


Precise Position Estimation of Road Users by Extracting Object-Specific Key Points for Embedded Edge Cameras


Abstract
1. Introduction
2. Related Works
2.1. Car Detection
2.2. Pedestrian Detection
2.3. Cyclist (Motorcyclist) and E-Scooter Rider Detection
3. Proposed Method
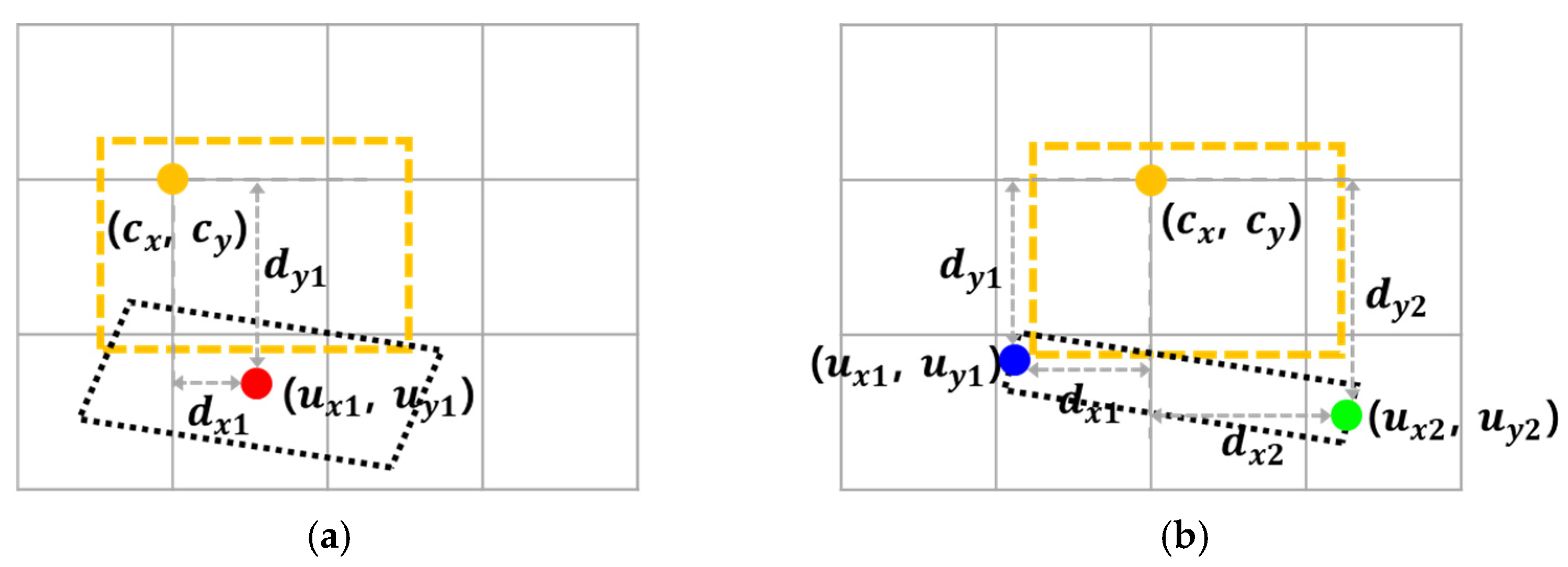
3.1. Definition of the One-Point
3.2. Definition of the Two-Point
3.3. Implementation Details
3.3.1. Detector Implementation with YOLOv7
3.3.2. Output Format of the One-Point and Two-Point Detectors
3.4. Network Simplification and Embedding
4. Experimental Results
4.1. Experimental Setup
4.2. Evaluation and Analysis
4.3. Network Simplification and Embedding
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J. Dair-v2x: A large-scale dataset for vehicle-infrastructure cooperative 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21361–21370. [Google Scholar]
- Cong, Z.; Li, K.; Zhang, R.; Peng, T.; Zong, C. Phase diagram in multi-phase heterogeneous traffic flow model integrating the perceptual range difference under human-driven and connected vehicles environment. Chaos Solitons Fractals 2024, 182, 114791. [Google Scholar]
- Ku, J.; Mozifian, M.; Lee, J.; Harakeh, A.; Waslander, S.L. Joint 3d proposal generation and object detection from view aggregation. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1–8. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multi-view 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Zhang, Y.; Lu, J.; Zhou, J. Objects are different: Flexible monocular 3d object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3289–3298. [Google Scholar]
- Brazil, G.; Liu, X. M3d-rpn: Monocular 3d region proposal network for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9287–9296. [Google Scholar]
- Liu, C.; Huynh, D.Q.; Sun, Y.; Reynolds, M.; Atkinson, S. A vision-based pipeline for vehicle counting, speed estimation, and classification. IEEE Trans. Intell. Transp. Syst. 2020, 22, 7547–7560. [Google Scholar]
- Wang, C.; Musaev, A. Preliminary research on vehicle speed detection using traffic cameras. In Proceedings of the IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 3820–3823. [Google Scholar]
- Giannakeris, P.; Kaltsa, V.; Avgerinakis, K.; Briassouli, A.; Vrochidis, S.; Kompatsiaris, I. Speed estimation and abnormality detection from surveillance cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–23 June 2018; pp. 93–99. [Google Scholar]
- Gupta, I.; Rangesh, A.; Trivedi, M. 3D Bounding Boxes for Road Vehicles: A One-Stage, Localization Prioritized Approach using Single Monocular Images. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Zhang, B.; Zhang, J. A traffic surveillance system for obtaining comprehensive information of the passing vehicles based on instance segmentation. IEEE Trans. Intell. Transp. Syst. 2020, 22, 7040–7055. [Google Scholar]
