

A Generic Image Steganography Recognition Scheme with Big Data Matching and an Improved ResNet50 Deep Learning Network


Abstract

1. Introduction
- (1)
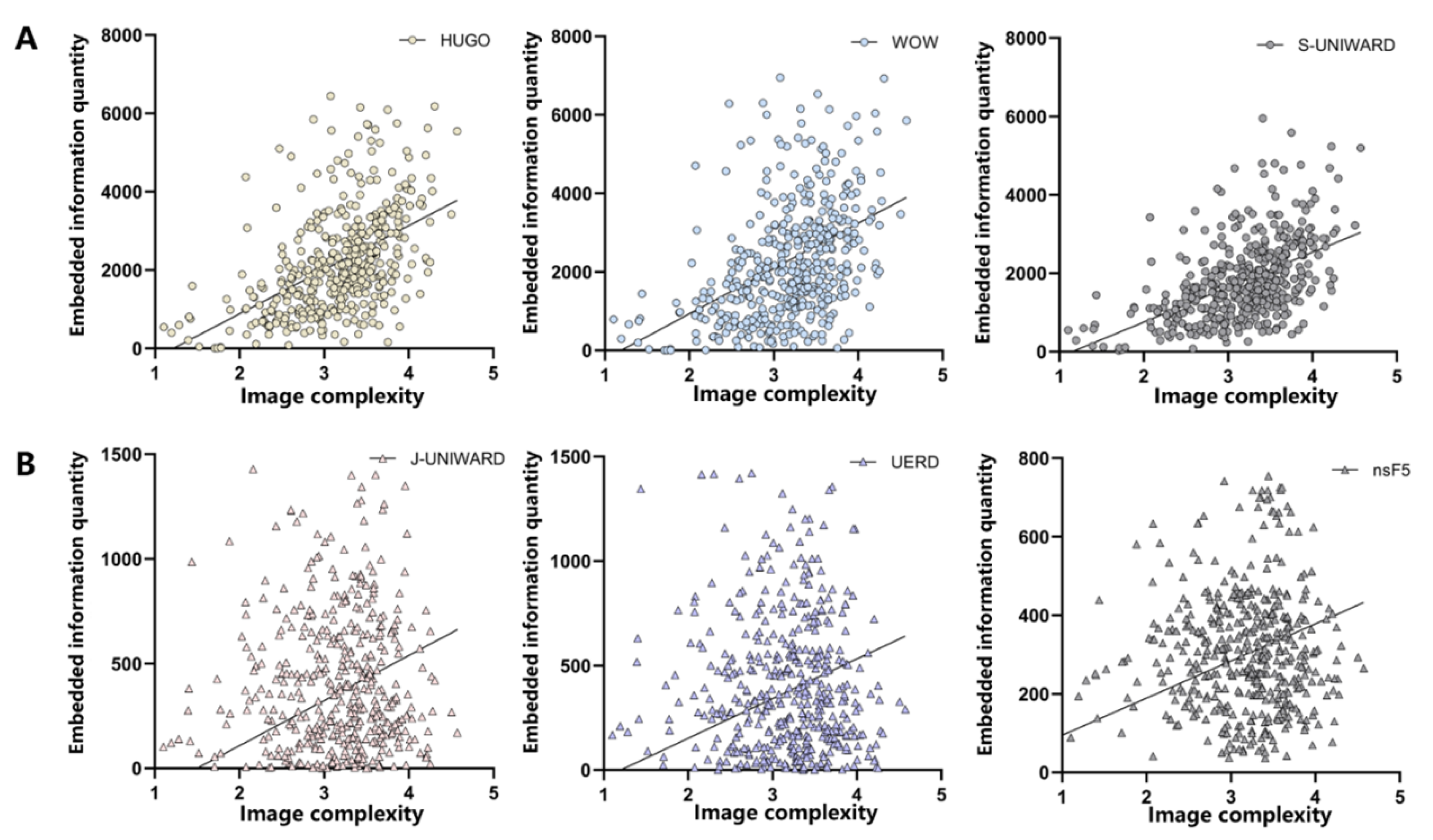
- We explore the differences in image modification caused by six image steganography algorithms under the same parameters, innovatively propose using the entropy value of the gray level co-occurrence matrix (GLCM) [10] to quantify the image complexity, and verify the positive correlation between the image complexity and the embedding position of steganographic information, which provides a new idea for the characterization of steganographic behavior.
- (2)
- For the first time, we introduce the image big data matching technique into the field of steganography analysis to solve the problem of insufficient accuracy in locating steganographic information in image steganography detection. The technique accurately identifies the embedded location of steganographic information by precisely matching the steganographic image with its original image, which provides important support for the efficient recognition of steganography algorithms.
- (3)
- We improve the ResNet50 model by combining the pyramid attention mechanism and the joint loss function based on Softmax loss [11] and ArcFace loss [12], which significantly improves the recognition accuracy and efficiency of the steganography algorithm. The method shows strong generality and robustness under multiple steganographic algorithms and image formats.
