1. Introduction
In recent years, the rapid advancement of unmanned aerial vehicle (UAV) technology has significantly enhanced its application in search and tracking tasks. Owing to their high mobility, broad application spectrum, and cost-effectiveness, UAVs have been extensively used in disaster relief, environmental monitoring, and military reconnaissance [
1,
2,
3,
4,
5]. Several conventional algorithms have been extensively integrated into UAV operations. For instance, the coverage path planning method divides the working area into sub-regions and explores them with simple back-and-forth motions to ensure full scene coverage and complete target search [
6]. The method of artificial potential field creates a virtual attraction field at the target’s location and a repulsion field at the obstacle’s location, allowing the UAV to track the target under combined forces [
7]. The genetic algorithm designs an appropriate encoding method and termination criteria, constructs a fitness function, and effectively performs genetic operations, such as selection, crossover, and mutation, to determine the UAV’s flight path [
8]. However, in dynamic and complex environments, efficiently searching for and tracking moving targets remains a challenging problem, particularly when the UAV’s field of view (FOV) is limited, the target moves quickly, and obstacles cause interference. First, the UAV must be capable of avoiding environmental obstacles during search and target tracking to prevent collisions. Second, it should autonomously plan the optimal search path to maximize coverage. In addition, the UAV must be robust and flexible enough to adapt to various environments. Lastly, due to factors such as sensor failures and target occlusion by the environment, target-detection algorithms may not provide fully reliable results in a short time. This necessitates the UAV having predictive capabilities for target movement.
The emergence of reinforcement learning (RL) methods has attracted increasing attention. RL is modeled as a Markov decision process (MDP), where the RL agent observes the environment’s state, makes decisions accordingly, interacts with the environment, and receives reward feedback to inform better actions [
9]. To enhance the ability of RL to address complex tasks, researchers have integrated it with deep learning, leading to the development of deep reinforcement learning (DRL) [
10]. DRL utilizes neural networks to approximate value or policy functions, enabling optimization of network parameters during agent-environment interactions, thus maximizing cumulative rewards. DRL has demonstrated significant success across several domains, including competitive gaming, smart manufacturing, and transportation systems [
11,
12,
13].
The advent of deep reinforcement learning has offered new solutions for addressing UAV target search and tracking challenges in dynamic and complex environments [
14]. For example, Yuanyuan Sheng et al. proposed a DRL-based UAV autonomous navigation algorithm that establishes a dynamic reward function and a novel state-space representation method to solve the UAV’s autonomous path planning problem in high-density and highly dynamic environments [
15]. Yongfeng Yin et al. tackled the problem of weak obstacle avoidance capability in UAV target tracking by proposing an innovative reinforcement learning method with attention guidance, enabling the UAV’s decision-making to shift between navigation and obstacle avoidance tasks based on changes in the environment [
16]. Haobin Shi et al. proposed an end-to-end DRL navigation strategy that leverages curiosity to encourage the agent to explore previously unvisited environmental states, addressing the problem of map-less navigation in complex environments with sparse rewards [
17]. However, these methods generally assume that the target’s location is known or that the target is static, which limits the system’s adaptability and generality for many real-world tasks. Therefore, Mei Liu et al. proposed a two-stage method for mobile target search and tracking in unknown environments, dividing the task into search and tracking phases and training the controller for each phase using a deep deterministic policy gradient algorithm with three critic networks [
18]. Despite its advantages, this method lacks sufficient research on task switching, particularly in handling target loss. Once a target is lost, quickly re-localizing it becomes difficult, which makes long-term target tracking in complex environments challenging. To address the issue of target loss, Tian Wang et al. proposed a quantum probability model, which records the probability of the target in a discrete grid and updates the probability based on UAV observations and target movement to search for the lost target [
19]. Yanyu Cui et al. developed an action decision-occlusion handling network based on deep reinforcement learning, using temporal and spatial contexts, object appearance models, and motion vectors to provide information on the occluded target, thus achieving target tracking under occlusion [
20]. Although the above methods have made significant progress in target relocation after loss, most of these approaches are designed for relatively simple scenarios or require detailed target information, which limits their applicability in complex real-world environments. Moreover, reinforcement learning models typically require continuous interaction with the environment to achieve convergence. Unfortunately, these models are often inefficient in terms of sample utilization [
21]. In particular, in UAV applications, training directly in the real world requires significant time and may damage the equipment [
22]. One common approach is learning from demonstration (LfD), where experience is obtained from experts to reduce the need for training samples in real-world settings [
23,
24,
25]. Nevertheless, LfD requires obtaining expert data, and the learning performance is largely dependent on the quality of the expert data. Additionally, in reinforcement learning applications, we often have prior information about the problem, but this knowledge is seldom leveraged by reinforcement learning algorithms. Therefore, Chao Wang et al. proposed an algorithm called non-expert-assisted deep reinforcement learning, which uses both prior and learned policy to jointly construct the behavior policy, successfully guiding UAVs to complete navigation tasks under sparse rewards [
26]. Dawei Wang et al. proposed a two-stage multi-UAV collision avoidance method based on reinforcement learning. In the first stage, supervised training is used to encourage agents to follow prior policy, and in the second stage, policy gradients are employed to further refine the strategy [
27]. The aforementioned methods effectively utilized prior policy in reinforcement learning, but they required certain rule-based guidance or staged training, leading to redundant training processes, which further inspired us to design a more novel training approach to utilizing prior policy.
To address the above issue, we propose a deep reinforcement learning method that accomplishes the two major tasks of target searching and target tracking, which improves the training efficiency of reinforcement learning through prior policy embedding. Specifically, we extend the concept of spatial information entropy and use it to compute rewards that guide the UAV’s target search [
28]. Upon locating the target, the UAV transitions from search mode to tracking mode and commences tracking the target. When the UAV loses the target, it utilizes the information collected during tracking and applies Gaussian process regression (GPR) to forecast the target’s future trajectory, offering a probable target location [
29]. This approach offers potential target locations, thereby substantially diminishing the time needed for the UAV to reacquire the target. As soon as the target re-enters the FOV, the UAV resumes the tracking task. This strategy, which integrates prediction and search, effectively enhances re-localization efficiency after target loss, addressing the limitations of conventional single-task methods in such scenarios. During the algorithm training phase, inspired by Kolmogorov–Arnold Networks (KANs) [
30], we designed a novel method of utilizing prior policy and propose the KANs-based deep deterministic policy gradient (KbDDPG) algorithm. The introduction of KANs enables prior policy to be embedded into the policy network, guiding training with the prior policy, which enhances the reinforcement learning training speed and further improves the UAV’s target search and tracking performance. The main contributions of this study are:
We propose an integrated decision-making framework for UAV search and tracking based on deep reinforcement learning, which significantly improves the efficiency of target search. It solves the re-localization problem after target loss, thereby achieving continuous target tracking.
We design a deep deterministic policy gradient algorithm, KbDDPG, based on Kolmogorov–Arnold networks, which uses prior policy embedding to significantly accelerate the algorithm’s convergence rate.
The proposed method is validated through extensive simulations in complex environments, demonstrating its effectiveness and superiority. Compared to existing DRL algorithms, our approach outperforms them in target search and tracking tasks.
