YOLOv9-e, and YOLOv4 present a good performance in that order. Furthermore, results indicate that all sizes of YOLOX models exhibit superior robustness compared to other models.
When images are attacked by applying some types of image corruption, the results are slightly different. Firstly, each corruption method introduces a distinct type of noise, which explains why a model that demonstrates robustness against one type of noise may not exhibit the same level of resilience against others. However, the top-performing models across each type of corruption are consistently YOLOX, YOLOv3, and YOLOv4. More precisely, the results for each corruption are as follows.
Fog: The introduction of fog noise causes the smallest degradation in performance among all corruptions. Large YOLOX achieved the best performance, losing only 0.8 mAP. However, a plethora of other models such as YOLOX-x, YOLOv9-e, YOLOv8m, YOLOv7x, and others have a similar behavior of maintaining high mAP. On the other hand, YOLO11n, YOLOv9-s, and YOLOv5n presented the worst performance.
Pixelate: In pixelate corruption, YOLOv3 surprisingly loses only 0.7% mAP while the other models have a significantly more significant decrease in their performance. YOLOv5n and YOLOv6n were the second-best models with 3.3% and 3.4% degradation, respectively. YOLOv7, YOLOR-CSP, and all sizes of YOLO11 except for nano achieved the worst performance.
Gaussian Noise (GN): In Gaussian noise, YOLOv3 is again the most robust model. Nevertheless, near to its performance are YOLOv4 and YOLOX-x. YOLO5n, YOLOv8n, and YOLO11n were the least robust models for this type of noise.
Impulse Noise (IN): YOLOv4 and YOLOX-x were the most robust models under attack with impulse noise as they were degraded by 8.9% mAP. Impulse noise was the strongest type of noise causing the biggest degradation in models. YOLO11, YOLOv5, YOLOv8, and YOLOv9 present some of the worst results.
