

Edge-Supervised Attention-Aware Fusion Network for RGB-T Semantic Segmentation


Abstract
1. Introduction
- We propose an edge-supervised attention-aware fusion network that effectively leverages complementary information across modalities, mitigates the adverse effects of interfering noise, and achieves superior performance through the efficient integration of multimodal feature information.
- We introduce a feature fusion module that employs Channel Attention and Spatial Attention mechanisms, enabling it to capture richer complementary feature information across both channel and spatial dimensions, thereby enhancing the effectiveness of the fusion process.
- We design an edge-aware refinement module that learns the edge correspondence between different modalities, enhancing the accuracy and clarity of segmentation boundaries.
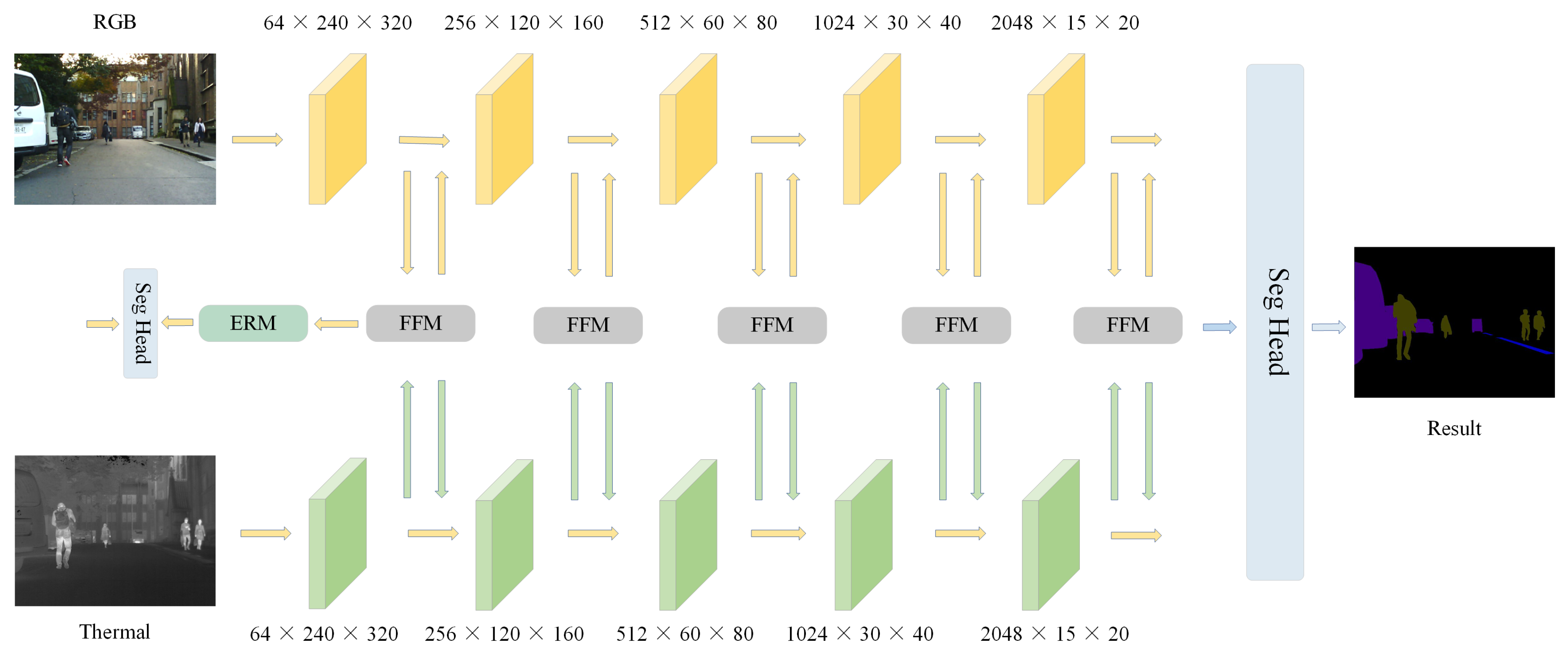
2. Proposed Method
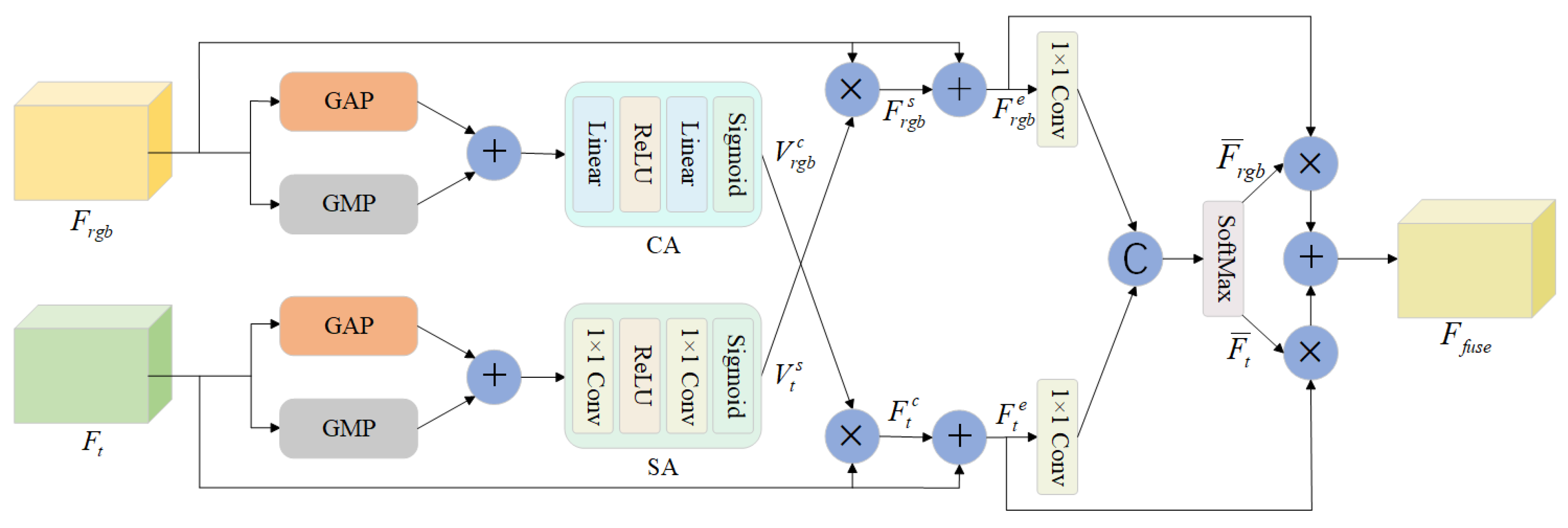
2.1. Feature Fusion Module
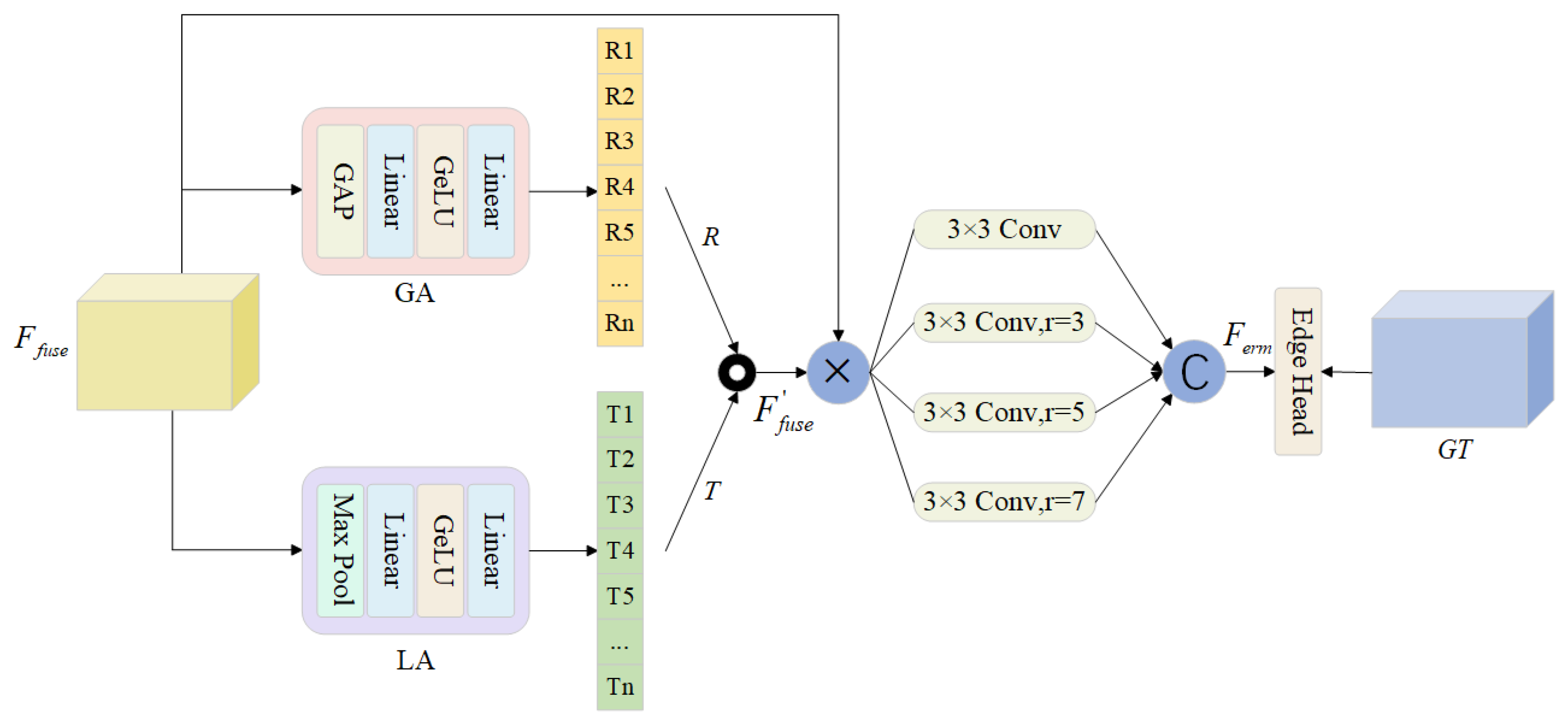
2.2. Edge-Aware Refinement Module
2.3. Loss Function
3. Experimental Results and Analysis
3.1. Datasets and Experimental Metrics
3.2. Comparison of MFNet Dataset
3.3. Comparison of PST900 Datasets
3.4. Comparison of NYUDv2 Datasets
3.5. Computational Complexity Analysis
3.6. Ablation Experiment
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Deng, L.; Yang, M.; Hu, B.; Li, T.; Li, H.; Wang, C. Semantic segmentation-based lane-level localization using around view monitoring system. IEEE Sens. J. 2019, 19, 10077–10086. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Glaeser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep multi-modal object detection and semantic segmentation for autonomous driving: Datasets, methods, and challenges. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1341–1360. [Google Scholar]
- Panda, S.K.; Lee, Y.; Jawed, M.K. Agronav: Autonomous Navigation Framework for Agricultural Robots and Vehicles using Semantic Segmentation and Semantic Line Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 6271–6280. [Google Scholar]
