1. Introduction
Knowledge graphs (KGs) are large-scale semantic networks with entities or concepts as nodes and various semantic relationships between nodes as edges. Building on traditional knowledge graphs, multimodal knowledge graphs (MKGs) integrate images, text, and other modal data, synthesizing text information with other modal information to provide a more comprehensive representation of entities and relational links in the real world. Knowledge graphs have been widely used in numerous intelligent systems, including natural language understanding, information retrieval, recommendation systems, and question-answering systems [
1,
2]. As data modalities become increasingly diverse, traditional unimodal knowledge graphs can no longer meet user needs. Compared with unimodal knowledge graphs, multimodal knowledge graph embedding can obtain richer semantic information. In downstream applications, a complete and accurate multimodal knowledge graph can provide richer semantic information, thus enhancing the performance and effectiveness of these applications [
3,
4]. Multimodal knowledge graph link prediction, on the other hand, is an important method to effectively mine potential knowledge and improve the multimodal knowledge graph.
Translation models, tensor decomposition, convolutional neural networks, and graph neural networks and their extensions are widely used in multimodal link prediction problems [
5,
6]. However, these embedding-based prediction methods, which generalize to similar data samples for prediction through the learning of statistical regularities in the training data, are only able to accomplish shallow reasoning and are unable to cover the full range of logical deductive capabilities, which results in deterioration of the model itself in terms of explainability. In areas where system decisions have a significant impact, such as the financial and healthcare industries [
7], the non-explainability of neural networks has a large impact on prediction results and associated backtracking. In-depth investigation and understanding of how models can effectively integrate and utilize diverse modal information interpret results by using a variety of modal information to provide a more multidimensional basis for interpretation of the final output. Building trust between users and inference models is of critical importance to significantly improve the credibility of the models as well as to enhance the trust of the users [
8]. Therefore, interpretation of multimodal knowledge graph link predictions should be based on the information in the knowledge graph and the properties of the multimodal data to provide a post hoc rational explanation of the model’s prediction decisions.
Multimodal knowledge graph link prediction uses known entities and relationships in the graph, along with multimodal features such as textual descriptions, images, and other relevant features, to predict missing triples. When different modal information contains more comprehensive information needed for link prediction, the use of multimodal features not only enriches the semantic information of entities and relations but also significantly improves the accuracy of link prediction. Relevant studies have shown that multimodal models exhibit obvious advantages in link prediction evaluation indexes compared to models relying only on single modal information [
9,
10]. This fully demonstrates that effective integration of multimodal features can obtain more accurate prediction results. At present, multimodal knowledge graph link prediction models are mainly divided into two categories: the transformer-based model [
11,
12,
13,
14] and the embedding-based model [
15,
16,
17,
18]. The transformer-based multimodal link prediction model processes and fuses multimodal data by utilizing the transformer architecture. The model extracts the respective features through different modal encoders and computes symmetric hybrid key-values for these features using the transformer’s self-attention mechanism, thus effectively capturing the interactions and dependencies between different modalities and improving the accuracy and robustness of link prediction. Transformer-based models usually contain a large number of parameters, and their training and inference processes usually require significant computational resources. Embedding-based link prediction models, which have advantages in terms of structural simplicity, feature representation intuition, and computational efficiency, make them more suitable for post hoc explanations. Compared with transformer-based models, the complex structure and large number of parameters of transformer models make it very difficult to understand their decision-making processes. The training and inference processes of transformer models require significant computing resources, which to some extent limits their interpretability in practical applications. Therefore, we choose an embedding-based link prediction model for explanation.
In the context of multimodal data fusion and complex reasoning scenarios, multimodal link prediction models have achieved rapid development, driven by increased computational power and the growth of massive datasets. However, this progress has also brought several challenges, such as high computational complexity, potential redundancy in multimodal data, and difficulties in acquiring high-quality multimodal data. Additionally, the application of multimodal information further complicates the task of explaining the models’ black-box characteristics. Interpretable link prediction models have emerged, and the current research directions are mainly categorized into two types: ante hoc and post hoc explanation [
19]. Ante hoc explanation involves designing link prediction models that are inherently explainable, and the models are no longer black boxes. Post hoc explanation is used to explain the black-box link prediction model after the fact, meaning that although the model is a black box, its predictions can be understood using post hoc explanation techniques. Ante hoc explanation models are usually chosen from self-interpreting models with a transparent structure and that are easy to understand, such as decision trees and logic rules [
20,
21,
22,
23], but they usually fail to achieve excellent prediction performance and scale to complex knowledge graphs. Post hoc explanation methods can be applied to a variety of complex models with high flexibility, so in this paper, we performed post hoc interpretation of embedding-based multimodal knowledge graph link prediction models.
