
WGA-SWIN: Efficient Multi-View 3D Object Reconstruction Using Window Grouping Attention in Swin Transformer





Abstract
:1. Introduction
- (1)
- We present a Window Grouping Attention (WGA) mechanism, which can segment tokens into groups from individual window attentions and efficiently establish both inter-view and intra-view feature extraction. A novel encoder is introduced for operating multi-view inputs by integrating WGA into a swin transformer architecture to enhance 3D reconstruction accuracy.
- (2)
- We introduce a progressive hierarchical decoder to integrate a 3D CNN and a swin transformer block to address the dependencies of working on the comparatively high-resolution voxel that can enhance reconstruction capability.
- (3)
- The experimental results on the datasets ShapeNet and Pix3D represent that our work outperforms other SOTA methods in both multi-view and single-view 3D object reconstruction.
2. Related Work
2.1. Multi-View 3D Reconstruction
2.2. Group Window Attention
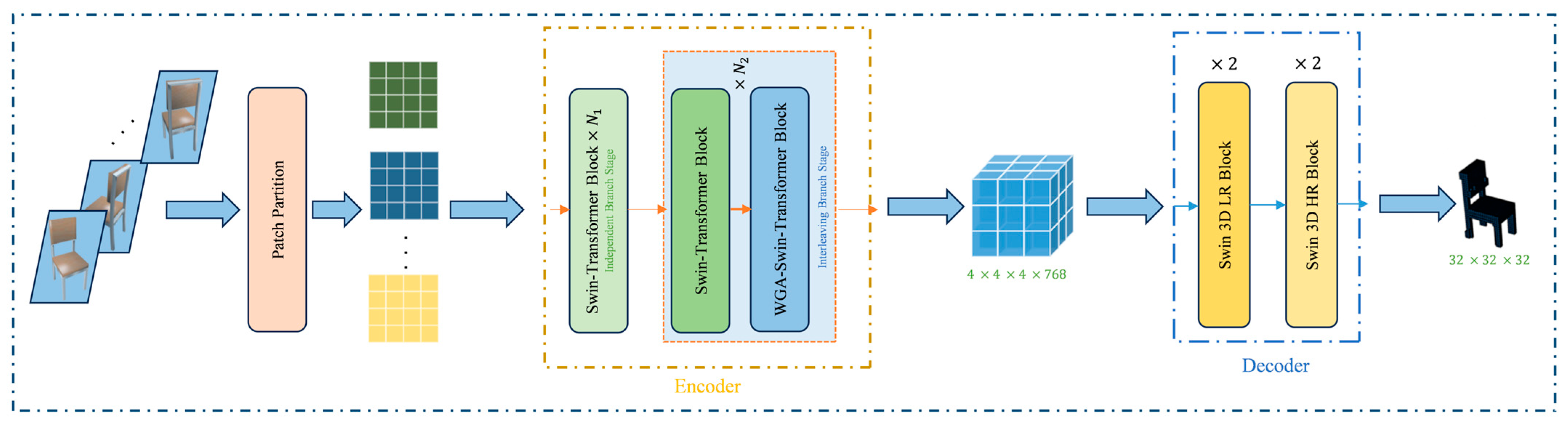
3. Methods
3.1. Encoder
3.1.1. Independent Branch Stage
3.1.2. Interleaving Branch Stage
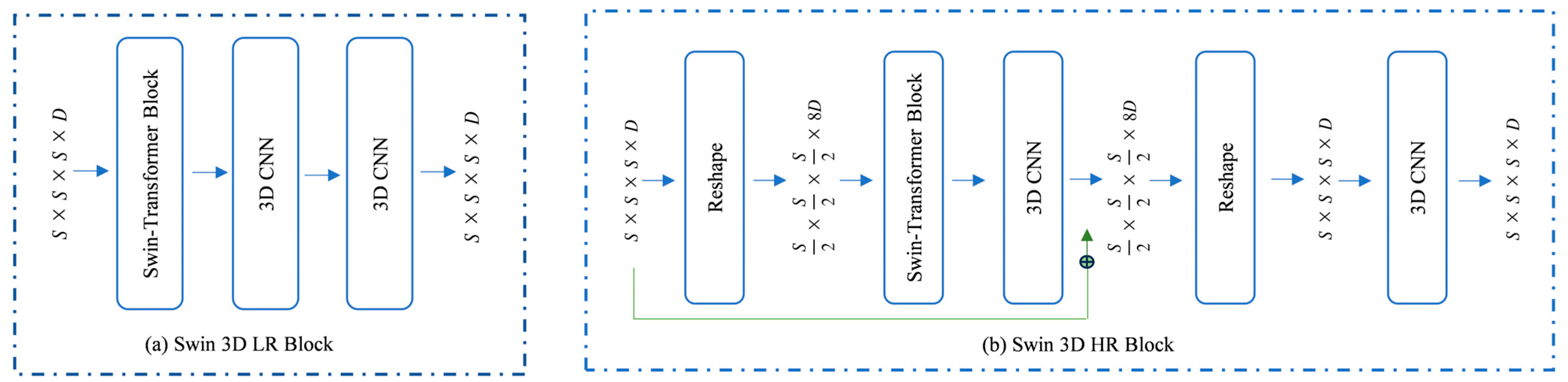
3.2. Decoder
3.3. Loss Function
4. Experimental Analysis
4.1. Dataset
4.2. Evaluation Metrics
4.3. Experimental Setup
4.4. Results and Discussion
4.4.1. Quantitative Results
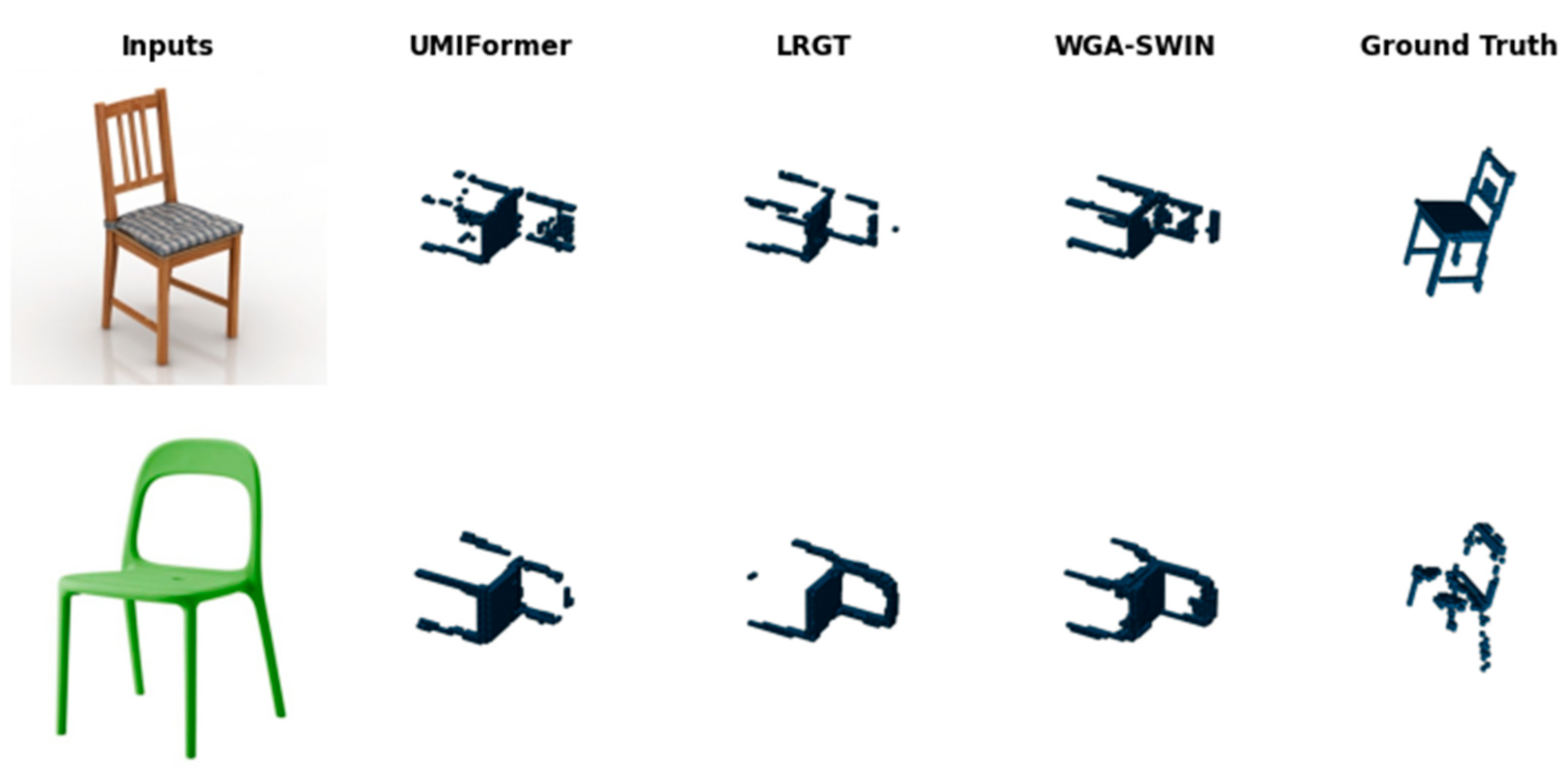
4.4.2. Qualitative Results
4.4.3. Evaluation of Real-World Objects
4.5. Ablation Study
4.5.1. Effectiveness of Encoder
4.5.2. Effectiveness of Decoder
4.5.3. Inference Efficiency
4.6. Failure Cases
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, J.; Wyman, O.; Tang, Y.; Pasini, D.; Wang, W. Multi-view 3D reconstruction based on deep learning: A survey and comparison of methods. Neurocomputing 2024, 582, 127553. [Google Scholar] [CrossRef]
- Özyeşil, O.; Voroninski, V.; Basri, R.; Singer, A. A survey of structure from motion. Acta Numer. 2017, 26, 305–364. [Google Scholar] [CrossRef]
- Fuentes-Pacheco, J.; Ruiz-Ascencio, J.; Rendón-Mancha, J.M. Visual simultaneous localization and mapping: A survey. Artif. Intell. Rev. 2015, 43, 55–81. [Google Scholar] [CrossRef]