The structure of the paper is as follows.
Section 2 introduces the main model for UAV target search and tracking.
Section 3 elaborates on the proposed method, covering trajectory prediction based on GPR, the extended spatial information entropy model, and the DRL algorithm based on KANs.
Section 4 conducts experiment and analyzes the results. Finally,
Section 5 concludes the paper and explores future research directions.
3. Method
This section begins by modeling the target search and tracking problem using the MDP. We extend the concept of spatial information entropy to enlarge the UAV’s search range. To mitigate target loss during tracking, a trajectory prediction method based on GPR is proposed. Lastly, we introduce the KbDDPG algorithm.
3.1. Problem Statement
In UAV target search and tracking tasks, the problem is often modeled as a MDP. The MDP model comprises a five-tuple .
The state space
S represents the set of all possible states. In this task, the state input includes the processed historical trajectory of the UAV, as well as the observed positions of obstacles and targets. Next, we will introduce the process of state extraction. The historical trajectory processing function is defined as
This function performs the following tasks:
Trajectory centralization: It centers all trajectory positions relative to the UAV’s current position. Centralizing the historical trajectory data removes the influence of global position information, preventing scale variations caused by differing absolute positions and focusing the state on the UAV’s relative movement. In search tasks, the UAV needs to efficiently cover unknown areas. The centralized trajectory data can more intuitively reflect the changes in the UAV’s position relative to its own historical path, which facilitates the learning of search strategies.
Weighted averaging with dynamic window size: It applies weighted averaging to the centralized trajectory using a dynamically adjusted window size. Weighted averaging can smooth the historical trajectory data, effectively reducing noise interference in state representation while also reducing the amount of data the model needs to process, significantly lowering the complexity of the state space. The inclusion of dynamic window techniques allows the window size to be adjusted based on the utilization of the historical trajectory, enabling it to capture the UAV’s fine motion details in the short term while also reflecting long-term movement trends. This flexibility allows the state representation to retain sufficient detail without introducing redundancy or outdated information from excessive historical data, thus improving sample efficiency and accelerating policy learning convergence.
For a given trajectory sequence
, where each
, the centering operation is defined as:
Assume the window starts with an initial size of
. Define a window function
, which adjusts the window size at each computation step
i and increases by a fixed increment
d after every
u steps. The weighted averaging process is as follows:
where
and
determine the range of the window, then
. Let
s denote the UAV’s state, then
The action space A is the set of all possible actions, representing the agent’s choices in each state. In this task, the actions correspond to the control inputs for the UAV, denoted as .
The state transition probability describes the probability of transitioning to the next state s after performing action a in state s.
The reward function represents the expected reward the agent receives for performing action a in state s. Designing the reward function is crucial and can greatly influence the success of the training task. The design for the search and tracking reward function will be discussed later.
The discount factor denotes the agent’s consideration of future rewards. Generally, future rewards are discounted by to balance immediate rewards and long-term gains.
The agent’s objective is to find the optimal policy
that maximizes the expected return. The return is typically defined as:
where
denotes the reward at time
.
To find the optimal policy
in the MDP, RL introduces two key functions: the state-value function and the action-value function. The state-value function
represents the expected return when the agent follows policy
from state
s:
The action-value function
represents the expected return for taking action
a in state
s and then following policy
:
In an MDP, the value function satisfies the Bellman equation:
where
denotes selecting action
a according to policy
in state
s,
represents the transition probability from state
s to the next state
after taking action
a, and
r is the reward obtained by executing action
a in state
s.
This formula indicates that the value of the current state-action pair equals the immediate reward received plus the discounted cumulative value of future rewards, where the computation of future rewards can again be expressed in the same form. The Bellman equation recursively expresses the value function, aiding in determining the optimal policy. The optimal policy
can be represented as:
In the process of policy optimization, the actor–critic framework can be applied to jointly learn the policy (actor) and the value function (critic). The essence of policy optimization is to enable the two networks to jointly improve the agent’s decision making. The goal of the policy network is to choose the optimal action based on the current state and update the policy by maximizing the Q-value from the value network, where the Q-value represents the expected return estimated by the value network. The value network evaluates each action by estimating the Q-value for the current state-action pair, and the network approximates the true Q-value by minimizing the error between the predicted and target values, where the target value is constructed using the Bellman equation. The two networks work in tandem: the value network provides feedback on the action values, while the policy network adjusts the policy accordingly, thus gradually enhancing the decision-making performance.
3.2. Spatial Information Entropy
To further expand the search range of the UAV during search, we expect the UAV to maintain a certain distance from previously detected positions within a certain time period. Specifically, when the UAV’s detection areas are close to each other spatially, the collected information is likely to be highly correlated. Consequently, the gathered information may be redundant, which significantly impacts the search efficiency. A direct solution to this problem is to collect spatially uncorrelated information. In other words, when the UAV’s detection coverage overlaps less, the collected information tends to be unrelated. To measure and optimize the UAV’s information acquisition efficiency during target search and tracking tasks, we extend the concept of spatial information entropy.
First, we define
as the information correlation density at the coordinates
at time step
t, which satisfies:
The higher the information correlation density within the detection area when the UAV reaches a new position, the more redundant information it gathers. The UAV will influence the information correlation density on the map within a certain radius of its current position
. To represent this, we define the indicator function
, which denotes the UAV’s influence at position
on position
:
At the initial time
, we initialize the position
as follows:
where
A is the number of grid points in the 2D space.
This initialization ensures that, at time
, the sum of the information correlation density values equals 1. In each subsequent time step, the UAV’s movement continuously impacts the information correlation density on the map. For position
, we apply the following update formula:
where
is the decay factor, which controls the rate at which the information correlation density decays over time.
denotes the number of coordinate points within the UAV’s FOV.
Based on the update formula, the relationship for updating the sum of information correlation densities on the map is:
When
, the sum of the information correlation densities on the map remains constant, satisfying the conditions for defining information correlation density. This guarantees that at each time step, the total information correlation density on the map neither increases nor decreases without bound but maintains a dynamic balance. This helps the model effectively measure changes in spatial information entropy during long-term searches, while ensuring that the total information correlation density on the map remains within a stable range. Similar to information entropy, given the information correlation density, we can define the spatial information entropy over the entire spatial area. The spatial information entropy at time
t,
, is defined as:
If the UAV’s detection areas overlap significantly (i.e., the collected information is highly correlated), the entropy value decreases, indicating reduced spatial diversity and increased information redundancy. If the UAV’s detection areas overlap less and the detected regions are highly independent (i.e., with low information correlation), the spatial information entropy will be relatively higher.
3.3. GPR for Trajectory Prediction
In each training episode, the UAV acquires the target’s motion trajectory information via the camera. The target’s observed acceleration data is expressed as a two-dimensional acceleration vector:
. The UAV stores the target’s acceleration information during the training process. When the target is lost, the UAV cannot obtain real-time position information. At this point, we construct a Gaussian process regression model based on historical episode data. Using the model, we predict the target’s future acceleration from its current episode’s trajectory information and subsequently forecast its movement trajectory. To use the data from these historical episodes for Gaussian process regression training, we need to construct appropriate input–output data pairs. Set a sliding window length of
, select sufficiently long acceleration sequences for each episode, and construct fixed-length input-output pairs. Specifically, extract input-output pairs from each episode’s trajectory data. Define input data
, representing a vector containing acceleration information for the next
w time steps. Define output data
, representing a vector containing acceleration information for the next
m time steps. Let
denote the episode index, and
represent the number of data points in episode
k. For the input–output dataset, a sliding window is applied to extract input–output pairs at each time step
t:
GPR assumes a joint Gaussian distribution between the input and output. Given the training dataset
X and
Y, the model posits:
where
is the predicted value and
is the input at the prediction time.
