Abstract
Modern computer vision techniques for forest fire detection face a trade-off between computational efficiency and detection accuracy in complex forest environments. To address this, we propose a lightweight YOLOv11n-based framework optimized for edge deployment. The backbone network integrates a novel C3k2MBNV2 (Cross Stage Partial Bottleneck with 3 convolutions and kernel size 2 MobileNetV2) block to enable efficient fire feature extraction via a compact architecture. We further introduce the SCDown (Spatial-Channel Decoupled Downsampling) block in both the backbone and neck to preserve critical information during downsampling. The neck further incorporates the C3k2WTDC (Cross Stage Partial Bottleneck with 3 convolutions and kernel size 2, combined with Wavelet Transform Depthwise Convolution) block, enhancing contextual understanding with reduced computational overhead. Experiments on a forest fire dataset demonstrate that our model achieves a 53.2% reduction in parameters and 28.6% fewer FLOPs compared to YOLOv11n (You Only Look Once version eleven), along with a 3.3% improvement in mean average precision. These advancements establish an optimal balance between efficiency and accuracy, enabling the proposed framework to attain real-time detection capabilities on resource-constrained edge devices in forest environments. This work provides a practical solution for deploying reliable forest fire detection systems in scenarios demanding low latency and minimal computational resources.
1. Introduction
In recent years, forest fires have posed severe threats to global ecosystems, human communities, and biodiversity. These disasters decimate critical forest habitats, eradicate native vegetation, and disrupt ecological balance, triggering cascading declines in wildlife populations and potentially driving vulnerable species to extinction. Furthermore, forest fires intensify soil degradation through erosion and nutrient depletion, severely compromising agricultural productivity. Post-fire landscapes also exhibit reduced water retention capacity, amplifying the risk of secondary disasters, such as debris flows and flash floods, which endanger both ecosystems and human settlements. Therefore, timely detection and effective prevention of forest fire spread are critical [1,2,3].
During the initial phase of a forest fire, flames propagate rapidly under wind influence. This process emits dense smoke plumes that disperse into the atmosphere. Traditional forest fire detection methods primarily rely on sensors, with the most common approach being the use of fire alarm systems for monitoring. These systems typically integrate smoke detectors, temperature and humidity sensors, and flame detectors [4]. When abnormal conditions are detected, the system automatically triggers an alarm to indicate the occurrence of a fire. However, limited sensor coverage in forest environments often leads to delayed fire detection. Additionally, fire alarm systems depend on costly hardware installations. Moreover, sensors cannot provide real-time visual data from the fire site, hindering rapid situational assessment and making this method unsuitable for real-time forest fire detection. In contrast, high-definition camera-based monitoring provides a more effective solution. With the support of drone technology [5,6,7], larger forest areas can be monitored in real time. This method enables real-time surveillance and captures comprehensive visual data on forest fires. It offers a more accurate and timely assessment of fire dynamics compared to sensor-based approaches [8].
With the continuous development of computer vision technologies, researchers have focused on applying image processing techniques to forest fire scenarios. Research has shown that, during a forest fire, the motion and texture features of smoke and flames can effectively detect fire occurrences. Additionally, suitable color models such as RGB [9], YUV [10], HSV [11], and YCbCr [12,13] can be employed for fire detection. Shidik et al. [14] employed multiple color features from the RGB, HSV, and YCbCr color spaces, including background subtraction and time frame selection, to achieve rapid fire detection. Hossain et al. [15] proposed a fire detection method for UAV-captured forest fire images, which utilizes flame and smoke features. Their method employs color and multi-color space local binary patterns to identify flames and smoke in UAV images. Ding et al. [16] enhanced flame detection by optimizing the color space using chaos theory and the k-medoids particle swarm optimization algorithm. Khondaker et al. [17] proposed a multi-level fire detection framework based on computer vision. Their approach utilizes advanced fire color detection rules through majority voting to obtain regions of interest, dynamically verifies pixel authenticity through shape change, and evaluates turbulence using an enhanced optical flow analysis algorithm to identify fire. Tung et al. [18] proposed a four-stage smoke detection algorithm for fire video images. The algorithm includes motion region segmentation, smoke candidate region clustering, parameter extraction, and a support vector machine classifier, utilizing the color and dynamic characteristics of smoke.
With the development of computer software and hardware, as well as advancements in computer algorithms, more researchers have utilized deep learning techniques for forest fire detection. Muhammad et al. [19] proposed an efficient system based on Convolutional Neural Networks (CNNs) for fire detection in videos recorded under uncertain monitoring environments. This system employs a lightweight network architecture without dense fully connected layers, making it highly suitable for mobile edge devices and embedded systems. Kaliyev et al. [20] proposed a forest fire detection method based on CNNs and drones, which are particularly useful for continuous patrols in fire-prone areas. Mowla et al. [21] introduced a novel architecture called an Adaptive Hierarchical Multi-Headed Convolutional Neural Network with Modified Convolutional Block Attention Module (AHMHCNN-mCBAM). This architecture integrates adaptive pooling, concatenated convolution, and an improved attention mechanism, effectively addressing challenges related to varying scales, resolutions, and complex spatial dependencies in wildfire datasets. Wang et al. [22] addressed the limitations of real-time small-target flame or smoke detection in forest fire scenarios by designing an efficient and lightweight architecture. They enhanced multi-scale flame and smoke detection capabilities through the Dilation Repconv Cross-Stage Partial Network and improved detection accuracy and robustness in complex forest backgrounds using the Global Mixed-Attention model with Cross-Feature Pyramid and the Lite-Path Aggregation Network. Yuan et al. [23] developed a target detection algorithm called FF-net (F_Res, Fire Label Assignment) to tackle the insufficient detection accuracy in the later stages of forest fires in complex environments. The F_Res (Fire ResNet) and F_fire activation functions enhance feature extraction and nonlinear fitting capabilities. Additionally, the Fire Label Assignment method reduces network complexity while maintaining detection accuracy, and Kullback–Leibler Focal Loss addresses data imbalance and gradient issues. Li et al. [24] proposed a high-precision and robust forest fire smoke recognition method to effectively solve the early detection problem of forest fire smoke. This method uses a Swin multidimensional window extractor to enhance information exchange between windows in horizontal and vertical dimensions for extracting global texture features. Furthermore, the guillotine feature pyramid network reduces redundant features, improving the model’s resistance to interference. The method also employs a contour-adaptive loss function to handle the sparsity and irregularity of smoke at the edges.
