
NCSBFF-Net: Nested Cross-Scale and Bidirectional Feature Fusion Network for Lightweight and Accurate Remote-Sensing Image Semantic Segmentation

Abstract
1. Introduction
- A new multi-scale feature fusion module, i.e., the NCSBFF module, is proposed for feature fusion to improve segmentation accuracy for scale-varied objects.
- The shallowest feature is passed to the Shuffle Attention block in the NCSBFF module, which adaptively filters out weak details and highlights critical information for classification of tiny objects.
- The proposed method improves state-of-the-art segmentation performance in both efficiency and accuracy on the Potsdam and Vaihingen benchmark dataset.
2. Related Work
2.1. Lightweight Networks
2.2. Multi-Scale Feature Fusion
3. Materials and Methods
3.1. Overview
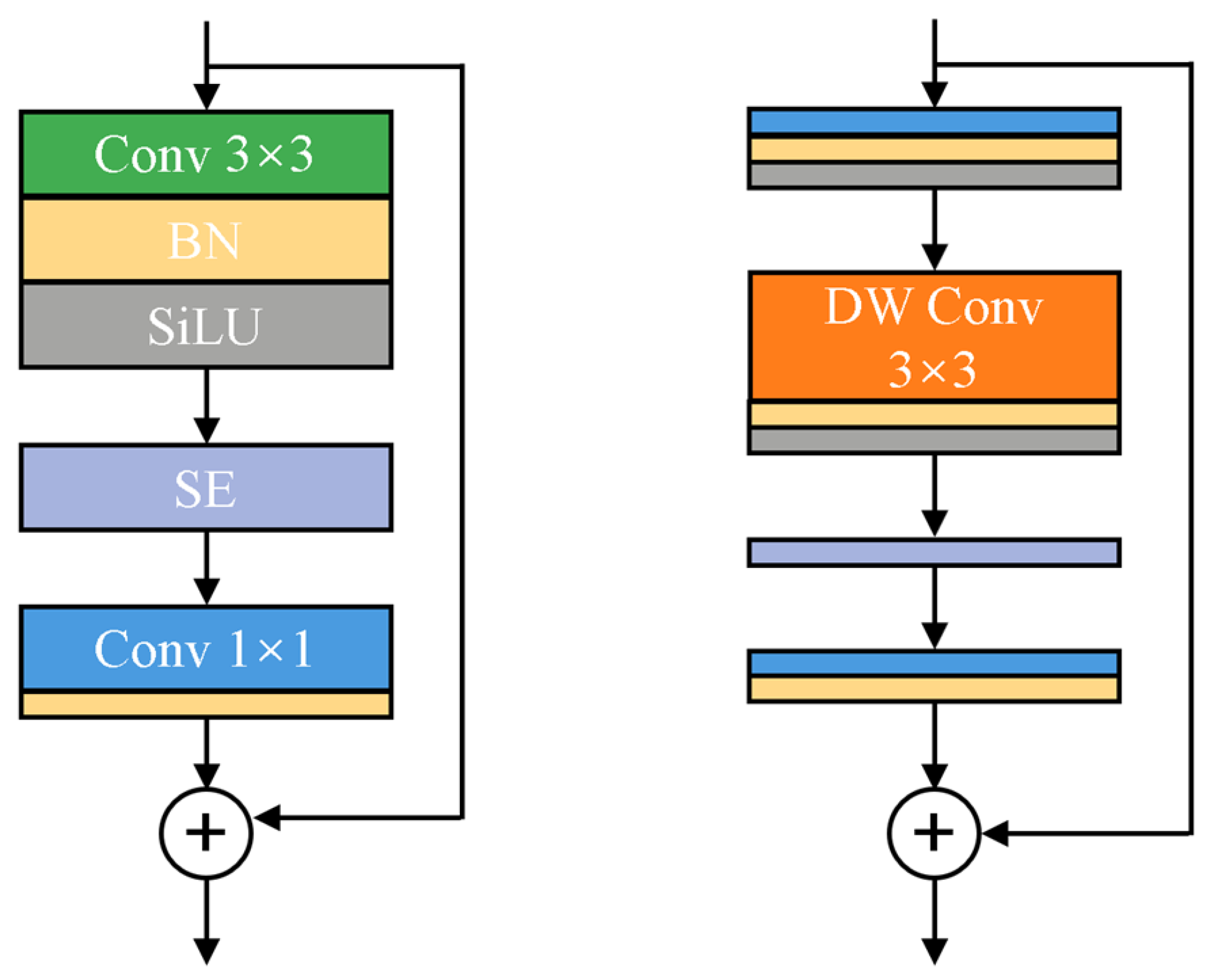
3.2. Lightweight Feature Pyramid Module
3.3. Nested Cross-Scale and Bidirectional Feature Fusion Module
3.4. Segmentation Head
4. Experiments and Results
4.1. Experimental Settings and Evaluation Metrics
4.2. Datasets