- Li, B.; Ouyang, W.; Sheng, L.; Zeng, X.; Wang, X. Gs3d: An efficient 3d object detection framework for autonomous driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1019–1028. [Google Scholar]
- Fang, J.; Zhou, L.; Liu, G. 3d bounding box estimation for autonomous vehicles by cascaded geometric constraints and depurated 2d detections using 3d results. arXiv 2019, arXiv:1909.01867. [Google Scholar]
- Zhu, M.; Zhang, S.; Zhong, Y.; Lu, P.; Peng, H.; Lenneman, J. Monocular 3d vehicle detection using uncalibrated traffic cameras through homography. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September 2021; pp. 3814–3821. [Google Scholar]
- Kim, G.; Jung, H.G.; Suhr, J.K. CNN-Based Vehicle Bottom Face Quadrilateral Detection Using Surveillance Cameras for Intelligent Transportation Systems. Sensors 2023, 23, 6688. [Google Scholar] [CrossRef]
- Gählert, N.; Wan, J.J.; Weber, M.; Zöllner, J.M.; Franke, U.; Denzler, J. Beyond bounding boxes: Using bounding shapes for real-time 3d vehicle detection from monocular rgb images. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 675–682. [Google Scholar]
- Qin, Z.; Wang, J.; Lu, Y. Monogrnet: A geometric reasoning network for monocular 3d object localization. Proc. AAAI Conf. Artif. Intell. 2019, 33, 8851–8858. [Google Scholar]
- Carrillo, J.; Waslander, S. Urbannet: Leveraging urban maps for long range 3d object detection. In Proceedings of the 2021 IEEE International Intelligent Transportation Systems Conference (ITSC), Indianapolis, IN, USA, 19–22 September 2021; pp. 3799–3806. [Google Scholar]
- Li, P.; Zhao, H.; Liu, P.; Cao, F. Rtm3d: Real-time monocular 3d detection from object keypoints for autonomous driving. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 644–660. [Google Scholar]
- Tang, X.; Wang, W.; Song, H.; Zhao, C. CenterLoc3D: Monocular 3D vehicle localization network for roadside surveillance cameras. Complex Intell. Syst. 2023, 9, 4349–4368. [Google Scholar]
- Weber, M.; Fürst, M.; Zöllner, J.M. Direct 3d detection of vehicles in monocular images with a cnn based 3d decoder. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 417–423. [Google Scholar]
- Liu, Z.; Wu, Z.; Tóth, R. Smoke: Single-stage monocular 3d object detection via keypoint estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 996–997. [Google Scholar]
- Jiaojiao, F.; Linglao, Z.; Guizhong, L. Monocular 3D Detection for Autonomous Vehicles by Cascaded Geometric Constraints and Depurated Using 3D Results. In Proceedings of the 2020 3rd International Conference on Unmanned Systems (ICUS), Harbin, China, 27–28 November 2020; pp. 954–959. [Google Scholar]
- Mauri, A.; Khemmar, R.; Decoux, B.; Haddad, M.; Boutteau, R. Lightweight convolutional neural network for real-time 3D object detection in road and railway environments. J. Real-Time Image Process. 2022, 19, 499–516. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Mousavian, A.; Anguelov, D.; Flynn, J.; Kosecka, J. 3d bounding box estimation using deep learning and geometry. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7074–7082. [Google Scholar]