Although the existing deep learning methods have shown potential in forest fire detection, most rely on complex network architectures to improve performance. However, the excessively high FLOPs and large parameter counts of these models create a significant accuracy–efficiency trade-off, hindering their deployment on mobile devices for real-time monitoring. To address this, we propose a lightweight YOLOv11n-based model that maintains high detection accuracy while significantly reducing computational complexity and storage demands. First, the backbone employs a C3k2Mbnv2 block, which utilizes inverted residual structures and depthwise separable convolutions to optimize channel operations, enabling efficient fire feature extraction with minimal overhead. Second, we integrate a spatial-channel decoupled downsampling (SCDown) block into both the backbone and neck. This block decouples spatial and channel dimensions during downsampling, retaining critical details while reducing feature map dimensions. Finally, the neck incorporates a C3k2WTDC block, which integrates wavelet transforms into convolutional operations to capture multi-scale fire details with lower computational costs.
2. Related Work
2.1. Dataset and Processing
The YOLOv11-based forest fire detection method requires a high-quality dataset. A high-quality training dataset allows deep learning models to learn forest fire features more effectively. To enhance the model’s generalization ability, we constructed a diverse training dataset. This dataset incorporates not only forest fire images but also scenes of other fire types, such as early small fires, changes in smoke patterns, and irregular fire spread. By collecting publicly available conventional fire images, we provided the model with broader fire scenario variations. This diversity enhances the model’s robustness and adaptability, enabling it to handle complex forest fire detection tasks.
In addition, we converted high-definition camera-captured forest fire videos into images and selected only high-quality data from the resulting frames. We then used LabelImg to annotate these fire images, generating YOLOv11-compatible label files in TXT format. To enhance the model’s ability to recognize various forest fire types, we selected images from diverse scenarios, including tree trunk fires, canopy fires, and long-distance forest fire captures.
The majority of the fire images in the dataset contain prominent fire-related features, such as flames and smoke [25,26]. These features are often direct manifestations of fires, making them highly distinguishable. The presence of flames typically indicates the spread of fires and the intense release of heat, while smoke signifies that fires are ongoing and releasing harmful gases. In addition to flames and smoke, fire images may include remnants of burning materials, damage to buildings or forests, and the impact of fires on the surrounding environment. Flames typically display vibrant colors, such as yellow, orange, and red, during combustion, and, in forest fires, the shape of the flames can vary. Smoke, on the other hand, is primarily black, gray, or white and exhibits high concentration and dynamic variation, often showing diffuse and spreading characteristics. Therefore, flames and smoke are the primary visual features used to identify the occurrence of forest fires. Figure 1 illustrates representative samples from the forest fire dataset.

Figure 1.
Selected representative forest fire images from the forest fire dataset: (a) remote capture of a forest fire. (b) Remote capture of a forest fire. (c) Trunk fire in a forest. (d) Canopy fire in a forest.
2.2. YOLOv11
YOLO (You Only Look Once) [27,28,29,30] is a real-time object detection algorithm that balances speed, efficiency, and accuracy. YOLOv11, the latest iteration of the YOLO series, comprises four main components: the input layer, backbone, neck, and detection head. In the backbone, the C3k2 block (Cross-Stage Partial with kernel size 2) employs two compact convolutions to enhance feature extraction efficiency. Multi-scale feature fusion is achieved via Spatial Pyramid Pooling-Fast (SPPF), followed by a Convolutional Block with parallel spatial attention (C2PSA). The C2PSA block integrates a parallel spatial attention mechanism to dynamically focus on key image regions, improving detection accuracy for multi-scale and variably positioned targets. The neck structure constructs an efficient feature pyramid through the C3k2 block using dual-path feature aggregation. In the upsampling stage, the CBS block refines features, while the downsampling stage leverages cross-stage connections to deeply integrate shallow and deep features. Additionally, dual depthwise convolution (DWConv) layers in the classification head reduce redundant computations, lowering the model’s parameter count and computational load.
YOLOv11 is available in multiple variants with a shared architecture but varying model sizes, making it suitable for object detection tasks across small, medium, and large scales. In forest fire detection, the model must balance detection accuracy and inference speed. The model’s computational footprint determines its feasibility for deployment on resource-constrained edge devices. We selected YOLOv11 as the baseline model due to its lowest parameter count and FLOPs, while retaining high accuracy and low inference latency. To address deployment challenges on hardware with limited resources, we optimized the backbone and neck networks of YOLOv11, resulting in a lightweight architecture with improved accuracy. Figure 2 illustrates YOLOv11’s architectural overview.
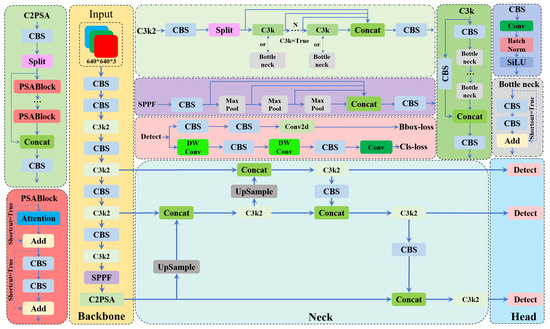
Figure 2.
