
AI-Enabled Text-to-Music Generation: A Comprehensive Review of Methods, Frameworks, and Future Directions


 and
and
Abstract
1. Introduction
1.1. Background
1.2. Motivation
1.3. Objectives
- To systematically classify and analyze text-to-music generation tasks: By categorizing tasks into symbolic and audio domains, this paper examines subtasks such as melody generation, polyphony generation, singing voice synthesis, and complete song composition. This taxonomy offers a clear aspect for understanding the distinct challenges and opportunities within each domain. This framework supports modular method development by providing researchers with a structured reference for locating domain-specific innovations;
- To emphasize the potential of LLMs through framework comparison: This study focuses on traditional methods, hybrid approaches, and end-to-end LLM systems, providing a detailed analysis of their strengths, limitations, and applicability. The analysis highlights the progressive improvements introduced by LLMs, demonstrating their ability to enhance user controllability, generalization capability, etc., offering a clearer perspective on the role of LLMs in advancing AI-enabled music composition;
- To identify challenges and propose future directions: This objective is crucial because addressing unresolved challenges—such as data scarcity, model generalization, emotion modeling, and user interactivity—is the foundation for advancing text-to-music generation. By systematically analyzing these barriers, this paper provides a roadmap for overcoming limitations that currently hinder the effectiveness and creativity of such systems. This exploration advances text-to-music generation, establishing it as a key direction for creative industries.
2. Evolution
2.1. Early Rule-Based Systems
2.2. Emergence of Machine Learning
2.3. The Rise of Deep Learning and Cross-Modal Approaches
2.4. The Integration of LLMs
3. Representation Forms of Text and Music
3.1. Text Types
3.2. Musical Representation
3.2.1. Event Representation: MIDI-like
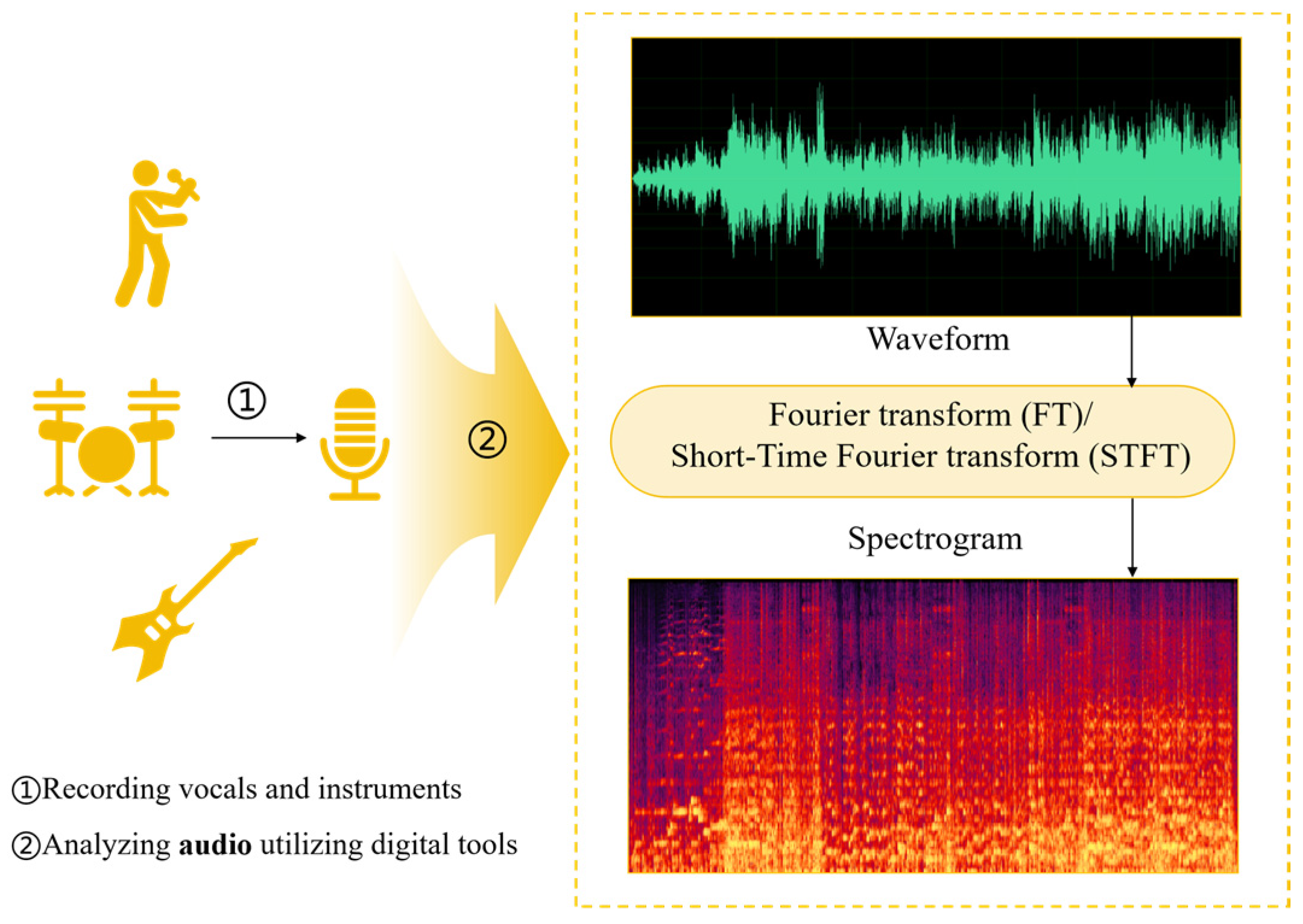
3.2.2. Audio Representation: Waveform and Spectrogram
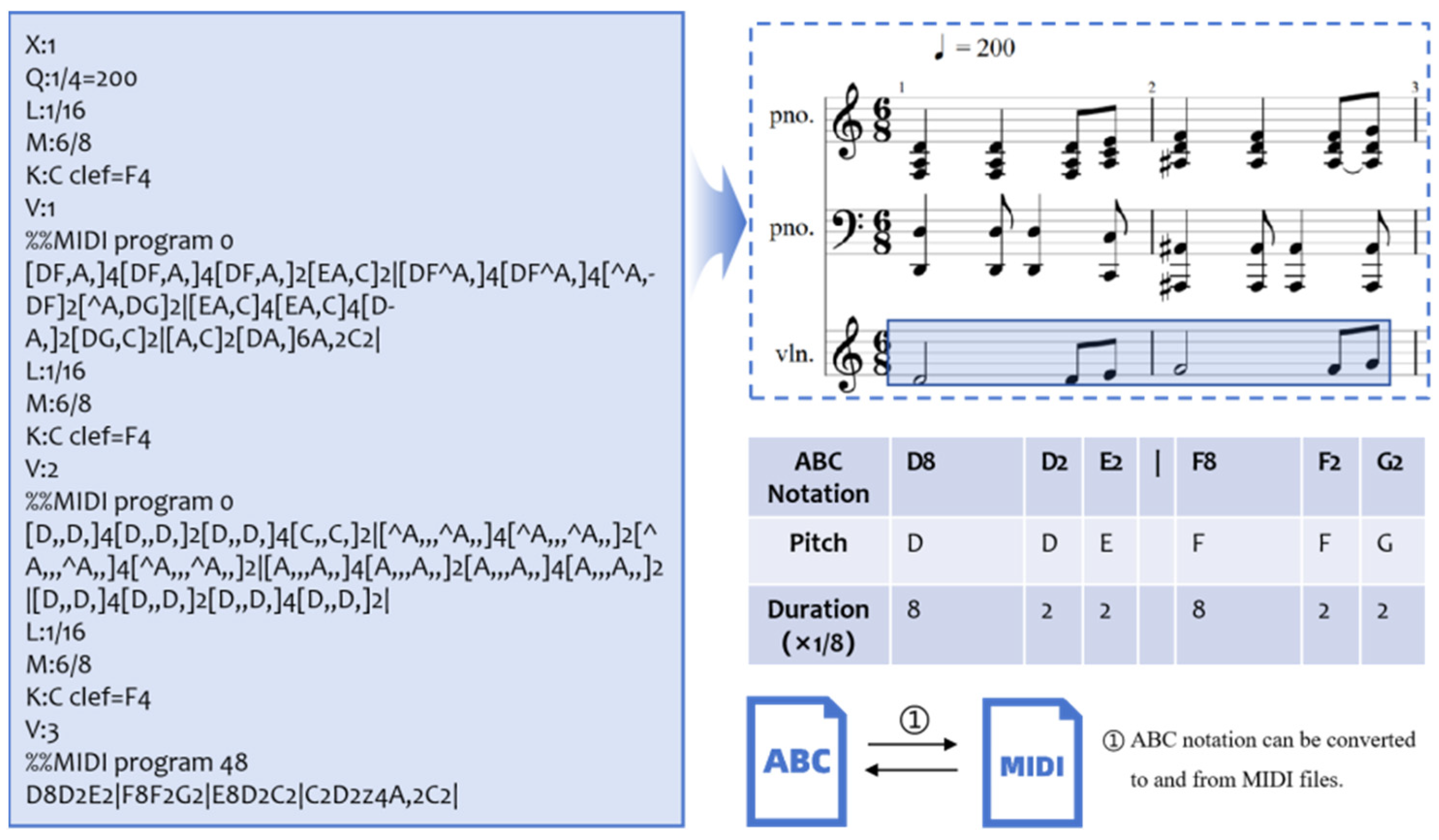
3.2.3. Text Representation: ABC Notation
4. Methods
4.1. Symbolic Domain Methods
4.1.1. Melody Generation
- Lyric-based Melody Generation
- 2.
- Musical attribute-based Melody Generation
- 3.
- Description-based Melody Generation
4.1.2. Polyphony Generation
- Musical Attribute-based Polyphony Generation
- 2.
- Description-based Polyphony Generation
4.2. Audio Domain Methods
4.2.1. Instrumental Music Generation
- Label-based Instrumental Music Generation
- 2.
- Description-based instrumental Music Generation
4.2.2. Singing Voice Synthesis
- 1.
- Splicing Synthesis
- 2.
- Statistical Parameter Synthesis
- 3.
- Neural Network Synthesis
4.2.3. Complete Song Generation
- 1.