Most of the existing work on predictive interpretation of knowledge graph links focuses on unimodal analysis, which mainly utilizes the structural information within the knowledge graph, such as node neighbor relationships and path characteristics, for model interpretation [
24]. Although unimodal interpretation methods have achieved significant results in specific scenarios, they have limitations in dealing with multimodal data. Multimodal data contain more information and more complex association patterns, and the complementarity between different modalities provides new perspectives and possibilities for link prediction interpretation. Therefore, the importance of multimodal interpretation in knowledge graph link prediction is becoming increasingly prominent. Therefore, this paper proposes a multi-granularity interpretation method for the task of multimodal knowledge graph link prediction, which is used to interpret the results of multimodal knowledge graph link prediction after the fact and to analyze and interpret the results of multimodal knowledge graph link prediction in terms of modal global and local features. The main contributions of this paper are as follows:
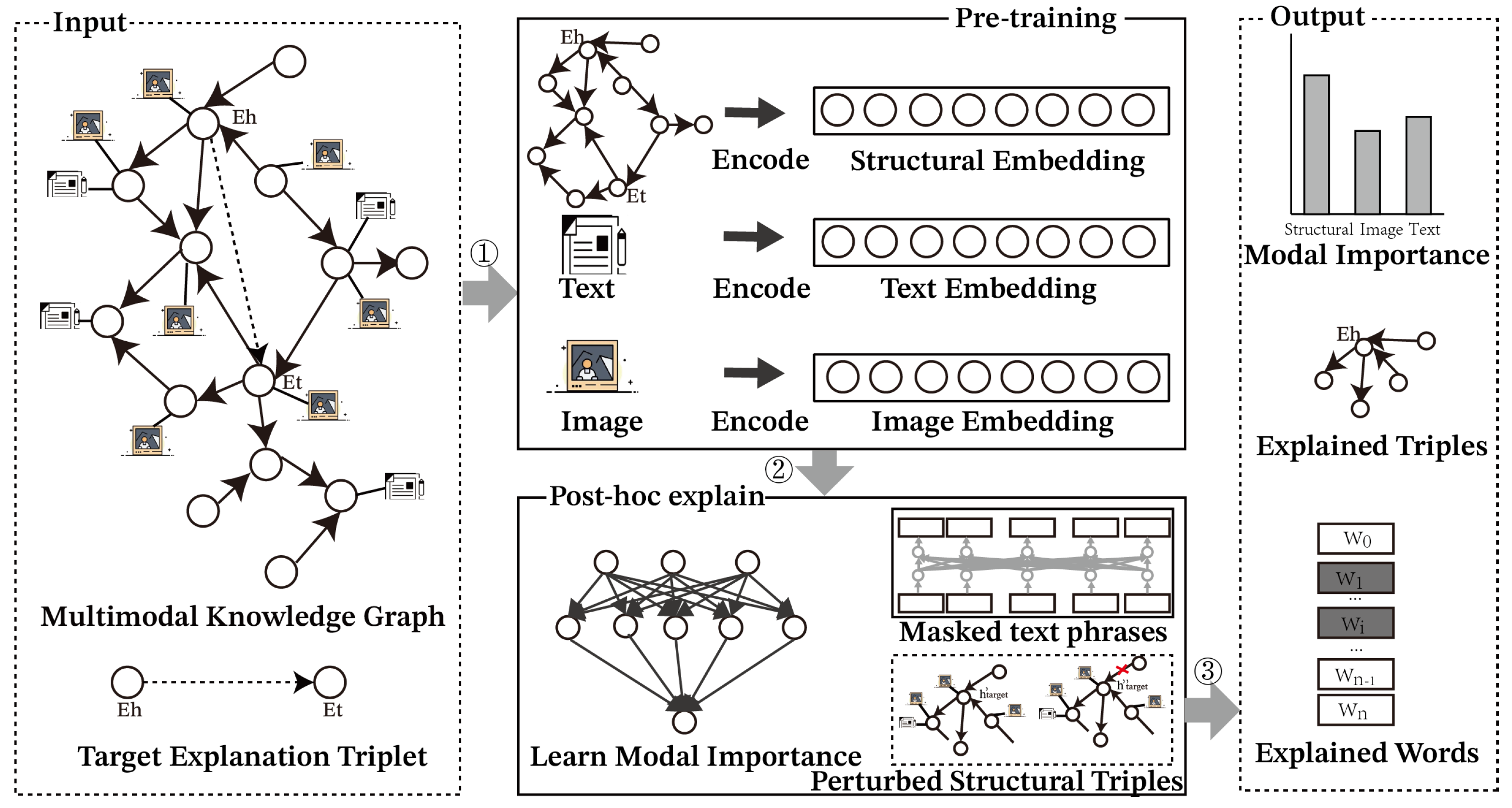
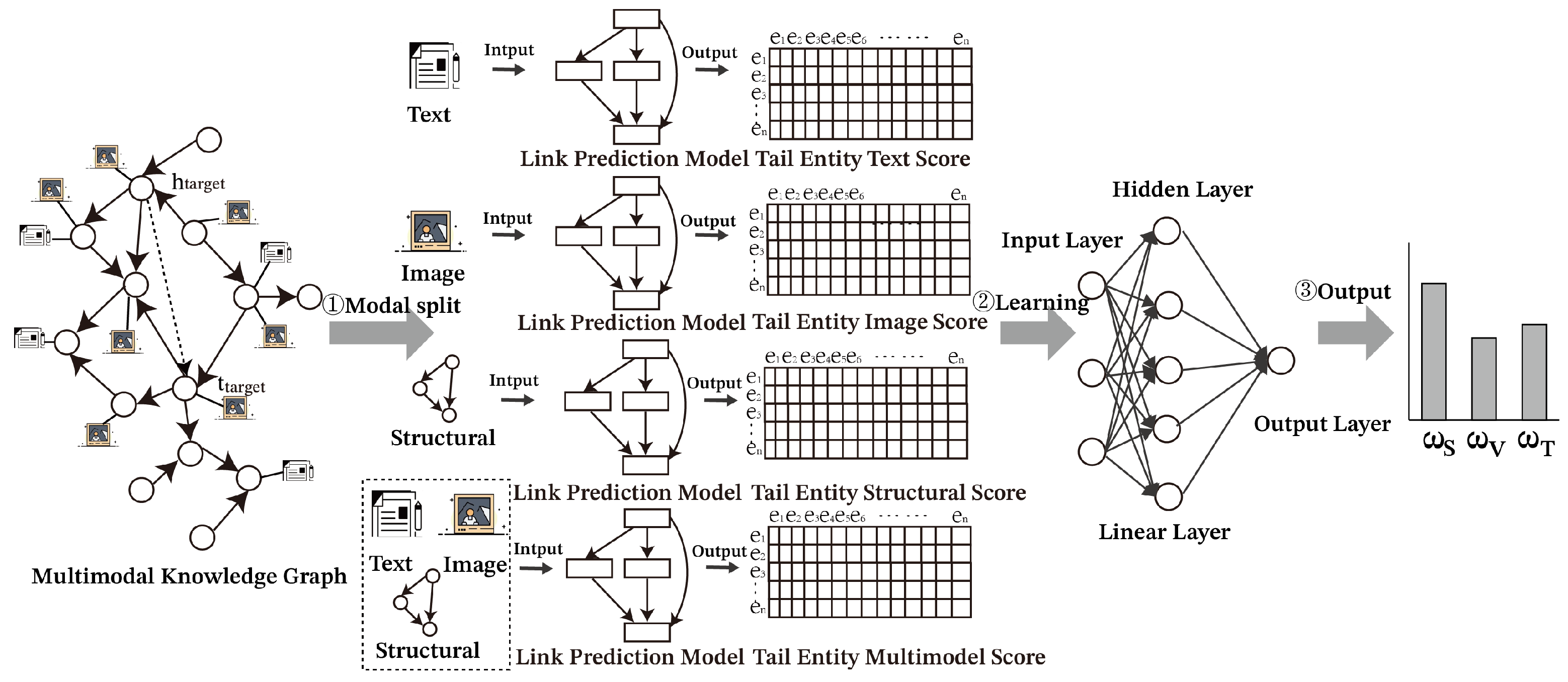
(1) We propose a post hoc model-independent interpretation method for multimodal knowledge graph-linked prediction models. Learning the importance of each modality through modal separation provides coarse-grained interpretation at the modal level.
(2) We propose a textual semantic enhancement heuristic search algorithm to reduce the number of candidate interpretation triples by introducing entity textual semantic information to guide the search process, and we refine a multimodal evaluator to quantitatively assess the predictive relevance of the explored interpretations, thus improving the interpretation efficiency and providing the model with fine-grained interpretations of important triples in structural modalities.
(3) We provide the model with fine-grained lexical interpretations in textual modalities by performing mask learning on entity text descriptions to find the words that have the greatest impact on the target prediction results. Experimental results on four multimodal knowledge graph-generalized datasets demonstrate the effectiveness of the approach in obtaining meaningful multi-granularity interpretations.
To describe our approach, we first present related work in
Section 2, formalize the problem in
Section 3, and define our solution in
Section 4.
Section 5 presents extensive experiments on four generic link prediction knowledge graphs. Finally, we draw conclusions and discuss future work in
Section 6.
