



An Automated Framework for Prioritizing Software Requirements


Abstract

1. Introduction
- Requirements Engineering (RE)—Covers the entire process of gathering, analyzing, specifying, and validating requirements.
- Requirement Prioritization (RP) [Main Focus]—A critical subtask of RE, determining which requirements should be addressed first.
2. Related Work
- 1.
- StakeRare: This approach is a stakeholder-based RP technique that utilizes a weighting mechanism based on stakeholders’ influence and expertise. While StakeRare effectively incorporates stakeholder perspectives, it suffers from biases due to subjective prioritization and the varying expertise levels of stakeholders. In contrast, our proposed method eliminates stakeholder dependency, reducing subjective bias and ensuring consistency through automated processing of raw requirements.
- 2.
- SRPTackle: SRPTackle integrates a hybrid approach that combines stakeholder preferences with prioritization models. Similarly to StakeRare, it involves active participation from domain experts to rank requirements. In the SRPTackle method, each stakeholder is assigned a Stakeholder Participation Value (SPV) based on their level of involvement. Using these SPVs, a Requirement Priority Value (RPV) is calculated for each requirement. The requirements are then classified into three predefined priority levels: high, medium, and low, according to their RPVs. Finally, the Binary Search Tree (BST) algorithm is used to sort the requirements.The foundation of this approach relies heavily on stakeholder-defined values, as RPV is determined based on the stakeholders’ participation and their assigned initial weights for each requirement.In contrast, our proposed method eliminates the dependency on stakeholder input, ensuring a fully automated approach. Instead of relying on manually assigned weights, our framework leverages AI-driven clustering and prioritization, using BERT for contextual representation, K-Means for clustering, and centroid similarity for ranking. This automation not only reduces subjectivity but also enhances scalability, making it more suitable for large and complex requirement datasets.
- 3.
- Genetic K-Means: This method applies evolutionary optimization techniques to cluster stakeholders. The primary objective is to enhance the K-Means algorithm for more effective stakeholder clustering. While requirement prioritization is mentioned as a challenge in this approach, it is not actually performed; instead, the focus is solely on clustering stakeholders. Our method, on the other hand, clusters the requirements, determines the optimal number of clusters using Elbow and Silhouette Score methods, ensuring an efficient and scalable clustering process without the complexity of genetic algorithms, and then prioritizing them.All the mentioned methods initially assign numerical values to the requirements in various ways before ultimately prioritizing them.However, in our proposed method, no numerical values are assigned to the requirements. Instead, the raw natural language requirements themselves serve as the real input to the framework. Both clustering and prioritization are performed directly on the requirements without any predefined numerical weighting, ensuring a more data-driven and automated approach.
- Analytical Hierarchy Process (AHP): Uses pairwise comparisons to assign weights to requirements.
- MoSCoW Method: Categorizes requirements into Must have, Should have, Could have, and Do not have.
- The 100-Dollar Method: Stakeholders distribute 100 points (or dollars) among requirements based on importance.
- Cumulative Voting: Similar to the 100-dollar method but allows more flexibility in voting.
- Value-Based Prioritization: Prioritizes requirements based on business value and cost–benefit analysis.
- Hybrid Methods: Combine multiple techniques (e.g., AHP + MoSCoW) for more accurate prioritization.
3. Background
3.1. RALIC Project
Key Aspects of the RALIC Project
- Requirements: The project aimed to enhance security and access control, design a multifunctional access card, and reduce operational costs.
- Stakeholders: More than 60 stakeholder groups from various UCL faculties and departments participated, highlighting a diversity of perspectives and, at times, conflicting requirements.
- Ranking and Weighting: Methods such as pairwise comparison and hierarchical organization were used to prioritize requirements at different levels.
- Ground Truth: Derived from extensive project documentation and validated through interviews with management-level stakeholders to ensure accuracy and completeness [5].
- Rate—A scoring system where requirements are assigned a value between −1 and 5 based on their importance (method used in this paper)
- Rank—A normalized ranking where values range between 0 and 1, indicating relative importance.
- Point—A distribution-based approach where stakeholders allocate a total of 100 points among different requirements, reflecting their perceived significance.
3.2. Preprocessing
- Stop word removal: Common words such as “the”, “is”, and “and” are removed to reduce data dimensionality, although their removal can be context-dependent.
- Lemmatization and stemming: These processes reduce words to their base or dictionary form and root form, respectively, aiding in the consistency and performance of text analysis tasks.