Defocus Blur (DB): The defocus blur degradation scores range from 3.7% to around 8.7%. YOLOv4 has the best performance under defocus blur with a score of 3.7%, indicating it is the most robust model against this specific corruption type. Other models with relatively high robustness for this type of noise include YOLOv3 (5.5%) and YOLOX-s (6.5%), which suggests that these models are also more resilient to defocus blur, albeit with slightly higher degradation than YOLOv4. Models such as YOLOv9-m (7.8%) and YOLOv11m (7.9%) show higher degradation, indicating they are more susceptible to performance drops under defocus blur.
Motion Blur (MB): YOLOv4 achieved the best performance in MB noise. YOLOv3 follows with very good performance too. YOLOX models also perform relatively well with this type of noise. In contrast, all sizes of YOLOv7, YOLOv9, and YOLO11 seem to be more susceptible in MB.
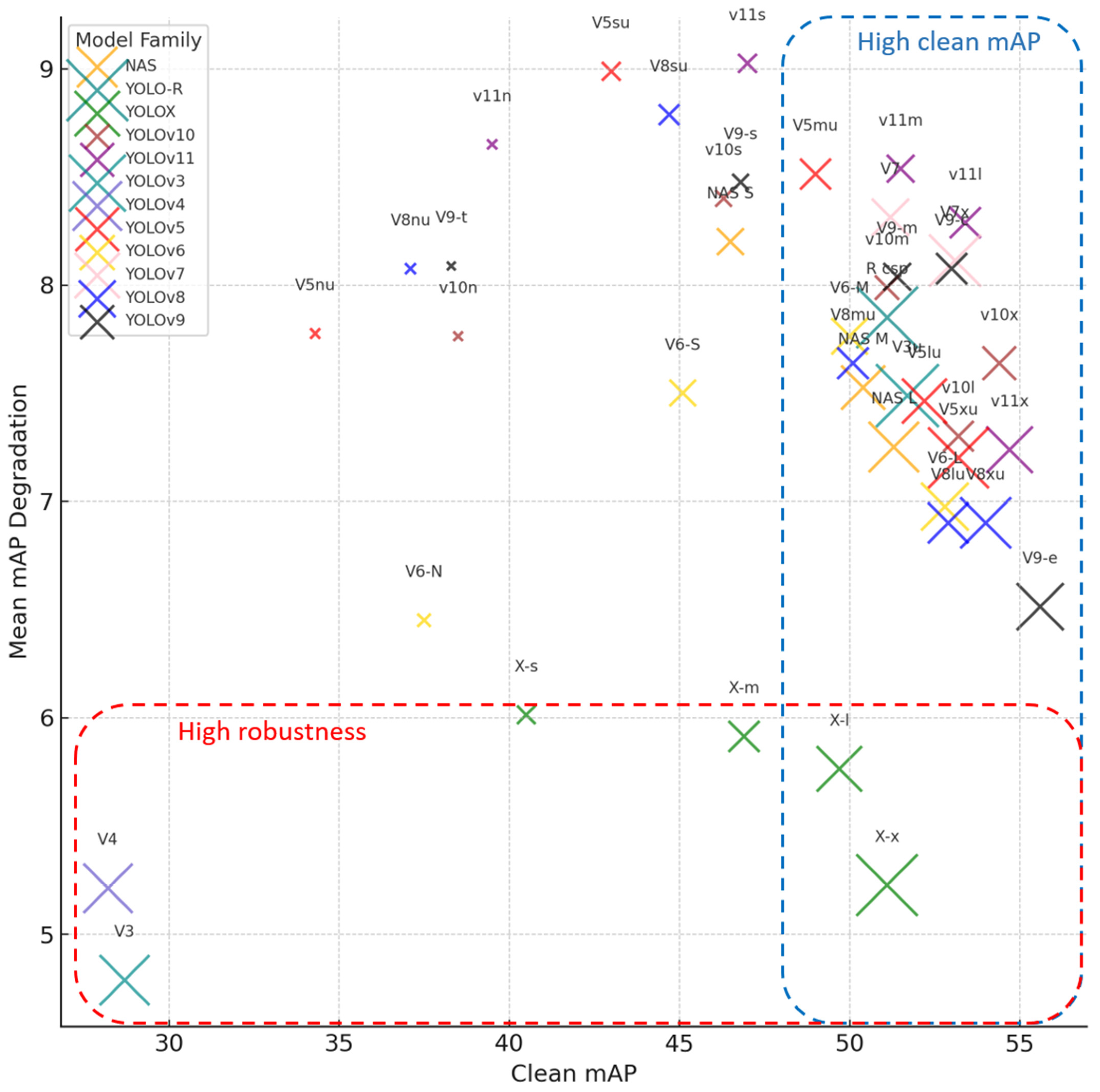
In
Figure 10, the overall behavior of the models is visualized. As is shown, the blue frame contains the models with high clean mAP performance while the red frame includes the models with the least mAP degradation. The intersection of these two frames provides us with models that achieve high mAP performance in both clean and attacked images. The size of the X marker in the figure is proportional to the number of parameters of each model; larger markers indicate models with higher parameter counts. It is observed that YOLOX-x and YOLOX-l are the only models that achieve both goals.
YOLOX models (particularly YOLOX-l and YOLOX-x) consistently exhibit low degradation across a range of attacks, such as FGSM and PGD, as well as various corruption types like Gaussian noise (GN) and pixelation. This suggests a high level of robustness in the YOLOX architecture, especially for large versions, making them suitable for environments where adversarial robustness is critical. YOLOX and certain versions of YOLOv3, YOLOv4, and YOLOv9-e are among the top-performing models across multiple corruption types. For example, they perform well under Gaussian noise (GN), defocus blur (DB), and motion blur (MB). This consistent robustness across diverse noise types implies that these models are better at handling various types of data imperfections, a key feature for applications in dynamic and uncontrolled environments.