- Potsdam Dataset [53]: The Potsdam dataset contains 38 high-resolution true orthophoto (TOP) images, each with the size of 6000 × 6000 pixels over Potsdam City, Germany, and the ground sampling distance is 5 cm. Each image has three channel combinations, namely, R-G-B, R-G-B-IR, and IR-R-G. In addition, the dataset offers two types of annotations: non-eroded and eroded options, which correspond to having and not having the boundary. To avoid ambiguity in labeling boundaries, all experimental results are performed and benchmarked on the eroded boundary dataset. Following the experimental setup [54], we divide the dataset into 24 images with R-G-B for training and 14 images with R-G-B for testing (image IDs: 2_13, 2_14, 3_13, 3_14, 4_13, 4_14, 4_15, 5_13, 5_14, 5_15, 6_13, 6_14, 6_15, and 7_13). The dataset consists of six categories: impervious surfaces, buildings, low vegetation, trees, cars, and clutter/background. Each image is overlap-partitioned into a set of sub-images of size 512 × 512 with a step size of 256 by 256.
- Vaihingen Dataset [53]: The Vaihingen dataset contains 33 TOP images collected by advanced airborne sensors, covering 1.38 km2 area of Vaihingen. The ground sampling distance is about 9 cm. Each TOP image has IR, R, and G channels. The dataset have the same six categories as the Potsdam Dataset. Following [55], we select 11 images for training (image IDs: 1, 3, 5, 7, 13, 17, 21, 23, 26, 32, and 37) and 5 images for testing (image IDs: 11, 15, 28, 30, and 34). Each image is overlap-partitioned into a set of sub-images sized of 512 × 512 with a step size of 256 by 256.
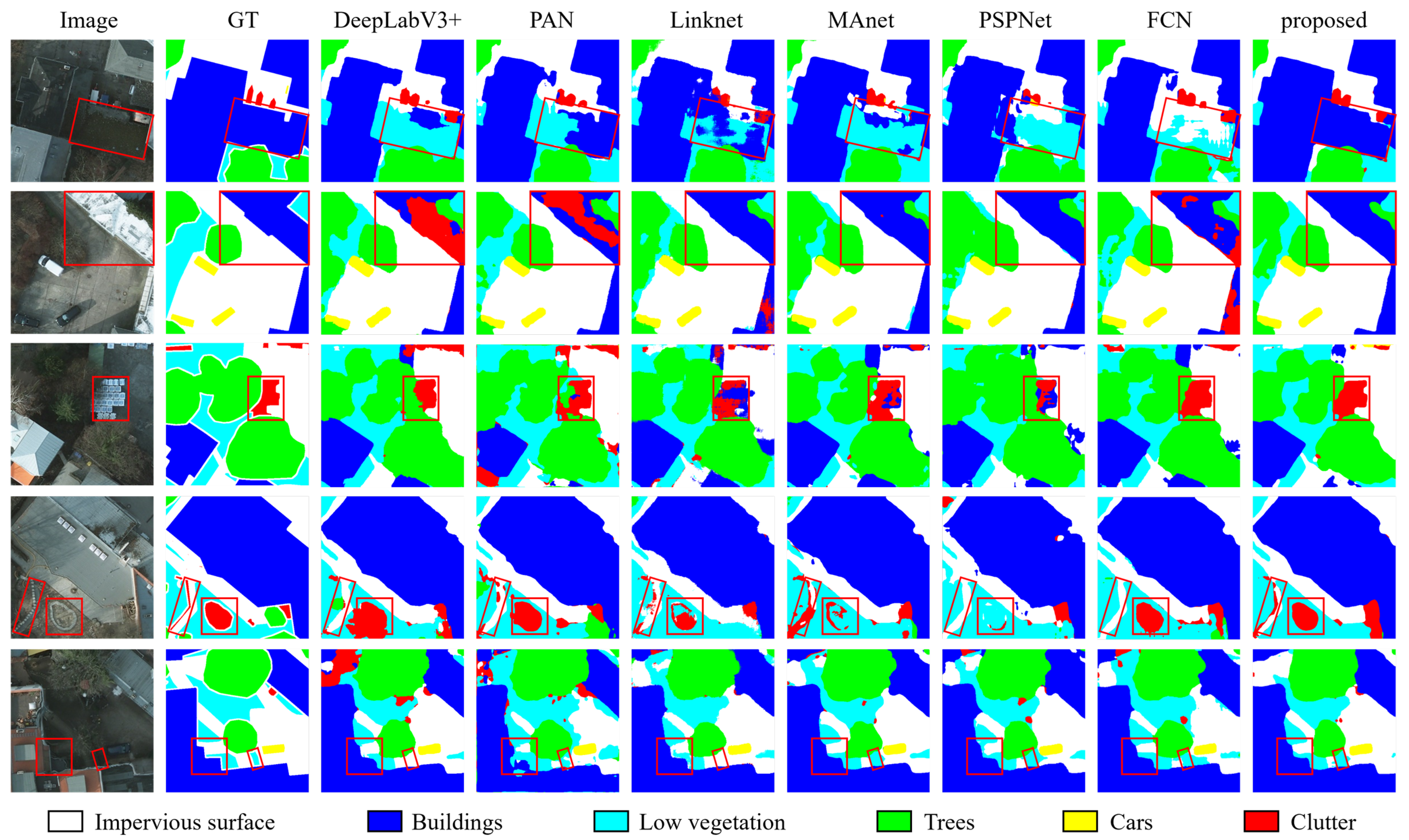
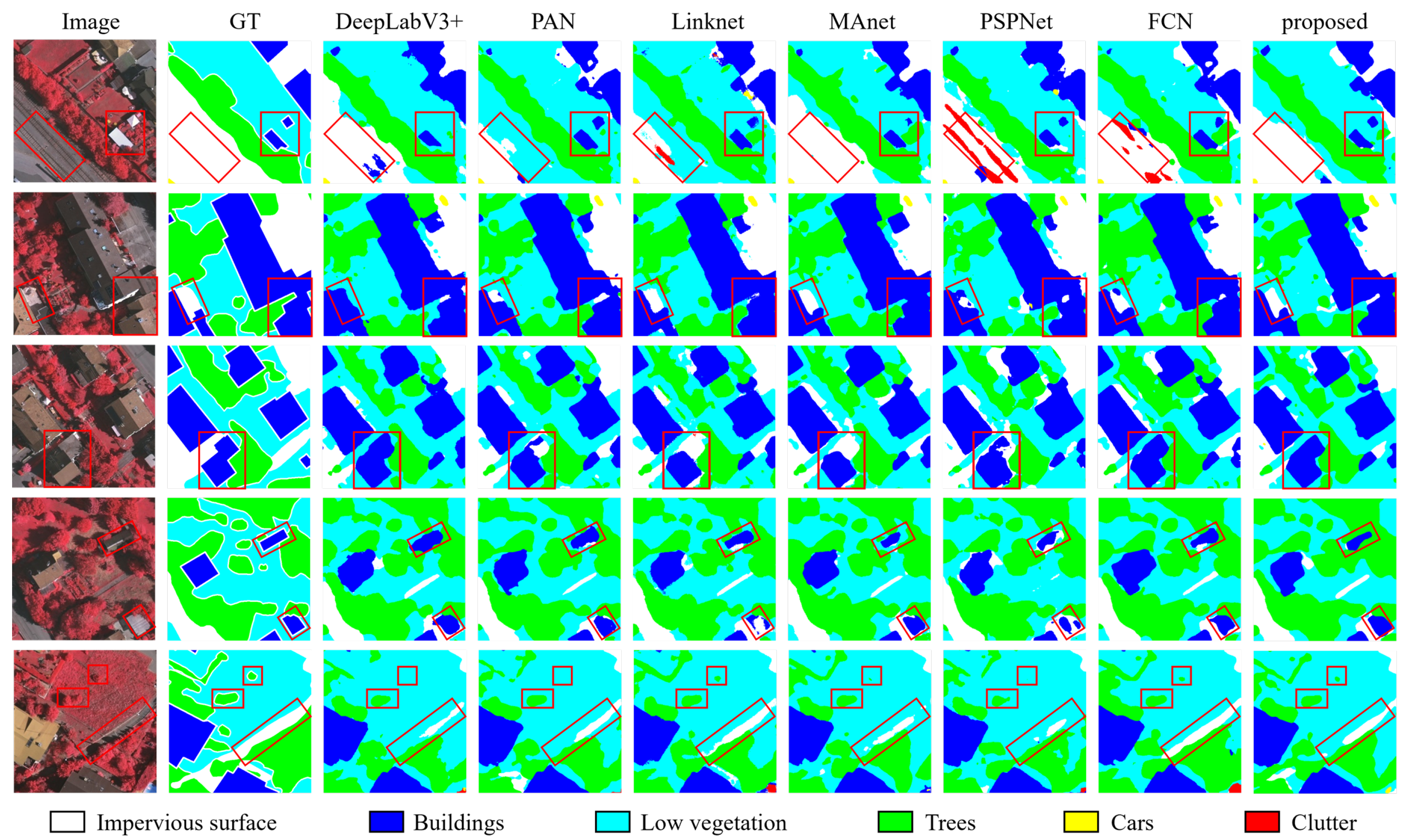
4.3. Comparison with State-of-the-Art Methods
- DeepLabV3+: A fourth-generation version of Google’s DeepLab series, enhanced with the atrous spatial pyramid pooling (ASPP) module. ASPP, with varying dilated rates, extracts features from different scales in paralle within the encoder. The decoder restores image resolution through two bilinear interpolations processes.
- PANet: A newtork that features an integrated top-down and bottom-up structure, enabling two-way interaction between high-resolution low-level features and coarse-resolution high-level features.
- Linknet: A U-shaped architecture in which encoder features generated by the backbone are directly linked through deconvolution and element-wise addition operations.
- MAnet: MANet combines position-wise attention blocks and multi-scale fusion attention blocks to adaptively integrate local features with their global dependencies based on the attention mechanism.
- PSPNet: PSPNet incorporates a pyramid pooling module (PPM) to aggregate contextual information. The PPM generates representations of different sub-regions. These features are subsequently upsampled and concatenated, allowing the model to integrate both local and global features.
- FCN: FCN is a classical CNN-based semantic segmentation model. In the decoder, fully connected layers are replaced with deconvolutional or upsampling layers and feature maps are restored to the image’s input size to achieve pixel-by-pixel predictions.
