
Roadside Perception Applications Based on DCAM Fusion and Lightweight Millimeter-Wave Radar–Vision Integration


Abstract
1. Introduction
2. Related Work
2.1. Visual Target Detection Methods
2.2. Millimeter-Wave Radar Detection Methods
2.3. Multi-Sensor Fusion Approaches
2.4. Key Contributions of the Proposed Method
3. Methods
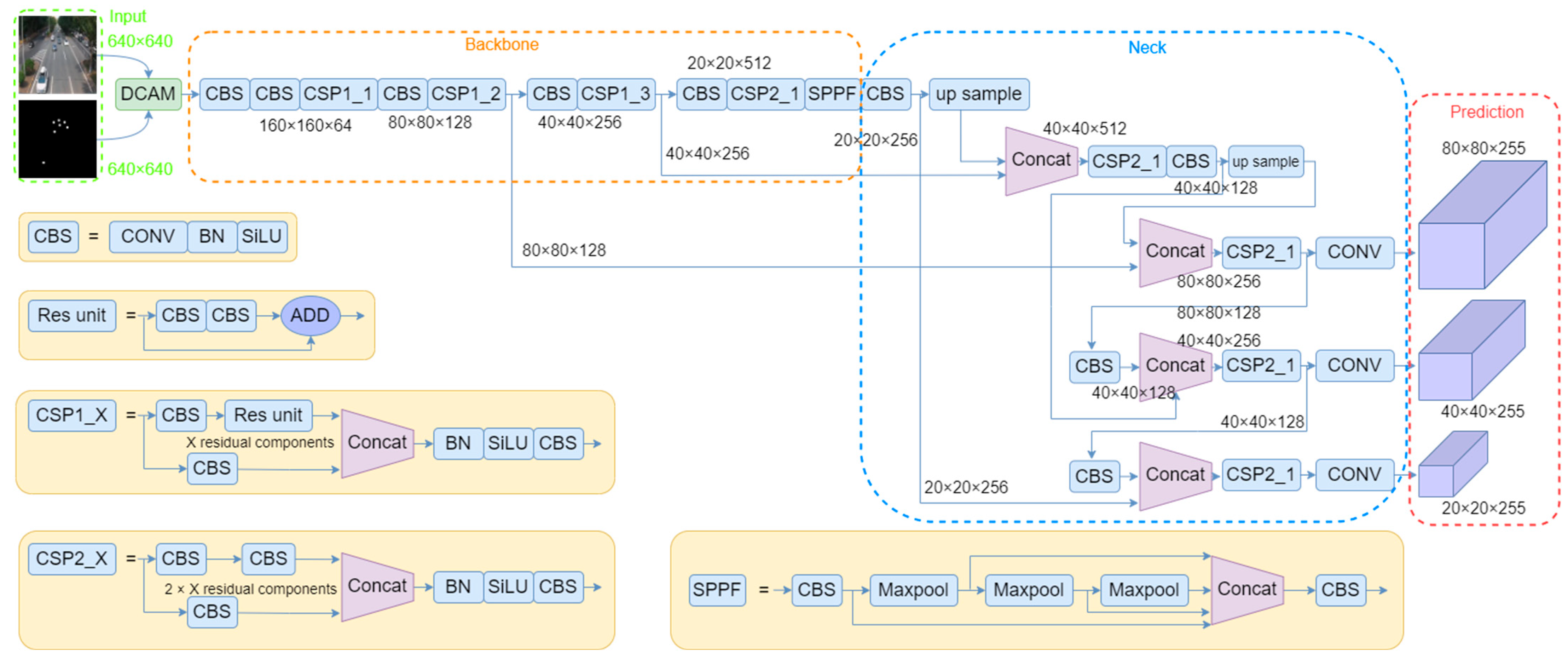
3.1. Roadside Sensing Architecture
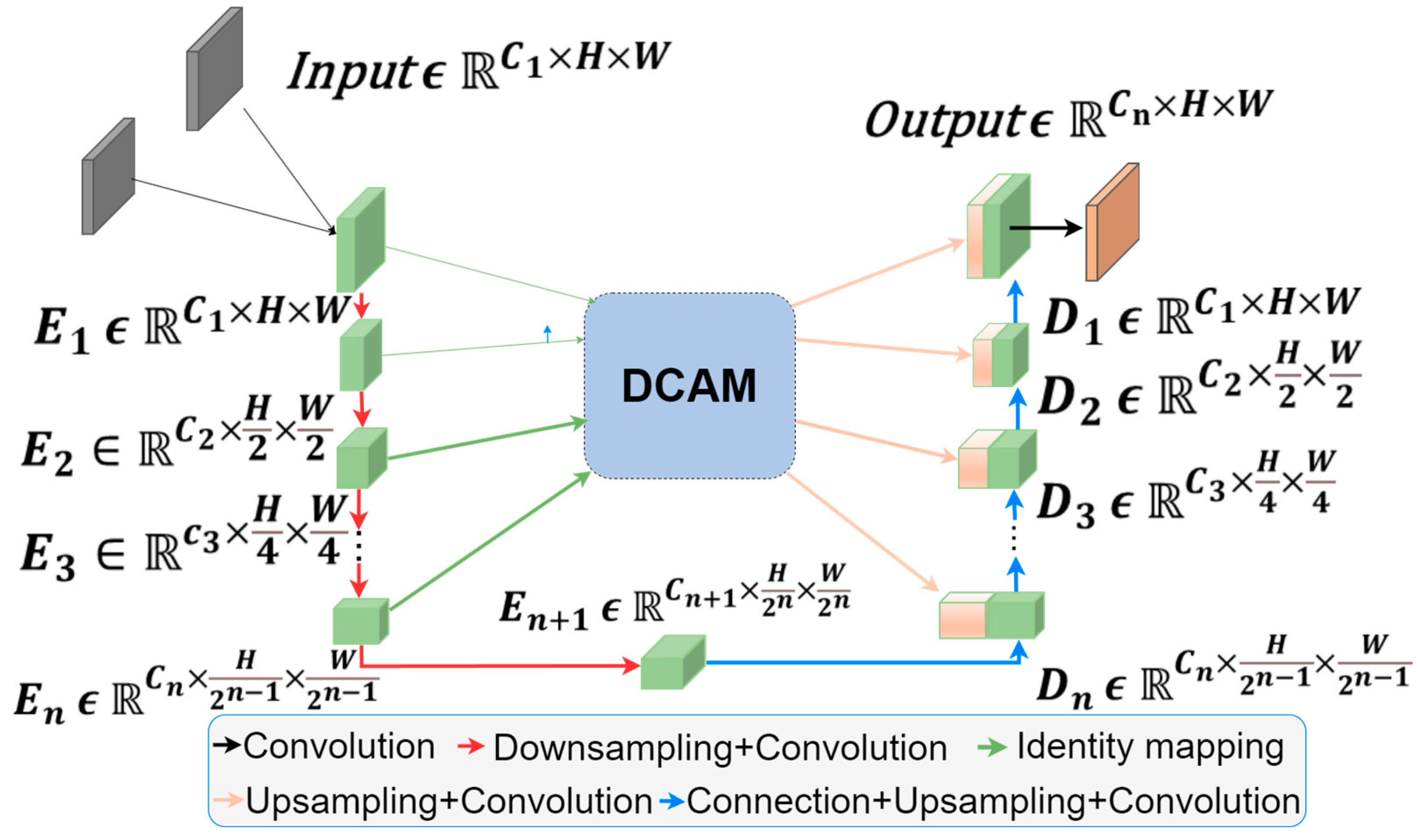
3.2. Improved Double-Cross-Attention Mechanism
- (1)
- YOLOv5 has been extensively validated and widely adopted in industrial applications since its initial release in 2020. Compared to its subsequent versions, it has undergone extensive community testing and bug fixes, resulting in higher stability and reliability, which is particularly crucial for roadside perception systems deployed in real-world traffic environments.
- (2)
- From an engineering perspective, YOLOv5 offers superior compatibility with inference acceleration frameworks such as ONNX and TensorRT, facilitating efficient deployment on embedded platforms.
