
BMAIU: Backdoor Mitigation in Self-Supervised Learning Through Active Implantation and Unlearning


Abstract
1. Introduction
- (1)
- Based on our research on multi-target attacks, it is found that unlearning any one of the triggers can deactivate other triggers simultaneously. As revealed by conducting further experiments, unlearning a specific trigger generally reduces the overall backdoor capability of the encoder.
- (2)
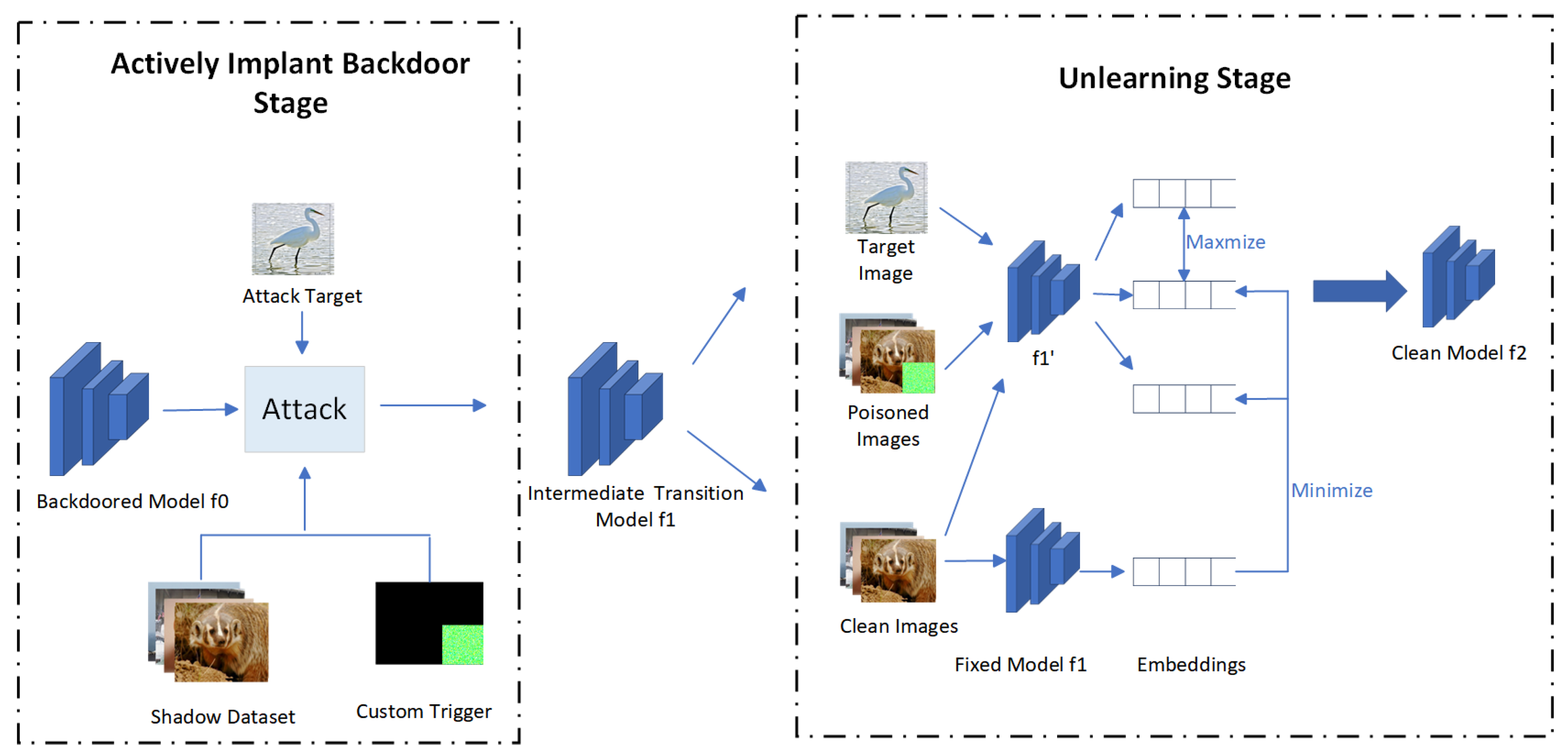
- A backdoor mitigation method based on active attack is proposed. Firstly, a backdoor is actively implanted using a custom trigger. Then, the trigger is unlearned. During this process, the unknown triggers used by the attacker are also rendered ineffective.
