
DJPETE-SLAM: Object-Level SLAM System Based on Distributed Joint Pose Estimation and Texture Editing

Abstract
1. Introduction
- (1)
- We propose a new object-level SLAM method that reconstructs rich texture information for objects while performing simultaneous localization and mapping. By using a sparse representation for the environment map and detailed construction for objects, our method achieves map building and object perception in complex scenes.
- (2)
- To address the lack of color and texture information in object-level SLAM, we propose an iterative strategy-based object texture editing and reconstruction algorithm. By utilizing localization trajectories and iteratively merging texture information from different viewpoints, this method achieves texture editing and reconstruction during the object construction process.
- (3)
- To address the issue of optimization error drift caused by pose optimization and the reuse of map points on objects in object-level SLAM, we propose a distributed parallel BA algorithm based on object and map point clouds for optimization. By utilizing distributed joint optimization of map points and objects, this method achieves precise visual localization and object pose estimation.
2. Related Works
3. Methods
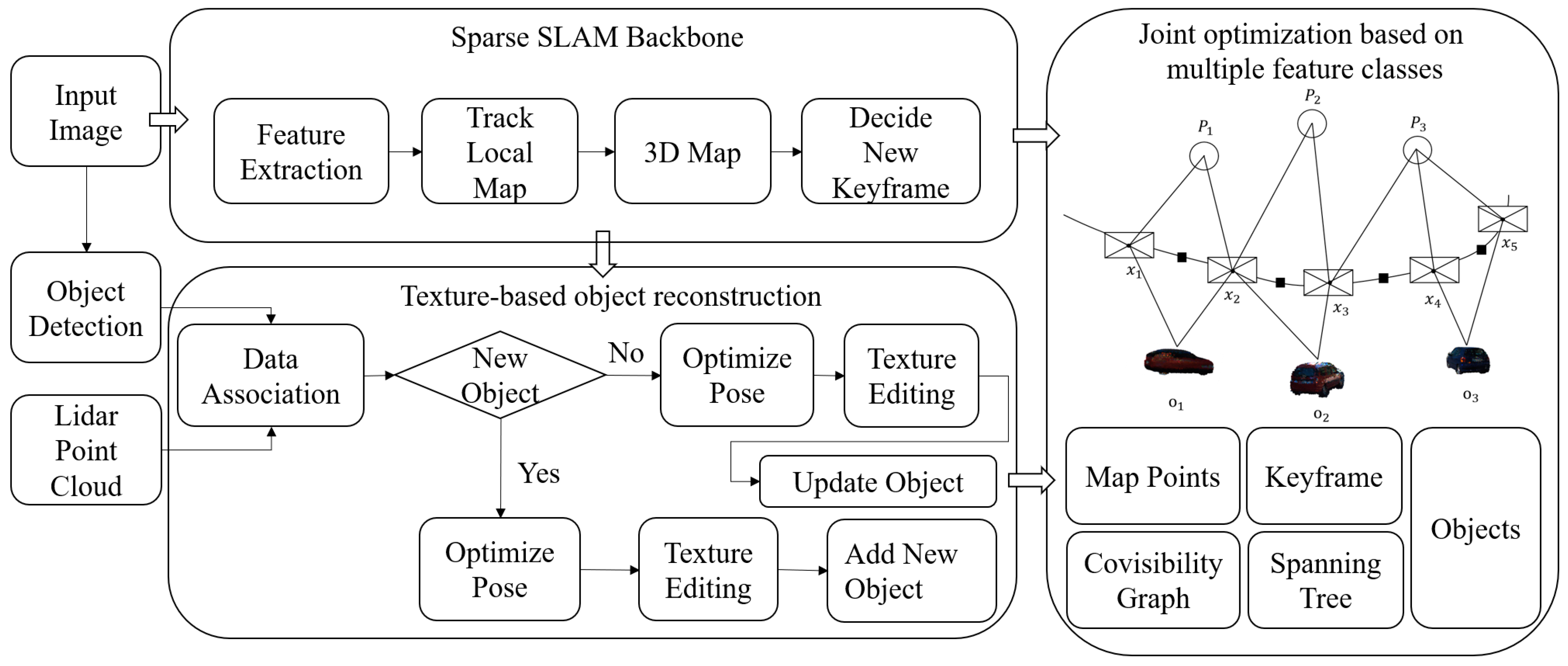
3.1. Overall Framework
3.2. Distributed Joint Optimization Based on Multiple Feature Classes
3.2.1. Camera–Object Pose Constraints
3.2.2. Camera–Map Point Constraints
3.2.3. Joint Graph Optimization Based on Multiple Feature Classes
3.3. Iterative Strategy-Based Texture Feature Editing in Object-Level SLAM
4. Experimental Results
4.1. Experimental Validation of Object Texture Editing Based on Object-Level SLAM
4.2. Validation of Object-Level SLAM Trajectory Accuracy
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dong, Y.; Wang, S.; Yue, J.; Chen, C.; He, S.; Wang, H.; He, B. A novel texture-less object oriented visual SLAM system. IEEE Trans. Intell. Transp. Syst. 2019, 22, 36–49. [Google Scholar] [CrossRef]
- Iqbal, A.; Gans, N.R. Localization of classified objects in slam using nonparametric statistics and clustering. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Campos, C.; Elvira, R.; Rodríguez, J.J.G.; Montiel, J.M.M.; Tardós, J.D. Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE Trans. Robot. 2021, 37, 1874–1890. [Google Scholar] [CrossRef]
- Wimbauer, F.; Yang, N.; von Stumberg, L.; Zeller, N.; Cremers, D. MonoRec: Semi-supervised dense reconstruction in dynamic environments from a single moving camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021. [Google Scholar]
