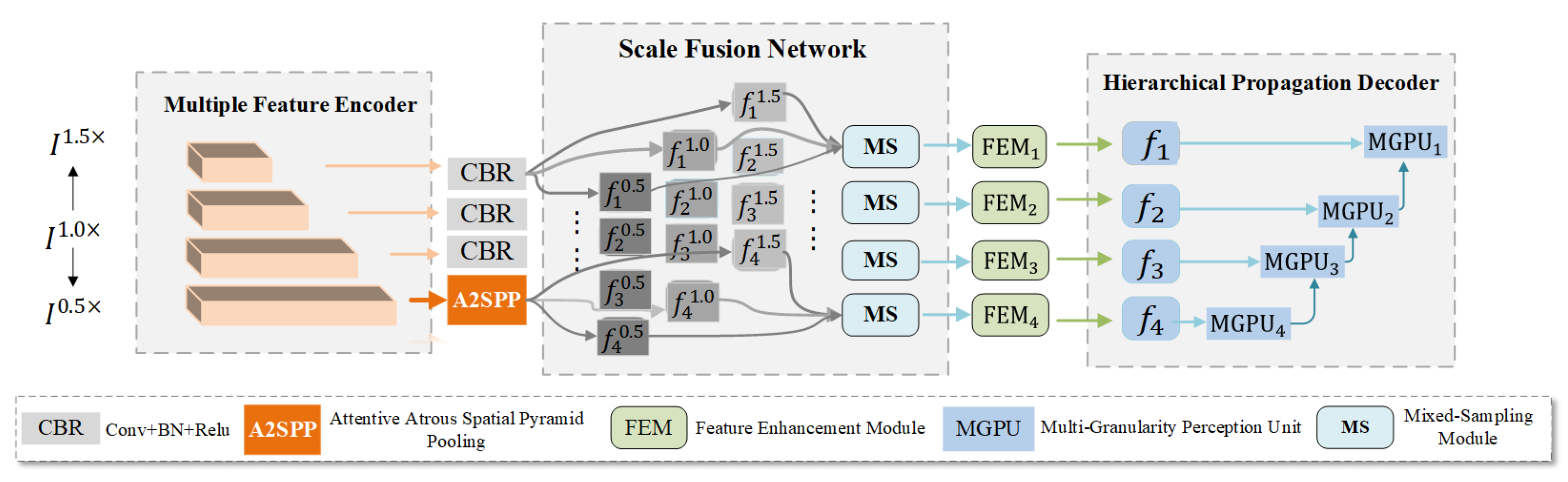
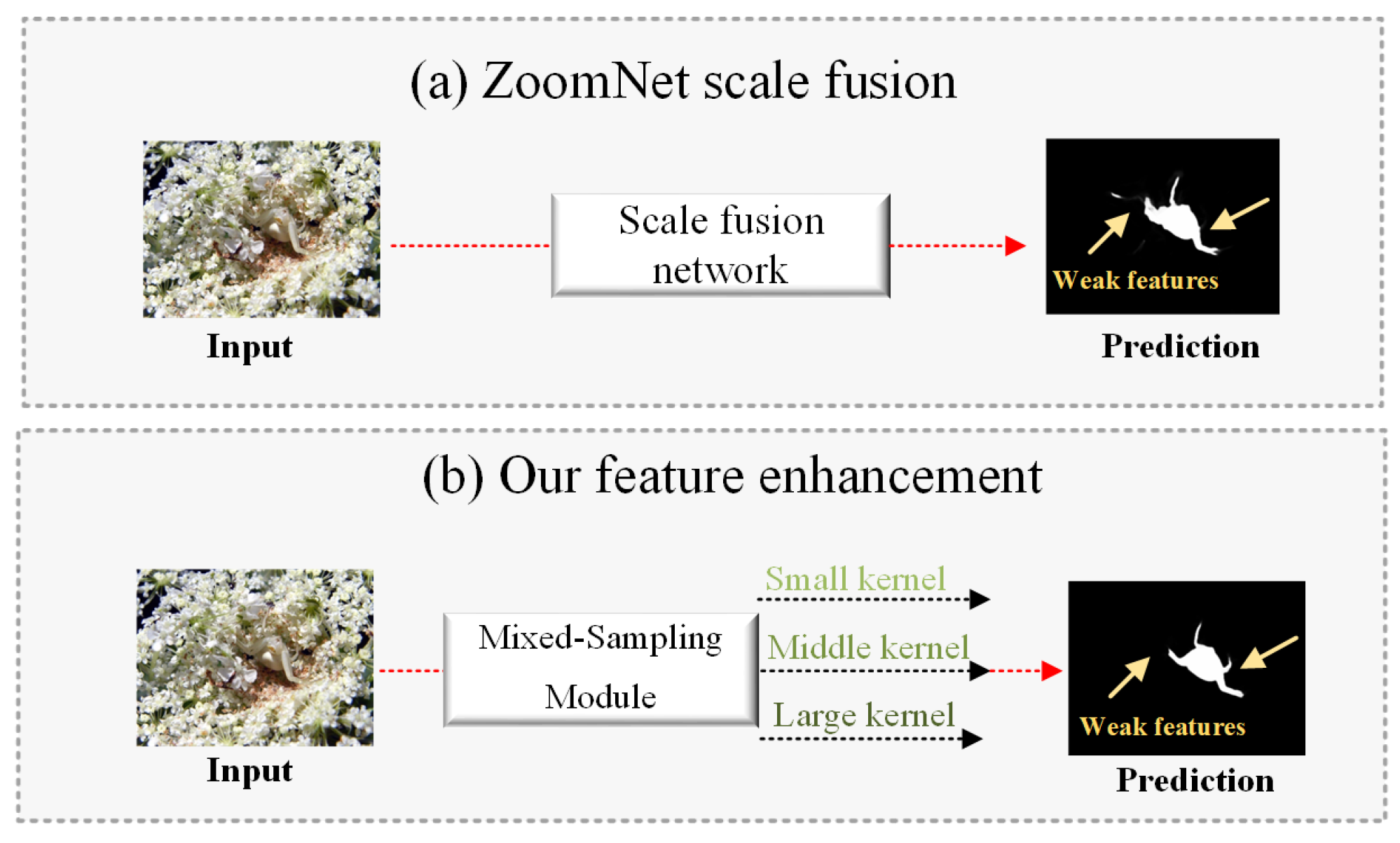
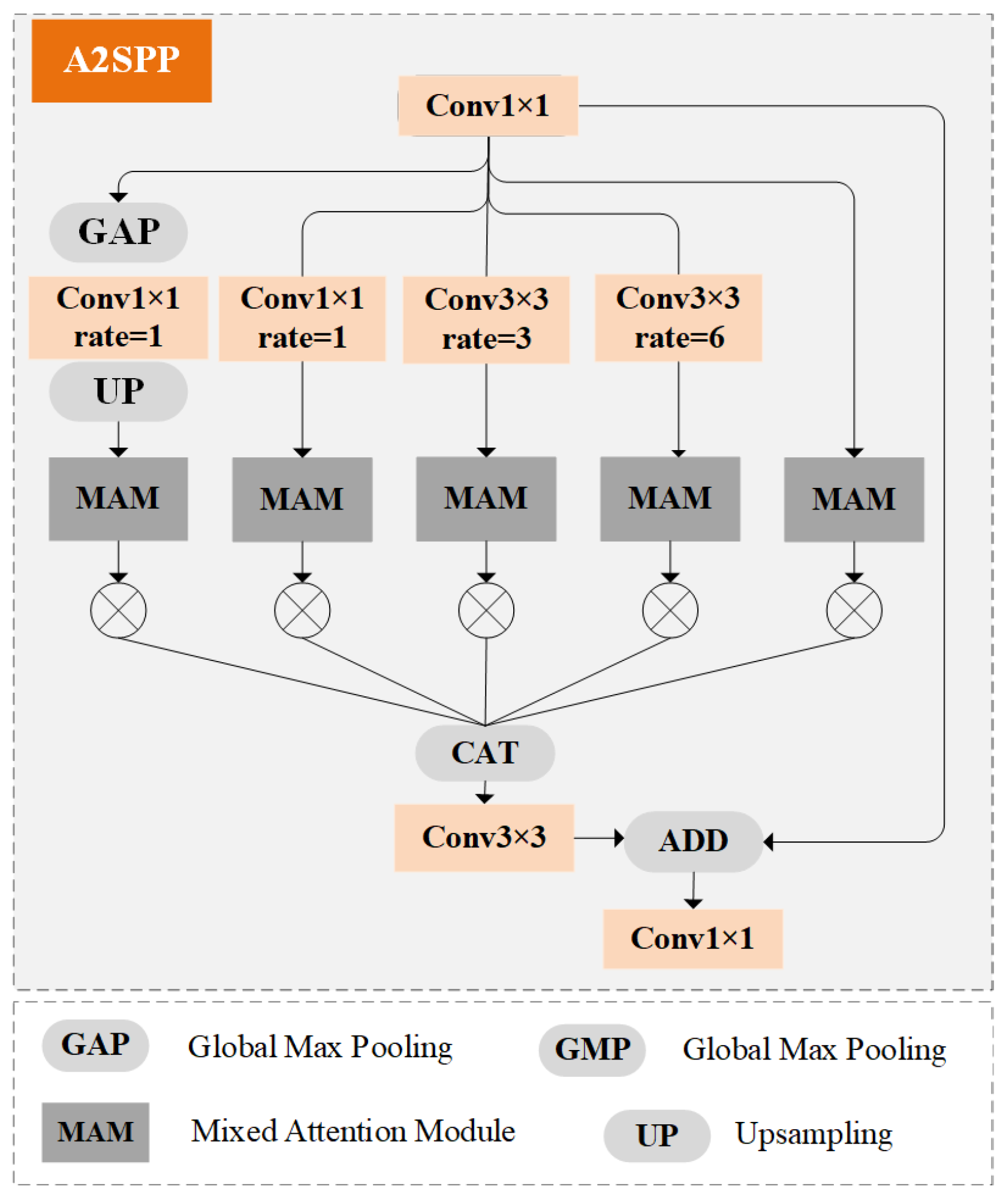
4.2. Quantitative Comparison
We conducted a comprehensive evaluation of our proposed model against ten state-of-the-art (SOTA) methods in the field, including SINet, SINetV2, PFNet [
11], DGNet [
29], BSA-Net [
30], CamoFormer [
31], BGNet [
32], FEDER, BANet, EANet [
33], CINet [
34], ZoomNet, SARNet [
4], and SDRNet [
35]. As shown in
Table 1, on the COD10K evaluation dataset, our method outperformed SDRNet (which also utilizes PVTv2 as the backbone) by 3.0%, 6.3%, 3.5%, and 0.006 for the metrics (
,
,
,
M), respectively.
To further assess the performance for small targets, we calculated the proportion of white pixels in the ground truth (GT) of the test datasets relative to the entire image. Images with less than 3% white pixels were classified as containing small targets, resulting in the creation of small-target test subsets: COD10K-small (28.8%), CAMO-small (4%), and NC4K-small (11%). On these small-target subsets, we compared our model with SDRNet. In the small subset COD10K, our model achieved improvements over SDRNet of 2.6%, 8.4%, and 3.3% in terms of , , and , respectively, while reducing the M metric by 0.007. This demonstrated the effectiveness of our approach, particularly in the challenging task of detecting small camouflaged objects.
The detection results are illustrated in
Figure 8, where our approach demonstrated a clear advantage over the other state-of-the-art (SOTA) methods in detecting both multi-scale and small targets. This superior performance highlights the robustness and adaptability of our model in handling objects of varying sizes and complexities.
