
Advancements, Challenges, and Future Directions in Scene-Graph-Based Image Generation: A Comprehensive Review

 ,
,  , ,
, ,  , and
, and 
Abstract
1. Introduction
- ❖
- Comprehensive overview. Provide a thorough summary of the background information and fundamental concepts in scene-graph-to-image generation.
- ❖
- Methodological classification. Group and analyze the methodologies proposed over time, highlighting their strengths and weaknesses.
- ❖
- Insight into challenges. Equip readers with the understanding necessary to grasp the challenges of generating images from structured scene graphs.
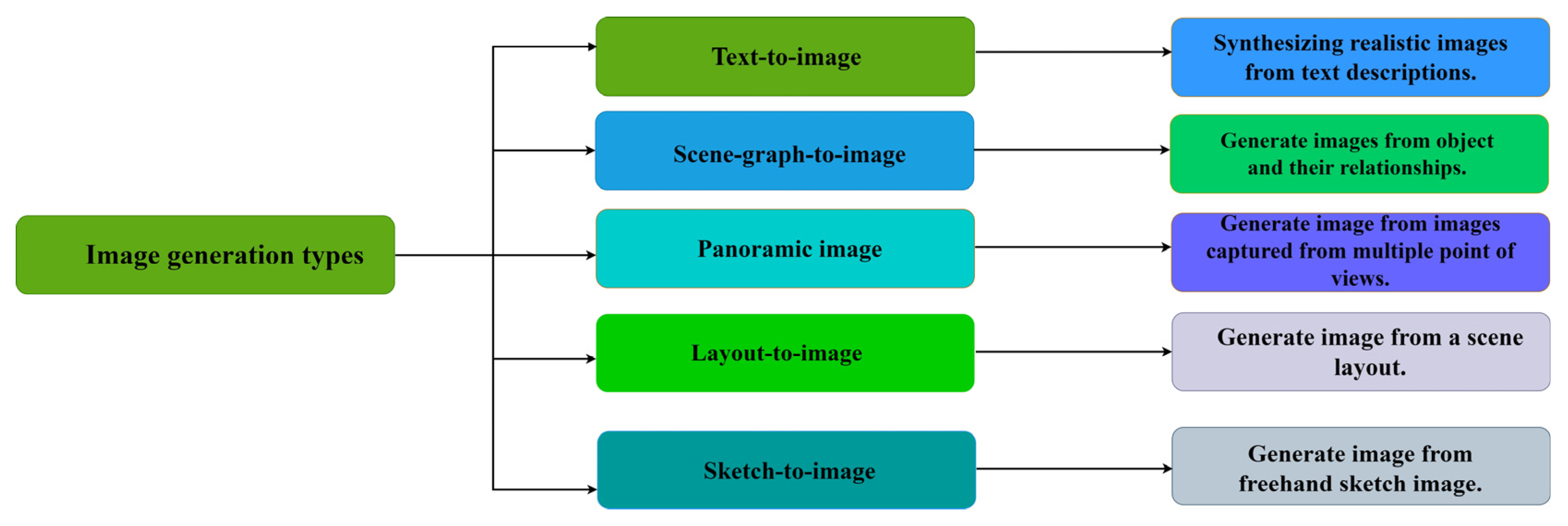
1.1. Scope of the Survey
- ❖
- What are the primary challenges in transforming scene graph representations into photorealistic images?
- ❖
- Which methodologies and algorithms are most commonly used for scene-graph-to-image generation?
- ❖
- How has deep learning contributed to the progress of scene-graph-based image generation methods?
1.2. Structure of the Survey
2. Existing Surveys
3. Background
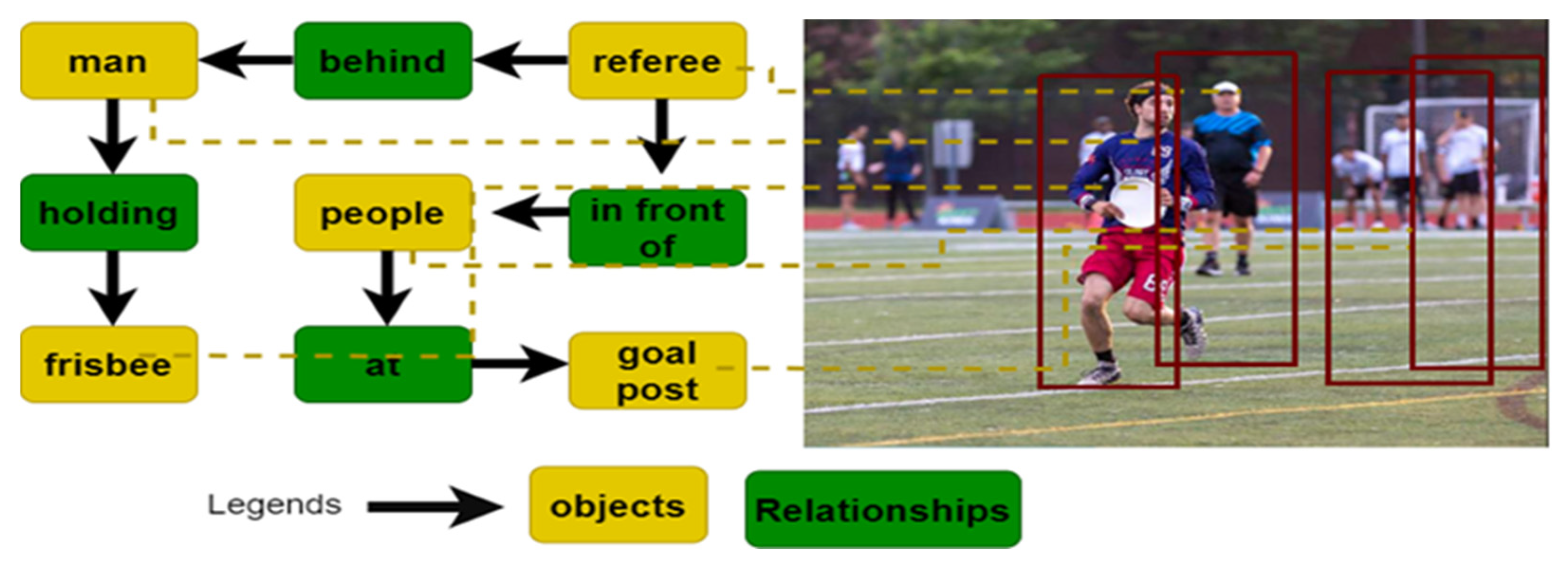
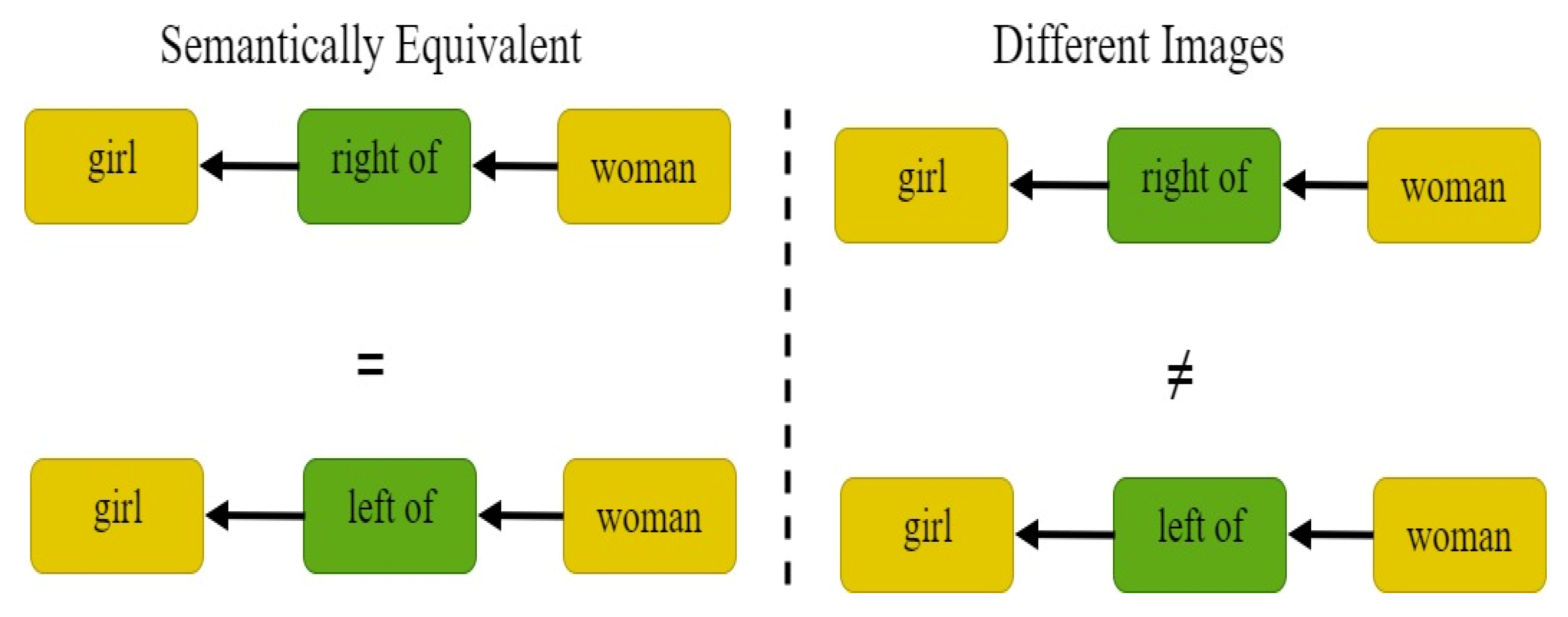
3.1. Scene Graphs
3.2. Graph Convolutional Networks
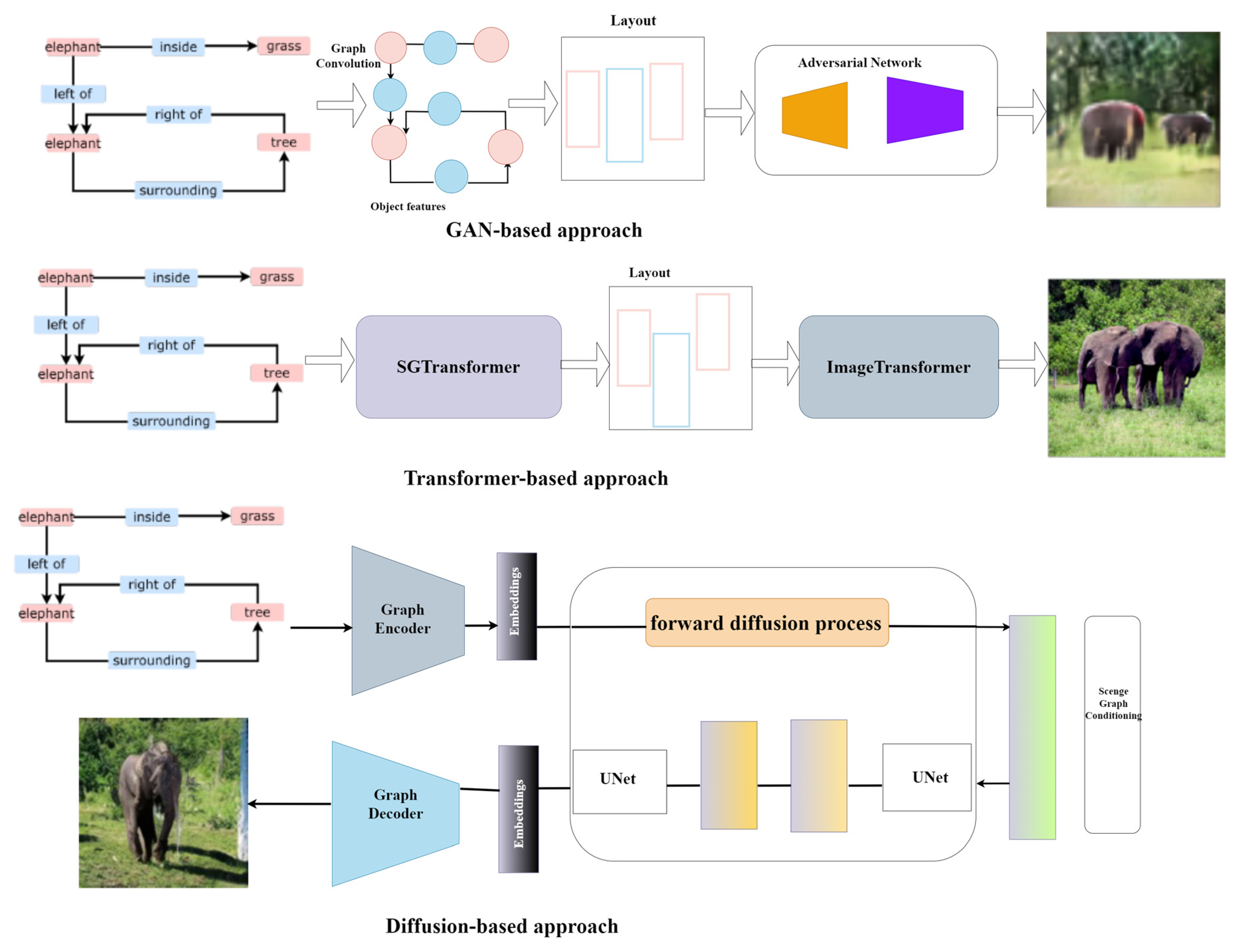
3.3. Overview of Scene-Graph-Based Image Generation Approaches
3.3.1. Image Generation from Scene Graphs and Layouts
3.3.2. GANs for Image Synthesis
- ❖
- GANs generate images in a single forward pass, making them significantly faster compared to diffusion models, which require iterative refinement.
- ❖
- Unlike transformers, which require quadratic attention computations, and diffusion models, which require multiple denoising steps, GANs are computationally lightweight once trained.
- ❖
- The discriminator in GANs ensures high-quality, photorealistic images by pushing the generator to refine details, textures, and object boundaries.
3.3.3. Diffusion Models for Image Synthesis
- ❖
- Diffusion models generate highly detailed and realistic images, often outperforming other generative models in quality.
- ❖
- They provide great flexibility in conditioning, allowing for generating a wide range of images from the same input by adjusting the noise levels and conditioning signals. It is essential to recognize that they have limitations, which include the following:
- ❖
- A significant limitation is the high computational demand, as generating an image involves numerous diffusion steps, resulting in a slower and more resource-intensive process than alternative methods.
- ❖
- Although diffusion models are highly effective, effectively incorporating specific structured data, such as scene graphs, into these models can be challenging and is currently an active area of research.
