
Parathyroid Gland Detection Based on Multi-Scale Weighted Fusion Attention Mechanism

 , , , and
, , , and
Abstract
1. Introduction
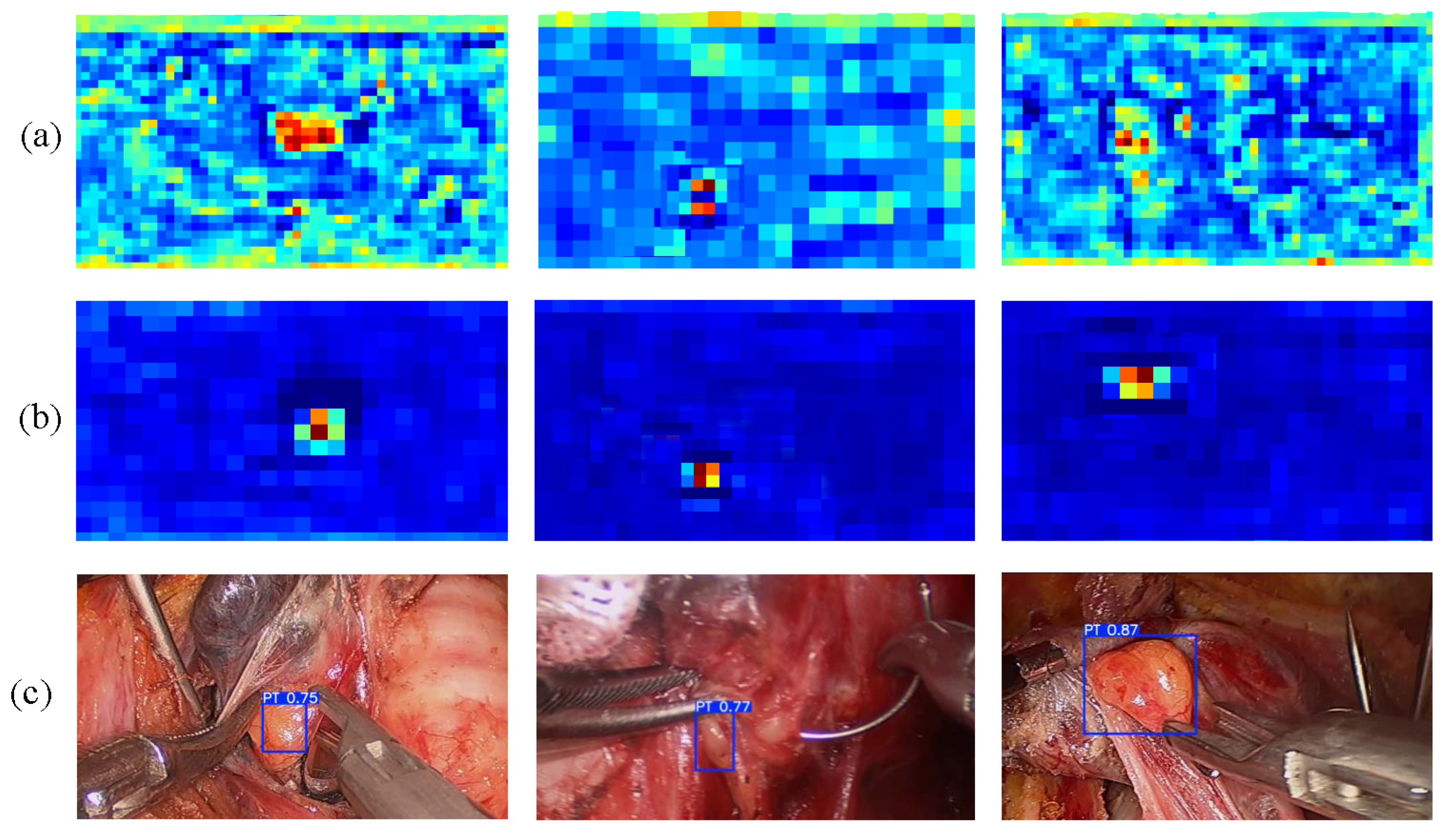
- We propose a novel end-to-end Multi-Scale Weighted Fusion Detection framework (MSWF-PGD) to enhance the accuracy and efficiency of parathyroid gland detection.