- (3)
- Experiments are conducted to validate the proposed method of defense based on the current state-of-the-art backdoor attack methods. The experimental results demonstrate that this method is effective in removing backdoors while maintaining the original level of model performance.
2. Background and Related Work
2.1. Self-Supervised Learning
2.2. Backdoor Attack on SSL
2.3. Limitations of Related Backdoor Defense
3. BMAIU: Backdoor Mitigation in Self-Supervised Learning Through Active Implantation and Unlearning
3.1. Threat Model and Defense Assumptions
3.2. Observations and Intuitions
3.3. Theoretical Insight into the Unlearning Effect
3.4. Proposed BMAIU Method
3.4.1. Active Implant Backdoor
| Algorithm 1 Stage 1: Active Attack for Backdoor Implantation |
|
3.4.2. Unlearning Triggers
| Algorithm 2 Stage 2: Trigger Unlearning for Backdoor Removal |
|
4. Experiments
4.1. Experimental Results
4.2. Ablation Studies
4.2.1. Defense Effectiveness with Different Ratios of Dataset
4.2.2. Defense Effectiveness on Different Architectures
4.2.3. Impact of Loss Terms
5. Conclusions
6. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krishnan, R.; Rajpurkar, P.; Topol, E.J. Self-supervised learning in medicine and healthcare. Nat. Biomed. Eng. 2022, 6, 1346–1352. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Albrecht, C.M.; Braham, N.A.A.; Mou, L.; Zhu, X.X. Self-supervised learning in remote sensing: A review. IEEE Geosci. Remote Sens. Mag. 2022, 10, 213–247. [Google Scholar] [CrossRef]
- Shurrab, S.; Duwairi, R. Self-supervised learning methods and applications in medical imaging analysis: A survey. PeerJ Comput. Sci. 2022, 8, e1045. [Google Scholar] [CrossRef] [PubMed]
- Goyal, P.; Mahajan, D.; Gupta, A.; Misra, I. Scaling and benchmarking self-supervised visual representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6391–6400. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M.; et al. Bootstrap your own latent-a new approach to self-supervised learning. Adv. Neural Inf. Process. Syst. 2020, 33, 21271–21284. [Google Scholar]
- Chen, X.; Fan, H.; Girshick, R.; He, K. Improved baselines with momentum contrastive learning. arXiv 2020, arXiv:2003.04297. [Google Scholar]
- Saha, A.; Tejankar, A.; Koohpayegani, S.A.; Pirsiavash, H. Backdoor attacks on self-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 13337–13346. [Google Scholar]
- Liu, H.; Jia, J.; Gong, N.Z. {PoisonedEncoder}: Poisoning the Unlabeled Pre-training Data in Contrastive Learning. In Proceedings of the 31st USENIX Security Symposium (USENIX Security 22), Boston, MA, USA, 10–12 August 2022; pp. 3629–3645. [Google Scholar]
- Li, C.; Pang, R.; Xi, Z.; Du, T.; Ji, S.; Yao, Y.; Wang, T. An embarrassingly simple backdoor attack on self-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4367–4378. [Google Scholar]
- Xue, J.; Lou, Q. Estas: Effective and stable trojan attacks in self-supervised encoders with one target unlabelled sample. arXiv 2022, arXiv:2211.10908. [Google Scholar]