3.3.4. Graph Transformers for Image Synthesis
- ❖
- Unlike GANs, which primarily focus on local features, transformers capture global relationships using self-attention mechanisms.
- ❖
- Transformers process the entire scene graph at once, ensuring that spatial and semantic relationships are well preserved.
- ❖
- Transformers, on the other hand, use attention mechanisms to learn generalizable representations, making them more adaptable to unseen scene structures.
- ❖
- Transformers can maintain correct spatial positioning between related entities.
4. Method Comparison
4.1. GAN-Based Models
4.1.1. Image Generation from Scene Graphs (SG2IM)
4.1.2. PasteGAN
4.1.3. Learning Canonical Representations for Scene-Graph-to-Image Generation (WSGC)
4.1.4. Image Generation from a Hyper-Scene Graph with Trinomial Hyperedges
4.1.5. Scene-Graph-to-Image Generation with Contextualized Object Layout Refinement
4.2. Transformer-Based Models
4.2.1. Transformer-Based Image Generation from Scene Graphs
4.2.2. Hierarchical Image Generation via Transformer-Based Sequential Patch Selection
4.3. Diffusion-Based Models
4.3.1. SceneGenie
4.3.2. Diffusion-Based Scene-Graph-to-Image Generation with Masked Contrastive Pre-Training
4.3.3. R3CD: Scene-Graph-to-Image Generation with Relation-Aware Compositional Contrastive Control Diffusion
5. Dataset
6. Analysis and Discussion
6.1. Evaluation Metrics
6.1.1. Inception Score (IS)
6.1.2. Fréchet Inception Distance (FID)
6.1.3. Diversity Score (DS)
6.1.4. Kernel Inception Distance (KID)
6.2. Discussion
Comparative Analysis of Image Generation Methods from Scene Graphs: Strengths and Limitations
7. Challenges
7.1. GANs
- Training GANs can be particularly unstable when dealing with scene graphs. The generator and discriminator networks may struggle to converge, leading to inadequate performance. This instability is exacerbated when the complexity of scene graphs increases, as the generator must learn to interpret and generate diverse object interactions and spatial arrangements [126].
- Mode collapse is a significant concern in GANs, especially in the context of scene graphs. When the generator learns to produce a limited set of images that deceive the discriminator, it may overlook the diverse range of object interactions specified in the scene graphs. This results in repetitive or homogeneous outputs that fail to capture the intended variety of scenes. In scene graph applications, mode collapse can manifest as a generator creating similar layouts or interactions across different inputs, leading to a lack of diversity in generated images [121].
- Catastrophic forgetting occurs when learning new information negatively impacts previously acquired knowledge within the network. In scene graphs, as new object relationships are introduced during training, the model may forget how to generate scenes based on earlier learned relationships. This challenge is particularly pronounced when training on datasets with varying complexity and types of relationships.
- Optimizing hyperparameters, such as learning rates, batch sizes, and regularization, becomes crucial in scene graphs. The impact of these parameters on image quality is significant; however, finding the right balance can be challenging due to the intricate nature of scene graph data. The need for fine-tuning increases with model complexity, making achieving stable and high-quality outputs difficult.
7.2. Diffusion Models
- Diffusion models are inherently computationally expensive due to their iterative nature. Each image generation involves numerous forward and backward passes through the model, significantly impeding training and inference speeds. Utilizing these models in real-time applications is challenging, where quick responses are necessary.
- The training procedure for diffusion models requires meticulous noise reduction management throughout a sequence of stages. Achieving the right balance of noise levels is crucial for effective image generation, but it can be challenging. This often necessitates extensive trial and error with various configurations and parameters, leading to longer training times.
- Like GANs, diffusion models are sensitive to hyperparameter selection, including the variance schedule of noise injected during training. Improper configuration can result in poor image quality or unsuccessful training sessions. For instance, the choice of how noise is added (linear vs. cosine schedules) can significantly impact model performance.
- While diffusion models excel at generating high-quality images, maintaining this quality at higher resolutions or with more intricate scene graphs poses difficulties. The model may require additional iterations to produce clear and coherent visuals as input complexity increases, raising computational demands.
7.3. Transformer Models
- Transformers need lots of memory and storage since they can handle whole data sequences simultaneously. This limits the scalability of models with substantial scene graphs or high-resolution picture synthesis. As scene graphs grow in size and complexity, memory requirements can surpass resources, causing out-of-memory (OOM) issues during training or inference.
- The intricate self-attention mechanisms in transformers necessitate considering interactions between all pairs of input and output elements. This results in a quadratic increase in computational complexity relative to the sequence length, which can be mainly taxing in tasks involving complex scene graphs that require detailed spatial and semantic understanding. Thus, training transformer models can be time-consuming and resource-intensive.
- Transformer models typically exhibit superior performance when trained on large datasets. However, obtaining large datasets with detailed annotations of scene graphs and equivalent images can be challenging. In scene-graph-to-image generation, this scarcity of annotated data can restrict the model’s efficacy in scenarios with incomplete information.
- While transformers have the potential to capture intricate relationships within data, they often struggle to generalize from known data to unknown scenarios. Suppose the training data do not adequately encompass the range of possibilities present in real-world situations. In that case, the model may generate images that do not accurately depict new scene graphs or misunderstand the spatial and semantic connections specified by these graphs. This limitation can lead to suboptimal results when generating images based on novel or complex scene configurations.
- The performance of transformer models is susceptible to hyperparameter selection, such as learning rates and attention mechanisms. Improper configuration can lead to poor image quality or ineffective training sessions. For instance, variations in attention patterns (local vs. global) can significantly impact how well the model learns from scene graph data.
7.4. Future Directions
- Future research should focus on developing hybrid models that integrate GANs with diffusion models or transformers. Such combinations could leverage GANs’ ability to generate high-quality images with diffusion models’ robustness against noise, potentially leading to more stable training processes.
- Implementing adaptive algorithms that dynamically adjust parameters during image generation can help mitigate computational costs associated with diffusion models. These algorithms could optimize noise levels based on real-time feedback, enhancing training efficiency and output quality.
- To improve model generalization, exploring advanced data augmentation strategies is crucial. Techniques such as generative augmentation using pre-trained models can enhance dataset diversity, thus enabling models to learn from a broader range of scenarios.
- Investigating the application of self-supervised learning and graph neural networks may provide innovative solutions for understanding complex relationships within scene graphs, leading to improved image generation capabilities.
- Encouraging collaboration between researchers in computer vision, natural language processing, and generative modeling can foster new insights and methodologies for advancing scene-graph-based image generation.
- The delay in image generation processes impedes real-time applications, such as interactive gaming or live digital media production. The development of fast-generation models specifically designed for real-time applications, potentially utilizing edge computing, has the potential to transform user experiences in interactive apps.
- Although models like SceneGenie have made significant advancements, generating exact and detailed images is difficult, particularly in industries that demand extraordinary accuracy, like medical imaging. Enhancing precision could be achieved by further refining models by integrating domain-specific knowledge and training on specialized datasets. Engaging in collaborations with specialists in specific fields to customize models according to precise requirements has the potential to generate substantial enhancements.
- Scene-graph-based image generation has the potential to be combined with other domains, like natural language processing and augmented reality. This integration can lead to more context-aware, more advanced systems that boost user interaction and engagement. Creating cohesive systems capable of directly transforming natural language descriptions into scene graphs or utilizing augmented reality to modify scene graphs in response to user interactions dynamically has the potential to unlock novel applications in educational technology and interactive media.