Decoupled head: YOLOX is the first YOLO variant to adopt a decoupled head architecture, separating classification and localization into independent branches. This design improves robustness by minimizing task interference—allowing each head to specialize without being impacted by conflicting gradients. Under adversarial conditions or image corruptions, this separation helps the model maintain more stable predictions, as it reduces the risk of compounded errors due to misalignment between object classification and localization. Although later YOLO models also adopt decoupled heads, our results indicate that they do not achieve comparable robustness to YOLOX, suggesting that decoupling alone is not sufficient, but plays a complementary role within YOLOX’s overall architecture.
Strong Data Augmentation: YOLOX employs extensive data augmentation techniques during training, such as Mosaic and MixUp, which expose the model to a broader distribution of visual patterns. This improves robustness by helping the model generalize across different lighting, textures, and occlusion conditions—characteristics that are common in real-world noise and perturbations. However, as observed in our experiments, subsequent models like YOLOv7 also utilize strong data augmentation but do not exhibit similar robustness under adversarial attacks. This implies that while augmentation enhances generalization, it does not fully explain YOLOX’s superior resilience to perturbations and adversarial input.
Anchor-free Training: YOLOX replaces traditional anchor-based detection with an anchor-free mechanism, which simplifies the object detection process by eliminating predefined anchor box configurations. This not only reduces computational complexity but also improves robustness by avoiding overfitting to fixed anchor sizes and aspect ratios. Such flexibility enables the model to better detect objects that are distorted or misaligned due to adversarial noise or corruptions. Nonetheless, our experimental results show that models like YOLOv6 and YOLOv8, which also adopt anchor-free training, fail to match YOLOX’s robustness. This suggests that anchor-free design, while helpful, is likely not the primary factor contributing to YOLOX’s performance in adverse conditions.
Multi-Positives: YOLOX incorporates a multi-positive label assignment strategy, which allows multiple predicted boxes to be matched to a single ground truth object during training. This is particularly beneficial in cluttered scenes or when objects are partially occluded—scenarios where standard one-to-one matching may fail. By learning from multiple correct predictions, the model becomes more resilient to variations in object positioning and overlap. However, this technique is also used in later models like YOLOv6 and v7, which do not achieve the same robustness performance in our evaluations. Therefore, multi-positive assignment contributes to robustness but likely serves as a supporting mechanism rather than the core driver of YOLOX’s resilience.
SimOTA: SimOTA, or Simple Optimal Transport Assignment, is the only feature of YOLOX that other YOLO models do not use. SimOTA works by assigning predicted bounding boxes to ground truth objects using a cost matrix that evaluates each prediction based on two factors: IoU (Intersection over Union), which measures spatial alignment, and classification confidence, which reflects the likelihood of a correct class match. It calculates the total cost for each possible match, dynamically selecting only the top-k predictions with the lowest cost for each ground truth object. This dynamic top-k thresholding lets SimOTA adapt to the specific quality of predictions in each image, focusing training on the highest-quality matches. This selective matching helps the model learn only from the clearest examples, improving accuracy and generalization. By combining classification confidence (how likely the prediction represents the correct object) with spatial alignment (measured through Intersection over Union, or IoU), SimOTA creates a balanced and adaptive matching process. Unlike traditional methods that use fixed matching criteria, SimOTA employs dynamic thresholding, allowing it to select only the highest-quality predictions for training, based on the specific characteristics of each image. This adaptability ensures that the model learns from the clearest, most reliable examples, reducing the influence of noisy or ambiguous predictions. As a result, the model learns representations that capture essential, generalizable features of objects, making it more effective when deployed in varied real-world scenarios. This dual focus on quality and spatial accuracy makes SimOTA particularly robust, equipping models to handle new environments and unexpected variations in object appearance with improved accuracy and reliability.
In summary, although later YOLO models adopt several of YOLOX’s innovations, only YOLOX consistently demonstrates superior robustness. This implies that robustness is not the result of any single feature but likely emerges from the specific combination of architectural and methodological choices—with SimOTA potentially being the most impactful based on our findings.
