
Review of Task-Scheduling Methods for Heterogeneous Chips


Abstract
1. Introduction
- The computing power, memory bandwidth, and latency of different processing units of heterogeneous chips are very different. Choosing the most suitable processing unit according to the characteristics of the task to avoid the waste of resources is the key problem in task scheduling [3].
- Computational tasks and dynamic changes in heterogeneous chip states increase the complexity of scheduling methods. The arrival time, execution time, priority, and other factors of tasks will change at any time. In contrast, the system load, resource availability, and other factors are also constantly fluctuating, which requires a high degree of real-time and adaptiveness [2].
- Scheduling methods must find a balance between real-time and complexity, especially in heterogeneous chips that accommodate multiple optimization goals. The delay of the scheduling methods directly affects the efficiency of the heterogeneous chip. In addition, the resource conflict between tasks is also a non-negligible problem. Some tasks need to share processing units or have dependencies with each other to improve the problem’s complexity [4].
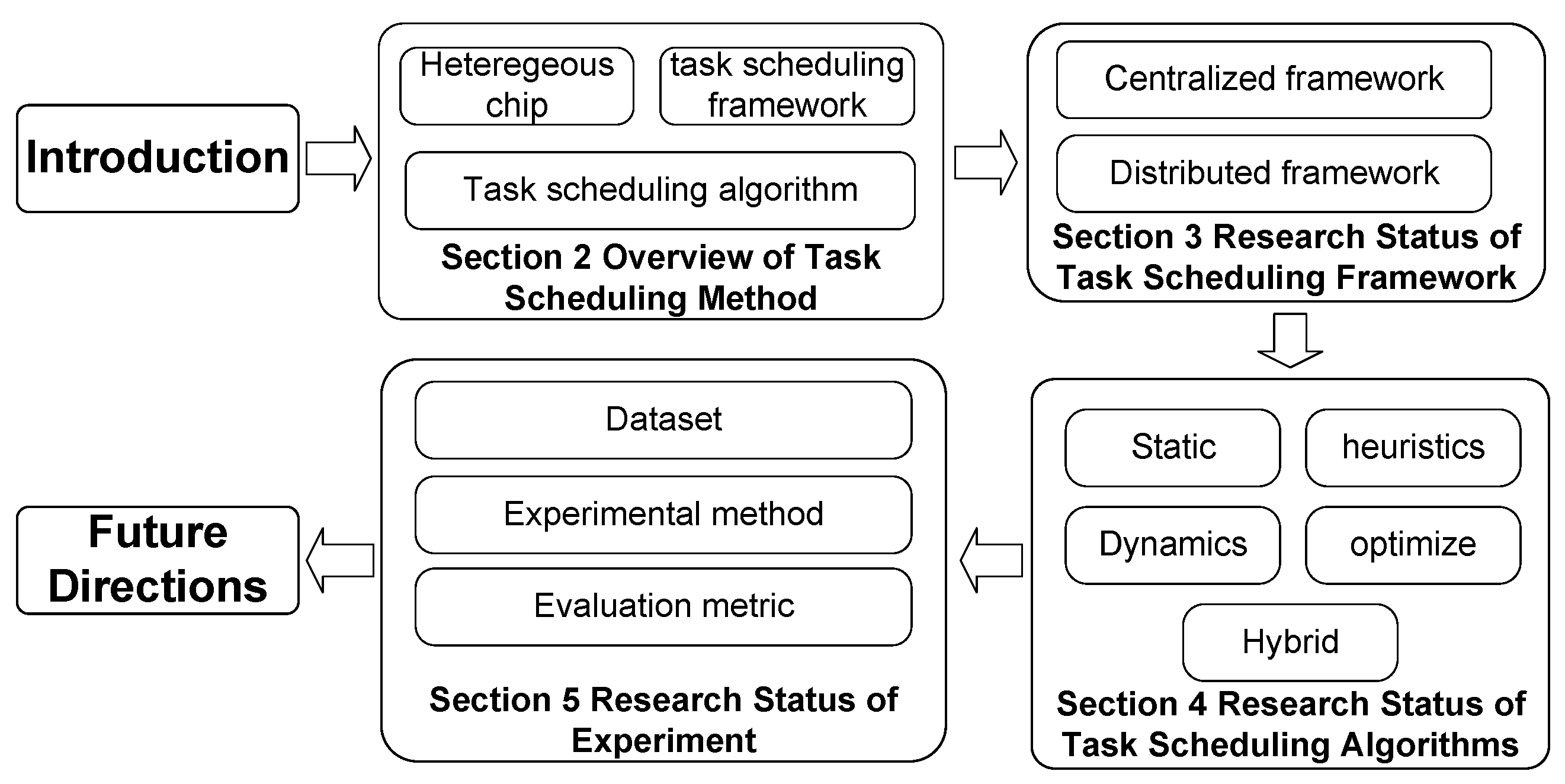
- This paper discusses the challenges of heterogeneous chip task scheduling in-depth, innovatively dividing the scheduling method into two parts: the scheduling framework and the scheduling algorithm, systematically combing the current research status of the heterogeneous chip task-scheduling method. In terms of scheduling framework, this study divides the existing task-scheduling framework into two main types, centralized and distributed, according to the differences in the system architecture and control mode. For the scheduling algorithm, according to the scheduling mechanism, i.e., dynamic, heuristic, mixed, and optimized, five categories are created, and a detailed summary and analysis is provided for each category.
