
An Efficient Convolutional Neural Network Accelerator Design on FPGA Using the Layer-to-Layer Unified Input Winograd Architecture


Abstract
1. Introduction
2. State of the Art in CNN Acceleration Algorithms
- To address the issues associated with existing direct kernel decomposition methods and varying convolution parameters, we introduce a reconfigurable Winograd method featuring layer-to-layer unified input-blocking. This method mitigates performance limitations arising from decomposing kernels of different sizes and strides, thereby expanding the applicability of the Winograd algorithm. Furthermore, to improve the multiplication saving ratio, we propose a method for decomposing, transforming, and computing large convolution kernels with non-fixed strides. We also design hardware circuits for unified input transformations, reducing the computational complexity of the transformation units;
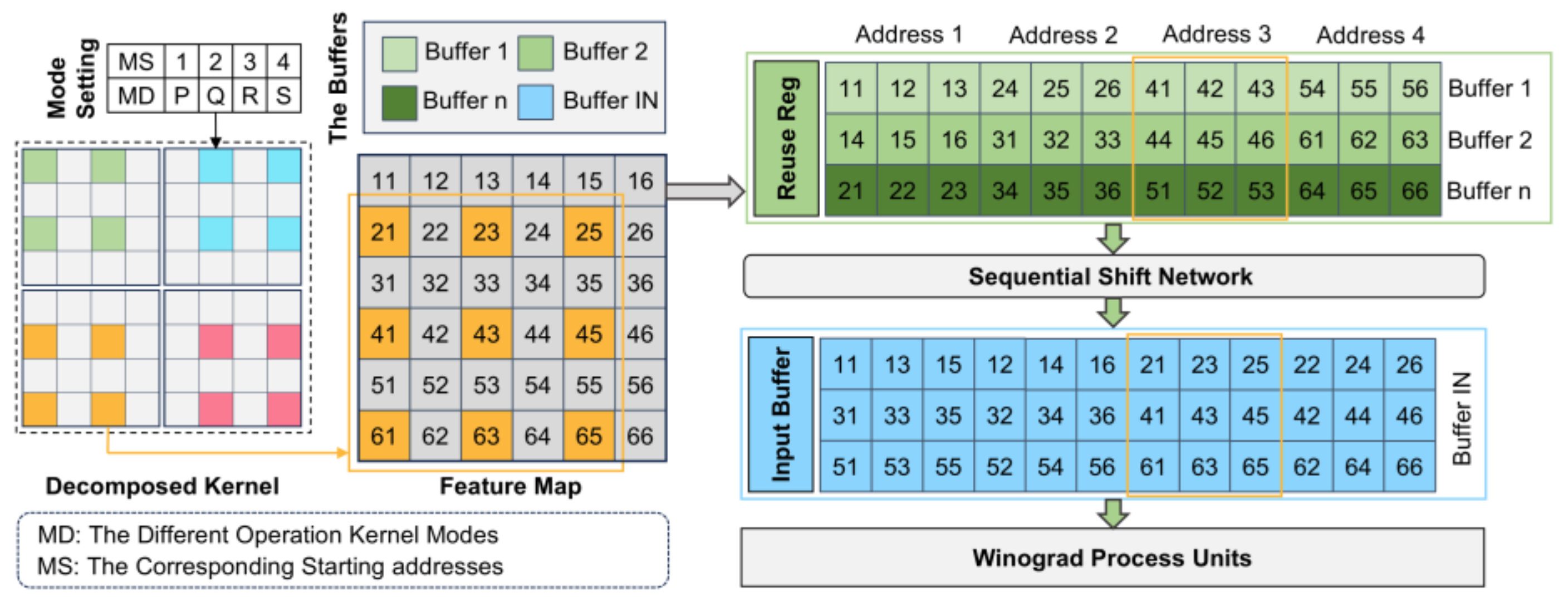
- To balance overall accelerator performance and power consumption, we present a design methodology for a reconfigurable Winograd processing system that effectively manages computational resources and power consumption. Additionally, by incorporating a preprocessing shift network and an address translation table, we achieve efficient data reuse between the accelerator system and storage blocks. This enhancement improves data access flexibility and efficiency while reducing system-induced latency;
- Implemented on the Xilinx XC7Z045 platform (AMD Xilinx, San Jose, CA, United States.), our design achieves an average throughput of 683.26 GOPS and a power efficiency of 74.51 GOPS/W.
3. Background
3.1. Winograd Algorithm
3.2. Computation Dataflow in CNN Training
- Forward Propagation (FP): In the forward propagation stage of a neural network, the input is typically passed from one neuron to the next. The output of a layer is determined based on its input and the corresponding activation of the current layer (). For example, in the CONV layer, as shown in Figure 2, the output value is computed using the formula in Equation (9), where the current layer’s weight activations () are convolved with the activations from the previous layer ().