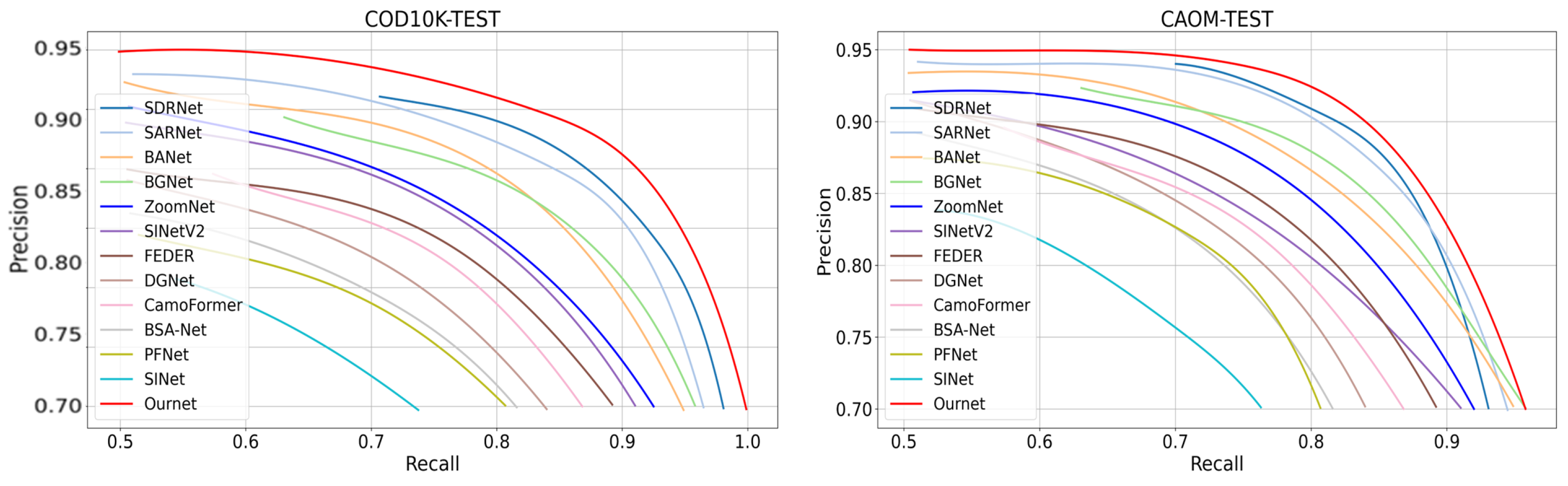
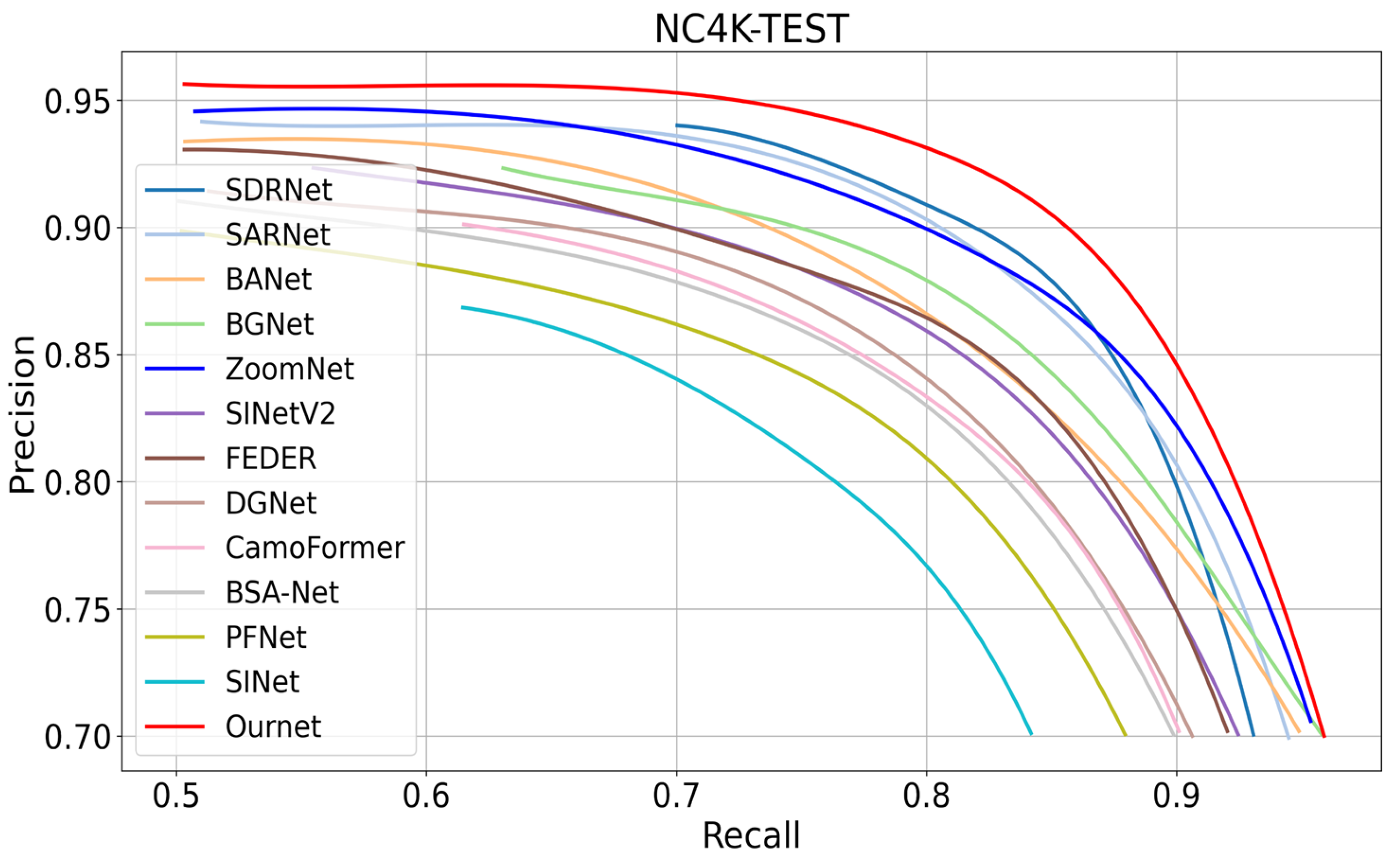
In addition to the comprehensive quantitative comparisons based on the aforementioned four evaluation metrics, we also present precision–recall (PR) curves in
Figure 9. The PR curves provide a more detailed perspective on the trade-off between precision and recall across different thresholds. As observed, our model consistently achieved a superior performance, outperforming the other camouflaged object detection (COD) methods across all levels. These results further validated the effectiveness of our proposed approach in accurately capturing camouflaged targets, particularly those that are small or exhibit multi-scale characteristics. The combination of strong quantitative metrics and favorable PR curve results underscores the significant advancements our method bring to the field of COD.
4.3. Qualitative Comparison
The detection results are presented in
Figure 8, where our proposed approach consistently demonstrated superior performance in detecting both large and small camouflaged targets. Notably, our model showed significant improvements in handling small targets, which are typically challenging to detect due to their subtle features and low contrast with the background.
Figure 8 compares the detection results of our model with those of five state-of-the-art (SOTA) camouflaged object detection (COD) methods. Visual analysis clearly shows that our model consistently achieved a more accurate and complete segmentation of the camouflaged objects, resulting in superior visual outcomes.
Large Targets (First Row): Our model effectively handled large-structure camouflaged objects and provided accurate segmentation results. In contrast, methods such as BGNet, ZoomNet, and SDRNet often exhibited segmentation inaccuracies, including missing details in boundary regions.
Small Targets (Second and Third Rows): For small-structure targets that were difficult to distinguish from the background and prone to misclassification, our model outperformed the other methods shown in the
