Lossless and High-Throughput Congestion Control in Satellite-Based Cloud Platforms †


Abstract
1. Introduction
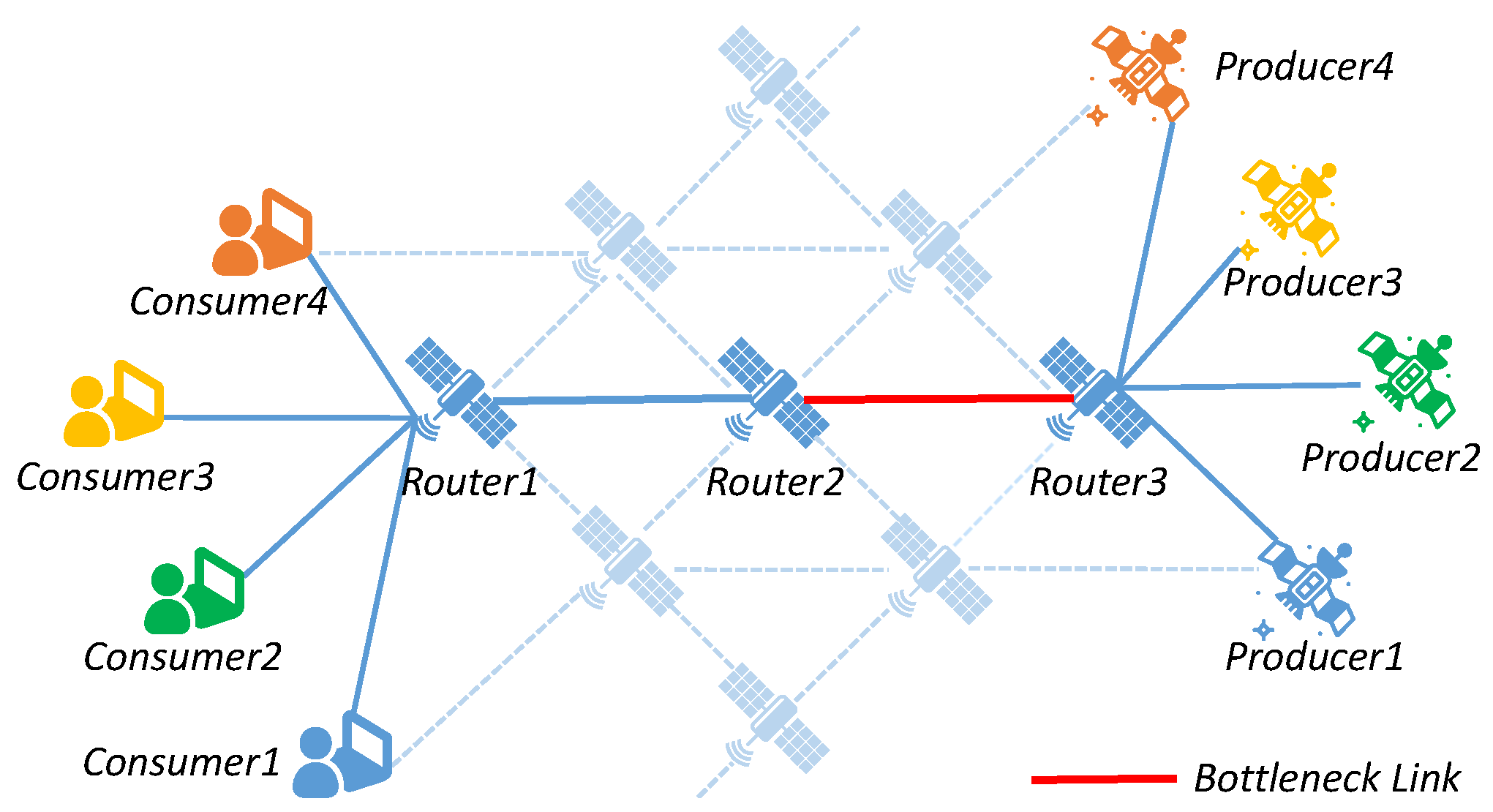
- Among the existing methods, network throughput is adjusted to match the bandwidth of the bottleneck link. By preventing full occupation of the bottleneck link, congestion is avoided. However, this results in low throughput and high flow completion times.
- The size of each Data is defined by the producer; thus, the sizes of Data packets retrieved by different Interests can vary significantly. Therefore, adjusting the sending rate of Interests alone cannot proportionally regulate the traffic of Data packets.
- The satellite-based cloud platform, characterized by its time-varying nature and significant propagation delays, may experience delayed congestion responses when existing congestion feedback mechanisms are used. This can lead to packet loss [21].
- We propose a lossless congestion control method termed CCLF, which enhances the content storage and data forwarding mechanisms of NDN. By monitoring output queues and regulating data forwarding, CCLF effectively eliminates packet loss.
- We optimize the aggregation and unified scheduling of Data packets, fully utilizing the bandwidth resources in the time-varying network. This approach overcomes the throughput limitations imposed by the constrained bandwidth of the end-to-end bottleneck link, thereby achieving high network throughput.
- We design a priority-based scheduling algorithm that supports swift forwarding of high-priority Data while ensuring appropriate bandwidth allocation for ordinary Data with the same priority, thus meeting the desired Quality of Service (QoS).
- We conduct a series of experiments to evaluate the CCLF method, comparing its performance with that of the recognized PCON approach. The results show that CCLF significantly reduces flow completion time and improves network throughput.