- Backward Propagation (BP): In the backward propagation stage of a neural network, the computation process mirrors that of forward propagation. The key difference is that, during backward propagation, the kernel of the convolutional layer must be rotated by 180°. Additionally, the dimensions between the input and output channels are transformed. For the convolutional layer in the backward propagation stage, the output value is obtained by convolving the activations of the current layer () with the errors from the same layer (), as shown in Equation (10).
- Weight Gradient (WG): The weight gradient is the derivative of the loss with respect to the weights. For the CONV layer, the weight gradient () is obtained by convolving the activations from the previous layer () with the errors from the current layer (), as shown in Equation (11).
3.3. The Layer-to-Layer Input-Uniform Decomposable Winograd Method
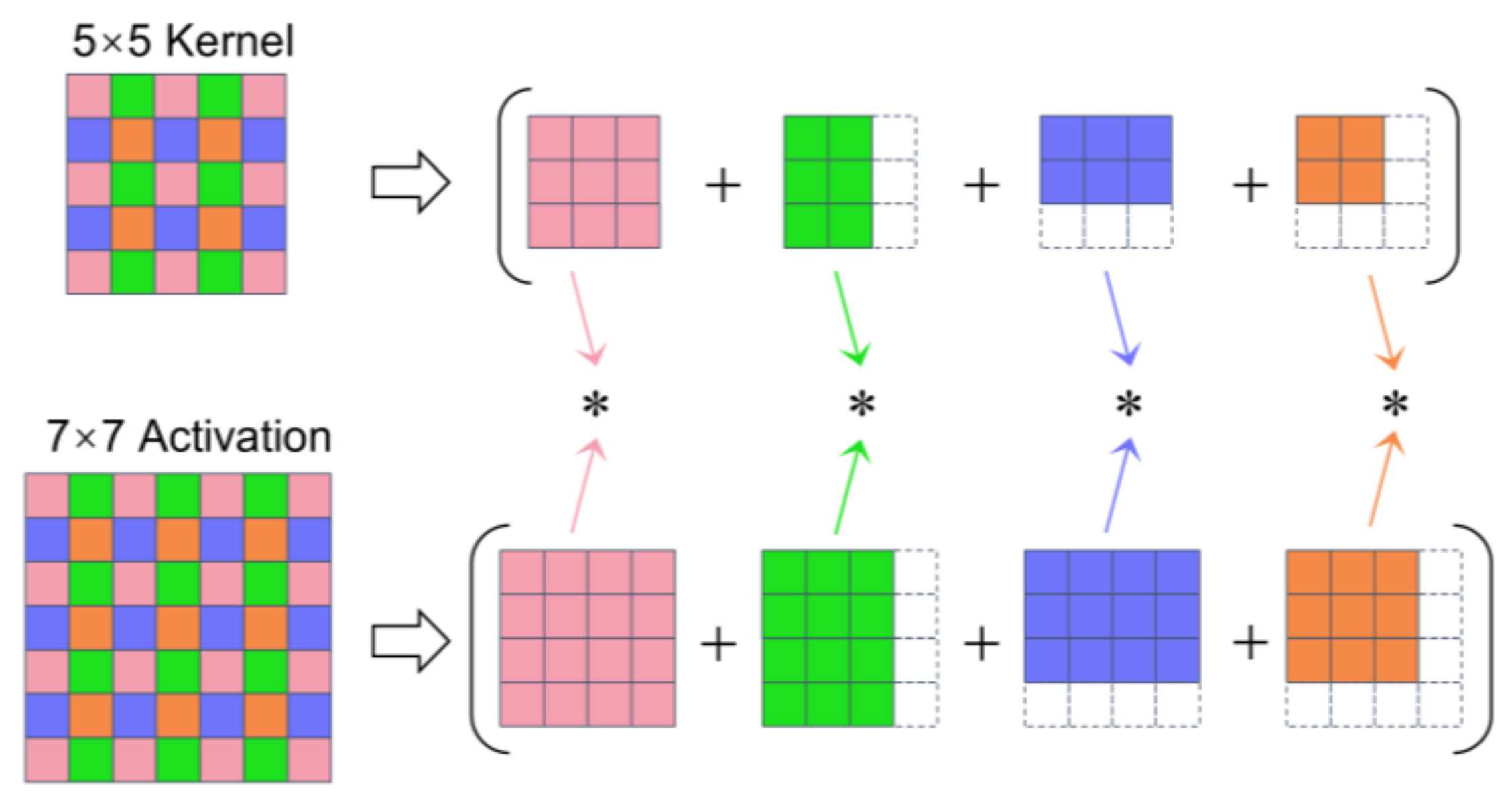
- Splitting: Large kernels are decomposed into smaller kernel tiles, each with a fixed stride of 1 and a size no greater than 3 × 3. Corresponding input tiles are also prepared. The kernel decomposition follows the stride-based convolution decomposition method proposed in [22], without requiring uniform