2. Related Work
2.1. Traditional Image Steganalysis Algorithms
2.2. Deep Learning-Based Image Steganalysis Algorithm
3. Program Design
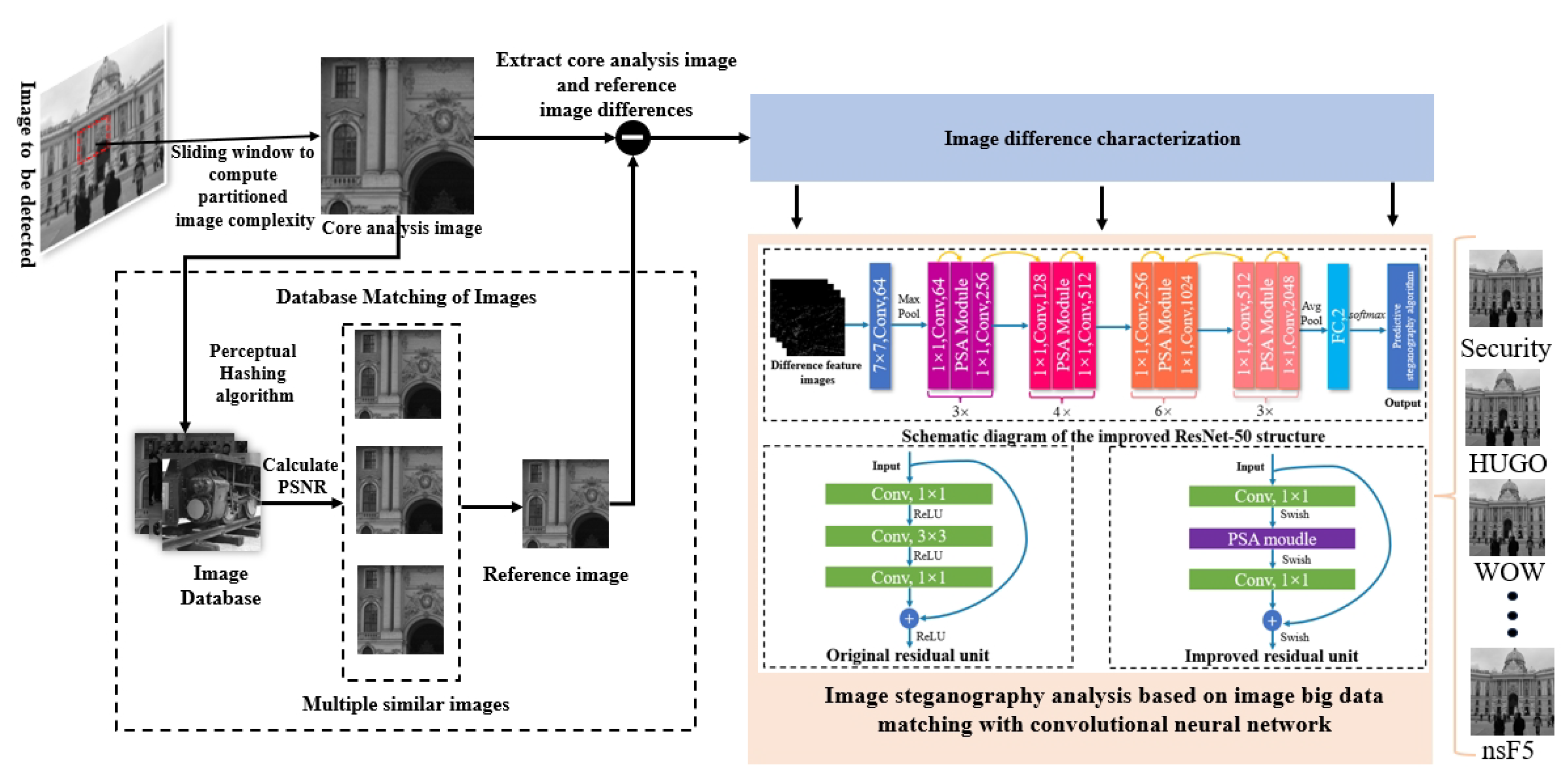
3.1. Overall Program Architecture
- (1)
- Apply the sliding window technique to partition the image to be detected, calculate the entropy value of the gray level co-occurrence matrix (GLCM) of each region to quantify the image complexity, and intercept the region with the highest complexity as the core analysis part.
- (2)
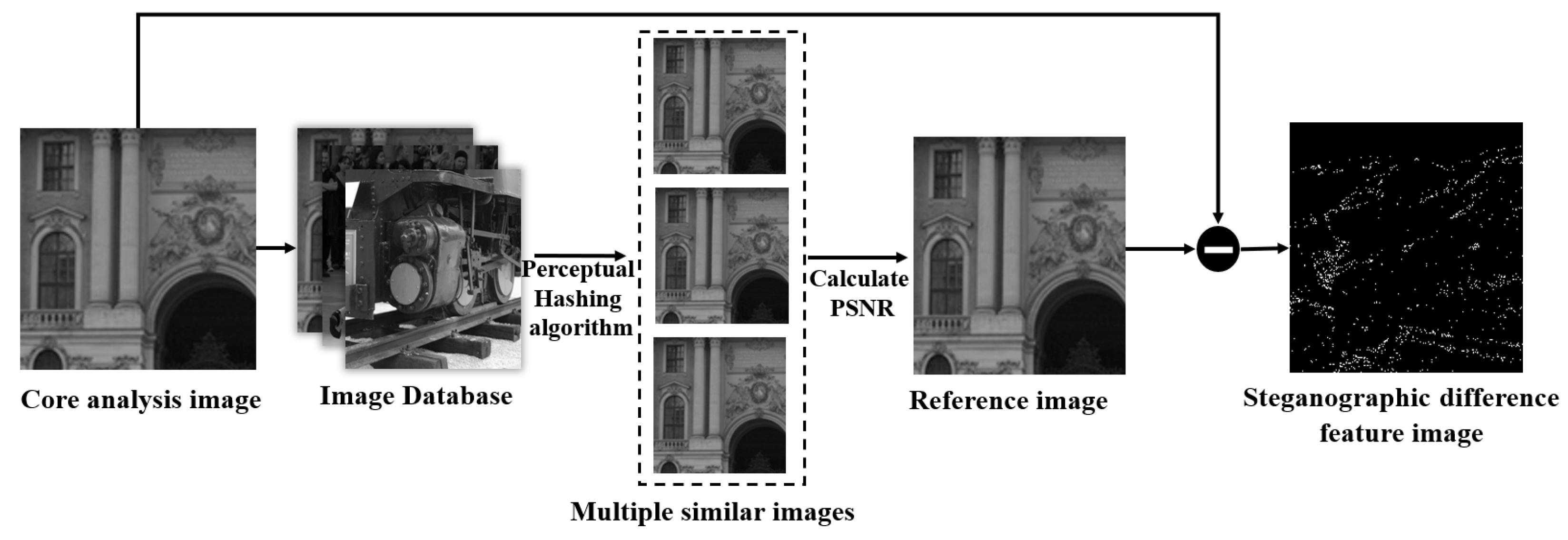
- Apply a perceptual hash algorithm to quickly match the core analysis images, retrieve them against images in a local database or a cloud database connected via the web, and extract all similar images. For the matched multiple similar images, Peak Signal-to-Noise Ratio () [30] is used for accurate similarity calculation, and the image with the highest similarity is selected as the reference image so as to generate the steganographic difference feature image between the reference image and the core analysis image.
- (3)
- The steganographic difference feature images are fed into the improved ResNet50-based steganography algorithm recognition model for deep feature extraction and classification. According to the output results of the model, the final judgment is made on whether the image to be detected is a safe image or not. Further, it completes the recognition task of the steganography algorithm.