- Kar, A.; Häne, C.; Malik, J. Learning a multi-view stereo machine. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 364–375. [Google Scholar]
- Choy, C.B.; Xu, D.; Gwak, J.; Chen, K.; Savarese, S. 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 628–644. [Google Scholar]
- Yang, B.; Wang, S.; Markham, A.; Trigoni, N. Robust Attentional Aggregation of Deep Feature Sets for Multi-view 3D Reconstruction. Int. J. Comput. Vis. 2020, 128, 53–73. [Google Scholar] [CrossRef]
- Xie, H.; Yao, H.; Sun, X.; Zhou, S.; Zhang, S. Pix2Vox: Context-Aware 3D Reconstruction from Single and Multi-View Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 2690–2698. [Google Scholar]
- Wang, M.; Wang, L.; Fang, Y. 3DensiNet: A Robust Neural Network Architecture towards 3D Volumetric Object Prediction from 2D Image. In Proceedings of the 25th ACM International Conference on Multimedia, Mountain View, CA, USA, 23–27 October 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 961–969. [Google Scholar]
- Xie, H.; Yao, H.; Zhang, S.; Zhou, S.; Sun, W. Pix2Vox++: Multi-scale Context-aware 3D Object Reconstruction from Single and Multiple Images. Int. J. Comput. Vis. 2020, 128, 2919–2935. [Google Scholar] [CrossRef]
- Zhu, Z.; Yang, L.; Lin, X.; Yang, L.; Liang, Y. GARNet: Global-aware multi-view 3D reconstruction network and the cost-performance tradeoff. Pattern Recognit. 2023, 142, 109674. [Google Scholar] [CrossRef]
- Yang, L.; Zhu, Z.; Nong, X.L.J.; Liang, Y. Long-Range Grouping Transformer for Multi-View 3D Reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023. [Google Scholar]
- Wang, D.; Cui, X.; Chen, X.; Zou, Z.; Shi, T.; Salcudean, S.; Wang, Z.J.; Ward, R. Multi-view 3D Reconstruction with Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Zhu, Z.; Yang, L.; Li, N.; Jiang, C.; Liang, Y. UMIFormer: Mining the Correlations between Similar Tokens for Multi-View 3D Reconstruction. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Paris, France, 1–6 October 2023. [Google Scholar]
- Shi, Z.; Meng, Z.; Xing, Y.; Ma, Y.; Wattenhofer, R. 3D-RETR: End-to-End Single and Multi-View 3D Reconstruction with Transformers. In Proceedings of the 32nd British Machine Vision Conference, BMVC 2021, Online, 22–25 November 2021. [Google Scholar]