3.3. BERT Model
3.3.1. Key Features of BERT
- 1.
- Bidirectional context understanding: Unlike traditional models (e.g., LSTMs or unidirectional transformers), BERT processes text in both directions simultaneously, capturing richer context.
- 2.
- Masked Language Model (MLM): Instead of predicting the next word (like GPT), BERT randomly masks some words in a sentence and tries to predict them using the surrounding context.
- 3.
- Next-Sentence Prediction (NSP): blackBERT is pre-trained to determine whether two sentences logically follow each other, improving their ability to understand relationships between sentences.
3.3.2. Mathematical Formulation
Token Embeddings in BERT
Self-Attention Mechanism (Scaled Dot-Product Attention)
Masked Language Model (MLM)
Next Sentence Prediction (NSP)
3.4. K-Means Clustering Algorithm
3.4.1. K-Means Algorithm Steps
- 1.
- Select K: Choose the number of clusters, K.
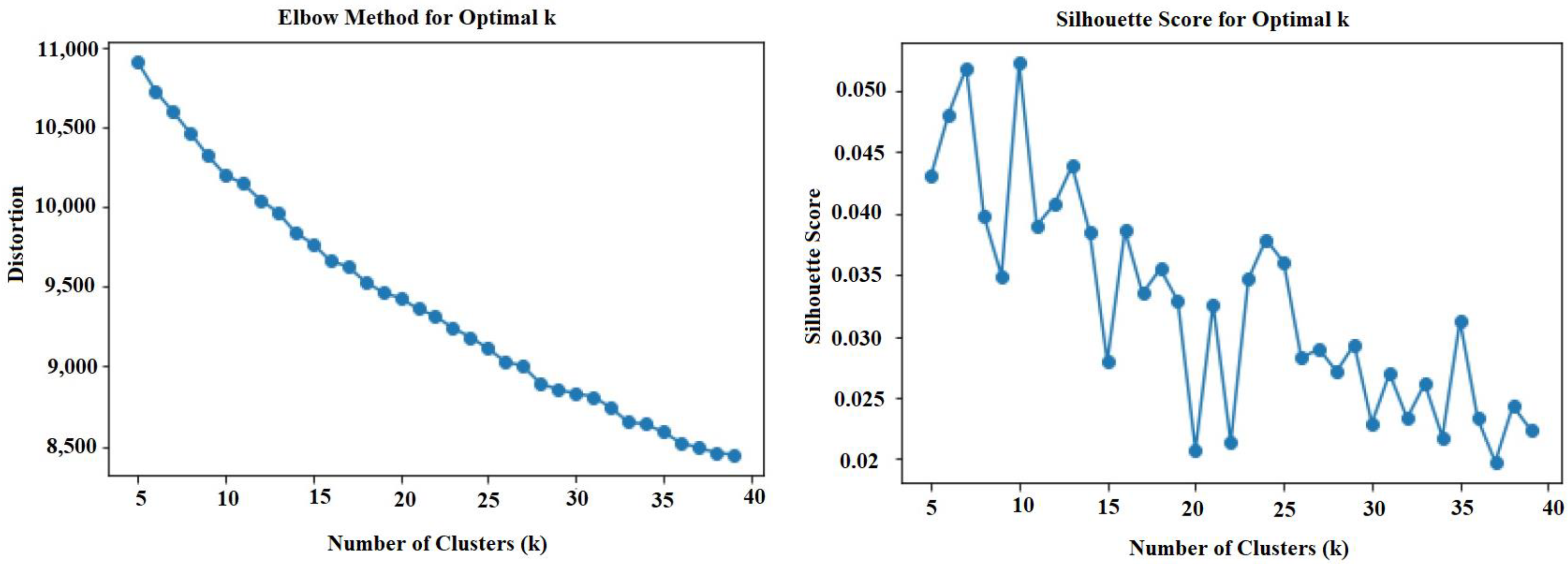
- The Elbow Method or Silhouette Score is often used to find the optimal K.
- 2.
- Initialize Centroids: Select K points as initial cluster centroids.
- 3.
- Assign Points to Clusters: Each data point is assigned to the nearest centroid using the Euclidean distance.
- 4.
- Update Centroids: Compute the new centroid for each cluster by taking the mean of all points assigned to that cluster.
- 5.
- Repeat Steps 3–4 until the centroids no longer change or a predefined number of iterations reached.