In GPR, a kernel function is used to represent the covariance between data points.
is the covariance matrix between the training data,
is the covariance matrix between the observed data and the training data, and
is the covariance matrix between the observed data. Define the kernel function:
where
is the hyperparameter of the kernel function, often referred to as the length scale. It controls the width of the kernel, influencing the similarity between neighboring data points.
The Gaussian kernel function measures the similarity between two data points: when the points are close, the kernel value approaches 1, and when they are distant, the kernel value approaches 0. Given the training dataset
X and
Y, as well as the input
for prediction, we can compute the predictive conditional distribution via GPR. Specifically, the predicted mean and covariance are:
Using the predicted mean acceleration , we can compute the target’s future velocity and position. The predicted covariance is used to assess the prediction accuracy, with higher covariance indicating greater uncertainty in the prediction. Set a variance threshold . If the predicted variance exceeds this threshold, the prediction is stopped. As the reinforcement learning training progresses and more target acceleration data is gathered, the prediction accuracy increases accordingly.
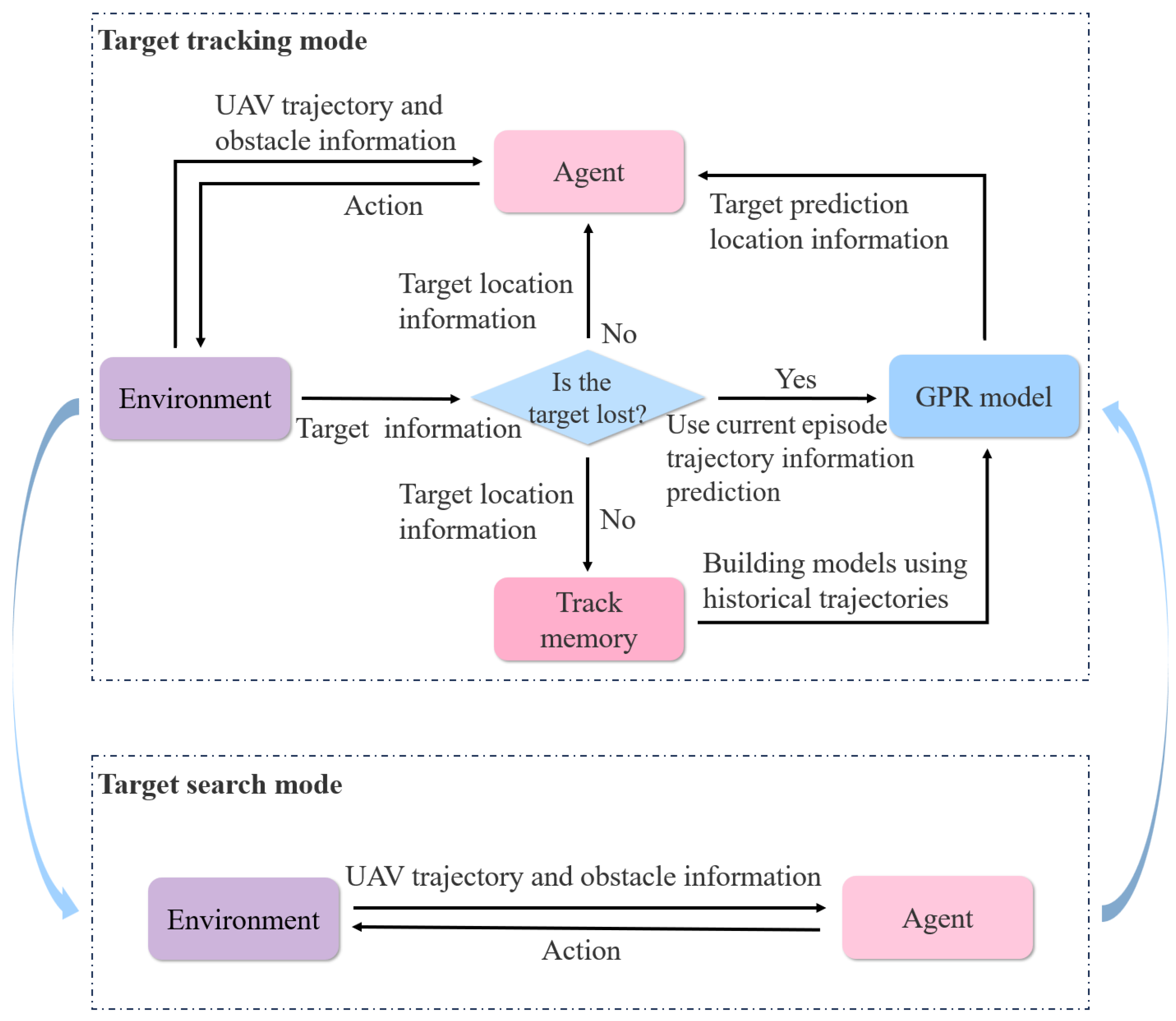
The incorporation of the target trajectory prediction method allows the UAV to quickly re-search and re-locate the target after temporarily losing the target position information. The system framework with the trajectory prediction method is shown in
Figure 2, with the system operating in two modes: search mode and tracking mode. When the UAV detects the target, the system transitions from search mode to tracking mode. In tracking mode, if the target is lost, the agent treats the predicted target position as the true position and continues decision making. If the model’s predicted variance exceeds the set threshold, or if the number of predicted time steps reaches the set maximum prediction length
and the target is still not found, the target is considered fully lost, and the system switches back to search mode.
3.4. Reward Function Design
RL uses rewards to estimate the expected return and derive the optimal policy. The design of the reward function is closely tied to the quality of the training outcome. A suitable reward function can accelerate training convergence and better guide the agent to perform favorable actions while avoiding undesirable ones. In the UAV target search and tracking problem, the reward design focuses on three key aspects: minimizing environmental uncertainty, find the target as quickly as possible, and maintaining tracking once the target is found. The entire search and tracking process should avoid collisions with threats. Based on these objectives, the reward function is defined as:
Search Reward
The objective of this reward function is to leverage spatial information entropy to encourage the UAV to explore uncovered areas and guide it in target search. Denote
as the search reward coefficient, then the search reward is expressed as:
Target Tracking Reward
This reward function provides continuous rewards when the target is within the UAV’s FOV, guiding the UAV to keep tracking the target. Let
represent the target tracking reward coefficient, then the target tracking reward function is defined as:
Target Loss Penalty
The purpose of this penalty function is to prevent the UAV from losing track of the target. Denote
as the target loss penalty coefficient, then the target loss penalty is defined as:
Collision Penalty
This penalty function guides the UAV to avoid threats. Denote
as the collision penalty coefficient, then the collision penalty is defined as:
The four rewards mentioned above work in unison, balancing the relationship between search, tracking, target loss, and collision risk via the reward function weights, offering a unified decision-making framework for the UAV. The weights of the reward function are set as hyperparameters. Initially, we made preliminary estimations of the importance of each reward component based on the experience of domain experts to set the initial weights. Subsequently, these hyperparameters were finely tuned through simulation experiments to balance the weights of different reward components, enabling the reward function to guide UAV action more effectively in complex environments. In summary, the complete reward function can be defined as:
3.5. Training Algorithm
RL tends to perform poorly in sample efficiency, especially when the UAV is tasked with search and tracking in complex dynamic environments. The RL agent typically needs extensive exploration and trial-and-error to gradually improve its decision-making abilities. However, conducting such extensive exploration in a real environment can lead to serious negative consequences. On one hand, the UAV may frequently collide during task execution, resulting in equipment damage or even property loss. On the other hand, this inefficient training method severely limits its applicability in high-risk, complex scenarios. Therefore, to enhance training efficiency and minimize potential risks in practical applications, this paper introduces the KbDDPG algorithm, which aims to accelerate RL convergence by using prior policy embedding in the policy network of the KANs structure.