- Staged Generation
- 2.
- End-to-end Generation
4.3. Comments on Existing Techniques
4.3.1. Comparative Analysis of Symbolic and Audio Domains
- 1.
- Editability
- 2.
- Expressiveness
- 3.
- Integrity
- 4.
- Data Efficiency
4.3.2. Critical Evaluation of Technical Approaches
- 1.
- Rule-Based and Template Methods
- 2.
- Statistical Models
- 3.
- Generative Models
- 4.
- Transformer-Based Models
- 5.
- Large Language Models
5. Frameworks
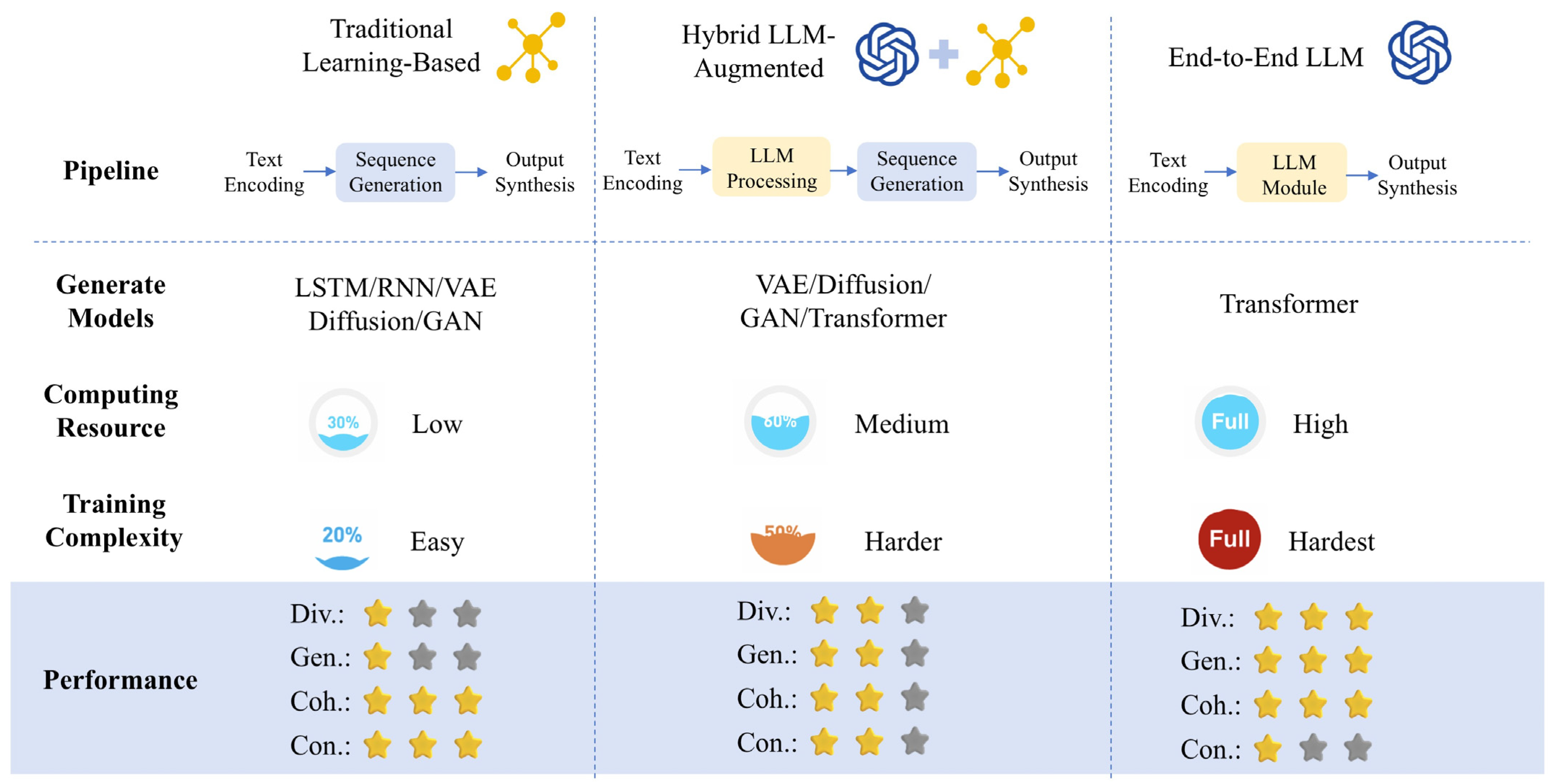
5.1. Traditional Learning-Based Frameworks
- Text Encoding: The input text (e.g., lyrics) is converted into numerical representations using embedding layers, capturing semantic and rhythmic information.
- Sequence Generation: Deep learning models (e.g., LSTM, RNN) generate musical sequences (e.g., melody, chords, or rhythm) based on the encoded text.
- Output Synthesis: The generated musical sequences are converted into symbolic music formats (e.g., MIDI) or synthesized into audio.
- Case 1: TeleMelody
5.2. Hybrid LLM-Augmented Frameworks
- Text Encoding: With traditional methods;
- LLM Module: Extracts key semantic features and contextual information from the input text and generates new content, such as lyrics or expanded descriptions, based on the input;
- Sequence Generation: With traditional methods;
- Output Synthesis: With traditional methods. Sometimes, LLM is used to give feedback.
- Case 2: MuseCoCo
5.3. End-to-End LLM-Centric Frameworks
- Text Encoding: With traditional methods;
- LLM Processing: The encoded text is processed by the language model, which treats music as a sequence similar to text. This model predicts the next musical element (e.g., note, rhythm, or harmony) based on the current context, generating a complete musical sequence in an iterative manner. In this stage, the LLM is able to use its extensive pre-trained knowledge of language and patterns to generate musically coherent sequences that align with the input description;
- Output Synthesis: Extract symbol information from textual music sequences and synthesize them.
- Case 3: SongComposer
5.4. Comparative Analysis and Limitations
- Strengths: These methods offer high control and reliable output quality due to their use of high-quality paired datasets. They excel in structured tasks, like generating music based on fixed templates or rhythms, offering good controllability over tonalities, chords, rhythm, and cadence. Additionally, these methods typically have lower computational demands compared to newer, more complex models;
- Limitations: Their creativity and generalization abilities are limited. They are often constrained by predefined templates, restricting them to a narrower range of tasks. Furthermore, they require labeled data for training and can struggle to adapt to more diverse, dynamic input.
- Strengths: Hybrid systems strike a balance between creativity and control. They can integrate multiple sources of data, offering higher diversity in the generated music. These systems are more flexible and can accommodate more complex input, including unstructured text descriptions;
- Limitations: Hybrid approaches still rely on traditional techniques to maintain some degree of control, which can limit the degree of innovation. The model size and computational demands are higher than traditional methods, though still more efficient than end-to-end LLM systems.
- Strengths: These systems push the boundaries of creativity and generalization. They can generate highly diverse outputs, incorporating various musical elements (such as melody, harmony, and rhythm) and adapt to cross-task and cross-genre settings. With the ability to use multi-modal data, they enhance the emotional and thematic depth of the generated music;
- Limitations: The control over specific attributes, such as rhythm or instrumentation, can be weaker in these systems. Additionally, computational resource efficiency is often a concern, as they require large-scale datasets and extensive processing power for both training and inference.
6. Challenges and Future Directions
6.1. Challenges
6.1.1. Technical Level
- 1.
- Dataset Scarcity and Representation Limitations
- 2.
- Model Training and Generalization
- 3.
- Evaluation Metrics for Creativity
- 4.
- Song Structure and Long-Term Coherence
- 5.
- Emotion Representation and Modeling
- 6.
- Interactivity between Human and Computer
- 7.
- Lack of Commercial Applications
- 8.
- AI Security and Adversarial Attacks
6.1.2. Social Level
- Copyright Issues
- 2.
- Privacy Concerns
- 3.
- Impact on Human Musicians
- 4.
- Bias in Music Datasets
- 5.
- Concerns Regarding Cultural Representation
6.2. Future Directions
- Enhancing Data Quality and Diversity
- 2.
- Addressing Bias in Music Datasets
- 3.
- Optimizing Training Efficiency
- 4.
- Improving the Quality and Personalization
- 5.
- Deepening Understanding of Musical Structures
- 6.
- Bridging Music and Emotion
- 7.
- Advancing Multi-Modal Music Generation
- 8.
- Developing Commercial Applications
- 9.
- Establishing Clear Copyright Ownership
- 10.
- Strengthening Privacy Protection
- 11.