- Yagubbayli, F.; Tonioni, A.; Tombari, F. LegoFormer: Transformers for Block-by-Block Multi-view 3D Reconstruction. arXiv 2021, arXiv:2106.12102. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16× 16 words: Transformers for image recognition at scale. In Proceedings of the ICLR 2021—9th International Conference on Learning Representations, Vienna, Austria, 3–7 May 2021. [Google Scholar]
- Zhu, M.; Zhao, Z.; Cai, W. Hybrid Focal and Full-Range Attention Based Graph Transformers. In Proceedings of the 2024 International Joint Conference on Neural Networks (IJCNN), Yokohama, Japan, 30 June–5 July 2024; pp. 1–9. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Li, C.; Xiao, M.; Chen, F.; Qiao, S.; Wang, D.; Gao, M.; Zhang, S. R3D-SWIN:Use Shifted Window Attention for Single-View 3D Reconstruction. arXiv 2023, arXiv:2312.02725. [Google Scholar]
- Hossain, M.d.B.; Shinde, R.K.; Imtiaz, S.M.; Hossain, F.M.F.; Jeon, S.-H.; Kwon, K.-C.; Kim, N. Swin Transformer and the Unet Architecture to Correct Motion Artifacts in Magnetic Resonance Image Reconstruction. Int. J. Biomed. Imaging. 2024, 2024, 8972980. [Google Scholar] [CrossRef] [PubMed]
- Kerbl, B.; Kopanas, G.; Leimkuehler, T.; Drettakis, G. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Trans. Graph. 2023, 42, 1–14. [Google Scholar] [CrossRef]
- Hedman, P.; Srinivasan, P.P.; Mildenhall, B.; Barron, J.T.; Debevec, P. Baking Neural Radiance Fields for Real-Time View Synthesis. In Proceedings of the IEEE International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Ning, X.; Jiang, L.; Li, W.; Yu, Z.; Xie, J.; Li, L.; Tiwari, P.; Alonso-Fernandez, F. Swin-MGNet: Swin Transformer based Multi-view Grouping Network for 3D Object Recognition. IEEE Trans. Artif. Intell. 2024, 6, 747–758. [Google Scholar] [CrossRef]
- Zeng, Y.; Fu, J.; Chao, H. Learning Joint Spatial-Temporal Transformations for Video Inpainting. In Computer Vision—ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 528–543. [Google Scholar]
- Liu, R.; Deng, H.; Huang, Y.; Shi, X.; Lu, L.; Sun, W.; Wang, X.; Dai, J.; Li, H. Decoupled Spatial-Temporal Transformer for Video Inpainting. arXiv 2021, arXiv:2104.06637. [Google Scholar]