- Automating digital content creation through advanced image generation models can significantly impact the marketing, design, and entertainment industries. Adapting generative models to specific content creation tasks, such as automatically generating marketing materials based on trend analysis or user engagement data, could streamline workflows and enhance content relevance and personalization.
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Correction Statement
Abbreviations
| CV | Computer vision |
| NLP | Natural language processing |
| SG2IM | Scene graph-to-image |
| GCNs | Graph convolutional networks |
| CNN | Convolutional neural network |
| GANs | Generative adversarial networks |
| VQA | Visual question answering |
| ViTs | Vision transformers |
| WSGC | Weighted scene graph canonicalization |
| R3CD | Relation-aware compositional contrastive control diffusion |
| IS | Inception score |
| DS | Diversity score |
| HIGT | Hierarchical Image Generation via Transformer-Based Sequential Patch Selection |
| TBIGSG | Transformer-based image generation from scene graphs |
| SL2I | Scene layout-to-image |
| ML | Machine learning |
| GNNs | Graph neural networks |
| MLP | Multilayer perceptron |
| CRN | Cascaded refinement network |
| SLN | Scene layout network |
| WGAN | Wasserstein GAN |
| SGDiff | Scene graph diffusion |
| SDMT | Scalable diffusion models with transformers |
| COLoR | Contextualized object layout refinement |
| TBIG | Transformer-based image generation |
| FID | Fréchet inception distance |
| KID | Kernel inception distance |
| IGHSGTH | Image generation from a hyper-scene graph with trinomial hyperedges |
| CLIP | Contrastive language–image pre-training |
References
- Ren, P.; Xiao, Y.; Chang, X.; Huang, P.-Y.; Li, Z.; Gupta, B.B.; Chen, X.; Wang, X. A survey of deep active learning. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Xu, J.; Zhao, J.; Zhou, R.; Liu, C.; Zhao, P.; Zhao, L. Predicting destinations by a deep learning based approach. IEEE Trans. Knowl. Data Eng. 2021, 33, 651–666. [Google Scholar] [CrossRef]
- Rossi, R.A.; Zhou, R.; Ahmed, N.K. Deep inductive graph representation learning. IEEE Trans. Knowl. Data Eng. 2018, 32, 438–452. [Google Scholar] [CrossRef]
- Liu, B.; Yu, L.; Che, C.; Lin, Q.; Hu, H.; Zhao, X. Integration and performance analysis of artificial intelligence and computer vision based on deep learning algorithms. arXiv 2023, arXiv:2312.12872. [Google Scholar] [CrossRef]
- Hassaballah, M.; Awad, A.I. Deep Learning in Computer Vision: Principles and Applications; CRC Press: Boca Raton, FL, USA, 2020. [Google Scholar]
- Wang, D.; Wang, J.-G.; Xu, K. Deep learning for object detection, classification and tracking in industry applications. Sensors 2021, 21, 7349. [Google Scholar] [CrossRef]
- Wu, H.; Liu, Q.; Liu, X. A review on deep learning approaches to image classification and object segmentation. Comput. Mater. Contin. 2019, 58, 575–597. [Google Scholar] [CrossRef]
- Johnson, J.; Krishna, R.; Stark, M.; Li, L.-J.; Shamma, D.; Bernstein, M.; Fei-Fei, L. Image retrieval using scene graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3668–3678. [Google Scholar]
- Zhang, C.; Cui, Z.; Chen, C.; Liu, S.; Zeng, B.; Bao, H.; Zhang, Y. Deeppanocontext: Panoramic 3d scene understanding with holistic scene context graph and relation-based optimization. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 12632–12641. [Google Scholar]
- Gao, C.; Li, B. Time-Conditioned Generative Modeling of object-centric representations for video decomposition and prediction. In Proceedings of the Uncertainty in Artificial Intelligence, Pittsburgh, PA, USA, 31 July–4 August 2023; pp. 613–623. [Google Scholar]
- Wang, R.; Wei, Z.; Li, P.; Zhang, Q.; Huang, X. Storytelling from an image stream using scene graphs. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 9185–9192. [Google Scholar]
- Reed, S.; Akata, Z.; Yan, X.; Logeswaran, L.; Schiele, B.; Lee, H. Generative adversarial text to image synthesis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 1060–1069. [Google Scholar]
- Liao, W.; Hu, K.; Yang, M.Y.; Rosenhahn, B. Text to image generation with semantic-spatial aware gan. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18187–18196. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large scale gan training for high fidelity natural image synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Crowson, K.; Biderman, S.; Kornis, D.; Stander, D.; Hallahan, E.; Castricato, L.; Raff, E. Vqgan-clip: Open domain image generation and editing with natural language guidance. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 88–105. [Google Scholar]
- Gafni, O.; Polyak, A.; Ashual, O.; Sheynin, S.; Parikh, D.; Taigman, Y. Make-a-scene: Scene-based text-to-image generation with human priors. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 89–106. [Google Scholar]
- Razavi, A.; den Oord, A.; Vinyals, O. Generating diverse high-fidelity images with vq-vae-2. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2019; Volume 32. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2020; Volume 33, pp. 6840–6851. [Google Scholar]
- Wild, V.D.; Ghalebikesabi, S.; Sejdinovic, D.; Knoblauch, J. A rigorous link between deep ensembles and (variational) bayesian methods. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2024; Volume 36. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-based generative modeling through stochastic differential equations. arXiv 2020, arXiv:2011.13456. [Google Scholar]
- Dhariwal, P.; Nichol, A. diffusion models beat gans on image synthesis. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2021; Volume 34, pp. 8780–8794. [Google Scholar]
- Ramesh, A.; Dhariwal, P.; Nichol, A.; Chu, C.; Chen, M. Hierarchical text-conditional image generation with clip latents. arXiv 2022, arXiv:2204.06125. [Google Scholar]
- Saharia, C.; Chan, W.; Saxena, S.; Li, L.; Whang, J.; Denton, E.L.; Ghasemipour, K.; Gontijo Lopes, R.; Karagol Ayan, B.; Salimans, T.; et al. Photorealistic text-to-image diffusion models with deep language understanding. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2022; Volume 35, pp. 36479–36494. [Google Scholar]
- Ho, J.; Salimans, T. Classifier-free diffusion guidance. arXiv 2022, arXiv:2207.12598. [Google Scholar]
- Kim, G.; Kwon, T.; Ye, J.C. Diffusionclip: Text-guided diffusion models for robust image manipulation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 2426–2435. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Couairon, G.; Verbeek, J.; Schwenk, H.; Cord, M. Diffedit: Diffusion-based semantic image editing with mask guidance. arXiv 2022, arXiv:2210.11427. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the in ICML Workshop on Deep Learning for Audio, Speech and Language Processing, Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Meng, C.; He, Y.; Song, Y.; Song, J.; Wu, J.; Zhu, J.-Y.; Ermon, S. Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv 2021, arXiv:2108.01073. [Google Scholar]