- Lv, C.; Wan, B.; Zhou, X.; Sun, Y.; Hu, J.; Zhang, J.; Yan, C. Cae-net: Cross-modal attention enhancement network for rgb-t salient object detection. Electronics 2023, 12, 953. [Google Scholar] [CrossRef]
- Zhao, Q.; Liu, J.; Wang, J.; Xiong, X. Real-Time RGBT Target Tracking Based on Attention Mechanism. Electronics 2024, 13, 2517. [Google Scholar] [CrossRef]
- Li, J.; Wu, H.; Gu, Y.; Lu, J.; Sun, X. DuSiamIE: A Lightweight Multidimensional Infrared-Enhanced RGBT Tracking Algorithm for Edge Device Deployment. Electronics 2024, 13, 4721. [Google Scholar] [CrossRef]
- Deng, F.; Feng, H.; Liang, M.; Wang, H.; Yang, Y.; Gao, Y.; Chen, J.; Hu, J.; Guo, X.; Lam, T.L. FEANet: Feature-enhanced attention network for RGB-thermal real-time semantic segmentation. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; IEEE: New York, NY, USA, 2021; pp. 4467–4473. [Google Scholar]
- Li, G.; Wang, Y.; Liu, Z.; Zhang, X.; Zeng, D. RGB-T semantic segmentation with location, activation, and sharpening. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1223–1235. [Google Scholar] [CrossRef]
- Wu, W.; Chu, T.; Liu, Q. Complementarity-aware cross-modal feature fusion network for RGB-T semantic segmentation. Pattern Recognit. 2022, 131, 108881. [Google Scholar]
- Zhang, Q.; Zhao, S.; Luo, Y.; Zhang, D.; Huang, N.; Han, J. ABMDRNet: Adaptive-weighted bi-directional modality difference reduction network for RGB-T semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2633–2642. [Google Scholar]
- Sun, Y.; Zuo, W.; Liu, M. RTFNet: RGB-thermal fusion network for semantic segmentation of urban scenes. IEEE Robot. Autom. Lett. 2019, 4, 2576–2583. [Google Scholar] [CrossRef]
- Frigo, O.; Martin-Gaffe, L.; Wacongne, C. DooDLeNet: Double DeepLab enhanced feature fusion for thermal-color semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3021–3029. [Google Scholar]