The overall structure of YOLOv11.
3. Proposed Algorithm
3.1. C3k2MBNV2 Block
In YOLOv11, the backbone network integrates the C3k2 block based on Cross-Stage Partial (CSP) technology. By employing two smaller convolutional kernels, the C3k2 block enhances feature extraction capabilities, enabling the network to capture richer multi-scale features critical for detecting fire and smoke in complex forest fire scenarios. However, this architecture introduces excessive computational complexity, increasing the model’s resource demands. To address this, we draw inspiration from the lightweight MobileNetV2 [31] and design the C3k2MBNV2 block. By leveraging inverted residuals and linear bottleneck structures, the C3k2MBNV2 reduces parameters and FLOPs, optimizes feature propagation, and preserves representation power.
Unlike traditional residual structures, the inverted residual integrates a pointwise convolution and a depthwise separable convolutional layer. This structure first expands feature channels through pointwise convolution, applies depthwise convolution for spatial filtering, and then compresses channels via linear projection—effectively reducing computational complexity while maintaining efficiency. Its skip connections serve dual roles: bypassing convolutional layers to preserve raw features and enhancing information flow through channel expansion followed by dimension restoration. However, mapping high-dimensional features to low dimensions through nonlinear activations can cause feature degradation. To address this, the inverted residual replaces nonlinear activations with linear functions during dimensionality reduction, effectively mitigating gradual information loss.
In this study, we optimized the architecture of YOLOv11. In the Mbnv2 block, we first used a 1 × 1 convolutional kernel to expand the input channels, which enhanced the network’s ability to capture high-level features. In the depthwise (DW) block, we employed a 5 × 5 depthwise convolutional kernel to extract spatial features. Thanks to the depthwise convolution design, we effectively reduced the model’s computational complexity. Meanwhile, the Cross-Bottleneck (CB) convolution block utilized a 1 × 1 convolutional kernel and removed the SiLU activation function. This compressed the feature map’s channels back to the original dimension while retaining the residual connection step, where the input and output were added together. Additionally, we replaced the original bottleneck block in the backbone with the MBNV2 block. The inverted residual and linear bottleneck structures extracted representative features from images. Specifically, the inverted residual structure mitigated dimensional collapse in low-dimensional representations, significantly reducing the model’s parameters and computational load, thereby improving network efficiency. The enhanced network demonstrated superior detection capabilities for small targets and complex scenes, enabling more accurate identification of flame and smoke features in forest fires under challenging backgrounds. The improved structure of the C3k2MBNV2 block is illustrated in Figure 3.
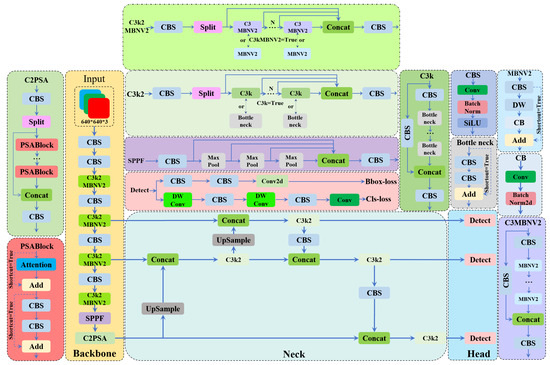
Figure 3.
The improved structure of the C3k2MBNV2 block.
3.2. SCDown Block
In CNNs, deep-layer feature maps contain rich semantic information; however, their lower spatial resolution diminishes the ability to extract features from small objects. Therefore, to enhance the detection performance for small objects in complex scenes, effective fusion of shallow and deep feature maps is crucial.
To address this issue, we integrate the SCDown [32] block into the backbone and neck structures of YOLOv11. The SCDown block first adjusts the input feature map’s channel dimensions via pointwise convolution while preserving spatial resolution. Next, a depthwise separable convolution layer downsamples the spatial resolution, retaining channel-wise information. Finally, the output feature map has reduced spatial dimensions but maintains the original channel count. By independently processing spatial information per channel during downsampling, the SCDown block mitigates information loss common in traditional convolutions and preserves fine-grained details. This design enhances multi-scale feature fusion by effectively combining shallow and deep features. As a result, the model achieves higher detection accuracy in complex scenarios and improved small-target recognition. Additionally, depthwise separable convolution reduces computational costs by operating on individual channels instead of all channels simultaneously, as in standard convolutions. The overall architecture with the SCDown block is illustrated in Figure 4.
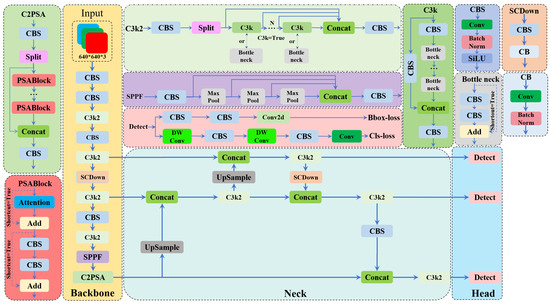
Figure 4.
The improved structure of the SCDown block.