4. Implementation of Dual Sensor Fusion
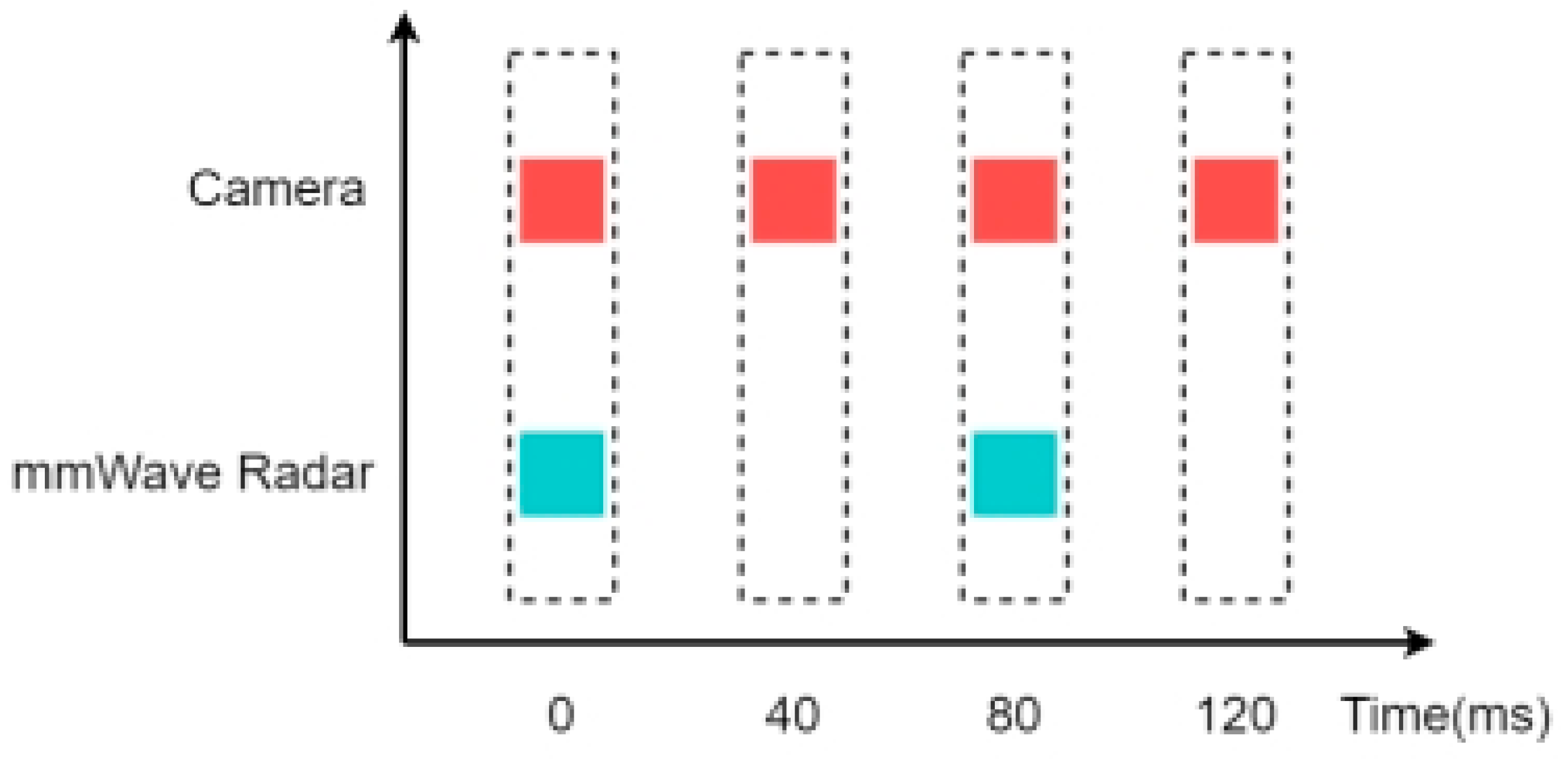
4.1. Temporal Alignment
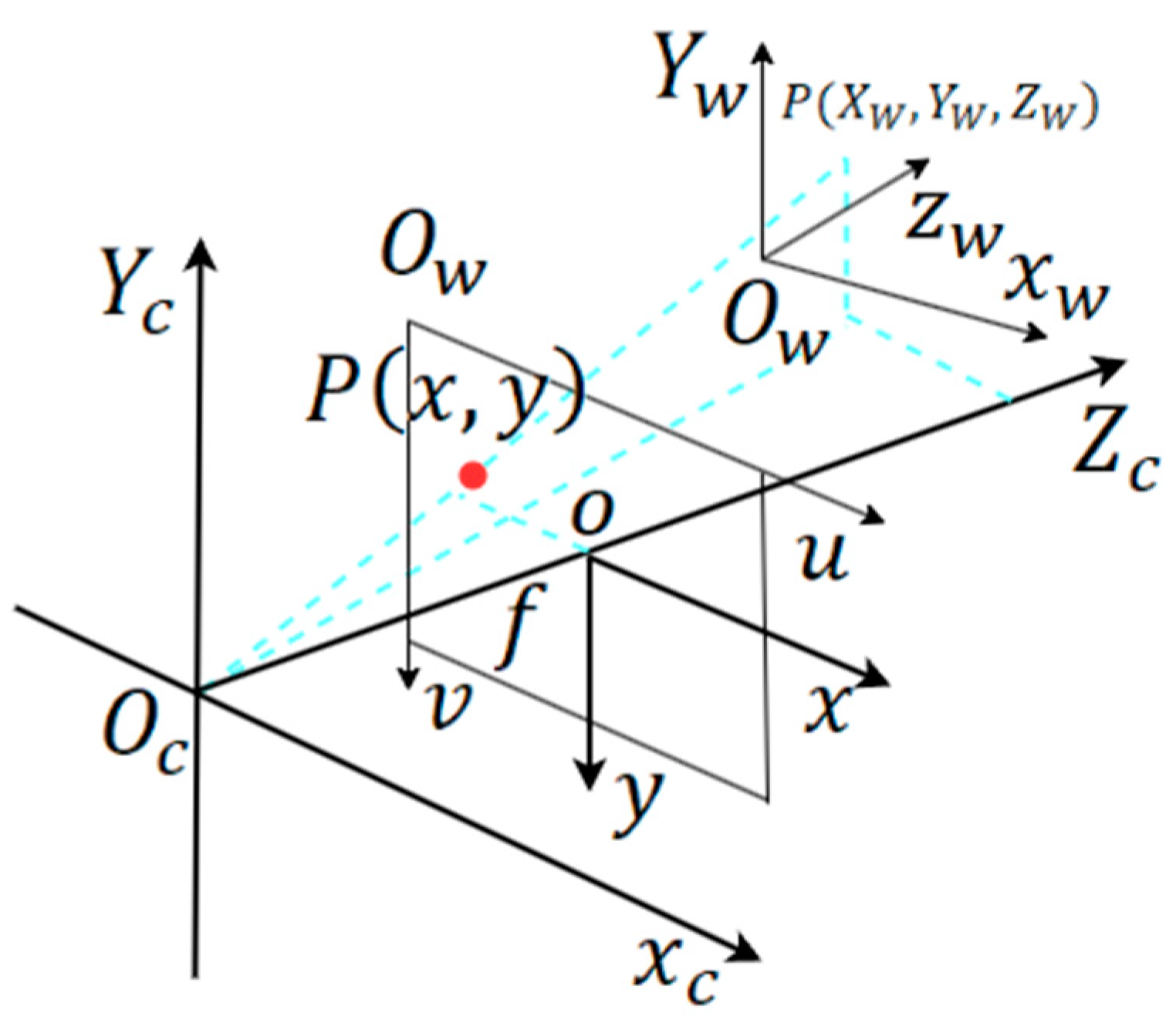
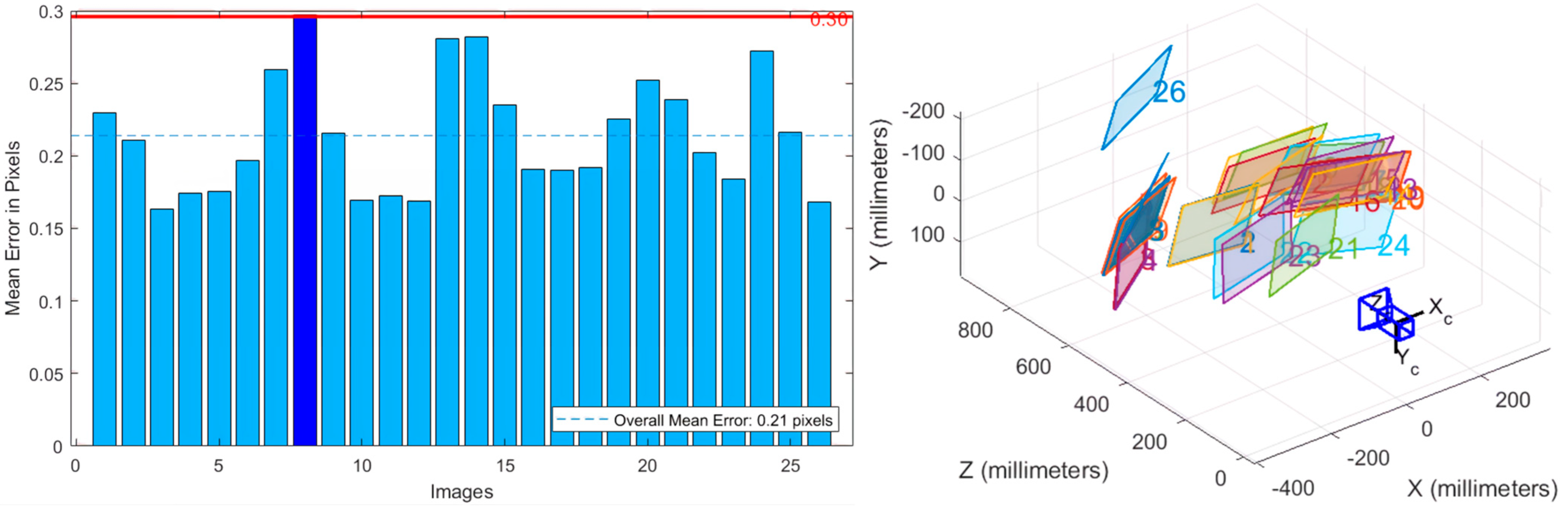
4.2. Spatio Calibration
4.3. Millimeter-Wave Radar Data Processing
4.4. Experimental Result Verification
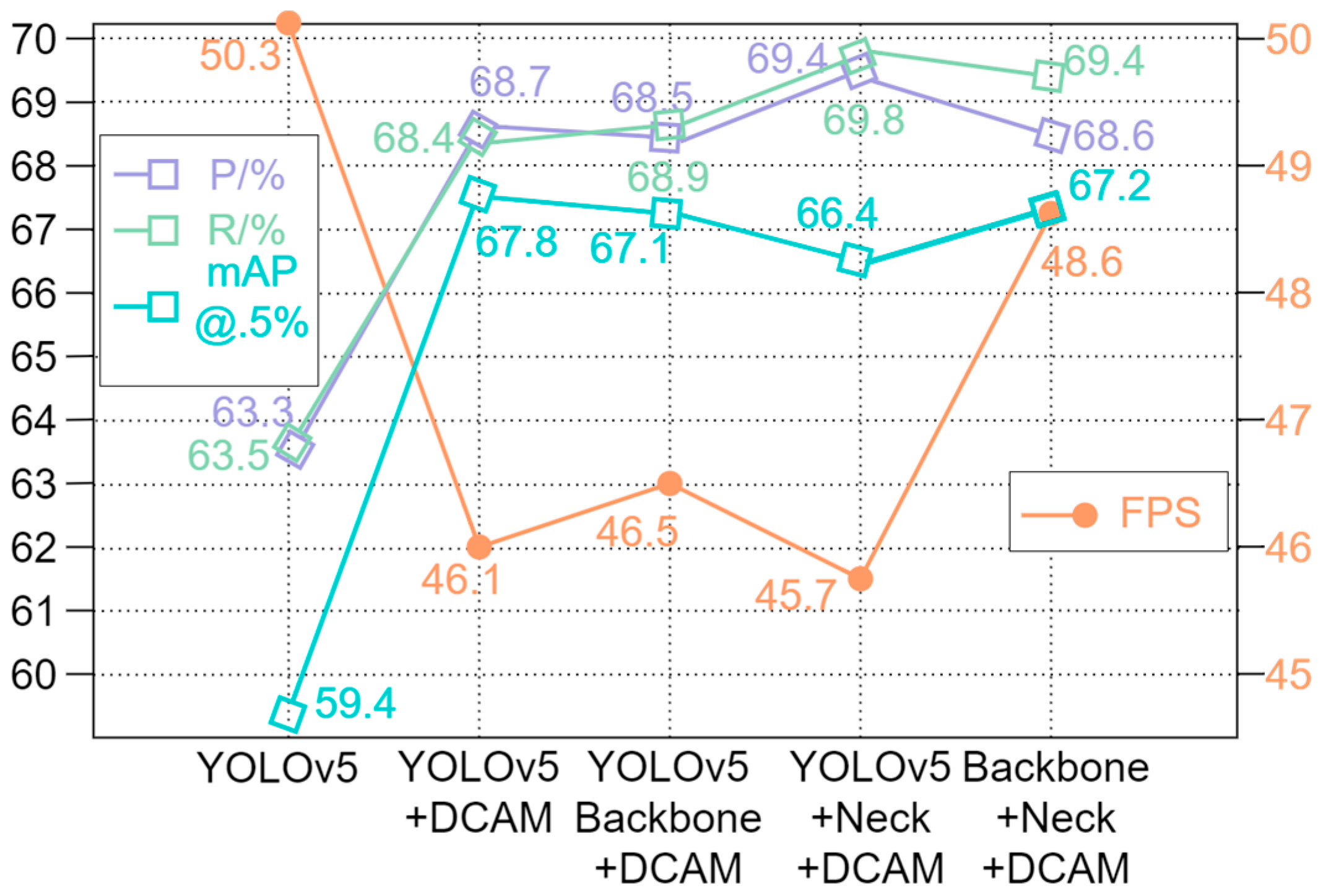
4.4.1. Ablation Experiment
4.4.2. Confusion Matrix
4.4.3. Comparative Analysis of P-R Curves
4.4.4. F1-Score Comparative Analysis
4.4.5. Robustness of Multimodal Fusion
- Small deviations (where the point cloud offset remains within the same lane as the vehicle) are corrected using the data association and error-handling algorithm detailed in Section 4.3, effectively eliminating such common errors.
- Large deviations (where the point cloud differs from the actual vehicle position by one or more lane widths), as illustrated in Figure 18, are handled through the inherent robustness of the fusion framework.
5. Lightweight and Embedded Deployment
5.1. Lightweight YOLOv5 Fusion Algorithm
5.2. Embedded Deployment and Acceleration
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chun, B.T.; Lee, S.H. A Study on Intelligent Traffic System Related with Smart City. Int. J. Smart Home 2015, 9, 223–230. [Google Scholar] [CrossRef]
- Zhang, C. Application of Artificial Intelligence in Urban Intelligent Traffic Management System. In Proceedings of the 3rd International Conference on Computer Information and Big Data Applications (CIBDA), Wuhan, China, 15–17 April 2022; pp. 1–5. [Google Scholar]