- Based on the in-depth investigation and systematic analysis of recent experiments and evaluation examples, this paper compares the heterogeneous chip task-scheduling method. On the one hand, the experimental evaluation system is based on multiple dimensions, such as load balancing, energy efficiency optimization, and real-time guarantee. On the other hand, a series of experimental methods are introduced, covering different hardware configurations, task load types, and application scenarios, to explore the key points and optimal experimental methods in the experimental simulation process further.
- Based on the research and analysis of heterogeneous chip task-scheduling methods in recent years, this paper provides a comprehensive research prospect for heterogeneous chip task-scheduling methods from an interdisciplinary perspective and combines computer science, artificial intelligence, and system optimization knowledge. This interdisciplinary discussion enriches existing research and provides ideas for future innovation in heterogeneous chip task-scheduling methods.
2. Overview of Task-Scheduling Method
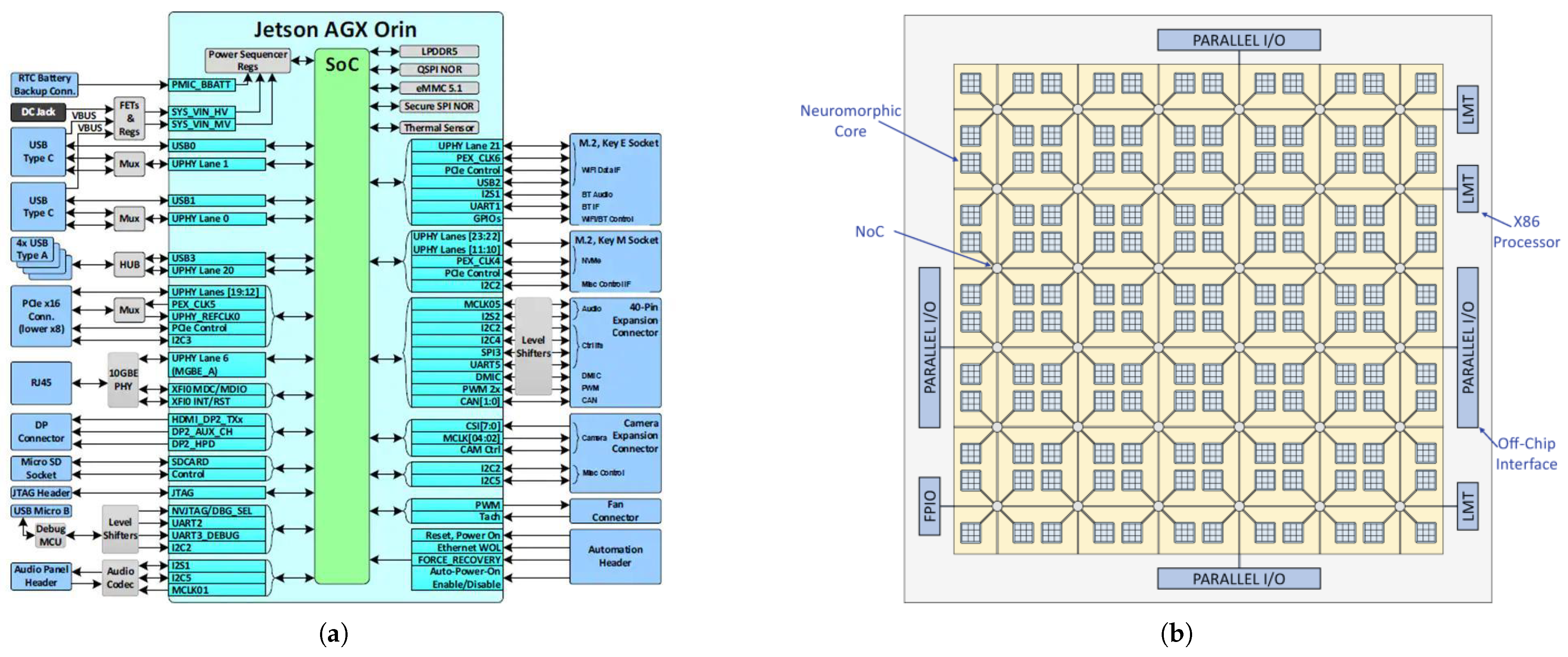
2.1. Heterogeneous Chips
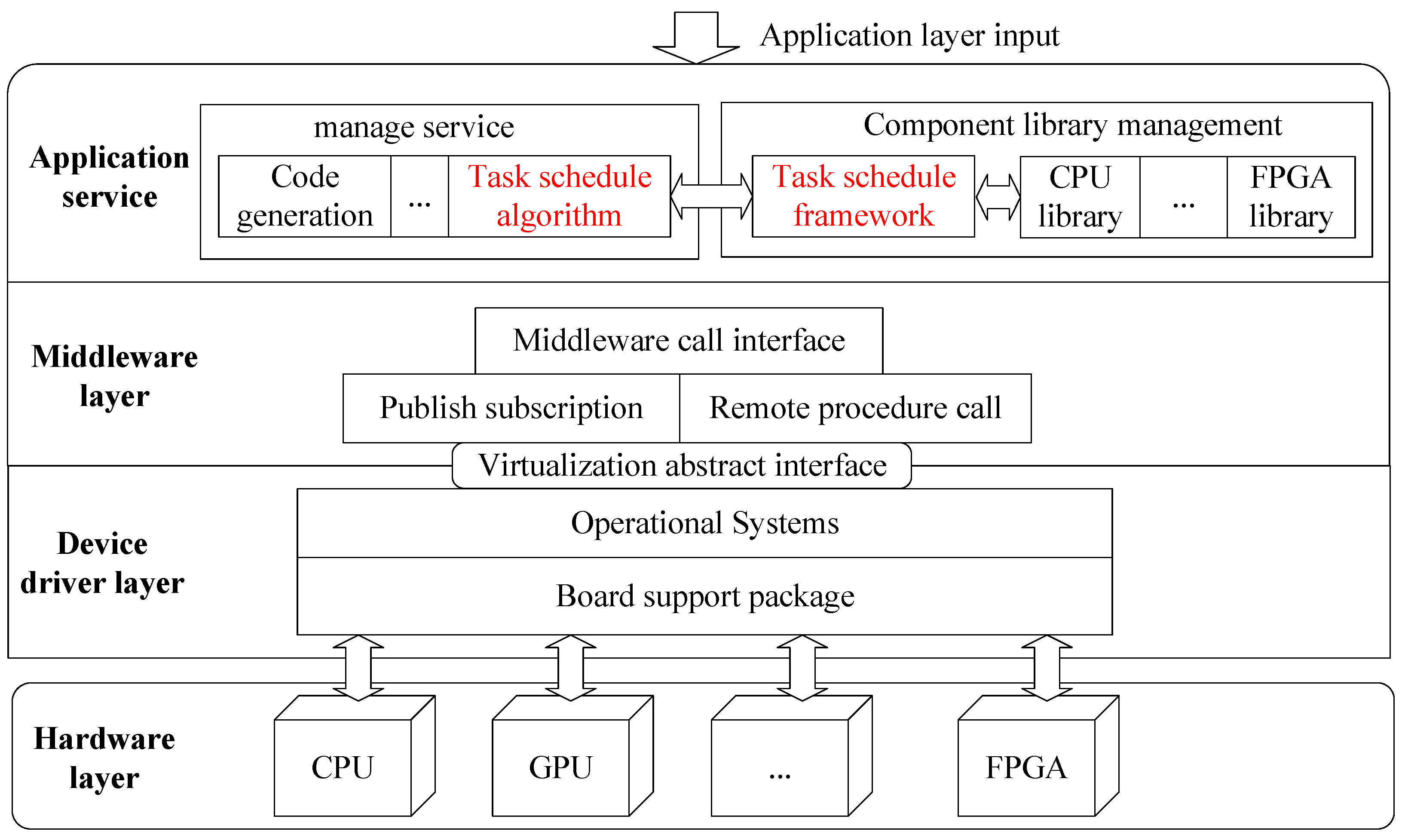
2.2. Task-Scheduling Method
3. Research Status of the Task-Scheduling Framework
3.1. Centralized Scheduling Framework
3.2. Distributed Scheduling Framework
4. Research Status of the Task-Scheduling Algorithm
4.1. Static Scheduling Algorithm
4.2. Dynamic Scheduling Algorithm
4.3. Heuristic Scheduling Algorithm
4.4. Optimized Scheduling Algorithm
4.5. Hybrid Scheduling Algorithm
5. Research Status of Experiment
5.1. Dataset
5.1.1. Real Load Dataset
5.1.2. Synthetic Datasets
5.1.3. Standard Benchmark
5.2. Experimental Methods
5.2.1. Model-in-Loop
5.2.2. Software-in-Loop
5.2.3. Hardware-in-Loop
5.3. Evaluation Metric
- Complexity: Complexity measures the cost of the algorithm in terms of computing resources, time, space, etc. The commonly used evaluation indicators include execution time and maximum completion time (makespan). Execution time is required by the task-scheduling algorithm to generate scheduling for a given application graph [27]. Makespan [53] refers to the total time required to complete a series of tasks or assignments with the formula shown below.where is the actual completion time of the DAG exit task.