KANs are inspired by the Kolmogorov–Arnold representation theorem, which states that any multivariate continuous function can be decomposed into a finite combination of univariate functions and addition operations. More specifically, for a smooth function
:
where
,
.
KANs parameterize each one-dimensional function in Expression (
31) using B-spline curves. A KANs layer with
-dimensional input and
-dimensional output can be defined as a univariate function matrix:
where the function
has trainable parameters.
Expression (
31) can be represented as a simple combination of two KANs layers. However, KANs are not restricted to this structure. Similar to multi-layer perceptrons (MLPs), KANs can also expand the width and depth of their network. Given an input vector
x, the output of KANs is:
All operations in the process are differentiable, allowing us to train KANs via backpropagation.
Traditional MLPs use fixed activation functions at the nodes, while KANs employ learnable activation functions at the edges. Each activation function in KANs is a univariate function parameterized by a spline curve, further improving the ability to approximate complex functions. These characteristics of KANs make their structure more intuitive and interpretable. The activation functions of KANs can be visually represented by spline curves, allowing researchers to interact with the model during simplification and optimization to modify or constrain certain function forms.
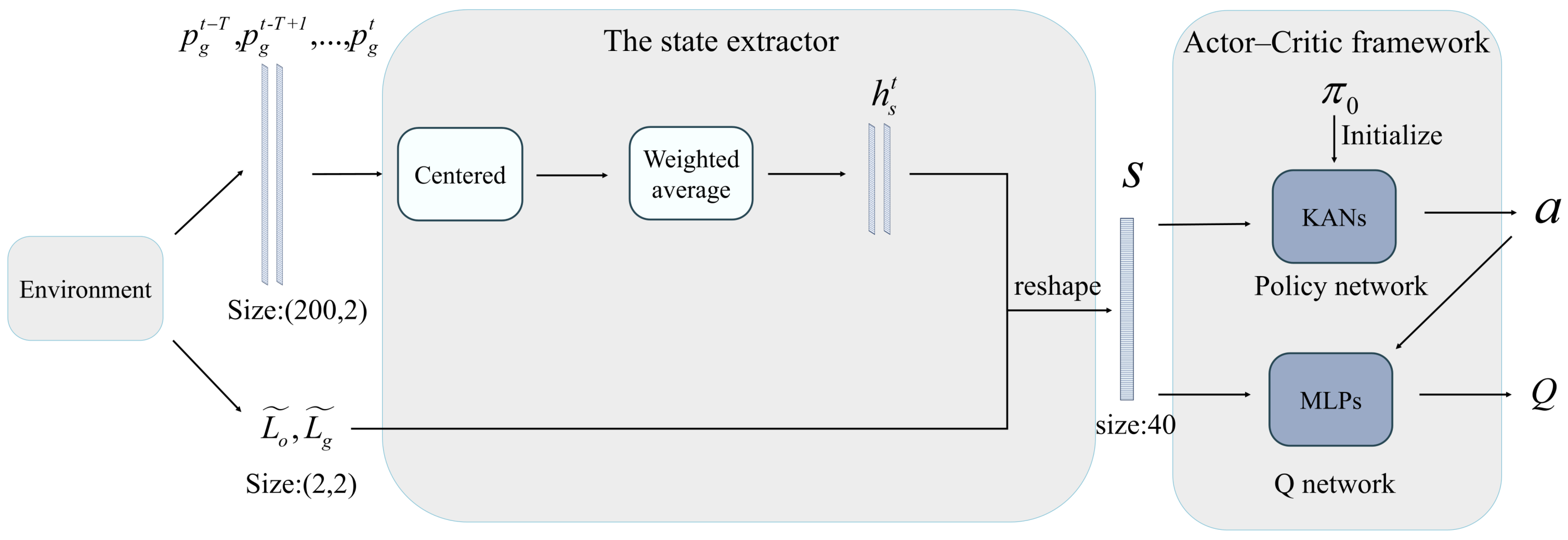
The structure of the KbDDPG algorithm is shown in the
Figure 3.
is used to process the UAV trajectory data. First, the data is centralized to standardize the input, improving the robustness of the state representation and enhancing generalization ability. Then, a weighted average is applied to compress the data length and increase information efficiency. Finally, the processed data is combined with the target and obstacle position information, serving as the agent’s state input. Additionally, in the traditional deep deterministic policy gradient (DDPG) algorithm, the policy network determines the action to take given a state, while the value network estimates the
for the current state–action pair. Both the policy network and the value network typically use MLPs structure [
32]. KbDDPG modifies the policy network by replacing the original MLPs structure with a KANs structure that includes prior policy, while the value network retains its MLPs architecture.
We assume that researchers can design a simple, low-performance prior policy
in advance, based on the agent’s state and environmental information. The prior policy helps the agent explore the environment and achieve its objectives. Due to the structural properties of KANs, the activation functions can be set to known symbolic forms, enabling the model to represent traditional mathematical expressions. In RL, we can embed an existing prior policy
, which is represented symbolically, into a trainable KANs, resulting in a KANs that incorporates initial policy [
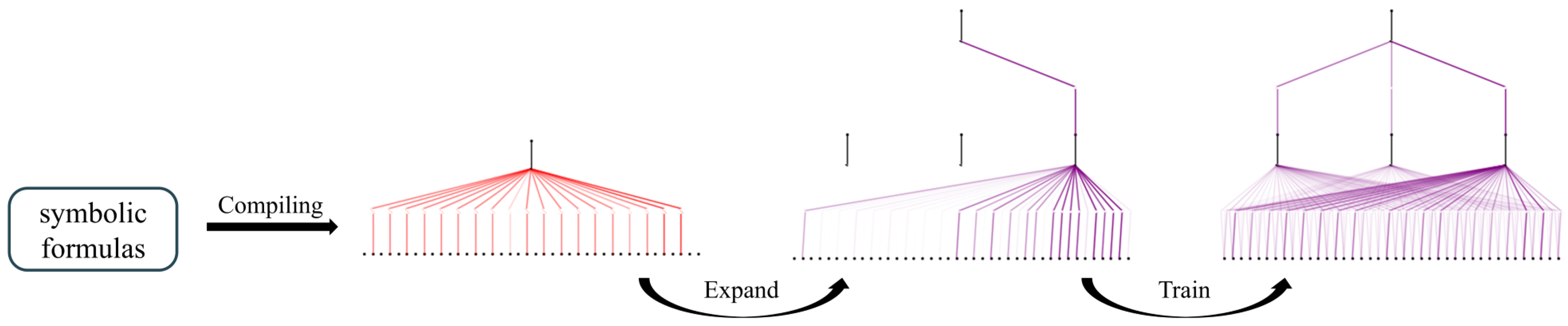
33]. This process involves three main steps, as shown in
Figure 4:
Compile symbolic formulas into KANs: First, parse the symbolic formulas into a tree structure, where nodes represent expressions and edges represent operations/functions. Then, modify the tree to align it with the KANs structure. This modification involves moving all leaf nodes to the input layer via virtual edges and adding virtual sub-nodes/nodes to match the KANs architecture. These virtual edges/nodes/sub-nodes perform only transformations. Finally, the variables are combined at the first layer, effectively converting the tree into a graph.