- Wang, J.; Fu, T.; Xue, J.; Li, C.; Song, H.; Xu, W.; Shangguan, Q. Realtime Wide-Area Vehicle Trajectory Tracking Using Millimeter-Wave Radar Sensors and the Open TJRD TS Dataset. Int. J. Transp. Sci. Technol. 2023, 12, 273–290. [Google Scholar] [CrossRef]
- Zhou, T.; Zhang, X.; Kang, B.; Chen, M. Multimodal Fusion Recognition for Digital Twin. Digit. Commun. Netw. 2024, 10, 337–346. [Google Scholar] [CrossRef]
- Su, H.; Gao, H.; Wang, X; Fang, X; Liu, Q; Huang, G.-B. Object Detection in Adverse Weather for Autonomous Vehicles Based on Sensor Fusion and Incremental Learning. In IEEE Transactions on Instrumentation and Measurement. In IEEE Transactions on Instrumentation and Measurement; IEEE: New York, NY, USA, 2024; Volume 73, pp. 1–10. [Google Scholar] [CrossRef]
- Ates, G.C.; Mohan, P.; Celik, E. Dual Cross-Attention for Medical Image Segmentation. Eng. Appl. Artif. Intell. 2023, 126, 107139. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 8–16 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, X.; Zhang, Y.; Zhang, Y. Research on Vehicle Object Detection Technology Based on YOLOv5s Fused with SENet. J. Graph. 2022, 43, 776–782. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Ghosh, R. On-Road Vehicle Detection in Varying Weather Conditions Using Faster R-CNN with Several Region Proposal Networks. Multimed. Tools Appl. 2021, 80, 25985–25999. [Google Scholar] [CrossRef]
- Ma, Y.; Chai, L.; Jin, L.; Yu, Y.; Yan, J. AVS-YOLO: Object Detection in Aerial Visual Scene. Int. J. Pattern Recognit. Artif. Intell. 2022, 36, 2250004. [Google Scholar] [CrossRef]
