4.1. Dataset Preparation
In this section, we present the Hard Defect Classification Dataset (HDCD), a comprehensive dataset designed to address the challenges of real-world bridge defect recognition. The HDCD was constructed through a multi-source data collection strategy, incorporating high-resolution images captured under diverse environmental conditions. The images were acquired using professional-grade equipment, including Leica cameras, to ensure high-quality visual data [
40]. While the dataset primarily focuses on concrete bridges, it also incorporates a strategic selection of other bridge types (steel and composite structures) to enhance generalization. The collection process involved systematic sampling of bridge surfaces, where images were captured at varying angles, distances, and lighting conditions to reflect the complexity of real-world inspection scenarios. To maximize data utility while addressing potential limitations in bridge-type diversity, all defect areas were extracted using multi-scale rectangular cropping prior to dataset construction. This approach not only augmented sample diversity through variable aspect ratios and spatial contexts but also effectively transformed single-source images into multiple training instances, thereby mitigating concerns about structural homogeneity. The cropping parameters were carefully optimized to preserve defect integrity while introducing meaningful variations in background content and scale.
To ensure a representative and challenging dataset, we employed a stratified sampling approach to partition the data into training and test sets. The training set consisted of high-quality, well-lit images, enabling the model to learn robust feature representations. In contrast, the test set was specifically curated to include hard samples, which were artificially modified to simulate challenging conditions. These modifications ensure that the test set accurately represents the variability encountered in practical industrial inspections.
The dataset’s class imbalance arises from the inherent variability in defect occurrence rates in real-world bridge structures. For instance, cracks and efflorescence are more frequently observed due to their association with common degradation mechanisms, while defects like scaling or spalling are less prevalent. This imbalance reflects the natural distribution of defects in civil infrastructure and ensures that the dataset aligns with practical inspection scenarios. By integrating diverse data sources and emphasizing challenging conditions, the HDCD provides a robust benchmark for evaluating defect classification methods under realistic constraints.
In practical industrial environments, we observe that images captured by drones often display significant variability and are frequently affected by six challenging conditions (the samples are shown in
Figure 6), making classification considerably more difficult than in existing industrial defect datasets:
- (1)
Darkened, where defects are obscured due to insufficient lighting or shadows, reducing visibility.
- (2)
Noisy, which contain substantial interference from environmental factors such as texture patterns or imaging artifacts.
- (3)
Faint Targets, where the defects are subtle and lack clear boundaries, making them difficult to distinguish from the surrounding material.
- (4)
Overexposed, resulting from excessive lighting, which leads to the loss of critical defect details.
- (5)
Blurry, caused by motion blur or focus issues during image capture, distorting the appearance of defects.
- (6)
Occluded, where defects are partially hidden by other structures or objects, complicating their identification.
As illustrated in
Table 1, our HDCD encompasses six image categories: crack, efflorescence, general, no defect, scaling, and spalling, with a total of 2418 images.
4.2. Implementation Details
For our challenging sample set, all categories except the unprocessed faint targets underwent manual secondary processing with reality-matching parameter adjustments: darkened images were generated through channel-wise multiplication with a darkness factor of 0.2 to reduce luminance; noisy samples incorporated additive Gaussian noise via np.random.normal at severity level 1; overexposed variants were created using ImageEnhance with a contrast amplification factor of 1.5; blurry images employed Gaussian blurring through cv2 with a 5 × 5 kernel; and occluded samples introduced random rectangular masks by zeroing pixel values.
Our proposed framework PPLF was implemented using PyTorch. All experiments were conducted on an NVIDIA 3060 GPU with 32 GB of memory. The model was implemented in Python 3.8 using PyTorch 1.10. The input query images were passed through three backbones: ResNet-50, EfficientNetV2-L, and ViT. All models were pre-trained on ImageNet, with ViT (base model p16) fine-tuned on ImageNet-21k. The input image size for all models was set to 224 × 224. Feature map dimensions extracted from the backbones were as follows: (a) ResNet-50: 2048 × 1 × 1 (channels, width, length), (b) EfficientNetV2-L: 1280 × 1 × 1, (c) ViT: 768 × 1 × 1. We trained ResNet-50 and EfficientNetV2-L for 100 epochs using the Adam optimizer, while ViT was trained with AdamW. The learning rate for all models was set to 0.001. After training, we loaded the optimal model parameters and tested them for 10 epochs on the test set.