2. Related Work
Embedding-based methods are important technical solutions in multimodal link prediction tasks. Embedding-based methods usually employ various embedding techniques, such as text embedding and image embedding, to convert data from different modalities into a unified vector space. These embedding vectors are then utilized to compute the similarity between different entities, thus inferring the possible linking relationships between them. According to the stage of fusion, it is divided into early feature fusion and late decision fusion.
Early feature fusion models mapped entities and relationships, along with multimodal information, into a shared low-dimensional continuous vector space. In this vector space, relationships are treated as a complex translation operation after the fusion of multimodal information, and the likelihood that a triple fact holds is measured by calculating the distance or similarity between the head entity, the tail entity, and a vector of fused multimodal features. The model captures the rich semantic information of entities and relations by learning the joint representation of different modal features, thus improving the accuracy of link prediction. Its representative model, IKRL [
15], uses a TransE-based multimodal scoring function for link prediction. RSME [
16] introduces a modal information selection gating mechanism. The post-decision fusion model first performs feature extraction and independent link prediction for each modality and then integrates these independent prediction results at the decision-making layer in order to form the final prediction results. Its representative model, MoSE [
17], utilizes structural, textual, and visual data to train three linked prediction models and uses an integration strategy to make joint predictions. IMF [
18] proposes interactive models to make robust predictions.
Although the explainability of the results for multimodal link prediction has not been extensively studied, research on the post hoc explainability of unimodal link prediction and graph neural networks is still an important reference, providing theoretical foundations and methodological guidance for understanding and improving the explainability of multimodal link prediction. The widely used methods in post hoc explanatory research work are to attribute changes in model results to certain changes in inputs, mainly gradient-based methods, agent-based methods, and perturbation-based methods.
Gradient-based approaches look for explanations by calculating the gradient change of a neural network with respect to the input features. Its representative model, CRIAGE [
25], proposes adversarial modifications to the knowledge graph and uses a gradient-based algorithm to identify the most influential modifications. The agent approach replaces the original model with an interpretable model to find explanations. Its representative model, GraphLIME [
26], is a locally interpretable model interpretation framework that finds the most representative features as explanations in a nonlinear manner. RelEx [
27] uses interpretable models to locally proxy GNNs and then obtains explanations from the proxy models. The perturbation-based approach applies small modifications to the inputs and measures how these changes affect the model’s outputs yields explanations. KE-X [
28] extracts the most valuable subgraph explanations for link predictions by performing an improved message passing mechanism on masked knowledge graphs and maximizing the knowledge information gain. Kelpie [
29] evaluates the impact on prediction scores by approximately evaluating the effect of removing the existing facts from a knowledge graph to search for the most important fact triples to explain the target prediction. PGExplainer [
30] applies a masking approach for explaining link prediction. SubgraphX [
31] uses a Monte Carlo tree search algorithm to explore different subgraphs and selects the most important subgraphs as explanations for the prediction. OrphicX [
32] isolates the latent space of the graph by maximizing the information flow metrics of causal factors in the graph, thus generating causal explanations for the results. The goal of all of the above models is to find the most influential input changes in the form of input features or sets of features that are considered highly relevant to the model predictions being interpreted.
The work in this paper focuses on the post hoc explainability of multimodal link prediction, which presents a more complex and enriched interpretation compared to the traditional post hoc interpretation method of unimodal link prediction [
15,
16,
17,
18,
25,
26,
27,
28,
29,
30,
31,
32]. Specifically, we are no longer limited to utilizing only the structural information within the knowledge graph or the attribute information of a single modality for the interpretation of the prediction results, but we go deeper into the fusion and interaction level of multimodal data, aiming to reveal the importance of different modalities and their contribution in the link prediction process and to provide multi-granularity interpretations from the global to the local level.
