
Interpretable Review Spammer Group Detection Model Based on Knowledge Distillation and Counterfactual Generation

Abstract
1. Introduction
- (1)
- We present a candidate group generation method based on graph agglomerative hierarchical clustering. In particular, we analyzed the user review information in the review dataset to generate a suspicious user review relationship graph. Meanwhile, we designed a graph agglomerative hierarchical clustering method to mine the close user relationships at a deeper level for learning candidate groups.
- (2)
- We present a knowledge distillation-based detection model (KDRSGD). In particular, we designed a graph masked autoencoder as the teacher mechanism to fully learn discriminative candidate group vector representations, helping the student mechanism better understand and learn complex group embeddings. Meanwhile, we design a simple graph autoencoder as the student mechanism to transfer knowledge from the teacher mechanism for detecting review spammer groups.
- (3)
- We proposed a counterfactual generation-based interpretation model (CFG). More specifically, we devised a counterfactual generation network consisting of a generator and a discriminator. We combined similarity masking and random masking methods to perform counterfactual operations on candidate groups by deleting or randomly adding edge relationships between user nodes and constructing a graph neural network as the generator to learn counterfactual groups. Meanwhile, we designed a discriminator to compare the distinctions between counterfactual groups and candidate groups, and mine the important subgraph structures to explain the detection results. We perform the experiments on the four datasets to compare KDCFG with the state-of-the-art detection and interpretation approaches.
2. Related Works
2.1. Review Spammer Group Detection
2.1.1. The Conventional Detection Methods
2.1.2. Deep Learning-Based Detection Methods
2.2. Approaches for Interpreting Classification Results
2.2.1. Features/Gradients-Based Approaches
2.2.2. Decomposition-Based Approaches
2.2.3. Surrogate-Based Approaches
2.2.4. Perturbation-Based Approaches
3. Problem Definition
4. Methodology
4.1. Overview
- (1)
- Discovering candidate groups. We analyze the review dataset to learn the suspicious user review relationship graph and use a binary coding approach to get user node vectors, based on which we design a graph agglomerative hierarchical clustering method to discover candidate groups with closer relationships.
- (2)
- The detection model based on knowledge distillation (KDRSGD). We design a graph masked autoencoder as a teacher mechanism to obtain the vector representations of candidate groups. Meanwhile, we design a graph autoencoder as a student mechanism to transfer the candidate group vectors from the teacher mechanism. We combine the teacher mechanism and the student mechanism to detect review spammer groups.
- (3)
- Counterfactual generation interpretation model (CFG). We design a counterfactual generation model to learn the counterfactual groups, based on which we compare the differences in detection results between candidate groups and counterfactual groups to extract the key subgraph structures for explaining the detection results.
4.2. Discovering Candidate Groups
4.2.1. Constructing the Suspicious User Review Relationship Graph
4.2.2. Finding Candidate Groups Based on Graph Agglomerative Hierarchical Clustering
| Algorithm 1. Discovering candidate groups through graph agglomerative hierarchical clustering |
| Input: review dataset number of iterations loops |
| Output: candidate groups C |
| 1 ; ; |
| 2 obtain the user feature matrix X and the suspicious user review relationship matrix A and according to Equations (3)–(6) |
| 3 for users um, un U do |
| 4 if A(um, un) = 1 then |
| 5 |
| 6 end if |
| 7 end for |
| 8 build the suspicious user review relationship graph G = (V, E, X) |
| 9 obtain the initial group set and user node similarity according to Equation (7) |
| 10 for i = 1 to loops do |
| 11 |
| 12 obtain the group similarity GS according to Equation (8) |
| 13 merge the most similar groups to generate the new groups |
| 14 end for |
| 15 |
| 16 return C |
4.3. Review Spammer Group Detection Model Based on Knowledge Distillation
4.3.1. The Construction of KDRSGD
4.3.2. Training of KDRSGD
4.3.3. Detection of Review Spammer Groups
| Algorithm 2. Review spammer group detection model |
| Input: training set Ctrain test set Ctest |
| Output: RSG |
| 1 initialize the parameters of model |
| 2 repeat |
| 3 for Ci in Ctrain do |
| 4 use a teacher mechanism to obtain the classification probability of Ci according to Equations (9)–(14) |
| 5 use a student mechanism to transfer the knowledge of the teacher mechanism according to Equations (15)–(17) |
| 6 end for |
| 7 calculate the model loss according to Equations (18)–(20) |
| 8 employ Adam to update the parameters of model |
| 9 until the model loss convergence |
| 10 RSGuse the trained model to detect review spammer groups in Ctest |
| 11 return RSG |
4.4. Counterfactual Generation Interpretation Model
4.4.1. Obtaining Counterfactual Groups
4.4.2. Interpreting the Detection Results
| Algorithm 3. Counterfactual generation interpretation model |
| Input: the test set Ctest the classification probability of test set qtest |
| Output: ISG |
| 1 |
| 2 repeat |
| 3 for each Ci in Ctest do |
| 4 learn the masked adjacency matrix of Ci through similarity mask |
| 5 construct a generator to learn the group feature of Ci with Equations (21) and (22) |
| 6 construct a discriminator to obtain the classification probability of Ci with Equation (23) |
| 7 end for |
| 8 calculate the model loss with Equations (24)–(25) |
| 9 update the counterfactual generation model with Adam |
| 10 until model loss convergence |
| 11 obtain the counterfactual groups with trained counterfactual generation model |
| 12 ISGobtain the important subgraphs as interpretation by comparing counterfactual groups and candidate groups according to Equation (26) |
| 13 return ISG |
5. Experiments
- (1)
- How does KDCFG perform in comparison with the baselines in detecting and interpreting review spammer groups?
- (2)
- How do parameters of KDCFG affect the detection and interpretation performance?
- (3)
- How do different model combinations affect the detection and interpretation performance?
5.1. Experimental Datasets
5.2. Evaluation Metrics
5.3. The Comparison of Detection Performance
- (1)
- GSCPM [4]: A clique percolation algorithm-based fraudster group detection approach, which adopts the clique percolation algorithm and the group indicators to obtain the most suspicious fraudster groups.
- (2)
- LP-RSG [5]: A label propagation-based fraudster group detection approach, which uses a designed a label propagation approach and an indicator weighted approach to detect the most suspicious fraudster groups.
- (3)
- CSGD-NE [6]: A network embedding-based collusive spammer detection approach, which utilizes K-means and Canopy approach and an indicator weighted approach to identify the most suspicious fraudster groups.
- (4)
- GSDB [40]: A review explosion-based collusive spammer detection approach, which adopts a kernel density estimation approach and indicators to identify the most suspicious fraudster groups.
- (5)
- HIN-RNN [41]: A graph neural network-based collusive spammer detection approach, which combines time interval between reviews and RNN to identify the most suspicious groups.