- Li, Y.; Lyu, X.; Koren, N.; Lyu, L.; Li, B.; Ma, X. Anti-backdoor learning: Training clean models on poisoned data. Adv. Neural Inf. Process. Syst. 2021, 34, 14900–14912. [Google Scholar]
- Huang, K.; Li, Y.; Wu, B.; Qin, Z.; Ren, K. Backdoor defense via decoupling the training process. arXiv 2022, arXiv:2202.03423. [Google Scholar]
- Chen, W.; Wu, B.; Wang, H. Effective backdoor defense by exploiting sensitivity of poisoned samples. Adv. Neural Inf. Process. Syst. 2022, 35, 9727–9737. [Google Scholar]
- Wang, B.; Yao, Y.; Shan, S.; Li, H.; Viswanath, B.; Zheng, H.; Zhao, B.Y. Neural cleanse: Identifying and mitigating backdoor attacks in neural networks. In Proceedings of the 2019 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 19–23 May 2019; pp. 707–723. [Google Scholar]
- Zheng, R.; Tang, R.; Li, J.; Liu, L. Data-free backdoor removal based on channel lipschitzness. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 175–191. [Google Scholar]
- Zeng, Y.; Chen, S.; Park, W.; Mao, Z.M.; Jin, M.; Jia, R. Adversarial unlearning of backdoors via implicit hypergradient. arXiv 2021, arXiv:2110.03735. [Google Scholar]
- Jia, J.; Liu, Y.; Gong, N.Z. Badencoder: Backdoor attacks to pre-trained encoders in self-supervised learning. In Proceedings of the 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 26 May 2022; pp. 2043–2059. [Google Scholar]
- Tejankar, A.; Sanjabi, M.; Wang, Q.; Wang, S.; Firooz, H.; Pirsiavash, H.; Tan, L. Defending against patch-based backdoor attacks on self-supervised learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 12239–12249. [Google Scholar]
- Pan, M.; Zeng, Y.; Lyu, L.; Lin, X.; Jia, R. {ASSET}: Robust backdoor data detection across a multiplicity of deep learning paradigms. In Proceedings of the 32nd USENIX Security Symposium (USENIX Security 23), Anaheim, CA, USA, 9–11 August 2023; pp. 2725–2742. [Google Scholar]
- Zheng, M.; Xue, J.; Wang, Z.; Chen, X.; Lou, Q.; Jiang, L.; Wang, X. Ssl-cleanse: Trojan detection and mitigation in self-supervised learning. arXiv 2023, arXiv:2303.09079. [Google Scholar]
- Feng, S.; Tao, G.; Cheng, S.; Shen, G.; Xu, X.; Liu, Y.; Zhang, K.; Ma, S.; Zhang, X. Detecting backdoors in pre-trained encoders. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16352–16362. [Google Scholar]
- Cinà, A.E.; Grosse, K.; Demontis, A.; Vascon, S.; Zellinger, W.; Moser, B.A.; Oprea, A.; Biggio, B.; Pelillo, M.; Roli, F. Wild patterns reloaded: A survey of machine learning security against training data poisoning. ACM Comput. Surv. 2023, 55, 1–39. [Google Scholar] [CrossRef]
- Qiao, X.; Yang, Y.; Li, H. Defending neural backdoors via generative distribution modeling. Adv. Neural Inf. Process. Syst. 2019, 32, 1–10. [Google Scholar]
- Ho-Phuoc, T. CIFAR10 to compare visual recognition performance between deep neural networks and humans. arXiv 2018, arXiv:1811.07270. [Google Scholar]