3. Preliminaries
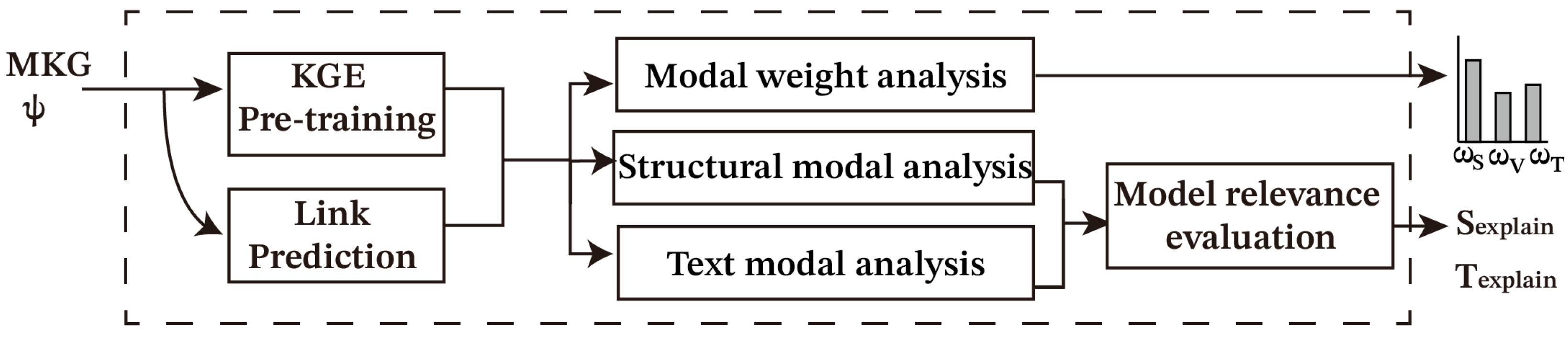
Multimodal knowledge graph link prediction plays a crucial role in mining missing triples from existing knowledge graphs, and it is equally important to provide explanations to multimodal link prediction in order to improve the credibility and transparency of link prediction models. In this paper, we focus on how to analyze and de-black-box the embedding-based multi-modal link prediction model to obtain evidence for the interpretation of the prediction results and provide the model with interpreted fact triples. The task description is shown in
Figure 1. Given an embedding-based multimodal link prediction model and a multimodal knowledge graph, the importance of each modality is analyzed, and explanations at the modality level are extracted. The structural modalities are analyzed to extract the triads that play an important role in the prediction process, and the textual modalities are analyzed to extract the key phrases in the prediction process.
The following definitions are provided for the symbols and concepts used in this text.
Definition 1. The symbols related to the multi-modal knowledge graph. A traditional knowledge graph is usually defined as a directed graph , where E and R denote the set of entities and relations, respectively, and the triplet is denoted as . A multimodal knowledge graph is an extension of the traditional knowledge graph, where each entity has its corresponding different modal data, which are usually defined as , where the definitions of E, R, and ζ are the same as in the traditional knowledge graph; V is the set of images corresponding to all entities; and T is the set of texts corresponding to all entities.
Definition 2. Multimodal knowledge graph link prediction. The multimodal link prediction model is used to predict missing links between entities. Given a query of entity–relationship pairs , the multimodal link prediction aims to find the target entities satisfying or belonging to the multi-modal knowledge graph MKG, and the likelihood of the link’s existence is obtained by calculating the score of or . The multimodal knowledge graph link prediction model to be explained is denoted as the target link prediction model ψ.
Definition 3. Target explanation triplet and predictive relevance. The target explanation triad is selected from the triad obtained after the training of the target link prediction model, which is denoted as , and the modality is denoted as , with S standing for the structural modality, V for the image modality, and T for the textual modality. The words in the text are denoted as . The predictive relevance scores of structure and text are denoted as and . The set of coarse-grained modal-level explanations is represented as . The set of fine-grained explanations under the structure is represented as . The set of fine-grained explanations under the text is represented as .
5. Experiments
The original training and explanation experiments for the multimodal knowledge graph link prediction model were run on a single server configured with an Intel(R) Core(TM) i9-14900 CPU (Manufacturer: Intel Corporation, Santa Clara, CA, USA), 64 GB of RAM (Manufacturer: Kingston Technology Company, Fountain Valley, CA, USA), and an NVIDIA GeForce RTX 3070 (Manufacturer: NVIDIA Corporation, Santa Clara, CA, USA). The operating system was Ubuntu 22.04 with CUDA version 12.2 and PyTorch 2.2.1.
5.1. Datasets
We conducted tests on four datasets, including FB15K, FB15K-237, WN18, and WN18RR. These datasets encompass diverse domains and scales of knowledge graphs to ensure the breadth and representativeness of our experimental results, as illustrated in
Table 1. FB15K and FB15K-237 are subsets of Freebase, entity pairs that contains knowledge base relation triplets and textual mentions. WN18 and WN18RR are subsets of WordNet and cover a broader range of English semantic knowledge bases. For WN18 and WN18RR, we use synonym set definitions as entity sentences. For all the datasets, the image data of the corresponding entities in MMKG [
33] were used.
5.2. Evaluation Metrics
The predictive performance of a link prediction model is often measured using two evaluation indicators: Mean Reciprocal Rank (MRR) and Hits@k (k = 1). To evaluate the effectiveness of the explanation model, we analyze its impact on Hits@1 and MRR for the target link prediction model, denoted as and . The metric consists of quantifying the difference in linking predictive metrics between the results of the original predictive model and the results of the model after removing the explanatory facts from the dataset. A higher absolute value of and signifies that the effectiveness of the explanation is greater.