- (1)
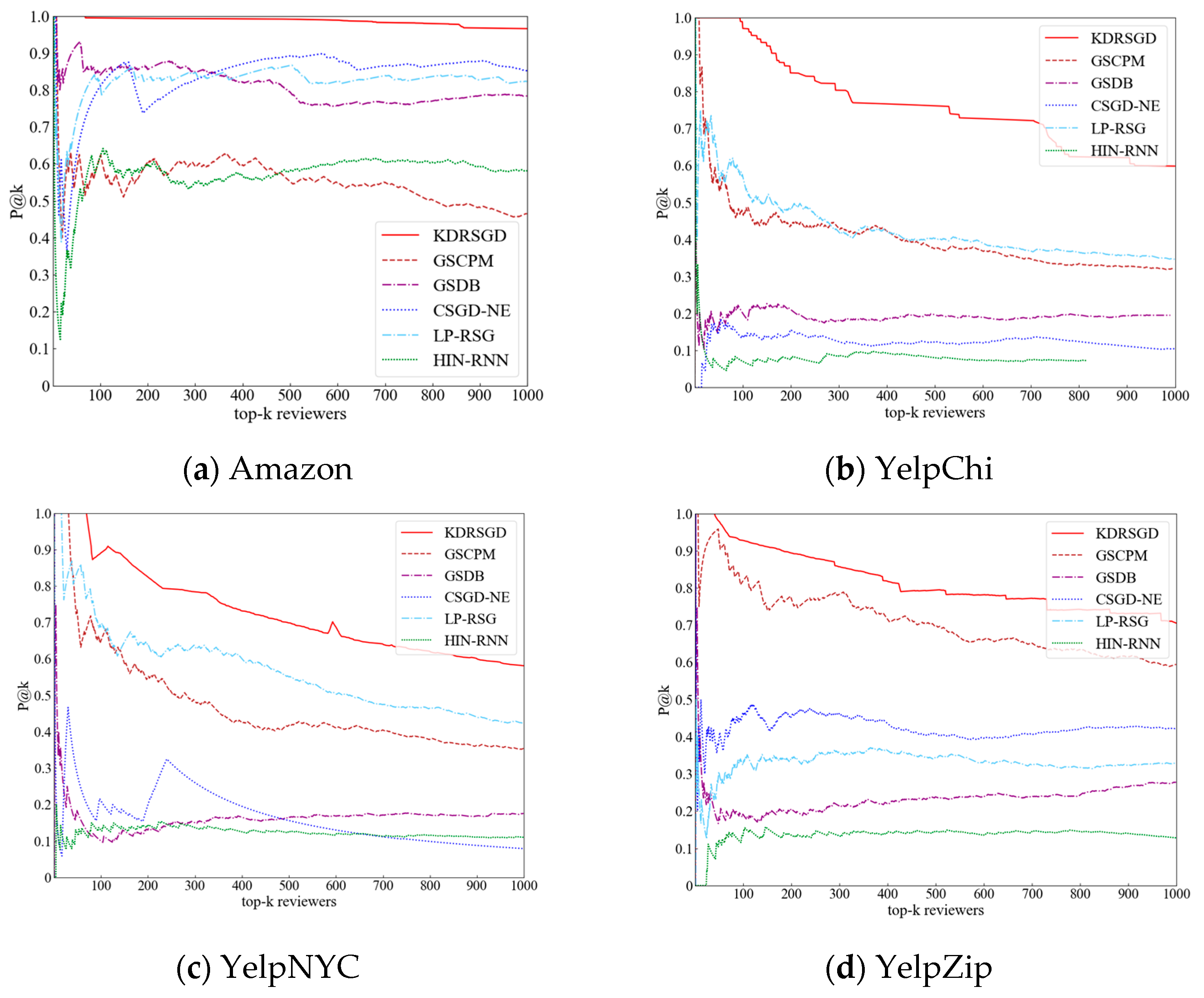
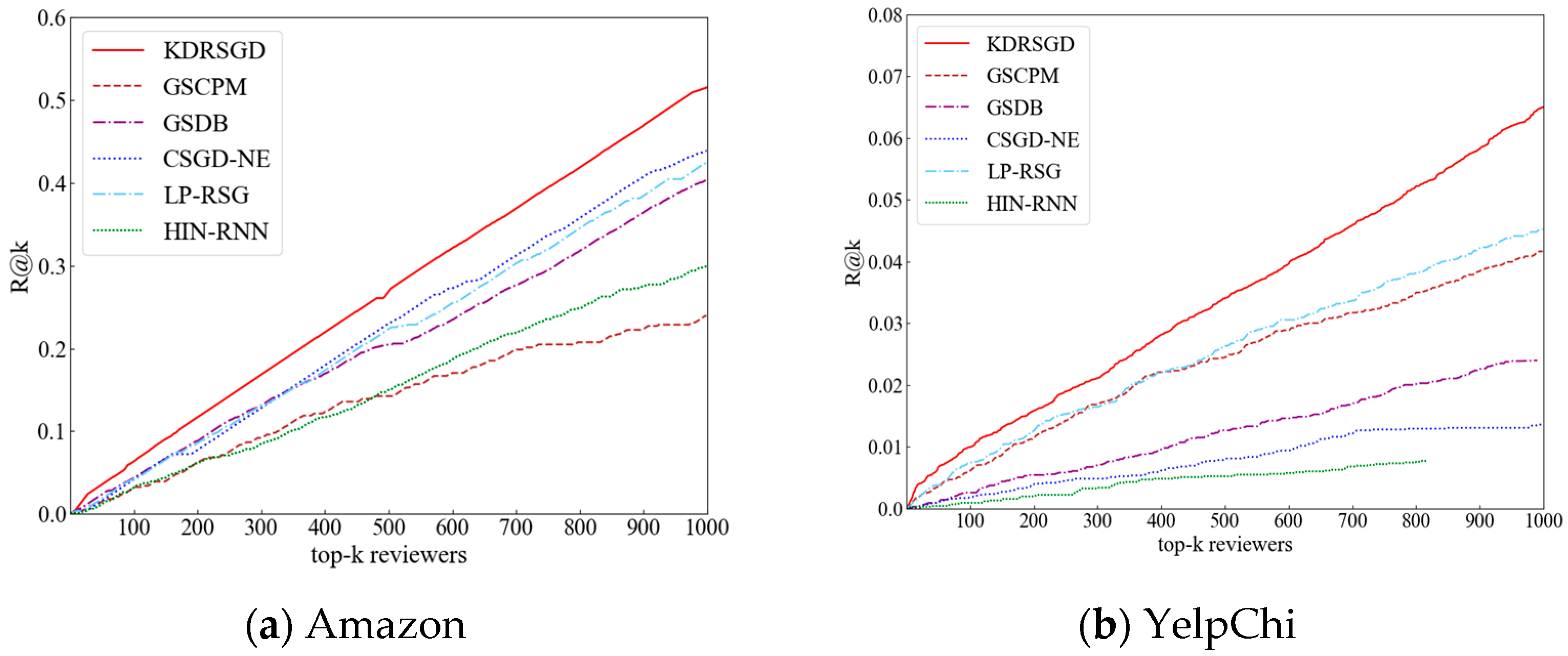
- KDRSGD outperforms the other six methods on the four datasets. KDRSGD’s P@k and R@k are improved by {13.37%, 17.34%} on Amazon, {72.63%, 43.81%} on YelpChi, {37.46%, 41.22%} on YelpNYC, and {18.83%, 21.05%} on YelpZip, respectively, being among the top-1000 when compared with state-of-the-art approaches. The reason is that KDRSGD uses a graph agglomerative hierarchical clustering method to mine candidate groups with closer relationships at a deeper level. Meanwhile, KDRSGD constructs a knowledge distillation model to learn the discriminative candidate group vector representations, thereby improving the detection performance of review spammer groups.