- Li, G.; Cui, Z.; Li, M.; Han, Y.; Li, T. Multi-attention fusion transformer for single-image super-resolution. Sci. Rep. 2024, 14, 10222. [Google Scholar] [CrossRef] [PubMed]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. SwinIR: Image Restoration Using Swin Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Chang, A.X.; Funkhouser, T.; Guibas, L.; Hanrahan, P.; Huang, Q.; Li, Z.; Savarese, S.; Savva, M.; Song, S.; Su, H.; et al. ShapeNet: An Information-Rich 3D Model Repository. arXiv 2015, arXiv:1512.03012. [Google Scholar]
- Sun, X.; Wu, J.; Zhang, X.; Zhang, Z.; Zhang, C.; Xue, T.; Tenenbaum, J.B.; Freeman, W.T. Pix3D: Dataset and Methods for Single-Image 3D Shape Modeling. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Tatarchenko, M.; Richter, S.R.; Ranftl, R.; Li, Z.; Koltun, V.; Brox, T. What do single-view 3D reconstruction networks learn? In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Su, H.; Qi, C.R.; Li, Y.; Guibas, L.J. Render for CNN: Viewpoint Estimation in Images Using CNNs Trained with Rendered 3D Model Views ILSVRC Image Classification Top-5 Error (%). In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Xiao, J.; Hays, J.; Ehinger, K.A.; Oliva, A.; Torralba, A. SUN database: Large-scale scene recognition from abbey to zoo. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 3485–3492. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | 1 View | 2 Views | 3 Views | 4 Views | 5 Views | 8 Views | 12 Views | 16 Views | 20 Views |
|---|---|---|---|---|---|---|---|---|---|
| 3D-R2N2 [5] | 0.560 | 0.603 | 0.617 | 0.625 | 0.634 | 0.635 | 0.636 | 0.636 | 0.636 |
| AttSets [6] | 0.642 | 0.662 | 0.670 | 0.675 | 0.677 | 0.685 | 0.688 | 0.692 | 0.693 |
| Pix2Vox++ [9] | 0.670 | 0.695 | 0.704 | 0.708 | 0.711 | 0.715 | 0.717 | 0.718 | 0.719 |
| GARNet [10] | 0.673 | 0.705 | 0.716 | 0.722 | 0.726 | 0.731 | 0.734 | 0.736 | 0.737 |
| GARNet++ | 0.655 | 0.696 | 0.712 | 0.719 | 0.725 | 0.733 | 0.737 | 0.740 | 0.742 |
| EVolT [12] | - | - | - | 0.609 | - | 0.698 | 0.720 | 0.729 | 0.735 |
| LegoFormer [15] | 0.519 | 0.644 | 0.679 | 0.694 | 0.703 | 0.713 | 0.717 | 0.719 | 0.721 |