- Fostering Collaboration Between Technology and Artists
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ji, S.; Luo, J.; Yang, X. A Comprehensive Survey on Deep Music Generation: Multi-Level Representations, Algorithms, Evaluations, and Future Directions. arXiv 2020, arXiv:2011.06801. [Google Scholar]
- Ma, Y.; Øland, A.; Ragni, A.; Sette, B.M.D.; Saitis, C.; Donahue, C.; Lin, C.; Plachouras, C.; Benetos, E.; Shatri, E.; et al. Foundation Models for Music: A Survey. arXiv 2024, arXiv:2408.14340. [Google Scholar]
- Briot, J.-P.; Pachet, F. Music Generation by Deep Learning—Challenges and Directions. Neural Comput. Appl. 2020, 32, 981–993. [Google Scholar] [CrossRef]
- Ji, S.; Yang, X.; Luo, J. A Survey on Deep Learning for Symbolic Music Generation: Representations, Algorithms, Evaluations, and Challenges. ACM Comput. Surv. 2023, 56, 1–39. [Google Scholar] [CrossRef]
- Hernandez-Olivan, C.; Beltran, J.R. Music Composition with Deep Learning: A Review; Springer: Cham, Switzerland, 2021. [Google Scholar]
- Civit, M.; Civit-Masot, J.; Cuadrado, F.; Escalona, M.J. A Systematic Review of Artificial Intelligence-Based Music Generation: Scope, Applications, and Future Trends. Expert Syst. Appl. 2022, 209, 118190. [Google Scholar] [CrossRef]
- Herremans, D.; Chuan, C.-H.; Chew, E. A Functional Taxonomy of Music Generation Systems. ACM Comput. Surv. 2017, 50, 69. [Google Scholar] [CrossRef]
- Zhu, Y.; Baca, J.; Rekabdar, B.; Rawassizadeh, R. A Survey of AI Music Generation Tools and Models. arXiv 2023, arXiv:2308.12982. [Google Scholar] [CrossRef]
- Wen, Y.-W.; Ting, C.-K. Recent Advances of Computational Intelligence Techniques for Composing Music. IEEE Trans. Emerg. Top. Comput. Intell. 2023, 7, 578–597. [Google Scholar] [CrossRef]
- Briot, J.-P.; Hadjeres, G.; Pachet, F.-D. Deep Learning Techniques for Music Generation—A Survey. arXiv 2019, arXiv:1709.01620. [Google Scholar]
- Xenakis, I. Formalized Music: Thought and Mathematics in Composition; Pendragon Press: Hillsdale, NY, USA, 1992. [Google Scholar]
- Schot, J.W.; Hiller, L.; Isaacson, L.M. Experimental Music Composition with an Electronic Computer. In Proceedings of the Mathematics of Computation; American Mathematical Society: Providence, RI, USA, 1962; Volume 16, p. 507. [Google Scholar]
- Biles, J.A. GenJam: A Genetic Algorithm for Generating Jazz Solos. In Proceedings of the International Conference on Mathematics and Computing; Rochester Institute of Technology: Rochester, NY, USA, 1994. [Google Scholar]
- Cope, D. Experiments in Music Intelligence (EMI). In Proceedings of the International Conference on Mathematics and Computing; University of California: Berkeley, CA, USA, 1987. [Google Scholar]
- Fukayama, S.; Nakatsuma, K.; Sako, S.; Nishimoto, T.; Sagayama, S. Automatic Song Composition From The Lyrics Exploiting Prosody Of Japanese Language; Zenodo: Genève, Switzerland, 2010. [Google Scholar]
- Scirea, M.; Barros, G.A.B.; Shaker, N.; Togelius, J. SMUG: Scientific Music Generator; Brigham Young University: Provo, UT, USA, 2015. [Google Scholar]
- Von Rütte, D.; Biggio, L.; Kilcher, Y.; Hofmann, T. FIGARO: Controllable Music Generation Using Learned and Expert Features. arXiv 2022, arXiv:2201.10936v4. [Google Scholar]
- Lu, P.; Xu, X.; Kang, C.; Yu, B.; Xing, C.; Tan, X.; Bian, J. MuseCoco: Generating Symbolic Music from Text. arXiv 2023, arXiv:2306.00110. [Google Scholar] [CrossRef]
- Herremans, D.; Weisser, S.; Sörensen, K.; Conklin, D. Generating Structured Music for Bagana Using Quality Metrics Based on Markov Models. Expert Syst. Appl. 2015, 42, 7424–7435. [Google Scholar] [CrossRef]
- Wu, J.; Hu, C.; Wang, Y.; Hu, X.; Zhu, J. A Hierarchical Recurrent Neural Network for Symbolic Melody Generation. IEEE Trans. Cybern. 2020, 50, 2749–2757. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Dimos, M.; Dorien, H. Hierarchical Recurrent Neural Networks for Conditional Melody Generation with Long-Term Structure. arXiv 2021, arXiv:2102.09794. [Google Scholar]
- Choi, K.; Fazekas, G.; Sandler, M. Text-Based LSTM Networks for Automatic Music Composition. arXiv 2016, arXiv:1604.05358. [Google Scholar]
- Dong, H.-W.; Hsiao, W.-Y.; Yang, L.-C.; Yang, Y.-H. MuseGAN: Multi-Track Sequential Generative Adversarial Networks for Symbolic Music Generation and Accompaniment. Proc. AAAI Conf. Artif. Intell. 2018, 32. [Google Scholar] [CrossRef]
- Huang, C.-Z.A.; Vaswani, A.; Uszkoreit, J.; Shazeer, N.M.; Simon, I.; Hawthorne, C.; Dai, A.M.; Hoffman, M.; Dinculescu, M.; Eck, D. Music Transformer: Generating Music with Long-Term Structure. arXiv 2018, arXiv:1809.04281. [Google Scholar]
- Borsos, Z.; Marinier, R.; Vincent, D.; Kharitonov, E.; Pietquin, O.; Sharifi, M.; Roblek, D.; Teboul, O.; Grangier, D.; Tagliasacchi, M.; et al. AudioLM: A Language Modeling Approach to Audio Generation. arXiv 2023, arXiv:2209.03143. [Google Scholar] [CrossRef]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv 2022, arXiv:2112.10752. [Google Scholar]
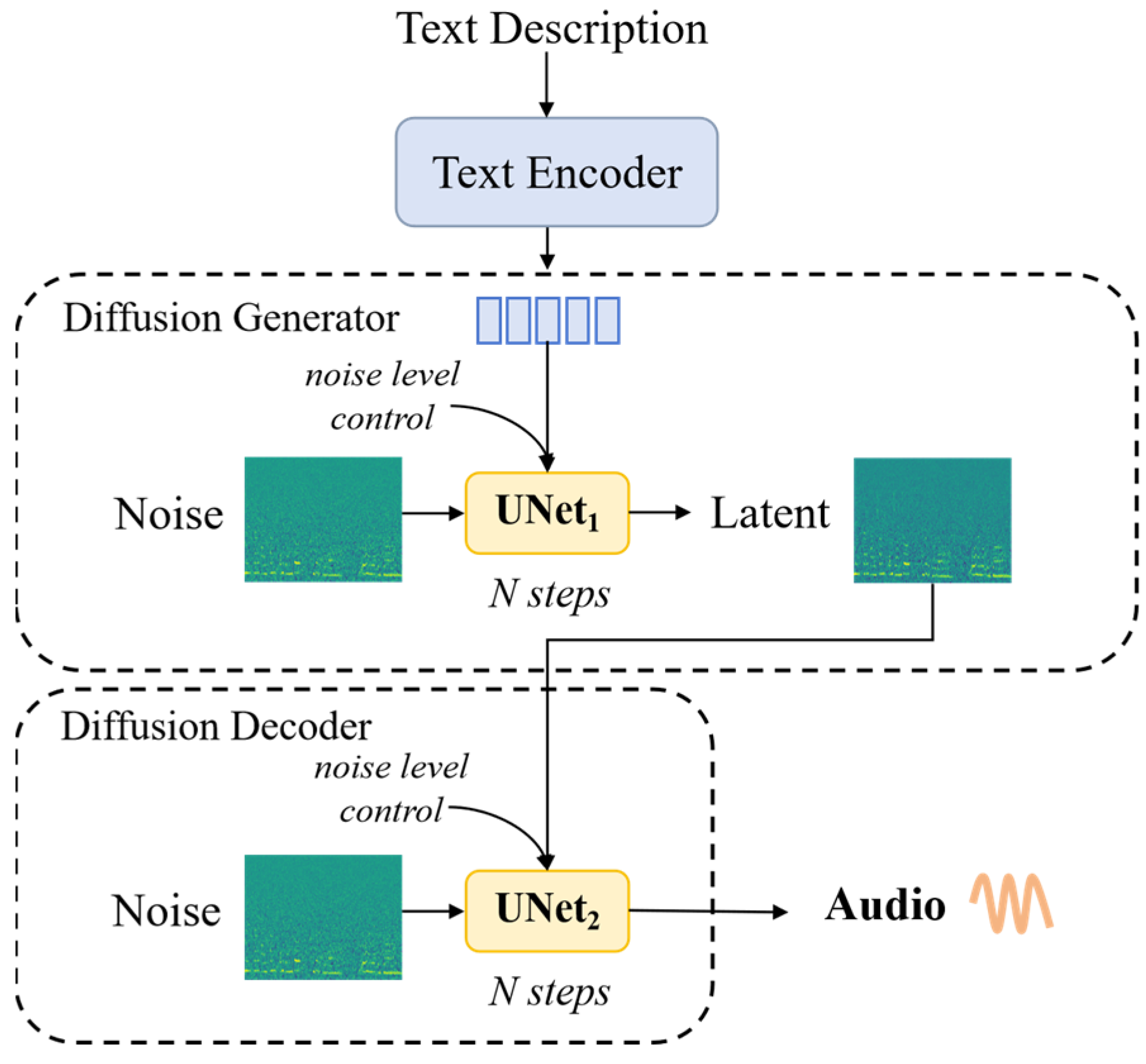
- Evans, Z.; Carr, C.; Taylor, J.; Hawley, S.H.; Pons, J. Fast Timing-Conditioned Latent Audio Diffusion. In Proceedings of the Forty-First International Conference on Machine Learning, Vienna, Austria, 21–27 July 2021. [Google Scholar]
- OpenAI; Achiam, J.; Adler, S.; Agarwal, S.; Ahmad, L.; Akkaya, I.; Aleman, F.L.; Almeida, D.; Altenschmidt, J.; Altman, S.; et al. GPT-4 Technical Report. arXiv 2024, arXiv:2303.08774. [Google Scholar]