2. Related Works
2.1. Consumer-Side Congestion Control
2.2. Hop-by-Hop Congestion Control
2.3. Hybrid Congestion Control
3. Integrated System and Algorithm Design
3.1. Design Goals
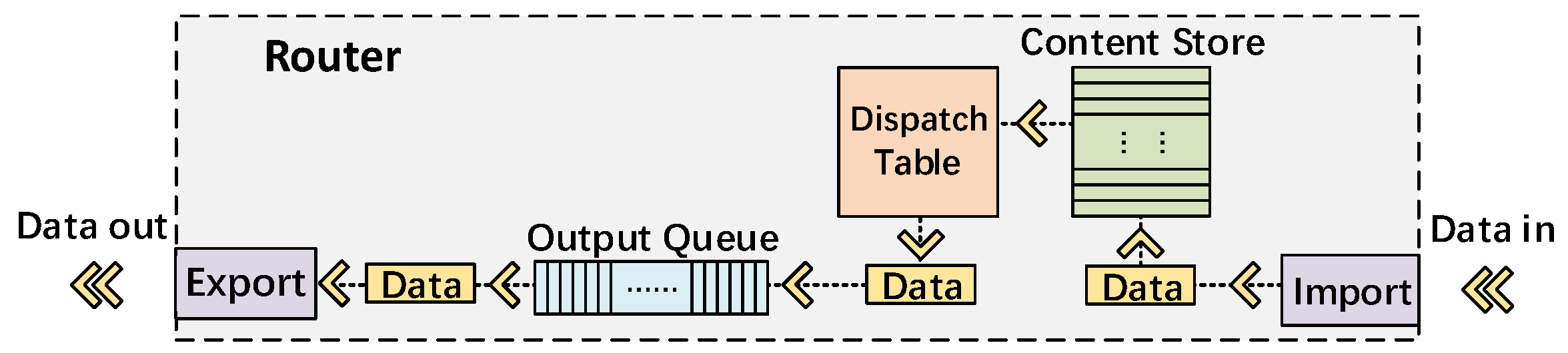
3.2. Framework of CCLF
3.3. Throughput Optimization Model
3.3.1. Throughput with CCLF
3.3.2. Average Bandwidth Comparison
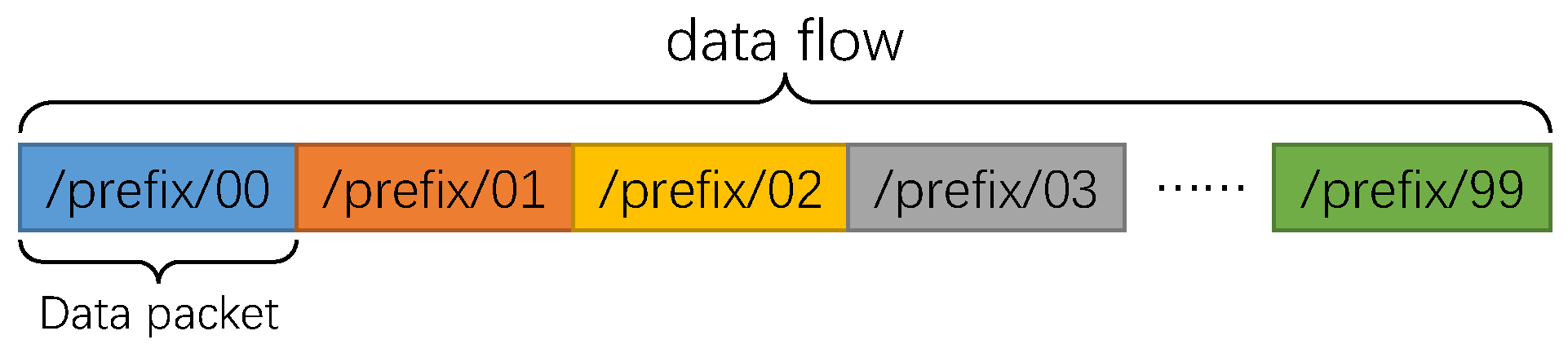
3.4. Data Flow Scheduling Model
3.5. Forwarding Dispatch Table
3.6. Data Forwarding Scheduling
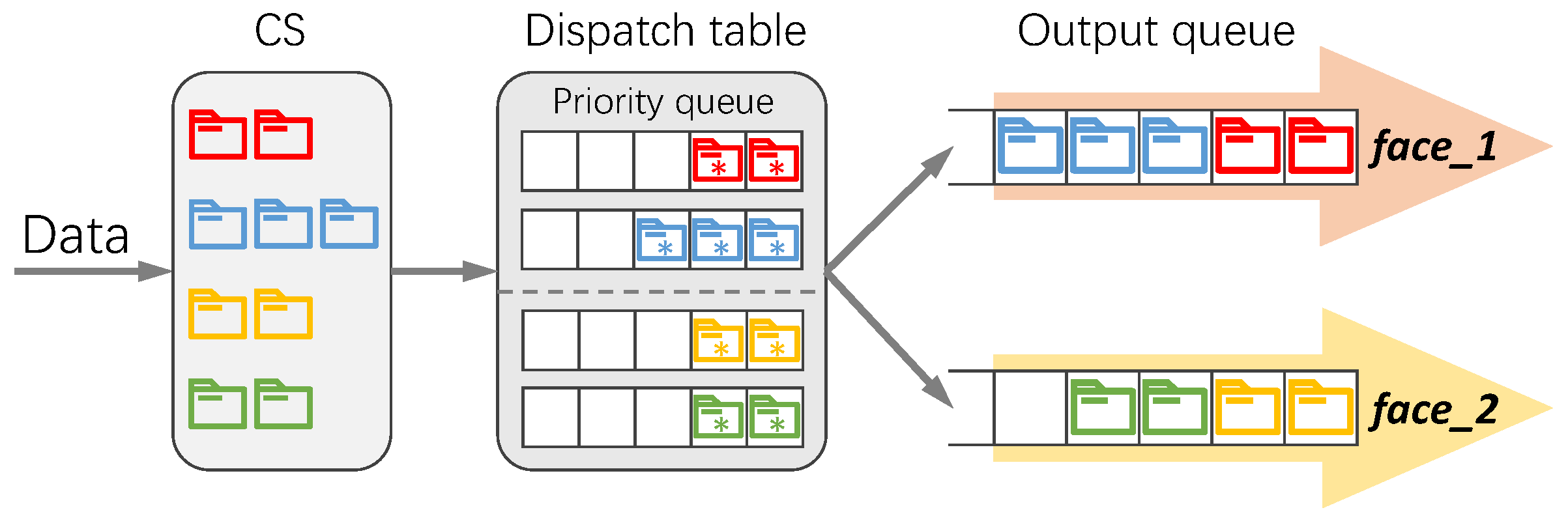
- Read the priority field in Data i and determine the queue from the forwarding database Q.