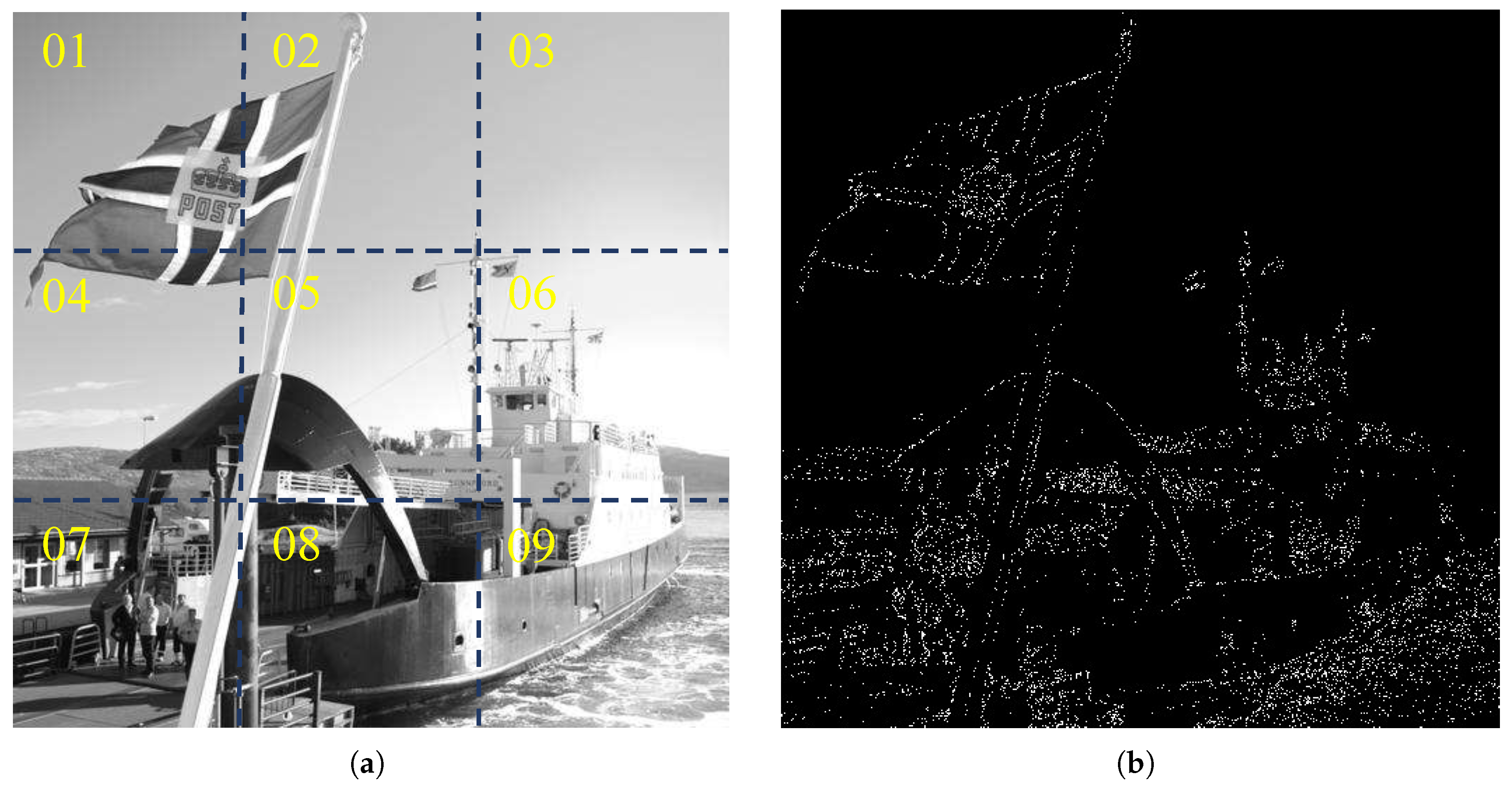
3.2. GLCM-Based Image Selection for Core Analysis
3.3. Image Big Data Matching and Steganographic Difference Feature Image Acquisition
3.3.1. Image Big Data Matching
3.3.2. Steganographic Difference Feature Image Acquisition
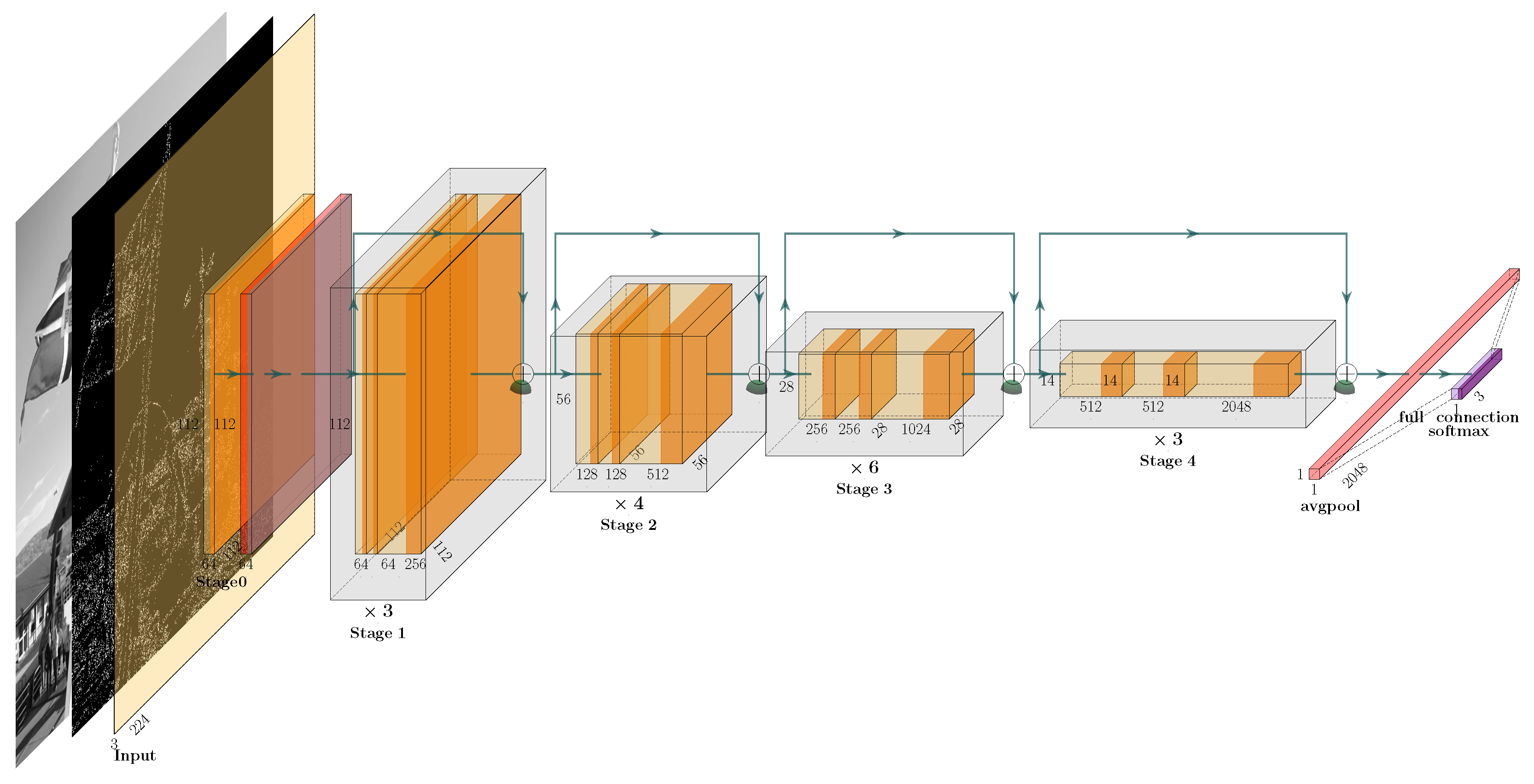
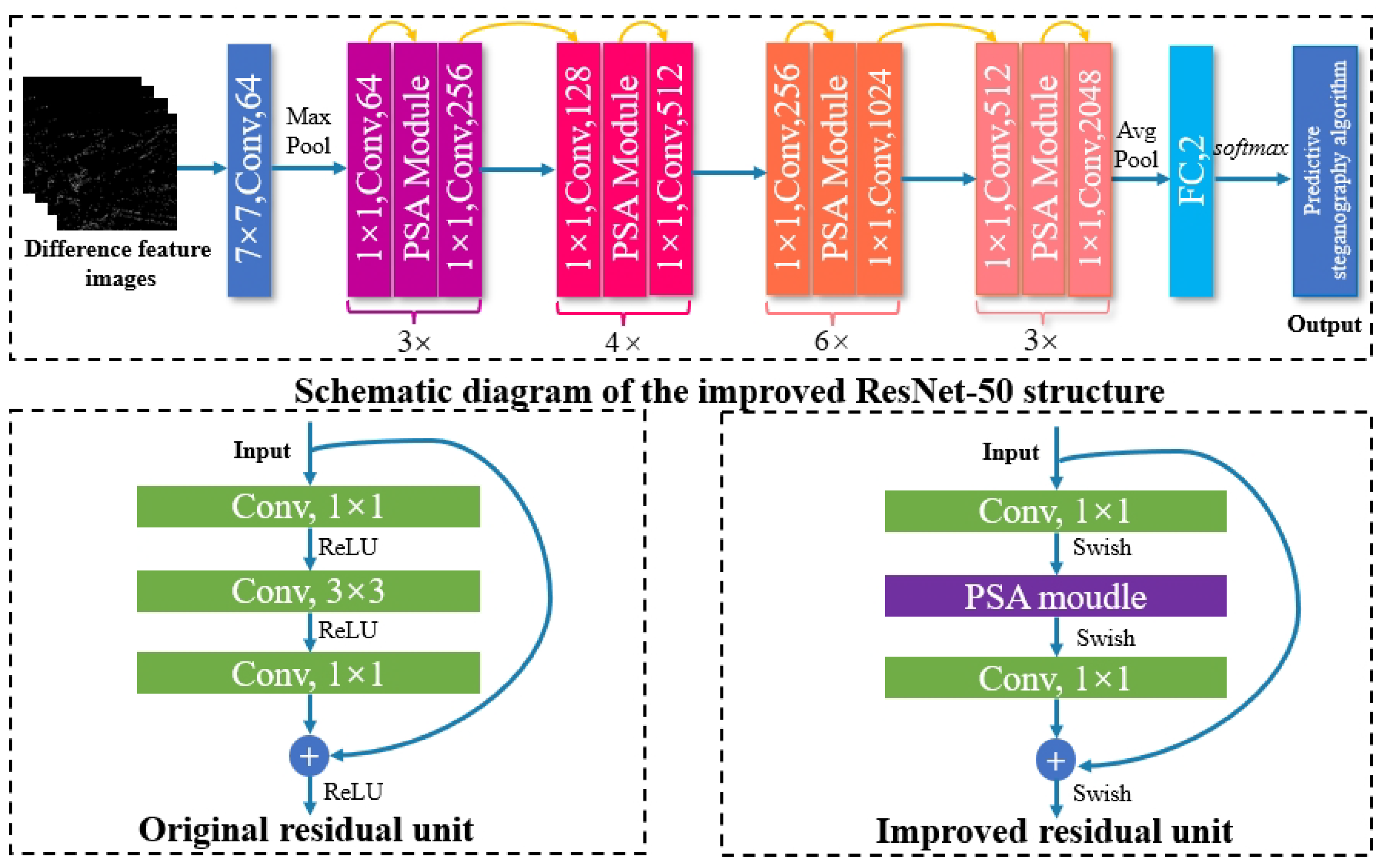
3.4. Image Steganography Algorithm Recognition Model Based on Improved ResNet50
3.4.1. ResNet50 Deep Learning Network
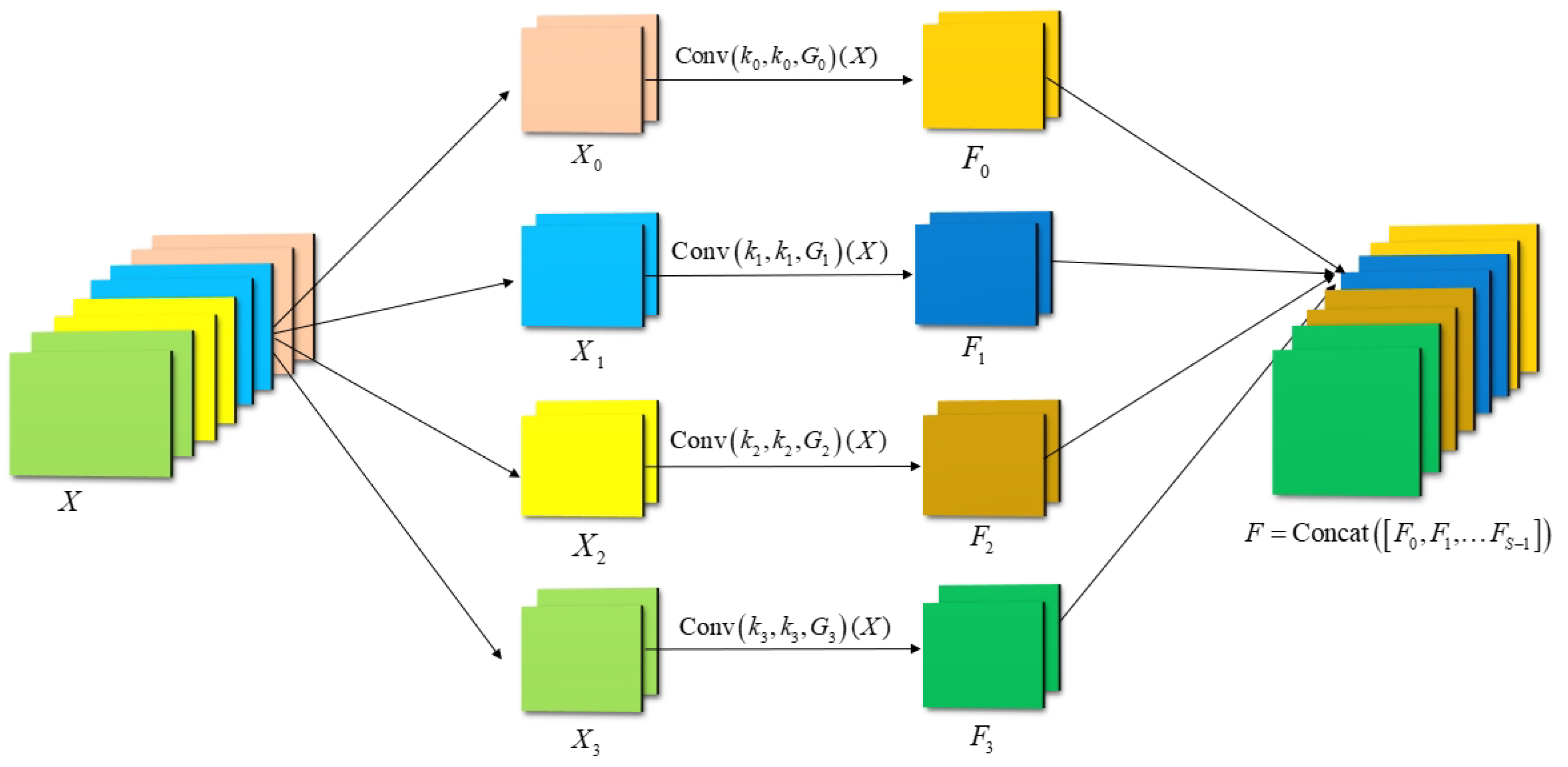
3.4.2. Pyramid Split Attention Module
- (a)
- The computation process of the SPC within the PSA module is illustrated in Figure 8. This module constructs a feature pyramid using multi-scale grouped convolution to extract spatial information across different scales within channel feature maps, generating feature maps with various resolutions and depths. Specifically, the input feature map is first divided along the channel dimension into S parts, denoted as , with each part containing channels. Convolution operations with different kernel sizes are then applied to each part, where the kernel size is determined by . To mitigate the significant increase in computational complexity caused by larger kernel sizes, the SPC module employs grouped convolution for each part, with the number of groups defined as . Multi-scale feature maps are generated for each part using the formula , and these feature maps are concatenated along the channel dimension to form a multi-channel representation enriched with multi-scale information, expressed as . By combining multi-scale grouped convolution and concatenation, the SPC module effectively captures multi-scale spatial features while significantly reducing computational complexity, thereby enhancing the networks ability to model multi-scale features.