- Huang, Y.-S.; Yang, Y.-H. Pop Music Transformer: Beat-Based Modeling and Generation of Expressive Pop Piano Compositions. In Proceedings of the MM ’20, 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1180–1188. [Google Scholar] [CrossRef]
- Monteith, K.; Martinez, T.R.; Ventura, D. Automatic Generation of Melodic Accompaniments for Lyrics. In Proceedings of the ICCC, Dublin, Ireland, 30 May–1 June 2012; pp. 87–94. [Google Scholar]
- Ackerman, M.; Loker, D. Algorithmic Songwriting with ALYSIA. In Proceedings of the Computational Intelligence in Music, Sound, Art and Design; Correia, J., Ciesielski, V., Liapis, A., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 1–16. [Google Scholar]
- Bao, H.; Huang, S.; Wei, F.; Cui, L.; Wu, Y.; Tan, C.; Piao, S.; Zhou, M. Neural Melody Composition from Lyrics. arXiv 2019, arXiv:1809.04318. [Google Scholar] [CrossRef]
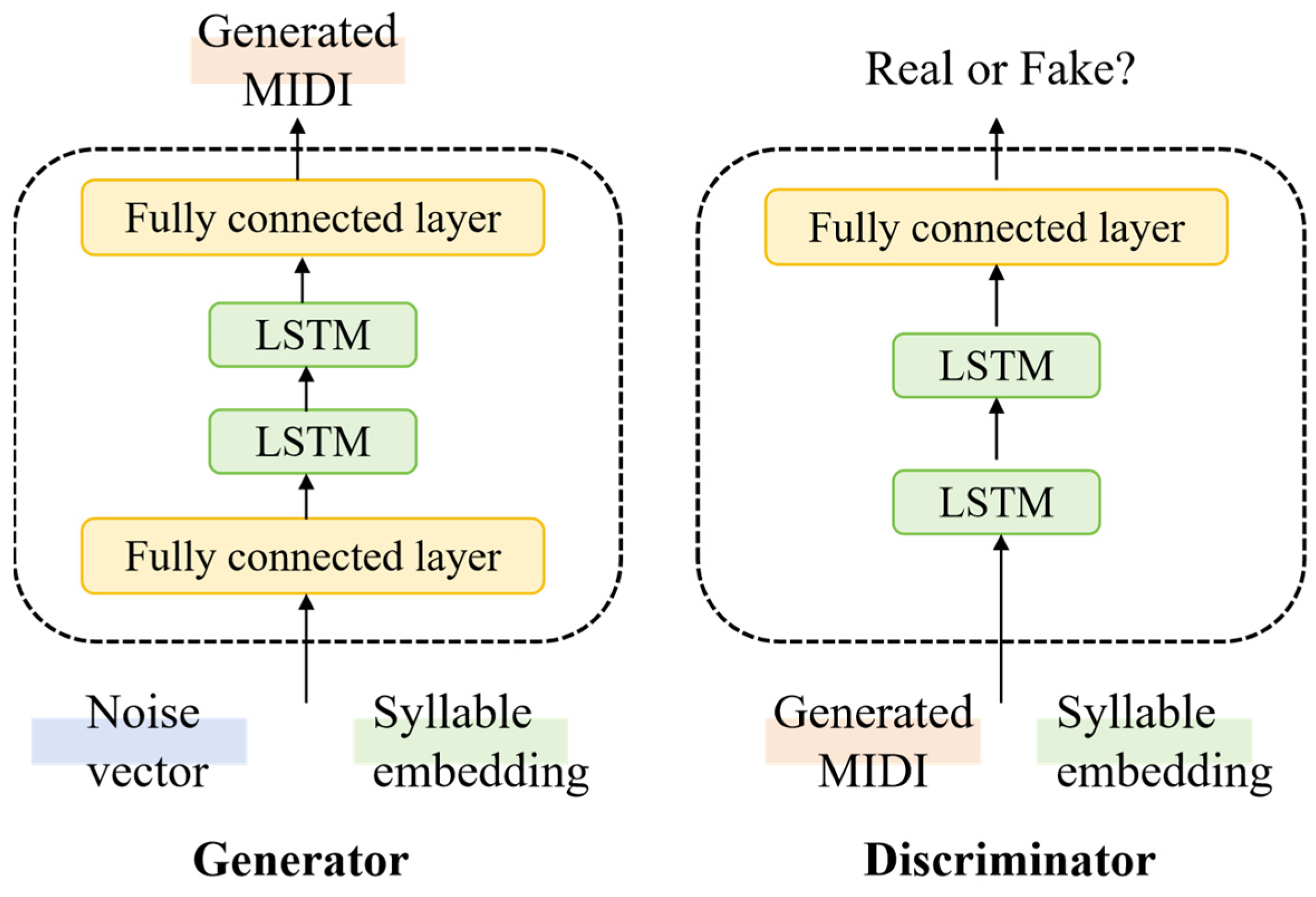
- Yu, Y.; Srivastava, A.; Canales, S. Conditional LSTM-GAN for Melody Generation from Lyrics. ACM Trans. Multimedia Comput. Commun. Appl. 2021, 17, 1–20. [Google Scholar] [CrossRef]
- Srivastava, A.; Duan, W.; Shah, R.R.; Wu, J.; Tang, S.; Li, W.; Yu, Y. Melody Generation from Lyrics Using Three Branch Conditional LSTM-GAN. In Proceedings of the MultiMedia Modeling; Þór Jónsson, B., Gurrin, C., Tran, M.-T., Dang-Nguyen, D.-T., Hu, A.M.-C., Huynh Thi Thanh, B., Huet, B., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 569–581. [Google Scholar]
- Yu, Y.; Zhang, Z.; Duan, W.; Srivastava, A.; Shah, R.; Ren, Y. Conditional Hybrid GAN for Melody Generation from Lyrics. Neural Comput. Appl. 2023, 35, 3191–3202. [Google Scholar] [CrossRef]
- Zhang, Z.; Yu, Y.; Takasu, A. Controllable Lyrics-to-Melody Generation. Neural Comput. Appl. 2023, 35, 19805–19819. [Google Scholar] [CrossRef]
- Sheng, Z.; Song, K.; Tan, X.; Ren, Y.; Ye, W.; Zhang, S.; Qin, T. SongMASS: Automatic Song Writing with Pre-Training and Alignment Constraint. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 19–21 May 2021; Volume 35, pp. 13798–13805. [Google Scholar]
- Ju, Z.; Lu, P.; Tan, X.; Wang, R.; Zhang, C.; Wu, S.; Zhang, K.; Li, X.-Y.; Qin, T.; Liu, T.-Y. TeleMelody: Lyric-to-Melody Generation with a Template-Based Two-Stage Method. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 5426–5437. [Google Scholar] [CrossRef]
- Ding, S.; Liu, Z.; Dong, X.; Zhang, P.; Qian, R.; He, C.; Lin, D.; Wang, J. SongComposer: A Large Language Model for Lyric and Melody Composition in Song Generation. arXiv 2024, arXiv:2402.17645. [Google Scholar] [CrossRef]
- Davis, H.; Mohammad, S. Generating Music from Literature. In Proceedings of the 3rd Workshop on Computational Linguistics for Literature (CLFL), Gothenburg, Sweden, 27 April 2014; Association for Computational Linguistics: Gothenburg, Sweden, 2014; pp. 1–10. [Google Scholar]
- Rangarajan, R. Generating Music from Natural Language Text. In Proceedings of the 2015 Tenth International Conference on Digital Information Management (ICDIM), Jeju, Republic of Korea, 21–23 October 2015; pp. 85–88. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, Z.; Wang, D.; Xia, G. BUTTER: A Representation Learning Framework for Bi-Directional Music-Sentence Retrieval and Generation. In Proceedings of the 1st Workshop on NLP for Music and Audio (NLP4MusA), Online, 16 October 2020; Oramas, S., Espinosa-Anke, L., Epure, E., Jones, R., Sordo, M., Quadrana, M., Watanabe, K., Eds.; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 54–58. [Google Scholar]
- Wu, S.; Sun, M. Exploring the Efficacy of Pre-Trained Checkpoints in Text-to-Music Generation Task. arXiv 2023, arXiv:2211.11216. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.-A.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Yuan, R.; Lin, H.; Wang, Y.; Tian, Z.; Wu, S.; Shen, T.; Zhang, G.; Wu, Y.; Liu, C.; Zhou, Z.; et al. ChatMusician: Understanding and Generating Music Intrinsically with LLM. arXiv 2024, arXiv:2402.16153. [Google Scholar] [CrossRef]
- Liang, X.; Du, X.; Lin, J.; Zou, P.; Wan, Y.; Zhu, B. ByteComposer: A Human-like Melody Composition Method Based on Language Model Agent. arXiv 2024, arXiv:2402.17785. [Google Scholar]
- Deng, Q.; Yang, Q.; Yuan, R.; Huang, Y.; Wang, Y.; Liu, X.; Tian, Z.; Pan, J.; Zhang, G.; Lin, H.; et al. ComposerX: Multi-Agent Symbolic Music Composition with LLMs. arXiv 2024, arXiv:2404.18081. [Google Scholar]
- Liu, H.; Chen, Z.; Yuan, Y.; Mei, X.; Liu, X.; Mandic, D.; Wang, W.; Plumbley, M.D. AudioLDM: Text-to-Audio Generation with Latent Diffusion Models. arXiv 2023, arXiv:2301.12503. [Google Scholar]
- Ghosal, D.; Majumder, N.; Mehrish, A.; Poria, S. Text-to-Audio Generation Using Instruction-Tuned LLM and Latent Diffusion Model. arXiv 2023, arXiv:2304.13731. [Google Scholar]
- Majumder, N.; Hung, C.-Y.; Ghosal, D.; Hsu, W.-N.; Mihalcea, R.; Poria, S. Tango 2: Aligning Diffusion-Based Text-to-Audio Generations through Direct Preference Optimization. In Proceedings of the 32nd ACM International Conference on Multimedia, Melbourne, Australia, 28 October–1 November 2024; pp. 564–572. [Google Scholar]
- Forsgren, S.; Martiros, H. Riffusion-Stable Diffusion for Real-Time Music Generation. 2022. Available online: https://riffusion.com (accessed on 17 February 2025).