For the loss function, during the backbone training stage, we used cross-entropy loss. In the overall framework training stage, we experimented with Label Smoothing Loss, which achieved an accuracy of 57.96%. However, the best performance was obtained using Mean Squared Error (MSE), achieving an accuracy of 60.51%.
For data augment, we used RandAugment with the parameters N = 4 (number of augmentation operations) and M = 9 (global magnitude), which provided the most satisfactory results.
4.3. The Effectiveness of Our Approach
The purpose of this experiment was to evaluate the effectiveness of our proposed PPLF. First, we assessed the performance of several widely used baseline models on our HDCD. We primarily selected three models: EfficientNetV2-L, ResNet-50, and ViT [
41] as backbones, which represent diverse architectural paradigms (e.g., convolutional networks, residual learning, and transformer-based models). Furthermore, most existing concrete-defect-detection methods employ these models as a backbone [
42,
43,
44,
45], suggesting that they are recognized as valid for texture-level classification. To ensure fairness and comparability, we applied consistent data preprocessing procedures and evaluation criteria across all models. After loading the pre-trained optimal parameters for each backbone, we integrated our PPLF with the frozen backbones and conducted further training and testing.
Table 2 presents the comparative results of baseline models with and without our PPLF, evaluated through accuracy and macro-F1 score. The suboptimal performance of the baseline models on the HDCD highlights the inherent challenges of classifying bridge defect images, particularly due to their texture-level characteristics. Unlike high-level semantic features, texture-level defects such as cracks, spalling, and corrosion often exhibit subtle and irregular patterns, making them difficult to distinguish even for state-of-the-art models. This complexity is further exacerbated by real-world conditions such as lighting variations, occlusions, and background noise, which are prevalent in our test dataset.
The integration of PPLF consistently improved performance across all models, with ResNet-50 achieving the most substantial gain, increasing accuracy from 53.51% to 60.51%. This significant improvement can be attributed to the synergistic interaction between ResNet-50’s residual blocks and PPLF’s design. The architectural design of ResNet-50, characterized by hierarchical convolutional layers and residual skip connections, demonstrates a strong capability to capture local texture features, making it particularly effective for identifying the fine-grained and spatially localized patterns inherent in bridge defect imagery. PPLF enhances this alignment by prompt learning and feature fusion.
In contrast, ViT exhibited more modest gains, with accuracy increasing from 46.51% to 48.96%. ViT relies on self-attention mechanisms to model global dependencies between image patches. While this design excels in capturing high-level semantic relationships, it introduces two critical challenges for texture-level defect classification. First, the self-attention operation computes pairwise interactions between all patches, which may dilute the focus on localized defect regions (e.g., cracks spanning only 5–10 pixels). Second, ViT’s patch embedding layer imposes a rigid grid structure on input images, potentially disrupting subtle texture patterns that require sub-patch granularity. These architectural constraints are exacerbated by the limited scale of the HDCD, as transformers typically require pretraining on large datasets to stabilize gradient updates in attention layers. Consequently, even with data augmentation in PPLF, which enhances sample diversity through geometric and photometric transformations, ViT struggles to converge on discriminative features for fine-grained defects.
Meanwhile, EfficientNetV2-L’s accuracy in the HDCD improved from 50.31% to 54.21%. It employs compound scaling to balance depth, width, and resolution, optimizing computational efficiency through depthwise separable convolutions. However, this design reduces the capacity for hierarchical feature fusion, a key component of PPLF. Specifically, PPLF operates by aligning intermediate convolutional features with prototype vectors learned from defect patterns, a process that benefits from rich multi-scale representations. In EfficientNetV2-L, the depthwise convolution layers generate spatially sparse feature maps, limiting the granularity of prototype matching. Additionally, the model’s heavy reliance on squeeze-and-excitation modules prioritizes channel-wise attention over spatial localization, which conflicts with PPLF’s emphasis on defect-specific spatial prototypes.