- If the queue with priority does not exist, create a new queue in the forwarding database Q.
- Read the name in Data i and select the sub-queue from the queue .
- If the sub-queue is empty, it indicates that a new data flow with the name prefix is being received. To ensure appropriate bandwidth allocation among flows with the same priority, reset the recorded sent byte count for all sub-queues of equal priority to zero.
- Insert the pointer of Data i into the sub-queue .
- After sending one Data packet, retrieve the database Q. Select the non-empty queue with the highest priority from Q.
- If there is only one sub-queue in , remove the first element l from and insert the corresponding Data packet into the output queue of the interface. Update the sent byte count for from to .
- If there are multiple sub-queues in , select the sub-queue with the least sent bytes: . Remove the first element l from , insert the associated Data into the output queue, and update the byte count for from to .
- If the sub-queue or becomes empty after removing the first element l, erase it to prevent selecting an empty sub-queue in subsequent steps.
- Repeat step (1) until the termination condition is met.
4. Implementation
4.1. Experimental Settings
4.2. Simulation Settings
5. Experimental Results and Discussion
5.1. Congestion Control Under Constant Bandwidth
5.1.1. Flow Completion Time
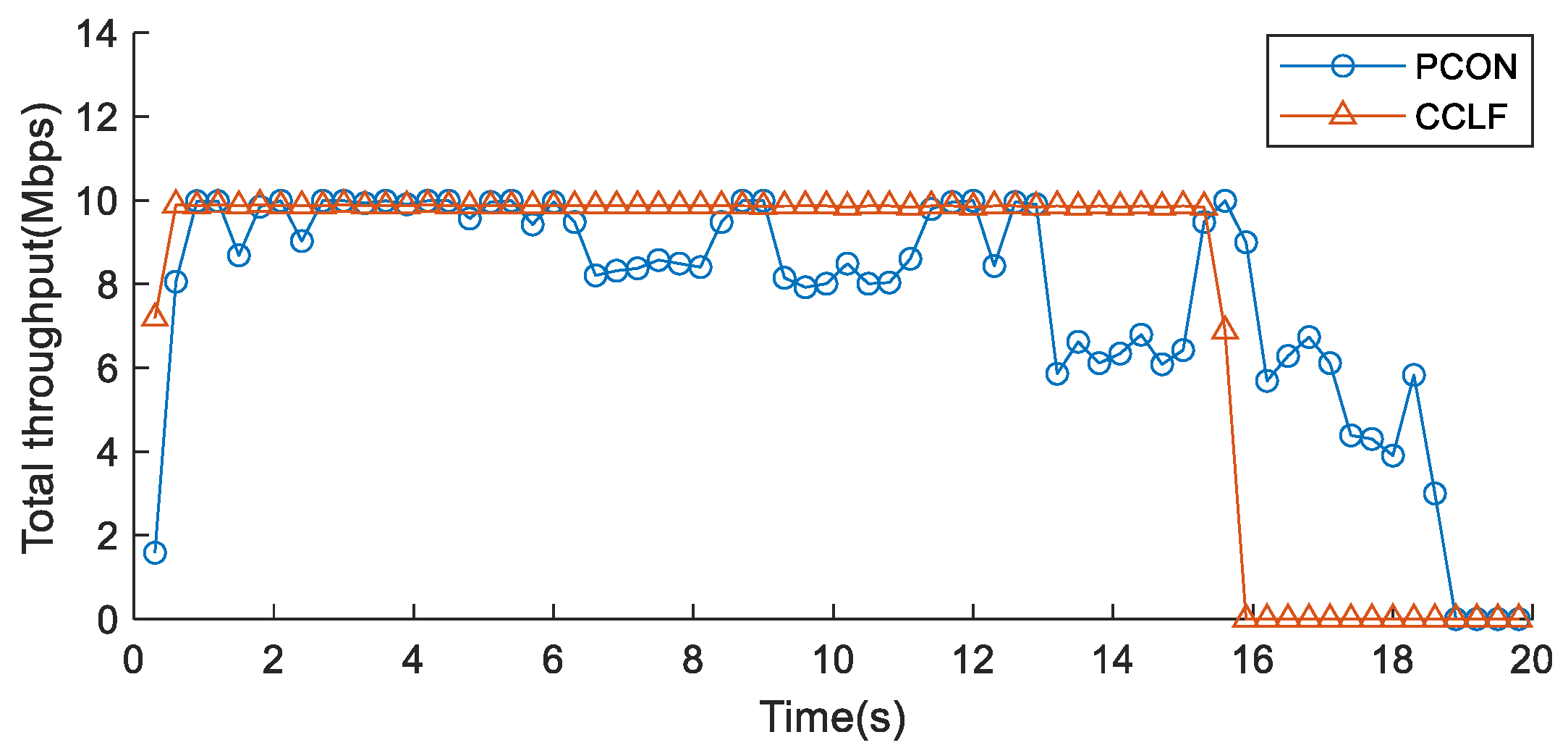
5.1.2. Network Throughput
5.1.3. Bandwidth Utilization
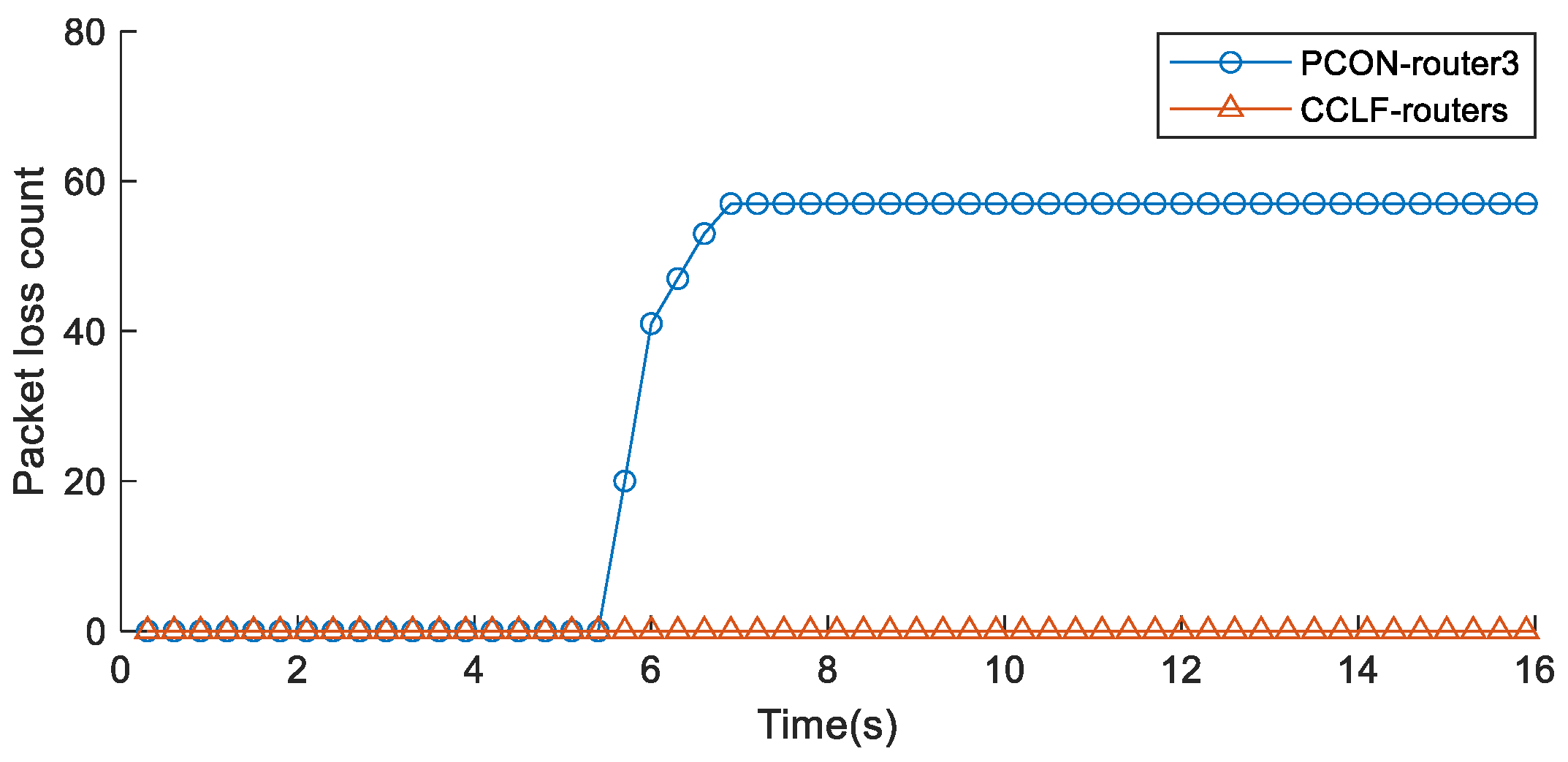
5.1.4. Verification of Zero Packet Loss
5.2. Congestion Control Under Dynamic Bandwidth
