1. Introduction
Phishing attacks pose a critical cybersecurity threat, targeting individuals and organizations by imitating the design and structure of benign webpages to deceive users and steal sensitive information [
1,
2,
3]. These attacks exploit similarities between phishing and benign webpages, making detection increasingly challenging [
4]. For example, phishing webpages often mimic benign ones by replicating layout, input fields, and logos, creating significant ambiguity in the feature space. This overlap increases the likelihood of false positives and false negatives in detection systems and complicates the development of robust detection models [
5,
6,
7,
8].
The key challenge in phishing detection lies in resolving the systematic ambiguity caused by overlapping features. Phishing webpages are intentionally crafted to resemble benign ones, blurring the boundary in the representation space. Existing methods often struggle with these overlaps and the scalability required for large and diverse datasets. This study addresses these challenges by introducing a framework to disentangle overlapping features of phishing and benign data while maintaining high scalability [
9,
10].
The proposed method makes two key contributions. First, it integrates multimodal features from URLs and HTML DOM structures. URLs reveal lexical patterns such as typosquatting and obfuscation that are commonly used in phishing. Meanwhile, HTML DOM graphs offer structural insights into the relationships between webpage elements. Combining these modalities creates a comprehensive representation of webpages, capturing subtle distinctions between phishing and benign samples [
11,
12,
13]. This approach effectively addresses feature overlaps that hinder existing methods.
Table 1 presents examples of phishing and benign URLs used in this study, illustrating the challenge of distinguishing between the two cases. The URLs exhibit various obfuscation techniques that phishing attackers use to deceive users.
Second, the study leverages reinforcement learning to optimize the sampling process for anchor-positive-negative triplets within a triplet network. Traditional sampling methods often overlook challenging samples, resulting in suboptimal feature learning. By contrast, the proposed reinforcement learning framework dynamically identifies and selects the most ambiguous and adversarial samples during training. This approach enhances the triplet network’s capacity to construct a disentangled representation space, allowing it to distinguish phishing from benign data, even when features significantly overlap.
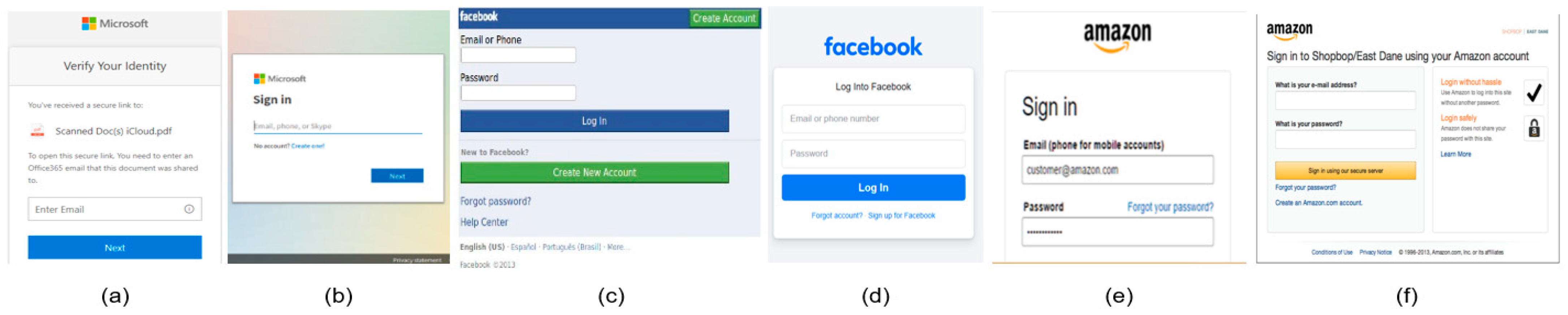
Figure 1 illustrates examples of phishing and benign webpages. Phishing cases (a, c, e) are crafted to closely resemble benign webpages (b, d, f), often replicating visual features such as logos and form fields to deceive users. However, a detailed examination of the URL structures reveals discrepancies that serve as indicators of malicious intent. The proposed method capitalizes on these discrepancies through multimodal feature integration and optimized sampling strategies, thereby enhancing the detection of phishing attempts with increased robustness and reliability. This study evaluates the proposed method using a dataset of over one million samples, encompassing both phishing and benign webpages. The experimental results indicate notable improvements across key classification metrics, including accuracy, precision, recall, and F1 score, outperforming current state-of-the-art methodologies. By addressing the key shortcomings of conventional approaches and integrating multimodal features with reinforcement learning, this framework marks a significant step forward in phishing detection research.