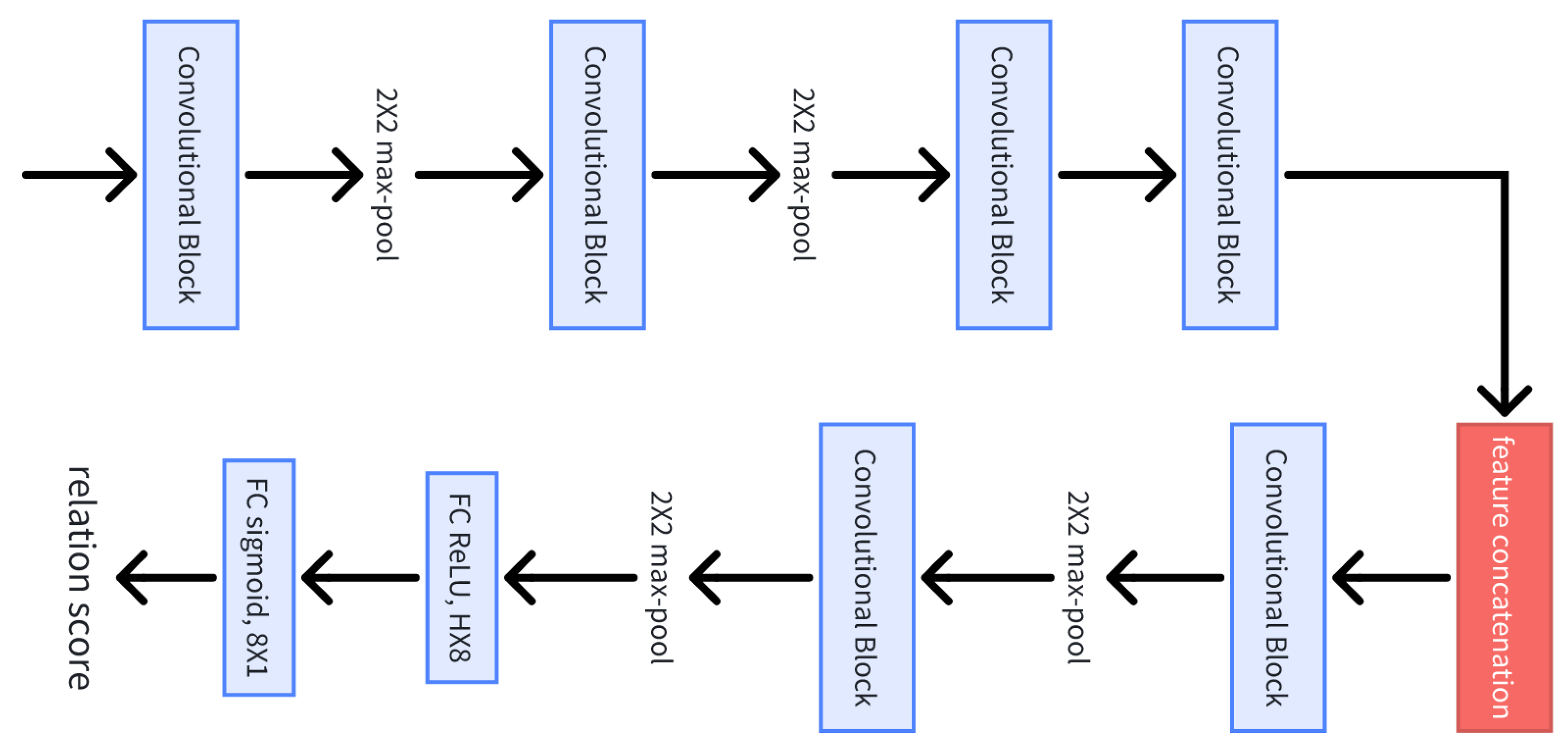
Table 3 presents the inference times of each model on our HDCD, benchmarked on an NVIDIA RTX 3060 GPU (32 GB memory). ResNet50 demonstrated the shortest inference time and training time while simultaneously achieving the highest metric performance in
Table 2. These results collectively indicate that ResNet-50’s local feature extraction capability provides the optimal balance for PPLF implementation. While ViT’s global attention mechanisms and EfficientNetV2-L’s parameter efficiency present alternative approaches, PPLF maintains strong generalizability across all backbones, highlighting its robustness for texture-level defect classification.