- Our approach incorporates critical multi-scale information by extracting feature maps at multiple scales, and we re-weight them using cluster-aware multi-scale alignment. These feature maps are further refined with the Non-Local Block and Multi-Scale Aggregation (NL-MSA) to provide more precise localization.
- We collected and pre-processed a dataset of 13,740 endoscopic parathyroid gland images, providing a valuable resource for future studies. Experimental results demonstrate that our framework outperforms state-of-the-art object detection methods.
2. Related Works
2.1. Object Detection
2.2. Parathyroid Gland Detection
3. Proposed Methods
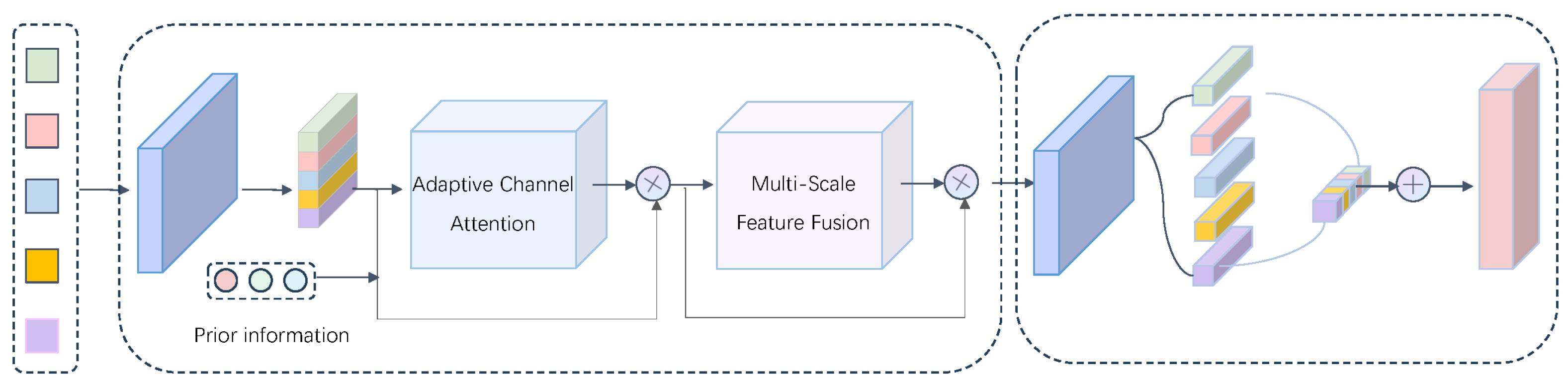
3.1. Network Architecture
3.2. Prior Feature
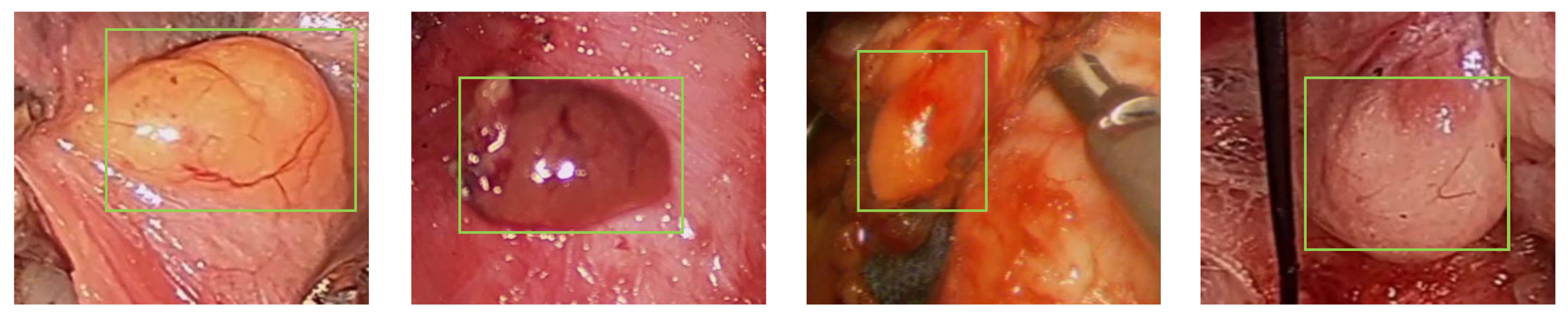
3.2.1. Size Information
3.2.2. Color Information
3.2.3. Position Information
3.3. Multi-Scale Dynamic Weighted Fusion
3.3.1. Prior Guided Scale-Aware Convolutional
3.3.2. Dynamic Weighted Fusion
3.4. Feature Contribution Adaptation Module
3.5. Loss Function
4. Experimental Results
4.1. Implementation Details
4.1.1. Experimental Environment
4.1.2. Datasets
4.2. Evaluation Metrics
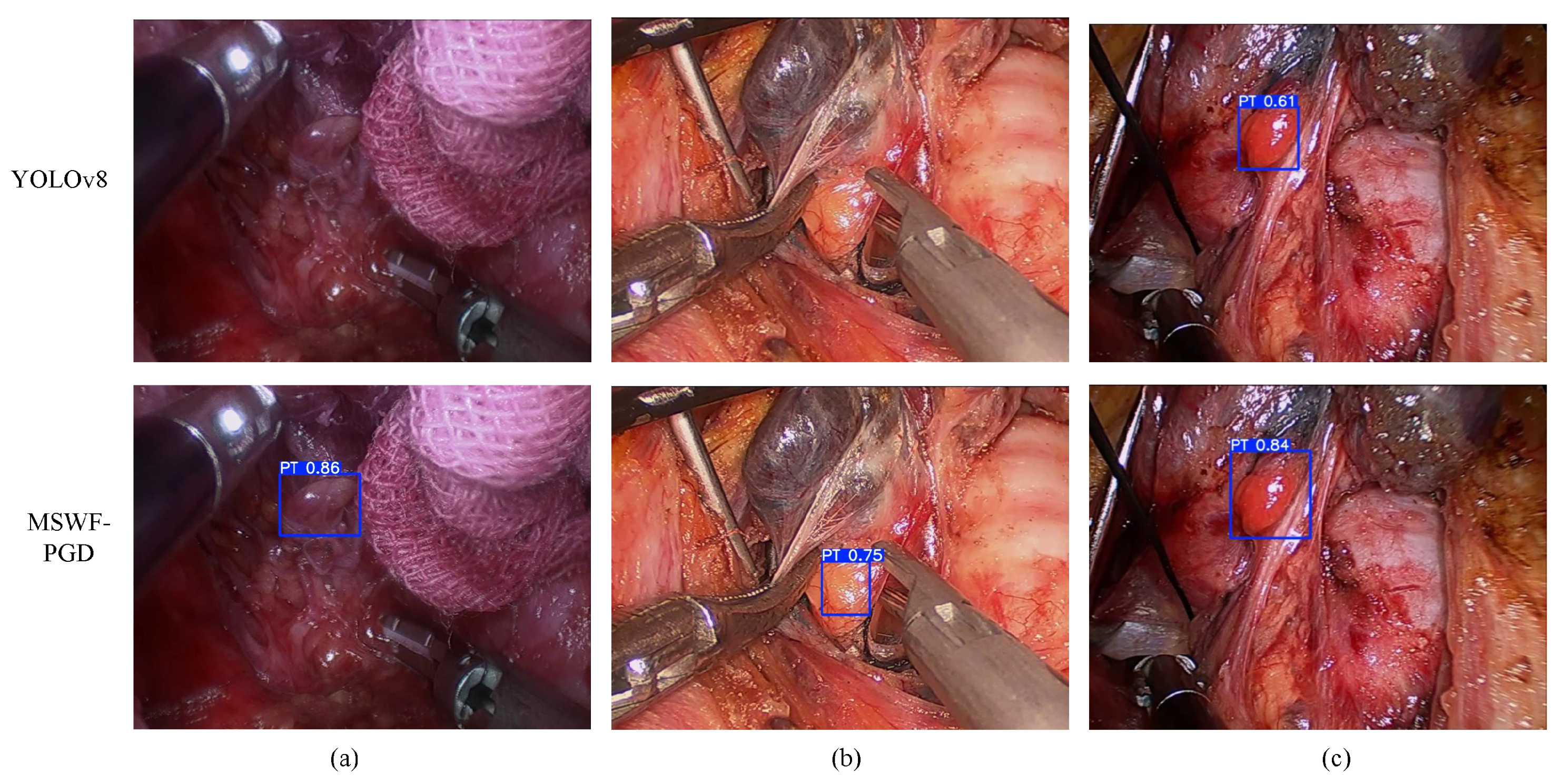
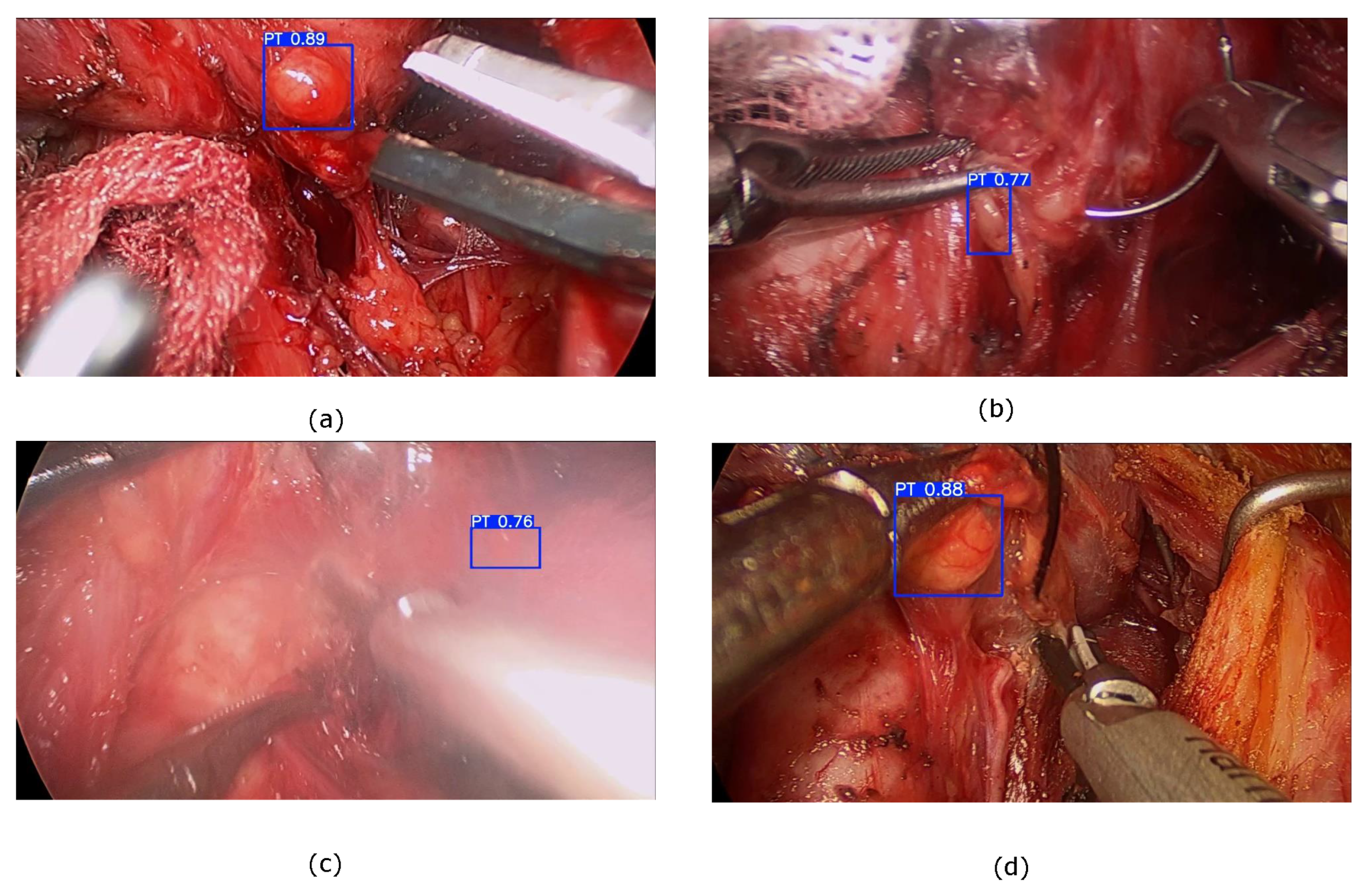
4.3. Comparative Experiments