5.2.1. Flow Completion Time
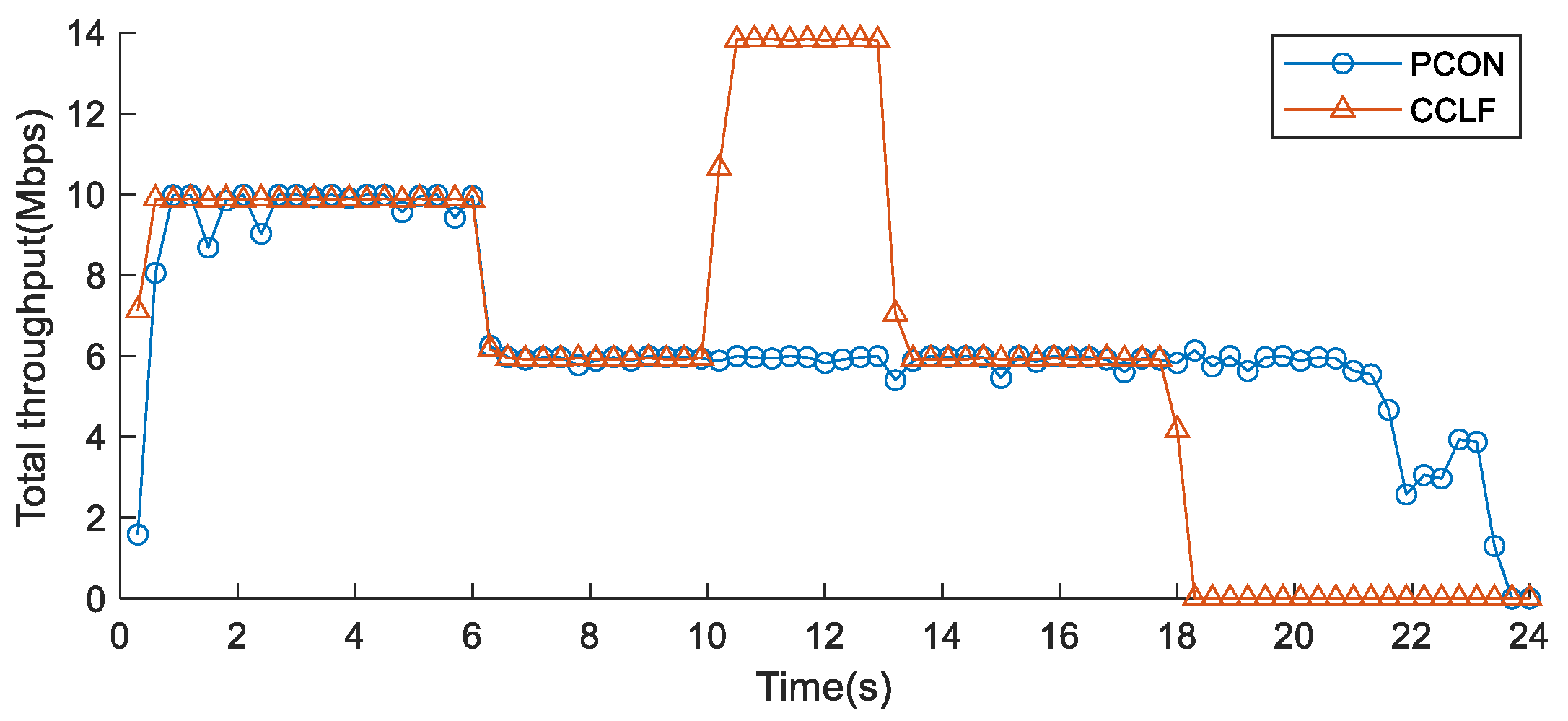
5.2.2. Network Throughput
5.2.3. Bandwidth Utilization
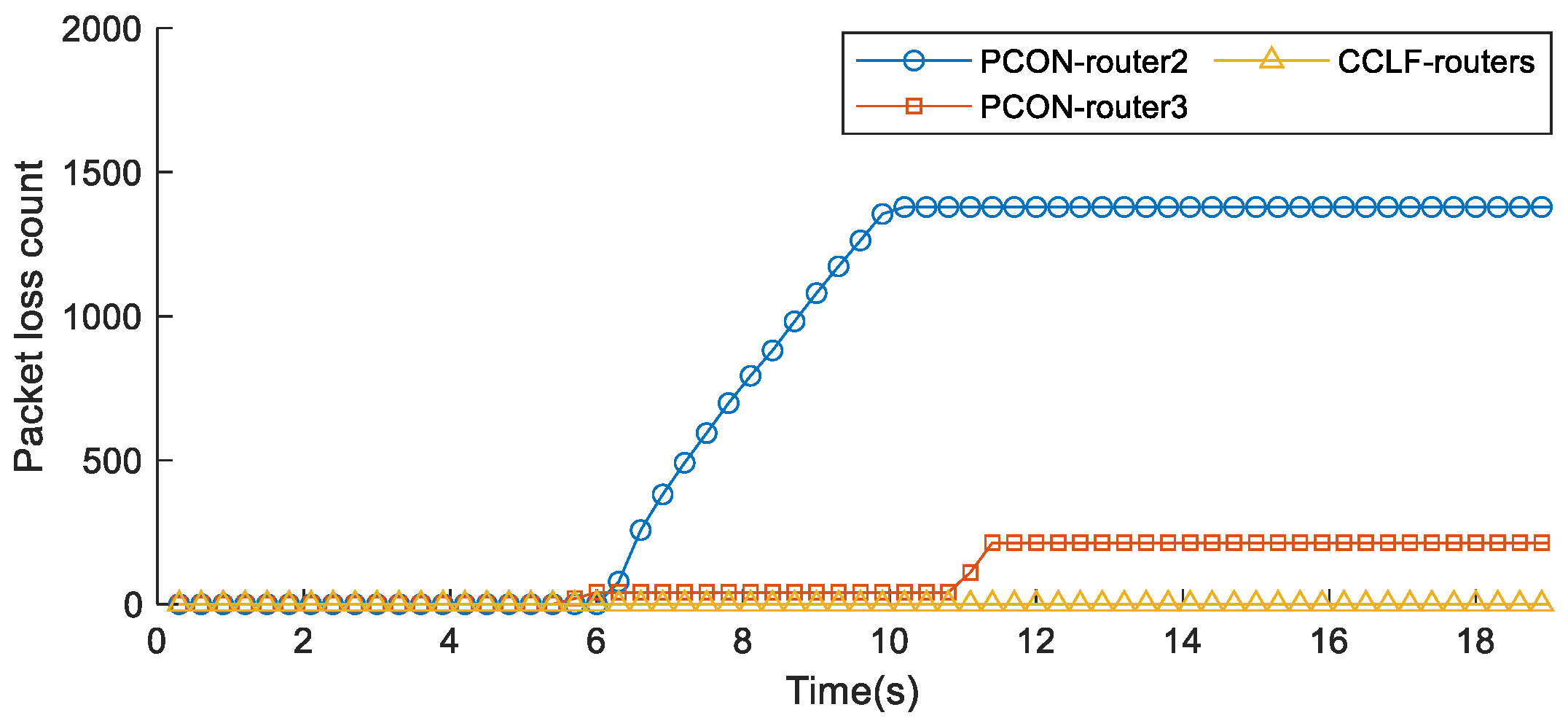
5.2.4. Verification of Zero Packet Loss
5.3. Evaluation Summary
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Diao, W.; An, J.; Li, T.; Wang, X.; Liu, Z.; Li, Z. Lossless congestion control based on priority scheduling in named data networking. In Proceedings of the 2024 International Conference on Electrical, Electronic Information and Communication Engineering (EEICE), Xi’an, China, 12–14 April 2024; Volume 2849, p. 012096. [Google Scholar] [CrossRef]
- Luo, X.; Chen, H.H.; Guo, Q. LEO/VLEO Satellite Communications in 6G and Beyond Networks–Technologies, Applications, and Challenges. IEEE Netw. 2024, 38, 273–285. [Google Scholar] [CrossRef]
- Toka, M.; Lee, B.; Seong, J.; Kaushik, A.; Lee, J.; Lee, J.; Lee, N.; Shin, W.; Poor, H.V. RIS-Empowered LEO Satellite Networks for 6G: Promising Usage Scenarios and Future Directions. IEEE Commun. Mag. 2024, 62, 128–135. [Google Scholar] [CrossRef]
- Han, Z.; Xu, C.; Zhao, G.; Wang, S.; Cheng, K.; Yu, S. Time-Varying Topology Model for Dynamic Routing in LEO Satellite Constellation Networks. IEEE Trans. Veh. Technol. 2023, 72, 3440–3454. [Google Scholar] [CrossRef]
- Diao, W.; An, J.; Li, T.; Zhu, C.; Zhang, Y.; Wang, X.; Liu, Z. Low delay fragment forwarding in LEO satellite networks based on named data networking. Comput. Commun. 2023, 211, 216–228. [Google Scholar] [CrossRef]