3.4.2. Mathematical Formula: Objective Function (Minimizing Inertia)
- Initialization: Initially, the algorithm selects k data points as the centroids of the clusters. These centroids serve as the reference points for measuring similarity during the clustering process.
- Document Representation: For text data, each or sentence is converted into a vector representation, typically using techniques like word embeddings (e.g., BERT).
- Assignment Step: Each document is assigned to the cluster whose centroid is the most similar to it. The similarity between a document’s vector and the centroid is often measured using cosine similarity or Euclidean distance. (Cosine similarity measures the angle between two vectors, and a smaller angle means the vectors are closer to each other.)
- The sentence is assigned to the cluster with the centroid that is closest in terms of the chosen similarity measure.
- Update Step: Once all sentences have been assigned to clusters, the centroid of each cluster is updated. The new centroid is the mean of the document vectors within that cluster. This new centroid is then used to measure similarity in the next iteration.
- Iteration: The algorithm repeats the assignment and update steps until convergence, meaning the centroids no longer change significantly or a maximum number of iterations is reached.
3.5. Elbow Method
3.6. Silhouette Score
3.7. Weighting Methods in Multi-Criteria Decision Making (MCDM)
3.8. Mean Absolute Error (MAE)
3.9. Precision, Recall, and F1-Score
- Precision represents the proportion of correctly identified high-priority requirements among the top-ranked results, indicating how accurate the framework is in selecting relevant requirements.
- Recall measures the proportion of actual high-priority requirements that were successfully retrieved by the framework, showing how well it captures all relevant requirements. There is often a trade-off between precision and recall, as increasing the number of retrieved items may improve recall but reduce precision.
- To balance these two metrics, F1-Score is used, which is the harmonic mean of precision and recall, providing a single measure of effectiveness. A high F1-score indicates that the framework performs well in both selecting relevant requirements and ensuring comprehensive retrieval, making it a crucial metric for evaluating automated requirement prioritization [19].
4. Proposed Method
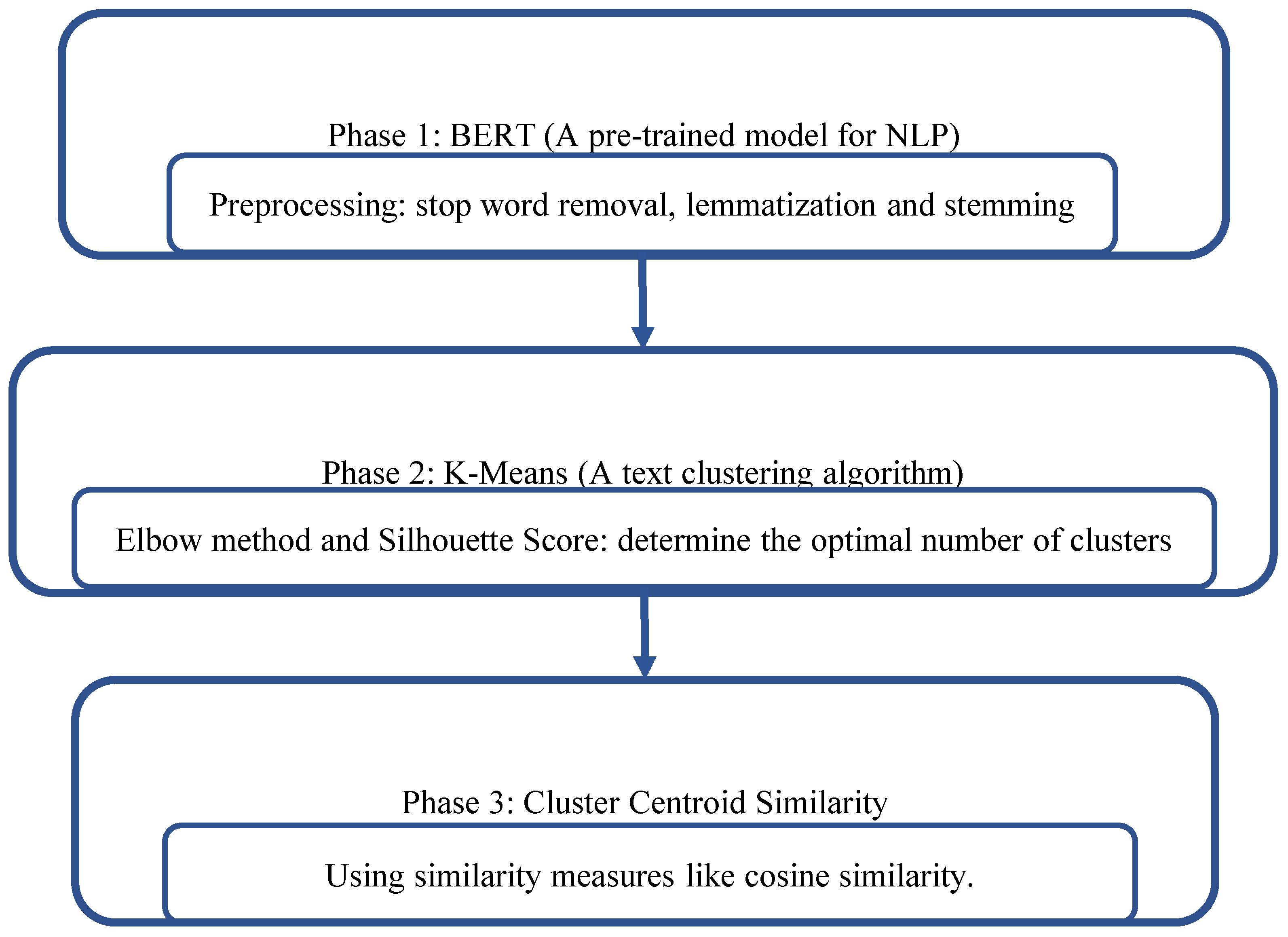
4.1. Phase 1: Preprocessing and BERT Embedding
- Stopword removal: Removes commonly used but uninformative words.
- Lemmatization: Reduces words to their base or dictionary forms.
- Stemming: Removes suffixes from words to reduce them to their root or stem form.
4.2. Phase 2: Clustering with K-Means
- 1.
- Efficiency and Scalability: K-Means is computationally efficient and scalable for large datasets, making it suitable for handling a high number of requirements. In contrast, Agglomerative Clustering has higher time complexity (O(n²) or O(n³) depending on the implementation), making it less efficient for large-scale requirement sets.