4.4. Ablation Study
4.5. Multi-Scale Image Impact
4.6. Model Computational Complexity
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Duo, L.; Wang, J.; Zhang, F.; Xia, Y.; Xiao, S.; He, B.-J. Assessing the spatiotemporal evolution and drivers of ecological environment quality using an enhanced remote sensing ecological index in Lanzhou City, China. Remote Sens. 2023, 15, 4704. [Google Scholar] [CrossRef]
- Jiang, D.; Jones, I.; Liu, X.; Simis, S.G.; Cretaux, J.-F.; Albergel, C.; Tyler, A.; Spyrakos, E. Impacts of droughts and human activities on water quantity and quality: Remote sensing observations of Lake Qadisiyah, Iraq. Int. J. Appl. Earth Obs. Geoinf. 2024, 132, 104021. [Google Scholar]
- Ding, L.; Zhang, J.; Bruzzone, L. Semantic segmentation of large-size VHR remote sensing images using a two-stage multiscale training architecture. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5367–5376. [Google Scholar] [CrossRef]
- Luo, H.; Chen, C.; Fang, L.; Khoshelham, K.; Shen, G. MS-RRFSegNet: Multiscale regional relation feature segmentation network for semantic segmentation of urban scene point clouds. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8301–8315. [Google Scholar]
- Zhao, J.; Zhou, Y.; Shi, B.; Yang, J.; Zhang, D.; Yao, R. Multi-stage fusion and multi-source attention network for multi-modal remote sensing image segmentation. ACM Trans. Intell. Syst. Technol. 2021, 12, 1–20. [Google Scholar]
- Liu, G.; Li, L.; Jiao, L.; Dong, Y.; Li, X. Stacked Fisher autoencoder for SAR change detection. Pattern Recognit. 2019, 96, 106971. [Google Scholar] [CrossRef]
- Sahar, L.; Muthukumar, S.; French, S.P. Using aerial imagery and GIS in automated building footprint extraction and shape recognition for earthquake risk assessment of urban inventories. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3511–3520. [Google Scholar]
- Sheikh, R.; Milioto, A.; Lottes, P.; Stachniss, C.; Bennewitz, M.; Schultz, T. Gradient and log-based active learning for semantic segmentation of crop and weed for agricultural robots. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1350–1356. [Google Scholar]
- Yu, Y.; Bao, Y.; Wang, J.; Chu, H.; Zhao, N.; He, Y.; Liu, Y. Crop row segmentation and detection in paddy fields based on treble-classification Otsu and double-dimensional clustering method. Remote Sens. 2021, 13, 901. [Google Scholar] [CrossRef]
- Wu, Y.; Yang, X.; Plaza, A.; Qiao, F.; Gao, L.; Zhang, B.; Cui, Y. Approximate computing of remotely sensed data: SVM hyperspectral image classification as a case study. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 5806–5818. [Google Scholar]
- Han, W.; Zhang, X.; Wang, Y.; Wang, L.; Huang, X.; Li, J.; Wang, S.; Chen, W.; Li, X.; Feng, R.; et al. A survey of machine learning and deep learning in remote sensing of geological environment: Challenges, advances, and opportunities. ISPRS J. Photogramm. Remote Sens. 2023, 202, 87–113. [Google Scholar]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic segmentation of urban buildings from VHR remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar]
- Zheng, C.; Hu, C.; Chen, Y.; Li, J. A self-learning-update CNN model for semantic segmentation of remote sensing images. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Huang, L.; Jiang, B.; Lv, S.; Liu, Y.; Fu, Y. Deep learning-based semantic segmentation of remote sensing images: A survey. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 8370–8396. [Google Scholar]
- Lin, G.; Liu, F.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path refinement networks for dense prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 1228–1242. [Google Scholar]