- Jiang, D.; Wang, F.; Lv, Z.; Mumtaz, S.; Al-Rubaye, S.; Tsourdos, A.; Dobre, O. QoE-Aware Efficient Content Distribution Scheme For Satellite-Terrestrial Networks. IEEE Trans. Mob. Comput. 2023, 22, 443–458. [Google Scholar] [CrossRef]
- Chen, X.; Gu, W.; Dai, G.; Xing, L.; Tian, T.; Luo, W.; Cheng, S.; Zhou, M. Data-Driven Collaborative Scheduling Method for Multi-Satellite Data-Transmission. Tsinghua Sci. Technol. 2024, 29, 1463–1480. [Google Scholar] [CrossRef]
- Arsalan, A.; Burhan, M.; Rehman, R.A.; Umer, T.; Kim, B.S. E-DRAFT: An Efficient Data Retrieval and Forwarding Technique for Named Data Network Based Wireless Multimedia Sensor Networks. IEEE Access 2023, 11, 15315–15328. [Google Scholar] [CrossRef]
- Cobblah, C.N.A.; Xia, Q.; Gao, J.; Xia, H.; Kusi, G.A.; Obiri, I.A. A Secure and Lightweight NDN-Based Vehicular Network Using Edge Computing and Certificateless Signcryption. IEEE Internet Things J. 2024, 11, 27043–27057. [Google Scholar] [CrossRef]
- Demiroglou, V.; Martinis, M.; Florou, D.; Tsaoussidis, V. IoT Data Collection Over Dynamic Networks: A Performance Comparison of NDN, DTN and NoD. In Proceedings of the 2023 IEEE 9th World Forum on Internet of Things (WF-IoT), Aveiro, Portugal, 12–27 October 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Xia, Z.; Zhang, Y.; Fang, B. Exploiting Knowledge for Better Mobility Support in the Future Internet. Mob. Netw. Appl. 2022, 27, 1671–1687. [Google Scholar] [CrossRef]