- Saha, A.; Subramanya, A.; Pirsiavash, H. Hidden trigger backdoor attacks. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11957–11965. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Chen, Z.; Jiang, Y.; Zhang, X.; Zheng, R.; Qiu, R.; Sun, Y.; Zhao, C.; Shang, H. ResNet18DNN: Prediction approach of drug-induced liver injury by deep neural network with ResNet18. Briefings Bioinform. 2022, 23, bbab503. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Le, Q. Efficientnetv2: Smaller models and faster training. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 10096–10106. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Iglovikov, V.; Shvets, A. Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Theckedath, D.; Sedamkar, R. Detecting affect states using VGG16, ResNet50 and SE-ResNet50 networks. SN Comput. Sci. 2020, 1, 79. [Google Scholar] [CrossRef]
- Koonce, B.; Koonce, B. ResNet 34. Convolutional Neural Networks with Swift for Tensorflow: Image Recognition and Dataset Categorization; Apress: New York, NY, USA, 2021; pp. 51–61. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack Targets | None Defense | ST0 | ST1 | ST2 | ST3 | ST4 | ST5 | ST6 | ST7 | ST8 | ST9 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Target 0 | 76.65 | 19.39 | 20.84 | 6.00 | 5.16 | 14.77 | 25.2 | 18.02 | 15.2 | 25.8 | 30.89 |
| Target 1 | 98.73 | 9.92 | 17.2 | 20.38 | 21.96 | 28.72 | 17.59 | 24.51 | 12.11 | 16.57 | 13.06 |
| Target 2 | 96.95 | 25.49 | 19.46 | 11.18 | 22.13 | 30.61 | 0.00 | 8.72 | 12.95 | 0.00 | 0.00 |
| Target 3 | 89.83 | 4.32 | 14.47 | 11.58 | 19.69 | 0.25 | 8.63 | 6.89 | 0.00 | 4.18 | 8.64 |
| Target 4 | 75.97 | 17.21 | 5.06 | 30.31 | 11.68 | 1.19 | 14.72 | 3.27 | 2.18 | 12.35 | 6.69 |
| Target 5 | 98.29 | 12.95 | 0.91 | 12.10 | 0.00 | 21.46 | 14.59 | 9.19 | 17.46 | 26.85 | 8.95 |
| Target 6 | 87.88 | 13.28 | 23.01 | 19.85 | 27.54 | 25.77 | 21.02 | 29.88 | 38.43 | 15.8 | 25.82 |
| Target 7 | 91.22 | 5.24 | 16.62 | 0.00 | 8.85 | 8.76 | 11.92 | 16.14 | 12.76 | 10.09 | 13.95 |
| Target 8 | 84.35 | 10.85 | 9.61 | 13.15 | 17.18 | 12.19 | 4.71 | 11.11 | 16.92 | 11.86 | 8.09 |
| Target 9 | 96.49 | 25.93 | 20.86 | 23.62 | 27.49 | 17.75 | 28.95 | 21.72 | 16.91 | 30.83 | 14.97 |
| AVE | 89.63 | 14.45 | 14.80 | 14.81 | 16.16 | 16.14 | 14.73 | 14.94 | 14.49 | 15.43 | 13.10 |
| Attack Target | None Defense | AT0 | AT1 | AT2 | AT3 | AT4 | AT5 | AT6 | AT7 | AT8 | AT9 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Target 0 | 76.65 | 11.41 | 10.44 | 11.26 | 11.42 | 14.01 | 11.43 | 10.4 | 11.14 | 10.26 | 11.98 |
| Target 1 | 98.73 | 9.41 | 9.72 | 10.01 | 9.09 | 9.55 | 10.10 | 9.59 | 9.85 | 9.92 | 9.97 |
| Target 2 | 96.95 | 8.06 | 10.16 | 7.96 | 8.35 | 5.95 | 9.53 | 12.56 | 8.06 | 8.58 | 12.65 |
| Target 3 | 89.83 | 7.76 | 10.29 | 7.33 | 5.10 | 7.44 | 7.15 | 6.98 | 12.24 | 7.6 | 5.02 |
| Target 4 | 75.97 | 12.44 | 8.67 | 12.21 | 9.13 | 13.92 | 9.78 | 9.58 | 10.95 | 10.59 | 8.35 |