padding of the kernels. Figure 3 illustrates the process of decomposing a 5 × 5 kernel with a stride of 2 into four smaller convolutions with a stride of 1, where the symbol “*” denotes the corresponding convolution operations;
- Transformation: The Winograd transformation matrix is applied to input tiles to obtain uniform 6 × 6 transformed matrices. This enhancement to uniform transformation focuses on increasing the input block size, thereby improving the multiplication saving ratio. The use of a 6 × 6 uniform input block, compared to smaller blocks, leads to better computational complexity and overall efficiency;
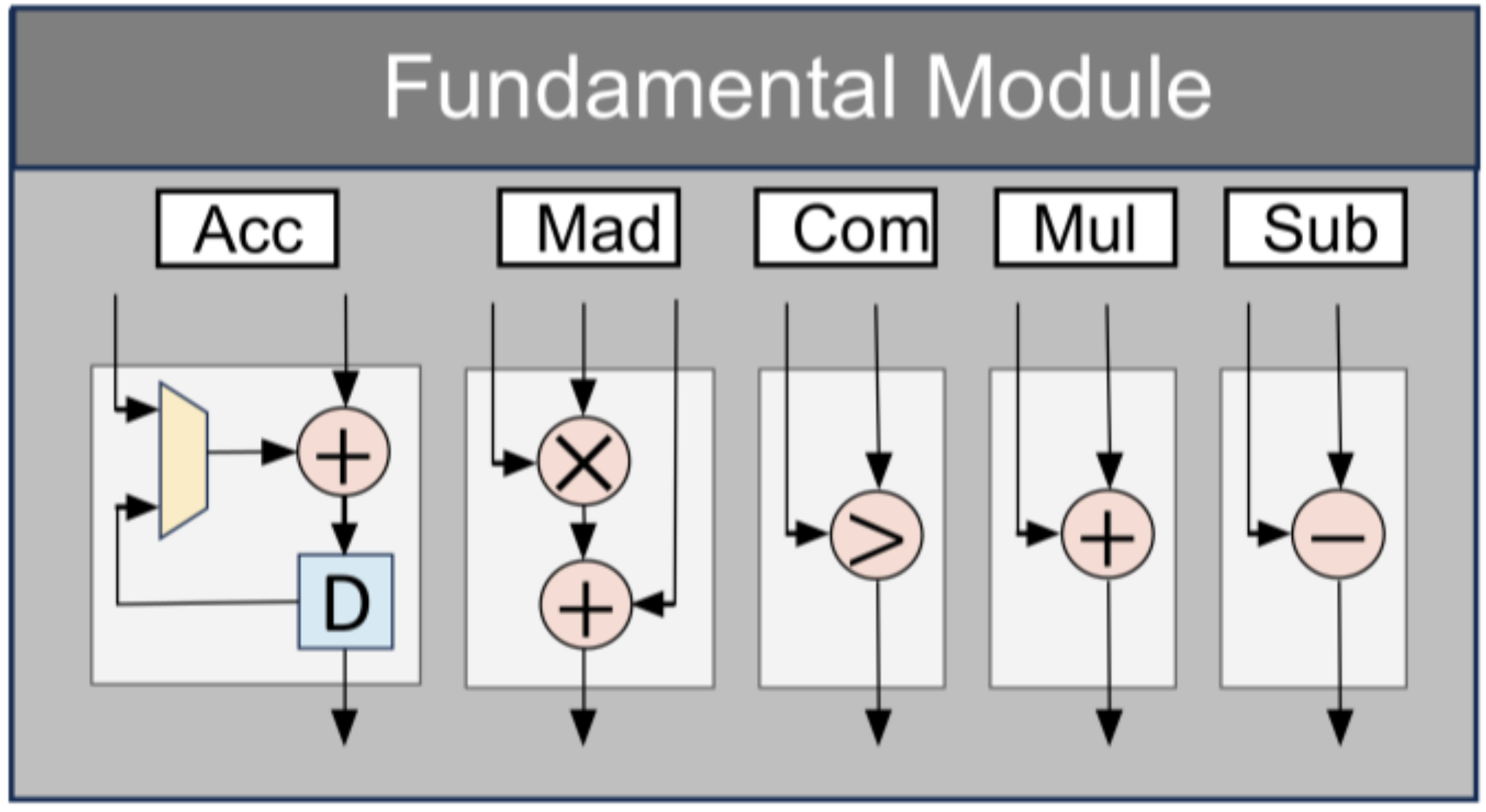
- Calculation: Do Element-wise multiplication and channel-wise summation, with these operations specifically implemented in the Winograd computation module and the Multiply-Accumulate (MAC) units designed in this paper;
- Inverse Transformation: The inverse transformation of the corresponding matrices is performed using the traditional Winograd algorithm, converting the intermediate results back to the spatial domain;
- Aggregation: The computed results from each part are summed, and the output tiles are rearranged to obtain the final result, which corresponds to the original convolution.