Figure 8. It accurately localized the targets and captured fine-grained details, demonstrating robustness in detecting challenging small targets.
Heavily Occluded Targets (Fourth Row): When camouflaged objects were heavily occluded by their surroundings and had unclear boundaries due to blending with the background, our model accurately detected the objects. As shown in the figure, it effectively preserved the edge details of targets partially obscured by grass, providing more precise segmentation results compared to the other methods.
Multiple Targets (Fifth Row): Detecting multiple camouflaged objects in a single scene is particularly challenging. While some methods failed to locate all targets, our model successfully detected and segmented multiple objects, showcasing its adaptability and scalability in handling complex scenarios.
In summary, the results in
Figure 8 show that our model consistently maintained a SOTA performance under various complex and challenging conditions. In camouflaged object detection across multiple scales, complex backgrounds, and occlusions, our approach demonstrated strong robustness and adaptability. These findings highlight the effectiveness of our model in COD tasks, particularly for small object detection, detail preservation, and multi-scale detection.
4.4. Ablation Study
(a) Effectiveness of Proposed Modules
To evaluate the contributions of the various key components in the proposed model, we performed a series of ablation studies by systematically removing individual components from the full model. As shown in
Table 2, these ablation experiments were conducted on the COD10K and CAMO test datasets, to validate the effectiveness of each module.
Baseline (I): The baseline model directly used multi-scale features from the backbone and simply fused them for object recognition. While providing a basic structure, it lacked advanced mechanisms for feature enhancement and scale-specific learning.