- Performance awareness: Performance-aware requirements refer to the scheduling algorithm that needs to take into account the maximization of the overall performance of the system when making decisions. The commonly used evaluation index has an acceleration ratio [54]. The speedup refers to the ratio of the task order execution time to the worst response time. The situation of the acceleration of the current algorithm for a task schedule can be obtained. The formula is shown below.where represents the time overhead of task sequential execution. To prevent contingency, multiple datasets are averaged.
- Optimality: Optimality evaluates whether the scheduling algorithm can determine the optimal or near-optimal solution scheduling task for heterogeneous chips under given constraints. One of the common evaluation indicators is the scheduling length ratio (scheduling length ratio, SLR). SLR refers to the ratio [55] of makespan to the theoretical optimal scheduling length. The formula is defined as follows:where the denominator is the sum of the minimum computational cost of the task belonging to the critical path called .
- Power awareness: The power awareness monitors and manages the immediate energy consumption of the device. It is designed to reduce the peak power demand of the device during operation. [53]. The goal of this metric is to minimize the overall parameters such as energy. [56] or the energy-delay product (EDP). [57]. The EDP provides a compromise measure by considering the energy consumption and execution time. The EDP formula is defined as follows:where represents the total energy consumption of the whole system and is the total execution time of the whole cluster system.
- Energy awareness: The energy awareness focuses on the total energy consumption of heterogeneous chips over a period of time. The goal of this approach is to reduce long-term energy consumption and reduce overall energy costs [56] by improving energy efficiency. In task scheduling, resource allocation or the system design strategy, how to minimize energy consumption while completing the necessary calculation tasks is an important consideration. The commonly used indicators are average power consumption, total energy consumption, and real energy consumption RE(i, j) [29]. The real energy consumption RE(i, j) of a task i on processor j can be defined aswhere is a binary variables and denotes whether task i execute in processing unit j. is used to represent the energy consumption of task i on the processing unit j.