- Heijne, R. Comparing Detection Algorithms for Short Range Radar: Based on the Use-Case of the Cobotic-65. Master’s Thesis, Delft University of Technology, Delft, The Netherlands, 2022. [Google Scholar]
- Deng, T.; Liu, X.; Wang, L. Occluded Vehicle Detection via Multi-Scale Hybrid Attention Mechanism in the Road Scene. Electronics 2022, 11, 2709. [Google Scholar] [CrossRef]
- Diskin, T.; Beer, Y.; Okun, U.; Wiesel, A. CFARnet: Deep Learning for Target Detection with Constant False Alarm Rate. Signal Process. 2024, 223, 109543. [Google Scholar] [CrossRef]
- Zhao, H.; Yang, J. An Optimized Poisson Multi-Bernoulli Multi-Target Tracking Algorithm. In Proceedings of the 2024 9th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 19–21 April 2024; pp. 46–50. [Google Scholar] [CrossRef]
- Cheng, L.; Cao, S. TransRAD: Retentive Vision Transformer for Enhanced Radar Object Detection. IEEE Trans. Radar Syst. 2025, 3, 303–317. [Google Scholar] [CrossRef]
- Ge, Q.; Bai, X.; Zeng, P. Gaussian-Cauchy Mixture Kernel Function Based Maximum Correntropy Criterion Kalman Filter for Linear Non-Gaussian Systems. IEEE Trans. Signal Process. 2025, 73, 158–172. [Google Scholar] [CrossRef]
- Zhang, Y.; Gao, L; Zhao, Y; Wu, S. Static Targets Recognition and Tracking Based on Millimeter Wave Radar. In Proceedings of the 3rd International Forum on Connected Automated Vehicle Highway System through the China Highway & Transportation, Jinan, China, 29 October 2020. [Google Scholar] [CrossRef]
- Fang, F.-F.; Qu, L.-B. Applying Bayesian Trigram Filter Model in Spam Identification and Its Disposal. In Proceedings of the 2011 International Conference on Electric Information and Control Engineering, Wuhan, China, 15–17 April 2011; pp. 3024–3027. [Google Scholar] [CrossRef]