- Yang, L.; Zhang, Z.; Song, Y.; Hong, S.; Xu, R.; Zhao, Y.; Zhang, W.; Cui, B.; Yang, M.-H. Diffusion models: A comprehensive survey of methods and applications. ACM Comput. Surv. 2023, 56, 105. [Google Scholar] [CrossRef]
- Krishna, R.; Zhu, Y.; Groth, O.; Johnson, J.; Hata, K.; Kravitz, J.; Chen, S.; Kalantidis, Y.; Li, L.-J.; Shamma, D.A.; et al. Visual genome: Connecting language and vision using crowdsourced dense image annotations. Int. J. Comput. Vis. 2017, 123, 32–73. [Google Scholar] [CrossRef]
- Johnson, J.; Gupta, A.; Fei-Fei, L. Image generation from scene graphs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1219–1228. [Google Scholar]
- Hughes, N.; Chang, Y.; Carlone, L. Hydra: A real-time spatial perception system for 3D scene graph construction and optimization. arXiv 2022, arXiv:2201.13360. [Google Scholar]
- Fei, Z.; Yan, X.; Wang, S.; Tian, Q. Deecap: Dynamic early exiting for efficient image captioning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12216–12226. [Google Scholar]
- Zhao, S.; Li, L.; Peng, H. Aligned visual semantic scene graph for image captioning. Displays 2022, 74, 102210. [Google Scholar] [CrossRef]
- Dhamo, H.; Farshad, A.; Laina, I.; Navab, N.; Hager, G.D.; Tombari, F.; Rupprecht, C. Semantic image manipulation using scene graphs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5213–5222. [Google Scholar]
- Rahman, T.; Chou, S.-H.; Sigal, L.; Carenini, G. An improved attention for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1653–1662. [Google Scholar]
- Zhang, C.; Chao, W.-L.; Xuan, D. An empirical study on leveraging scene graphs for visual question answering. arXiv 2019, arXiv:1907.12133. [Google Scholar]
- Schuster, S.; Krishna, R.; Chang, A.; Fei-Fei, L.; Manning, C.D. Generating semantically precise scene graphs from textual descriptions for improved image retrieval. In Proceedings of the Fourth Workshop on Vision and Language, Lisbon, Portugal, 18 September 2015; pp. 70–80. [Google Scholar]
- He, S.; Liao, W.; Yang, M.Y.; Yang, Y.; Song, Y.-Z.; Rosenhahn, B.; Xiang, T. Context-aware layout to image generation with enhanced object appearance. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15049–15058. [Google Scholar]
- Zhou, R.; Jiang, C.; Xu, Q. A survey on generative adversarial network-based text-to-image synthesis. Neurocomputing 2021, 451, 316–336. [Google Scholar] [CrossRef]
- Shamsolmoali, P.; Zareapoor, M.; Granger, E.; Zhou, H.; Wang, R.; Celebi, M.E.; Yang, J. Image synthesis with adversarial networks: A comprehensive survey and case studies. Inf. Fusion 2021, 72, 126–146. [Google Scholar] [CrossRef]
- Elasri, M.; Elharrouss, O.; Al-Maadeed, S.; Tairi, H. Image generation: A review. Neural Process. Lett. 2022, 54, 4609–4646. [Google Scholar] [CrossRef]
- PM, A.F.; Rahiman, V.A. A review of generative adversarial networks for text-to-image synthesis. In Proceedings of the International Conference on Emerging Trends in Engineering-YUKTHI2023, Kerala, India, 10–12 April 2023. [Google Scholar]
- Hassan, M.U.; Alaliyat, S.; Hameed, I.A. Image generation models from scene graphs and layouts: A comparative analysis. J. King Saud Univ. Inf. Sci. 2023, 35, 101543. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef]
- Lu, C.; Krishna, R.; Bernstein, M.; Fei-Fei, L. Visual relationship detection with language priors. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Proceedings, Part I. Amsterdam, The Netherlands, 11–14 October 2016; Volume 14, pp. 852–869. [Google Scholar]
- Zhao, L.; Yuan, L.; Gong, B.; Cui, Y.; Schroff, F.; Yang, M.-H.; Adam, H.; Liu, T. Unified visual relationship detection with vision and language models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6962–6973. [Google Scholar]
- Liao, W.; Rosenhahn, B.; Shuai, L.; Yang, M.Y. Natural language guided visual relationship detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Armeni, I.; He, Z.-Y.; Gwak, J.; Zamir, A.R.; Fischer, M.; Malik, J.; Savarese, S. 3D scene graph: A structure for unified semantics, 3d space, and camera. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5664–5673. [Google Scholar]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef] [PubMed]
- Ding, M.; Guo, Y.; Huang, Z.; Lin, B.; Luo, H. GROM: A generalized routing optimization method with graph neural network and deep reinforcement learning. J. Netw. Comput. Appl. 2024, 229, 103927. [Google Scholar] [CrossRef]
- Michel, G.; Nikolentzos, G.; Lutzeyer, J.F.; Vazirgiannis, M. Path neural networks: Expressive and accurate graph neural networks. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2023; pp. 24737–24755. [Google Scholar]
- Talal, M.; Gerfan, S.; Qays, R.; Pamucar, D.; Delen, D.; Pedrycz, W.; Alamleh, A.; Alamoodi, A.; Zaidan, B.B.; Simic, V. A Comprehensive Systematic Review on Machine Learning Application in the 5G-RAN Architecture: Issues, Challenges, and Future Directions. J. Netw. Comput. Appl. 2024, 233, 104041. [Google Scholar] [CrossRef]
- Zhang, Z.; Tessone, C.J.; Liao, H. Heterogeneous graph representation learning via mutual information estimation for fraud detection. J. Netw. Comput. Appl. 2024, 234, 104046. [Google Scholar] [CrossRef]
- Wang, K.; Cui, Y.; Qian, Q.; Chen, Y.; Guo, C.; Shen, G. USAGE: Uncertain flow graph and spatio-temporal graph convolutional network-based saturation attack detection method. J. Netw. Comput. Appl. 2023, 219, 103722. [Google Scholar] [CrossRef]
- Zhang, P.; Luo, Z.; Kumar, N.; Guizani, M.; Zhang, H.; Wang, J. CE-VNE: Constraint escalation virtual network embedding algorithm assisted by graph convolutional networks. J. Netw. Comput. Appl. 2024, 221, 103736. [Google Scholar] [CrossRef]
- Li, Y.; Ma, T.; Bai, Y.; Duan, N.; Wei, S.; Wang, X. Pastegan: A Semi-Parametric Method to Generate Image from Scene Graph. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2019; Volume 32. [Google Scholar]
- Zhao, B.; Meng, L.; Yin, W.; Sigal, L. Image generation from layout. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8584–8593. [Google Scholar]
- Zhao, B.; Yin, W.; Meng, L.; Sigal, L. Layout2image: Image generation from layout. Int. J. Comput. Vis. 2020, 128, 2418–2435. [Google Scholar] [CrossRef]
- Chen, Q.; Koltun, V. Photographic image synthesis with cascaded refinement networks. In Proceedings of the IEEE International Conference on Computer Vision, Norwell, MA, USA, 1 October 2017; pp. 1511–1520. [Google Scholar]
- Henaff, M.; Bruna, J.; LeCun, Y. Deep convolutional networks on graph-structured data. arXiv 2015, arXiv:1506.05163. [Google Scholar]
- Zhang, S.; Tong, H.; Xu, J.; Maciejewski, R. Graph convolutional networks: A comprehensive review. Comput. Soc. Netw. 2019, 6, 11. [Google Scholar] [CrossRef] [PubMed]