- Decomposing convolution kernels larger than 3 × 3 or with a stride different from 1 into smaller unit convolutions;
- Performing the Winograd computation on the decomposed unit convolutions, as described in Equation (12). Specifically, when the convolution kernel size is 1 × 1, F (6 × 6, 6 × 6, 1 × 1) can be considered a special case, where the operation effectively reduces to element-wise matrix multiplication.
4. Architecture Design of Reconfigurable Accelerator
4.1. Overall Architecture
- These architectures differ in the data processing dimensions within the MAC unit, resulting in distinct convolution parallel execution schemes. The GEMM architecture uses a one-dimensional sequential design for its PE array, whereas the Winograd architecture typically employs a two-dimensional design. The hybrid Winograd architecture combines both dimensions, allowing for dynamic selection of CONV loop unrolling modes based on the kernel size. The reconfigurable Winograd architecture generally adopts a two-dimensional systolic array design. The differing array dimensions affect the execution order, partitioning, slicing, and unrolling operations during the CONV process;
- Compared to the GEMM, classic Winograd, and hybrid Winograd architectures, the reconfigurable Winograd architecture offers the greatest advantage through its ability to optimize across layers. This feature enhances hardware resource utilization via cross-layer pipelining reorganization and dynamic memory partitioning. Such software–hardware co-optimization is especially well suited for applications in edge heterogeneous computing environments. Consequently, we have chosen the reconfigurable Winograd architecture for our overall design framework.
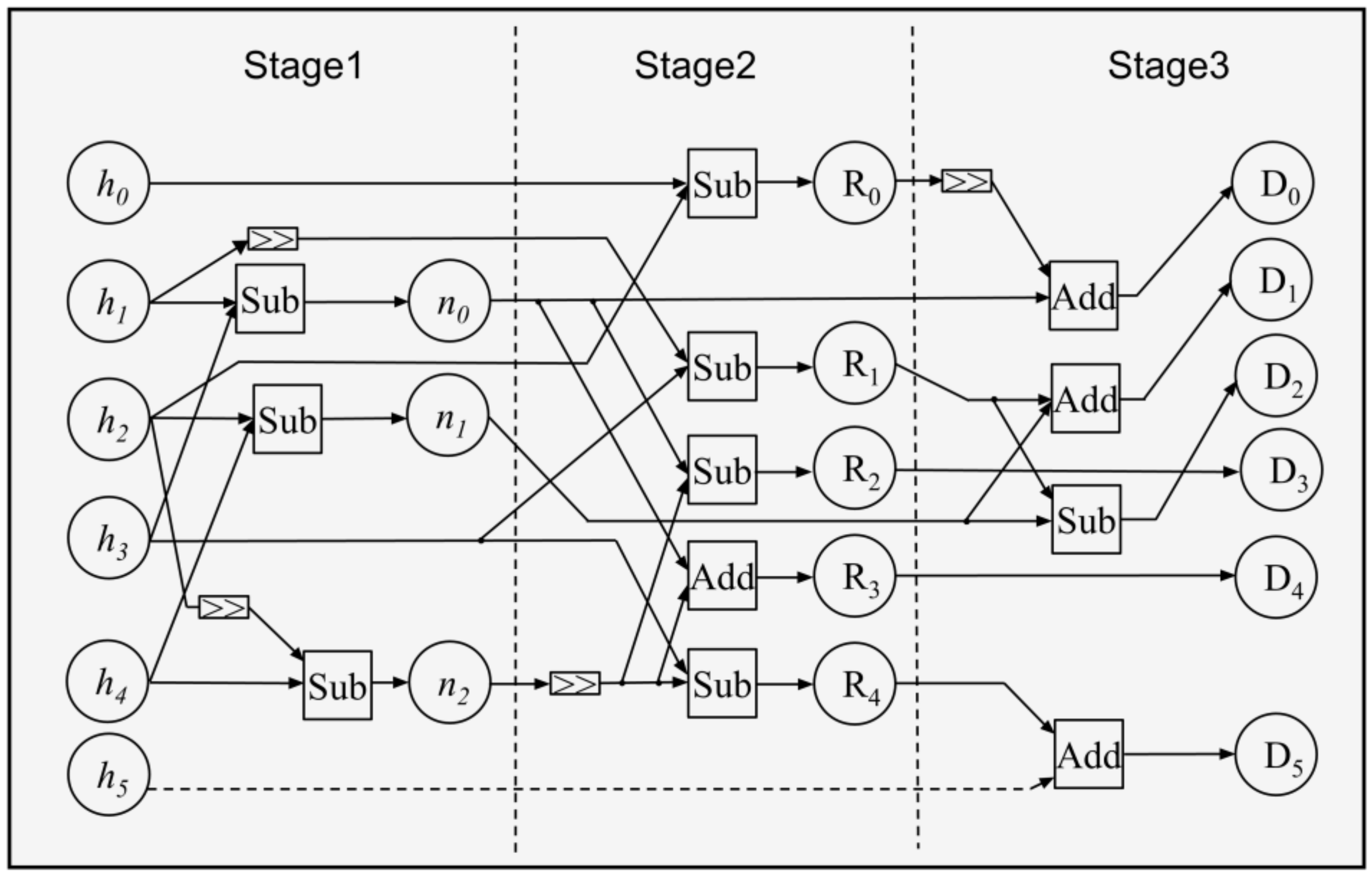
4.2. Design of Layer-to-Layer Transformation Units
- The computation of U = BT HB requires completing the U = BT HB calculation before proceeding to the subsequent multiplication with the matrix B. This sequential processing can result in the addition delay exceeding the matrix dot product unit delay, thereby degrading the overall performance of the accelerator;
- The input transformation matrix involves lengthy chain additions, which can adversely impact the system clock frequency. Additionally, the intermediate results from the addition computation contain reusable components, leading to significant redundant calculations when computed directly.
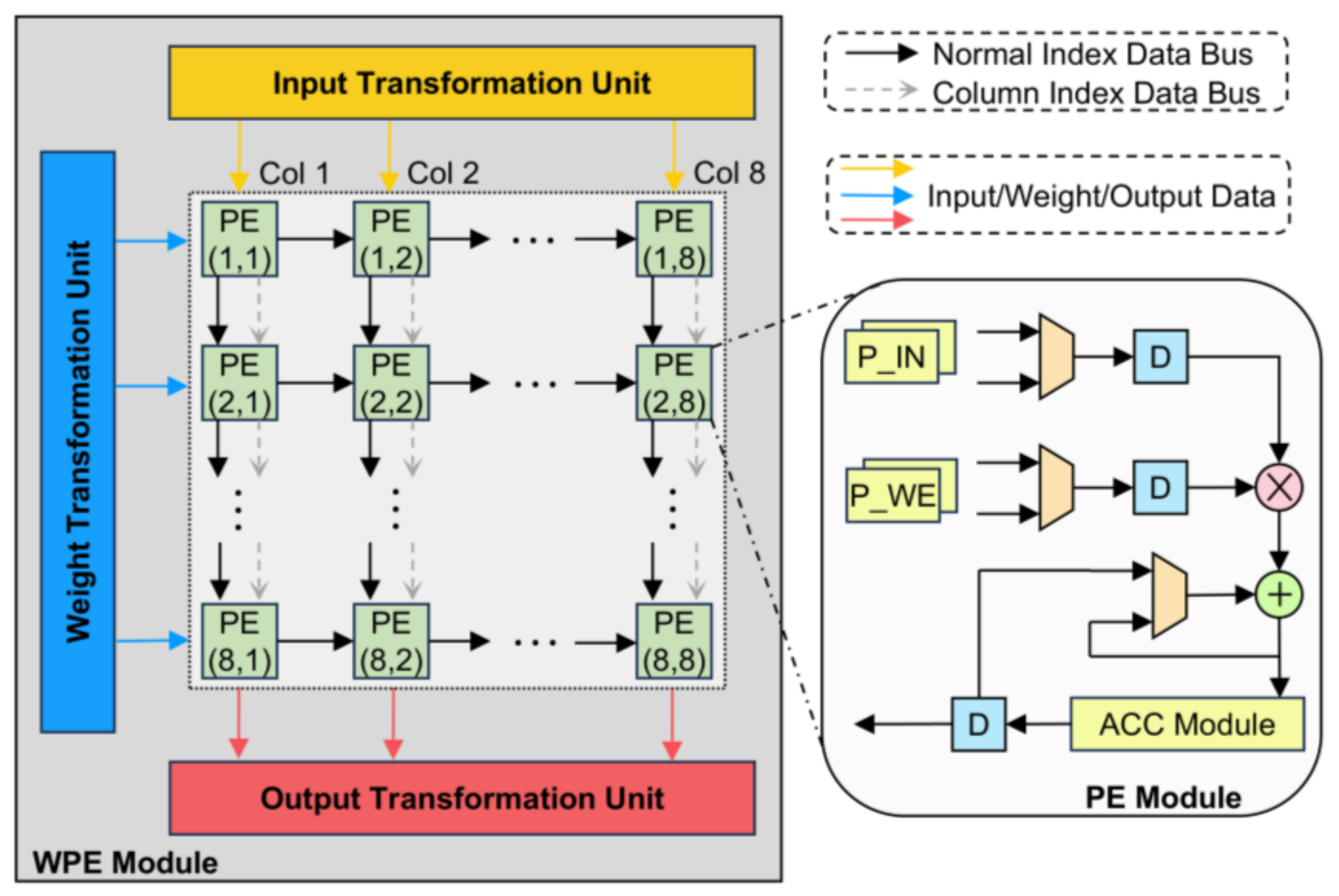
4.3. Architecture of Winograd Processing Element
4.4. Data and Memory Allocation
5. Discussion
5.1. Experimental Setup
5.2. Experiment Results Analysis
5.3. Comparison with Other Works
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CNNs | Convolutional Neural Networks |