- Huang, Q.; Park, D.S.; Wang, T.; Denk, T.I.; Ly, A.; Chen, N.; Zhang, Z.; Zhang, Z.; Yu, J.; Frank, C.; et al. Noise2Music: Text-Conditioned Music Generation with Diffusion Models. arXiv 2023, arXiv:2302.03917. [Google Scholar]
- Schneider, F.; Kamal, O.; Jin, Z.; Schölkopf, B. Moûsai: Text-to-Music Generation with Long-Context Latent Diffusion. arXiv 2023, arXiv:2301.11757. [Google Scholar] [CrossRef]
- Li, P.P.; Chen, B.; Yao, Y.; Wang, Y.; Wang, A.; Wang, A. JEN-1: Text-Guided Universal Music Generation with Omnidirectional Diffusion Models. In Proceedings of the 2024 IEEE Conference on Artificial Intelligence (CAI), Singapore, 25–27 June 2024; pp. 762–769. [Google Scholar] [CrossRef]
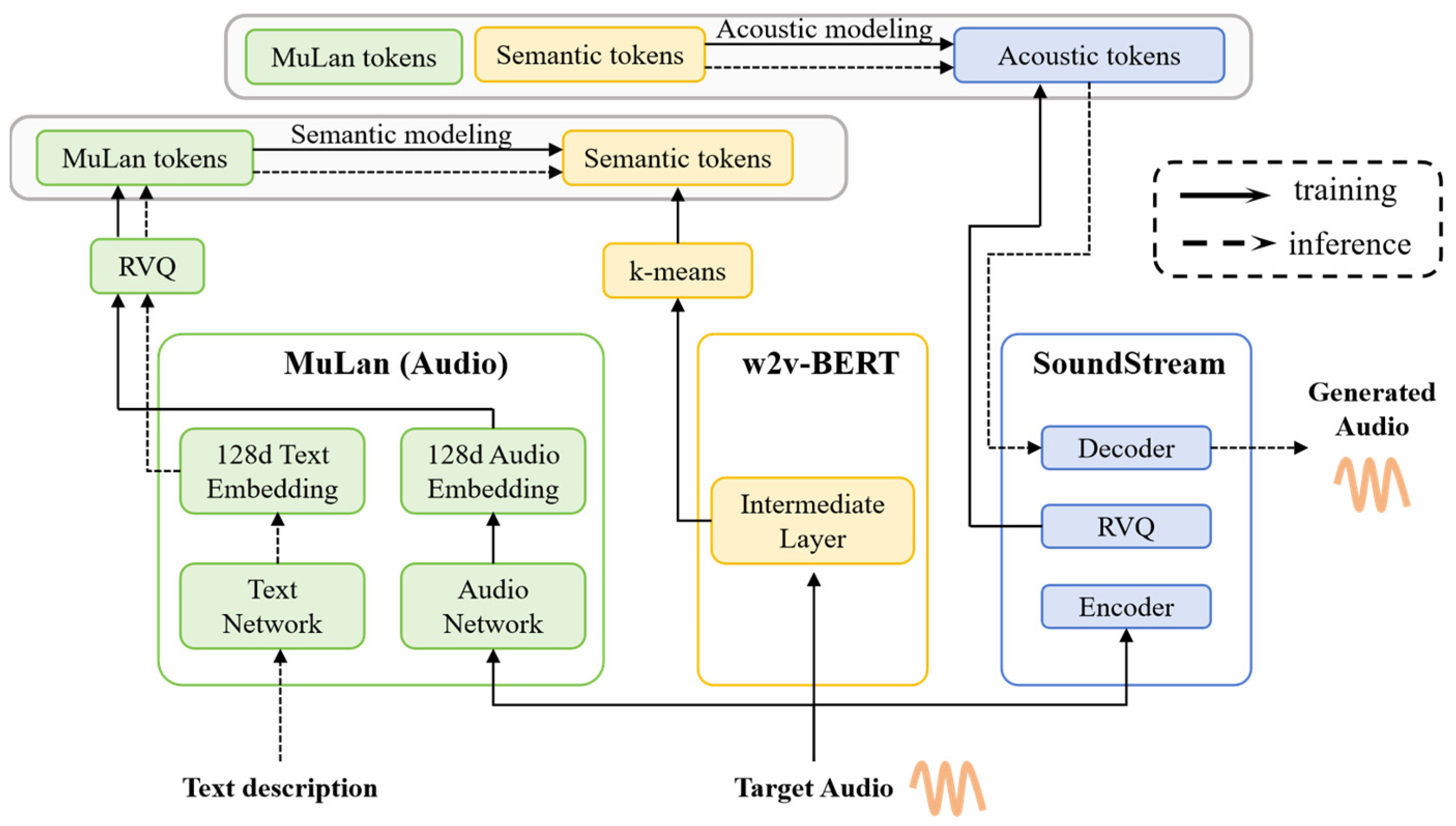
- Agostinelli, A.; Denk, T.I.; Borsos, Z.; Engel, J.; Verzetti, M.; Caillon, A.; Huang, Q.; Jansen, A.; Roberts, A.; Tagliasacchi, M.; et al. MusicLM: Generating Music From Text. arXiv 2023, arXiv:2301.11325. [Google Scholar]
- Huang, Q.; Jansen, A.; Lee, J.; Ganti, R.; Li, J.Y.; Ellis, D.P.W. MuLan: A Joint Embedding of Music Audio and Natural Language. arXiv 2022, arXiv:2208.12415. [Google Scholar]
- Lam, M.W.Y.; Tian, Q.; Li, T.; Yin, Z.; Feng, S.; Tu, M.; Ji, Y.; Xia, R.; Ma, M.; Song, X.; et al. Efficient Neural Music Generation. Adv. Neural Inf. Process. Syst. 2023, 36, 17450–17463. [Google Scholar]
- Chen, K.; Wu, Y.; Liu, H.; Nezhurina, M.; Berg-Kirkpatrick, T.; Dubnov, S. MusicLDM: Enhancing Novelty in Text-to-Music Generation Using Beat-Synchronous Mixup Strategies. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; pp. 1206–1210. [Google Scholar]
- Copet, J.; Kreuk, F.; Gat, I.; Remez, T.; Kant, D.; Synnaeve, G.; Adi, Y.; Defossez, A. Simple and Controllable Music Generation. Adv. Neural Inf. Process. Syst. 2023, 36, 47704–47720. [Google Scholar]
- Macon, M.W.; Jensen-Link, L.; George, E.; Oliverio, J.C.; Clements, M. Concatenation-Based MIDI-to-Singing Voice Synthesis. J. Audio Eng. Soc. 1997, 4591. Available online: https://secure.aes.org/forum/pubs/conventions/?elib=7188 (accessed on 17 February 2025).
- Kenmochi, H.; Ohshita, H. VOCALOID-Commercial Singing Synthesizer Based on Sample Concatenation. In Proceedings of the INTERSPEECH 2007, 8th Annual Conference of the International Speech Communication Association, Antwerp, Belgium, 27–31 August 2007; Volume 2007, pp. 4009–4010. [Google Scholar]
- Saino, K.; Zen, H.; Nankaku, Y.; Lee, A.; Tokuda, K. An HMM-Based Singing Voice Synthesis System. In Proceedings of the Interspeech 2006, Pittsburgh, PA, USA, 17–21 September 2006; ISCA: Singapore, 2006. [Google Scholar]
- Nishimura, M.; Hashimoto, K.; Oura, K.; Nankaku, Y.; Tokuda, K. Singing Voice Synthesis Based on Deep Neural Networks. In Proceedings of the Interspeech 2016, San Francisco, CA, USA, 8–12 September 2016; ISCA: Singapore, 2016; pp. 2478–2482. [Google Scholar]
- Nakamura, K.; Hashimoto, K.; Oura, K.; Nankaku, Y.; Tokuda, K. Singing Voice Synthesis Based on Convolutional Neural Networks. arXiv 2019, arXiv:1904.06868. [Google Scholar]
- Kim, J.; Choi, H.; Park, J.; Kim, S.; Kim, J.; Hahn, M. Korean Singing Voice Synthesis System Based on an LSTM Recurrent Neural Network. In Proceedings of the Interspeech, Hyderabad, India, 2–6 September 2018; pp. 1551–1555. [Google Scholar]
- Hono, Y.; Hashimoto, K.; Oura, K.; Nankaku, Y.; Tokuda, K. Singing Voice Synthesis Based on Generative Adversarial Networks. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6955–6959. [Google Scholar] [CrossRef]
- Lu, P.; Wu, J.; Luan, J.; Tan, X.; Zhou, L. XiaoiceSing: A High-Quality and Integrated Singing Voice Synthesis System. arXiv 2020, arXiv:2006.06261. [Google Scholar]
- Ren, Y.; Ruan, Y.; Tan, X.; Qin, T.; Zhao, S.; Zhao, Z.; Liu, T.-Y. FastSpeech: Fast, Robust and Controllable Text to Speech. arXiv 2019, arXiv:1905.09263. [Google Scholar]
- Morise, M.; Yokomori, F.; Ozawa, K. World: A Vocoder-Based High-Quality Speech Synthesis System for Real-Time Applications. IEICE Trans. Inf. Syst. 2016, 99, 1877–1884. [Google Scholar] [CrossRef]
- Blaauw, M.; Bonada, J. Sequence-to-Sequence Singing Synthesis Using the Feed-Forward Transformer. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7229–7233. [Google Scholar] [CrossRef]
- Zhuang, X.; Jiang, T.; Chou, S.-Y.; Wu, B.; Hu, P.; Lui, S. Litesing: Towards Fast, Lightweight and Expressive Singing Voice Synthesis. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; p. 7082. [Google Scholar]
- Lee, G.-H.; Kim, T.-W.; Bae, H.; Lee, M.-J.; Kim, Y.-I.; Cho, H.-Y. N-Singer: A Non-Autoregressive Korean Singing Voice Synthesis System for Pronunciation Enhancement. arXiv 2022, arXiv:2106.15205v2. [Google Scholar]
- Chen, J.; Tan, X.; Luan, J.; Qin, T.; Liu, T.-Y. HiFiSinger: Towards High-Fidelity Neural Singing Voice Synthesis. arXiv 2020, arXiv:2009.01776. [Google Scholar]
- Yamamoto, R.; Song, E.; Kim, J.-M. Parallel WaveGAN: A Fast Waveform Generation Model Based on Generative Adversarial Networks with Multi-Resolution Spectrogram. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Wang, Y.; Skerry-Ryan, R.J.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards End-to-End Speech Synthesis. arXiv 2017, arXiv:1703.10135. [Google Scholar]
- Gu, Y.; Yin, X.; Rao, Y.; Wan, Y.; Tang, B.; Zhang, Y.; Chen, J.; Wang, Y.; Ma, Z. ByteSing: A Chinese Singing Voice Synthesis System Using Duration Allocated Encoder-Decoder Acoustic Models and WaveRNN Vocoders. arXiv 2021, arXiv:2004.11012. [Google Scholar]
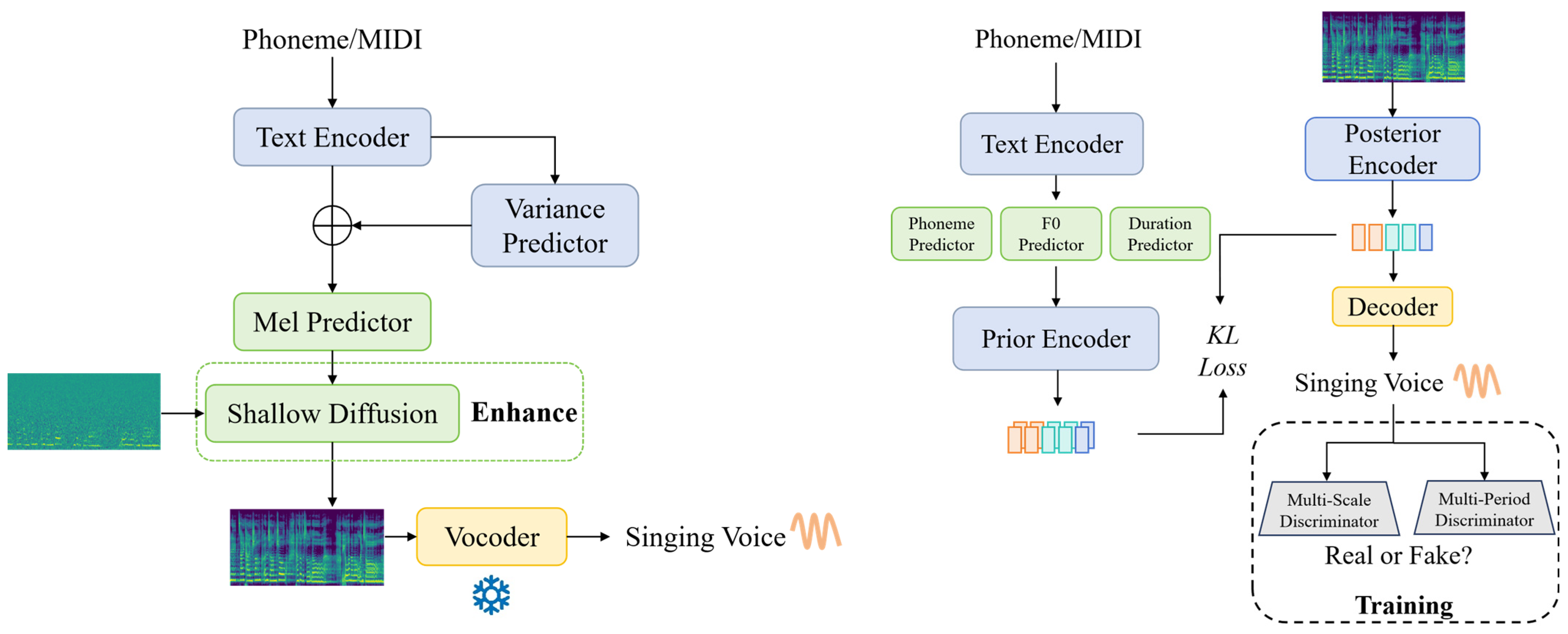
- Liu, J.; Li, C.; Ren, Y.; Chen, F.; Zhao, Z. DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism. arXiv 2022, arXiv:2105.02446. [Google Scholar] [CrossRef]
- Hono, Y.; Hashimoto, K.; Oura, K.; Nankaku, Y.; Tokuda, K. Sinsy: A Deep Neural Network-Based Singing Voice Synthesis System. Proc. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 2803–2815. [Google Scholar] [CrossRef]
- Zhang, Y.; Cong, J.; Xue, H.; Xie, L.; Zhu, P.; Bi, M. VISinger: Variational Inference with Adversarial Learning for End-to-End Singing Voice Synthesis. arXiv 2022, arXiv:2110.08813. [Google Scholar]
- Zhang, Y.; Xue, H.; Li, H.; Xie, L.; Guo, T.; Zhang, R.; Gong, C. VISinger 2: High-Fidelity End-to-End Singing Voice Synthesis Enhanced by Digital Signal Processing Synthesizer. arXiv 2022, arXiv:2211.02903. [Google Scholar]
- Kim, J.; Kong, J.; Son, J. Conditional Variational Autoencoder with Adversarial Learning for End-to-End Text-to-Speech. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 5530–5540. [Google Scholar]