- Mittal, G.; Agrawal, S.; Agarwal, A.; Mehta, S.; Marwah, T. Interactive image generation using scene graphs. arXiv 2019, arXiv:1905.03743. [Google Scholar]
- Tripathi, S.; Bhiwandiwalla, A.; Bastidas, A.; Tang, H. Using scene graph context to improve image generation. arXiv 2019, arXiv:1901.03762. [Google Scholar]
- Herzig, R.; Bar, A.; Xu, H.; Chechik, G.; Darrell, T.; Globerson, A. Learning canonical representations for scene graph to image generation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Proceedings Part XXVI. Glasgow, UK, 23–28 August 2020; Volume 16, pp. 210–227. [Google Scholar]
- Sylvain, T.; Zhang, P.; Bengio, Y.; Hjelm, R.D.; Sharma, S. Object-centric image generation from layouts. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 19–21 May 2021; Volume 35, pp. 2647–2655. [Google Scholar]
- Caesar, H.; Uijlings, J.; Ferrari, V. Coco-stuff: Thing and stuff classes in context. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1209–1218. [Google Scholar]
- Xu, X.; Xu, N. Hierarchical image generation via transformer-based sequential patch selection. In Proceedings of the AAAI Conference on Artificial Intelligence, Palo Alto, CA, USA, 22 February–1 March 2022; Volume 36, pp. 2938–2945. [Google Scholar]
- Sortino, R.; Palazzo, S.; Rundo, F.; Spampinato, C. Transformer-based image generation from scene graphs. Comput. Vis. Image Underst. 2023, 233, 103721. [Google Scholar] [CrossRef]
- Zhang, Y.; Meng, C.; Li, Z.; Chen, P.; Yang, G.; Yang, C.; Sun, L. Learning object consistency and interaction in image generation from scene graphs. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, Vienna, Austria, 19–25 August 2023; pp. 1731–1739. [Google Scholar]
- Farshad, A.; Yeganeh, Y.; Chi, Y.; Shen, C.; Ommer, B.; Navab, N. Scenegenie: Scene graph guided diffusion models for image synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 88–98. [Google Scholar]
- Yang, L.; Huang, Z.; Song, Y.; Hong, S.; Li, G.; Zhang, W.; Cui, B.; Ghanem, B.; Yang, M.-H. Diffusion-based scene graph to image generation with masked contrastive pre-training. arXiv 2022, arXiv:2211.11138. [Google Scholar]
- Liu, J.; Liu, Q. R3CD: Scene graph to image generation with relation-aware compositional contrastive control diffusion. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 20–27 February 2024; Volume 38, pp. 3657–3665. [Google Scholar]
- Ivgi, M.; Benny, Y.; Ben-David, A.; Berant, J.; Wolf, L. Scene graph to image generation with contextualized object layout refinement. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 2428–2432. [Google Scholar]
- Miyake, R.; Matsukawa, T.; Suzuki, E. Image generation from a hyper scene graph with trinomial hyperedges. In Proceedings of the VISIGRAPP (5: VISAPP), Lisbon, Portugal, 19–21 February 2023; pp. 185–195. [Google Scholar]
- Ko, M.; Cha, E.; Suh, S.; Lee, H.; Han, J.-J.; Shin, J.; Han, B. Self-supervised dense consistency regularization for image-to-image translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18301–18310. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Skorokhodov, I.; Tulyakov, S.; Elhoseiny, M. Stylegan-v: A continuous video generator with the price, image quality and perks of stylegan2. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3626–3636. [Google Scholar]
- Vondrick, C.; Pirsiavash, H.; Torralba, A. Generating videos with scene dynamics. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2016; Volume 29. [Google Scholar]
- Zhao, X.; Guo, J.; Wang, L.; Li, F.; Li, J.; Zheng, J.; Yang, B. STS-GAN: Can we synthesize solid texture with high fidelity from arbitrary 2d exemplar? In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, Macao SAR, China, 19–25 August 2023; pp. 1768–1776. [Google Scholar]
- Cao, T.; Kreis, K.; Fidler, S.; Sharp, N.; Yin, K. Texfusion: Synthesizing 3d textures with text-guided image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4169–4181. [Google Scholar]
- Li, C.; Su, Y.; Liu, W. Text-to-text generative adversarial networks. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Chai, Y.; Yin, Q.; Zhang, J. Improved training of mixture-of-experts language gans. In Proceedings of the ICASSP 2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Shen, Y.; Yang, C.; Tang, X.; Zhou, B. Interfacegan: Interpreting the disentangled face representation learned by gans. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2004–2018. [Google Scholar] [CrossRef]
- Gauthier, J. Conditional generative adversarial nets for convolutional face generation. In Class Project for Stanford CS231N: Convolutional Neural Networks for Visual Recognition, Winter Semester; Stanford University: Stanford, CA, USA, 2014; Volume 2014, p. 2. [Google Scholar]
- Kammoun, A.; Slama, R.; Tabia, H.; Ouni, T.; Abid, M. Generative adversarial networks for face generation: A survey. ACM Comput. Surv. 2022, 55, 1–37. [Google Scholar] [CrossRef]
- Odena, A.; Olah, C.; Shlens, J. Conditional image synthesis with auxiliary classifier gans. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 2642–2651. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2016; Volume 29. [Google Scholar]
- Mao, Q.; Lee, H.-Y.; Tseng, H.-Y.; Ma, S.; Yang, M.-H. Mode seeking generative adversarial networks for diverse image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1429–1437. [Google Scholar]
- Alaluf, Y.; Patashnik, O.; Cohen-Or, D. Restyle: A residual-based stylegan encoder via iterative refinement. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6711–6720. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2014; Volume 27. [Google Scholar]
- Metz, L.; Poole, B.; Pfau, D.; Sohl-Dickstein, J. Unrolled generative adversarial networks. arXiv 2016, arXiv:1611.02163. [Google Scholar]
- Wiatrak, M.; Albrecht, S.V.; Nystrom, A. Stabilizing generative adversarial networks: A survey. arXiv 2019, arXiv:1910.00927. [Google Scholar]
- Mishra, R.; Subramanyam, A. V Image synthesis with graph conditioning: Clip-guided diffusion models for scene graphs. arXiv 2024, arXiv:2401.14111. [Google Scholar]
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2256–2265. [Google Scholar]
- Song, Y.; Ermon, S. Generative modeling by estimating gradients of the data distribution. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2019; Volume 32. [Google Scholar]
- Gu, S.; Chen, D.; Bao, J.; Wen, F.; Zhang, B.; Chen, D.; Yuan, L.; Guo, B. Vector quantized diffusion model for text-to-image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10696–10706. [Google Scholar]
- Saharia, C.; Chan, W.; Chang, H.; Lee, C.; Ho, J.; Salimans, T.; Fleet, D.; Norouzi, M. Palette: Image-to-image diffusion models. In Proceedings of the ACM SIGGRAPH 2022 Conference Proceedings, Vancouver, BC, Canada, 7–11 August 2022; pp. 1–10. [Google Scholar]