- Ahmed, S.; Huda, M.N.; Rajbhandari, S.; Saha, C.; Elshaw, M.; Kanarachos, S. Pedestrian and cyclist detection and intent estimation for autonomous vehicles: A survey. Appl. Sci. 2019, 9, 2335. [Google Scholar] [CrossRef]
- Li, X.; Li, L.; Flohr, F.; Wang, J.; Xiong, H.; Bernhard, M.; Pan, S.; Gavrila, D.M.; Li, K. A unified framework for concurrent pedestrian and cyclist detection. IEEE Trans. Intell. Transp. Syst. 2016, 18, 269–281. [Google Scholar]
- Zhou, C.; Yuan, J. Bi-box regression for pedestrian detection and occlusion estimation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 135–151. [Google Scholar]
- Cai, J.; Lee, F.; Yang, S.; Lin, C.; Chen, H.; Kotani, K.; Chen, Q. Pedestrian as points: An improved anchor-free method for center-based pedestrian detection. IEEE Access 2020, 8, 179666–179677. [Google Scholar] [CrossRef]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7103–7112. [Google Scholar]
- Rezaei, M.; Azarmi, M.; Mir, F.M.P. Traffic-Net: 3D traffic monitoring using a single camera. arXiv 2021, arXiv:2109.09165 2021. [Google Scholar] [CrossRef]
- Liu, X.; Xue, N.; Wu, T. Learning auxiliary monocular contexts helps monocular 3d object detection. Proc. AAAI Conf. Artif. Intell. 2022, 36, 1810–1818. [Google Scholar]
- Mauri, A.; Khemmar, R.; Decoux, B.; Haddad, M.; Boutteau, R. Real-time 3D multi-object detection and localization based on deep learning for road and railway smart mobility. J. Imaging 2021, 7, 145. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Flohr, F.; Yang, Y.; Xiong, H.; Braun, M.; Pan, S.; Li, K.; Gavrila, D.M. A new benchmark for vision-based cyclist detection. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 1028–1033. [Google Scholar]
- Boonsirisumpun, N.; Puarungroj, W.; Wairotchanaphuttha, P. Automatic detector for bikers with no helmet using deep learning. In Proceedings of the 2018 22nd International Computer Science and Engineering Conference (ICSEC), Chiang Mai, Thailand, 21–24 November 2018; pp. 1–4. [Google Scholar]
- Dollár, P.; Appel, R.; Belongie, S.; Perona, P. Fast feature pyramids for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 1532–1545. [Google Scholar] [CrossRef] [PubMed]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.; Ramanan, D. Object detection with discriminatively trained part-based models. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 1627–1645. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Chen, H.H.; Lin, C.C.; Wu, W.Y.; Chan, Y.M.; Fu, L.C.; Hsiao, P.Y. Integrating appearance and edge features for on-road bicycle and motorcycle detection in the nighttime. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 354–359. [Google Scholar]