| MM | Matrix Multiplication |
| FPGA | Field-Programmable Gate Array |
| GEMM | General Matrix Multiplication |
| PEs | Processing Elements |
| FP | Forward Propagation |
| BP | Backward Propagation |
| WG | Weight Gradient |
| DWM | Decomposable Winograd Method |
| CONV | Convolution Layer |
| APU | Auxiliary Processing Unit |
| WPEs | Winograd Processing Elements |
| MACs | Multiply-Accumulate Operations |
| DRAM | Dynamic Random Access Memory |
| BRAM | Block Random Access Memory |
| DSP | Digital Signal Processor |
| GOPS | Giga Operations Per Second |
References
- Nguyen, D.T.; Nguyen, T.N.; Kim, H.; Lee, H.-J. A High-Throughput and Power-Efficient FPGA Implementation of YOLO CNN for Object Detection. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 1861–1873. [Google Scholar] [CrossRef]
- Ndikumana, A.; Tran, N.H.; Kim, D.H.; Kim, K.T.; Hong, C.S. Deep Learning Based Caching for Self-Driving Cars in Multi-Access Edge Computing. IEEE Trans. Intell. Transp. Syst. 2021, 22, 2862–2877. [Google Scholar] [CrossRef]
- Arefin, M.; Hossen, K.M.; Uddin, M.N. Natural Language Query to SQL Conversion Using Machine Learning Approach. In Proceedings of the 2021 3rd International Conference on Sustainable Technologies for Industry 4.0 (STI), Dhaka, Bangladesh, 18–19 December 2021; pp. 1–6. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Kim, N.J.; Kim, H. FP-AGL: Filter Pruning with Adaptive Gradient Learning for Accelerating Deep Convolutional Neural Networks. IEEE Trans. Multimed. 2023, 25, 5279–5290. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Choquette, J.; Gandhi, W.; Giroux, O.; Stam, N.; Krashinsky, R. NVIDIA A100 Tensor Core GPU: Performance and Innovation. IEEE Micro 2021, 41, 29–35. [Google Scholar] [CrossRef]
- Syed, R.T.; Andjelkovic, M.; Ulbricht, M.; Krstic, M. Towards Reconfigurable CNN Accelerator for FPGA Implementation. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 1249–1253. [Google Scholar] [CrossRef]
- Zhao, Z.; Cao, R.; Un, K.-F.; Yu, W.-H.; Mak, P.-I.; Martins, R.P. An FPGA-Based Transformer Accelerator Using Output Block Stationary Dataflow for Object Recognition Applications. IEEE Trans. Circuits Syst. II Express Briefs 2023, 70, 281–285. [Google Scholar] [CrossRef]
- Chun, D.; Choi, J.; Lee, H.-J.; Kim, H. CP-CNN: Computational Parallelization of CNN-Based Object Detectors in Heterogeneous Embedded Systems for Autonomous Driving. IEEE Access 2023, 11, 52812–52823. [Google Scholar] [CrossRef]
- Habib, G.; Qureshi, S. Optimization and Acceleration of Convolutional Neural Networks: A Survey. J. King Saud Univ.—Comput. Inf. Sci. 2022, 34, 4244–4268. [Google Scholar] [CrossRef]