3.3. C3K2WTDC Block
In forest fire detection tasks, flame and smoke features exhibit distinct multi-scale characteristics: flames show dynamic local high-frequency patterns, while smoke displays diffuse low-frequency variations. Traditional CNNs typically extract features within limited receptive fields, focusing on local regions. This makes it challenging for CNN-based models to capture multi-scale interactions between large and small features in dynamic, complex scenarios. Additionally, standard convolutions suffer from aliasing artifacts during downsampling, leading to high-frequency information loss and degraded feature representation. Although larger kernels expand the receptive field, they increase computational complexity and parameter count, hindering real-time deployment on resource-constrained devices. To address these limitations, we integrate wavelet transform convolution (WTConv) [33] into the neck structure and propose the C3K2WTDC block.
The wavelet transform convolution (WTC) layer integrates the wavelet transform (WT) with convolutional operations, enabling CNNs to capture local and global information more effectively through multi-frequency processing of input data. First, the input feature map is decomposed by the wavelet transform into multi-scale sub-bands across different frequencies. Convolutional layers then extract hierarchical features from these sub-bands. By incorporating WTConv, the model leverages multi-frequency responses to dynamically expand receptive fields. This design allows small-kernel convolutions to operate across multiple scales, enhancing the detection of flame and smoke regions with varying sizes in complex forest fire scenarios.
Building on this, we designed the wavelet transform pointwise convolution (WTPC) block to enhance feature extraction efficiency. In the WTPC layer, a 1 × 1 convolutional kernel processed the feature maps from the WTC layer, adjusting channel dimensions and fusing channels while retaining spatial details and reducing computational costs (e.g., FLOPs). This design ensures efficient utilization of multi-scale features while minimizing model complexity. In the wavelet transform depthwise convolution (WTDC) layer, depthwise convolution was applied to the WTPC output. Unlike standard convolution, depthwise convolution independently operates on each channel, drastically reducing computations. This method optimizes efficiency while preserving per-channel feature representations, enhancing robustness for detecting flames and smoke across scales. By integrating wavelet transforms with multi-convolution operations, we constructed the C3k2WTDC block. This block improves multi-scale feature extraction and reduces computational overhead without sacrificing accuracy. The enhanced network architecture is illustrated in Figure 5.
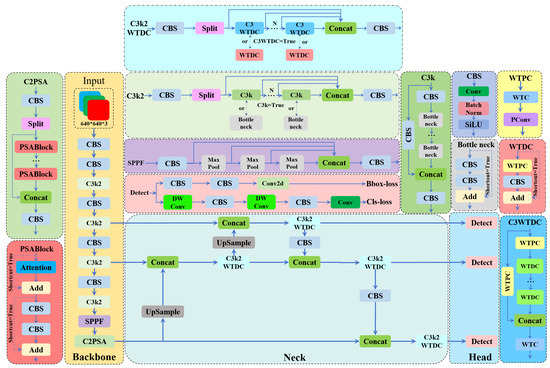
Figure 5.
The improved structure of the C3K2WTDC block.
3.4. Improved YOLOv11n Model
Our model achieves lightweight feature extraction and reduces computational complexity through three architectural innovations: the C3k2MBNV2 block in the backbone network integrates inverted residuals and linear bottlenecks to maintain flame and smoke feature extraction while minimizing redundant computations; the SCDown block in both backbone and neck decouples spatial and channel dimensions to compress feature maps while preserving critical details, thereby enhancing detection accuracy in complex forest fire scenarios; and the C3k2WTDC block in the neck combines wavelet transform convolution (WTConv) with multi-convolutional operations to capture fine-grained flame and smoke patterns.
The C3k2MBNV2 optimizes computational efficiency through bottleneck channel compression without sacrificing feature fidelity. The SCDown block independently processes spatial and channel information during downsampling, mitigating aliasing artifacts and improving robustness in cluttered fire environments. Meanwhile, the C3k2WTDC leverages WTConv’s multi-frequency responses to dynamically expand receptive fields, enabling multi-scale feature fusion. Compared to traditional convolutions, this design significantly reduces model complexity while improving detection accuracy across diverse fire scales. By synergistically balancing spatial detail retention, channel efficiency, and multi-scale analysis, our model achieves superior computational efficiency and detection performance in resource-constrained forest fire monitoring.
Through the proposed blocks, the improved model effectively reduces computational costs while enhancing detection accuracy—a critical advantage in resource-constrained forest fire monitoring. It can be deployed on mobile or embedded devices for real-time monitoring, achieving high accuracy with minimal computational overhead. The architecture of the improved model is shown in Figure 6.
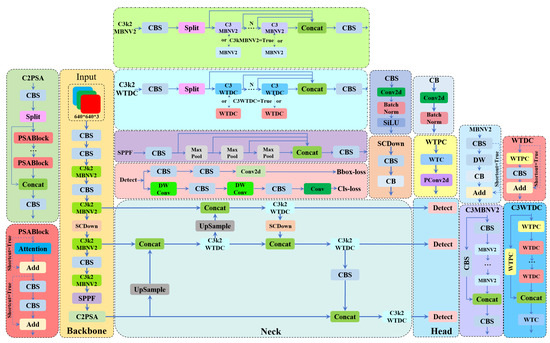
Figure 6.
The overall structure of our model is shown in Figure 6.
3.5. Performance Evaluation
To evaluate the performance of the improved model and validate the effectiveness of each enhancement, we adopt the following key evaluation metrics: precision (P), recall (R), average precision (AP), mean average precision (mAP), F1-score, parameter count (Params), floating-point operations (FLOPs), and detection time per image. Among these, Params and FLOPs quantify computational complexity, while P, R, mAP, and F1-score measure detection accuracy.
In model evaluation, TP represent the regions that the model correctly predicts as fire and smoke, meaning the model’s prediction matches the ground truth. FP refer to areas where the model incorrectly identifies the background as fire and smoke and the model predicts fire and smoke but the ground truth is background. FN represent areas where the model fails to detect fire and smoke, meaning the model predicts background while the ground truth is fire and smoke. In this study, all of the model’s detection results can simultaneously include fire and smoke, represented as TP + FP. Meanwhile, TP + FN represents the total number of fire and smoke instances that actually exist in the image.