Baseline + A2SPP (II): Building upon the baseline, the A2SPP module was introduced to guide the model in automatically selecting feature scales. This mechanism facilitated more effective multi-scale learning by dynamically adapting to the contextual needs of the input, leading to enhanced performance.
Baseline + FEM (III): This variant incorporated the FEM module into the baseline, which dynamically adjusts features from multiple receptive fields to improve the accuracy of detecting small objects. Additionally, the FEM integrates features from various hierarchical levels, thereby enhancing the model’s ability to identify targets with greater precision.
Baseline + FEM + A2SPP (IV): This configuration combined both the FEM and A2SPP modules with the baseline to leverage the complementary strengths of dynamic multi-receptive field feature adjustment and adaptive scale selection. This holistic approach maximized the model’s capability to detect camouflaged objects, particularly small and subtle ones.
The quantitative results of the ablation studies are presented in
Table 2, while the visual detection performance on small-structured objects for the four configurations (I-IV) is illustrated in
Figure 10. The results clearly demonstrate that the inclusion of the A2SPP and FEM modules significantly improved the model’s ability to detect small-structured objects. Specifically, the A2SPP module excelled in learning and adapting to multi-scale features, while the FEM module enhanced the detection of fine-grained details and minute structures. Together, these components effectively address the challenges of small object detection and camouflaged object identification, leading to substantial improvements in overall performance. These findings highlight the critical role of each module in increasing the model’s efficacy and robustness across diverse test scenarios.
(b) Mixed-sampling Input Scheme
In the scale fusion network, we downsample the high-resolution features to , aiming to produce effectively integrated and diverse multi-scale features that enhance the detection of camouflaged objects. Downsampling plays a critical role in this process, as it helps incorporate complementary feature information across different scales, ensuring a more robust representation of objects with varying sizes and complexities.
To determine the most appropriate downsampling method for the SSCOD task, we conducted a comparative analysis of several commonly used techniques, including average pooling, max pooling, bilinear interpolation, and bicubic interpolation, as shown in
Table 3. Each method was evaluated based on its ability to preserve key structural details, while effectively reducing the spatial resolution of the feature maps. From the analysis, it became clear that the HWD method, introduced earlier in our work, consistently outperformed the other approaches. This superior performance resulted from its ability to retain fine-grained details and critical boundary information, making it particularly suitable for the challenges associated with camouflaged object detection.
Consequently, the HWD method served as the default setting in our framework for the subsequent studies and experiments. By leveraging the strengths of HWD, the scale fusion network achieves a more comprehensive and detailed feature representation, significantly enhancing the overall effectiveness of the proposed approach in addressing small-structure camouflaged object detection scenarios.
(c) Validation of design choices of A2SPP
Considering the inherent limitations of ASPP, we proposed an enhanced A2SPP module that integrates an MAM into each branch of the ASPP structure. The MAM module builds upon the Convolutional Block Attention Module (CBAM) [
37] framework, incorporating a self-attention mechanism specifically within the computation of spatial attention. This enhancement allows the module to capture more nuanced spatial relationships and improve its ability to process multi-scale contextual information.
To evaluate the effectiveness of this design, we conducted a series of ablation studies by systematically modifying the MAM module. First, we removed the self-attention mechanism, reducing the MAM to a standard CBAM module. We then replaced all MAM modules in A2SPP with CBAM modules, to observe the impact on performance. Furthermore, we separately substituted the MAM with simpler attention mechanisms, such as spatial attention (SA) and channel attention (CA), to assess their relative contributions.
The experimental results, detailed in
Table 4, revealed a significant decline in performance across all scenarios. This demonstrates that the inclusion of the self-attention mechanism in the CBAM framework is crucial for the enhanced performance of the MAM. Specifically, the self-attention mechanism allows for a more effective weighting of spatial features, improving the model’s ability to capture fine-grained details and complex spatial relationships. These findings underscore the critical role of the MAM in optimizing the A2SPP module, and highlight the importance of incorporating advanced attention mechanisms for robust multi-scale feature learning.