| Target 5 | 98.29 | 8.48 | 7.46 | 10.64 | 12.31 | 8.15 | 8.31 | 8.95 | 5.54 | 11.8 | 9.28 |
| Target 6 | 87.88 | 11.34 | 12.74 | 11.82 | 14.67 | 12.25 | 13.78 | 13.08 | 12.20 | 11.95 | 12.38 |
| Target 7 | 91.22 | 9.67 | 10.43 | 9.01 | 9.14 | 9.92 | 9.78 | 8.98 | 9.68 | 8.6 | 10.43 |
| Target 8 | 84.35 | 10.80 | 9.71 | 9.78 | 9.70 | 9.23 | 10.48 | 9.75 | 10.65 | 10.7 | 9.69 |
| Target 9 | 96.49 | 10.62 | 10.13 | 10.00 | 11.17 | 10.48 | 10.16 | 10.21 | 10.00 | 9.67 | 9.62 |
| AVE | 89.63 | 9.99 | 9.97 | 10.00 | 10.01 | 10.09 | 10.05 | 10.01 | 10.03 | 9.96 | 9.93 |
| SSL Methods | Attack Methods | None Defense | CLP | I-BAU | SSL_Cleanse | BMAIU | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BA | ASR | PA | BA | ASR | PA | BA | ASR | PA | BA | ASR | PA | BA | ASR | PA | ||
| SimCLR | SSL_Backdoor | 77.19 | 16.00 | 66.56 | 66.22 | 9.13 | 52.77 | 72.83 | 2.16 | 67.47 | 71.62 | 2.58 | 68.63 | 78.05 | 1.17 | 75.44 |
| CTRL | 74.94 | 89.40 | 9.31 | 65.05 | 15.94 | 52.08 | 65.94 | 0.33 | 58.03 | 66.92 | 44.6 | 35.31 | 72.15 | 11.63 | 60.76 | |
| BadEncoder | 77.67 | 59.98 | 32.66 | 63.48 | 27.98 | 36.56 | 69.37 | 1.17 | 62.84 | 70.54 | 21.69 | 54.77 | 76.26 | 13.68 | 66.47 | |
| ESTAS | 79.66 | 97.46 | 1.66 | 65.73 | 12.56 | 55.3 | 73.15 | 2.01 | 68.15 | 74.6 | 33.17 | 24.8 | 77.1 | 8.4 | 67.37 | |
| BYOL | SSL_Backdoor | 72.42 | 18.03 | 61.59 | 58.11 | 8.23 | 44.4 | 45.90 | 1.01 | 44.81 | 59.41 | 11.92 | 54.27 | 70.26 | 1.42 | 68.19 |
| CTRL | 73.12 | 89.79 | 3.48 | 66.26 | 1.33 | 63.32 | 51.30 | 0.44 | 48.36 | 54.387 | 43.5 | 33.12 | 71.21 | 14.3 | 59.59 | |
| BadEncoder | 72.95 | 87.83 | 9.92 | 61.87 | 68.42 | 18.42 | 52.29 | 0.47 | 47.11 | 54.33 | 62.94 | 16.51 | 66.85 | 10.24 | 56.89 | |
| ESTAS | 71.70 | 92.49 | 5.76 | 67.29 | 6.39 | 56.72 | 54.34 | 1.07 | 52.53 | 54.8 | 29.68 | 35.33 | 69.08 | 11.52 | 60.16 | |
| AVE | 74.36 | 68.87 | 23.86 | 64.25 | 18.74 | 47.44 | 60.64 | 1.08 | 56.17 | 63.33 | 31.26 | 40.34 | 72.62 | 9.05 | 64.36 | |
| Attack Methods | None Defense | CLP | I-BAU | SSL_Cleanse | BMAIU | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| BA | ASR | PA | BA | ASR | PA | BA | ASR | PA | BA | ASR | PA | BA | ASR | PA | |
| SSL_Backdoor | 59.39 | 38.22 | 35.18 | 54.82 | 32.83 | 33.88 | 52.45 | 2.42 | 45.11 | 51.00 | 26.66 | 34.94 | 58.16 | 0.19 | 51.86 |
| CTRL | 58.22 | 38.98 | 36.80 | 53.23 | 19.46 | 42.41 | 51.98 | 0.72 | 45.99 | 50.83 | 17.93 | 45.82 | 57.32 | 3.33 | 53.89 |
| BadEncoder | 60.03 | 61.11 | 17.73 | 48.99 | 35.19 | 18.98 | 51.06 | 1.55 | 47.30 | 51.16 | 14.02 | 38.24 | 58.24 | 1.23 | 52.65 |
| AVE | 59.21 | 46.10 | 29.90 | 52.34 | 29.16 | 31.75 | 51.83 | 1.56 | 46.13 | 60.72 | 14.87 | 39.67 | 57.91 | 1.58 | 52.80 |
| Attack Target | None Defense | CLP | I-BAU | SSL_Cleanse | BMAIU | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| ASR | PA | ASR | PA | ASR | PA | ASR | PA | ASR | PA | |
| Target 0 | 76.65 | 26.87 | 62.61 | 37.10 | 2.81 | 61.37 | 18.29 | 55.84 | 14.71 | 77.48 |