- Ahmad, Z.N.; Triana, F.; Rachel, R.; Negara, R.M.; Mayasari, R.; Astuti, S.; Rizal, S. Optimizing Forwarding Strategies in Named Data Networking Using Reinforcement Learning. In Proceedings of the 2023 9th International Conference on Wireless and Telematics (ICWT), Solo, Indonesia, 6–7 July 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Rodríguez-Pérez, M.; Herrería-Alonso, S.; Suárez-Gonzalez, A.; López-Ardao, J.C.; Rodríguez-Rubio, R. Cache Placement in an NDN-Based LEO Satellite Network Constellation. IEEE Trans. Aerosp. Electron. Syst. 2023, 59, 3579–3587. [Google Scholar] [CrossRef]
- Tan, X.; Feng, W.; Lv, J.; Jin, Y.; Zhao, Z.; Yang, J. f-NDN: An Extended Architecture of NDN Supporting Flow Transmission Mode. IEEE Trans. Commun. 2020, 68, 6359–6373. [Google Scholar] [CrossRef]
- Siddiqui, S.; Waqas, A.; Khan, A.; Zareen, F.; Iqbal, M.N. Congestion Controlling Mechanisms in Content Centric Networking and Named Data Networking—A Survey. In Proceedings of the 2019 2nd International Conference on Computing, Mathematics and Engineering Technologies (iCoMET), Sukkur, Pakistan, 30–31 January 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Kato, T.; Bandai, M. A hop-by-hop window-based congestion control method for named data networking. In Proceedings of the 2018 15th IEEE Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 12–15 January 2018; pp. 1–7. [Google Scholar] [CrossRef]
- Bandai, M.; Kato, T.; Yamamoto, M. A congestion control method for named data networking with hop-by-hop window-based approach. IEICE Trans. Commun. 2019, 102, 97–110. [Google Scholar] [CrossRef]
- Schneider, K.; Yi, C.; Zhang, B.; Zhang, L. A Practical Congestion Control Scheme for Named Data Networking. In Proceedings of the 3rd ACM Conference on Information-Centric Networking, Kyoto, Japan, 26–28 September 2016; pp. 21–30. [Google Scholar] [CrossRef]