5.3. Evaluation Settings
To validate the performance of the model, we trained the model using complex as a decoder for multimodal link prediction on four generalized multimodal knowledge graph datasets, and a set of ternaries containing 100 correct predictions was randomly selected as the target explanation ternary from the results predicted by the model. After the explanation models extracted the explanations, the link prediction models were removed from the training set and retrained to verify the explanations. In our experiment, we selected triples that could be correctly predicted by the link prediction model as the interpretation objects, so their initial values of and were both 1.
To improve the efficiency of interpretation, we used a textual semantic heuristic search strategy to find k candidate interpretation triples, which narrowed the space of candidate explanation to the top k most promising combinations of facts. Therefore, we conducted experiments to analyze how changes in the number of candidate explanation triples affect the explanation results by varying the value of k. The results are shown in
Figure 7, which demonstrate the effectiveness of interpreting different candidate triplet numbers K on the multimodal dataset FB15K-237. The horizontal axis represents the path length k, and the vertical axis represents the explained performance metrics. The left panel shows the model explanation metric
, and the right panel shows the model explanation metric
. The experimental results indicate that when the value of k exceeds 10, the absolute values of both key assessment metrics
and
tend to level off. This indicates that increasing the value of k beyond 10 does not significantly improve these two evaluation metrics. Therefore, setting k to 10 can effectively achieve better explanatory performance.
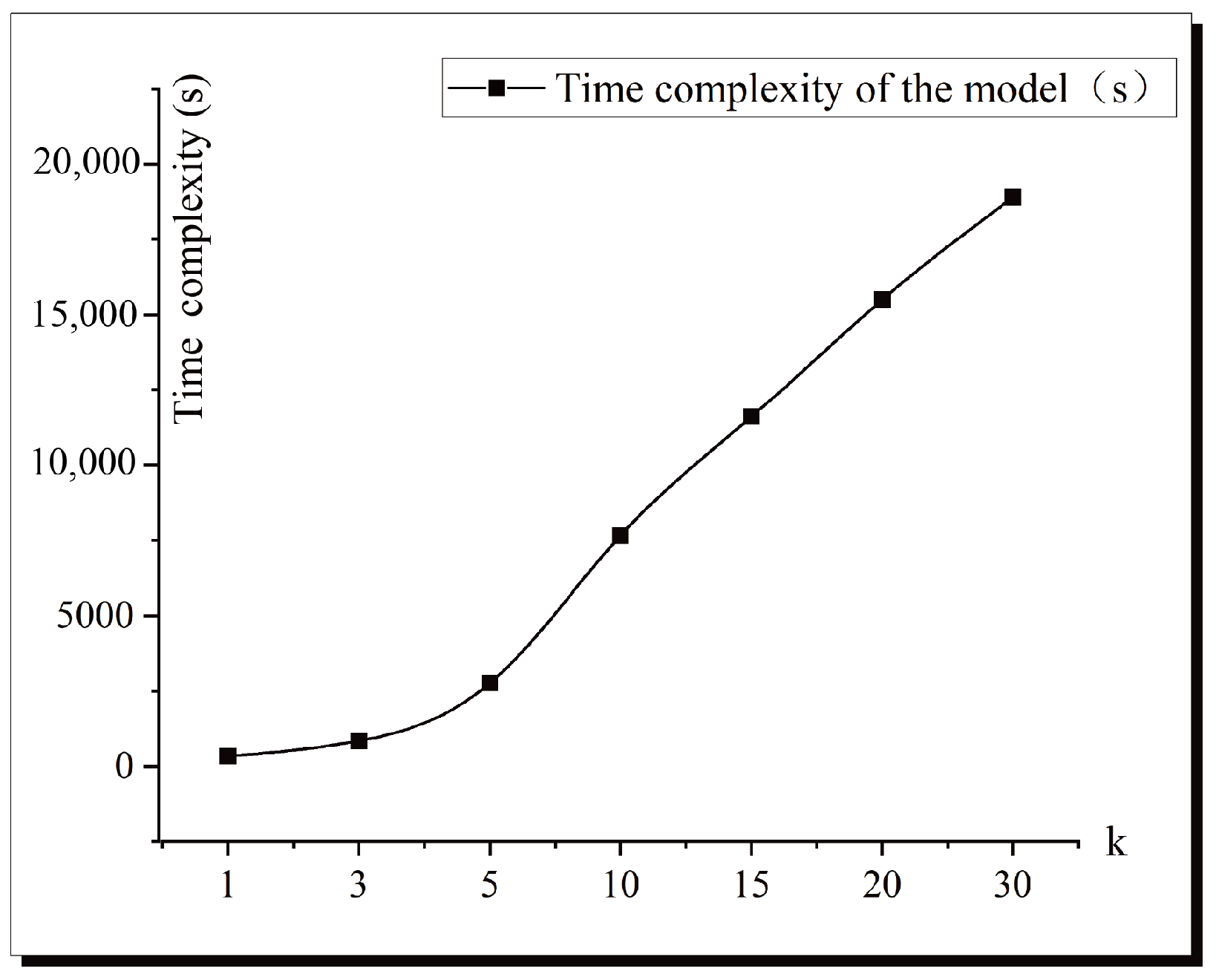
The results are shown in
Figure 8, which illustrates the experimental results of the model’s running time complexity under the multimodal dataset FB15K-237. The horizontal axis represents the path length k, and the vertical axis represents the time complexity. The time complexity increases exponentially with the increase in k. Although increasing the number of candidate explanation triples may bring some degree of performance improvement, it also significantly increases the computational cost, which in turn affects the efficiency and feasibility of the experiment. Based on the above experimental results, after weighing the relationship between performance improvement and computational cost, the parameter of the number of candidate explanatory triples k is set to 10, which ensures the efficiency and practicability of the explanatory model.