- Basalama, S.; Sohrabizadeh, A.; Wang, J.; Guo, L.; Cong, J. FlexCNN: An End-to-end Framework for Composing CNN Accelerators on FPGA. ACM Trans. Reconfigurable Technol. Syst. 2023, 16, 1–32. [Google Scholar] [CrossRef]
- Liang, Y.; Lu, L.; Xiao, Q.; Yan, S. Evaluating Fast Algorithms for Convolutional Neural Networks on FPGAs. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2020, 39, 857–870. [Google Scholar] [CrossRef]
- Lavin, A.; Gray, S. Fast Algorithms for Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4013–4021. [Google Scholar]
- Kala, S.; Jose, B.R.; Mathew, J.; Nalesh, S. High-Performance CNN Accelerator on FPGA Using Unified Winograd-GEMM Architecture. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 2019, 27, 2816–2828. [Google Scholar] [CrossRef]
- Mahale, G.; Udupa, P.; Chandrasekharan, K.K.; Lee, S. WinDConv: A Fused Datapath CNN Accelerator for Power-Efficient Edge Devices. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2020, 39, 4278–4289. [Google Scholar] [CrossRef]
- Huang, W.; Wu, H.; Chen, Q.; Luo, C.; Zeng, S.; Li, T.; Huang, Y. FPGA-Based High-Throughput CNN Hardware Accelerator With High Computing Resource Utilization Ratio. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 4069–4083. [Google Scholar] [CrossRef]
- Li, G.; Liu, Z.; Li, F.; Cheng, J. Block Convolution: Toward Memory-Efficient Inference of Large-Scale CNNs on FPGA. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2022, 41, 1436–1447. [Google Scholar] [CrossRef]
- Kim, D.; Jeong, S.; Kim, J.Y. Agamotto: A Performance Optimization Framework for CNN Accelerator With Row Stationary Dataflow. IEEE Trans. Circuits Syst. I Regul. Pap. 2023, 70, 2487–2496. [Google Scholar] [CrossRef]
- Yang, C.; Yang, Y.; Meng, Y.; Huo, K.; Xiang, S.; Wang, J.; Geng, L. Flexible and Efficient Convolutional Acceleration on Unified Hardware Using the Two-Stage Splitting Method and Layer-Adaptive Allocation of 1-D/2-D Winograd Units. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2024, 43, 919–932. [Google Scholar] [CrossRef]
- See, J.-C.; Ng, H.-F.; Tan, H.-K.; Chang, J.-J.; Mok, K.-M.; Lee, W.-K.; Lin, C.-Y. Cryptensor: A Resource-Shared Co-Processor to Accelerate Convolutional Neural Network and Polynomial Convolution. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2023, 42, 4735–4748. [Google Scholar] [CrossRef]
- Yang, C.; Wang, Y.; Wang, X.; Geng, L. A Stride-Based Convolution Decomposition Method to Stretch CNN Acceleration Algorithms for Efficient and Flexible Hardware Implementation. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 3007–3020. [Google Scholar] [CrossRef]
- Cheng, C.; Parhi, K.K. Fast 2D Convolution Algorithms for Convolutional Neural Networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 1678–1691. [Google Scholar] [CrossRef]