- (2)
- GSDB, LP-RSG, and GSCPM show different trends of change on the four datasets. LP-RSG’s P@k and R@k are {35.77%, 18.44%} on Amazon, {3.96%, 0.36%} on YelpChi, and {6.91%, 0.24%} on YelpNYC, respectively, being among the top-1000 and higher than those of GSCPM. This may be because LP-RSG adopts the indicator weighting strategy to detect more collusive review spammers, but GSCPM only uses the group indicators to detect the suspicious spammer groups. GSDB has lower detection results than GSCPM and LP-RSG on three Yelp datasets. The possible reason is that the co-reviewing relationships between users in three Yelp datasets are sparse, making it difficult for the indicators used in GSDB to accurately identify collusive user relationships.
- (3)
- HIN-RNN and CSGD-NE have poor P@k and R@k on four datasets, e.g., their P@k values remain around 0 and 0.1042—among the top-1000—on YelpChi and around 0.1283 and 0.4218—among thetop-1000—on YelpZip, respectively. CSGD-NE and HIN-RNN’s R@k reach around 0 and 0.0136—among the top-1000—on YelpChi and around 0.0028 and 0.0039—among the top-1000—on YelpNYC, respectively. The main reason is that CSGD-NE uses the indicator weighting strategy to detect review spammer groups and HIN-RNN is unable to accurately mine the collusive user relationships on the sparse datasets, resulting in poor detection effect.
5.4. The Evaluation of Interpretation Results
- (1)
- PGM-Explainer [19]: A probabilistic graphical model-based interpretation method, which deletes unimportant data in the sampled data as the filtered data and inputs it into the probabilistic graphical model for interpreting the prediction results.
- (2)
- SubgraphX [23]: An interpretation method based on subgraph exploration, which calculates the importance of different subgraphs according to Shapley values and selects important subgraphs as the interpretations of the prediction results.
- (3)
- GNNExplainer [42]: A generative interpretation method based on graph neural networks, which labels the key features of paths and utilizes a maximizing mutual information approach to interpret the prediction results.
- (4)
- CAL [43]: A graph classification interpretation method based on causal attention learning, which applies a causal attention mechanism to search the causal information for explaining the prediction results.
- (5)