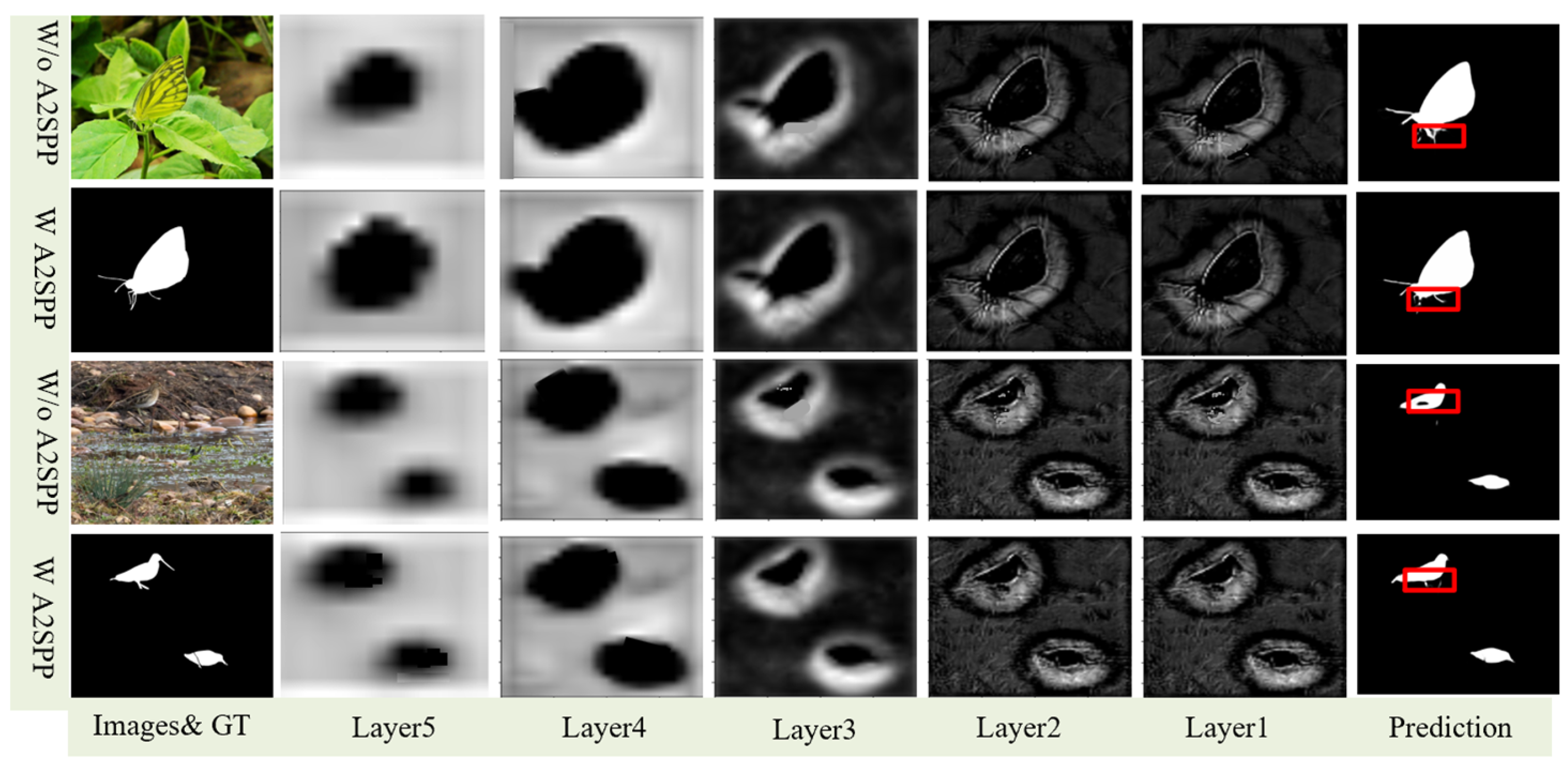
Figure 11 illustrates the intermediate feature maps at different stages of the decoder, with layers 1 to 5 representing progressively shallower levels of the decoder. We visualize and compare the intermediate feature maps across these layers to demonstrate the effectiveness of the A2SPP module. As shown in the figure, the model equipped with A2SPP exhibited superior performance in capturing fine details, such as the legs of the butterfly, compared to standard pooling methods. This highlights the enhanced capability of A2SPP for preserving small structural features during the decoding process.