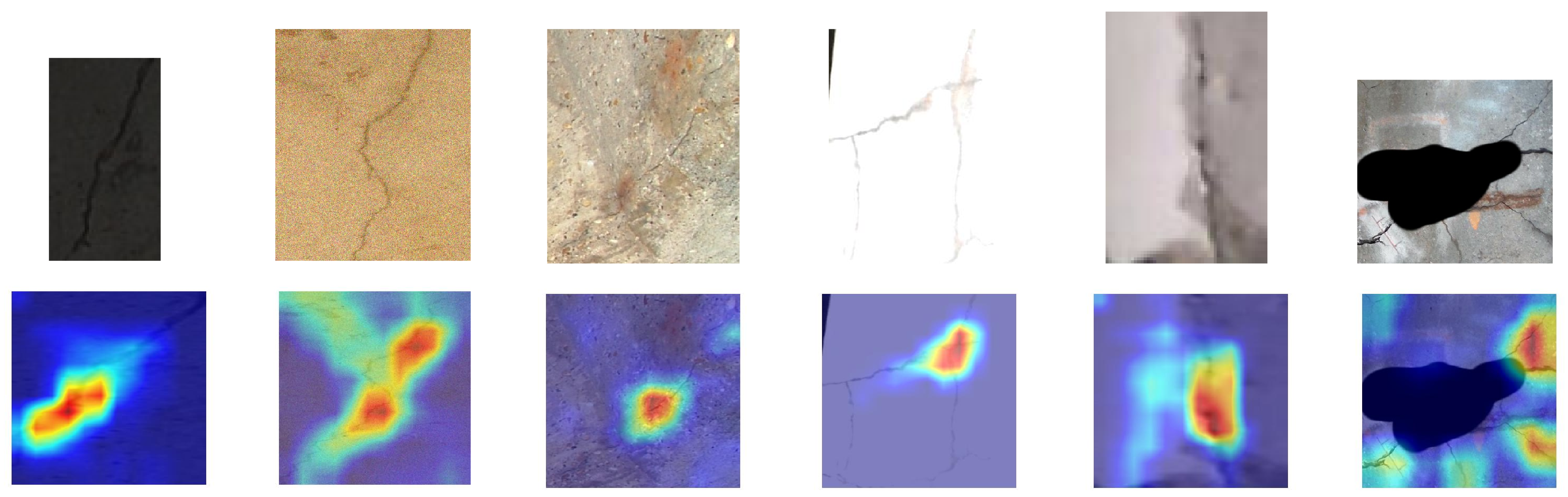
Figure 7 presents Grad-CAM visualizations of PPLF’s attention under six challenging conditions: darkened, noisy, faint targets, overexposed, blurry, and occluded. Using crack samples as representative cases, the results demonstrate PPLF’s consistent ability to localize defects accurately across all scenarios.
Although our model initially improves accuracy on hard samples, our dataset remains relatively small, containing only 2418 images. This is sparse compared to standard image classification datasets like ImageNet or CUB. And since defects are distributed in bridges with different degrees of commonness, some defects will be more prevalent, such as cracks, resulting in a varying number of images per category, which exacerbated the difficulty of our experiment. By analyzing the performance across precision, recall, and macro-F1 metrics, we observed variability in the results of our PPLF framework (using ResNet-50 as the backbone) for different defect categories; the results are shown in
Table 4.
The
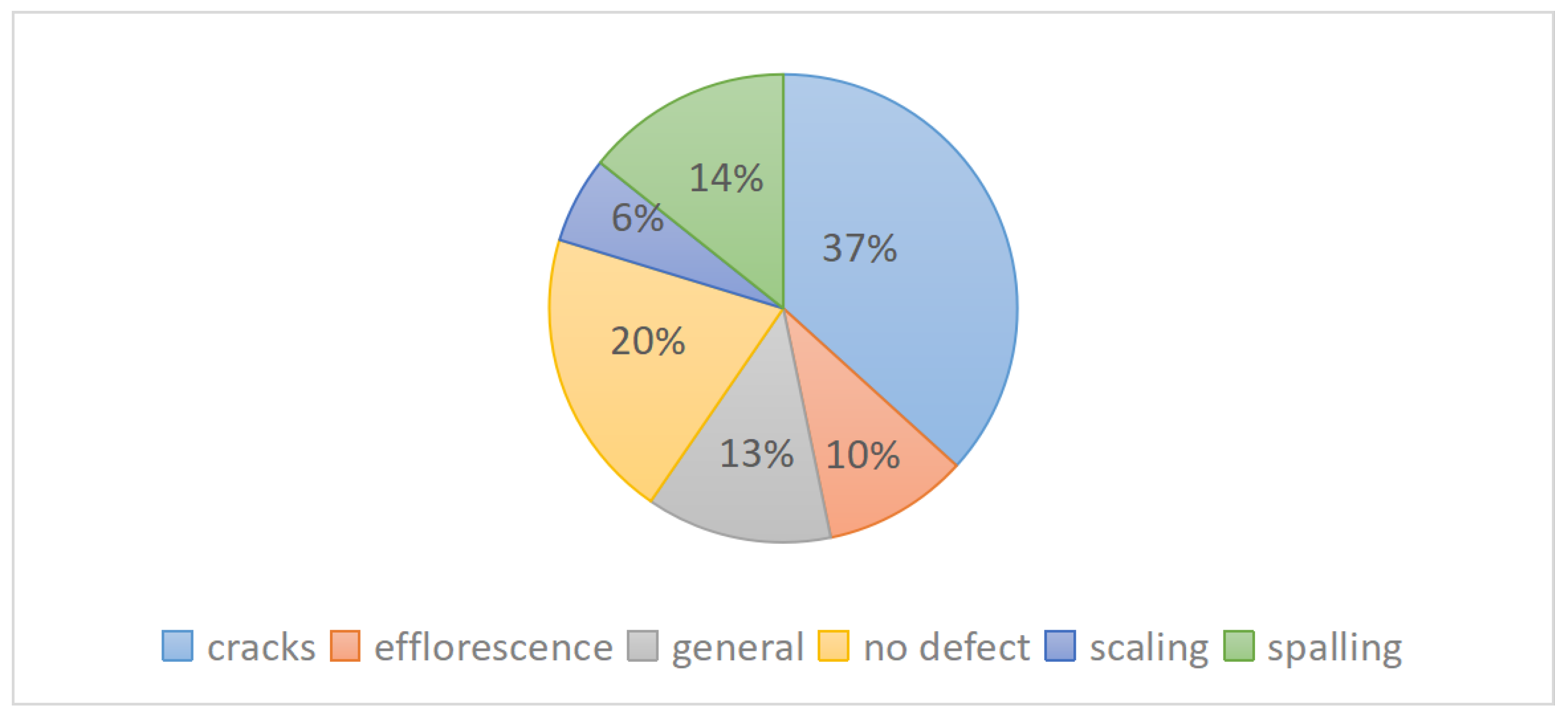
crack category exhibited the highest recall of 0.88, which means that the framework was able to identify 88% of the actual crack samples. This high recall is largely due to ResNet-50’s convolutional layers, which excel at capturing local linear patterns—a key characteristic of cracks. PPLF further enhances this capability by aligning intermediate features with prototype vectors representing crack textures, enabling robust localization even under noisy conditions. However, the precision of 0.55 suggests that only 55% of the samples predicted as cracks were actually cracks. Considering that the number of training sets for the crack category was 627, which was the largest number relative to the other categories as shown in