- Causal-GNN [44]: An interpretation method based on causal learning, which adopts the attention network and gated graph neural network to mine some causal features for interpretation results.
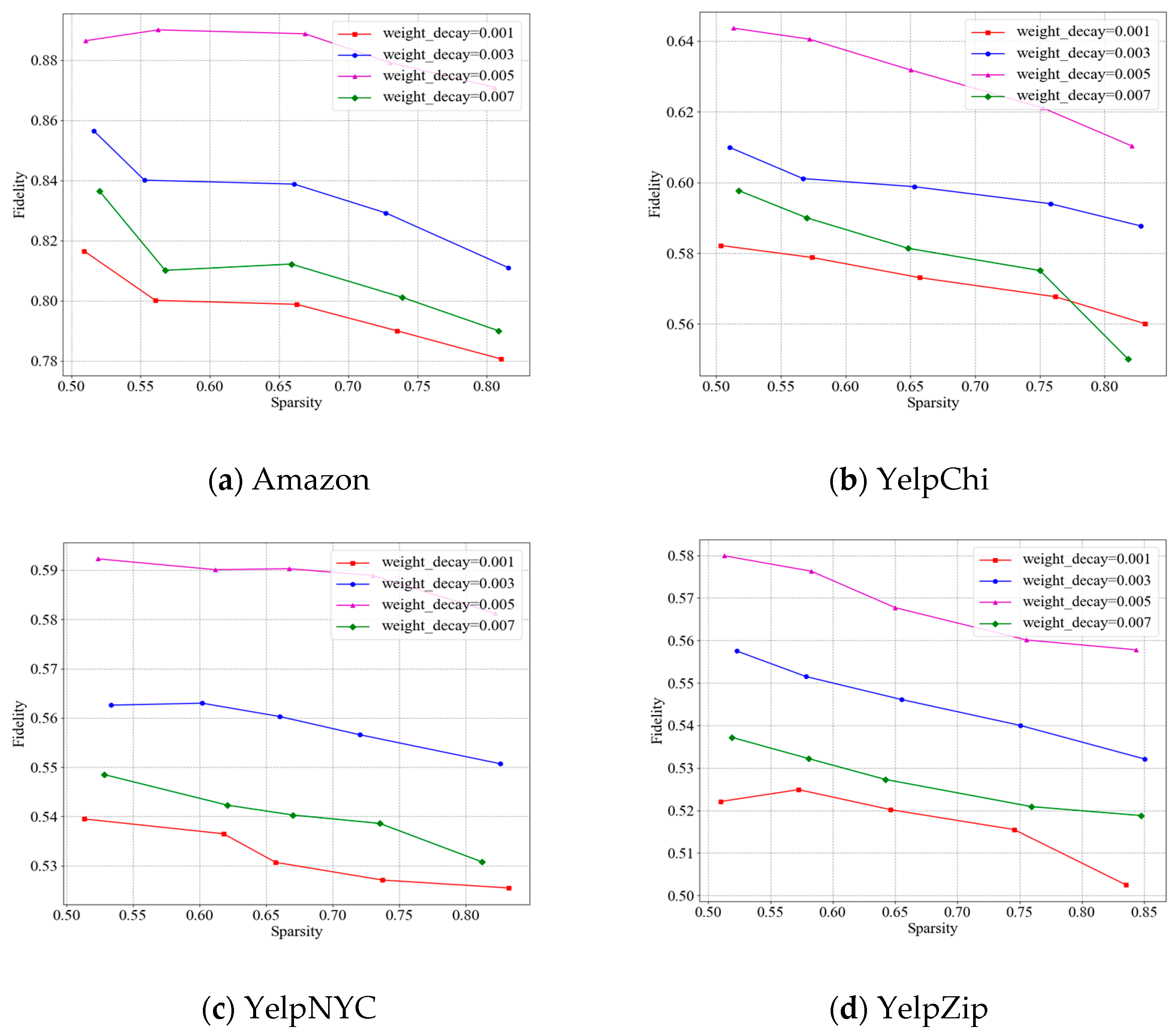
5.4.1. Comparison of Interpretation Effect on the Four Datasets
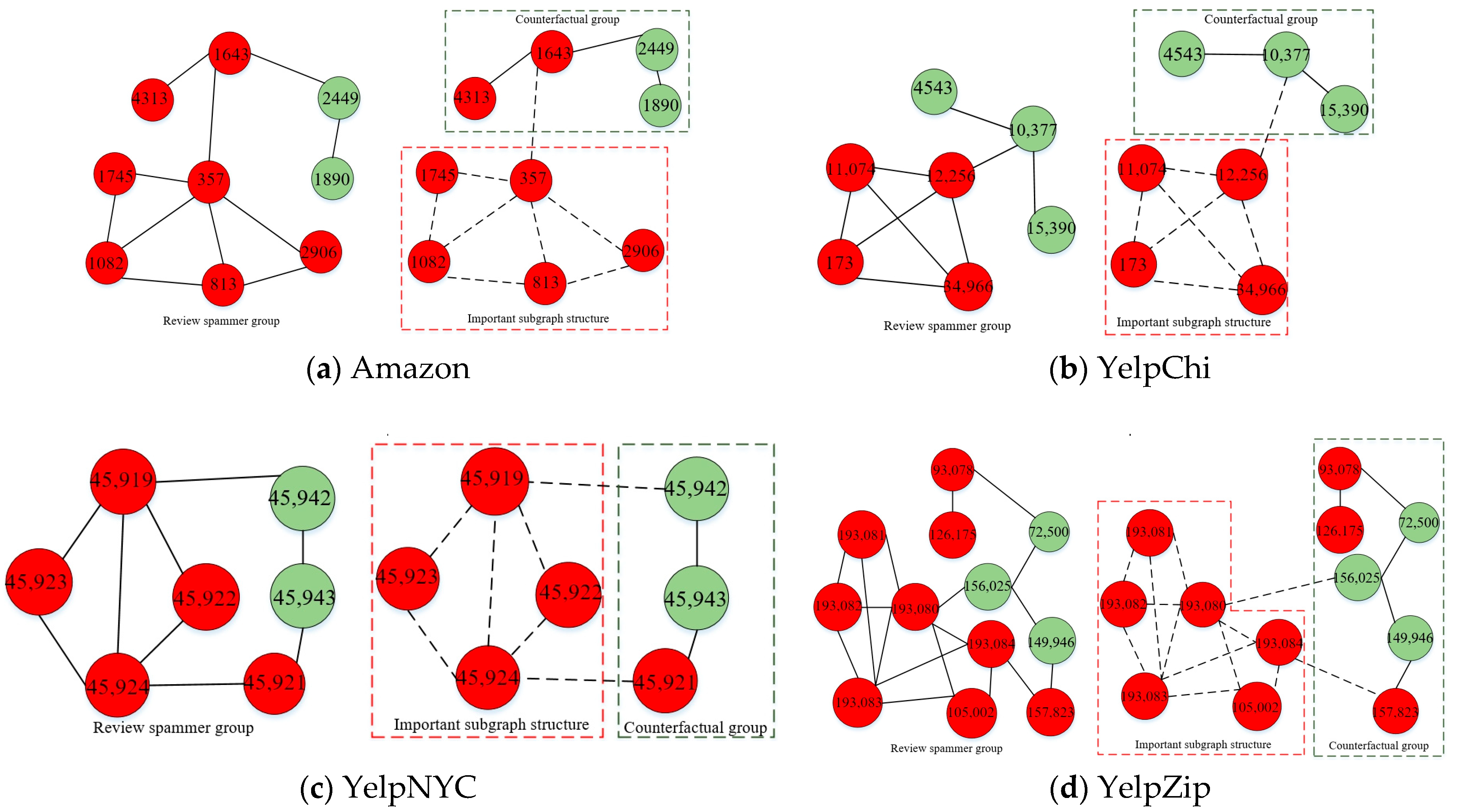
- (1)
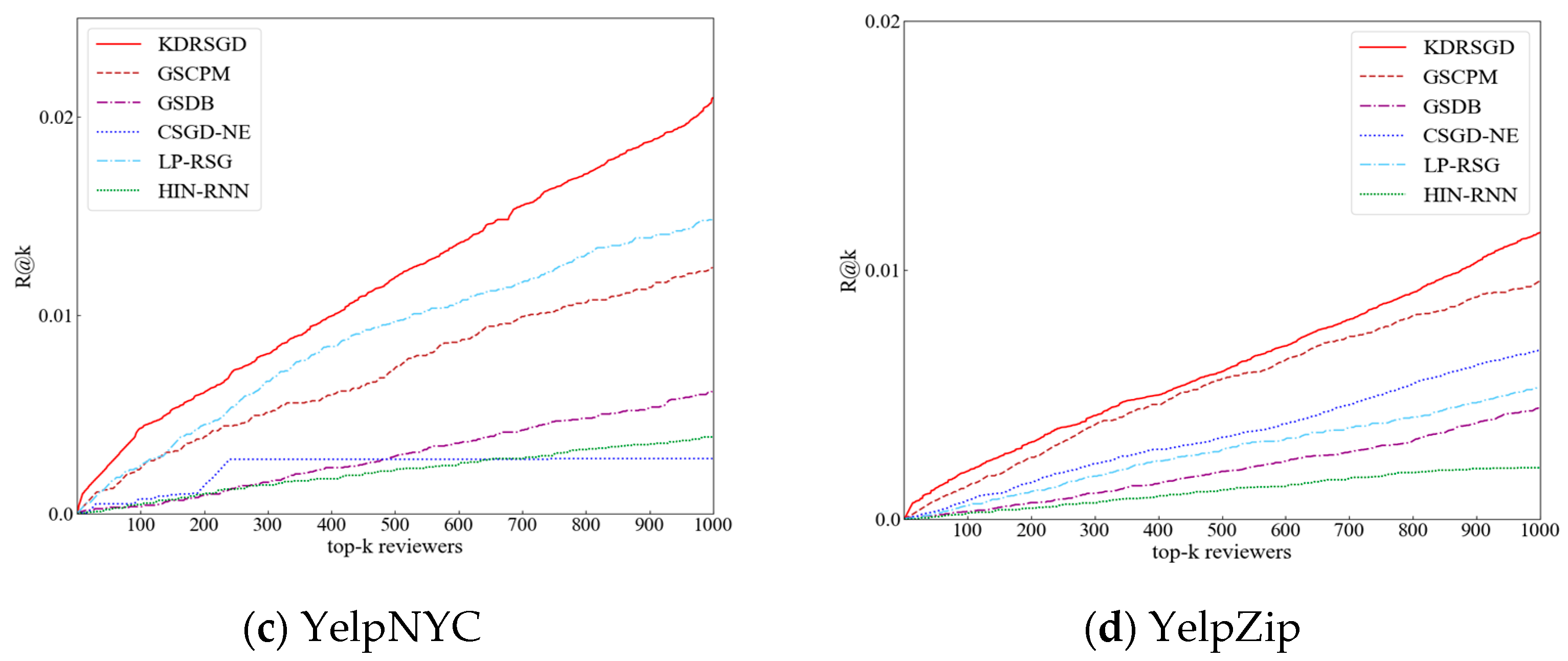
- At diverse Sparsity, CFG’s Fidelity is superior to other methods on the four datasets. CFG’s Fidelity varies around 0.88, 0.63, 0.59, and 0.56 and is around 6%, 7%, 7%, and 6% higher than that of the optimal comparison methods, respectively. The reason is that CFG uses a counterfactual generation method to obtain counterfactual groups that are completely opposite to the detection results of candidate groups, which can further compare the candidate groups and counterfactual groups to accurately mine the important subgraph structures for the interpretation of the detection results.
- (2)
- Graph neural network-based methods (i.e., PGM-Explainer, SubgraphX, and GNNExplainer) display various changing trends of Fidelity with diverse Sparsity on the four datasets. SubgraphX’s Fidelity is 6%, 9%, 11%, and 10% greater than that of PGM-Explainer with diverse Sparsity on the four datasets, respectively. This shows that mining subgraphs to search the relational local topological structures of predictions is effective for interpreting the prediction results. The Fidelity of PGM-Explainer is 7%, 12%, 19%, and 23% greater than that of GNNExplainer with diverse Sparsity on the four datasets, respectively. The reason is that PGM-Explainer uses a probabilistic graphical model to obtain the accurate interpretations. GNNExplainer has poorer interpretation performance compared with PGM-Explainer and SubgraphX. The reason is that GNNExplainer ignores the interpretation of the detection results from a global structure and loses important node information.
- (3)
- Causal learning-based methods (i.e., CAL and Causal-GNN) perform better than graph neural network-based methods. CAL’s Fidelity is 9%, 10%, and 6% greater than that of Causal-GNN with diverse Sparsity on three Yelp datasets, respectively. The reason is that CAL fully considers the structural relationships of data to search the key causal features, but Causal-GNN only mines the causal relationships between input features and prediction results.