Extend the network: The compiled KANs network structure is compact, without redundant edges, which could limit its expressive power and hinder further fine-tuning. To improve expressiveness, the network width and depth can be increased according to the task complexity.
Training: The agent, after policy initialization, already possesses a certain ability to complete tasks, which can significantly accelerate the convergence speed of subsequent training and reduce the task failure rate during the training process. Finally, building on the prior policy, the strategy is further optimized using DRL algorithms.
The policy network
, which embeds the prior policy
, is used to generate the action based on the current state
:
By executing the action
, interacting with the environment, and receiving the next state
, reward
, and done flag, the current experience
is obtained and stored in the experience replay buffer
. The value network and policy network are updated by randomly sampling experience data
from the experience replay buffer. According to Equation (
14), the target
Q-value is expressed as:
where
is the target value of the
i-th experience data,
and
represent the target network, which is specifically used to compute the target value.
During training, to make the target network updates smoother, it uses soft updating to gradually approach the value network and policy network, with the soft update coefficient
controlling the target network parameter update speed. The objective of the value network is to approximate the true
Q-values by minimizing the mean squared error (MSE) loss of the
Q-value function. Thus, the loss function for the value network is defined as the MSE between the predicted
Q-values and the target
Q-values:
The gradient of the value network is the derivative of the loss function with respect to the parameter
:
The objective of the policy network is to find the optimal policy by maximizing the
Q-value output by the value network. The goal is to maximize the expected return under the policy. The loss function of the policy network can be defined as the negative
Q-value:
Since the policy network embeds prior policy
, the policy network can be represented as:
where
represents the difference between the current network and the prior policy.
At the beginning of training, the network difference is zero. This way, the network has a reasonable behavioral foundation from the start. Compared to traditional reinforcement learning algorithms, this effectively reduces the inefficiency caused by starting exploration from a completely random policy. Additionally, in terms of network training, the derivative of the policy network with respect to the parameters can be expressed as:
It can be observed that the gradient in the above equation only involves the
part, meaning that the network only needs to learn the correction term of the ideal policy relative to the prior policy. At the same time, the prior policy
provides a starting point close to the optimal solution, reducing the exploration range and making the gradient direction more stable, which significantly reduces the complexity of the learning task and accelerates convergence. Parameters are updated using gradient descent in the direction opposite to the gradient:
where
and
are the learning rates for the policy network and value network, respectively.