- Pan, J.; Chen, D. Accelerate Non-Unit Stride Convolutions with Winograd Algorithms. In Proceedings of the Proceedings of the 26th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 18–21 January 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 358–364. [Google Scholar]
- Winograd, S. Arithmetic Complexity of Computations; SIAM: Delhi, India, 1980; ISBN 978-0-89871-163-9. [Google Scholar]
- Alzubaidi, L.; Zhang, J.; Humaidi, A.J.; Al-Dujaili, A.; Duan, Y.; Al-Shamma, O.; Santamaría, J.; Fadhel, M.A.; Al-Amidie, M.; Farhan, L. Review of Deep Learning: Concepts, CNN Architectures, Challenges, Applications, Future Directions. J. Big Data 2021, 8, 53. [Google Scholar] [CrossRef] [PubMed]
- Huang, D.; Zhang, X.; Zhang, R.; Zhi, T.; He, D.; Guo, J.; Liu, C.; Guo, Q.; Du, Z.; Liu, S.; et al. DWM: A Decomposable Winograd Method for Convolution Acceleration. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 4174–4181. [Google Scholar] [CrossRef]
- Wang, H.; Lu, J.; Lin, J.; Wang, Z. An FPGA-Based Reconfigurable CNN Training Accelerator Using Decomposable Winograd. In Proceedings of the 2023 IEEE Computer Society Annual Symposium on VLSI (ISVLSI), Foz do Iguacu, Brazil, 20–23 June 2023; pp. 1–6. [Google Scholar]
- Shen, J.; Qiao, Y.; Huang, Y.; Wen, M.; Zhang, C. Towards a Multi-Array Architecture for Accelerating Large-Scale Matrix Multiplication on FPGAs. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; IEEE: Florence, Italy, 2018; pp. 1–5. [Google Scholar]
- Yu, J.; Ge, G.; Hu, Y.; Ning, X.; Qiu, J.; Guo, K.; Wang, Y.; Yang, H. Instruction Driven Cross-Layer CNN Accelerator for Fast Detection on FPGA. ACM Trans. Reconfigurable Technol. Syst. 2018, 11, 1–23. [Google Scholar] [CrossRef]
- Lu, J.; Ni, C.; Wang, Z. ETA: An Efficient Training Accelerator for DNNs Based on Hardware-Algorithm Co-Optimization. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 7660–7674. [Google Scholar] [CrossRef]
- Simonyan, K. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Guo, K.; Zeng, S.; Yu, J.; Wang, Y.; Yang, H. [DL] A Survey of FPGA-Based Neural Network Inference Accelerators. ACM Trans. Reconfigurable Technol. Syst. 2019, 12, 1–26. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Implication |
|---|---|
| L | The indices of the convolutional layer |
| h/w | The row or column indices of the feature map |
| H/W | The height or width of the feature map |
| Kh/kw | The row or column indices of the weight kernel |
| Kh/Kw | The height or width of the weight kernel |
| m/n | The indices of the input or output channel |
| M/N | The quantity of the input or output channel |
| Architecture Type | MAC Array | Characteristics | Drawbacks |
|---|---|---|---|
| GEMM-like | One-dimensional | High generality | Intensive computational complexity |