5.4.2. The Visualization of Interpretation Results
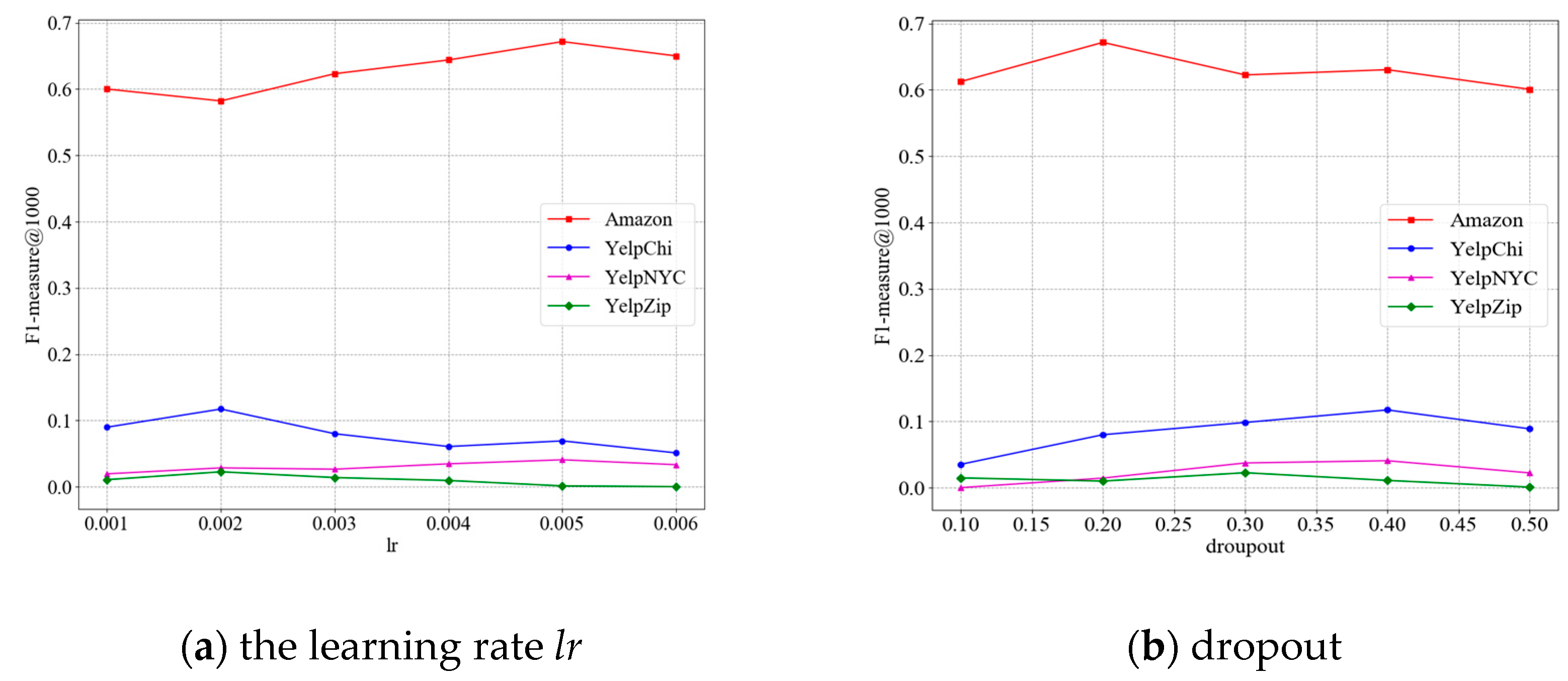
5.5. The Parameter Analysis of KDCFG
5.6. Ablation Study
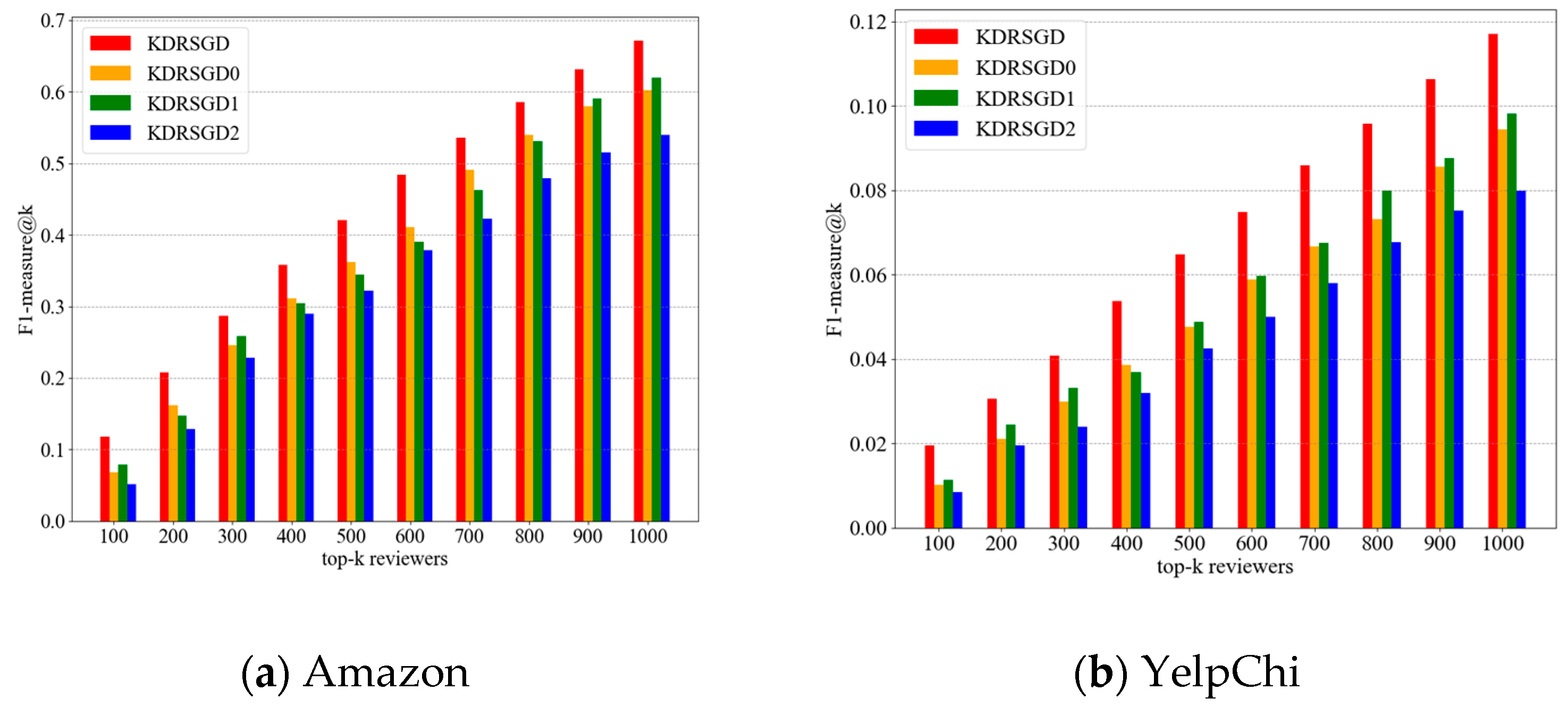
5.6.1. Ablation Study on Effect in Detection Performance
- (1)
- Aiming at the Assumption 1, we consider the user review behavior in shorter time intervals and with similar polarity ratings in the process of constructing a suspicious user review relationship graph. To test Assumption 1, we propose a variant method KDRSGD0 (i.e., NURG+DBSCAN+KD) to verify changes in detection performance without considering the user review behavior, which learn the user relationship graph with N-nearest neighbor (NURG) to replace the suspicious user review relationship graph (SURG), and use a DBSCAN algorithm to replace the graph agglomerative hierarchical clustering approach (GAHC) for discovering candidate groups. KDRSGD0 first uses NURG and DBSCAN [10] to obtain candidate groups and subsequently uses a knowledge distillation model (KD) to identify the dubious spammer groups.