4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Apostolopoulos, I.D.; Papandrianos, N.I.; Papageorgiou, E.I.; Apostolopoulos, D.J. Artificial Intelligence methods for identifying and localizing abnormal Parathyroid Glands: A review study. Mach. Learn. Knowl. Extr. 2022, 4, 814–826. [Google Scholar] [CrossRef]
- Liu, W.; Cai, Z.; Chen, F.; Wang, B.; Zhao, W.; Lu, W. Ellipse shape prior based anti-noise network for parathyroid detection. In Proceedings of the Fourteenth International Conference on Graphics and Image Processing (ICGIP 2022), SPIE, Nanjing, China, 21–23 October 2022; Volume 12705, pp. 897–909. [Google Scholar]
- Wang, B.; Yu, J.F.; Lin, S.Y.; Li, Y.J.; Huang, W.Y.; Yan, S.Y.; Wang, S.S.; Zhang, L.Y.; Cai, S.J.; Wu, S.B.; et al. Intraoperative AI-assisted early prediction of parathyroid and ischemia alert in endoscopic thyroid surgery. Head Neck 2024, 46, 1975–1987. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Z.; Cui, Z.; Zang, Z.; Meng, X.; Cao, Z.; Yang, J. Ultrahi-prnet: An ultra-high precision deep learning network for dense multi-scale target detection in sar images. Remote Sens. 2022, 14, 5596. [Google Scholar] [CrossRef]
- Deng, J.; Xuan, X.; Wang, W.; Li, Z.; Yao, H.; Wang, Z. A review of research on object detection based on deep learning. J. Phys. Conf. Ser. 2020, 1684, 012028. [Google Scholar] [CrossRef]