- Song, S.; Zhang, L. Effective NDN congestion control based on queue size feedback. In Proceedings of the ICN’22: 9th ACM Conference on Information-Centric Networking, Osaka, Japan, 19–21 September 2022; pp. 11–21. [Google Scholar] [CrossRef]
- Li, Z.; Shen, X.; Xun, H.; Miao, Y.; Zhang, W.; Luo, P.; Liu, K. CoopCon: Cooperative Hybrid Congestion Control Scheme for Named Data Networking. IEEE Trans. Netw. Serv. Manag. 2023, 20, 4734–4750. [Google Scholar] [CrossRef]
- Zhong, X.; Zhang, J.; Zhang, Y.; Guan, Z.; Wan, Z. PACC: Proactive and Accurate Congestion Feedback for RDMA Congestion Control. In Proceedings of the IEEE INFOCOM 2022—IEEE Conference on Computer Communications, London, UK, 2–5 May 2022; pp. 2228–2237. [Google Scholar] [CrossRef]
- Bai, H.; Li, H.; Que, J.; Smahi, A.; Zhang, M.; Chong, P.H.J.; Li, S.Y.R.; Wang, X.; Lu, P. QSCCP: A QoS-Aware Congestion Control Protocol for Information-Centric Networking. IEEE Trans. Netw. Serv. Manag. 2024; early access. [Google Scholar] [CrossRef]
- Bai, H.; Li, H.; Que, J.; Zhang, M.; Chong, P.H.J. DSCCP: A Differentiated Service-based Congestion Control Protocol for Information-Centric Networking. In Proceedings of the 2022 IEEE Wireless Communications and Networking Conference (WCNC), Austin, TX, USA, 10–13 April 2022; pp. 1641–1646. [Google Scholar] [CrossRef]
- Google Cloud. M2 UltraMemory Machine Types. Available online: https://cloud.google.com/compute/docs/machine-types#m2-machine-types (accessed on 23 December 2024).