- Online adaptation: Online adaptability evaluates the ability of a heterogeneous chip to dynamically adapt to task changes during operation, especially the response ability during task arrival, system load, or resource status changes [22]. Common indicators include the task migration time, scheduling delay, and throughput [58]. Throughput refers to the number of tasks that the scheduling algorithm performs in a unit of time. Online adaptability of the algorithm can be evaluated by observing the change in throughput with increasing task volume [54].
- Load balancing: Load balancing refers to the reasonable allocation of workload among the processing units of the heterogeneous chip to ensure that no single processing unit becomes a performance bottleneck due to overload while avoiding idle processing units. One of the commonly used evaluation indicators is the relaxation degree, which is called Slack. Slack reflects the size of the time window for absorbing the calculation delay provided by the scheduling results of the algorithm without increasing the makespan [59]. There is a conflict between the Slack measures and the SLR measures, and a lower SLR generally implies lower Slack. The formula of Slack is defined as follows:where n is the number of task nodes, indicating the longest path length from the entry node to the task node. represents the length of the longest path from the task node to the termination node.
6. Discussion
6.1. Challenges and Limitations
6.2. Future Direction
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Citation Report: Heterogeneous Chip and Task Scheduling. 2024. Available online: https://webofscience.clarivate.cn/wos/alldb/citation-report/939b0a4e-656e-4c89-86f8-66de26f7c757-0101ee96ed?page=1 (accessed on 8 October 2024).
- Mack, J.; Arda, S.E.; Ogras, U.Y.; Akoglu, A. Performant, multi-objective scheduling of highly interleaved task graphs on heterogeneous system on chip devices. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 2148–2162. [Google Scholar] [CrossRef]
- Basaklar, T.; Goksoy, A.A.; Krishnakumar, A.; Gumussoy, S.; Ogras, U.Y. DTRL: Decision Tree-based Multi-Objective Reinforcement Learning for Runtime Task Scheduling in Domain-Specific System-on-Chips. ACM Trans. Embed. Comput. Syst. 2023, 22, 113. [Google Scholar] [CrossRef]
- Topcuoglu, H.; Hariri, S.; Wu, M.Y. Performance-effective and low-complexity task scheduling for heterogeneous computing. IEEE Trans. Parallel Distrib. Syst. 2002, 13, 260–274. [Google Scholar] [CrossRef]
- Fang, J.; Huang, C.; Tang, T.; Wang, Z. Parallel programming models for heterogeneous many-cores: A comprehensive survey. CCF Trans. High Perform. Comput. 2020, 2, 382–400. [Google Scholar] [CrossRef]
- Nollet, V.; Marescaux, T.; Avasare, P.; Verkest, D.; Mignolet, J.Y. Centralized run-time resource management in a network-on-chip containing reconfigurable hardware tiles. In Proceedings of the Design, Automation and Test in Europe, Munich, Germany, 7–11 March 2005; pp. 234–239. [Google Scholar]
- Luo, J.; Jha, N.K. Power-efficient scheduling for heterogeneous distributed real-time embedded systems. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2007, 26, 1161–1170. [Google Scholar] [CrossRef]
- Braun, T.D.; Siegel, H.J.; Beck, N.; Bölöni, L.L.; Maheswaran, M.; Reuther, A.I.; Robertson, J.P.; Theys, M.D.; Yao, B.; Hensgen, D.; et al. A comparison of eleven static heuristics for mapping a class of independent tasks onto heterogeneous distributed computing systems. J. Parallel Distrib. Comput. 2001, 61, 810–837. [Google Scholar] [CrossRef]
- Karande, P.; Dhotre, S.; Patil, S. Task management for heterogeneous multi-core scheduling. Int. J. Comput. Sci. Inf. Technol. 2014, 5, 636–639. [Google Scholar]
- Bao, Z.; Chen, C.; Zhang, W. Task Scheduling of Data-Parallel Applications on HSA Platform; Springer: Berlin/Heidelberg, Germany, 2018; pp. 452–461. [Google Scholar]
- Phanibhushana, B.; Kundu, S. Network-on-chip design for heterogeneous multiprocessor system-on-chip. In Proceedings of the 2014 IEEE Computer Society Annual Symposium on VLSI, Tampa, FL, USA, 9–11 July 2014; pp. 486–491. [Google Scholar]
- Liu, C.L.; Layland, J.W. Scheduling algorithms for multiprogramming in a hard-real-time environment. J. ACM (JACM) 1973, 20, 46–61. [Google Scholar] [CrossRef]
- Baruah, S. Feasibility analysis of preemptive real-time systems upon heterogeneous multiprocessor platforms. In Proceedings of the 25th IEEE International Real-Time Systems Symposium, Lisbon, Portugal, 5–8 December 2004; pp. 37–46. [Google Scholar]
- Orr, J.; Baruah, S. Algorithms for implementing elastic tasks on multiprocessor platforms: A comparative evaluation. Real-Time Syst. 2021, 57, 227–264. [Google Scholar] [CrossRef]
- Peng, B.; Fisher, N. Parameter adaption for generalized multiframe tasks and applications to self-suspending tasks. In Proceedings of the 2016 IEEE 22nd International Conference on Embedded and Real-Time Computing Systems and Applications (RTCSA), Daegu, Republic of Korea, 17–19 August 2016; pp. 49–58. [Google Scholar]
- Han, M.; Guan, N.; Sun, J.; He, Q.; Deng, Q.; Liu, W. Response time bounds for typed DAG parallel tasks on heterogeneous multi-cores. IEEE Trans. Parallel Distrib. Syst. 2019, 30, 2567–2581. [Google Scholar] [CrossRef]
- Karumbunathan, L.S. NVIDIA Jetson AGX Orin Series. 2022. Available online: https://www.nvidia.cn/content/dam/en-zz/Solutions/gtcf21/jetson-orin/nvidia-jetson-agx-orin-technical-brief.pdf (accessed on 12 October 2024).