- Wu, Z.; Liu, C.; Song, B.; Pei, H.; Li, P.; Chen, M. Diff-HRNet: A diffusion model-based high-resolution network for remote sensing semantic segmentation. IEEE Geosci. Remote Sens. Lett. 2024, 22, 6000505. [Google Scholar]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. ResUNet-A: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar]
- Li, R.; Zheng, S.; Duan, C.; Su, J.; Zhang, C. Multistage attention ResU-Net for semantic segmentation of fine-resolution remote sensing images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar]
- Zhang, Q.-L.; Yang, Y.-B. SA-Net: Shuffle attention for deep convolutional neural networks. arXiv 2021, arXiv:2102.00240. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 11–15 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2881–2890. [Google Scholar]
- Wang, F.; Piao, S.; Xie, J. CSE-HRNet: A context and semantic enhanced high-resolution network for semantic segmentation of aerial imagery. IEEE Access 2020, 8, 182475–182489. [Google Scholar]
- Zuo, R.; Zhang, G.; Zhang, R.; Jia, X. A deformable attention network for high-resolution remote sensing images semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–14. [Google Scholar]
- Shafique, A.; Cao, G.; Khan, Z.; Asad, M.; Aslam, M. Deep learning-based change detection in remote sensing images: A review. Remote Sens. 2022, 14, 871. [Google Scholar] [CrossRef]
- Huo, B.; Li, C.; Zhang, J.; Xue, Y.; Lin, Z. SAFF-SSD: Self-attention combined feature fusion-based SSD for small object detection in remote sensing. Remote Sens. 2023, 15, 3027. [Google Scholar] [CrossRef]
- Deng, L.; Wang, Y.; Lan, Q.; Chen, F. Remote sensing image building change detection based on Efficient-UNet++. J. Appl. Remote Sens. 2023, 17, 034501. [Google Scholar]
- Feng, J.; Wang, H. A multi-scale contextual attention network for remote sensing visual question answering. Int. J. Appl. Earth Obs. Geoinf. 2024, 126, 103641. [Google Scholar]
- Su, Y.; Cheng, J.; Wang, W.; Bai, H.; Liu, H. Semantic segmentation for high-resolution remote-sensing images via dynamic graph context reasoning. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar]
- Chen, S.; Lei, F.; Zang, Z.; Zhang, M. Forest mapping using a VGG16-UNet++ & stacking model based on Google Earth Engine in the urban area. IEEE Geosci. Remote Sens. Lett. 2023, 20, 1–5. [Google Scholar]
- Su, Y.; Cheng, J.; Bai, H.; Liu, H.; He, C. Semantic segmentation of very-high-resolution remote sensing images via deep multi-feature learning. Remote Sens. 2022, 14, 533. [Google Scholar] [CrossRef]
- Li, J.; Hu, Y.; Huang, X. CASAFormer: A cross-and self-attention based lightweight network for large-scale building semantic segmentation. Int. J. Appl. Earth Obs. Geoinf. 2024, 130, 103942. [Google Scholar]
- Li, X.; Li, J. MFCA-Net: A deep learning method for semantic segmentation of remote sensing images. Sci. Rep. 2024, 14, 5745. [Google Scholar]
- Li, L.; Ding, J.; Cui, H.; Chen, Z.; Liao, G. LITEMS-Net: A lightweight semantic segmentation network with multi-scale feature extraction for urban streetscape scenes. Vis. Comput. 2024, 41, 2801–2815. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking model scaling for convolutional neural networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; PMLR: New York, NY, USA, 2019; pp. 6105–6114. [Google Scholar]
- Chen, F.; Tsou, J.Y. Assessing the effects of convolutional neural network architectural factors on model performance for remote sensing image classification: An in-depth investigation. Int. J. Appl. Earth Obs. Geoinf. 2022, 112, 102865. [Google Scholar] [CrossRef]
- Wang, B.; Huang, G.; Li, H.; Chen, X.; Zhang, L.; Gao, X. Hybrid CBAM-EfficientNetV2 fire image recognition method with label smoothing in detecting tiny targets. Mach. Intell. Res. 2024, 21, 1145–1161. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4510–4520. [Google Scholar]