- Wu, Y.; Zhang, Y.; Zhu, D.; Feng, Y.; Coleman, S.; Kerr, D. Eao-slam: Monocular semi-dense object slam based on ensemble data association. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Zhong, F.; Wang, S.; Zhang, Z.; Wang, Y. Detect-SLAM: Making object detection and SLAM mutually beneficial. In Proceedings of the 2018 IEEE winter conference on applications of computer vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Choudhary, S.; Carlone, L.; Nieto, C.; Rogers, J.; Liu, Z.; Christensen, H.I.; Dellaert, F. Multi robot object-based slam. In Proceedings of the 2016 International Symposium on Experimental Robotics, Nagasaki, Japan, 3–8 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Jablonsky, N.; Milford, M.; Sünderhauf, N. An orientation factor for object-oriented SLAM. arXiv 2018, arXiv:1809.06977. [Google Scholar]
- Liu, Y.; Petillot, Y.; Lane, D.; Wang, S. Global localization with object-level semantics and topology. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Lin, S.; Wang, J.; Xu, M.; Zhao, H.; Chen, Z. Contour-SLAM: A Robust Object-Level SLAM Based on Contour Alignment. IEEE Trans. Instrum. Meas. 2023, 72, 5006812. [Google Scholar] [CrossRef]
- Choudhary, S.; Trevor, A.J.; Christensen, H.I.; Dellaert, F. SLAM with object discovery, modeling and mapping. In Proceedings of the 2014 IEEE/RSJ International Conference on Intelligent Robots and Systems, Chicago, IL, USA, 14–18 September 2014; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Wang, J.; Rünz, M.; Agapito, L. DSP-SLAM: Object oriented SLAM with deep shape priors. In Proceedings of the 2021 International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Yang, S.; Scherer, S. Cubeslam: Monocular 3-d object slam. IEEE Trans. Robot. 2019, 35, 925–938. [Google Scholar] [CrossRef]
- Liao, Z.; Hu, Y.; Zhang, J.; Qi, X.; Zhang, X.; Wang, W. So-slam: Semantic object slam with scale proportional and symmetrical texture constraints. IEEE Robot. Autom. Lett. 2022, 7, 4008–4015. [Google Scholar] [CrossRef]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.J.; Davison, A.J. Slam++: Simultaneous localisation and mapping at the level of objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Nicholson, L.; Milford, M.; Sünderhauf, N. Quadricslam: Dual quadrics from object detections as landmarks in object-oriented slam. IEEE Robot. Autom. Lett. 2018, 4, 1–8. [Google Scholar] [CrossRef]
- Tian, R.; Zhang, Y.; Feng, Y.; Yang, L.; Cao, Z.; Coleman, S.; Kerr, D. Accurate and robust object SLAM with 3D quadric landmark reconstruction in outdoors. IEEE Robot. Autom. Lett. 2021, 7, 1534–1541. [Google Scholar] [CrossRef]
- Zhang, J.; Gui, M.; Wang, Q.; Liu, R.; Xu, J.; Chen, S. Hierarchical topic model based object association for semantic SLAM. IEEE Trans. Vis. Comput. Graph. 2019, 25, 3052–3062. [Google Scholar] [CrossRef]