- 2.
- Interpretability: K-Means provides clear, well-defined clusters with centroids, which help in structuring the prioritization process. Hierarchical clustering methods like Agglomerative Clustering generates dendrograms, which are not as straightforward as defining ranked groups.
- 3.
- Requirement Nature: Since the requirements were transformed into numerical vector representations using BERT embeddings, K-Means was well suited for handling these representations. Density-based clustering techniques such as DBSCAN, which rely on proximity-based density estimation, were found to be less effective in this context.
- 4.
- Empirical Results: To ensure the suitability of K-Means, a comparative experiment was conducted with Agglomerative Clustering. The results showed that while Agglomerative Clustering could form meaningful hierarchical structures, it struggled with the high-dimensional embeddings generated by BERT and had higher computational complexity. Additionally, K-Means provided a more balanced distribution of requirements across clusters, making it preferable for subsequent prioritization.
- 5.
- Necessity of a Centroid-Based Clustering Method: A key requirement of the proposed framework was to prioritize requirements within each cluster using centroid similarity (Phase 3). Since K-Means inherently assigns a centroid to each cluster, it allowed for a straightforward, objective prioritization process using cosine similarity between each requirement and the cluster centroid. Hierarchical clustering methods, including Agglomerative Clustering, do not generate explicit centroids, making them unsuitable for this purpose.
4.3. Phase 3: Prioritization Within Clusters
- 1.
- Objectives are prioritized first.
- 2.
- Requirements within each objective are then ranked separately.
- 3.
- Finally, specific requirements within each requirement (if there are any) are prioritized independently.
5. Results
- Improved efficiency: The system automated library access and borrowing processes, reducing manual data entry and processing time.
- Centralized management: RALIC streamlined user authentication for library access, ensuring that only authorized members could enter or borrow materials.
- Enhanced security: The system allowed the real-time monitoring of library access logs, reducing unauthorized use and security breaches.
- Convenience for users: Instead of managing multiple cards, students and staff had a single card for access to library resources, eliminating the need for barcode scanning at specific locations.
6. Discussion
- No manual numerical weighting is needed before prioritization—the framework understands and processes textual requirements directly.
- Uses contextual embeddings from BERT, making it more effective than TF-IDF or rule-based NLP approaches.