Figure 8, it is likely that the model was overfitted during training for this category. This phenomenon arises because, during training, the model is exposed to a disproportionately large number of features in the crack compared to other samples. As a result, it may incorrectly classify other defects as cracks. In essence, the model for this category may have learned not only the meaningful patterns in the data but also the noise and random fluctuations, which are irrelevant and non-informative. The F1 score for the crack category was 0.68, which is a combination of precision and recall. Specifically, a high F1 score means that the model neither misses too many cracks that are actually present when predicting cracks (high recall), nor incorrectly identifies too many non-cracks as cracks (relatively high precision). This balance is especially important for crack classification, since too many false positives can lead to unnecessary inspections and repairs, while missed inspections can pose a safety hazard.
The Efflorescence category achieved the highest precision of 0.80, demonstrating the model’s ability to accurately identify efflorescence with 80% confidence. This high precision can be attributed to the unique visual characteristics of efflorescence (e.g., white, powdery appearance), which make it easier for ResNet-50’s hierarchical feature extraction to distinguish it from other defects. PPLF’s prototype vectors further enhance this capability by learning discriminative representations of efflorescence patterns. Conversely, the model performed poorly on the scaling category, particularly in recall, indicating that many actual scaling samples were missed. This underperformance can be attributed to the limited representation of scaling in the training data, preventing the model from learning sufficient information about this category.
4.4. Ablation Study
To validate the design choices of our method and model components for optimal efficiency and accuracy, we conducted ablation studies on the HDCD using ResNet-50 as the backbone network. The results presented in
Table 5 demonstrate that each proposed module contributes significantly to overall performance improvement.