- Sasiadek, J.Z.; Hartana, P. Sensor data fusion using Kalman filter. In Proceedings of the Third International Conference on Information Fusion, Paris, France, 10-13 July 2020; Volume 2, pp. WED5/19–WED5/25. [Google Scholar] [CrossRef]
- Gao, J.B.; Harris, C.J. Some Remarks on Kalman Filters for the Multisensor Fusion. Inf. Fusion 2002, 3, 191–201. [Google Scholar] [CrossRef]
- Zhao, K.; Li, L.; Chen, Z.; Sun, R.; Yuan, G.; Li, J. A Survey: Optimization and Applications of Evidence Fusion Algorithm Based on Dempster–Shafer Theory. Appl. Soft Comput. 2022, 124, 109075. [Google Scholar] [CrossRef]
- Fang, Y.; Masaki, I.; Horn, B. Depth-Based Target Segmentation for Intelligent Vehicles: Fusion of Radar and Binocular Stereo. IEEE Trans. Intell. Transp. Syst. 2002, 3, 196–202. [Google Scholar] [CrossRef]
- Yeong, D.J.; Velasco-Hernandez, G.; Barry, J.; Walsh, J. Sensor and Sensor Fusion Technology in Autonomous Vehicles: A Review. Sensors 2021, 21, 2140. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhou, M.; Qiu, P.; Huang, Y.; Li, J. Radar and Vision Fusion for the Real-Time Obstacle Detection and Identification. Ind. Robot 2019, 46, 391–395. [Google Scholar] [CrossRef]
- Wu, Y.; Li, D.; Zhao, Y.; Yu, W.; Li, W. Radar-Vision Fusion for Vehicle Detection and Tracking. In Proceedings of the 2023 International Applied Computational Electromagnetics Society Symposium (ACES), Monterey, CA, USA, 26–30 March 2023; pp. 1–2. [Google Scholar] [CrossRef]