In forest fire detection, P is a key metric to evaluate the model’s ability to avoid false alarms. It calculates the proportion of true fire predictions (correctly identified fires) among all predicted fires, as expressed in Equation (1):
R is a metric that quantifies a model’s ability to correctly identify positive samples among all actual positives, with higher values indicating fewer missed detections. It is formally defined by Equation (2):
AP is calculated as the area under the precision–recall (PR) curve. The detection threshold determines the trade-off between P and R. In single-class detection, AP aggregates PR values across all thresholds, as defined in Equation (3):
Here, P(R) denotes the precision at recall R. In multi-class object detection, the mAP is computed by averaging the AP values across all categories. The formula for mAP is defined in Equation (4):
where is the AP for the i-th category, and N is the total number of categories.
The F1-score is a critical metric that evaluates the balance between precision and recall in fire detection models. It combines both metrics by balancing their values to provide a comprehensive performance assessment. The F1-score is calculated as the harmonic mean of precision and recall, as defined in Equation (5):
In this study, a higher mAP value suggests superior detection performance and improved recognition accuracy of the model. By optimizing these metrics, the model enhances its practical effectiveness, particularly in complex fire and smoke detection scenarios.
4. Results
4.1. Training
Table 1 summarizes the experimental training environment conditions, and Table 2 lists the key training parameters for the forest fire detection model. Our custom-built fire detection dataset contains 3970 annotated fire images, which were partitioned into training, validation, and test sets in an 8:1:1 ratio.

Table 1.
Experimental conditions.
Table 2.
Key parameters of experimental training.
Figure 7 illustrates the precision, recall, mAP, and F1-score of the model across training epochs. As the number of epochs increases, precision and recall show gradual improvement. During the initial training stages, the high learning rate causes rapid but unstable growth in mAP and F1-score, with significant fluctuations. Beyond 50 epochs, however, these metrics stabilize and exhibit a steady upward trend. By epoch 150, both the mAP and F1-score curves converge, indicating model performance stabilization. Overall, the model demonstrates robust performance in real-world forest fire scenarios, enabling rapid flame and smoke detection and real-time deployment capability.
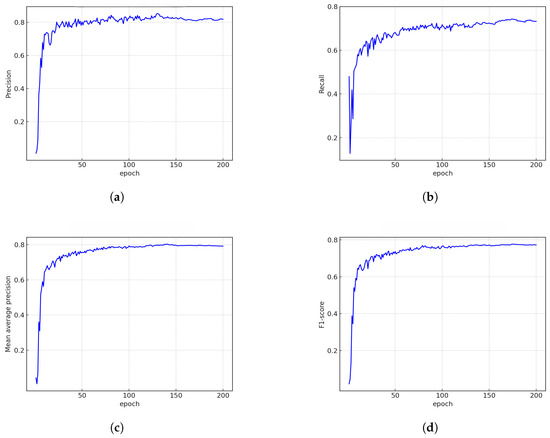
Figure 7.
Training progress curve: (a) precision of our model. (b) Recall of our model. (c) mAP50 of our model. (d) F1-score of our model.
4.2. Ablation Experiments
Figure 8 illustrates the performance improvements at each stage of the ablation experiment, showing the mAP curves of four different models. As seen in the figure, after 50 epochs, our model achieves a stable convergence trend and significantly outperforms the others in terms of mAP. This indicates a substantial improvement in precision, attributed to the synergistic effects of the proposed blocks, which enhance multi-scale feature fusion and suppress background noise in fire scenes. The improvement enables our model to effectively recognize flames and smoke in fire images even under challenging conditions such as occlusions or low visibility. Specifically, the C3K2WTDC block improves edge detection of smoke plumes, while the SCDown block preserves critical spatial details during resolution reduction. The model’s ability to identify key features more effectively in forest fire images enhances its capability to perform forest fire detection tasks. This is particularly important in complex scenarios, such as densely vegetated areas or overlapping fire signatures, where accurate detection of details is crucial for real-time monitoring of forest fires and minimizing false alarms in practical deployments.

Figure 8.
The comparison of mAP50 across different models is shown in the figure above.
To verify the computational resource requirements of the improved model, an ablation study was conducted by integrating the proposed blocks into YOLOv11n. The model’s parameters, FLOPs, detection time per image, and model size were then measured to assess the effectiveness of the lightweight design. The results of the ablation study are summarized in Table 3.
Table 3.
The data of the ablation experiments.
As shown in Table 3, after incorporating the C3k2MBNV2 block into YOLOv11n, the model’s parameters and FLOPs decreased by 36.5% and 16.5%, respectively. Subsequently, applying the SCDown block further reduced the parameters and FLOPs. Finally, with the addition of the C3k2WTDC block, the improved model achieved reductions of 53.2% in parameters and 28.6% in FLOPs compared to the original YOLOv11n. These results demonstrate that each proposed block effectively reduces computational complexity, with the final model size being only half of YOLOv11n. This highlights the suitability of our improved model for deployment in resource-constrained forest environments. Although the model exhibits a slight increase in inference time, it still satisfies real-time forest fire detection requirements.
4.3. Comparative Experiments
To validate the improved detection accuracy of the modified model, we tested it on a created test dataset and compared its performance with the baseline methods. The detection accuracy results are presented in Table 4.
Table 4.
Comparison of various YOLOv11 models on the test dataset.