- (2)
- KDRSGD1 (i.e., SURG+GAHC+Autoencoder) replaces KD with an autoencoder. KDRSGD1 first utilizes SURG and GAHC to discover candidate groups, and then uses Autoencoder [9] to detect review spammer groups.
- (3)
- KDRSGD2 (i.e., SURG+GAHC+KD0) is a variant of KDRSGD. KDRSGD2 first uses SURG and GAHC to discover candidate groups and then replaces the similarity mask method in KD with a random mask method [45] to identify the dubious spammer groups.
- (1)
- SURG and GAHC can help improve the detection performance. Compared to KDRSGD0, KDRSGD’s F1-measure@1000 is improved by 11.54% and 24.05% on two datasets, respectively. This indicates that the graph agglomerative hierarchical clustering algorithm can mine the users with closer relationships to obtain candidate groups with high quality, which helps to detect the collusive spammers more accurately.
- (2)
- KDRSGD’s detection performance exceeds the performance of KDRSGD1 and KDRSGD2. Compared to KDRSGD1, KDRSGD’s F1-measure@1000 is improved by 8.29% and 19.25% on two datasets, respectively. This is because KDRSGD uses a knowledge distillation model to fully learn discriminative candidate group vectors, which help detect the collusive spammers accurately. Compared to KDRSGD2, KDRSGD’s F1-measure@1000 is improved by 24.39% and 46.56% on two datasets, respectively. This indicates that the use of similarity masking in KDRSGD helps reduce the noise and irrelevant feature information, which improves the detection performance of KDRSGD.
5.6.2. The Ablation Study on Effect on Interpretation Performance
- (1)
- CFG0 replaces the counterfactual generative model with a Variational Autoencoder (VAE) [46]. CFG0 first uses a VAE to obtain the counterfactual groups and then compares the differences of detection results between the counterfactual groups and candidate groups to search the key subgraph structures for explaining the detection results.
- (2)
- CFG1 replaces the graph neural networks (GNNs) model in the generator with graph attention networks (GATs) [47]. CFG1 initially utilizes a counterfactual generation model that uses GAT as a generator to obtain counterfactual groups, and then compares the differences of detection results between the counterfactual groups and candidate groups to search the key subgraph structures for explaining the detection results.
- (1)
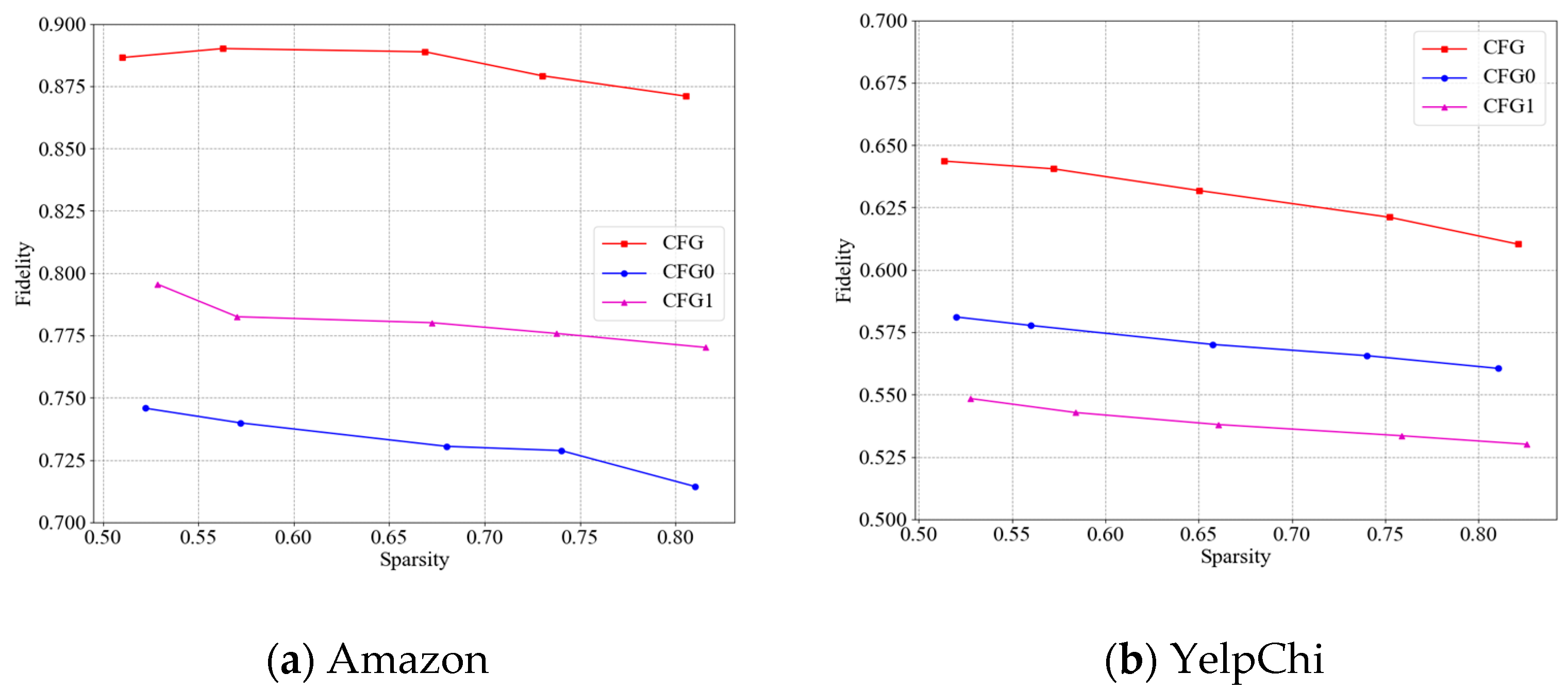
- CFG’s Fidelity is greater than that of CFG0 with diverse Sparsity on two datasets. The improvements of the Fidelity of CFG over CFG0 are around 21% on Amazon and 10% on YelpChi, respectively. This is because CFG uses a generative adversarial network as a counterfactual generation model, which can fully explore the causal relationships between candidate groups and detection results to obtain the counterfactual groups in accurately explaining the detection results.
- (2)
- CFG’s Fidelity is greater than that of CFG1 with diverse Sparsity on two datasets. The improvements of the Fidelity of CFG over CFG1 are around 13% on Amazon and 19% on YelpChi, respectively. This is because CFG uses a graph neural network as a generator, which can effectively learn and generate counterfactual groups that are completely opposite of the detection results of candidate groups, further improving the accuracy of interpretation.
5.7. Discussion
6. Conclusions and Future Work
- (1)
- We devise a graph agglomerative hierarchical clustering approach to obtain candidate groups. Our method obtains the suspicious user review relationship graph and learns the user node vector representations. A graph agglomerative hierarchical clustering method is designed to search the collusive user review relationships. The users with high similarity are continuously merged to discover candidate groups.