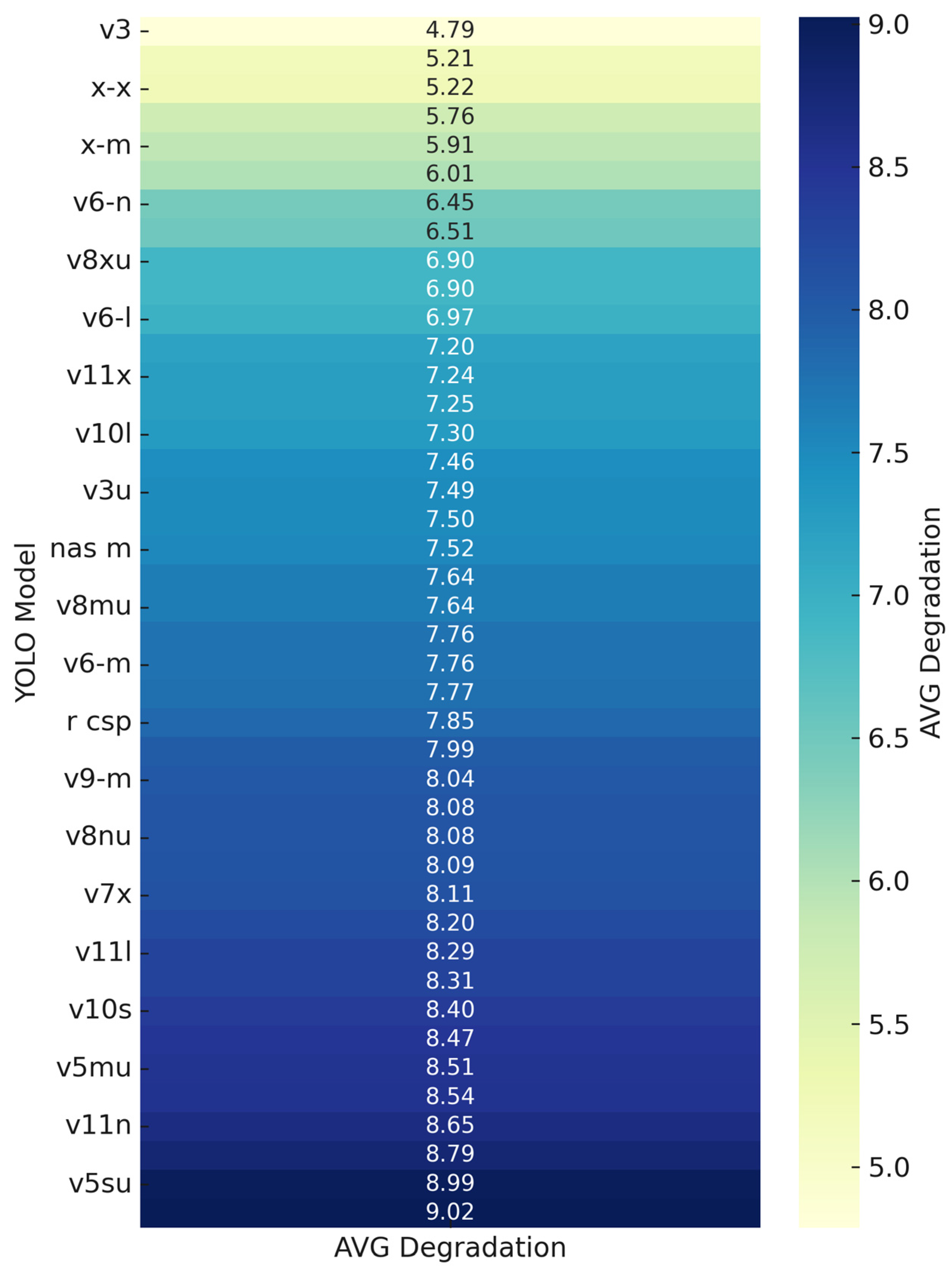
Also, it is observed that some small models behave better in some types of noise. In pixelate noise, motion blur, and defocus blur, the nano versions of v5, v6, v8, v10, and v11 present significant improvement in degradation than the bigger corresponding version. This may be because larger models with more parameters have a higher capacity to learn fine details in training data. While this allows them to capture intricate patterns in clean images, it also makes them more sensitive to high-frequency details and pixel-level structures. While larger model capacity generally leads to greater robustness against adversarial attacks, this is not necessarily the case for image corruption. This also can be shown in
Figure 6, which illustrates the overall performance of each model in relation to its corresponding size.