As indicated in Table 4, our model outperforms YOLOv11n across key metrics such as precision, recall, F1-score, and mAP. When compared to YOLOv11s, our model shows a slight decrease in precision, suggesting a slight increase in false positives. However, our model surpasses YOLOv11s in critical metrics like recall, F1-score, and mAP, which indicates that it is more effective in minimizing false negatives. This improvement leads to higher detection accuracy, allowing our model to capture more comprehensive forest fire data. Particularly in real-time forest fire detection in complex environments, our model demonstrates significantly better performance.
FASDD_UAV [34] is a drone-based dataset specifically designed for forest fire detection. It comprises multiple drone-captured forest fire videos that simulate flame and smoke characteristics in realistic scenarios, enabling the assessment of fire detection algorithms in practical applications. To evaluate our proposed algorithm’s effectiveness, we conducted experiments using FASDD_UAV. Through comparative studies, we assessed its performance in real-world fire detection tasks against popular real-time models, including YOLOv8n, YOLOv9t, YOLOv10n, and YOLOv11n. Additionally, we compared our model with state-of-the-art YOLO-based fire detection models to benchmark its capabilities.
From Table 5, our forest fire detection algorithm demonstrates superior performance on the FASDD_UAV dataset, outperforming the existing methods in key metrics. Our model achieves a precision of 89.7% and a recall of 84.6%, reflecting balanced performance. With an mAP50 of 91.6%, it closely trails YOLOv8n and Kong et al. while maintaining robustness under a relaxed IoU threshold. The model’s lightweight architecture is evidenced by 1,209,358 parameters and 4.5B FLOPs, ensuring high computational efficiency. It achieves real-time detection with a latency of 3.1 ms per image, critical for edge deployment. These results highlight a balance between accuracy and efficiency, making it ideal for resource-constrained environments. Although precision is marginally lower than state-of-the-art models, the high mAP50 and low resource demands solidify its competitiveness in real-time forest fire monitoring.
Table 5.
Comparative analysis of multiple fire detection algorithms.
5. Discussion
5.1. Flame Detection Performance
At the early stages of a forest fire, flames are typically small and often exhibit irregular patterns. This irregularity poses a challenge for forest fire detection models. Enhancing the model’s ability to detect small flame targets enables timely detection of early-stage fires, which improves the model’s overall capability. We trained the improved model on both our dataset and the FASDD_UAV dataset and compared the performance of both versions in detecting small-target flames. Importantly, the small-target flame images used for testing were excluded from both datasets.
As clearly illustrated in Figure 9, the same fire detection model trained on our dataset successfully detects most small flame targets, whereas its FASDD_UAV-trained version fails to identify these targets. This highlights that our dataset is more suitable for complex forest fire detection tasks, enabling the model to reduce false negatives and improve detection accuracy.

Figure 9.
Comparison of small-target flame detection performance in forest fire models: (a) fire detection model trained on our dataset for small-target flame detection. (b) Fire detection model trained on the FASDD_UAV dataset for small-target flame detection.
5.2. Smoke Detection Performance
During a forest fire, smoke rising is common, making smoke a key indicator for fire detection. The smoke produced by burning materials varies in form and exhibits dynamic changes, with the colors typically ranging from white to gray to black. In practical detection, we found that smoke shares similar colors and shapes with clouds. This similarity may lead the fire detection model to mistakenly identify clouds as smoke, resulting in false positives. We trained the improved fire detection model on both our dataset and the FASDD_UAV dataset and compared its performance in detecting smoke in forest fires. The selected images depict both smoke and clouds, and they were excluded from both datasets.
As clearly shown in Figure 10, the fire detection model trained on our dataset can effectively identify smoke without misclassifying clouds as smoke. In contrast, the model trained on the FASDD_UAV dataset fails to detect smoke. This indicates that our model is less likely to misclassify clouds as smoke. The improved model successfully recognizes smoke across diverse scenarios.

Figure 10.
Comparison of fire detection model performance in detecting small-target flames: (a) detection performance of the fire model trained on our dataset for small-target flames. (b) Detection performance of the fire model trained on the FASDD_UAV dataset for small-target flames.
5.3. Model Performance Under Various Conditions
To perform real-time detection tasks in forest environments, the model must be capable of identifying forest fires under diverse conditions. To evaluate the performance of our fire detection model in recognizing flames and smoke under varying conditions, we selected forest images captured under different scenarios, including daytime, nighttime, cloudy, and hazy conditions. These images were not included in our training dataset.
As shown in Figure 11, our model effectively identifies flames and smoke in forest fires under various environmental conditions, including daytime, nighttime, hazy, and cloudy conditions. This demonstrates that the model exhibits strong robustness and adaptability, whether in complex lighting or high-background-noise environments. Under varying illumination and weather conditions, the model accurately detects flames and smoke while distinguishing fire signals from environmental interference, thereby mitigating environmental interference. By reducing false positives and false negatives, our model provides reliable fire monitoring outcomes, ensuring early detection and timely response to forest fires.

Figure 11.
Performance of our fire detection model tested under various environmental conditions: (a) sunny. (b) Night. (c) Cloudy. (d) Hazy.
The stability and accuracy of these capabilities not only enhance the reliability of fire detection but also significantly improve the model’s applicability in real-world scenarios. This is particularly evident in real-time monitoring and forest fire prevention, where the model rapidly captures fire signals and delivers timely alerts, a capability critical for responding to sudden forest fire incidents, minimizing damage, and protecting ecosystems. Furthermore, the model’s consistent performance across diverse environmental conditions provides robust technical support for practical deployment and long-term monitoring, highlighting its potential for broader applications in other domains.