- Zhou, Z.; Wu, S.; Zhu, G.; Wang, H.; He, Z. Channel and Spatial Relation-Propagation Network for RGB-Thermal Semantic Segmentation. arXiv 2023, arXiv:2308.12534. [Google Scholar]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; IEEE: New York, NY, USA, 2017; pp. 5108–5115. [Google Scholar]
- Shivakumar, S.S.; Rodrigues, N.; Zhou, A.; Miller, I.D.; Kumar, V.; Taylor, C.J. Pst900: Rgb-thermal calibration, dataset and segmentation network. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: New York, NY, USA, 2020; pp. 9441–9447. [Google Scholar]
- Sun, Y.; Zuo, W.; Yun, P.; Wang, H.; Liu, M. FuseSeg: Semantic segmentation of urban scenes based on RGB and thermal data fusion. IEEE Trans. Autom. Sci. Eng. 2020, 18, 1000–1011. [Google Scholar]
- Zhou, W.; Lin, X.; Lei, J.; Yu, L.; Hwang, J.N. MFFENet: Multiscale feature fusion and enhancement network for RGB–Thermal urban road scene parsing. IEEE Trans. Multimed. 2021, 24, 2526–2538. [Google Scholar] [CrossRef]
- Zhou, W.; Liu, J.; Lei, J.; Yu, L.; Hwang, J.N. GMNet: Graded-feature multilabel-learning network for RGB-thermal urban scene semantic segmentation. IEEE Trans. Image Process. 2021, 30, 7790–7802. [Google Scholar] [CrossRef] [PubMed]
- Cai, Y.; Zhou, W.; Zhang, L.; Yu, L.; Luo, T. DHFNet: Dual-decoding hierarchical fusion network for RGB-thermal semantic segmentation. Vis. Comput. 2023, 40, 169–179. [Google Scholar]
- Zhou, H.; Tian, C.; Zhang, Z.; Huo, Q.; Xie, Y.; Li, Z. Multispectral fusion transformer network for RGB-thermal urban scene semantic segmentation. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Dong, S.; Zhou, W.; Xu, C.; Yan, W. EGFNet: Edge-aware guidance fusion network for RGB–thermal urban scene parsing. IEEE Trans. Intell. Transp. Syst. 2023, 25, 657–669. [Google Scholar] [CrossRef]
- Zhou, W.; Gong, T.; Lei, J.; Yu, L. DBCNet: Dynamic bilateral cross-fusion network for RGB-T urban scene understanding in intelligent vehicles. IEEE Trans. Syst. Man, Cybern. Syst. 2023, 53, 7631–7641. [Google Scholar]