5.4. Experimental Results
In order to verify whether the model is able to find the key influences in the target link prediction model, this paper conducts comparative experiments with the following baseline explanatory models for the complex-based link prediction model. The baseline explanatory models are Data Poisoning (DP) [
34], which obtains the optimal perturbation gain by targeting the data attacks embedded in the knowledge graph, identifying the individual facts that are most relevant to the link prediction. Criage [
25] uses a Taylor approximation influence function to estimate the change in scores due to deletion of facts. Kelpie [
29] explains the prediction by calculating a subset of the training facts via model post-training, divided into the Kelpie version explained by combinations of multiple facts and the K1 version explained by a single fact.
The validity of the explanation method was measured using the
and
indicators, with the experimental results presented in
Table 2. We used the
metric to evaluate the overall ranking change of link prediction results, where our method outperformed the baseline model with the highest metric by 1% on the WN18RR dataset, 2% on the WN18 dataset, 3% on the FB15K dataset, and 17% on the FB15K-237 dataset. Additionally, improvements in the
metric were observed across all four datasets. These results demonstrate that the text semantic heuristic search strategy is effective in identifying the triples most likely to serve as link prediction explanations. Furthermore, this strategy performs particularly well in identifying explanatory triples under the structural modality. The superiority of WN18 over FB15K in explaining the experimental results can be attributed to the simpler relationship types in WN18, which facilitate the model’s ability to identify key explanatory facts more easily. In contrast, the greater complexity of relationships in FB15K results in a more limited explanatory effect.
5.5. Case Study
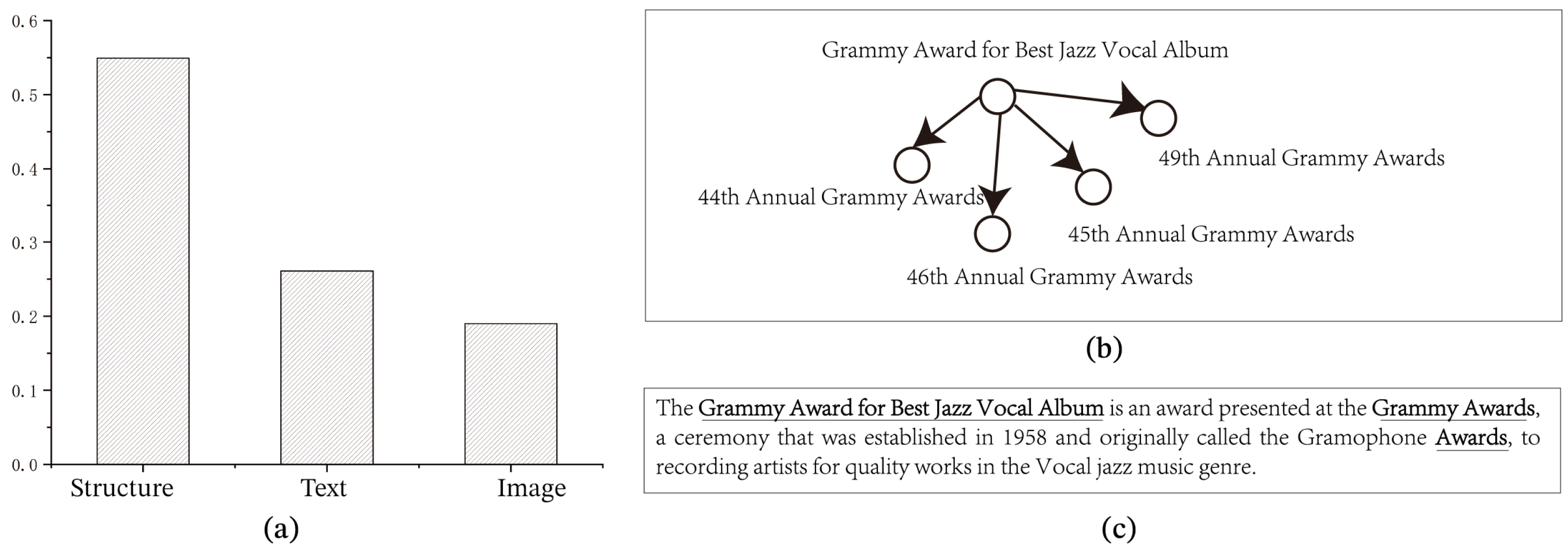
Under the FB15K-237 dataset, we perform a post hoc multi-granularity explanation analysis of the prediction results to obtain the contribution of each modality in the link prediction task. As shown in
Figure 9, we observe that structural modal information contributes most significantly to the prediction results, with a contribution rate of 0.549. This result further confirms the importance of structural modalities in revealing the potential relationships among entities in the knowledge graph, as well as their irreplaceability in the link prediction task. Secondly, the contribution of textual modal information to the prediction result is 0.261. Textual modality plays an important supporting role in the prediction process by providing rich semantic information that helps the model to understand the correlations among entities in a deeper way. The information contribution of image modality is relatively low, with a contribution rate of 0.19. Compared with structural and textual modalities, the information representation of the image modality is more complex and abstract, which leads to the loss of part of the useful information after complex preprocessing and feature extraction steps. In addition, the problem of the noise present in the image data can also lead to its relatively poor contribution.