As learning progresses, the policy network is continuously optimized, and the agent gradually moves away from the prior policy’s influence, independently achieving the task objectives. In summary, the proposed algorithm can be summarized as Algorithm 1.
| Algorithm 1 KbDDPG Algorithm |
- 1:
Randomly initialize critic network with weights - 2:
Compile the initial policy into - 3:
Extend the KANs - 4:
Initialize target network and with weight - 5:
Initialize replay buffer R - 6:
for each episode = 1,M do - 7:
Initialize a random process for action exploration - 8:
Receive initial observation state - 9:
for each episode = 1,T do - 10:
Select the action , represents the exploration noise - 11:
Execute action and observe reward and observe new state - 12:
Store transition in R - 13:
Sample a random minibatch of transitions from R - 14:
Set - 15:
Update critic by minimizing the loss: - 16:
Update the actor policy using the sampled policy gradient: - 17:
Update the target networks: - 18:
end for - 19:
end for
|
5. Discussion
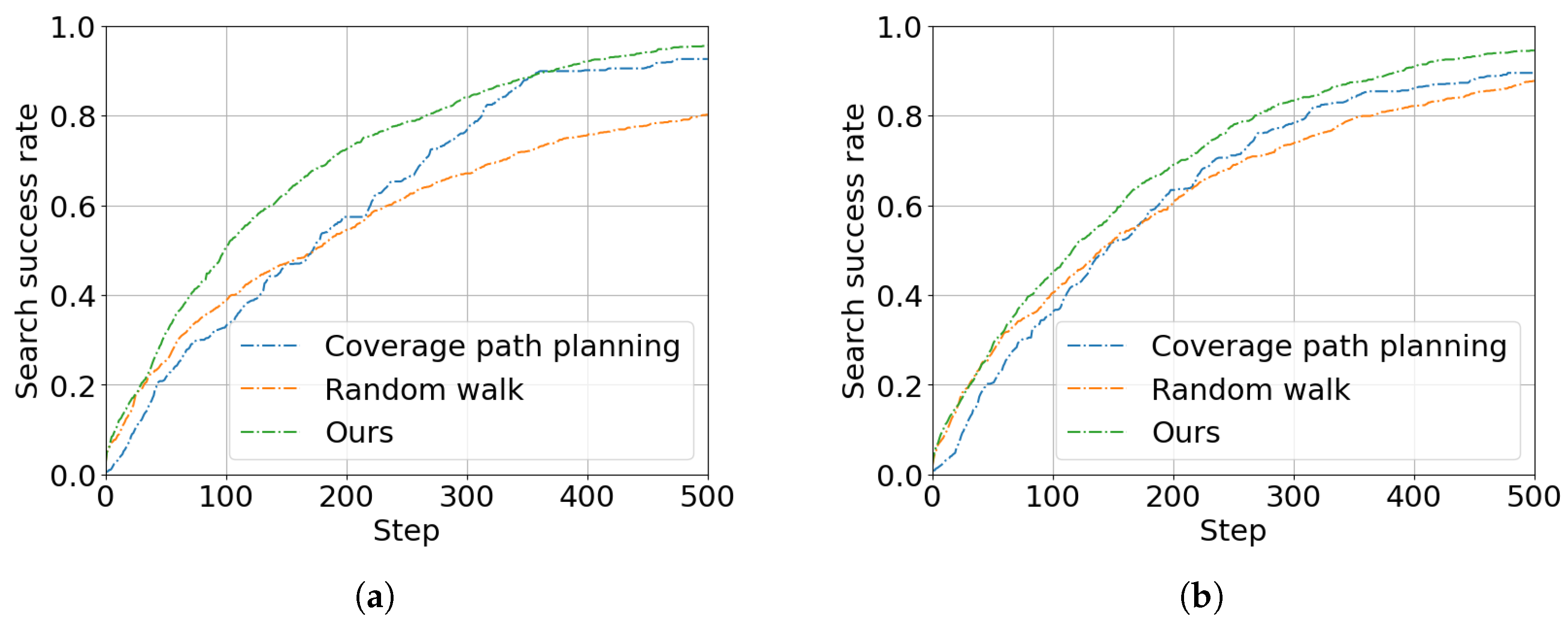
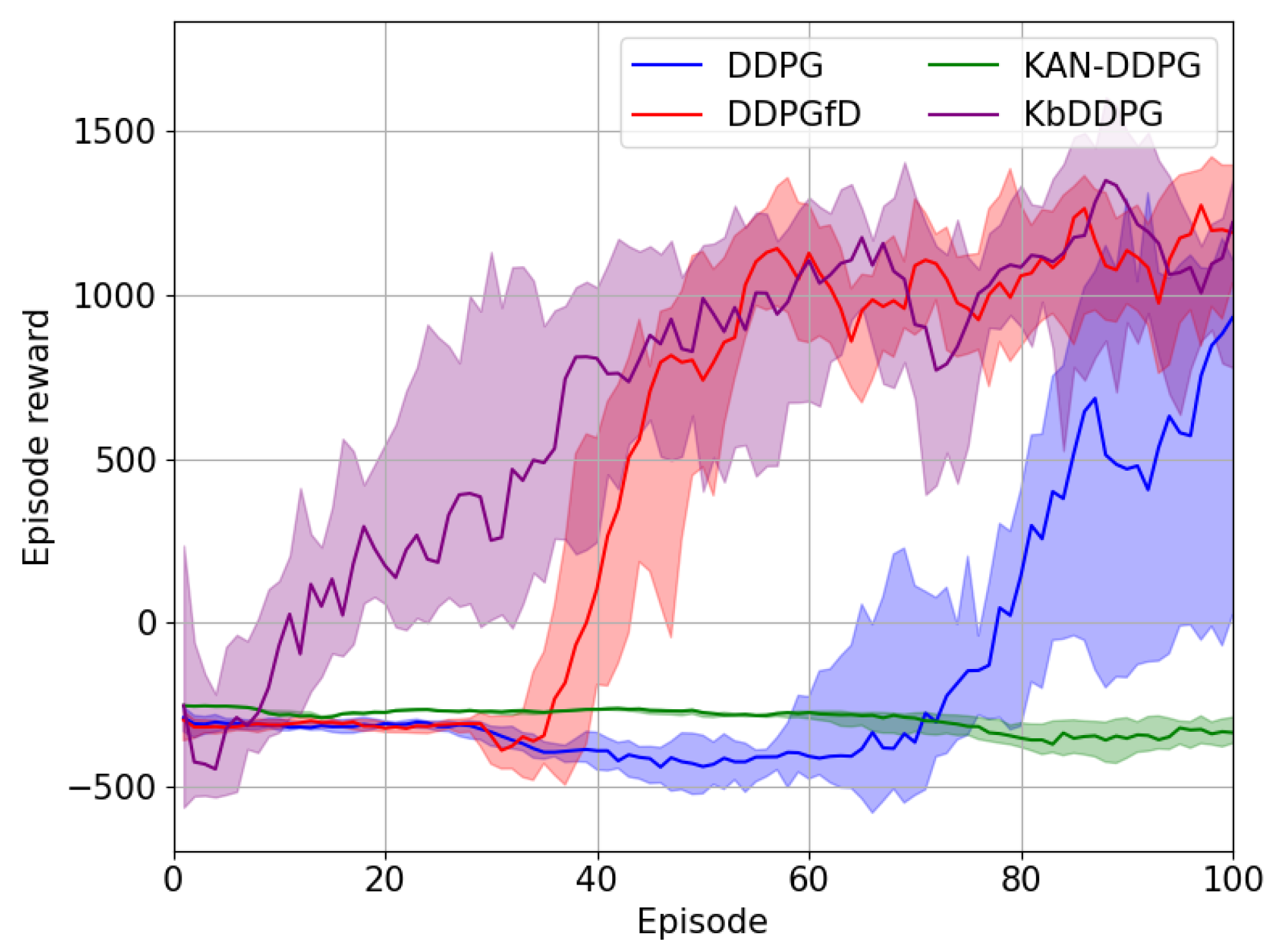
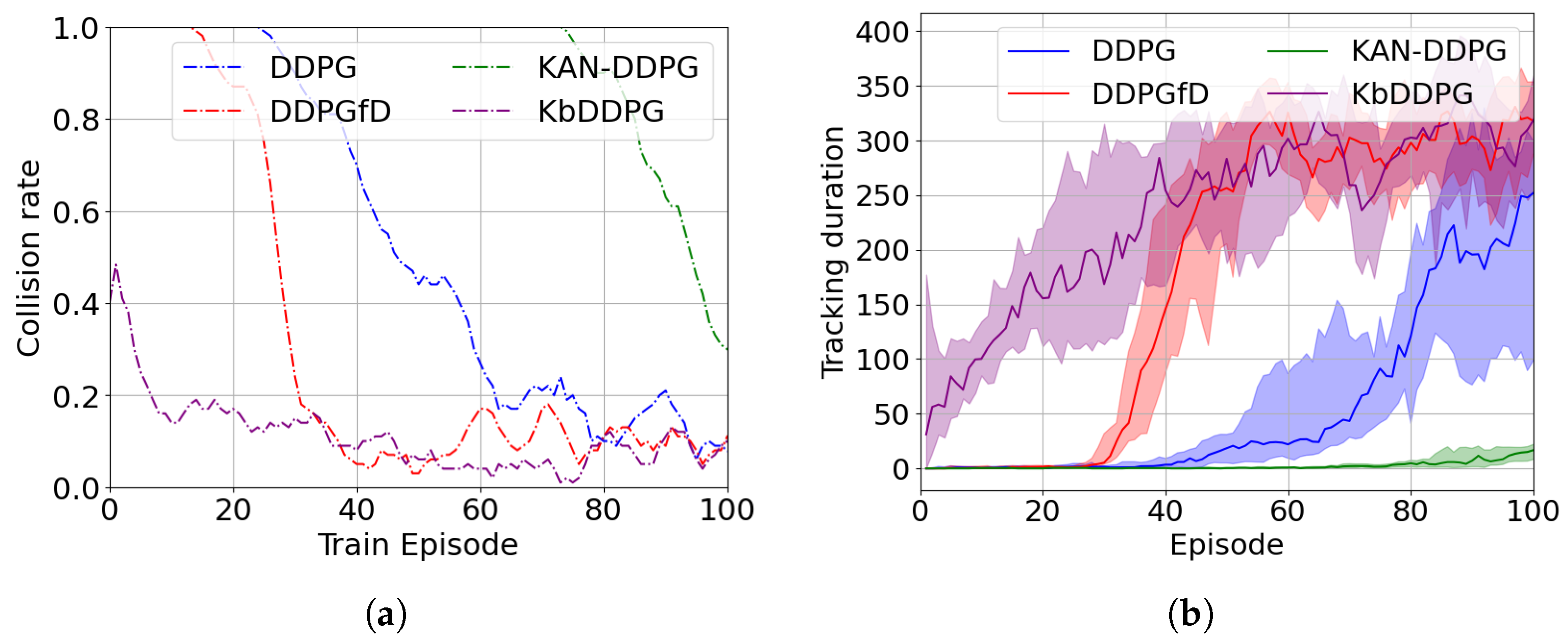
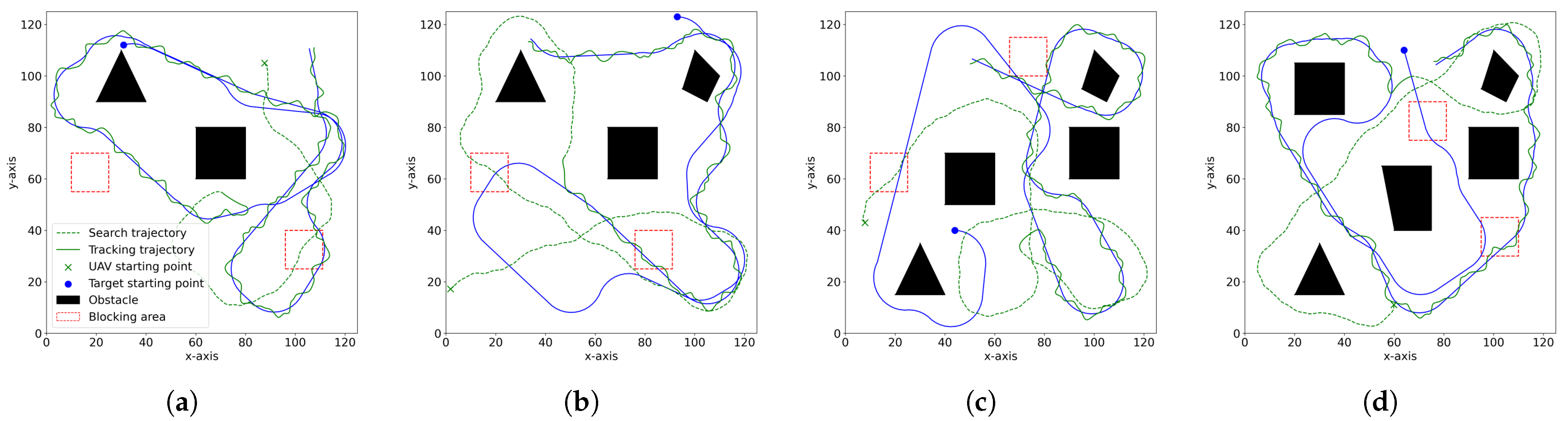
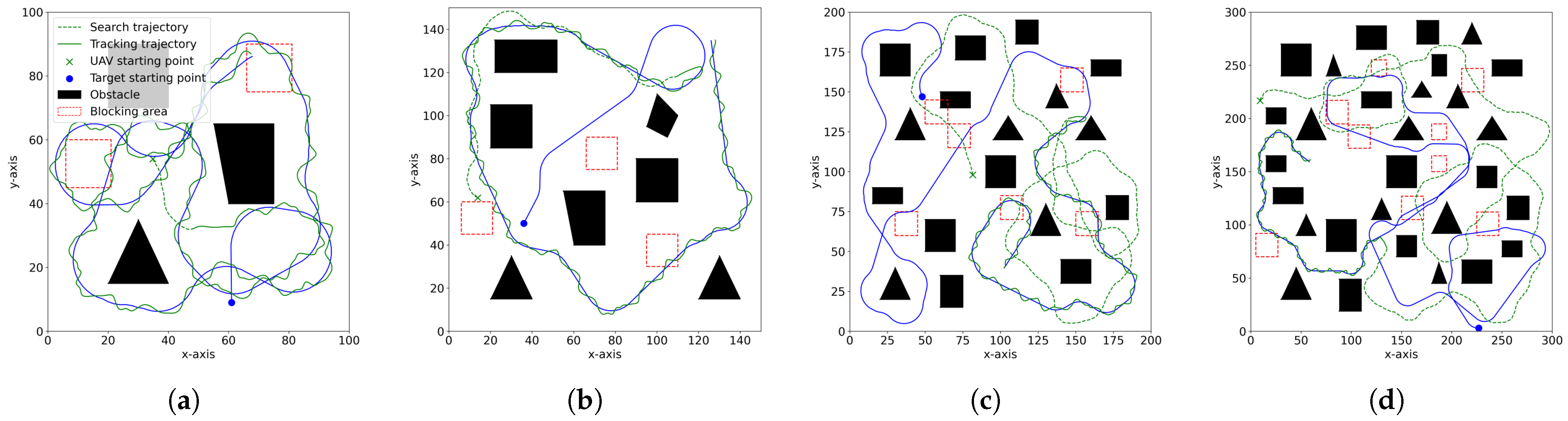
In this paper, we focus on the UAV target search and tracking problem. We use the GPR model to predict the target’s trajectory, addressing the target loss issue. Furthermore, we extend the concept of spatial information entropy to target search. To address the issue of low sample efficiency in DRL, we propose a novel DRL algorithm based on KANs. A large number of simulation results demonstrate that, compared to other DRL algorithms, our method shows superior convergence performance. Moreover, due to the application of spatial information entropy, our method outperforms existing path planning algorithms in target search.