- Zhang, X.; Zhao, Z.; Ran, L.; Xing, Y.; Wang, W.; Lan, Z.; Yin, H.; He, H.; Liu, Q.; Zhang, B.; et al. FastICENet: A real-time and accurate semantic segmentation model for aerial remote sensing river ice image. Signal Process. 2023, 212, 109150. [Google Scholar] [CrossRef]
- He, H.; Zhou, F.; Xia, Y.; Chen, M.; Chen, T. Parallel fusion neural network considering local and global semantic information for citrus tree canopy segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2023, 17, 1535–1549. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, S.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 8759–8768. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10781–10790. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Zhao, S.; Feng, Z.; Chen, L.; Li, G. DANet: A semantic segmentation network for remote sensing of roads based on dual-ASPP structure. Electronics 2023, 12, 3243. [Google Scholar] [CrossRef]
- Tang, H.; Li, Z.; Zhang, D.; He, S.; Tang, J. Divide-and-conquer: Confluent triple-flow network for RGB-T salient object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 1958–1974. [Google Scholar] [CrossRef]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Chi, Y.; Li, J.; Fan, H. Pyramid-attention based multi-scale feature fusion network for multispectral pan-sharpening. Appl. Intell. 2022, 52, 5353–5365. [Google Scholar] [CrossRef]
- Zheng, Z.; Ermon, S.; Kim, D.; Zhang, L.; Zhong, Y. ChangeNet2: Multi-temporal remote sensing generative change foundation model. IEEE Trans. Pattern Anal. Mach. Intell. 2025, 47, 725–741. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Le, Q. EfficientNetV2: Smaller models and faster training. In Proceedings of the 38th International Conference on Machine Learning (ICML), Virtual, 18–24 July 2021; PMLR: New York, NY, USA, 2021; pp. 10096–10106. [Google Scholar]
- Wang, J.; Wang, B.; Wang, X.; Zhao, Y.; Long, T. Hybrid attention-based U-shaped network for remote sensing image super-resolution. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–15. [Google Scholar] [CrossRef]
- Rottensteiner, F.; Sohn, G.; Jung, J.; Gerke, M.; Baillard, C.; Benitez, S.; Breitkopf, U. The ISPRS benchmark on urban object classification and 3D building reconstruction. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2012, 1, 293–298. [Google Scholar] [CrossRef]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. High-resolution aerial image labeling with convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7092–7103. [Google Scholar] [CrossRef]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 801–818. [Google Scholar]
- Chaurasia, A.; Culurciello, E. LinkNet: Exploiting encoder representations for efficient semantic segmentation. In 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Fan, T.; Wang, G.; Li, Y.; Wang, H. MA-Net: A multi-scale attention network for liver and tumor segmentation. IEEE Access 2020, 8, 179656–179665. [Google Scholar] [CrossRef]
- Hanyu, T.; Yamazaki, K.; Tran, M.; McCann, R.A.; Liao, H.; Rainwater, C.; Adkins, M.; Cothren, J.; Le, N. AerialFormer: Multi-resolution transformer for aerial image segmentation. Remote Sens. 2024, 16, 2930. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Stage | Operator | Kernel Size | Stride | Dimensions | #Layers |
|---|---|---|---|---|---|
| Stem | Conv3 × 3 | 3 × 3 | 2 | 256 × 256 × 24 | 1 |
| 1 | Fused-MBConv | 3 × 3 | 1 | 128 × 128 × 24 | 2 |
| 2 | Fused-MBConv | 3 × 3 | 2 | 128 × 128 × 48 | 4 |
| 3 | Fused-MBConv | 3 × 3 | 2 | 64 × 64 × 64 | 4 |
| 4 | MBConv | 3 × 3 | 2 | 32 × 32 × 128 | 6 |