- (b)
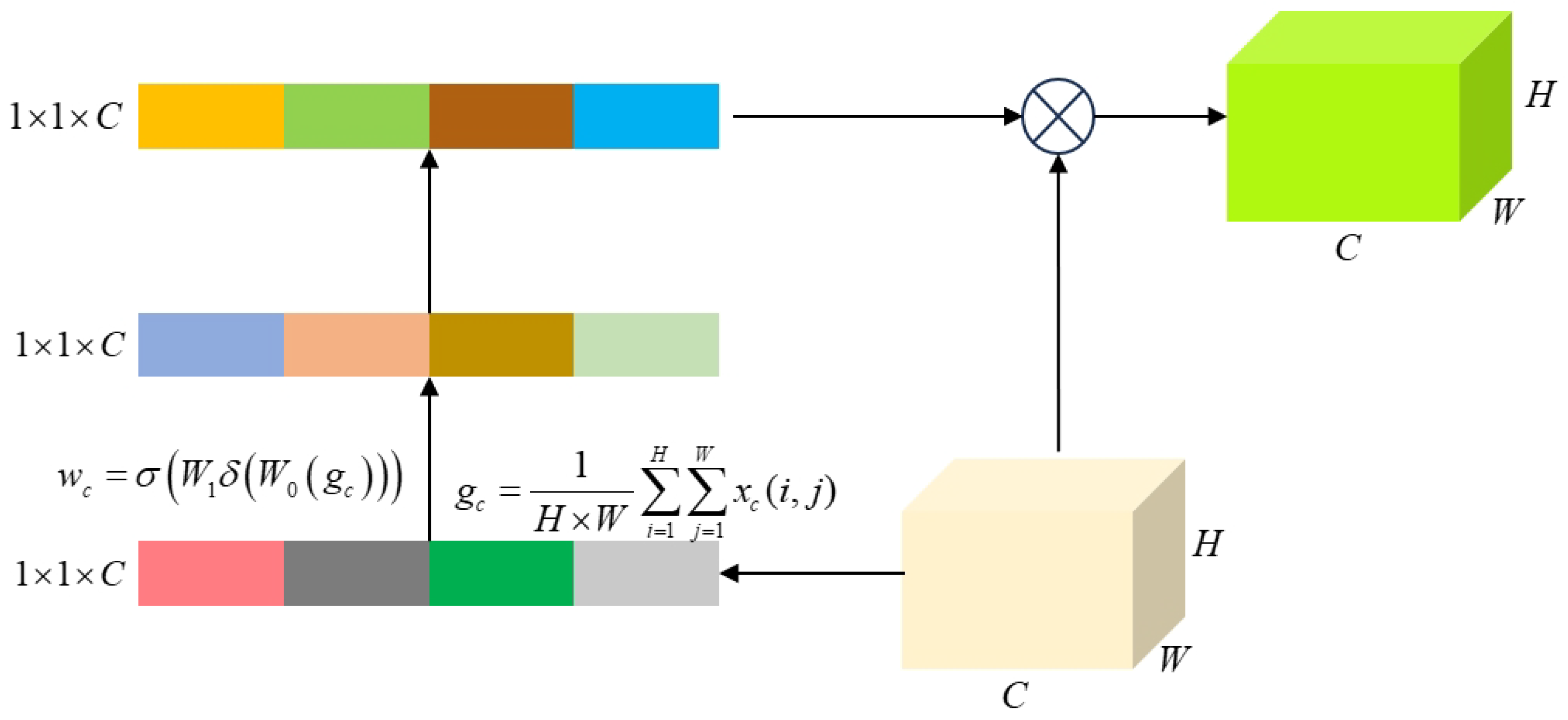
- As shown in Figure 9, the SE module consists of two main components: “squeeze” and “excitation”. First, global average pooling is applied to compress the channel dimension of the input feature map, generating a global feature vector with dimensions . Assuming the input of the c-th channel is x, the global average pooling is computed as . Subsequently, fully connected layers and activation functions are employed to capture inter-channel dependencies and compute attention weights. The attention weight for the c-th channel is defined as , where and denote the Sigmoid and ReLU activation functions, respectively, and and represent the weight matrices of the two fully connected layers. The fully connected layers perform linear transformations on the input data, while the activation functions introduce non-linearity, effectively modeling the semantic dependencies across distant channels. Finally, the attention weights are normalized using a Softmax function and fused with the outputs of the multi-scale feature extraction module through weighted integration, thereby enhancing the representational capacity of the image features.