- Davies, M.; Srinivasa, N.; Lin, T.H.; Chinya, G.; Cao, Y.; Choday, S.H.; Dimou, G.; Joshi, P.; Imam, N.; Jain, S.; et al. Loihi: A neuromorphic manycore processor with on-chip learning. IEEE Micro 2018, 38, 82–99. [Google Scholar] [CrossRef]
- Maheswaran, M.; Ali, S.; Siegel, H.J.; Hensgen, D.; Freund, R.F. Dynamic mapping of a class of independent tasks onto heterogeneous computing systems. J. Parallel Distrib. Comput. 1999, 59, 107–131. [Google Scholar] [CrossRef]
- Bittencourt, L.F.; Sakellariou, R.; Madeira, E.R. Dag scheduling using a lookahead variant of the heterogeneous earliest finish time algorithm. In Proceedings of the 2010 18th Euromicro Conference on Parallel, Distributed and Network-Based Processing, Pisa, Italy, 17–19 February 2010; pp. 27–34. [Google Scholar]
- Li, Q.-Y.; Kang, J.-J.; Guo, W.-F. Research and Simulation of embedded burst task scheduling method. Comput. Simul. 2022, 39, 423–426, 435. [Google Scholar] [CrossRef]
- Chen, Y.S.; Liao, H.C.; Tsai, T.H. Online real-time task scheduling in heterogeneous multicore system-on-a-chip. IEEE Trans. Parallel Distrib. Syst. 2012, 24, 118–130. [Google Scholar] [CrossRef]
- Mandal, S.K.; Bhat, G.; Patil, C.A.; Doppa, J.R.; Pande, P.P.; Ogras, U.Y. Dynamic resource management of heterogeneous mobile platforms via imitation learning. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 2842–2854. [Google Scholar] [CrossRef]
- Reuven, M.; Wiseman, Y. Medium-term scheduler as a solution for the thrashing effect. Comput. J. 2006, 49, 297–309. [Google Scholar] [CrossRef]
- Gholami, H.; Zakerian, R. A list-based heuristic algorithm for static task scheduling in heterogeneous distributed computing systems. In Proceedings of the 2020 6th international conference on web research (ICWR), Tehran, Iran, 22–23 April 2020; pp. 21–26. [Google Scholar]
- Sakellariou, R.; Zhao, H. A hybrid heuristic for DAG scheduling on heterogeneous systems. In Proceedings of the 18th International Parallel and Distributed Processing Symposium, 2004. Proceedings, Santa Fe, NM, USA, 26–30 April 2004; p. 111. [Google Scholar]
- Sulaiman, M.; Halim, Z.; Lebbah, M.; Waqas, M.; Tu, S. An evolutionary computing-based efficient hybrid task scheduling approach for heterogeneous computing environment. J. Grid Comput. 2021, 19, 1–31. [Google Scholar] [CrossRef]
- Sung, T.T.; Ha, J.; Kim, J.; Yahja, A.; Sohn, C.B.; Ryu, B. Deepsocs: A neural scheduler for heterogeneous system-on-chip (soc) resource scheduling. Electronics 2020, 9, 936. [Google Scholar] [CrossRef]
- Wang, Y.; Li, K.; Chen, H.; He, L.; Li, K. Energy-aware data allocation and task scheduling on heterogeneous multiprocessor systems with time constraints. IEEE Trans. Emerg. Top. Comput. 2014, 2, 134–148. [Google Scholar] [CrossRef]
- Diwan, P.; Toraskar, S.; Venkitaraman, V.; Boran, N.K.; Chaudhary, C.; Singh, V. MIST: Many-ISA Scheduling Technique for Heterogeneous-ISA Architectures. In Proceedings of the 2024 37th International Conference on VLSI Design and 2024 23rd International Conference on Embedded Systems (VLSID), Bengal, India, 6–10 January 2024; pp. 348–353. [Google Scholar]
- Nikseresht, M.; Raji, M. MOGATS: A multi-objective genetic algorithm-based task scheduling for heterogeneous embedded systems. Int. J. Embed. Syst. 2021, 14, 171–184. [Google Scholar] [CrossRef]
- Suhendra, V.; Raghavan, C.; Mitra, T. Integrated scratchpad memory optimization and task scheduling for MPSoC architectures. In Proceedings of the 2006 International Conference on Compilers, Architecture and Synthesis for Embedded Systems, Seoul, Republic of Korea, 22–25 October 2006; pp. 401–410. [Google Scholar]
- Hu, W.; Gan, Y.; Lv, X.; Wang, Y.; Wen, Y. A improved list heuristic scheduling algorithm for heterogeneous computing systems. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 1111–1116. [Google Scholar]
- Peng, Q.; Wang, S. Masa: Multi-application scheduling algorithm for heterogeneous resource platform. Electronics 2023, 12, 4056. [Google Scholar] [CrossRef]
- Taheri, G.; Khonsari, A.; Entezari-Maleki, R.; Sousa, L. A hybrid algorithm for task scheduling on heterogeneous multiprocessor embedded systems. Appl. Soft Comput. 2020, 91, 106202. [Google Scholar] [CrossRef]
- Abdi, A.; Salimi-Badr, A. ENF-S: An evolutionary-neuro-fuzzy multi-objective task scheduler for heterogeneous multi-core processors. IEEE Trans. Sustain. Comput. 2023, 8, 479–491. [Google Scholar] [CrossRef]
- Arda, S.E.; Krishnakumar, A.; Goksoy, A.A.; Kumbhare, N.; Mack, J.; Sartor, A.L.; Akoglu, A.; Marculescu, R.; Ogras, U.Y. DS3: A system-level domain-specific system-on-chip simulation framework. IEEE Trans. Comput. 2020, 69, 1248–1262. [Google Scholar] [CrossRef]
- Cordeiro, D.; Mounié, G.; Perarnau, S.; Trystram, D.; Vincent, J.M.; Wagner, F. Random graph generation for scheduling simulations. In Proceedings of the 3rd International ICST Conference on Simulation Tools and Techniques (SIMUTools 2010). ICST, Malaga, Spain, 15–19 March 2010; p. 10. [Google Scholar]
- Yao, Y.; Song, Y.; Huang, Y.; Ni, W.; Zhang, D. A memory-constraint-aware list scheduling algorithm for memory-constraint heterogeneous muti-processor system. IEEE Trans. Parallel Distrib. Syst. 2022, 34, 1082–1099. [Google Scholar] [CrossRef]
- Suter, F.; Hunold, S. Daggen: A Synthetic Task Graph Generator. 2013. Available online: https://github.com/frs69wq/daggen (accessed on 10 October 2024).