| 5 | MBConv | 3 × 3 | 1 | 32 × 32 × 160 | 9 |
| 6 | MBConv | 3 × 3 | 2 | 16 × 16 × 256 | 15 |
| Method | mIoU | OA | Ave. F1 | F1 per Category | |||||
|---|---|---|---|---|---|---|---|---|---|
| Imp. Surf. | Buildings | Low Veg. | Trees | Cars | Clutter | ||||
| DeepLabV3+ | 78.10 | 92.05 | 86.50 | 92.91 | 96.41 | 86.56 | 88.26 | 95.32 | 59.55 |
| PAN | 76.94 | 91.77 | 85.61 | 92.53 | 96.15 | 85.67 | 87.66 | 95.00 | 56.66 |
| Linknet | 77.28 | 92.05 | 85.85 | 92.45 | 96.29 | 85.56 | 87.78 | 94.93 | 57.12 |
| MAnet | 76.15 | 91.84 | 84.88 | 92.51 | 96.05 | 85.62 | 87.78 | 94.43 | 52.87 |
| PSPNet | 74.23 | 90.82 | 83.64 | 91.17 | 94.29 | 84.72 | 87.05 | 93.12 | 51.51 |
| FCN | 77.58 | 92.07 | 85.95 | 92.78 | 96.26 | 86.35 | 87.96 | 96.14 | 56.23 |
| Proposed | 79.24 | 92.65 | 87.32 | 93.43 | 97.01 | 87.40 | 88.69 | 95.63 | 61.74 |
| Method | mIoU | OA | Ave. F1 | F1 per Category | |||||
|---|---|---|---|---|---|---|---|---|---|
| Imp. Surf. | Buildings | Low Veg. | Trees | Cars | Clutter | ||||
| DeepLabV3+ | 70.30 | 90.51 | 80.43 | 92.29 | 94.93 | 83.72 | 88.79 | 80.05 | 42.79 |
| PANet | 71.82 | 90.40 | 81.96 | 91.99 | 95.18 | 83.43 | 88.72 | 82.77 | 49.69 |
| Linknet | 71.57 | 90.61 | 81.41 | 92.16 | 95.34 | 83.41 | 89.13 | 83.92 | 44.52 |
| MAnet | 69.97 | 90.88 | 79.42 | 92.19 | 95.37 | 84.11 | 89.33 | 82.28 | 33.25 |
| PSPNet | 68.35 | 89.15 | 78.95 | 90.33 | 93.10 | 82.84 | 88.41 | 79.70 | 39.33 |
| FCN | 72.23 | 90.47 | 82.10 | 92.17 | 94.79 | 83.11 | 89.32 | 85.54 | 47.64 |
| Proposed | 73.66 | 90.72 | 83.56 | 92.35 | 95.58 | 83.63 | 88.98 | 85.08 | 55.71 |
| Method | NCSBFF | SA | Potsdam | Vaihingen | ||||
|---|---|---|---|---|---|---|---|---|
| mIoU | OA | Ave. F1 | mIoU | OA | Ave. F1 | |||
| Baseline | ✘ | ✘ | 78.22 | 92.65 | 86.46 | 71.22 | 90.61 | 81.31 |
| NCSBFF without SA | ✔ | ✘ | 78.68 | 92.73 | 86.84 | 72.40 | 90.65 | 82.50 |
| Proposed | ✔ | ✔ | 79.24 | 92.65 | 87.32 | 73.66 | 90.72 | 83.56 |
| Input Size | mIoU | OA | F1 |
|---|---|---|---|
| 512 × 512 | 79.24 | 92.65 | 87.32 |
| 384 × 384 | 75.75 | 91.81 | 84.56 |
| Method | Params (MB) | FLOPs (G) | Potsdam (mIoU) | Vaihingen (mIoU) | Inference Time (ms) |
|---|---|---|---|---|---|
| DeepLabV3+ | 101.77 | 7.07 | 78.10 | 70.30 | 2.9 |
| PAN | 92.55 | 6.69 | 76.94 | 71.82 | 3.4 |
| Linknet | 118.93 | 8.27 | 77.28 | 71.57 | 3.1 |
| MAnet | 562.44 | 14.32 | 76.15 | 69.97 | 5.6 |
| PSPNet | 8.62 | 2.29 | 74.23 | 68.35 | 1.5 |
| FCN | 125.69 | 26.58 | 77.58 | 72.23 | 4.0 |
| NCSBFF + ResNet50 | 95.52 | 4.99 | – | – | – |
| Proposed | 77.06 | 3.96 | 79.24 | 73.66 | 5.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, S.; Zhang, B.; Wen, D.; Tian, Y. NCSBFF-Net: Nested Cross-Scale and Bidirectional Feature Fusion Network for Lightweight and Accurate Remote-Sensing Image Semantic Segmentation. Electronics 2025, 14, 1335. https://doi.org/10.3390/electronics14071335
Zhu S, Zhang B, Wen D, Tian Y. NCSBFF-Net: Nested Cross-Scale and Bidirectional Feature Fusion Network for Lightweight and Accurate Remote-Sensing Image Semantic Segmentation. Electronics. 2025; 14(7):1335. https://doi.org/10.3390/electronics14071335
Chicago/Turabian StyleZhu, Shihao, Binqiang Zhang, Dawei Wen, and Yuan Tian. 2025. "NCSBFF-Net: Nested Cross-Scale and Bidirectional Feature Fusion Network for Lightweight and Accurate Remote-Sensing Image Semantic Segmentation" Electronics 14, no. 7: 1335. https://doi.org/10.3390/electronics14071335
APA StyleZhu, S., Zhang, B., Wen, D., & Tian, Y. (2025). NCSBFF-Net: Nested Cross-Scale and Bidirectional Feature Fusion Network for Lightweight and Accurate Remote-Sensing Image Semantic Segmentation. Electronics, 14(7), 1335. https://doi.org/10.3390/electronics14071335