3.4.3. Swish Function
3.4.4. Joint Loss Function
3.4.5. Image Steganalysis Based on the Improved ResNet50 Algorithm
4. Experiments and Analysis of Results
4.1. Datasets and Data Processing
4.2. Experimental Environment and Parameter Setup
4.3. Feasibility Validation of the Core Analysis Area Selection Method
4.4. Feasibility Validation and Timeliness Analysis of PSNR-Based Image Similarity Assessment Methods
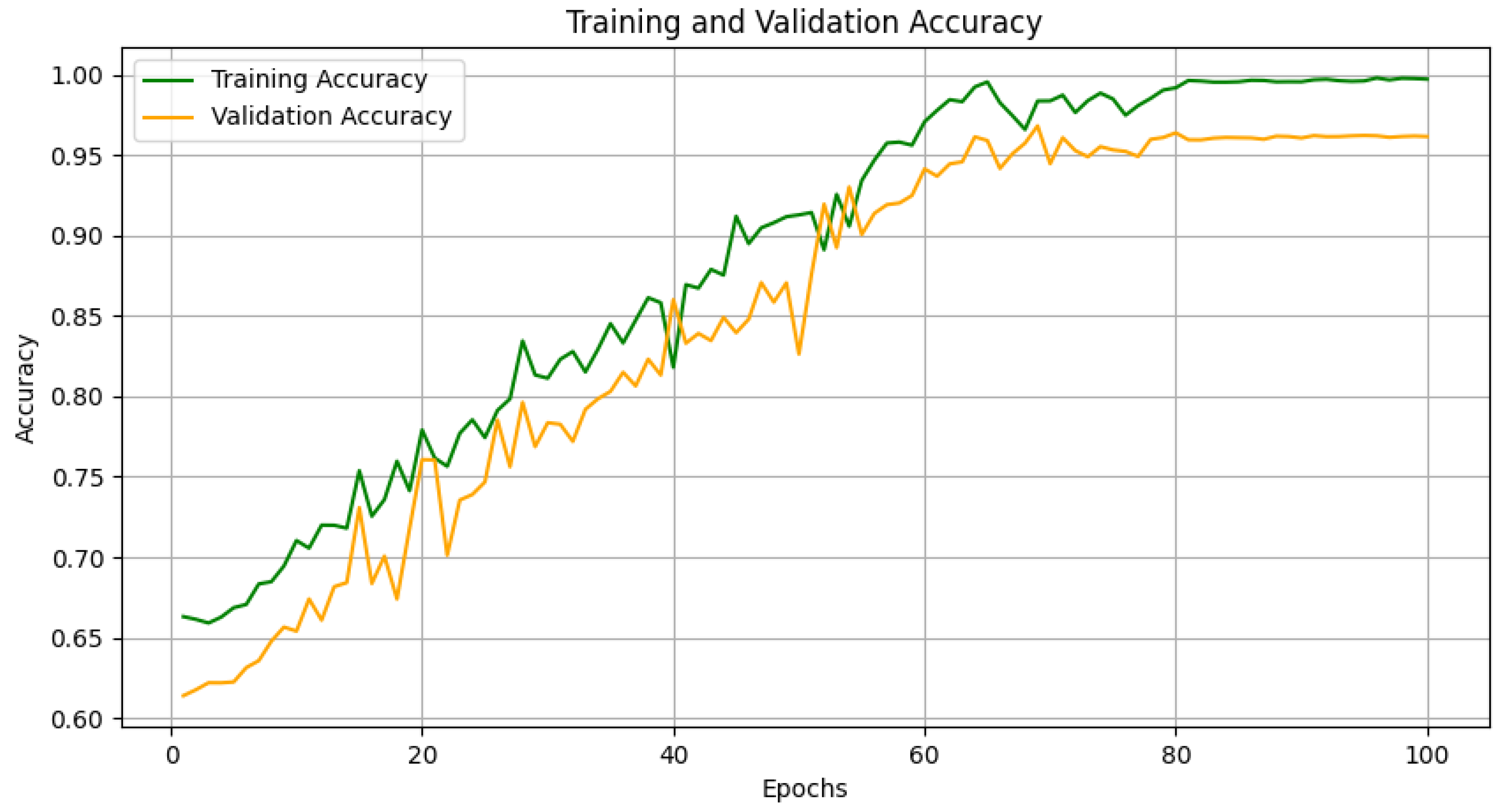
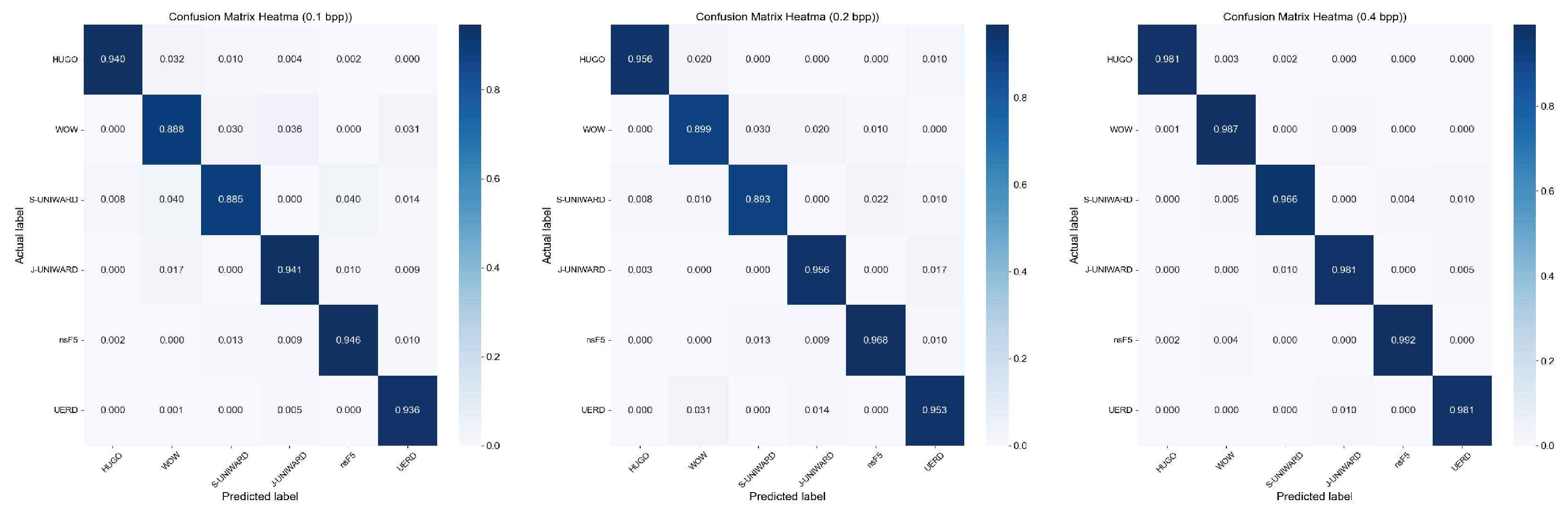
4.5. Performance Validation of Steganographic Algorithm Recognition Model Based on Improved ResNet50
4.5.1. Impact of ResNet50 Improvements on Image Steganalysis
4.5.2. Comparison with Existing Research on Common Image Steganalysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hu, K.; Wang, M.; Ma, X.; Chen, J.; Wang, X.; Wang, X. Learning-based image steganography and watermarking: A survey. Expert Syst. Appl. 2024, 249, 123715. [Google Scholar] [CrossRef]
- Wang, L.; Banerjee, S.; Cao, Y.; Mou, J.; Sun, B. A new self-embedding digital watermarking encryption scheme. Nonlinear Dyn. 2024, 112, 8637–8652. [Google Scholar] [CrossRef]
- Vyas, N.; Kakade, S.M.; Barak, B. On provable copyright protection for generative models. In Proceedings of the 40th International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 35277–35299. [Google Scholar]
- Zhao, P.; Wang, B.; Qin, Z.; Ding, Y.; Choo, K.K.R. A privacy protection scheme for green communication combining digital steganography. Peer-to-Peer Netw. Appl. 2024, 17, 2507–2522. [Google Scholar] [CrossRef]
- Xiang, X.; Tan, Y.; Qin, J.; Tan, Y. Advancements and challenges in coverless image steganography: A survey. Signal Process. 2024, 228, 109761. [Google Scholar] [CrossRef]
- Eid, W.M.; Alotaibi, S.S.; Alqahtani, H.M.; Saleh, S.Q. Digital image steganalysis: Current methodologies and future challenges. IEEE Access 2022, 10, 92321–92336. [Google Scholar] [CrossRef]
- Priscilla, C.V.; HemaMalini, V. Steganalysis Techniques: A Systematic Review. J. Surv. Fish. Sci. 2023, 10, 244–263. [Google Scholar] [CrossRef]
- Farooq, N.; Selwal, A. Image steganalysis using deep learning: A systematic review and open research challenges. J. Ambient Intell. Humaniz. Comput. 2023, 14, 7761–7793. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Pantic, I.; Cumic, J.; Dugalic, S.; Petroianu, G.A.; Corridon, P.R. Gray level co-occurrence matrix and wavelet analyses reveal discrete changes in proximal tubule cell nuclei after mild acute kidney injury. Sci. Rep. 2023, 13, 4025. [Google Scholar] [CrossRef]
- Zhou, J.; Jia, X.; Shen, L.; Wen, Z.; Ming, Z. Improved softmax loss for deep learning-based face and expression recognition. Cogn. Comput. Syst. 2019, 1, 97–102. [Google Scholar] [CrossRef]
- Deng, J.; Guo, J.; Xue, N.; Zafeiriou, S. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4690–4699. [Google Scholar]
- Liu, J.; Jiao, G.; Sun, X. Feature passing learning for image steganalysis. IEEE Signal Process. Lett. 2022, 29, 2233–2237. [Google Scholar] [CrossRef]
- Sakshi, S.; Verma, S.; Chaturvedi, P.; Yadav, S.A. Least Significant Bit Steganography for Text and Image hiding. In Proceedings of the 2022 3rd International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 27–29 April 2022; pp. 415–421. [Google Scholar]
- Laishram, D.; Tuithung, T. A secure adaptive Hidden Markov Model-based JPEG steganography method. Multimed. Tools Appl. 2024, 83, 38883–38908. [Google Scholar] [CrossRef]
- Salama, W.M.; Aly, M.H.; Abouelseoud, Y. Deep learning-based spam image filtering. Alex. Eng. J. 2023, 68, 461–468. [Google Scholar] [CrossRef]
- Willis, J.R.; Sivaganesan, M.; Haugland, R.A.; Kralj, J.; Servetas, S.; Hunter, M.E.; Jackson, S.A.; Shanks, O.C. Performance of NIST SRM® 2917 with 13 recreational water quality monitoring qPCR assays. Water Res. 2022, 212, 118114. [Google Scholar] [CrossRef] [PubMed]
- Holub, V.; Fridrich, J. Phase-aware projection model for steganalysis of JPEG images. In Proceedings of the Media Watermarking, Security, and Forensics 2015, San Francisco, CA, USA, 9–11 February 2015; Volume 9409, pp. 259–269. [Google Scholar]