Despite their overall robustness, even the top models experience variability in their resilience based on the type of corruption. Pixelation, in particular, leads to a notable drop in performance for many models, but YOLOX-x and YOLOX-l handle it relatively well compared to others. This indicates that while robustness is high in general, certain noise types still pose challenges, and specialized defenses might be needed for pixelation-type noises. Based on these results, YOLOX models, especially in their larger variants, are likely the best choice for applications requiring high robustness against adversarial attacks and corruption. While YOLOv3 and YOLOv4 could still be considered viable options, their relatively poor performance in clean images suggests they may not be the optimal choice for applications where accuracy is a critical requirement. Since YOLOv3 and YOLOv4 already perform relatively poorly on clean images compared to more advanced models, the degree of degradation they experience under various corruptions may appear less pronounced. In terms of architectural foundations, YOLOX incorporates components that were already explored in previous YOLO versions, but it also introduces distinct advancements that appear to enhance its robustness. YOLOX leverages CSPNet as its backbone—a structure that is also used in YOLOv5—while utilizing an FPN-based neck, as found in YOLOv3 and YOLOv3u. Despite these commonalities, YOLOv5 and YOLOv3u do not exhibit notable robustness against adversarial attacks and image corruption, suggesting that robustness in YOLOX is likely attributed to additional factors beyond these shared architectural elements. YOLOX builds upon YOLOv3 but makes five critical modifications: (1) decoupled head, (2) strong data augmentation, (3) anchor-free training, (4) multi-positives, and (5) SimOTA. To investigate the underlying factors contributing to the robustness of YOLOX, an analysis of the key architectural and methodological improvements it introduces is conducted hereafter.
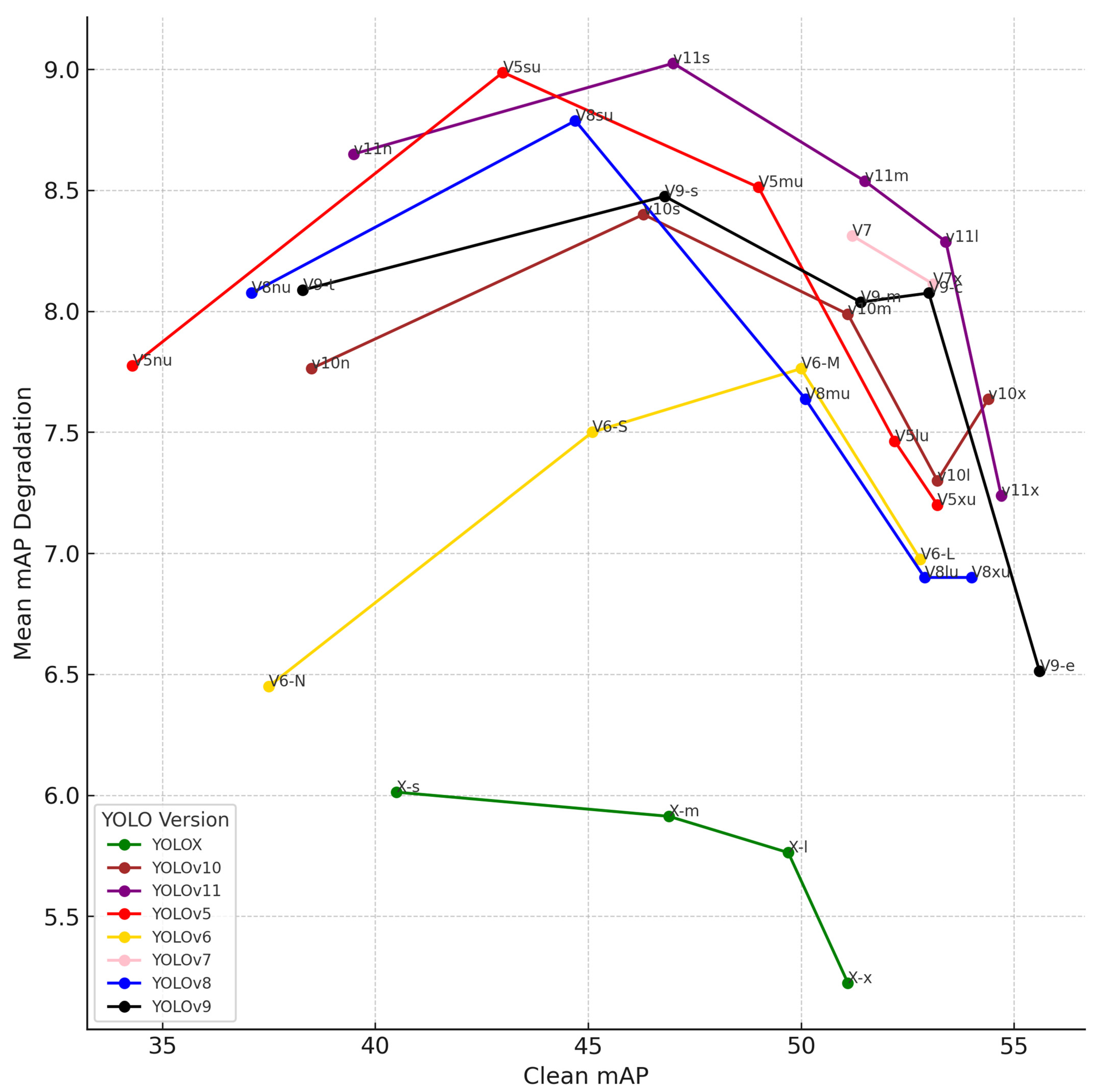