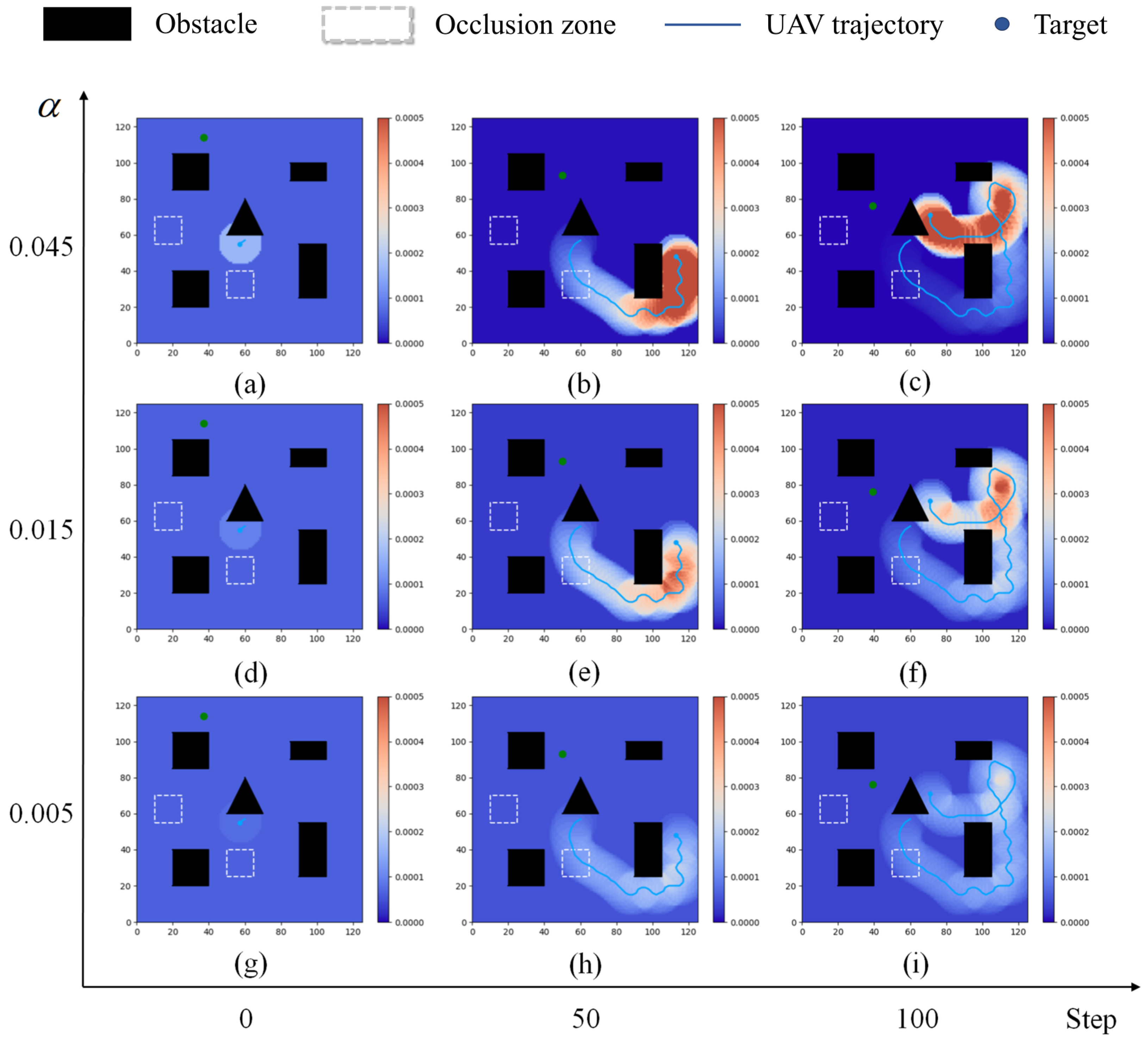
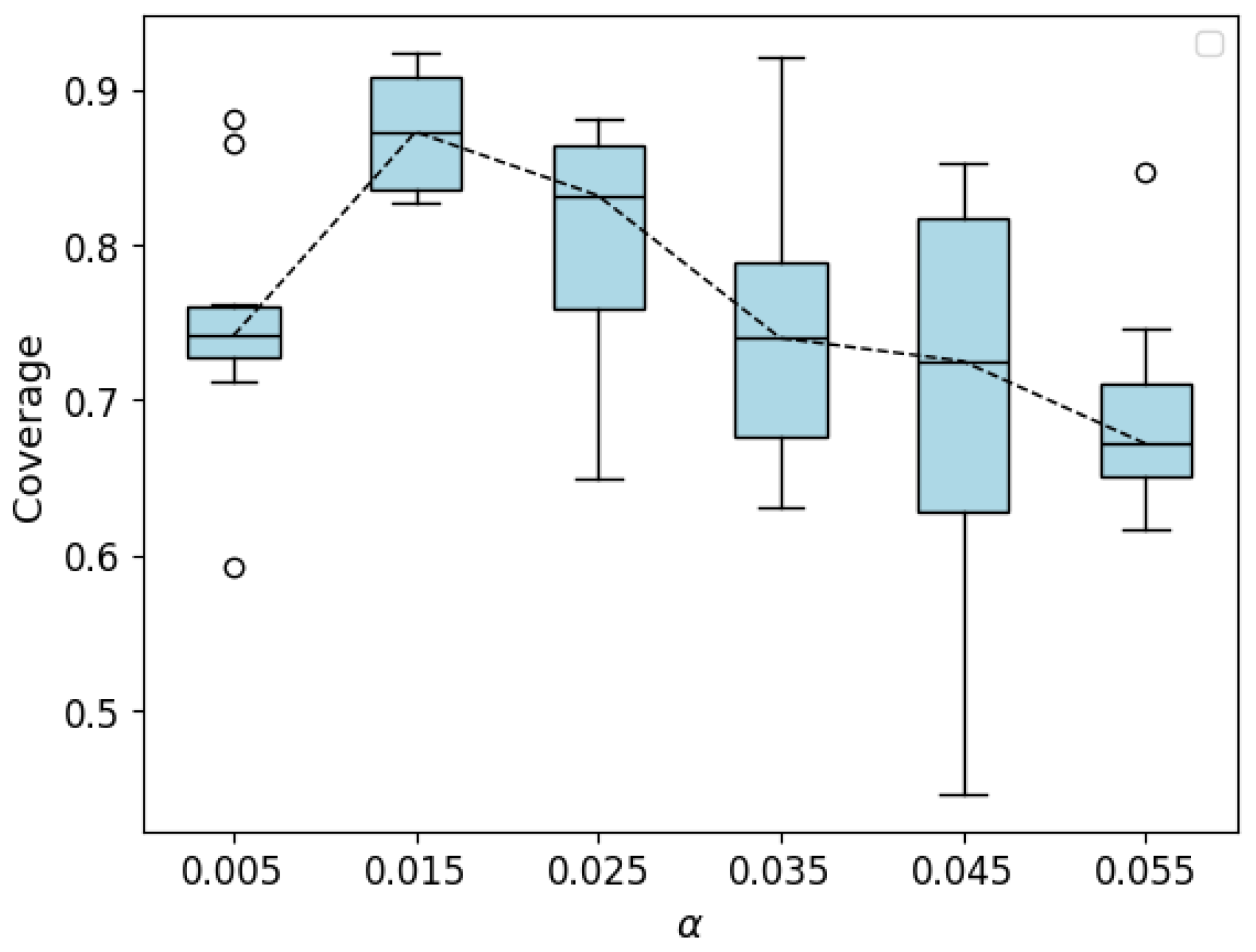
However, in the simulation, we made the simple assumption that the target’s next state only depends on the current state. In reality, the target’s movement contains higher-order dependencies, its behavior is more unpredictable, and it may even exhibit evasive actions against the searching UAV. Therefore, more reasonable modeling of the target’s movement will be a direction for our future research. Additionally, our study on the information correlation density decay coefficient alpha is limited to the optimal value in the same environment. However, the decay coefficient can be designed to adjust adaptively according to the environment. Thus, our future work will consider introducing an adaptive adjustment mechanism to enhance the flexibility and robustness of the algorithm in different dynamic environments. Meanwhile, although our virtual environment design considers factors such as obstacles, occlusion zones, and target movement, to simplify the study and improve computational efficiency, we still adopted simplified modeling for UAV dynamics, sensor noise, and target behavior, and restricted the environment to a 2D space. In real environments, UAV flight dynamics are often more complex, with various random noises bringing additional interference to the UAV’s decision making. There is often a performance gap between the simulation environment and real-world applications. We have not yet conducted comprehensive tests on real UAV platforms, and we plan to explore the deployment of DRL algorithms on real UAVs in future work, further improving the method to address more non-ideal factors in real environments. Finally, this paper only verifies the impact of relatively simple prior policies on the algorithm. In future work, we will delve deeper into the reinforcement learning algorithm based on KANs to explore its potential in complex tasks and further improve the algorithm’s performance in high-dimensional continuous action spaces.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}