- Prioritizes requirements within each cluster based on centroid similarity, ensuring that the most representative requirements are ranked higher.
- Provides a scalable and domain-independent solution that can generalize to different projects beyond RALIC.
6.1. Rationale for Automation
6.2. Advantages of the Automated Framework
- Consistency: Automation ensures that the same criteria are applied uniformly to all requirements, promoting consistency in the prioritization outcomes.
- Scalability: The ability to process large volumes of requirements without incremental costs or delays is another significant advantage, making the framework highly scalable and adaptable to various project sizes.
- Speed: Automated systems can process requirements much faster than human teams, enabling quicker transitions from the planning phase to implementation.
6.3. Challenges and Limitations
- Complexity in Setup: Configuring the BERT and K-Means algorithms to accurately interpret and cluster complex requirement statements can be challenging and time-intensive.
- Loss of Human Insight: The absence of stakeholder input might lead to the oversight of context-specific priorities that are not apparent through textual analysis alone.
- Adaptability Issues: The framework’s dependence on predefined models and algorithms might limit its adaptability to highly dynamic or unconventional project requirements.
- Handling Evolving RequirementsSince requirements can change over time, our framework’s automated and iterative nature allows it to be reapplied periodically to accommodate new or modified requirements. The BERT-based embeddings ensure that semantic similarities remain valid, even if new requirements are introduced. Potential Enhancement: A mechanism for incremental updates could be explored in future work, where new requirements are dynamically incorporated without rerunning the entire pipeline.
- Managing Conflicting PrioritiesOur clustering approach groups similar requirements together, reducing the risk of conflicting requirements being prioritized at opposite ends of the ranking. However, if conflicts arise, a hybrid approach could be integrated in future work, combining automated prioritization with stakeholder opinions for the final stages of the proposed approach.
- Adapting to Dynamic Project ConstraintsProject constraints, such as budget, time, and resource limitations, can impact requirement prioritization. Our method can be extended by introducing constraint-aware ranking: For example, using a cost–benefit analysis to ensure that high-priority requirements are also feasible within the given constraints. If a requirement is ranked high but exceeds constraints, a constraint-adjusted prioritization step could be introduced.
6.4. Ethical and Practical Challenges in Requirement Prioritization Automation
- 1.
- While automation improves objectivity and efficiency, it removes valuable domain knowledge and contextual insights from stakeholders. This can lead to misinterpretation of nuanced requirements, especially in complex projects where expert judgment is essential.
- 2.
- Automated methods, including clustering and similarity-based ranking, rely on the data they are trained on. If the dataset is imbalanced or contains hidden biases, the prioritization results may reflect and even reinforce those biases, potentially leading to unfair or suboptimal decisions.
- 3.
- Many automated approaches, particularly those based on machine learning models like BERT, operate as “black boxes”. Ensuring that prioritization decisions are interpretable and justifiable to stakeholders is crucial for trust and adoption.
- 4.
- Removing human decision-makers from the prioritization process may raise ethical concerns, especially in domains like healthcare, public policy, or critical infrastructure, where stakeholder values and ethical considerations play a significant role.
- 5.
- Automated approaches need to be adaptable to evolving requirements, changing business needs, and dynamic stakeholder expectations. A rigid automation framework might not be suitable for projects where flexibility is essential.
6.5. Proposed Framework’s Practical Applicability
- 1.
- Smart City Infrastructure Management Systems
- Scenario:
- –
- A city government is developing an integrated smart city management system, which includes traffic monitoring, public transportation, security surveillance, and waste management.
- Challenges:
- –
- Hundreds of requirements from multiple departments (e.g., transport, security, public works, IT).
- –
- Conflicting priorities between stakeholders (e.g., security teams prioritize surveillance, but transport teams prioritize real-time traffic data).
- –
- Manual prioritization is slow and prone to biases.
- How our framework helps:
- –
- Clusters and prioritizes requirements automatically, reducing dependence on stakeholder input.
- –
- Ensures objective ranking based on inherent requirement characteristics rather than subjective opinions.
- –
- Enhances scalability, making it easier to manage large, evolving requirement sets.
- 2.
- Large-Scale Healthcare Management Systems
- Scenario
- –
- A national healthcare system is upgrading its electronic medical records (EMR) system to integrate patient data, telemedicine services, and AI-based diagnostics.
- Challenges:
- –
- Thousands of requirements across multiple domains (doctors, hospitals, insurance providers, IT teams, regulatory agencies).