- Sharma, A.; Dong, W.; Kaess, M. Compositional and scalable object slam. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Dong, J.; Fei, X.; Soatto, S. Visual-inertial-semantic scene representation for 3D object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Yang, B.; Ran, W.; Wang, L.; Lu, H.; Chen, Y.P. Multi-classes and motion properties for concurrent visual slam in dynamic environments. IEEE Trans. Multimed. 2021, 24, 3947–3960. [Google Scholar] [CrossRef]
- Xu, B.; Li, W.; Tzoumanikas, D.; Bloesch, M.; Davison, A.; Leutenegger, S. Mid-fusion: Octree-based object-level multi-instance dynamic slam. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019. [Google Scholar]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- McCormac, J.; Clark, R.; Bloesch, M.; Davison, A.; Leutenegger, S. Fusion++: Volumetric object-level slam. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Bowman, S.L.; Atanasov, N.; Daniilidis, K.; Pappas, G.J. Probabilistic data association for semantic slam. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Sucar, E.; Wada, K.; Davison, A. NodeSLAM: Neural object descriptors for multi-view shape reconstruction. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 00 | 01 | 02 | 03 | 04 | 05 | 06 | 07 | Average |
|---|---|---|---|---|---|---|---|---|---|
| ORB-SLAM3 | 1.994 | 8.847 | 3.601 | 3.323 | 1.692 | 1.961 | 2.165 | 1.101 | 3.086 |
| ORB-SLAM2 | 1.697 | 3.268 | 3.679 | 2.900 | 1.260 | 1.732 | 1.959 | 0.907 | 2.175 |
| DynaSLAM | 1.842 | 10.731 | 5.675 | 1.129 | 0.744 | 1.278 | 1.284 | 1.041 | 6.947 |
| DSP-SLAM | 8.279 | 17.944 | 24.398 | 0.770 | 0.888 | 1.301 | 1.302 | 0.691 | 2.966 |
| Ours | 1.873 | 4.256 | 3.854 | 3.231 | 1.439 | 1.192 | 2.352 | 1.264 | 2.433 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, C.; Wang, D.; Li, Z.; Xu, Y.; Zhang, Z. DJPETE-SLAM: Object-Level SLAM System Based on Distributed Joint Pose Estimation and Texture Editing. Electronics 2025, 14, 1181. https://doi.org/10.3390/electronics14061181
Yuan C, Wang D, Li Z, Xu Y, Zhang Z. DJPETE-SLAM: Object-Level SLAM System Based on Distributed Joint Pose Estimation and Texture Editing. Electronics. 2025; 14(6):1181. https://doi.org/10.3390/electronics14061181
Chicago/Turabian StyleYuan, Chaofeng, Dan Wang, Zhi Li, Yuelei Xu, and Zhaoxiang Zhang. 2025. "DJPETE-SLAM: Object-Level SLAM System Based on Distributed Joint Pose Estimation and Texture Editing" Electronics 14, no. 6: 1181. https://doi.org/10.3390/electronics14061181
APA StyleYuan, C., Wang, D., Li, Z., Xu, Y., & Zhang, Z. (2025). DJPETE-SLAM: Object-Level SLAM System Based on Distributed Joint Pose Estimation and Texture Editing. Electronics, 14(6), 1181. https://doi.org/10.3390/electronics14061181