| 3D-RETR [14] | 0.674 | 0.707 | 0.716 | 0.720 | 0.723 | 0.727 | 0.729 | 0.730 | 0.731 |
| UMIFormer [13] | 0.6802 | 0.7384 | 0.7518 | 0.7573 | 0.7612 | 0.7661 | 0.7682 | 0.7696 | 0.7702 |
| UMIFormer+ | 0.5672 | 0.7115 | 0.7447 | 0.7588 | 0.7681 | 0.7790 | 0.7843 | 0.7873 | 0.7886 |
| LRGT [11] | 0.6962 | 0.7462 | 0.7590 | 0.7653 | 0.7692 | 0.7744 | 0.7766 | 0.7781 | 0.7786 |
| LRGT+ | 0.5847 | 0.7145 | 0.7476 | 0.7625 | 0.7719 | 0.7833 | 0.7888 | 0.7912 | 0.7922 |
| WGA-SWIN | 0.7032 | 0.7487 | 0.7636 | 0.7732 | 0.7748 | 0.7786 | 0.7808 | 0.7819 | 0.7827 |
| WGA-SWIN+ | 0.5976 | 0.7217 | 0.7563 | 0.7712 | 0.7814 | 0.7882 | 0.7955 | 0.7996 | 0.8017 |
| Methods | 1 View | 2 Views | 3 Views | 4 Views | 5 Views | 8 Views | 12 Views | 16 Views | 20 Views |
|---|---|---|---|---|---|---|---|---|---|
| 3D-R2N2 [5] | 0.351 | 0.372 | 0.372 | 0.378 | 0.382 | 0.383 | 0.382 | 0.382 | 0.383 |
| AttSets [6] | 0.395 | 0.418 | 0.426 | 0.430 | 0.432 | 0.444 | 0.445 | 0.447 | 0.448 |
| Pix2Vox++ [9] | 0.436 | 0.452 | 0.455 | 0.457 | 0.458 | 0.459 | 0.460 | 0.461 | 0.462 |
| GARNet [10] | 0.418 | 0.455 | 0.468 | 0.475 | 0.479 | 0.486 | 0.489 | 0.491 | 0.492 |
| GARNet++ | 0.399 | 0.446 | 0.465 | 0.475 | 0.481 | 0.491 | 0.498 | 0.501 | 0.504 |
| EVolT [12] | - | - | - | 0.358 | - | 0.448 | 0.475 | 0.486 | 0.492 |
| LegoFormer [15] | 0.282 | 0.392 | 0.428 | 0.444 | 0.453 | 0.464 | 0.470 | 0.472 | 0.472 |
| 3D-RETR [14] | - | - | - | - | - | - | - | - | - |
| UMIFormer [13] | 0.4281 | 0.4919 | 0.5067 | 0.5127 | 0.5168 | 0.5213 | 0.5232 | 0.5245 | 0.5251 |
| UMIFormer+ | 0.3177 | 0.4568 | 0.4947 | 0.5104 | 0.5216 | 0.5348 | 0.5415 | 0.5451 | 0.5466 |
| LRGT [11] | 0.4461 | 0.5005 | 0.5148 | 0.5214 | 0.5257 | 0.5311 | 0.5337 | 0.5347 | 0.5353 |
| LRGT+ | 0.3378 | 0.4618 | 0.4989 | 0.5161 | 0.5271 | 0.5403 | 0.5467 | 0.5497 | 0.5510 |
| WGA-SWIN | 0.4596 | 0.5095 | 0.5261 | 0.5312 | 0.5354 | 0.5408 | 0.5427 | 0.5442 | 0.5457 |
| WGA-SWIN+ | 0.3492 | 0.4723 | 0.5109 | 0.5297 | 0.5379 | 0.5492 | 0.5565 | 0.5594 | 0.5617 |
| UMIFormer [13] | LRGT [11] | WGA-SWIN |
|---|---|---|
| 0.317/0.142 | 0.302/0.129 | 0.321/0.147 |
| WGA | W-MSA | 3 Views | 5 Views | 8 Views | 12 Views | 16 Views | 20 Views |
|---|---|---|---|---|---|---|---|