| Target 1 | 98.73 | 10.73 | 93.06 | 15.01 | 11.34 | 60.26 | 14.91 | 53.72 | 12.21 | 75.27 |
| Target 2 | 96.95 | 11.92 | 92.08 | 14.24 | 17.96 | 61.11 | 19.91 | 55.12 | 13.16 | 75.21 |
| Target 3 | 89.83 | 14.20 | 34.01 | 23.97 | 0.42 | 60.85 | 10.79 | 57.27 | 7.24 | 77.85 |
| Target 4 | 75.97 | 23.35 | 74.95 | 28.33 | 14.23 | 60.48 | 7.92 | 55.38 | 9.33 | 77.71 |
| Target 5 | 98.29 | 11.15 | 93.01 | 15.17 | 18.94 | 61.41 | 7.26 | 57.00 | 13.05 | 78.62 |
| Target 6 | 87.88 | 19.5 | 73.82 | 28.97 | 3.82 | 61.23 | 17.49 | 55.79 | 12.76 | 77.90 |
| Target 7 | 91.22 | 14.24 | 79.14 | 20.23 | 9.92 | 61.99 | 9.55 | 56.93 | 10.29 | 78.13 |
| Target 8 | 84.35 | 21.18 | 70.59 | 32.18 | 14.87 | 61.50 | 11.45 | 57.34 | 9.67 | 78.77 |
| Target 9 | 96.49 | 12.39 | 93.86 | 14.09 | 9.68 | 61.64 | 16.51 | 56.03 | 11.76 | 77.52 |
| AVE | 89.63 | 16.55 | 76.71 | 22.92 | 10.39 | 61.15 | 13.40 | 56.04 | 11.42 | 77.44 |
| BA | 82.71 | 79.09 | 64.97 | 59.86 | 82.27 | |||||
| Data Ratio | CIFAR10 | ImageNet | ||||
|---|---|---|---|---|---|---|
| BA | ASR | PA | BA | ASR | PA | |
| 1% | 74.51 | 12.52 | 63.55 | 55.80 | 1.58 | 51.09 |
| 5% | 74.93 | 12.20 | 64.90 | 57.07 | 2.28 | 52.10 |
| 10% | 76.26 | 13.68 | 66.47 | 58.24 | 1.23 | 52.65 |
| Backbones | Metrics | Before Migitation | After Migitation |
|---|---|---|---|
| VGG11 | BA | 70.77 | 69.11 |
| ASR | 51.22 | 9.49 | |
| PA | 36.02 | 60.51 | |
| VGG16 | BA | 67.99 | 67.55 |
| ASR | 77.17 | 11.39 | |
| PA | 18.29 | 60.23 | |
| ResNet18 | BA | 79.66 | 77.1 |
| ASR | 97.46 | 8.4 | |
| PA | 1.66 | 67.37 | |
| ResNet34 | BA | 77.79 | 74.44 |
| ASR | 84.74 | 6.38 | |
| PA | 11.15 | 70.14 | |
| SENet18 | BA | 79.82 | 75.73 |
| ASR | 73.73 | 4.88 | |
| PA | 23.4 | 72.69 | |
| SENet34 | BA | 80.17 | 77.40 |
| ASR | 74.84 | 5.19 | |
| PA | 22.02 | 73.72 |
| Removed Loss Terms | BA | ASR | PA |
|---|---|---|---|
| 72.22 | 10.52 | 52.76 | |
| 74.26 | 19.57 | 44.77 | |
| 76.99 | 22.94 | 43.71 | |
| None | 77.1 | 8.4 | 67.37 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, F.; Li, J.; Huang, W.; Chen, X. BMAIU: Backdoor Mitigation in Self-Supervised Learning Through Active Implantation and Unlearning. Electronics 2025, 14, 1587. https://doi.org/10.3390/electronics14081587
Zhang F, Li J, Huang W, Chen X. BMAIU: Backdoor Mitigation in Self-Supervised Learning Through Active Implantation and Unlearning. Electronics. 2025; 14(8):1587. https://doi.org/10.3390/electronics14081587
Chicago/Turabian StyleZhang, Fan, Jianpeng Li, Wei Huang, and Xi Chen. 2025. "BMAIU: Backdoor Mitigation in Self-Supervised Learning Through Active Implantation and Unlearning" Electronics 14, no. 8: 1587. https://doi.org/10.3390/electronics14081587
APA StyleZhang, F., Li, J., Huang, W., & Chen, X. (2025). BMAIU: Backdoor Mitigation in Self-Supervised Learning Through Active Implantation and Unlearning. Electronics, 14(8), 1587. https://doi.org/10.3390/electronics14081587