- Liang, F.; Zhou, Y.; Chen, X.; Liu, F.; Zhang, C.; Wu, X. Review of target detection technology based on deep learning. In Proceedings of the 5th International Conference on Control Engineering and Artificial Intelligence, Sanya, China, 14–16 January 2021; pp. 132–135. [Google Scholar]
- Brunetti, A.; Buongiorno, D.; Trotta, G.F.; Bevilacqua, V. Computer vision and deep learning techniques for pedestrian detection and tracking: A survey. Neurocomputing 2018, 300, 17–33. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Tian, Z.; Shen, C.; Chen, H.; He, T. FCOS: Fully Convolutional One-Stage Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Hussain, M. YOLO-v1 to YOLO-v8, the rise of YOLO and its complementary nature toward digital manufacturing and industrial defect detection. Machines 2023, 11, 677. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Yu, F.; Sang, T.; Kang, J.; Deng, X.; Guo, B.; Yang, H.; Chen, X.; Fan, Y.; Ding, X.; Wu, B. An automatic parathyroid recognition and segmentation model based on deep learning of near-infrared autofluorescence imaging. Cancer Med. 2024, 13, e7065. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Liu, W.; Lu, W.; Sun, Q.; Chen, F.; Wang, B.; Zhao, W. Real-Time Double-Layer Graph Attention Networks for Parathyroid Detection. In Proceedings of the 2024 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Lisboa, Portugal, 3–6 December 2024; pp. 1606–1610. [Google Scholar]