- Zhao, S.; Zhang, Q. A Feature Divide-and-Conquer Network for RGB-T Semantic Segmentation. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 2892–2905. [Google Scholar] [CrossRef]
- Liang, W.; Yang, Y.; Li, F.; Long, X.; Shan, C. Mask-guided modality difference reduction network for RGB-T semantic segmentation. Neurocomputing 2023, 523, 9–17. [Google Scholar] [CrossRef]
- Wang, Y.; Li, G.; Liu, Z. SGFNet: Semantic-Guided Fusion Network for RGB-Thermal Semantic Segmentation. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 7737–7748. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Hu, X.; Yang, K.; Fei, L.; Wang, K. Acnet: Attention based network to exploit complementary features for rgbd semantic segmentation. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: New York, NY, USA, 2019; pp. 1440–1444. [Google Scholar]
- Liu, J.; Zhou, W.; Cui, Y.; Yu, L.; Luo, T. GCNet: Grid-like context-aware network for RGB-thermal semantic segmentation. Neurocomputing 2022, 506, 60–67. [Google Scholar]
- Gong, T.; Zhou, W.; Qian, X.; Lei, J.; Yu, L. Global contextually guided lightweight network for RGB-thermal urban scene understanding. Eng. Appl. Artif. Intell. 2023, 117, 105510. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Zhou, W.; Lv, Y.; Lei, J.; Yu, L. Embedded control gate fusion and attention residual learning for RGB–thermal urban scene parsing. IEEE Trans. Intell. Transp. Syst. 2023, 24, 4794–4803. [Google Scholar]
- Lv, Y.; Liu, Z.; Li, G. Context-aware interaction network for rgb-t semantic segmentation. IEEE Trans. Multimed. 2024, 26, 6348–6360. [Google Scholar]
- Yang, J.; Bai, L.; Sun, Y.; Tian, C.; Mao, M.; Wang, G. Pixel difference convolutional network for RGB-D semantic segmentation. IEEE Trans. Circuits Syst. Video Technol. 2023, 34, 1481–1492. [Google Scholar]