- Apurv, K.; Tian, R.; Sherony, R. Detection of e-scooter riders in naturalistic scenes. arXiv 2021, arXiv:2111.14060. [Google Scholar]
- Gilroy, S.; Mullins, D.; Jones, E.; Parsi, A.; Glavin, M. E-scooter rider detection and classification in dense urban environments. Results Eng. 2022, 16, 100677. [Google Scholar] [CrossRef]
- Ahmed, D.B.; Diaz, E.M. Survey of machine learning methods applied to urban mobility. IEEE Access 2022, 10, 30349–30366. [Google Scholar] [CrossRef]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H. Designing network design strategies through gradient path analysis. arXiv 2022, arXiv:2211.04800 2022. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part V, 13. pp. 740–755. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2736–2744. [Google Scholar]
- Han, S.; Pool, J.; Tran, J.; Dally, W. Learning both weights and connections for efficient neural network. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar]
- Lee, Y.; Moon, Y.H.; Park, J.Y.; Min, O.G. Recent R&D trends for lightweight deep learning. Electron. Telecommun. Trends 2019, 34, 40–50. [Google Scholar]
- Torch-Pruning. Available online: https://github.com/VainF/Torch-Pruning (accessed on 8 May 2024).
- Fang, G.; Ma, X.; Song, M.; Mi, M.B.; Wang, X. Depgraph: Towards any structural pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 16091–16101. [Google Scholar]
- Lee, Y.J.; Jung, H.G.; Suhr, J.K. Semantic Segmentation Network Slimming and Edge Deployment for Real-Time Forest Fire or Flood Monitoring Systems Using Unmanned Aerial Vehicles. Electronics 2023, 12, 4795. [Google Scholar] [CrossRef]
- Devernay, F.; Faugeras, O. Straight lines have to be straight. Mach. Vis. Appl. 2001, 13, 14–24. [Google Scholar]
- AI Hub. Available online: https://www.aihub.or.kr/aihubdata/data/view.do?currMenu=&topMenu=&aihubDataSe=data&dataSetSn=169 (accessed on 21 March 2023).
- Caprile, B.; Torre, V. Using vanishing points for camera calibration. Int. J. Comput. Vis. 1990, 4, 127–139. [Google Scholar] [CrossRef]
- Cipolla, R.; Drummond, T.; Robertson, D. Camera Calibration from Vanishing Points in Image of Architectural Scenes. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 13–16 September 1999. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | Test | |
|---|---|---|
| Customized | 9752 | 1724 |
| AIHUB | 1682 | 293 |
| Total | 11434 | 2017 |
| Car | Pedestrian | Cyclist | e-Scooter | Total | |
|---|---|---|---|---|---|
| Training | 9073 | 9734 | 8869 | 3327 | 31,003 |
| Test | 1665 | 1617 | 1555 | 533 | 5370 |
| Class | Existing Method | One-Point Detector | Two-Point Detector | |||
|---|---|---|---|---|---|---|
| AP | mPE | AP | mPE | AP | mPE | |
| Car | 99.32% | 0.3609 | 99.29% | 0.0654 | 99.21% | 0.0710 |
| Pedestrian | 83.81% | 0.1750 | 82.92% | 0.1153 | 82.29% | 0.1201 |