- Hong, Z.; Huang, R.; Cheng, X.; Wang, Y.; Li, R.; You, F.; Zhao, Z.; Zhang, Z. Text-to-Song: Towards Controllable Music Generation Incorporating Vocals and Accompaniment. arXiv 2024, arXiv:2404.09313. [Google Scholar]
- Dhariwal, P.; Jun, H.; Payne, C.; Kim, J.W.; Radford, A.; Sutskever, I. Jukebox: A Generative Model for Music. arXiv 2020, arXiv:2005.00341. [Google Scholar]
- Bai, Y.; Chen, H.; Chen, J.; Chen, Z.; Deng, Y.; Dong, X.; Hantrakul, L.; Hao, W.; Huang, Q.; Huang, Z.; et al. Seed-Music: A Unified Framework for High Quality and Controlled Music Generation. arXiv 2024, arXiv:2409.09214. [Google Scholar]
- Chen, G.; Liu, Y.; Zhong, S.; Zhang, X. Musicality-Novelty Generative Adversarial Nets for Algorithmic Composition. In Proceedings of the 26th ACM international conference on Multimedia, Seoul, Republic of Korea, 22–26 October 2018; pp. 1607–1615. [Google Scholar] [CrossRef]
- Hakimi, S.H.; Bhonker, N.; El-Yaniv, R. BebopNet: Deep Neural Models for Personalized Jazz Improvisations. In Proceedings of the ISMIR, Online, 11–15 October 2020; pp. 828–836. [Google Scholar]
- Monteith, K.; Martinez, T.R.; Ventura, D. Automatic Generation of Music for Inducing Emotive Response. In Proceedings of the ICCC, Lisbon, Portugal, 7–9 January 2010; pp. 140–149. [Google Scholar]
- Hung, H.-T.; Ching, J.; Doh, S.; Kim, N.; Nam, J.; Yang, Y.-H. EMOPIA: A Multi-Modal Pop Piano Dataset For Emotion Recognition and Emotion-Based Music Generation. arXiv 2021, arXiv:2108.01374. [Google Scholar]
- Zheng, K.; Meng, R.; Zheng, C.; Li, X.; Sang, J.; Cai, J.; Wang, J.; Wang, X. EmotionBox: A Music-Element-Driven Emotional Music Generation System Based on Music Psychology. Front. Psychol. 2022, 13, 841926. [Google Scholar] [CrossRef] [PubMed]
- Neves, P.; Fornari, J.; Florindo, J. Generating Music with Sentiment Using Transformer-GANs. arXiv 2022, arXiv:2212.11134. [Google Scholar]
- Dash, A.; Agres, K.R. AI-Based Affective Music Generation Systems: A Review of Methods, and Challenges. arXiv 2023, arXiv:2301.06890. [Google Scholar] [CrossRef]
- Ji, S.; Yang, X. EmoMusicTV: Emotion-Conditioned Symbolic Music Generation with Hierarchical Transformer VAE. IEEE Trans. Multimed. 2024, 26, 1076–1088. [Google Scholar] [CrossRef]
- Jiang, N.; Jin, S.; Duan, Z.; Zhang, C. RL-Duet: Online Music Accompaniment Generation Using Deep Reinforcement Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton, NY, USA, 7–12 February 2020; Volume 34, pp. 710–718. [Google Scholar]
- Louie, R.; Coenen, A.; Huang, C.Z.; Terry, M.; Cai, C.J. Novice-AI Music Co-Creation via AI-Steering Tools for Deep Generative Models. In Proceedings of the CHI ‘20, 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–13. [Google Scholar] [CrossRef]
- Kwon, H. AudioGuard: Speech Recognition System Robust against Optimized Audio Adversarial Examples. Multimed. Tools Appl. 2024, 83, 57943–57962. [Google Scholar] [CrossRef]
- Surbhi, A.; Roy, D. Tunes of Tomorrow: Copyright and AI-Generated Music in the Digital Age. AIP Conf. Proc. 2024, 3220, 050003. [Google Scholar] [CrossRef]
- Hsiao, W.-Y.; Liu, J.-Y.; Yeh, Y.-C.; Yang, Y.-H. Compound Word Transformer: Learning to Compose Full-Song Music over Dynamic Directed Hypergraphs. Proc. AAAI Conf. Artif. Intell. 2021, 35, 178–186. [Google Scholar] [CrossRef]
- Josan, H.H.S. AI and Deepfake Voice Cloning: Innovation, Copyright and Artists’ Rights; Centre for International Governance Innovation: Waterloo, ON, Canada, 2024. [Google Scholar]
- Zhang, Z.; Ning, H.; Shi, F.; Farha, F.; Xu, Y.; Xu, J.; Zhang, F.; Choo, K.-K.R. Artificial Intelligence in Cyber Security: Research Advances, Challenges, and Opportunities. Artif. Intell. Rev. 2022, 55, 1029–1053. [Google Scholar] [CrossRef]
- Fox, M.; Vaidyanathan, G.; Breese, J.L. The Impact of Artificial Intelligence on Musicians. Issues Inf. Syst. 2024, 25, 267–276. [Google Scholar]
- Liu, X.; Dong, Z.; Zhang, P. Tackling Data Bias in Music-Avqa: Crafting a Balanced Dataset for Unbiased Question-Answering. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 4478–4487. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Keywords | Focus on Cross-Modal Text-to-Music | Classification Based on Symbolic & Audio | Task-Oriented Generation | Inclusion of Kinds of Methods | General Text-to-Music Framework | Challenges and Future Directions |
|---|---|---|---|---|---|---|---|
| [1] | Multi-level Representations | × | √ | √ | Deep Learning Methods | × | √ |
| [2] | Foundation Model | × | √ | √ | LLMs Methods | × | √ |
| [3] | Deep Learning | × | × | × | Deep Learning Methods | × | √ |
| [4] | Deep Learning, Symbolic Music | × | Only Symbolic | √ | Deep Learning Methods | × | √ |
| [5] | Deep Learning | × | × | √ | Deep Learning Methods | × | × |
| [6] | Scoping review | × | × | × | × | × | × |
| [7] | Functional Taxonomy | × | × | √ | Traditional Methods and Deep Learning Methods | × | √ |
| [8] | Tools and Models | × | × | × | Neural Network and Non-Neural Network Methods | × | × |
| [9] | Evolutionary Computation and Genetic Algorithm | × | × | × | EC and GA Methods | × | √ |
| [10] | Deep Learning | × | √ | × | Neural Network Methods | × | √ |
| Our Review | Text to music | √ | √ | √ | Both Traditional, Neural Network and LLMs Methods | √ | √ |
| Category | Description | Application Example | Generation Characteristics | Challenges |
|---|---|---|---|---|
| Lyrics | The singing words of songs. | “Let it be, let it be…” |
|
|
| Musical Attributes | Describes musical rules like chords. | I-IV-V-I, 120 bpm |
|
|
| Natural Language Description | Describes emotion or scene. | “Create a melody filled with hope…” |
|
|
| Event Type | Description | Example Format |
|---|---|---|
| Note On | Starts a note | Note On, Channel 1, Pitch 60, Velocity 100 |
| Note Off | Ends a note | Note Off, Channel 1, Pitch 60, Velocity 0 |
| Program Change | Changes in instrument or sound | Program Change, Channel 1, Program 32 |
| Control Change | Adjusts control parameters (e.g., volume, sustain pedal) | Control Change, Channel 1, Controller 64, Value 127 |
| Pitch Bend | Bends pitch slightly or continuously | Pitch Bend, Channel 1, Value 8192 |
| Aftertouch | Pressure applied after pressing a note | Aftertouch, Channel 1, Pressure 60 |
| Tempo Change | Sets playback speed in beats per minute (BPM) | Tempo Change, 120 BPM |
| Time Signature | Defines beat structure (e.g., 4/4, 3/4 time) | Time Signature, 4/4 |
| Key Signature | Sets the song’s key (e.g., C Major, G Minor) | Key Signature, C Major |
| Task Type | Model Name | Year | Music Representation | Model Architecture | Framework Category 1 | Description | Large Model Relevance | Dataset | Generated Music Length | Accessed Link | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T. | H. | L. | ||||||||||