The baseline model achieved a macro-F1 score of 48.69%, accompanied by a moderate accuracy at 53.90% and precision at 52.42%. This suboptimal performance highlights ResNet-50’s limitations in processing complex texture-level defects, particularly when distinguishing subtle inter-class variations such as cracks versus spalling or handling intra-class diversity like efflorescence patterns. These challenges demand finer-grained feature discrimination capabilities.
The introduction of the FFC elevated the average accuracy to 55.15% and macro-F1 to 50.18%. This component overcomes the backbone’s constraints by computing pairwise affinity matrices between feature maps from different convolutional stages. The accuracy gains confirm its capacity for resolving ambiguous cases through relational reasoning.
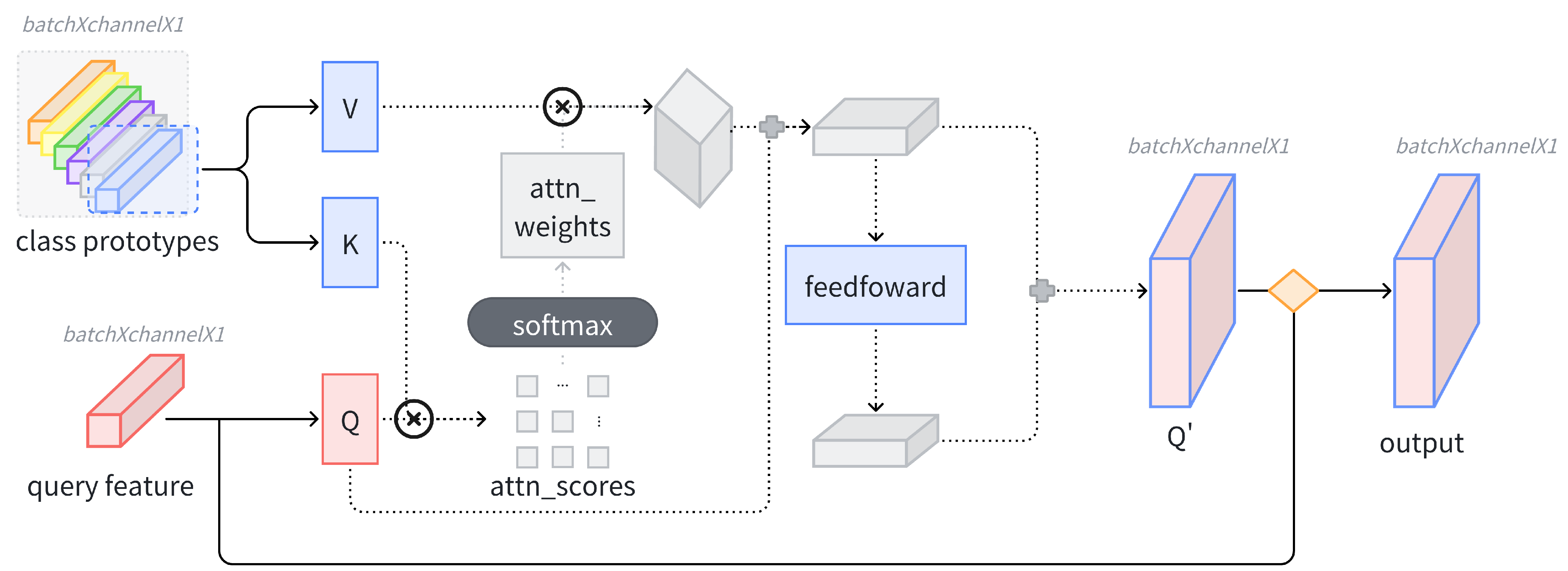
Further performance enhancements came from the CERM-enhanced FFC, which raised macro-F1 to 53.49% and average accuracy to 58.87%. This module dynamically integrates low-level texture features with high-level semantic embeddings. Such integration enables focused attention on discriminative local regions while filtering out irrelevant background noise. The concurrent improvement in both precision and recall metrics demonstrates the module’s dual capability to boost prediction confidence through context-aware localization while maintaining comprehensive defect coverage.
The ablation studies verify that both the FFC and CERM are indispensable. The former injects explicit relational inductive biases, while the latter enables hierarchical feature refinements. Together, they address the backbone’s limitations in texture-level defect classification.