- Dong, S.; Zhou, W.; Qian, X.; Yu, L. GEBNet: Graph-enhancement branch network for RGB-T scene parsing. IEEE Signal Process. Lett. 2022, 29, 2273–2277. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | mIoU | Car | Person | Bike | Curve | Car Stop | Guardrail | Color Cone | Bump |
|---|---|---|---|---|---|---|---|---|---|
| PSTNet [15] | 48.4 | 76.8 | 52.6 | 55.3 | 29.6 | 25.1 | 15.1 | 39.4 | 45.0 |
| RTFNet [11] | 53.2 | 87.4 | 70.3 | 62.7 | 45.3 | 29.8 | 0.0 | 29.1 | 55.7 |
| FuseSeg [16] | 54.5 | 87.9 | 71.7 | 64.6 | 44.8 | 22.7 | 6.4 | 46.9 | 47.9 |
| MMDRNet [24] | 56.0 | 85.7 | 70.3 | 61.5 | 46.9 | 32.7 | 7.7 | 48.2 | 53.4 |
| DBCNet [22] | 56.2 | 87.4 | 73.6 | 62.9 | 47.1 | 33.8 | 6.8 | 50.9 | 45.4 |
| FDCNet [23] | 56.3 | 87.5 | 72.4 | 61.7 | 43.8 | 27.2 | 7.3 | 52.0 | 56.6 |
| MFFENet [17] | 57.1 | 88.2 | 74.1 | 62.9 | 46.2 | 37.1 | 7.6 | 52.4 | 47.4 |
| GMNet [18] | 57.3 | 86.5 | 73.1 | 61.7 | 44.0 | 42.3 | 14.5 | 48.7 | 47.4 |
| DHFNet [19] | 57.2 | 87.6 | 71.7 | 61.1 | 39.5 | 42.4 | 9.5 | 49.3 | 56.0 |
| MFTNet [20] | 57.3 | 87.9 | 66.8 | 64.4 | 47.1 | 36.1 | 8.4 | 55.5 | 62.2 |
| DooDLeNet [12] | 57.3 | 86.7 | 72.2 | 62.5 | 46.7 | 28.0 | 5.1 | 50.7 | 65.8 |
| EGFNet [21] | 57.5 | 89.8 | 71.6 | 63.9 | 46.7 | 31.3 | 6.7 | 52.0 | 57.4 |
| SGFNet [25] | 57.6 | 88.4 | 77.6 | 63.4 | 45.8 | 31.0 | 6.0 | 57.1 | 55.0 |
| CCFFNet [9] | 57.6 | 89.6 | 74.2 | 63.1 | 50.5 | 31.9 | 4.8 | 49.7 | 56.3 |
| Ours | 58.5 | 87.8 | 71.2 | 63.6 | 47.0 | 29.7 | 10.8 | 53.4 | 64.6 |
| Model | mIoU | Background | Fire-Extinguisher | Backpack | Hand-Drill | Survivor |
|---|---|---|---|---|---|---|
| UNet [30] | 52.80 | 98.00 | 43.00 | 52.90 | 38.30 | 31.60 |
| RTFNet [11] | 57.60 | 98.90 | 52.00 | 75.30 | 25.40 | 36.40 |
| CCNet [26] | 61.42 | 99.05 | 51.84 | 66.42 | 32.27 | 57.50 |
| PSTNet [15] | 68.40 | 98.90 | 70.10 | 69.20 | 53.60 | 50.00 |
| ABMDRNet [10] | 71.30 | 99.00 | 66.20 | 67.90 | 61.50 | 62.00 |
| ACNet [27] | 71.81 | 99.25 | 59.95 | 83.19 | 51.46 | 65.19 |
| MMDRNet [24] | 74.50 | 98.90 | 52.40 | 71.10 | 40.60 | 62.30 |
| FDCNet [23] | 77.11 | 99.15 | 71.52 | 72.17 | 70.36 | 72.36 |