When interpreting the target interpretation triad <Grammy Award for Best Jazz Vocal Album, award, 48th Annual Grammy Awards>, the model gives the interpretation triad <Grammy Award for Best Jazz Vocal Album, award, 44th Annual Grammy Awards>, <Grammy Award for Best Jazz Vocal Album, award, 46th Annual Grammy Awards>, <Grammy Award for Best Jazz Vocal Album, award, 49th Annual Grammy Awards>, <Grammy Award for Best Jazz Vocal Album, award, 45th Annual Grammy Awards>. The results show that the explanation model is able to understand the semantic information in the target triad, and it is able to find entities that are semantically similar to the target triad in the knowledge graph.
In its header text description, “The Grammy Award for Best Jazz Vocal Album is an award presented at the Grammy Awards, a ceremony that was established in 1958 and originally called the Gramophone Awards, to record artists for quality works in the Vocal jazz music genre. Originally called the Gramophone Awards, to recording artists for quality works in the Vocal jazz music genre.”, the model identified the key phrases ‘Grammy Award for Best Jazz Vocal Album’ and ‘Grammy Awards’. ‘Grammy Award for Best Jazz Vocal Album’ serves as the subject of this description, and ‘Grammy Awards’, another key concept that is closely related to the header entity, reveals the series to which the awards belong, the Grammy Awards. Together, these two key phrases constitute important contextual information for the target interpretation triad, <Grammy Award for Best Jazz Vocal Album, award, 48th Annual Grammy Awards>. The model is able to recognize these key phrases as key information that can be used by the link prediction model to provide a fine-grained interpretation in the textual modality of the link prediction model.
6. Conclusions
In this paper, we propose a post hoc model-independent multimodal link prediction interpretation model. Through modal separation pre-training, structural perturbation, and text mask learning, our model provides both modal-level coarse-grained interpretation and fine-grained interpretation under structural and textual modalities. We propose a strategy for modal separation learning when obtaining coarse-grained explanations at the modal level. We introduce a heuristic search for interpretation triplets based on entity text semantic information when obtaining structural modality explanations. Additionally, we employ a strategy where the model is retrained after masked learning of entity text descriptions when obtaining text explanations. Experimental results on the multimodal datasets FB15K, FB15K-237, WN18, and WN18RR show that our method performs well in identifying key modal information, which significantly improves the explainability of the model and provides important support for understanding the behavior of link prediction models.
Through experimental validation on multiple benchmark datasets, our method is able to obtain modal information that plays a key role in the model’s prediction, which is important for understanding the behavior of embedding-based multimodal link prediction models. Since structural and textual modalities play a major role in link prediction, the MMExplainer model only considers structural and textual modalities. However, image modality, as another important source of information, may also provide valuable clues for link prediction. In addition, the complexity of domain datasets can impact the interpretation performance. Therefore, an in-depth analysis of image modalities will be considered in future work, along with an evaluation of its practical usability in real-world applications.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}