- –
- High complexity due to legal and security constraints (e.g., patient data privacy).
- –
- Traditional prioritization methods struggle to account for dynamic changes in medical technology and regulations.
- How our framework helps:
- –
- Uses BERT-based clustering to group requirements by theme (e.g., security, usability, compliance).
- –
- Ensures high-priority healthcare requirements (e.g., patient data protection, emergency response) are not overshadowed by less critical ones.
- –
- Reduces human effort in requirement analysis and decision making, enabling faster project execution.
6.6. Future Directions
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Umar, M.A.; Lano, K. Advances in automated support for requirements engineering: A systematic literature review. Requir. Eng. 2024, 29, 177–207. [Google Scholar]
- Khan, M.A.; Azim, A.; Liscano, R.; Smith, K.; Chang, Y.K.; Tauseef, Q.; Seferi, G. Machine Learning-based Test Case Prioritization using Hyperparameter Optimization. In Proceedings of the 5th ACM/IEEE International Conference on Automation of Software Test (AST 2024), Lisbon, Portugal, 15–16 April 2024; pp. 125–135. [Google Scholar]
- Ajiga, D.; Okeleke, P.A.; Folorunsho, S.O.; Ezeigweneme, C. Navigating ethical considerations in software development and deployment in technological giants. Int. J. Eng. Res. Update 2024, 7, 50–63. [Google Scholar]
- Vestola, M. A comparison of nine basic techniques for requirements prioritization. Hels. Univ. Technol. 2010, 1–8. [Google Scholar]
- Hujainah, F.; Bakar, R.B.A.; Nasser, A.B.; Al-haimi, B.; Zamli, K.Z. SRPTackle: A semi-automated requirements prioritisation technique for scalable requirements of software system projects. Inf. Softw. Technol. 2021, 131, 106501. [Google Scholar] [CrossRef]
- Hujainah, F.; Bakar, R.B.A.; Abdulgabber, M.A.; Zamli, K.Z. Software requirements prioritisation: A systematic literature review on significance, stakeholders, techniques and challenges. IEEE Access 2018, 6, 71497–71523. [Google Scholar] [CrossRef]
- Lim, S.L.; Finkelstein, A. StakeRare: Using social networks and collaborative filtering for large-scale requirements elicitation. IEEE Trans. Softw. Eng. 2011, 38, 707–735. [Google Scholar]
- Reyad, O.; Dukhan, W.H.; Marghny, M.; Zanaty, E.A. Genetic k-means adaption algorithm for clustering stakeholders in system requirements. In Advanced Machine Learning Technologies and Applications, Proceedings of the AMLTA 2021, Cairo, Egypt, 22–24 March 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 195–204. [Google Scholar]
- Tzimos, D.; C. Gerogiannis, V.; Son, L.H.; Karageorgos, A. A Recommender System based on Intuitionistic Fuzzy Sets for Software Requirements Prioritization. In Proceedings of the 25th Pan-Hellenic Conference on Informatics, Volos, Greece, 26–28 November 2021; pp. 466–471. [Google Scholar]
- Limaylla, M.I.; Condori-Fernandez, N.; Luaces, M.R. Towards a semi-automated data-driven requirements prioritization approach for reducing stakeholder participation in SPL development. Eng. Proc. 2021, 7, 27. [Google Scholar] [CrossRef]
- Achimugu, P.; Selamat, A.; Ibrahim, R. A clustering based technique for large scale prioritization during requirements elicitation. In Recent Advances on Soft Computing and Data Mining, Proceedings of the First International Conference on Soft Computing and Data Mining (SCDM-2014) Universiti Tun Hussein Onn Malaysia, Johor, Malaysia, 16–18 June 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 623–632. [Google Scholar]
- Lim, S.L. Social Networks and Collaborative Filtering for Large-Scale Requirements Elicitation. Ph.D. Thesis, UNSW Sydney, Kensington, Australia, 2010. [Google Scholar]
- Hu, W.; Xu, D.; Niu, Z. Improved k-means text clustering algorithm based on BERT and density peak. In Proceedings of the 2021 2nd Information Communication Technologies Conference (ICTC), Nanjing, China, 7–9 May 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 260–264. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Kenton, J.D.M.W.C.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, p. 2. [Google Scholar]