Almost all models exhibit an upward trend in performance as their model size increases, with a characteristic curve after their smallest version (
Figure 11). However, YOLOX deviates from this pattern, showing a downward trend in performance as model size increases. Additionally, smaller models generally achieve relatively low mean Average Precision (mAP) scores. Small models may inherently show limited mAP improvement with further reductions in model size because their baseline performance is already constrained by their reduced capacity. These models, designed with fewer parameters and simpler architectures, often lack the depth and feature extraction ability needed to capture intricate patterns in the data. Consequently, they start with relatively low mAP, meaning there is less room for a noticeable drop.
A limitation of our study is that we evaluated pre-trained models on a fixed test set without retraining. As a result, conventional statistical significance tests or confidence interval analyses could not be directly applied, since model-level variance across multiple training runs was not available. Future work involving retraining models from scratch or using cross-validation would allow for more rigorous statistical validation of the observed robustness differences.
Additionally, the scope of adversarial attacks in this study was limited to FGSM and PGD due to their wide adoption and interpretability, particularly in benchmarking scenarios. More recent and powerful attacks, such as AutoAttack, APGD, or Square Attack, were not included, mainly due to the high computational cost associated with testing a large number of YOLO variants. Moreover, our experiments focused on a black-box threat model, which better reflects real-world conditions where model internals are typically inaccessible to attackers. However, we acknowledge that evaluating under white-box settings and incorporating stronger adversarial attacks would offer a more comprehensive assessment of model robustness. We consider this an important direction for future research.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}