- Catania, V.; Mineo, A.; Monteleone, S.; Palesi, M.; Patti, D. Noxim: An open, extensible and cycle-accurate network on chip simulator. In Proceedings of the 2015 IEEE 26th International Conference on Application-Specific systems, Architectures and Processors (ASAP), Toronto, ON, Canada, 27–29 July 2015; pp. 162–163. [Google Scholar]
- Bienia, C.; Kumar, S.; Singh, J.P.; Li, K. The PARSEC benchmark suite: Characterization and architectural implications. In Proceedings of the 17th International Conference on Parallel Architectures and Compilation Techniques, Toronto, ON, Canada, 25–29 October 2008; pp. 72–81. [Google Scholar]
- Che, S.; Boyer, M.; Meng, J.; Tarjan, D.; Sheaffer, J.W.; Lee, S.H.; Skadron, K. Rodinia: A benchmark suite for heterogeneous computing. In Proceedings of the 2009 IEEE International Symposium on Workload Characterization (IISWC), Austin, TX, USA, 4–6 October 2009; pp. 44–54. [Google Scholar]
- Dongarra, J.J.; Takahashi, D.; Bailey, D.; Koester, D.; Luszczek, P.; Rabenseifner, R.; Lucas, B.; McCalpin, J. Introduction to the HPC Challenge Benchmark Suite. 2005. Available online: https://escholarship.org/content/qt6sv079jp/qt6sv079jp.pdf (accessed on 10 October 2024).
- Krishnamoorthy, R.; Krishnan, K.; Chokkalingam, B.; Padmanaban, S.; Leonowicz, Z.; Holm-Nielsen, J.B.; Mitolo, M. Systematic approach for state-of-the-art architectures and system-on-chip selection for heterogeneous IoT applications. IEEE Access 2021, 9, 25594–25622. [Google Scholar] [CrossRef]
- Ubal, R.; Jang, B.; Mistry, P.; Schaa, D.; Kaeli, D. Multi2Sim: A simulation framework for CPU-GPU computing. In Proceedings of the 21st International Conference on Parallel Architectures and Compilation Techniques, Minneapolis, MN, USA, 19–23 September 2012; pp. 335–344. [Google Scholar]
- Lowe-Power, J.; Ahmad, A.M.; Akram, A.; Alian, M.; Amslinger, R.; Andreozzi, M.; Armejach, A.; Asmussen, N.; Beckmann, B.; Bharadwaj, S. The gem5 simulator: Version 20.0+. arXiv 2020, arXiv:2007.03152. [Google Scholar]
- Magnusson, P.S.; Christensson, M.; Eskilson, J.; Forsgren, D.; Hallberg, G.; Hogberg, J.; Larsson, F.; Moestedt, A.; Werner, B. Simics: A full system simulation platform. Computer 2002, 35, 50–58. [Google Scholar] [CrossRef]
- Data, B.M. Texas Instruments Incorporated. 2002. Available online: https://www.sprow.co.uk/bbc/hardware/speech/tms6100.pdf (accessed on 10 October 2024).