4.5. Experiment on Polyp Segmentation
(1) Datasets: We evaluated our model on five benchmark datasets for polyp segmentation, including ETIS [
38], CVC-ClinicDB [
39], CVC-ColonDB [
40], and Kvasir [
41]. Specifically, the ETIS dataset consists of 196 polyp images, the CVC-ClinicDB dataset contains 612 polyp images, the CVC-ColonDB dataset includes 380 images, and the Kvasir dataset comprises 1000 images.
(2) Comparison with other SOTA Polyp Segmentation methods: The primary objective of polyp segmentation is to accurately detect polyp tissue that closely resembles the surrounding background, which plays a crucial role in the effective prevention of cancer in clinical practice. To evaluate the performance of our model in the polyp segmentation task, we validated it on four publicly available datasets: ETIS, ColonDB, ClinicDB, and Kvasir-SEG, while ensuring that all hyperparameter settings remained consistent with those used in the SSCOD task described in the main text.
We compared our model against eight state-of-the-art polyp segmentation methods, including UNet [
42], UNet++ [
43], SFA [
44], EU-Net [
45], SANet [
46], PraNet [
47], DCRNet [
48], and FDRNet [
49]. The quantitative comparison results appear in
Table 5, showing that our model achieved the best overall performance among all methods. This demonstrates its capability to effectively handle tasks that share similar challenges with SSCOD.
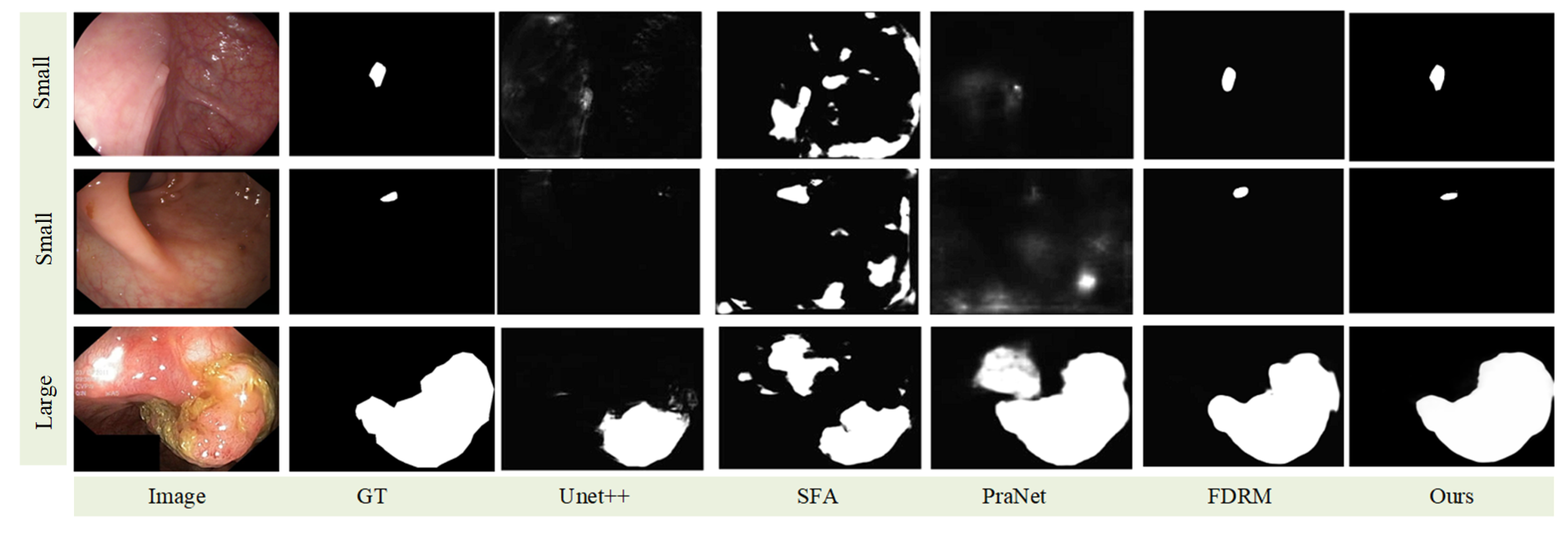
The qualitative evaluation results appear in
Figure 12. As shown in the figure, our proposed method consistently produced more accurate and complete segmentation results, while maintaining a clean background. Additionally, the first and second rows in the figure indicate that our model performed well in segmenting small-structure targets within the polyp segmentation task.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}