- Xia, B.; Hang, Y.; Tian, Y.; Yang, W.; Liao, Q.; Zhou, J. Efficient non-local contrastive attention for image super-resolution. Proc. AAAI Conf. Artif. Intell. 2022, 36, 2759–2767. [Google Scholar] [CrossRef]
- Llugsi, R.; El Yacoubi, S.; Fontaine, A.; Lupera, P. Comparison between Adam, AdaMax and Adam W optimizers to implement a Weather Forecast based on Neural Networks for the Andean city of Quito. In Proceedings of the 2021 IEEE Fifth Ecuador Technical Chapters Meeting (ETCM), Cuenca, Ecuador, 12–15 October 2021; pp. 1–6. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object Detection in 20 Years: A Survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Mahaur, B.; Mishra, K.K. Small-object detection based on YOLOv5 in autonomous driving systems. Pattern Recognit. Lett. 2023, 168, 115–122. [Google Scholar] [CrossRef]
- Ge, Z. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Khanam, R.; Hussain, M. YOLOv11: An Overview of the Key Architectural Enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | 0.5:0.95 | FPS | ||
|---|---|---|---|---|
| FCOS [12] | 80.1 | 36.2 | 40.4 | 20.75 |
| YOLOv3 [24] | 80.9 | 30.5 | 31.3 | 20.18 |
| RetinaNet [23] | 84.5 | 44.9 | 42.2 | 22.15 |
| FoveaBox [17] | 87.7 | 45.6 | 47.6 | 19.87 |
| EfficientDet [16] | 90.4 | 50.3 | 51.1 | 26.13 |
| YOLOv5 [25] | 85.7 | 47.3 | 47.9 | 21.2 |
| YOLOX [26] | 89.2 | 49.7 | 46.4 | 26.14 |