- Wiseman, Y. Ancillary Ultrasonic Rangefinder for Autonomous Vehicles. Int. J. Secur. Appl. 2018, 12, 49–58. [Google Scholar] [CrossRef]
- Premnath, S.; Mukund, S.; Sivasankaran, K.; Sidaarth, R.; Adarsh, S. Design of an Autonomous Mobile Robot Based on the Sensor Data Fusion of LIDAR 360, Ultrasonic Sensor and Wheel Speed Encoder. In Proceedings of the 2019 9th IEEE International Conference on Advances in Computing and Communication (ICACC), Bangalore, India, 15–16 March 2019; pp. 62–65. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Experimental Environment | Environmental Condition |
|---|---|
| CPU | 13th Gen Intel (R) Core (TM) i7-13700H 2.40 GHz (Intel Corporation, Santa Clara, CA, USA) |
| GPU | NVIDIA GeForce RTX 4060 (Nvidia Corporation, Santa Clara, CA, USA) |
| Operating system | Ubuntu 18.04 |
| Programming language embedded platform | Python 3.8 RDK x3 |
| Parameter Name | Parameter Value |
|---|---|
| Image size | 640 × 640 |
| Weight decay | 0.0005 |
| Batch size | 16 |
| Learning rate | 0.01 |
| Epochs | 100 |
| Number | Module Repetition | Module Names | Parameter Configuration | Output Size |
|---|---|---|---|---|
| 0 | 1 | Focus | [3,32,3] | 32 × 320 × 320 |
| 1 | 1 | S-(2) | [32,64,2] | 64 × 160 × 160 |
| 2 | 1 | S-(1) | [64,64,1] | 64 × 160 × 160 |
| 3 | 1 | S-(2) | [64,128,2] | 128 × 80 × 80 |
| 4 | 3 | S-(1) | [128,128,1] | 128 × 80 × 80 |
| 5 | 1 | S-(2) | [128,256,2] | 256 × 40 × 40 |
| 6 | 3 | S-(1) | [256,256,1] | 256 × 40 × 40 |
| 7 | 1 | S-(2) | [256,512,2] | 512 × 20 × 20 |
| 8 | 1 | SPPF | [512,512,[5,5,5]] | 512 × 20 × 20 |
| 9 | 1 | S-(1) | [512,512,1] | 512 × 20 × 20 |