| Lyric-based Melody Generation | SongComposer [39] | 2024 | MIDI | Transformer | √ | LLM, Instruction Following, Next Token Prediction | A LLM designed for composing songs | 283 k Lyrics 20 k Melodies 15 k Paired Lyric-melody | Multiple minutes | https://pjlab-songcomposer.github.io/ (accessed on 17 February 2025) | ||
| TeleMelody [35] | 2022 | MIDI | Transformer | √ | Transformer-based Encoder-Decoder, Template-Based Two-Stage Method | / | 84 k Paired Lyric-melody | Not mentioned | https://ai-muzic.github.io/telemelody/ (accessed on 17 February 2025) | |||
| SongMass [37] | 2021 | MIDI | Transformer | √ | Pre-training, the sentence-level and token-level alignment constraints. | / | 380 k Lyrics 66 k Melodies 8 k Paired Lyric-melody | Not mentioned | https://musicgeneration.github.io/SongMASS/ (accessed on 17 February 2025) | |||
| [33] | 2021 | MIDI | LSTM-GAN | √ | Conditional LSTM-GAN, Synchronized Lyrics—Note Alignment | / | 12,197 MIDI songs | Not mentioned | https://drive.google.com/file/d/1ugOwfBsURax1VQ4jHmI8P3ldE5xdDj0l/view?usp=sharing (accessed on 17 February 2025) | |||
| SongWriter [32] | 2019 | MIDI | RNN | √ | Seq-to-Seq, Lyric-Melody Alignment | / | 18,451 Chinese pop songs | Not mentioned | / | |||
| ALYSIA [28] | 2017 | MusicXML 2 & MIDI | Random Forests | √ | Co-creative Songwriting Partner, Rhythm Model, Melody Model | / | / | Not mentioned | http://bit.ly/2eQHado (accessed on 17 February 2025) | |||
| Orpheus [15] | 2010 | MIDI | / | / | Dynamic Programming | / | Japanese prosody dataset | Not mentioned | https://www.orpheus-music.org/index.php (accessed on 17 February 2025) | |||
| Musical attribute-based Melody Generation | BUTTER [42] | 2020 | MIDI, ABC Notation | VAE | √ | Representation Learning, Bi-directional Music-Text Retrieval | / | 16,257 Chinese folk songs | Short Music Fragment | https://github.com/ldzhangyx/BUTTER (accessed on 17 February 2025) | ||
| [41] | 2015 | MIDI | / | / | Full parse tree, POS Tag | / | / | Not mentioned | / | |||
| TransProse [37] | 2014 | MIDI | Markov Chains | / | Generate music from Literature, Emotion Density | / | Emotional words from the literature | Not mentioned | https://www.musicfromtext.com/ (accessed on 17 February 2025) | |||
| Description- based Melody Generation | ChatMusician [45] | 2024 | ABC Notation | Transformer | √ | Music Reasoning, Repetition Structure | An LLM of symbolic music understanding and generation | 5.17 M datas in different formats (MusicPile) | Full Score of ABC Notation | https://shanghaicannon.github.io/ChatMusician/ (accessed on 17 February 2025) | ||
| [43] | 2023 | ABC Notation | Transformer | √ | Exploring the Efficacy of Pre-trained Checkpoints. | Using pre-trained checkpoints | 282,870 text-tune pairs | Full Score of ABC Notation | / | |||
| Agent Name | Task Description |
|---|---|
| Group Leader Agent | Responsible for analyzing user input and breaking it down into specific tasks to be assigned to other agents. |
| Melody Agent | Generates a monophonic melody under the guidance of the Group Leader. |
| Harmony Agent | Adds harmony and counterpoint elements to the composition to enrich its structure. |
| Instrument Agent | Selects appropriate instruments for each voice part. |
| Reviewer Agent | Evaluates and provides feedback on the melody, harmony, and instrument choices. |
| Arrangement Agent | Standardizes the final output into ABC notation format. |
| Task Type | Model Name | Year | Music Representation | Model Architecture | Framework Category | Description | Large Model Relevance | Dataset | Generated Music Length | Accessed Link | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T. | H. | L. | ||||||||||
| Musical Attribute-based Polyphony Generation | FIGARO [17] | 2023 | REMI+ | Transformer | √ | Human- interpretable, Expert Description, Multi-Track | / | 176,581 MIDI files (LakhMIDI Dataset) | Not mentioned | https://tinyurl.com/28etxz27 (accessed on 17 February 2025). | ||
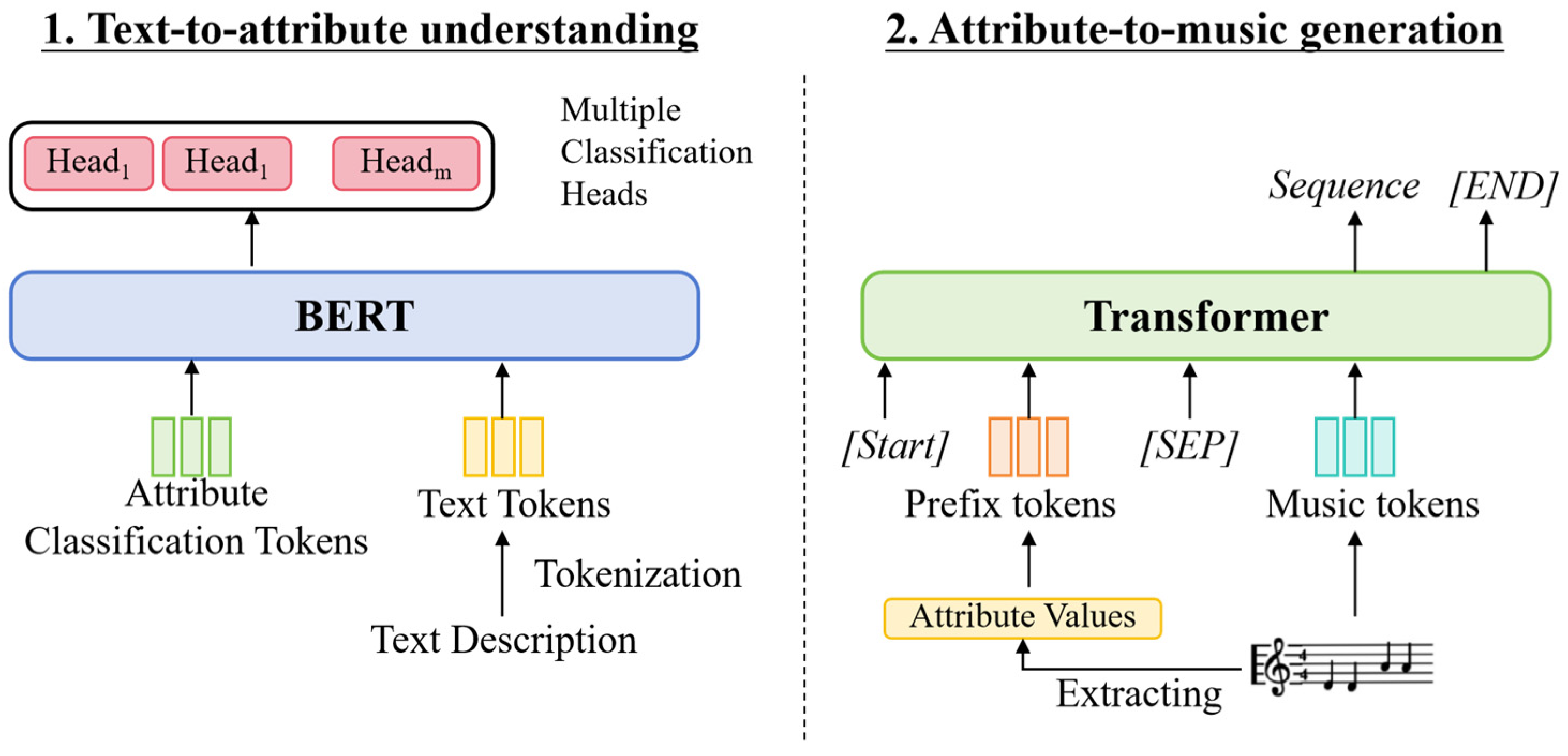
| MuseCoco [18] | 2023 | MIDI | Transformer | √ | Text-to-attribute understanding and attribute-to-music generation | Textual synthesis and template refinement | 947,659 MIDI (Partially contains emotional, genre information) | <= 16 bars | https://ai-muzic.github.io/musecoco/ (accessed on 17 February 2025) | |||
| Description- based Polyphony Generation | ByteComposer [46] | 2024 | MIDI | Transformer | √ | Imitate the human creative process, Multi-step Reasoning, Procedural Control | A melody composition LLM agent | 216,284 ABC Notations | Not mentioned | / | ||
| ComposerX [47] | 2024 | ABC Notation | Transformer | √ | Significantly improve the music generation quality of GPT-4 through a multi-agent approach | Multi-agent LLM-based framework | 324,987 ABC Notations | Varied Lengths | https://lllindsey0615.github.io/ComposerX_demo/ (accessed on 17 February 2025). | |||
| Task Type | Model Name | Year | Music Representation | Model Architecture | Framework Category | Description | Large Model Relevance | Dataset | Generated Music Length | Accessed Link | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T. | H. | L. | ||||||||||
| Label-based Instrumental Music Generation | Mubert | / | Waveform | / | / | Tag-based control, Music segment combination | / | / | Varied lengths | https://mubert.com/ (accessed on 17 February 2025). | ||
| Description-based instrumental music Generation | JEN-1 [54] | 2024 | Waveform (48 kHz) | Diffusion | √ | Omnidirectional Diffusion Models, Hybrid AR and NAR Architecture, Masked Noise Robust Autoencoder | Employ FLAN-T5 to provide superior text embedding extraction | 15 k 48 kHz audios | Varied lengths | https://jenmusic.ai/audio-demos (accessed on 17 February 2025). | ||
| MusicLDM [58] | 2024 | Mel-Spectrogram | Diffusion | √ | Beat-synchronous mixup, Latent Diffusion, CLAP, AudioLDM | Trained on Broad Data at Scale | 2.8 M music-audio pairs for CLAP (20 k hours) 10 k pairs for MusicLDM | Varied lengths | https://musicldm.github.io/ (accessed on 17 February 2025). | |||
| Moûsai [53] | 2023 | Waveform (48 kHz@2) | Diffusion | √ | Latent Diffusion, 64× compression | / | 50 k 48 kHz Text-music pairs (2.5 k h) | Multiple minutes | https://diligent-pansy-4cb.notion.site/Music-Generation-with-Diffusion-ebe6e9e528984fa1b226d408f6002d87 (accessed on 17 February 2025). | |||
| MusicGen [59] | 2023 | Discrete tokens (32 kHz) | Transformer | √ | Transformer LM, Codebook Interleaving Strategy | Trained on Broad Data at Scale | 390 k 32 kHz audios (20 k hours) | <= 5 min | https://github.com/facebookresearch/audiocraft (accessed on 17 February 2025). | |||