- Wang, S.; Shi, J.; Ye, Z.; Dong, D.; Yu, D.; Zhou, M.; Liu, Y.; Gevaert, O.; Wang, K.; Zhu, Y.; et al. Predicting EGFR mutation status in lung adenocarcinoma on computed tomography image using deep learning. Eur. Respir. J. 2019, 53, 1800986. [Google Scholar] [CrossRef]
- Qian, Y.; Dong, J.; Wang, W.; Tan, T. Deep learning for steganalysis via convolutional neural networks. In Proceedings of the Media Watermarking, Security, and Forensics 2015, San Francisco, CA, USA, 9–11 February 2015; Volume 9409, pp. 171–180. [Google Scholar]
- Xu, G.; Wu, H.Z.; Shi, Y.Q. Structural design of convolutional neural networks for steganalysis. IEEE Signal Process. Lett. 2016, 23, 708–712. [Google Scholar] [CrossRef]
- Ye, J.; Ni, J.; Yi, Y. Deep learning hierarchical representations for image steganalysis. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2545–2557. [Google Scholar] [CrossRef]
- Boroumand, M.; Chen, M.; Fridrich, J. Deep residual network for steganalysis of digital images. IEEE Trans. Inf. Forensics Secur. 2018, 14, 1181–1193. [Google Scholar] [CrossRef]
- Zhang, R.; Zhu, F.; Liu, J.; Liu, G. Depth-wise separable convolutions and multi-level pooling for an efficient spatial CNN-based steganalysis. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1138–1150. [Google Scholar] [CrossRef]
- Yedroudj, M.; Comby, F.; Chaumont, M. Yedroudj-net: An efficient CNN for spatial steganalysis. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2092–2096. [Google Scholar]
- Wang, X.; Li, J.; Song, Y. DDAC: A feature extraction method for convolutional neural network image steganalysis model. J. Commun. 2022, 43, 68–81. [Google Scholar]
- Chao, X.; Yaqi, L.; Qingchu, G.; Xin, J.; Yanshuo, Z.; Shengwei, X. Nonlinear residual-based steganalysis of JPEG images. J. Commun. 2023, 44, 142–152. [Google Scholar]
- Li, Y.; Ling, B.; Hu, D.; Zheng, S.; Zhang, G. A Deep Learning Driven Feature Based Steganalysis Approach. Intell. Autom. Soft Comput. 2023, 37. [Google Scholar] [CrossRef]
- Ma, Y.; Yang, Z.; Li, T.; Xu, L.; Qiao, Y. Image steganalysis method based on cover selection and adaptive filtered residual network. Comput. Graph. 2023, 115, 43–54. [Google Scholar] [CrossRef]
- Setiadi, D.R.I.M. PSNR vs. SSIM: Imperceptibility quality assessment for image steganography. Multimed. Tools Appl. 2021, 80, 8423–8444. [Google Scholar] [CrossRef]
- Wang, J.; Liu, D.; Fu, X.; Xiao, F.; Tian, C. DHash: Dynamic Hash Tables with Non-blocking Regular Operations. IEEE Trans. Parallel Distrib. Syst. 2022, 33, 3274–3290. [Google Scholar] [CrossRef]
- Auchère, F.; Soubrié, E.; Pelouze, G.; Buchlin, É. Image enhancement with wavelet-optimized whitening. arXiv 2022, arXiv:2212.10134. [Google Scholar] [CrossRef]
- Li, J.; Wang, X.; Song, Y.; Wang, P. FPFnet: Image steganalysis model based on adaptive residual extraction and feature pyramid fusion. Multimed. Tools Appl. 2024, 83, 48539–48561. [Google Scholar] [CrossRef]
- Holub, V.; Fridrich, J. Digital image steganography using universal distortion. In Proceedings of the First ACM Workshop on Information Hiding and Multimedia Security, Montpellier, France, 17–19 June 2013; pp. 59–68. [Google Scholar]
- Beneš, M.; Hofer, N.; Böhme, R. The effect of the JPEG implementation on the cover-source mismatch error in image steganalysis. In Proceedings of the 2022 30th European Signal Processing Conference (EUSIPCO), Belgrade, Serbia, 29 August–2 September 2022; pp. 1057–1061. [Google Scholar]
- Bakurov, I.; Buzzelli, M.; Schettini, R.; Castelli, M.; Vanneschi, L. Structural similarity index (SSIM) revisited: A data-driven approach. Expert Syst. Appl. 2022, 189, 116087. [Google Scholar] [CrossRef]
- Wang, Z.; Feng, G.; Qian, Z.; Zhang, X. JPEG steganography with content similarity evaluation. IEEE Trans. Cybern. 2023, 53, 5082–5093. [Google Scholar] [CrossRef]