- (2)
- We propose an interpretable review spammer group detection method using knowledge distillation and counterfactual generation. Our method uses a knowledge distillation network consisting of a graph mask autoencoder and graph autoencoder to detect review spammer groups. Moreover, we adopt a counterfactual generation model to obtain the counterfactual groups and mine the important subgraph structures as interpretations.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Fei, G.; Mukherjee, A.; Liu, B.; Hsu, M.; Malu, C.; Riddhiman, G. Exploiting burstiness in reviews for review spammer detection. In Proceedings of the 7th International Conference on Weblogs and Social Media, Cambridge, MA, USA, 8–11 July 2013; pp. 175–184. [Google Scholar]
- Allahbakhsh, M.; Ignjatovic, A.; Benatallah, B.; Beheshti, S.; Bertino, E.; Foo, N. Collusion detection in online rating systems. Lect. Notes Comput. Sci. 2013, 7808, 196–207. [Google Scholar]
- Wang, Z.; Gu, S.; Zhao, X.; Xu, X. Graph-based review spammer group detection. Knowl. Inf. Systems. Syst. 2018, 55, 571–597. [Google Scholar] [CrossRef]
- Xu, G.; Hu, M.; Ma, C.; Daneshmand, M. GSCPM: CPM-based group spamming detection in online product reviews. In Proceedings of the 2019 IEEE International Conference on Communications, Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Zhang, F.; Hao, X.; Chao, J.; Yuan, S. Label propagation-based approach for detecting review spammer groups on e-commerce websites. Knowl Based Syst. 2020, 193, 105520. [Google Scholar] [CrossRef]
- Chao, J.; Zhao, C.; Zhang, F. Network embedding-based approach for detecting collusive spamming groups on e-commerce platforms. Secur. Commun. Networks. 2022, 2022, 4354086. [Google Scholar] [CrossRef]
- Shehnepoor, S.; Togneri, R.; Liu, W.; Bennamoun, M. Spatio-temporal graph representation learning for fraudster group detection. IEEE Trans. Neural Networks Learn. Sys. 2024, 35, 6628–6642. [Google Scholar] [CrossRef]
- Zhang, F.; Wu, J.; Zhang, P.; Ma, R.; Yu, H. Detecting collusive review spammers with heterogeneous graph attention network. Inf. Process. Manag. 2023, 60, 103282. [Google Scholar] [CrossRef]
- Zhang, F.; Yuan, S.; Wu, J.; Zhang, P.; Chao, J. Detecting collusive review spammers on e-commerce websites based on reinforcement learning and adversarial autoencoder. Expert Syst. Appl. 2022, 203, 117482. [Google Scholar] [CrossRef]
- Zhang, F.; Yuan, S.; Zhang, P.; Chao, J.; Yu, H. Detecting review spammer groups based on generative adversarial networks. Inf. Sci. 2022, 606, 819–836. [Google Scholar] [CrossRef]
- Baldassarre, F.; Azizpour, H. Explainability techniques for graph convolutional networks. In Proceedings of the 2019 Workshop on Learning and Reasoning with Graph-Structured Representations, Long Beach, CA, USA, 31 May 2019; pp. 2–4. [Google Scholar]
- Pope, P.E.; Kolouri, S.; Rostami, M.; Martin, C.E.; Hoffmann, H. Explainability methods for graph convolutional neural networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 10764–10773. [Google Scholar]
- Zheng, T.Y.; Wang, Q.; Shen, Y.; Ma, X.; Lin, X.T. High-resolution rectified gradient-based visual explanations for weakly supervised segmentation. Pattern Recognit. 2022, 129, 108724. [Google Scholar] [CrossRef]
- Zivkovic, T.; Nikolic, B.; Simic, V.; Pamucar, C.; Bacanin, N. Software defects prediction by metaheuristics tuned extreme gradient boosting and analysis based on Shapley Additive Explanations. Appl. Soft Comput. 2023, 146, 110659. [Google Scholar] [CrossRef]
- Schwarzenberg, R.; Hubner, M.; Harbecke, D.; Alt, C.; Hennig, L. Layerwise relevance visualization in convolutional text graph classifiers. In Proceedings of the EMNLP-IJCNLP 2019 Graph-Based Methods for Natural Language Processing, Hong Kong, China, 4 November 2019; pp. 58–62. [Google Scholar]
- Schnake, T.; Eberle, O.; Lederer, J.; Nakajima, S.; Schutt, K.T.; Mueller, K.R.; Montavon, G. Higher-order explanations of graph neural networks via relevant walks. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 44, 7581–7596. [Google Scholar] [CrossRef] [PubMed]
- Feng, Q.; Liu, N.; Yang, F.; Tang, R.; Du, M.; Hu, X. Degree: Decomposition based explanation for graph neural networks. In Proceedings of the ICLR 2022 10th International Conference on Learning Representations, Online, 25–29 April 2022; pp. 1–19. [Google Scholar]
- Wu, P.; Zhao, X.; Ding, M.; Zheng, Y.; Cui, L.; Huang, T. Tensor ring decomposition-based model with interpretable gradient factors regularization for tensor completion. Knowl. Based Syst. 2023, 259, 110094. [Google Scholar] [CrossRef]
- Vu, M.N.; Thai, M.T. Pgm-explainer: Probabilistic graphical model explanations for graph neural networks. Adv. Neural Inf. Process. Syst. 2020, 33, 12225–12235. [Google Scholar]
- Zhu, X.; Wang, D.; Pedrycz, W.; Li, Z. Fuzzy Rule-Based Local Surrogate Models for Black-Box Model Explanation. IEEE Trans. Fuzzy Syst. 2023, 31, 2056–2064. [Google Scholar] [CrossRef]
- Holzinger, A.; Malle, B.; Saranti, A.; Pfeifer, B. Towards multi-modal causability with graph neural networks enabling information fusion for explainable AI. Inf. Fusion. 2021, 71, 28–37. [Google Scholar] [CrossRef]
- Li, X.; Xiong, H.; Li, X.; Zhang, X.; Liu, J.; Jiang, H.; Chen, Z.; Dou, Z. G-LIME: Statistical learning for local interpretations of deep neural networks using global priors. Artif. Intell. 2023, 314, 103823. [Google Scholar] [CrossRef]
- Yuan, H.; Yu, H.; Wang, J.; Li, K.; Ji, S. On explainability of graph neural networks via subgraph explorations. In Proceedings of the International Conference on Machine Learning, Online, 18–24 July 2021; pp. 12241–12252. [Google Scholar]
- Luo, D.; Cheng, W.; Xu, D.; Yu, W.; Zong, B.; Chen, H.; Zhang, X. Parameterized explainer for graph neural network. In Proceedings of the 34th Conference on Neural Information Processing Systems, Online, 6–12 December 2020; pp. 4–8. [Google Scholar]
- Tang, C.; Cui, Q.; Li, L.; Zhou, J. GINT: A Generative Interpretability method via perturbation in the latent space. Expert Syst. Appl. 2023, 232, 120570. [Google Scholar] [CrossRef]
- Arumugam, D.; Kiran, R. Interpreting denoising autoencoders with complex perturbation approach. Pattern Recognit. 2023, 136, 109212. [Google Scholar] [CrossRef]
- Manaskasemsak, B.; Chanmakho, C.; Klainongsuang, J.; Rungsawang, A. Opinion spam detection through user behavioral graph partitioning approach. In Proceedings of the 2019 3rd International Conference on Intelligent Systems, Male, Maldives, 23–24 March 2019; pp. 73–77. [Google Scholar]
- Wang, G.; Xie, S.; Liu, B.; Yu, P.S. Review graph based online store review spammer detection. In Proceedings of the IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2019; pp. 1242–1247. [Google Scholar]
- Hang, J.; Hong, Z.; Feng, X.; Wang, G.; Yang, G.; Li, F.; Song, X.; Zhang, D. Paths2pair: Meta-path based link prediction in billion-scale commercial heterogeneous graphs. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Barcelona, Spain, 25–29 August 2024; pp. 5082–5092. [Google Scholar]
- Kim, J.; Park, J.; Low, C.Y.; Teoh, A.B.J. Cancellable biometrics based on the index-of-maximum hashing with random sparse binary encoding. Multimed. Tools Appl. 2024, 83, 59915–59942. [Google Scholar] [CrossRef]