| Winograd-like | Two-dimensional | Small convolution kernels exhibit high computational efficiency | Large convolution kernels degrade computational performance |
| Winograd-GEMM-like | One or Two-dimensional | Dynamic optimal mode selection | Complex control logic introduces critical path delays |
| Reconfigurable-Winograd-like | Two-dimensional | Co-designed hardware and software ensure superior resource utilization | Transform kernel reconfiguration necessitates additional timing control |
| Tile Size | Segmentation Size | Multiplication Complexity | Addition Complexity |
|---|---|---|---|
| 4 × 4 | (N/2)2 | 16× (N/2)2 | 56× (N/2)2 |
| 6 × 6 | (N/4)2 | 32× (N/2)2 | 276× (N/2)2 |
| 2019 [15] | 2020 [13] | 2022 [18] | 2022 [17] | 2023 [19] | 2023 [21] | 2024 [20] | Ours | ||
|---|---|---|---|---|---|---|---|---|---|
| Model | VGG-16 | ResNet-18 | VGG-16 | VGG-16 | VGG-16 | ResNet-18 | VGG-16 | VGG-16 | ResNet-18 |
| Platform | VX690T | XC7Z045 | XC7Z045 | VX980T | XCVU9P | XC7Z045 | XCVU9P | XC7Z045 | |
| Freq (MHz) | 200 | 200 | 150 | 150 | 200 | 200 | 430 | 150 | |
| Precision | 16-bit | 8-bit | 8-bit | 8/16-bit | 8-bit | 8-bit | 8-bit | 8-bit | |
| LUT | 468.0 K | 100.2 K | NA | 335.0 | NA | 17.4 K | 93.0 K | 114.7 K | |
| BRAMs | 1465 | NA | 545 | 1492 | NA | 112 | 336 | 272 | |
| DSPs | 1436 | 818 | 900 | 3395 | 384 | 182 | 576 | 786 | |
| Power (W) | 17.30 | 7.31 | NA | 14.36 | NA | 0.62 | 37.60 | 9.03 | 9.17 |
| Throughput (GOPS) | 407.23 | 124.90 | 374.98 | 1000.00 | 402.00 | 88.91 | 711.00 | 665.38 | 683.26 |
| DSP Eff. (GOPS/DSPs) | 0.28 | 0.15 | 0.42 | 0.29 | 1.05 | 0.49 | 1.23 | 0.85 | 0.87 |
| Power Eff. (GOPS/W) | 23.53 | 17.09 | NA | 69.64 | NA | 143.41 | 18.91 | 72.84 | 74.51 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Liang, Y.; Yang, Z.; Li, X. An Efficient Convolutional Neural Network Accelerator Design on FPGA Using the Layer-to-Layer Unified Input Winograd Architecture. Electronics 2025, 14, 1182. https://doi.org/10.3390/electronics14061182
Li J, Liang Y, Yang Z, Li X. An Efficient Convolutional Neural Network Accelerator Design on FPGA Using the Layer-to-Layer Unified Input Winograd Architecture. Electronics. 2025; 14(6):1182. https://doi.org/10.3390/electronics14061182
Chicago/Turabian StyleLi, Jie, Yong Liang, Zhenhao Yang, and Xinhai Li. 2025. "An Efficient Convolutional Neural Network Accelerator Design on FPGA Using the Layer-to-Layer Unified Input Winograd Architecture" Electronics 14, no. 6: 1182. https://doi.org/10.3390/electronics14061182
APA StyleLi, J., Liang, Y., Yang, Z., & Li, X. (2025). An Efficient Convolutional Neural Network Accelerator Design on FPGA Using the Layer-to-Layer Unified Input Winograd Architecture. Electronics, 14(6), 1182. https://doi.org/10.3390/electronics14061182