| × | ✓ | 0.7562 | 0.7679 | 0.7713 | 0.7758 | 0.7783 | 0.7790 |
| ✓ | × | 0.7636 | 0.7748 | 0.7786 | 0.7808 | 0.7819 | 0.7827 |
| 3 Views | 5 Views | 8 Views | 12 Views | 16 Views | 20 Views | |
|---|---|---|---|---|---|---|
| 36 | 0.7592 | 0.7702 | 0.7744 | 0.7787 | 0.7798 | 0.7809 |
| 49 | 0.7636 | 0.7748 | 0.7786 | 0.7808 | 0.7819 | 0.7827 |
| 64 | 0.7612 | 0.7734 | 0.7772 | 0.7795 | 0.7808 | 0.7816 |
| Decoder | 3 Views | 5 Views | 8 Views | 12 Views | 16 Views | 20 Views |
|---|---|---|---|---|---|---|
| LegoFormer [15] | 0.7536 | 0.7643 | 0.7696 | 0.7729 | 0.7737 | 0.7751 |
| 3D-RETR [14] | 0.7592 | 0.7685 | 0.7723 | 0.7775 | 0.7787 | 0.7796 |
| LRGT [11] | 0.7581 | 0.7687 | 0.7721 | 0.7766 | 0.7773 | 0.7785 |
| WGA-SWIN (Ours) | 0.7636 | 0.7748 | 0.7786 | 0.7808 | 0.7819 | 0.7827 |
| Models | 3 Views | 8 Views | 12 Views | 16 Views | 20 Views |
|---|---|---|---|---|---|
| UMIFormer [13] | 0.0328 (s) | 0.0494 (s) | 0.0652 (s) | 0.0818 (s) | 0.0995 (s) |
| LRGT [11] | 0.0319 (s) | 0.0480 (s) | 0.0639 (s) | 0.0796 (s) | 0.0983 (s) |
| WGA-SWIN (Ours) | 0.0302 (s) | 0.0469 (s) | 0.0627 (s) | 0.0784 (s) | 0.0973 (s) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mamun, S.S.; Ren, S.; Rakib, M.Y.K.; Asafa, G.F. WGA-SWIN: Efficient Multi-View 3D Object Reconstruction Using Window Grouping Attention in Swin Transformer. Electronics 2025, 14, 1619. https://doi.org/10.3390/electronics14081619
Mamun SS, Ren S, Rakib MYK, Asafa GF. WGA-SWIN: Efficient Multi-View 3D Object Reconstruction Using Window Grouping Attention in Swin Transformer. Electronics. 2025; 14(8):1619. https://doi.org/10.3390/electronics14081619
Chicago/Turabian StyleMamun, Sheikh Sohan, Shengbing Ren, MD Youshuf Khan Rakib, and Galana Fekadu Asafa. 2025. "WGA-SWIN: Efficient Multi-View 3D Object Reconstruction Using Window Grouping Attention in Swin Transformer" Electronics 14, no. 8: 1619. https://doi.org/10.3390/electronics14081619
APA StyleMamun, S. S., Ren, S., Rakib, M. Y. K., & Asafa, G. F. (2025). WGA-SWIN: Efficient Multi-View 3D Object Reconstruction Using Window Grouping Attention in Swin Transformer. Electronics, 14(8), 1619. https://doi.org/10.3390/electronics14081619