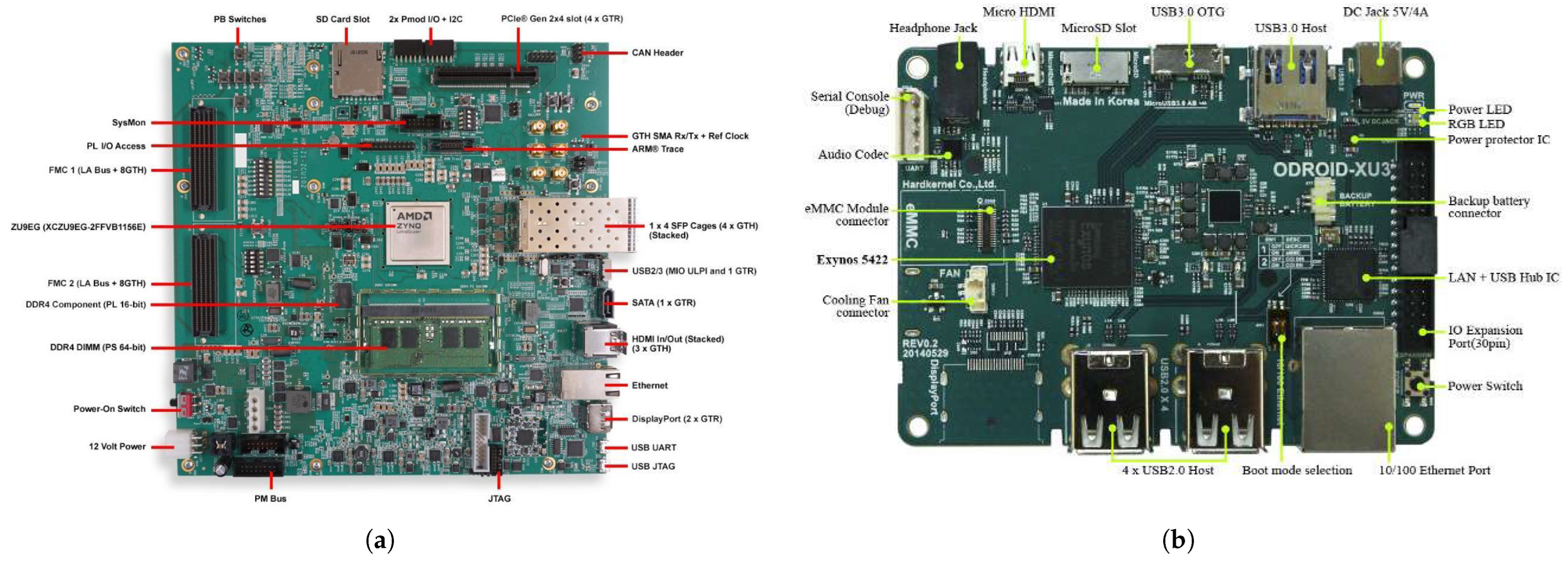
- Gensh, R.; Aalsaud, A.; Rafiev, A.; Xia, F.; Iliasov, A.; Romanovsky, A.; Yakovlev, A. Experiments with Odroid-XU3 board. In School of Computing Science Technical Report Series; Newcastle University: Newcastle upon Tyne, UK, 2015. [Google Scholar]
- Goksoy, A.A.; Hassan, S.; Krishnakumar, A.; Marculescu, R.; Akoglu, A.; Ogras, U.Y. Theoretical validation and hardware implementation of dynamic adaptive scheduling for heterogeneous systems on chip. J. Low Power Electron. Appl. 2023, 13, 56. [Google Scholar] [CrossRef]
- Soni, R.S.; Asati, D. Development of Embedded Web Server Configured on FPGA Using Soft-core Processor and Web Client on PC. Int. J. Eng. Adv. Technol. (IJEAT) 2012, 1, 295–298. [Google Scholar]
- Bunde, D.P. Power-aware scheduling for makespan and flow. In Proceedings of the Eighteenth Annual ACM Symposium on Parallelism in Algorithms and Architectures, Cambridge, MA, USA, 30 July–2 August 2006; pp. 190–196. [Google Scholar]
- Chen, J.; Soomro, P.N.; Abduljabbar, M.; Pericàs, M. An Adaptive Performance-oriented Scheduler for Static and Dynamic Heterogeneity. arXiv 2019, arXiv:1905.00673. [Google Scholar]
- Baskiyar, S.; SaiRanga, P.C. Scheduling directed a-cyclic task graphs on heterogeneous network of workstations to minimize schedule length. In Proceedings of the 2003 International Conference on Parallel Processing Workshops, 2003. Proceedings, Kaohsiung, Taiwan, 6–9 October 2003; pp. 97–103. [Google Scholar]
- Huang, J.; Buckl, C.; Raabe, A.; Knoll, A. Energy-aware task allocation for network-on-chip based heterogeneous multiprocessor systems. In Proceedings of the 2011 19th International Euromicro Conference on Parallel, Distributed and Network-Based Processing, Ayia Napa, Cyprus, 9–11 February 2011; pp. 447–454. [Google Scholar]
- Hamano, T.; Endo, T.; Matsuoka, S. Power-aware dynamic task scheduling for heterogeneous accelerated clusters. In Proceedings of the 2009 IEEE International Symposium on Parallel & Distributed Processing, Rome, Italy, 23–29 May 2009; pp. 1–8. [Google Scholar]
- Amalarethinam, D.G.; Josphin, A.M. Dynamic task scheduling methods in heterogeneous systems: A survey. Int. J. Comput. Appl. 2015, 110, 12–18. [Google Scholar]
- Shi, Z.; Jeannot, E.; Dongarra, J.J. Robust task scheduling in non-deterministic heterogeneous computing systems. In Proceedings of the 2006 IEEE International Conference on Cluster Computing, Barcelona, Spain, 25–28 September 2006; pp. 1–10. [Google Scholar]
- Bonnet, S.; Teuteberg, F. Impact of blockchain and distributed ledger technology for the management of the intellectual property life cycle: A multiple case study analysis. Comput. Ind. 2023, 144, 103789. [Google Scholar] [CrossRef]
- Leus, G.; Marques, A.G.; Moura, J.M.; Ortega, A.; Shuman, D.I. Graph Signal Processing: History, development, impact, and outlook. IEEE Signal Process. Mag. 2023, 40, 49–60. [Google Scholar] [CrossRef]
- Chen, J.; Wang, W.; Yu, K.; Hu, X.; Cai, M.; Guizani, M. Node connection strength matrix-based graph convolution network for traffic flow prediction. IEEE Trans. Veh. Technol. 2023, 72, 12063–12074. [Google Scholar] [CrossRef]
- Cheng, Y.; Cao, Z.; Zhang, X.; Cao, Q.; Zhang, D.J.T. Multi objective dynamic task scheduling optimization algorithm based on deep reinforcement learning. J. Supercomput. 2024, 80, 6917–6945. [Google Scholar] [CrossRef]
- Yin, S.; Fu, C.; Zhao, S.; Li, K.; Sun, X.; Xu, T.; Chen, E. A survey on multimodal large language models. arXiv 2023, arXiv:2306.13549. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Centralized Scheduling Framework | Distributed Scheduling Framework |
|---|---|---|
| System Model | Central scheduler manages all resources and task assignments. | Decentralized nodes with autonomous schedulers. |
| Task Model | Suited for tasks with simple dependencies. | Handles complex dependencies through localized decision-making. |
| Scalability | Limited as the central scheduler may become a performance bottleneck. | Enhanced through distributed management of tasks and resources across multiple nodes. |
| Fault Tolerance | Lower fault tolerance due to reliance on a single scheduler. | Higher fault tolerance through redundancy and distribution of scheduling responsibilities. |
| Complexity | Lower complexity arising from centralized task and resource management. | Lower complexity due to decentralized task and resource management. |
| Adaptability | Limited adaptability to dynamic changes in task requirements. | High adaptability with local decision-making capabilities responsive to changes in local environments. |