| Cyclist | 99.38% | 0.2045 | 98.90% | 0.0682 | 98.67% | 0.0741 |
| E-scooter | 97.66% | 0.1742 | 98.25% | 0.0948 | 95.99% | 0.1011 |
| Average | 95.04% (mAP) | 0.2452 | 94.84% (mAP) | 0.0821 | 94.04% (mAP) | 0.0875 |
| Class | Two-Point Detector’s Results | |
|---|---|---|
| mPEOrdered | mPEOrderless | |
| Car | 0.1061 | 0.0993 |
| Pedestrian | 0.1760 | 0.1452 |
| Cyclist | 0.1119 | 0.1023 |
| E-scooter | 0.1405 | 0.1224 |
| Average | 0.1291 | 0.1142 |
| Target Speed-Up | mAP (%) | mPE | FPS | Model Size (MB) | GFLOPs |
|---|---|---|---|---|---|
| 1 (baseline) | 94.70 | 0.1147 | 4.85 | 71.44 | 98.23 |
| 2 | 94.21 | 0.1138 | 7.03 | 35.28 | 48.63 |
| 3 | 92.64 | 0.1086 | 7.86 | 23.64 | 32.05 |
| 4 | 91.51 | 0.1211 | 10.61 | 17.65 | 23.71 |
| Target Speed-Up | mAP (%) | mPE | mPEOrdered | mPEOrderless | FPS | Model Size (MB) | GFLOPs |
|---|---|---|---|---|---|---|---|
| 1 (baseline) | 93.46 | 0.1058 | 0.1541 | 0.1399 | 4.90 | 71.60 | 98.49 |
| 2 | 91.91 | 0.1076 | 0.1567 | 0.1417 | 6.62 | 35.04 | 48.59 |
| 3 | 91.28 | 0.1042 | 0.1496 | 0.1385 | 8.44 | 24.21 | 32.66 |
| 4 | 89.30 | 0.1060 | 0.1553 | 0.1404 | 10.17 | 18.63 | 24.39 |
| Target Speed-Up | One-Point Detector’s Results | ||||
|---|---|---|---|---|---|
| Car AP (%) | Pedestrian AP (%) | Cyclist AP (%) | E-Scooter AP (%) | mAP (%) | |
| 1 (baseline) | 99.10% | 83.10% | 99.00% | 97.60% | 94.70% |
| 2 | 99.20% | 81.40% | 98.50% | 97.80% | 94.20% |
| 3 | 99.10% | 77.90% | 98.70% | 94.90% | 92.60% |
| 4 | 98.60% | 73.60% | 98.10% | 95.70% | 91.50% |
| Target Speed-Up | Two-Point Detector’s Results | ||||
|---|---|---|---|---|---|
| Car AP (%) | Pedestrian AP (%) | Cyclist AP (%) | E-Scooter AP (%) | mAP (%) | |
| 1 (baseline) | 99.00% | 81.80% | 98.60% | 93.46% | 93.50% |
| 2 | 98.80% | 76.60% | 98.20% | 94.10% | 91.91% |
| 3 | 98.50% | 74.40% | 97.90% | 94.30% | 91.28% |
| 4 | 97.80% | 69.60% | 97.00% | 92.70% | 89.30% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, G.; Yoo, J.H.; Jung, H.G.; Suhr, J.K. Precise Position Estimation of Road Users by Extracting Object-Specific Key Points for Embedded Edge Cameras. Electronics 2025, 14, 1291. https://doi.org/10.3390/electronics14071291
Kim G, Yoo JH, Jung HG, Suhr JK. Precise Position Estimation of Road Users by Extracting Object-Specific Key Points for Embedded Edge Cameras. Electronics. 2025; 14(7):1291. https://doi.org/10.3390/electronics14071291
Chicago/Turabian StyleKim, Gahyun, Ju Hee Yoo, Ho Gi Jung, and Jae Kyu Suhr. 2025. "Precise Position Estimation of Road Users by Extracting Object-Specific Key Points for Embedded Edge Cameras" Electronics 14, no. 7: 1291. https://doi.org/10.3390/electronics14071291
APA StyleKim, G., Yoo, J. H., Jung, H. G., & Suhr, J. K. (2025). Precise Position Estimation of Road Users by Extracting Object-Specific Key Points for Embedded Edge Cameras. Electronics, 14(7), 1291. https://doi.org/10.3390/electronics14071291