- Ilyas, F.M.; Priscila, S.S. An Optimized Clustering Quality Analysis in K-Means Cluster Using Silhouette Scores. In Explainable AI Applications for Human Behavior Analysis; IGI Global: Hershey, PA, USA, 2024; pp. 49–63. [Google Scholar]
- Darji, K.; Patel, D.; Vakharia, V.; Panchal, J.; Dubey, A.K.; Gupta, P.; Singh, R.P. Watershed prioritization and decision-making based on weighted sum analysis, feature ranking, and machine learning techniques. Arab. J. Geosci. 2023, 16, 71. [Google Scholar] [CrossRef]
- Shambour, Q.Y.; Abu-Alhaj, M.M.; Al-Tahrawi, M.M. A hybrid collaborative filtering recommendation algorithm for requirements elicitation. Int. J. Comput. Appl. Technol. 2020, 63, 135–146. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Aspect | AHP (Analytic Hierarchy Process) | MoSCoW Method | MCDM (Multi-Criteria Decision Making) | SRP Tackle | Proposed Method |
|---|---|---|---|---|---|
| Type | Traditional | Traditional | hybrid (multi-criteria) | Algorithmic | Automated clustering prioritization |
| Stakeholder Involvement | High (pairwise comparisons) | High (manual categorization) | High (weight-based) | High (SPV and RPV-based) | Low (automatic prioritization) |
| Prioritization Basis | Pairwise comparisons | Expert judgment | Weight-based decision criteria | Stakeholder rank and weights | Requirement clustering & Centroid similarity |
| Automation Level | Low (manual pairwise) | Low (manual) | Medium (criteria-based automation) | Medium (algorithm-driven sorting) | High (automated requirement categorization and prioritization) |
| Scalability | Low (complex for large datasets) | Medium (simple for small datasets) | Medium (depends on criteria) | High (scalable to many stakeholders) | High (scalable to large requirement sets) |
| Computational Complexity | High ( for comparisons) | Low (categorization-based) | Medium (depends on MCDM model) | Medium (BST sorting applied) | High (clustering and cosine similarity computation) |
| Ranking Granularity | Precise (numerical weights) | Subjective (categories: must, should, etc.) | Precise (weight-based) | Three levels (high, medium, low) | Cluster-based with fine-grained granularity |
| Main Limitation | Subjectivity and lack of precise comparisons | requires expert-dependency | stakeholder dependency | Computational overhead for clustering | Dependency on clustering |
| Project Objectives | Rate |
|---|---|
| Number of stakeholders provide more than one rating | 76 |
| Number of items | 10 |
| Number of ratings | 439 |
| Requirements | |
| Number of stakeholders provide more than one rating | 76 |
| Number of items | 48 |
| Number of ratings | 1514 |
| Specific Requirements | |
| Number of stakeholders provide more than one rating | 76 |
| Number of items | 104 |
| Number of ratings | 3113 |
| ID | Short Description of Requirement | Rate (−1.5) |
|---|---|---|
| h.2 | Include payment mechanism | 1 |
| h.3 | Used for computer logon | 1 |
| g.2 | Export data to other systems | 5 |
| g.3 | Import data from other systems | 5 |
| g.1.2 | Data should not be duplicated | 4 |
| Role Rank | Stakeholder Rank | ||
|---|---|---|---|
| 1 | Security and Access Systems | 1 | Mike Dawson |
| 2 | Jason Ortiz | ||
| 3 | Nick Kyle | ||
| 4 | Paul Haywood | ||
| Rank | Project Objective | Rank | Requirement | Rank | Specific Requirement |
|---|---|---|---|---|---|
| 1 | Better user Experience | 1 | All in 1 card | 1.5 | Combine ID card and session card |
| 1.5 | Combine library card | ||||
| 3 | Combine Bloomsbury fitness card | ||||
| 4 | The combined card should not have many features | ||||
| 2 | Easier to use | 1 | More accurate scanning | ||
| 3 | Use the same access control for library entrance |
| Cluster | MAE Value | Comments |
|---|---|---|
| 1 | 1.00 | A moderate level of accuracy |
| 2 | 1.02 | A moderate level of accuracy |
| 3 | 1.33 | Acceptable deviation |
| 4 | 1.04 | A moderate level of accuracy |
| 5 | 1.01 | A moderate level of accuracy |
| 6 | 1.05 | A moderate level of accuracy |