- Hafeezallah, A.; Al-Dhamari, A.; Abu-Bakar, S.A.R. Motion segmentation using Ward’s hierarchical agglomerative clustering for crowd disaster risk mitigation. Int. J. Disast. Risk Reduct. 2024, 102, 104262. [Google Scholar] [CrossRef]
- Hou, Z.Y.; Liu, X.; Cen, Y.K.; Dong, Y.X.; Yang, H.X.; Wang, C.J.; Tang, J. GraphMAE: Self-Supervised Masked Graph Autoencoders. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 594–604. [Google Scholar]
- Chen, X.; Ding, M.; Wang, X.; Xin, Y.; Mo, S.; Wang, Y.; Han, S.; Luo, P.; Zeng, G.; Wang, J. Context autoencoder for self-supervised representation learning. Int. J. Comput. Vis. 2024, 132, 208–223. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–5. [Google Scholar]
- Xu, C.; Zhang, J.; Long, C.; Chang, K. Uncovering collusive review spammers in Chinese review websites. In Proceedings of the 22nd ACM International Conference on Conference on Information & Knowledge Management, San Francisco, CA, USA, 27 October–1 November 2013; pp. 979–988. [Google Scholar]
- Mukherjee, A.; Venkataraman, V.; Liu, B.; Glance, N. What yelp fake review filter might be doing? In Proceedings of the 7th International Conference on Weblogs and Social Media, Cambridge, MA, USA, 8–11 July 2013; pp. 409–418. [Google Scholar]
- Rayana, S.; Akoglu, L. Collective opinion spam detection: Bridging review networks and metadata. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 985–994. [Google Scholar]
- Zhang, Y.; Tan, Y.; Zhang, M.; Liu, L.; Tal-Sang, C.; Ma, S. Catch the black sheep: Unified framework for shilling attack detection based on fraudulent action propagation. In Proceedings of the 24th International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 2408–2414. [Google Scholar]
- Yuan, H.; Yu, H.Y.; Gui, S.R.; Ji, S.W. Explainability in graph neural networks: A taxonomic survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 5782–5799. [Google Scholar] [CrossRef] [PubMed]
- Ji, S.; Zhang, Q.; Li, J.; Chiu, D.K.W.; Xu, S.; Yi, L.; Gong, M. A burst-based unsupervised method for detecting review spammer groups. Inf. Sci. 2020, 536, 454–469. [Google Scholar] [CrossRef]
- Shehnepoor, S.; Togneri, R.; Liu, W.; Bennamoun, M. HIN-RNN: A graph representation learning neural network for fraudster group detection with no handcrafted features. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 4153–4166. [Google Scholar] [CrossRef]
- Ying, Z.; Bourgeois, D.; You, J.; Zitnik, M.; Leskovec, J. GNNExplainer: Generating explanations for graph neural networks. In Proceedings of the 33rd Annual Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 9244–9255. [Google Scholar]
- Sui, Y.; Wang, X.; Wu, J.; Lin, M.; He, X.; Chua, T. Causal attention for interpretable and generalizable graph classification. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 1696–1705. [Google Scholar]
- Zhai, P.Y.; Yang, Y.W.; Zhang, C.J. Causality based CTR prediction using graph neural networks. Inf. Process. Manag. 2023, 60, 103137. [Google Scholar] [CrossRef]
- Shi, Y.; Dong, Y.; Tan, Q.; Li, J.; Liu, N. GiGaMAE: Generalizable graph masked autoencoder via collaborative latent space reconstruction. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, Birmingham, UK, 21–25 October 2023; pp. 2259–2269. [Google Scholar]
- Akkem, Y.; Biswas, S.K.; Varanasi, A. A comprehensive review of synthetic data generation in smart farming by using variational autoencoder and generative adversarial network. Eng. Appl. Artif. Intell. 2024, 131, 107881. [Google Scholar] [CrossRef]
- Huang, P.; Guo, J.; Liu, S.; Corman, F. Explainable train delay propagation: A graph attention network approach. Transp. Res. Part E Logist. Transp. Rev. 2024, 184, 103457. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Aspect of Differences | Existing Methods | Our Proposed Method |
|---|---|---|
| Prior knowledge | The conventional methods need prior knowledge to detect review spammer groups | Our proposed method constructs a deep learning-based model to detect review spammer groups, avoiding the use of prior knowledge |
| Extract handcraft indicators | The conventional methods rely on handcraft indicators to detect spammer groups | Our proposed method designs a knowledge distillation network and does not require extracting handcraft indicators |
| Discriminability of candidate group features | The existing methods for detecting review spammer groups use max or mean methods to obtain group features, ignoring the discriminative power of group features | Our proposed method designs a graph masked autoencoder as the teacher mechanism to learn the discriminative candidate group features |
| Interpretability of detection model | Most deep learning-based detection methods are deficient in providing an interpretation for their detection results | Our proposed method designs a counterfactual generation model to interpret the detection results |
| The influence of noise features during the explanation process | Most interpretation methods are easily affected by noise features and graph structures. | KDCFG employs a counterfactual generation method to explain the detection results, which can mitigate the influence of interfering features on explanation performance |
| Interpreting graph data without fixed structures | Existing interpretation methods aim at the interpretation of image, text, and molecular graph classifications, which are not suitable for interpreting review spammer groups without fixed structure | Our proposed method designs a counterfactual generation model to interpret review spammer groups without fixed structure |
| Notations | Descriptions |
|---|---|
| G | Suspicious user review relationship graph |
| P, U, E, V | Product set, user set, edge set, user node set |
| A | The suspicious user review relationship matrix |
| X | User feature matrix |
| S | Similarity matrix |
| Masked feature matrix | |
| Masked adjacency matrix | |
| of teacher mechanism | |
| of student mechanism | |
| The classification probability of candidate group Ci | |
| Ctrain, Ctest | Training set and test set of candidate groups |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huo, C.; Luo, Y.; Chao, J.; Zhang, F. Interpretable Review Spammer Group Detection Model Based on Knowledge Distillation and Counterfactual Generation. Electronics 2025, 14, 1086. https://doi.org/10.3390/electronics14061086
Huo C, Luo Y, Chao J, Zhang F. Interpretable Review Spammer Group Detection Model Based on Knowledge Distillation and Counterfactual Generation. Electronics. 2025; 14(6):1086. https://doi.org/10.3390/electronics14061086
Chicago/Turabian StyleHuo, Chenghang, Yunfei Luo, Jinbo Chao, and Fuzhi Zhang. 2025. "Interpretable Review Spammer Group Detection Model Based on Knowledge Distillation and Counterfactual Generation" Electronics 14, no. 6: 1086. https://doi.org/10.3390/electronics14061086
APA StyleHuo, C., Luo, Y., Chao, J., & Zhang, F. (2025). Interpretable Review Spammer Group Detection Model Based on Knowledge Distillation and Counterfactual Generation. Electronics, 14(6), 1086. https://doi.org/10.3390/electronics14061086