| Model | Par/MB | FPS | mAP@.5% |
|---|---|---|---|
| YOLOv5 | 7.05 | 50.29 | 59.4 |
| YOLOv5 + DCAM | 8.40 | 46.15 | 67.8 |
| YOLOv5 + Backbone + DCAM | 5.04 | 46.53 | 67.1 |
| YOLOv5 + Neck + DCAM | 5.88 | 45.74 | 66.4 |
| Backbone + Neck + DCAM | 2.52 | 48.56 | 67.2 |
| RDK x3 | Raspberry Pie 5 | Jetson Nano | |
|---|---|---|---|
| CPU | 8x Cortex A55@1.5 GHz | 4x A76@2.4 GHz | 4-core ARM Cortex-A57 |
| NPU | 5 TOPS | / | 7 TOPS |
| Network | 1 × RJ45 gigabit supporting PoE power supply dual frequency WIFI-6 | 1 × RJ45 Gigabit PoE requires additional HAT dual band WIFI-5 | 1 × RJ45 gigabit supporting PoE power supply, dual frequency WIFI-5 |
| Price | ¥375 | ¥486 | ¥1500 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Hu, T.; Zhu, H. Roadside Perception Applications Based on DCAM Fusion and Lightweight Millimeter-Wave Radar–Vision Integration. Electronics 2025, 14, 1576. https://doi.org/10.3390/electronics14081576
Yu X, Hu T, Zhu H. Roadside Perception Applications Based on DCAM Fusion and Lightweight Millimeter-Wave Radar–Vision Integration. Electronics. 2025; 14(8):1576. https://doi.org/10.3390/electronics14081576
Chicago/Turabian StyleYu, Xiaoyu, Tao Hu, and Haozhen Zhu. 2025. "Roadside Perception Applications Based on DCAM Fusion and Lightweight Millimeter-Wave Radar–Vision Integration" Electronics 14, no. 8: 1576. https://doi.org/10.3390/electronics14081576
APA StyleYu, X., Hu, T., & Zhu, H. (2025). Roadside Perception Applications Based on DCAM Fusion and Lightweight Millimeter-Wave Radar–Vision Integration. Electronics, 14(8), 1576. https://doi.org/10.3390/electronics14081576