6. Conclusions
Fire smoke detection is critical for preventing forest fires. This paper proposed a real-time forest fire detection algorithm based on deep learning, which incorporates innovative lightweight and efficient feature extraction blocks, C3k2MBNV2 and C3K2WTDC, to ensure high accuracy while significantly reducing model parameters and FLOPs. Additionally, a lightweight SCDown block was introduced to maximize information retention during downsampling, maintaining high detection accuracy with a lightweight architecture. Through these improvements, we conducted experimental validation on our custom forest fire dataset. Compared to the YOLOv8n baseline, our algorithm achieved a 3.3% increase in mAP while reducing the parameters and FLOPs by 53.2% and 28.6%, respectively.
Our custom forest fire dataset includes various fire types, such as early small fires, dynamic smoke patterns, and irregular fire spread. Special attention was paid to annotating small flame targets and dynamic smoke patterns, and cloud images were explicitly labeled to prevent mistaking clouds for smoke. The dataset’s diversity closely simulates complex early-stage forest fire scenarios, thereby enhancing the model’s sensitivity to subtle features. In contrast, the FASDD_UAV dataset focuses on large-scale open flame detection and lacks early-stage fire data, limiting the model’s generalization in complex scenarios. Therefore, although the improved algorithm trained on our dataset achieves a lower overall mAP than the model trained on the FASDD_UAV dataset, it excels in detecting small targets in early-stage fires and significantly reduces the misclassification of clouds as smoke.
The experimental results demonstrate that the proposed algorithm effectively balances computational complexity, detection accuracy, and efficiency, making it highly suitable for practical deployment. Currently, drones can autonomously take off, recharge, and patrol along pre-set paths. When integrated with our model, drones perform routine forest fire monitoring tasks, enabling efficient patrols and real-time surveillance. Additionally, cameras can be deployed in high-risk fire-prone forest regions, where our model monitors and analyzes captured images, enabling timely detection of potential fire hazards.
Author Contributions
Methodology, B.L.; Formal analysis, J.Q.; Investigation, L.Q.; Writing—original draft, Y.T.; Visualization, P.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Alizadeh, M.R.; Abatzoglou, J.T.; Luce, C.H.; Adamowski, J.F.; Farid, A.; Sadegh, M. Warming enabled upslope advance in western US forest fires. Proc. Natl. Acad. Sci. USA 2021, 118, e2009717118. [Google Scholar] [CrossRef]
- da Silva, S.S.; Fearnside, P.M.; de Alencastro Graça, P.M.L.; Brown, I.F.; Alencar, A.; de Melo, A.W.F. Dynamics of forest fires in the southwestern Amazon. For. Ecol. Manag. 2018, 424, 312–322. [Google Scholar] [CrossRef]
- Edwards, R.B.; Naylor, R.L.; Higgins, M.M.; Falcon, W.P. Causes of Indonesia’s forest fires. World Dev. 2020, 127, 104717. [Google Scholar] [CrossRef]
- Bushnaq, O.M.; Chaaban, A.; Al-Naffouri, T.Y. The Role of UAV-IoT Networks in Future Wildfire Detection. IEEE Internet Things J. 2021, 8, 16984–16999. [Google Scholar] [CrossRef]
- Barmpoutis, P.; Papaioannou, P.; Dimitropoulos, K.; Grammalidis, N. A Review on Early Forest Fire Detection Systems Using Optical Remote Sensing. Sensors 2020, 20, 6442. [Google Scholar] [CrossRef]
- Sudhakar, S.; Vijayakumar, V.; Sathiya Kumar, C.; Priya, V.; Ravi, L.; Subramaniyaswamy, V. Unmanned Aerial Vehicle (UAV) based Forest Fire Detection and monitoring for reducing false alarms in forest-fires. Comput. Commun. 2020, 149, 1–16. [Google Scholar] [CrossRef]
- Hu, J.; Niu, H.; Carrasco, J.; Lennox, B.; Arvin, F. Fault-tolerant cooperative navigation of networked UAV swarms for forest fire monitoring. Aerosp. Sci. Technol. 2022, 123, 107494. [Google Scholar] [CrossRef]
- Muhammad, K.; Ahmad, J.; Mehmood, I.; Rho, S.; Baik, S.W. Convolutional Neural Networks Based Fire Detection in Surveillance Videos. IEEE Access 2018, 6, 18174–18183. [Google Scholar] [CrossRef]
- Pathare, S.J.; Bhombra, G.K.; Kamble, K.D.; Nagare, G.D. Early Identification of Fire by Utilization of Camera. In Proceedings of the IEEE 2018 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 3–5 April 2018; pp. 0001–0004. [Google Scholar] [CrossRef]
- Prema, C.E.; Vinsley, S.S.; Suresh, S. Multi Feature Analysis of Smoke in YUV Color Space for Early Forest Fire Detection. Fire Technol. 2016, 52, 1319–1342. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, J.; Han, T.; Cai, X. Fire Smoke Detection Based on Vision Transformer. In Proceedings of the 2022 4th International Conference on Natural Language Processing (ICNLP), Xi’an, China, 25–27 March 2022; pp. 39–43. [Google Scholar] [CrossRef]
- Chen, X.; An, Q.; Yu, K.; Ban, Y. A Novel Fire Identification Algorithm Based on Improved Color Segmentation and Enhanced Feature Data. IEEE Trans. Instrum. Meas. 2021, 70, 5009415. [Google Scholar] [CrossRef]