| MeLoDy [57] | 2023 | Waveform (24 kHz) | Diffusion& VAE-GAN | √ | Dual-path diffusion, language model, Audio VAE-GAN | Trained LLaMA for semantic modeling | 6.4 M 24 kHz audios (257 k hour) | 10 s–30 s | https://efficient-melody.github.io/ (accessed on 17 February 2025). | |||
| MusicLM [55] | 2023 | Waveform (24 kHz) | Transformer | √ | Based on AudioLM, multi-stage modeling, MuLan | Optimize using pre-trained models Mulan and w2v-BERT | 5 M 24 kHz audios (280 k hours) | Multiple minutes | https://google-research.github.io/seanet/musiclm/examples/ (accessed on 17 February 2025). | |||
| Noise2Music [52] | 2023 | Spectrogram and Waveform(better) | Diffusion | √ | Cascading diffusion, 1D Efficient U-Net | Using for Description for Training Generation and Text Embedding Extraction | 6.8 M 24 kHz and 16 kHz audios (340 k hours) | 30 s | https://google-research.github.io/noise2music (accessed on 17 February 2025). | |||
| Riffusion [51] | 2022 | Spectrogram | Diffusion | √ | Tag-based control, Music segment combination | / | / | ≈10 s | https://www.riffusion.com/ (accessed on 17 February 2025). | |||
| Task Type | Model Name | Year | Music Representation | Model Architecture | Description | Dataset | Accessed Link |
|---|---|---|---|---|---|---|---|
| Commercial Singing Voice Engine | ACE Studio | 2021 | / | / | AI synthesis, Auto pitch | / | https://acestudio.ai/ (accessed on 17 February 2025). |
| Synthesizer V Studio | 2018 | / | / | WaveNet vocoder, DNN, AI synthesis | / | https://dreamtonics.com/synthesizerv/ (accessed on 17 February 2025). | |
| Vocaloid | 2004 | Waveform&Spectrum | / | sample concatenation | / | https://www.vocaloid.com/ (accessed on 17 February 2025). | |
| Singing Voice Synthesis | VISinger 2 [80] | 2022 | Mel-Spectrogram | VAE + DSP | conditional VAE, Improved Decoder, Parameter Optimization, Higher Sampling Rate (Considering to VISinger) | 100 24 kHz Chinese singing records (5.2 h) | https://zhangyongmao.github.io/VISinger2/ (accessed on 17 February 2025). |
| VISinger [79] | 2022 | Mel-Spectrogram | VAE + GAN | end-to-end solution, F0 predictor, normalizing flow based prior encoder and adversarial decoder | 100 24 kHz Mandarin singing records (4.7 h) | https://zhangyongmao.github.io/VISinger/ (accessed on 17 February 2025). | |
| DiffSinger [77] | 2021 | Mel-Spectrogram | Diffusion + Neural Vocoder | Shallow diffusion mechanism, parameterized Markov chain, Denoising Diffusion Probabilistic Model, FastSpeech | 117 24 kHz Mandarin singing records (5.89 h) | https://www.diffsinger.com/ (accessed on 17 February 2025). | |
| HiFiSinger [73] | 2020 | Mel-Spectrogram | Transformer + Neural Vocoder | Parallel WaveGAN (sub-frequency GAN + multi-length GAN), FastSpeech | 6817 48 kHz pieces singing records (11 h) | https://speechresearch.github.io/hifisinger/ (accessed on 17 February 2025). | |
| ByteSing [76] | 2020 | Mel-Spectrogram | Transformer + Neural Vocoder | WaveRNN, Auxiliary Phoneme Duration Prediction model, Tacotron | 90 24 kHz Mandarin singing records | https://ByteSings.github.io (accessed on 17 February 2025). | |
| XiaoiceSing [67] | 2020 | Acoustic parameters | Transformer + WORLD | integrated network, Residual F0, syllable duration modeling, FastSpeech | 2297 48 kHz Mandarin singing records (74 h) | https://xiaoicesing.github.io/ (accessed on 17 February 2025). | |
| [63] | 2016 | Acoustic parameters | DNN | musical-note-level pitch normalization, linear-interpolation | 70 48 kHz Japanese singing records | / | |
| [62] | 2006 | Acoustic parameters | HMM | Context-dependent HMMs, duration models, and time-lag models | 60 44.1 kHz Japanese singing records | https://www.sp.nitech.ac.jp/~k-saino/music/ (accessed on 17 February 2025). | |
| Lyricos [60] | 1997 | Waveform | Sinusoidal model | ABS/OLA sinusoidal model, vibrato, phonetic modeling | 10 min singing records | / |
| Task Type | Model Name | Year | Music Representation | Model Architecture | Framework Category | Description | Large Model Relevance | Dataset Name | Generated Music Length | Accessed Link | ||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| T. | H. | L. | ||||||||||
| Staged Generation | Melodist [82] | 2024 | Waveform | Transformer | √ | Tri-Tower Contrastive Pre-training, Cross-Modality Information Matching, Lyrics and Prompt-based | Using LLM to generate natural language prompts | 5 k Chinese songs with attributes (180 h) | Not mentioned | https://text2songMelodist.github.io/Sample/ (accessed on 17 February 2025). | ||
| end-to-end Generation | Seed-Music [84] | 2024 | Waveform & MIDI | Transformer& Diffusion | √ | Multi-modal Inputs, Auto-regressive Language Modeling, Vocoder Latents, Zero-shot Singing Voice Conversion | Large multi-modal language models for understanding and generation | Not mentioned | Varied Length | https://team.doubao.com/en/special/seed-music (accessed on 17 February 2025). | ||
| Suno AI | 2023 | Waveform | Transformer | √ | Heuristic method, Audio Tokenization, Zero threshold for use | / | Not mentioned | <= 4 min | https://alpha.suno.ai/ (accessed on 17 February 2025). | |||
| Jukebox [83] | 2020 | Waveform | VQ-VAE + Transformer | √ | Multiscale VQ-VAE, Autoregressive Transformer, Conditional Generation, Hierarchical Modeling | Trained on Broad Data at Scale | 1.2 M English songs with attributes (600 k hours) | Multiple minutes | https://jukebox.openai.com/ (accessed on 17 February 2025). | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Yang, M.; Lin, Y.; Zhang, X.; Shi, F.; Wang, Z.; Ding, J.; Ning, H. AI-Enabled Text-to-Music Generation: A Comprehensive Review of Methods, Frameworks, and Future Directions. Electronics 2025, 14, 1197. https://doi.org/10.3390/electronics14061197
Zhao Y, Yang M, Lin Y, Zhang X, Shi F, Wang Z, Ding J, Ning H. AI-Enabled Text-to-Music Generation: A Comprehensive Review of Methods, Frameworks, and Future Directions. Electronics. 2025; 14(6):1197. https://doi.org/10.3390/electronics14061197
Chicago/Turabian StyleZhao, Yujia, Mingzhi Yang, Yujia Lin, Xiaohong Zhang, Feifei Shi, Zongjie Wang, Jianguo Ding, and Huansheng Ning. 2025. "AI-Enabled Text-to-Music Generation: A Comprehensive Review of Methods, Frameworks, and Future Directions" Electronics 14, no. 6: 1197. https://doi.org/10.3390/electronics14061197
APA StyleZhao, Y., Yang, M., Lin, Y., Zhang, X., Shi, F., Wang, Z., Ding, J., & Ning, H. (2025). AI-Enabled Text-to-Music Generation: A Comprehensive Review of Methods, Frameworks, and Future Directions. Electronics, 14(6), 1197. https://doi.org/10.3390/electronics14061197