- Hoang, T.N.; Kim, D. Supervised contrastive ResNet and transfer learning for the in-vehicle intrusion detection system. Expert Syst. Appl. 2024, 238, 122181. [Google Scholar] [CrossRef]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Swish: A Self-Gated Activation Function. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Bas, P.; Filler, T.; Pevný, T. “Break Our Steganographic System”: The Ins and Outs of Organizing BOSS; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Xia, C.; Liu, Y.; Guan, Q.; Jin, X.; Zhang, Y.; Xu, S. Steganalysis of JPEG images using non-linear residuals. J. Commun./Tongxin Xuebao 2023, 44, 142. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Shore | Image Complexity | The Amount of Steganography Information | |||||
|---|---|---|---|---|---|---|---|
| HUGO [32] | WOW [33] | S-UNIWARD [34] | J-UNIWARD [35] | nsF5 [36] | UERD [37] | ||
| 1 | 3.11303 | 1572 | 1437 | 1232 | 169 | 202 | 273 |
| 2 | 2.95307 | 1380 | 1344 | 1066 | 162 | 155 | 223 |
| 3 | 1.91555 | 0 | 0 | 30 | 0 | 32 | 0 |
| 4 | 3.49875 | 2109 | 1914 | 1608 | 231 | 236 | 289 |
| 5 | 3.50382 | 2967 | 3077 | 2381 | 393 | 280 | 400 |
| 6 | 2.43412 | 862 | 1001 | 801 | 125 | 103 | 115 |
| 7 | 3.83679 | 3338 | 3033 | 2526 | 347 | 351 | 515 |
| 8 | 4.23709 | 5246 | 5390 | 4228 | 779 | 422 | 726 |
| 9 | 3.59842 | 4788 | 4960 | 4126 | 693 | 377 | 411 |
| Steganographic Algorithm | PSNR [30] | SSIM [36] | ||||
|---|---|---|---|---|---|---|
| 0.1 bpp | 0.2 bpp | 0.4 bpp | 0.1 bpp | 0.2 bpp | 0.4 bpp | |
| HUGO [32] | 65.2276 | 61.8881 | 58.4410 | 99.9960 | 99.9881 | 99.9629 |
| WOW [33] | 65.2143 | 61.8176 | 58.4007 | 99.9945 | 99.9847 | 99.9564 |
| S-UNIWARD [34] | 65.2143 | 62.7923 | 59.2832 | 99.9945 | 99.9849 | 99.9576 |
| J-UNIWARD [35] | 56.2645 | 52.5968 | 48.6147 | 99.9698 | 99.9187 | 99.7662 |
| nsF5 [36] | 52.9668 | 49.1891 | 45.1523 | 99.8557 | 99.6574 | 99.1545 |
| UERD [37] | 55.2476 | 51.6024 | 47.2312 | 99.8724 | 99.8934 | 99.6850 |
| Module | Exp1 | Exp2 | Exp3 | Exp4 | Exp5 | Exp6 |
|---|---|---|---|---|---|---|
| PSA | × | ✓ | × | × | ✓ | ✓ |
| Swish function | × | × | ✓ | × | ✓ | ✓ |
| Joint loss function | × | × | × | ✓ | ✓ | ✓ |
| Ranger | × | × | × | × | × | |
| Accuracy(%) | 92.79 | 94.98 | 93.41 | 93.76 | 95.69 | 96.11 |
| Method | Embedding Rate | Model Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Ours | ZhuNet [24] | YeNet [22] | SRNet [23] | CSRNet [29] | ||
| HUGO [32] | 0.1 | 93.97 | 56.71 | 65.33 | 56.51 | 83.63 |
| 0.2 | 95.62 | 59.83 | 68.77 | 59.32 | 85.49 | |
| 0.4 | 98.13 | 68.32 | 81.16 | 69.06 | 95.30 | |
| WOW [33] | 0.1 | 88.79 | 58.83 | 59.99 | 59.32 | 81.79 |
| 0.2 | 89.91 | 76.71 | 67.49 | 63.50 | 83.37 | |
| 0.4 | 98.73 | 86.16 | 79.18 | 84.58 | 93.37 | |
| S-UNIWARD [34] | 0.1 | 88.53 | 77.65 | 65.46 | 72.68 | 78.82 |
| 0.2 | 89.25 | 79.46 | 68.78 | 75.26 | 83.99 | |
| 0.4 | 96.64 | 87.43 | 81.17 | 86.23 | 95.79 | |
| Method | Embedding Rate | Model Accuracy (%) | ||||
|---|---|---|---|---|---|---|
| Ours | GFRspam [41] | DCTRspam [41] | SRNet [23] | CSRNet [29] | ||
| J-UNIWARD [35] | 0.1 | 94.11 | 55.32 | 51.57 | 53.51 | 59.71 |
| 0.2 | 95.57 | 58.18 | 56.58 | 56.85 | 62.27 | |
| 0.4 | 98.06 | 73.83 | 70.09 | 63.86 | 79.05 | |
| nsF5 [36] | 0.1 | 94.55 | 53.43 | 52.95 | 57.69 | 79.41 |
| 0.2 | 96.76 | 56.33 | 55.79 | 63.96 | 83.40 | |
| 0.4 | 99.24 | 73.57 | 71.26 | 82.79 | 98.37 | |
| UERD [37] | 0.1 | 93.59 | 53.77 | 54.37 | 71.76 | 71.28 |
| 0.2 | 95.32 | 57.55 | 56.93 | 75.28 | 75.82 | |
| 0.4 | 98.13 | 71.03 | 69.49 | 80.87 | 88.36 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, X.; Yi, J.; Liu, L.; Tan, L. A Generic Image Steganography Recognition Scheme with Big Data Matching and an Improved ResNet50 Deep Learning Network. Electronics 2025, 14, 1610. https://doi.org/10.3390/electronics14081610
Gao X, Yi J, Liu L, Tan L. A Generic Image Steganography Recognition Scheme with Big Data Matching and an Improved ResNet50 Deep Learning Network. Electronics. 2025; 14(8):1610. https://doi.org/10.3390/electronics14081610
Chicago/Turabian StyleGao, Xuefeng, Junkai Yi, Lin Liu, and Lingling Tan. 2025. "A Generic Image Steganography Recognition Scheme with Big Data Matching and an Improved ResNet50 Deep Learning Network" Electronics 14, no. 8: 1610. https://doi.org/10.3390/electronics14081610
APA StyleGao, X., Yi, J., Liu, L., & Tan, L. (2025). A Generic Image Steganography Recognition Scheme with Big Data Matching and an Improved ResNet50 Deep Learning Network. Electronics, 14(8), 1610. https://doi.org/10.3390/electronics14081610