- Tan, Y.; Qin, J.; Xiang, X.; Ma, W.; Pan, W.; Xiong, N.N. A Robust Watermarking Scheme in YCbCr Color Space Based on Channel Coding. IEEE Access 2019, 7, 25026–25036. [Google Scholar] [CrossRef]
- Shidik, G.F.; Adnan, F.N.; Supriyanto, C.; Pramunendar, R.A.; Andono, P.N. Multi color feature, background subtraction and time frame selection for fire detection. In Proceedings of the IEEE 2013 International Conference on Robotics, Biomimetics, Intelligent Computational Systems, Jogjakarta, Indonesia, 25–27 November 2013; pp. 115–120. [Google Scholar] [CrossRef]
- Hossain, F.A.; Zhang, Y.M.; Tonima, M.A. Forest fire flame and smoke detection from UAV-captured images using fire-specific color features and multi-color space local binary pattern. J. Unmanned Veh. Syst. 2020, 8, 285–309. [Google Scholar] [CrossRef]
- Ding, X.; Gao, J. A new intelligent fire color space approach for forest fire detection. J. Intell. Fuzzy Syst. 2022, 42, 5265–5281. [Google Scholar] [CrossRef]
- Khondaker, A.; Khandaker, A.; Uddin, J. Computer Vision-based Early Fire Detection Using Enhanced Chromatic Segmentation and Optical Flow Analysis Technique. Int. Arab J. Inf. Technol. 2020, 17, 947–953. [Google Scholar] [CrossRef]
- Tung, T.X.; Kim, J.M. An effective four-stage smoke-detection algorithm using video images for early fire-alarm systems. Fire Saf. J. 2011, 46, 276–282. [Google Scholar] [CrossRef]
- Muhammad, K.; Khan, S.; Elhoseny, M.; Hassan Ahmed, S.; Wook Baik, S. Efficient Fire Detection for Uncertain Surveillance Environment. IEEE Trans. Ind. Informatics 2019, 15, 3113–3122. [Google Scholar] [CrossRef]
- Kaliyev, D.; Shvets, O.; Grigoryeva, S.; Alimkhanova, A. Intelligent Forest Fire Detection Using CNN and UAVs. In Proceedings of the IEEE 2024 6th International Symposium on Logistics and Industrial Informatics (LINDI), Karaganda, Kazakhstan, 23–25 October 2024; pp. 000131–000134. [Google Scholar] [CrossRef]
- Mowla, M.N.; Asadi, D.; Masum, S.; Rabie, K. Adaptive Hierarchical Multi-Headed Convolutional Neural Network With Modified Convolutional Block Attention for Aerial Forest Fire Detection. IEEE Access 2025, 13, 3412–3433. [Google Scholar] [CrossRef]
- Wang, G.; Li, H.; Xiao, Q.; Yu, P.; Ding, Z.; Wang, Z.; Xie, S. Fighting against forest fire: A lightweight real-time detection approach for forest fire based on synthetic images. Expert Syst. Appl. 2025, 262, 125620. [Google Scholar] [CrossRef]
- Yuan, J.; Wang, H.; Yang, T.; Su, Y.; Song, W.; Li, S.; Gong, W. FF-net: A target detection method tailored for mid-to-late stages of forest fires in complex environments. Case Stud. Therm. Eng. 2025, 65, 105515. [Google Scholar] [CrossRef]
- Li, R.; Hu, Y.; Li, L.; Guan, R.; Yang, R.; Zhan, J.; Cai, W.; Wang, Y.; Xu, H.; Li, L. SMWE-GFPNNet: A high-precision and robust method for forest fire smoke detection. Knowl. Based Syst. 2024, 289, 111528. [Google Scholar] [CrossRef]
- Ding, C.; Zhang, X.; Chen, J.; Ma, S.; Lu, Y.; Han, W. Wildfire detection through deep learning based on Himawari-8 satellites platform. Int. J. Remote Sens. 2022, 43, 5040–5058. [Google Scholar] [CrossRef]
- Moayedi, H.; Mehrabi, M.; Bui, D.T.; Pradhan, B.; Foong, L.K. Fuzzy-metaheuristic ensembles for spatial assessment of forest fire susceptibility. J. Environ. Manag. 2020, 260, 109867. [Google Scholar] [CrossRef] [PubMed]
- Xu, R.; Lin, H.; Lu, K.; Cao, L.; Liu, Y. A Forest Fire Detection System Based on Ensemble Learning. Forests 2021, 12, 217. [Google Scholar] [CrossRef]
- Niu, K.; Wang, C.; Xu, J.; Yang, C.; Zhou, X.; Yang, X. An Improved YOLOv5s-Seg Detection and Segmentation Model for the Accurate Identification of Forest Fires Based on UAV Infrared Image. Remote Sens. 2023, 15, 4694. [Google Scholar] [CrossRef]
- Xue, Z.; Lin, H.; Wang, F. A Small Target Forest Fire Detection Model Based on YOLOv5 Improvement. Forests 2022, 13, 1332. [Google Scholar] [CrossRef]
- Jia, N.; Wei, Z.; Li, B. Attention-Enhanced Lightweight One-Stage Detection Algorithm for Small Objects. Electronics 2023, 12, 1607. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.G.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:abs/2405.14458. [Google Scholar]
- Finder, S.E.; Amoyal, R.; Treister, E.; Freifeld, O. Wavelet Convolutions for Large Receptive Fields. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024. [Google Scholar]
- Wang, M.; Yue, P.; Jiang, L.; Yu, D.; Tuo, T.; Li, J. An open flame and smoke detection dataset for deep learning in remote sensing based fire detection. Geo-Spat. Inf. Sci. 2024, 1–16. [Google Scholar] [CrossRef]
- Kong, D.; Li, Y.; Duan, M. Fire and smoke real-time detection algorithm for coal mines based on improved YOLOv8s. PLoS ONE 2024, 19, e0300502. [Google Scholar] [CrossRef]
- Sun, F.; Du, L.; Dai, Y. GGSYOLOv5: Flame recognition method in complex scenes based on deep learning. PLoS ONE 2025, 20, e0317990. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).