| 7 | 0.81 | Better-than-average |
| 8 | 0.95 | Fairly alignment |
| 9 | 0.65 | Excellent alignment |
| 10 | 0.98 | Fairly alignment |
| No. | Raw Requirement | Base Weight | Similarity Score | Base Priority | Proposed Priority |
|---|---|---|---|---|---|
| 1 | While providing security | 0.0677 | 0.886 | 1 | 1 |
| enable staff and students | |||||
| to access building | |||||
| and facilities easily | |||||
| 2 | The cards and readers | 0.0655 | 0.869 | 2 | 2 |
| should permit reuse | |||||
| for tracking presence | |||||
| 3 | Allow guards to see | 0.0654 | 0.866 | 3 | 3 |
| pictures of people | |||||
| passing the gate | |||||
| 4 | To enable smooth/efficient | 0.0654 | 0.845 | 3 | 5 |
| building access control | |||||
| whether via visual inspection | |||||
| 5 | Access to buildings | 0.0641 | 0.857 | 4 | 4 |
| and other services should be | |||||
| capable of being extended | |||||
| 6 | Allow access to | 0.0641 | 0.857 | 4 | 4 |
| buildings for different staff | |||||
| 7 | To allow checking | 0.0641 | 0.838 | 4 | 6 |
| of the roles a person | |||||
| has in their department | |||||
| 8 | Monitor alumni use, eg | 0.0638 | 0.857 | 5 | 4 |
| library use, shop, fitness etc. | |||||
| 9 | Enable additional access | 0.0625 | 0.838 | 6 | 6 |
| control to buildings | |||||
| 10 | To place card access | 0.0625 | 0.838 | 6 | 6 |
| on all buildings | |||||
| 11 | Readers can be easily | 0.0625 | 0.780 | 6 | 8 |
| installed in new locations | |||||
| 12 | Access for users | 0.0619 | 0.838 | 7 | 6 |
| of Bloomsbury Fitness | |||||
| 13 | To access university buildings | 0.0616 | 0.831 | 8 | 7 |
| & borrow library books | |||||
| 14 | To be able to gain access | 0.0616 | 0.761 | 8 | 9 |
| to different buildings, so | |||||
| correct level access given | |||||
| 15 | To be able to control the | 0.0616 | 0.745 | 8 | 10 |
| access to all buildings at UCL | |||||
| 16 | Enter libraries | 0.0615 | 0.831 | 9 | 7 |
| with appropriate access | |||||
| 17 | To allow entry to the Kathleen | 0.0615 | 0.780 | 9 | 8 |
| Lonsdale building where the | |||||
| user services office resides | |||||
| 18 | To control access to high hazard | 0.0615 | 0.761 | 9 | 9 |
| areas both in the main campus and | |||||
| in the satellite and "shared" facilities | |||||
| 19 | To be able to find out who has | 0.0615 | 0.745 | 9 | 10 |
| gained entry to cluster rooms / IT rooms | |||||
| 20 | To allow/deny access to rooms | 0.0615 | 0.625 | 9 | 11 |
| Raw Requirements | Pre-Processed Requirements |
|---|---|
| While providing security, enable staff and students | provide secure enable staff |
| to access building and facilities easily | student access build facil easili |
| The cards and readers should | card reader permit |
| permit reuse for tracking presence | reus track presens |
| Allow guards to see pictures | allow guard see pictur |
| of people passing the gate | peopl pass gate |
| To enable smooth/efficient | enable build access |
| building access control | control whether |
| whether via visual inspection | via visual inspect |
| Access to buildings | access build |
| and other services should | servic capable |
| be capable of being extended | extend |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jamasb, B.; Khayami, S.R.; Akbari, R.; Taheri, R. An Automated Framework for Prioritizing Software Requirements. Electronics 2025, 14, 1220. https://doi.org/10.3390/electronics14061220
Jamasb B, Khayami SR, Akbari R, Taheri R. An Automated Framework for Prioritizing Software Requirements. Electronics. 2025; 14(6):1220. https://doi.org/10.3390/electronics14061220
Chicago/Turabian StyleJamasb, Behnaz, Seyed Raouf Khayami, Reza Akbari, and Rahim Taheri. 2025. "An Automated Framework for Prioritizing Software Requirements" Electronics 14, no. 6: 1220. https://doi.org/10.3390/electronics14061220
APA StyleJamasb, B., Khayami, S. R., Akbari, R., & Taheri, R. (2025). An Automated Framework for Prioritizing Software Requirements. Electronics, 14(6), 1220. https://doi.org/10.3390/electronics14061220