- Nichol, A.; Dhariwal, P.; Ramesh, A.; Shyam, P.; Mishkin, P.; McGrew, B.; Sutskever, I.; Chen, M. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. arXiv 2021, arXiv:2112.10741. [Google Scholar]
- Vahdat, A.; Kreis, K.; Kautz, J. Score-based generative modeling in latent space. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2021; Volume 34, pp. 11287–11302. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2017; Volume 30. [Google Scholar]
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling vision transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12104–12113. [Google Scholar]
- Chen, L.; Lu, K.; Rajeswaran, A.; Lee, K.; Grover, A.; Laskin, M.; Abbeel, P.; Srinivas, A.; Mordatch, I. Decision transformer: Reinforcement learning via sequence modeling. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2021; Volume 34, pp. 15084–15097. [Google Scholar]
- Janner, M.; Li, Q.; Levine, S. Offline reinforcement learning as one big sequence modeling problem. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2021; Volume 34, pp. 1273–1286. [Google Scholar]
- Peebles, W.; Radosavovic, I.; Brooks, T.; Efros, A.A.; Malik, J. Learning to learn with generative models of neural network checkpoints. arXiv 2022, arXiv:2209.12892. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling laws for neural language models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Henighan, T.; Kaplan, J.; Katz, M.; Chen, M.; Hesse, C.; Jackson, J.; Jun, H.; Brown, T.B.; Dhariwal, P.; Gray, S.; et al. Scaling laws for autoregressive generative modeling. arXiv 2020, arXiv:2010.14701. [Google Scholar]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating long sequences with sparse transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative pretraining from pixels. In Proceedings of the International Conference on Machine Learning, Shenzhen, China, 15–17 February 2020; pp. 1691–1703. [Google Scholar]
- Parmar, N.; Vaswani, A.; Uszkoreit, J.; Kaiser, L.; Shazeer, N.; Ku, A.; Tran, D. Image C. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 4055–4064. [Google Scholar]
- Ramesh, A.; Pavlov, M.; Goh, G.; Gray, S.; Voss, C.; Radford, A.; Chen, M.; Sutskever, I. Zero-Shot Text-to-Image Generation. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8821–8831. [Google Scholar]
- Esser, P.; Rombach, R.; Ommer, B. Taming Transformers for High-Resolution Image Synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12873–12883. [Google Scholar]
- Chang, H.; Zhang, H.; Jiang, L.; Liu, C.; Freeman, W.T. Maskgit: Masked Generative Image Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11315–11325. [Google Scholar]
- Van Den Oord, A.; Vinyals, O.; Kavukcuoglu, K. Neural Discrete Representation Learning. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2017; Volume 30. [Google Scholar]
- Yu, J.; Xu, Y.; Koh, J.Y.; Luong, T.; Baid, G.; Wang, Z.; Vasudevan, V.; Ku, A.; Yang, Y.; Ayan, B.K.; et al. Scaling autoregressive models for content-rich text-to-image generation. arXiv 2022, arXiv:2206.10789. [Google Scholar]
- Peebles, W.; Xie, S. Scalable Diffusion Models with Transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 4195–4205. [Google Scholar]
- Bińkowski, M.; Sutherland, D.J.; Arbel, M.; Gretton, A. Demystifying mmd gans. arXiv 2018, arXiv:1801.01401. [Google Scholar]
- Wang, Y.; Gonzalez-Garcia, A.; Berga, D.; Herranz, L.; Khan, F.S.; Weijer, J. van de Minegan: Effective Knowledge Transfer from Gans to Target Domains with Few Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9332–9341. [Google Scholar]
- Cao, H.; Tan, C.; Gao, Z.; Xu, Y.; Chen, G.; Heng, P.-A.; Li, S.Z. A survey on generative diffusion models. IEEE Trans. Knowl. Data Eng. 2024, 36, 2814–2830. [Google Scholar] [CrossRef]
- Yuan, C.; Zhao, K.; Kuruoglu, E.E.; Wang, L.; Xu, T.; Huang, W.; Zhao, D.; Cheng, H.; Rong, Y. A Survey of Graph Transformers: Architectures, Theories and Applications. arXiv 2025, arXiv:2502.16533. [Google Scholar]
- Sun, W.; Wu, T. Image Synthesis from Reconfigurable Layout and Style. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10531–10540. [Google Scholar]
- Johnson, J.; Hariharan, B.; van der Maaten, L.; Fei-Fei, L.; Zitnick, C.L.; Girshick, R. CLEVR: A Diagnostic Dataset for Compositional Language and Elementary Visual Reasoning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2901–2910. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans Trained by a Two Time-Scale Update Rule Converge to a Local Nash Equilibrium. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2017; Volume 30. [Google Scholar]
- Meshry, M.M. Neural Rendering Techniques for Photo-Realistic Image Generation and Novel View Synthesis. Ph.D. Thesis, University of Maryland, College Park, MD, USA, 2022. [Google Scholar]
- Wu, Y.-L.; Shuai, H.-H.; Tam, Z.-R.; Chiu, H.-Y. Gradient Normalization for Generative Adversarial Networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 6373–6382. [Google Scholar]
- Kim, J.; Choi, Y.; Uh, Y. Feature Statistics Mixing Regularization for Generative Adversarial Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 11294–11303. [Google Scholar]
- Miyato, T.; Kataoka, T.; Koyama, M.; Yoshida, Y. Spectral normalization for generative adversarial networks. arXiv 2018, arXiv:1802.05957. [Google Scholar]
- Zhou, F.; Cao, C. Overcoming Catastrophic Forgetting in Graph Neural Networks with Experience Replay. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 2–9 February 2021; Volume 35, pp. 4714–4722. [Google Scholar]
- Ho, J.; Saharia, C.; Chan, W.; Fleet, D.J.; Norouzi, M.; Salimans, T. Cascaded diffusion models for high fidelity image generation. J. Mach. Learn. Res. 2022, 23, 2249–2281. [Google Scholar]
- Tang, S.; Wang, X.; Chen, H.; Guan, C.; Wu, Z.; Tang, Y.; Zhu, W. Post-training Quantization for Text-to-Image Diffusion Models with Progressive Calibration and Activation Relaxing. arXiv 2023, arXiv:2311.06322. [Google Scholar]
- Kang, M.; Zhang, R.; Barnes, C.; Paris, S.; Kwak, S.; Park, J.; Shechtman, E.; Zhu, J.-Y.; Park, T. Distilling Diffusion Models into Conditional Gans. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; pp. 428–447. [Google Scholar]
- Guo, Y.; Yuan, H.; Yang, Y.; Chen, M.; Wang, M. Gradient Guidance for Diffusion Models: An Optimization Perspective. In Advances in Neural Information Processing Systems; Neural Information Processing Systems Foundation, Inc. (NeurIPS): La Jolla, CA, USA, 2025; Volume 37, pp. 90736–90770. [Google Scholar]
- Valevski, D.; Leviathan, Y.; Arar, M.; Fruchter, S. Diffusion models are real-time game engines. arXiv 2024, arXiv:2408.14837. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Year | Architecture | Input Type | Dataset |
|---|---|---|---|---|
| SG2IM [32] | 2018 | GCN, SLN, CRN, GAN | Scene graph | Visual Genome [31], COCO-Stuff [68] |