| Advantages | Optimal resource allocation guarantees and deterministic execution timelines. | Elastic horizontal scaling and intrinsic geographical redundancy. |
| Disadvantages | Scalability bottleneck and single-point-of-failure vulnerability | Potential consistency issues and latency sensitivity in wide-area deployments. |
| Algorithm | Description | Limitation |
|---|---|---|
| Static | Determines the scheduling plan takes place before task execution begins. | Limited adaptability to runtime dynamics. |
| Dynamic | Adapts to dynamic changes in tasks and system resources. | Incurs significant computational and communication overheads from frequent re-evaluations. |
| Heuristic | Uses empirical rules or heuristic rules to quickly generate acceptable scheduling plans without guaranteeing a globally optimal solution. | Computational intractability for large-scale problems due to NP-hard complexity. |
| Optimization | Relies on mathematical models and optimization algorithms to minimize or maximize a specific objective function to obtain an optimal solution. | Solution quality varies unpredictably and may converge to local optima. |
| Hybrid | Combines multiple scheduling algorithms to leverage the strengths of different algorithms. | Increases design complexity and sensitivity to parameter tuning. |
| Dataset Type | Data Characteristics | Scenario Complexity | Limitation |
|---|---|---|---|
| Real Load | Dynamic heterogeneity with real-world task features | Highest complexity (adaptation to dynamic environments) | High acquisition cost and privacy sensitivity |
| Synthetic Dataset | Adjustable parameters and controllable distributions | Moderate complexity (customizable scenarios) | Potential deviation from real-world conditions |
| Standard Benchmark | Standardized structures for reproducibility | Low complexity (controlled and fixed scenarios) | Over-idealization and limited diversity coverage |
| Application | Max Width | Depth | Numbers of Nodes | Supported Accelerators |
|---|---|---|---|---|
| WiFi TX | 5 | 7 | 27 | IFFT |
| WiFi RX | 5 | 10 | 34 | FF, Viterbi Decoder |
| Radar Correlator | 2 | 6 | 7 | FFT, IFFT |
| Temporal Mitigation | 2 | 6 | 10 | Matrix Multiply |
| Single Carrier TX | 1 | 8 | 8 | |
| Single Carrier RX | 1 | 8 | 8 | Viterbi Decoder |
| Metric | Model-in-Loop | Software-in-Loop | Hardware-in-Loop |
|---|---|---|---|
| Experimental object | Task model | Software | Heterogeneous chip |
| Precision | Low | Medium | High |
| Number of test cases | High | Relatively High | Low |
| Complexity | Simple | General | Complex |
| Scenario | Simple | General | Complex |
| Cost | Low | Low | High |
| Limitation | Requires specialized equipment; high implementation complexity and cost. | Limited hardware interaction fidelity; potential timing inaccuracies. | Dependent on model accuracy; may overlook hardware-specific constraints. |
| Evaluation Metric | Content |
|---|---|
| Optimality | Finding the best or near-best task-scheduling method according to a certain optimization objective (such as minimizing completion time, maximizing resource utilization, minimizing energy consumption, etc.). |
| Complexity | Measuring the complexity of the scheduling method and the additional overhead introduced during its execution. |
| Online adaptability | The ability to dynamically adapt to the constantly changing environment and system status during runtime. |
| Load Balancing | Balancing the workload between various processing units. |
| Performance awareness | Considering the maximization of the overall performance of the heterogeneous chip. |
| Power awareness | Optimizing the power consumption of the heterogeneous chip at a certain moment. |
| Energy awareness | Optimizing the total energy consumption of the heterogeneous chip over a period of time. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miao, Z.; Shao, C.; Li, H.; Tang, Z. Review of Task-Scheduling Methods for Heterogeneous Chips. Electronics 2025, 14, 1191. https://doi.org/10.3390/electronics14061191
Miao Z, Shao C, Li H, Tang Z. Review of Task-Scheduling Methods for Heterogeneous Chips. Electronics. 2025; 14(6):1191. https://doi.org/10.3390/electronics14061191
Chicago/Turabian StyleMiao, Zujia, Cuiping Shao, Huiyun Li, and Zhimin Tang. 2025. "Review of Task-Scheduling Methods for Heterogeneous Chips" Electronics 14, no. 6: 1191. https://doi.org/10.3390/electronics14061191
APA StyleMiao, Z., Shao, C., Li, H., & Tang, Z. (2025). Review of Task-Scheduling Methods for Heterogeneous Chips. Electronics, 14(6), 1191. https://doi.org/10.3390/electronics14061191