| YOLOv8 [15] | 91.3 | 56.5 | 53.2 | 26.4 |
| YOLOv11 [27] | 92.3 | 55.6 | 56.9 | 31.4 |
| Ours | 94.1 | 66.3 | 67.7 | 30.22 |
| CSPDarknet | MDWF | FCA | 0.5:0.95 | ||
|---|---|---|---|---|---|
| √ | 91.3% | 56.5% | 53.2% | ||
| √ | √ | 91.8% | 57.3% | 57.5% | |
| √ | √ | 92.9% | 58.5% | 58.8% | |
| √ | √ | √ | 94.1% | 66.3% | 67.7% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, W.; Lu, W.; Li, Y.; Chen, F.; Jiang, F.; Wei, J.; Wang, B.; Zhao, W. Parathyroid Gland Detection Based on Multi-Scale Weighted Fusion Attention Mechanism. Electronics 2025, 14, 1092. https://doi.org/10.3390/electronics14061092
Liu W, Lu W, Li Y, Chen F, Jiang F, Wei J, Wang B, Zhao W. Parathyroid Gland Detection Based on Multi-Scale Weighted Fusion Attention Mechanism. Electronics. 2025; 14(6):1092. https://doi.org/10.3390/electronics14061092
Chicago/Turabian StyleLiu, Wanling, Wenhuan Lu, Yijian Li, Fei Chen, Fan Jiang, Jianguo Wei, Bo Wang, and Wenxin Zhao. 2025. "Parathyroid Gland Detection Based on Multi-Scale Weighted Fusion Attention Mechanism" Electronics 14, no. 6: 1092. https://doi.org/10.3390/electronics14061092
APA StyleLiu, W., Lu, W., Li, Y., Chen, F., Jiang, F., Wei, J., Wang, B., & Zhao, W. (2025). Parathyroid Gland Detection Based on Multi-Scale Weighted Fusion Attention Mechanism. Electronics, 14(6), 1092. https://doi.org/10.3390/electronics14061092