| DBCNet [22] | 81.78 | 99.40 | 72.95 | 82.67 | 76.68 | 77.19 |
| CCFFNet [9] | 82.10 | 99.40 | 79.90 | 75.80 | 82.80 | 72.70 |
| DHFNet [19] | 82.19 | 99.44 | 78.15 | 87.34 | 71.18 | 74.81 |
| GCNet [28] | 82.58 | 99.35 | 77.68 | 79.37 | 82.92 | 73.58 |
| SGFNet [25] | 82.80 | 99.40 | 75.60 | 85.40 | 76.70 | 76.70 |
| GCGLNet [29] | 83.24 | 99.39 | 77.57 | 81.01 | 81.90 | 76.31 |
| GMNet [18] | 84.12 | 99.44 | 73.79 | 83.82 | 85.17 | 78.36 |
| Ours | 85.38 | 99.59 | 80.55 | 85.90 | 83.74 | 77.14 |
| Models | mIoU |
|---|---|
| RTFNet [11] | 49.1 |
| ECGFNet [31] | 51.5 |
| CAINet [32] | 52.6 |
| PDCNet [33] | 53.5 |
| Ours | 53.8 |
| Models | FLOPs/G | Params/M | mIoU |
|---|---|---|---|
| FuseSeg [16] | 142.22 | 100.11 | 54.5 |
| CCFFNet [9] | 527.48 | 109.05 | 57.6 |
| GEBNet [34] | 216.38 | 126.18 | 56.2 |
| Ours | 203.86 | 147.35 | 58.5 |
| Baseline | Type | ERM | FFM | mIoU |
|---|---|---|---|---|
| ✔ | RGB | × | × | 53.43 |
| ✔ | RGB-T | ✔ | × | 57.82 |
| ✔ | RGB-T | × | ✔ | 55.37 |
| ✔ | RGB-T | ✔ | ✔ | 58.52 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, M.; Zhu, Z.; Wang, Y.; Tu, R.; Weng, J.; Yu, X. Edge-Supervised Attention-Aware Fusion Network for RGB-T Semantic Segmentation. Electronics 2025, 14, 1489. https://doi.org/10.3390/electronics14081489
Wang M, Zhu Z, Wang Y, Tu R, Weng J, Yu X. Edge-Supervised Attention-Aware Fusion Network for RGB-T Semantic Segmentation. Electronics. 2025; 14(8):1489. https://doi.org/10.3390/electronics14081489
Chicago/Turabian StyleWang, Ming, Zhongjie Zhu, Yuer Wang, Renwei Tu, Jiuxing Weng, and Xianchao Yu. 2025. "Edge-Supervised Attention-Aware Fusion Network for RGB-T Semantic Segmentation" Electronics 14, no. 8: 1489. https://doi.org/10.3390/electronics14081489
APA StyleWang, M., Zhu, Z., Wang, Y., Tu, R., Weng, J., & Yu, X. (2025). Edge-Supervised Attention-Aware Fusion Network for RGB-T Semantic Segmentation. Electronics, 14(8), 1489. https://doi.org/10.3390/electronics14081489