4.5. Data Augmentation
According to
Section 4.3, although our framework achieved good success, some problems with the data led to poor categorization results. Data augmentation is a technique for expanding a training set by creating variants of the original data, which increases data diversity through geometric transformations, color adjustments, noise injection, etc. Appropriate data enhancement methods can effectively solve the overfitting phenomenon of our model on cracks due to the problem of unbalanced datasets.
The comparison results are presented in
Table 6. None refers to the method in
Table 5 that uses ResNet-50 as the backbone and includes only the FFC and CERM. The data augmentation methods we employed include the following: (1) RandomErasing, which improved the accuracy to 60.51% by simulating occlusions (e.g., dirt, shadows) through random rectangular masking [
46]. (2) Cutmix&Mixup: CutMix [
47] and Mixup [
48] are two popular data augment methods, both of which improve the generalization ability and robustness of a model by image blending and label interpolation. They had a limited efficacy (54.40% macro-F1), stemming from their semantic-level blending strategies, which conflict with texture-level defect detection. (3) BSR (Block Shuffle and Rotation), a novel input transformation-based attack [
49]. BSR’s block shuffle and rotation introduces structured chaos by rearranging image regions, theoretically encouraging global context learning. In BSR (all), we quadrupled the entire dataset, which led to performance improvements but significantly increased training time with an accuracy of 59.46%. To optimize further, we focused on augmenting only the efflorescence and scaling categories, which had the fewest training samples. This approach yielded a slightly better accuracy (60.13%) than BSR (all). These methods inadvertently corrupt the discriminative texture features that PPLF’s prototype vectors rely on, explaining their suboptimal performance despite improving generalization in conventional classification tasks. However, façade defect classification relies more on texture, reducing their effectiveness. (4) TrivialAugmentWide’s random policy selection with a 59.00% accuracy introduces uncontrolled variations, such as extreme color jittering or over-rotation, which distorts subtle texture patterns [
50]. (5) RandAugment achieved the highest accuracy, 60.51%, and macro-F1, 59.89%, by striking an optimal balance between diversity and consistency. It has two parameters: the number of enhancement operations
N and a global enhancement magnitude
M. By tuning the parameters, we finally found the most suitable parameters for our dataset and method to achieve the highest accuracy rate. (6) The combination of RandAugment and BSR (all) achieved only marginal improvements, with a 60.08% accuracy, as BSR’s spatial fragmentation counteracts RandAugment’s carefully calibrated transformations. This antagonism highlights the importance of a coherent augmentation design—strategies must complement rather than conflict with each other and the model’s inductive biases. Based on their performance, we ultimately integrated RandAugment as the data augmentation method into our PPLF.
In fact, we also made some substitutions and attempts in the FFC module and the CERM, such as replacing the CERM with the FMRM module to bi-directionally refactor prototype vectors and query vectors [
51], bridging two cross-attentions, etc. These supplementary experiments are detailed in
Table 7. Some module combinations also yielded good results, but the framework was ultimately designed to prioritize the combination with the best overall performance.
The combination of the dual CERM with the FFC achieved an accuracy of 59.39% and macro-F1 of 52.78%. While this configuration improved over the baseline (+5.49% accuracy), its suboptimal F1 score suggests that stacking multiple CERM layers introduces feature redundancy. Specifically, the first CERM module refines low-level texture features by focusing on defect regions. The second CERM module, however, over-suppresses non-defective background regions, inadvertently removing contextual cues needed for inter-class relationship modeling in RelationNet. This tension between localized refinement and global dependency modeling explains the lower macro-F1 compared to configurations with fewer attention layers. The FMRM combined with the FFC achieved the highest accuracy but the lowest macro-F1 among the tested combinations. We hypothesize that FMRM operates by generating multi-scale feature representations, which improve the localization of texture anomalies. However, its recalibration mechanism, likely involving channel-wise reweighting, over-emphasizes high-frequency texture details, conflicting with RelationNet’s goal of learning smooth inter-class dependencies. Their full combination achieved a 60.03% accuracy and 52.22% macro-F1. FMRM prioritizes multi-scale feature multiplicity, which generates noisy intermediate representations. The CERM attempts to filter this noise but struggles to reconcile the conflicting goals of local refinement and global recalibration. RelationNet’s dependency graphs are, thus, trained on inconsistent features, limiting their ability to model robust inter-class relationships.
The FFC and CERM exhibit natural synergy—the former models global dependencies, while the latter refines local features. However, adding redundant or conflicting modules disrupts this balance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}