- Carofiglio, G.; Gallo, M.; Muscariello, L. ICP: Design and evaluation of an Interest control protocol for content-centric networking. In Proceedings of the 2012 Proceedings IEEE INFOCOM Workshops, Orlando, FL, USA, 25–30 March 2012; pp. 304–309. [Google Scholar] [CrossRef]
- Saino, L.; Cocora, C.; Pavlou, G. CCTCP: A scalable receiver-driven congestion control protocol for content centric networking. In Proceedings of the 2013 IEEE International Conference on Communications (ICC), Budapest, Hungary, 9–13 June 2013; pp. 3775–3780. [Google Scholar] [CrossRef]
- Carofiglio, G.; Gallo, M.; Muscariello, L.; Papali, M. Multipath congestion control in content-centric networks. In Proceedings of the 2013 IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Turin, Italy, 14–19 April 2013; pp. 363–368. [Google Scholar] [CrossRef]
- Zheng, R.; Zhang, B.; Zhao, X.; Wang, L.; Wu, Q. A Receiver-Driven Named Data Networking (NDN) Congestion Control Method Based on Reinforcement Learning. Electronics 2024, 13, 4609. [Google Scholar] [CrossRef]
- Rozhnova, N.; Fdida, S. An extended Hop-by-hop interest shaping mechanism for content-centric networking. In Proceedings of the 2014 IEEE Global Communications Conference, Austin, TX, USA, 8–12 December 2014; pp. 1–7. [Google Scholar] [CrossRef]
- Mejri, S.; Touati, H.; Malouch, N.; Kamoun, F. Hop-by-Hop Congestion Control for Named Data Networks. In Proceedings of the 2017 IEEE/ACS 14th International Conference on Computer Systems and Applications (AICCSA), Hammamet, Tunisia, 30 October–3 November 2017; pp. 114–119. [Google Scholar] [CrossRef]
- Touati, H.; Mejri, S.; Malouch, N.; Kamoun, F. Fair hop-by-hop interest rate control to mitigate congestion in named data networks. Clust. Comput. 2021, 24, 2213–2230. [Google Scholar] [CrossRef]
- Mejri, S.; Touati, H.; Kamoun, F. Hop-by-hop interest rate notification and adjustment in named data networks. In Proceedings of the 2018 IEEE Wireless Communications and Networking Conference (WCNC), Barcelona, Spain, 15–18 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Ye, Y.; Lee, B.; Qiao, Y. Hop-by-Hop Congestion Measurement and Practical Active Queue Management in NDN. In Proceedings of the GLOBECOM 2020—2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Thibaud, A.; Fasson, J.; Arnal, F.; Sallantin, R.; Dubois, E.; Chaput, E. Reactivity Enhancement of Cooperative Congestion Control for Satellite Networks. In Proceedings of the 2020 3rd International Conference on Hot Information-Centric Networking (HotICN), Hefei, China, 12–14 December 2020; pp. 135–141. [Google Scholar] [CrossRef]
- Schneider, L.K.; Yi, C.; Zhang, B. PCON Source Code. 2019. Available online: https://github.com/schneiderklaus/ndnSIM (accessed on 1 June 2024).
- David, H.A.; Nagaraja, H.N. Order Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Itô, K. On Stochastic Differential Equations; American Mathematical Society: New York, NY, USA, 1951. [Google Scholar]
- Kuhn, H.; Tucker, A. Nonlinear Programming Proceedings of the Second Berkeley Symposium on Mathematical Statistics and Probability; University of California Press: Berkeley, CA, USA, 1951; pp. 481–492. [Google Scholar]
- Mastorakis, S.; Afanasyev, A.; Zhang, L. On the Evolution of ndnSIM: An Open-Source Simulator for NDN Experimentation. SIGCOMM Comput. Commun. Rev. 2017, 47, 19–33. [Google Scholar] [CrossRef]
- NDN Team. Named Data Networking Forwarding Daemon (NFD) 22.02-3-gdeb5427 Documentation. 2022. Available online: https://named-data.net/doc/NFD/current/overview.html (accessed on 6 July 2024).
- NDN Teams. NDN-cxx. 2021. Available online: http://named-data.net/doc/ndn-cxx (accessed on 10 September 2024).
- NDN Team. NS-3-Based NDN Simulator. 2021. Available online: https://ndnsim.net/2.8/# (accessed on 14 February 2024).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Definitions |
|---|---|
| The priority of Data i | |
| The name prefix of Data i | |
| The queue with priority in database Q | |
| The sub-queue with name prefix in the queue | |
| Total byte length of the forwarded Data in sub-queue |
| Simulation Parameters | Value |
|---|---|
| Link type | point-to-point link |
| General link bandwidth | 100 Mbps |
| Congested link bandwidth | 10 Mbps |
| Propagation delay | 10 ms |
| Queue (maxpackets on the link) | 200 |
| Interest sending rate | 1000 pkts/s |
| Size of Content Store (CS) | 32 GB (approx. packets) |
| Time Interval | Bandwidth of Link 1 | Bandwidth of Link 2 |
|---|---|---|
| 0–6 s | 10 Mbps | 10 Mbps |
| 6–10 s | 6 Mbps | 14 Mbps |
| 10–14 s | 14 Mbps | 6 Mbps |
| 14–25 s | 6 Mbps | 14 Mbps |
| Performance | PCON | CCLF |
|---|---|---|
| Packet loss | Occurrence | Non-occurrence |
| Control master | Consumers and routers | Routers |
| Control mode | Adjust sending rate of Interests | Data scheduling and forwarding |
| Throughput | Floating | Stable |
| Bandwidth usage | Underutilized bandwidth | Full bandwidth utilization |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diao, W.; An, J.; Li, T.; Zhang, Y.; Liu, Z. Lossless and High-Throughput Congestion Control in Satellite-Based Cloud Platforms. Electronics 2025, 14, 1206. https://doi.org/10.3390/electronics14061206
Diao W, An J, Li T, Zhang Y, Liu Z. Lossless and High-Throughput Congestion Control in Satellite-Based Cloud Platforms. Electronics. 2025; 14(6):1206. https://doi.org/10.3390/electronics14061206
Chicago/Turabian StyleDiao, Wenlan, Jianping An, Tong Li, Yu Zhang, and Zhoujie Liu. 2025. "Lossless and High-Throughput Congestion Control in Satellite-Based Cloud Platforms" Electronics 14, no. 6: 1206. https://doi.org/10.3390/electronics14061206
APA StyleDiao, W., An, J., Li, T., Zhang, Y., & Liu, Z. (2025). Lossless and High-Throughput Congestion Control in Satellite-Based Cloud Platforms. Electronics, 14(6), 1206. https://doi.org/10.3390/electronics14061206