| IIGSG [64] | 2019 | GCN, SLN, CRN | Scene graph | Visual Genome, COCO-Stuff |
| IGLO [59] | 2019 | Layout2Im | Image Layout | Visual Genome, COCO-Stuff |
| WSGC [66] | 2020 | GCN, GAN | Scene graph | Visual Genome, COCO, CLEVR |
| CALIG [40] | 2021 | GAN | Image Layout | COCO-Stuff |
| PASTEGAN [58] | 2019 | GAN | Scene graph | Visual Genome, COCO-Stuff |
| HIGTBSPS [69] | 2022 | Transformer, VAE | Scene graph | Visual Genome, COCO-Stuff |
| TBIGSG [70] | 2023 | Transformer | Scene graph | Visual Genome, COCO-Stuff |
| LOCIIG [71] | 2023 | GAN | Scene graphs | Visual Genome, COCO-Stuff |
| SCENEGENIE [72] | 2023 | Diffusion model | Scene graphs | Visual Genome, COCO-Stuff |
| SGDiff [73] | 2022 | Diffusion model | Scene graphs | Visual Genome, COCO-Stuff |
| R3CD [74] | 2024 | Diffusion Model | Scene graphs | Visual Genome, COCO-Stuff |
| Color [75] | 2021 | GCN, LRN, GAN | Scene graph | Visual Genome, COCO-Stuff |
| HSG2IM [76] | 2023 | GAN | Scene graph | Visual Genome, COCO-Stuff |
| Aspect | GANs | Diffusion Models | Graph Transformers |
|---|---|---|---|
| Architecture | Generator and discriminator [44]. | Forward and reverse diffusion [73]. | Uses self-attention mechanisms [70]. |
| Training Stability | It is often unstable and prone to mode collapse. | Generally stable due to the iterative refinement process. | Variable stability based on transformer depth [69]. |
| Image Quality | Generates high-quality images but is incosistent. | Generates detailed, high-resolution images [72]. | Captures relational data well. Detailed images. |
| Computational Cost | More efficient in terms of training time and resources [44]. | Computationally expensive due to multiple denoising steps [73]. | Varies, and large transformers can be resource-intensive. |
| Use Cases | Appropriate for real-time applications | High-quality synthesis and complex scene graphs. | Complex scene graph interaction [70]. |
| Challenges | Mode collapse and limited diversity [43]. | High computational cost makes scalability difficult [122]. | Requires careful attention design to effectively capture graph relationships [123]. |
| Dataset | Visual Genome | COCO-Stuff | CLEVR |
|---|---|---|---|
| Number of images | 108,077 | 163,957 | 100,000 |
| Training set | 62,565 | 24,972 | 70,000 |
| Validation set | 5506 | 1024 | 15,000 |
| Test set | 5088 | 2048 | 15,000 |
| Total number of classes | 178 | 172 | - |
| Things classes | - | 80 | - |
| Stuff classes | - | 91 | - |
| No. of objects in an image | 3–30 | 3–8 | - |
| Min. number of relationships between objects | 1 | 6 | - |
| Metric | Description | Strengths | Weaknesses |
|---|---|---|---|
| KID | Measures distribution distance using kernels. | Unbiased, sensitive to differences. | Requires kernel tuning, computationally intensive. |
| FID | Compares feature distributions assuming Gaussianity. | Single scalar for image quality, effective for large datasets. | Sensitive to sample size, assumes Gaussianity. |
| DS | Evaluates diversity by measuring feature variance. | Captures output variety, prevents similar images. | May not correlate with quality and variable implementation. |
| IS | Measures quality based on classification probabilities. | Encourages high quality and diversity, simple to compute. | Classifier choice can bias results, sensitive to sample size. |
| Dataset | Method | Evaluation Metrics | |||
|---|---|---|---|---|---|
| IS ↑ | FID ↓ | DS ↓ | KID ↓ | ||
| Visual Genome | SG2IM [32] | 5.5 | - | - | - |
| PasteGAN [58] | 6.9 | 58.53 | 0.24 | - | |
| WSGC [66] | 8.0 | - | - | ||
| HIGT [69] | 10.8 | 63.7 | 0.59 | - | |
| IGHSGTH [76] | 9.93 | - | - | - | |
| SceneGenie [72] | 20.25 | 42.41 | - | 8.43 | |
| R3CD [74] | 18.9 | 23.4 | - | - | |
| SGDiff [73] | 9.3 | 16.6 | - | - | |
| TBIGSG [70] | 12.8 | - | - | ||
| COCO-Stuff | SG2IM | 6.7 | - | - | - |
| PasteGAN | 9.1 | 50.94 | 0.27 | - | |
| WSGC | 5.6 | - | - | ||
| COLoR [75] | - | 95.8 | - | - | |
| HIGT | 15.2 | 51.6 | 0.63 | - | |
| IGHSGTH | 11.89 | - | - | - | |
| SceneGenie | 9.05 | 67.51 | - | 7.86 | |
| R3CD [74] | 19.5 | 32.9 | - | - | |
| SGDiff | 11.4 | 22.4 | - | - | |
| TBIGSG | 13.7 | - | - | ||
| Method | Strengths | Limitations | Applications |
|---|---|---|---|
| SG2IM [32] | Utilizes explicit structure for high-quality synthesis. | Complex training, requires detailed annotations. | Scene understanding, illustration generation. |
| PasteGAN [58] | Fine control over object appearance. | Dependent on crop quality, risk of overfitting. | Artistic image generation. |
| WSGC [66] | Robust generalization to graph complexity. | Complex setup and learning curve. | Generalized scene understanding. |
| HIGT [69] | Enhances realism with hierarchical generation. | Complexity in crop selection, computationally intensive. | High-resolution image generation. |
| IGHSGTH [76] | Advanced relationship modeling. | Increased model complexity. | Complex relational scene generation. |
| SceneGenie [72] | High-resolution imaging. | Complex inference integration. | High-fidelity image generation. |
| SGDiff [73] | Improved alignment, enhanced image quality. | Complexity in training. | Artistic applications. |
| COLoR [75] | Accurate contextualized layout generation. | Complex model architecture, high computational demand. | Context-aware image synthesis. |
| R3CD [74] | Captures local/global relational features for diverse and realistic images. | Computationally intensive, dependent on scene graph quality. | Storytelling, complex scene generation. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amuche, C.I.; Zhang, X.; Monday, H.N.; Nneji, G.U.; Ukwuoma, C.C.; Chikwendu, O.C.; Hyeon Gu, Y.; Al-antari, M.A. Advancements, Challenges, and Future Directions in Scene-Graph-Based Image Generation: A Comprehensive Review. Electronics 2025, 14, 1158. https://doi.org/10.3390/electronics14061158
Amuche CI, Zhang X, Monday HN, Nneji GU, Ukwuoma CC, Chikwendu OC, Hyeon Gu Y, Al-antari MA. Advancements, Challenges, and Future Directions in Scene-Graph-Based Image Generation: A Comprehensive Review. Electronics. 2025; 14(6):1158. https://doi.org/10.3390/electronics14061158
Chicago/Turabian StyleAmuche, Chikwendu Ijeoma, Xiaoling Zhang, Happy Nkanta Monday, Grace Ugochi Nneji, Chiagoziem C. Ukwuoma, Okechukwu Chinedum Chikwendu, Yeong Hyeon Gu, and Mugahed A. Al-antari. 2025. "Advancements, Challenges, and Future Directions in Scene-Graph-Based Image Generation: A Comprehensive Review" Electronics 14, no. 6: 1158. https://doi.org/10.3390/electronics14061158
APA StyleAmuche, C. I., Zhang, X., Monday, H. N., Nneji, G. U., Ukwuoma, C. C., Chikwendu, O. C., Hyeon Gu, Y., & Al-antari, M. A. (2025). Advancements, Challenges, and Future Directions in Scene-Graph-Based Image Generation: A Comprehensive Review. Electronics, 14(6), 1158. https://doi.org/10.3390/electronics14061158