The remainder of this paper is structured as follows.
Section 2 reviews related work and outlines the study’s motivations.
Section 3 elaborates on the proposed method, emphasizing reinforcement learning for triplet sampling and multimodal feature integration.
Section 4 discusses experimental results, including confusion matrix analysis, t-SNE visualizations, and the effect of varying positive and negative sampling configurations. Finally,
Section 5 concludes with key findings and future research directions.
2. Related Works
Phishing detection remains highly challenging due to evolving attack strategies and the complexity of online fraud. Early heuristic-based methods, relying on handcrafted features, often struggled against sophisticated phishing tactics. Deep learning has significantly improved detection by leveraging URLs, HTML structures, and visual cues, but feature disentanglement and scalability remain key issues. Many existing approaches fail to effectively separate phishing from benign webpages, leading to frequent misclassifications.
Table 2 provides a summary of key contributions in phishing detection research, highlighting different methodologies, data representations, datasets, and performance metrics. This section reviews existing methods, their limitations, and how our approach effectively addresses these challenges.
Y. Zhang et al. [
15] introduced a content-based method for phishing detection by analyzing web page textual content, generating TF-IDF-based lexical signatures, and leveraging Google search for domain name comparisons. S. Sheng et al. [
16] evaluated phishing blacklists and highlighted their limited initial detection accuracy (<20% within the first hour). They also proposed faster updates combined with heuristic integration for enhanced early detection. E. Medvet et al. [
17] utilized visual similarity by analyzing text attributes, embedded images, and overall page layout, achieving high accuracy with minimal false positives. M. He et al. [
18] integrated identity extraction and SVM classification, achieving a 97.33% true positive rate with a low false positive rate of 1.45% by combining content and structural analysis.
To address the limitations of traditional methods, researchers turned to deep learning, enabling automated feature extraction and enhanced adaptability to evolving phishing tactics. H. Le et al. [
19] proposed a malicious URL detection approach using character-level and word-level CNNs to learn URL representations, addressing challenges such as manual feature engineering and unseen word generalization. J. Feng et al. [
11] employed a hybrid CNN-BiLSTM network with attention mechanisms to extract multidimensional features from URLs, page content, and DOM structures. F. Tajaddodianfar et al. [
20] introduced a model that integrates character-level and word-level embeddings with parallel convolutional layers. This model improved the true positive rate by 126.7% compared to traditional methods while maintaining a 0.01% false positive rate. S. Ariyadasa et al. [
12] utilized Long-term Recurrent Convolutional Networks (LRCNs) and Graph Convolutional Networks (GCNs) to autonomously extract features. Their model achieved 96.42% accuracy and excelled in zero-day phishing detection with an average detection time of 1.8 s. C. Opara et al. [
13] developed an end-to-end deep learning model utilizing raw URLs and HTML content, achieving 98.1% accuracy while minimizing reliance on manual feature engineering. A. Maci et al. [
21] proposed a cost-sensitive deep reinforcement learning approach to phishing detection by leveraging a Cost-Sensitive Deep Double Q-Network (DDQN). Traditional machine learning and deep learning models often suffer from imbalanced datasets, where phishing webpages constitute a smaller proportion of the total dataset, leading to biased learning. To mitigate this issue, the authors employed a cost-sensitive strategy to dynamically adjust the learning process based on classification costs. Their model operates on numerical URL features and optimizes detection by penalizing the misclassification of phishing URLs more heavily than benign ones. This approach allows the model to focus on minimizing false negatives while maintaining an acceptable false positive rate. The study demonstrated a true positive rate (TPR) of 96% and a false positive rate (FPR) of 8%, showcasing its potential in handling class imbalance and improving phishing detection efficiency.
Despite significant advances, challenges still remain. Traditional methods relying on handcrafted features struggle with scalability, adaptability, and generalization, while deep learning approaches still face issues in effectively separating overlapping features between phishing and benign webpages. However, phishing detection still faces challenges, particularly in handling adversarial attacks and generalizing across domains. Many deep learning models rely on large labeled datasets, which are costly and may not generalize well to new phishing techniques. Additionally, feature entanglement remains an issue, as phishing and benign webpages share structural similarities, complicating classification. Future research should explore stronger feature disentanglement, self-supervised learning, and adaptive models that evolve with phishing trends. To address these problems, we propose a Reinforced Disentangled HTML Representation Learning framework with Hard-sample Mining. Our method leverages multi-modal features from URL characters and HTML DOM graphs, using reinforcement learning to dynamically optimize the sampling of challenging examples and improve feature separation.
3. Proposed Method
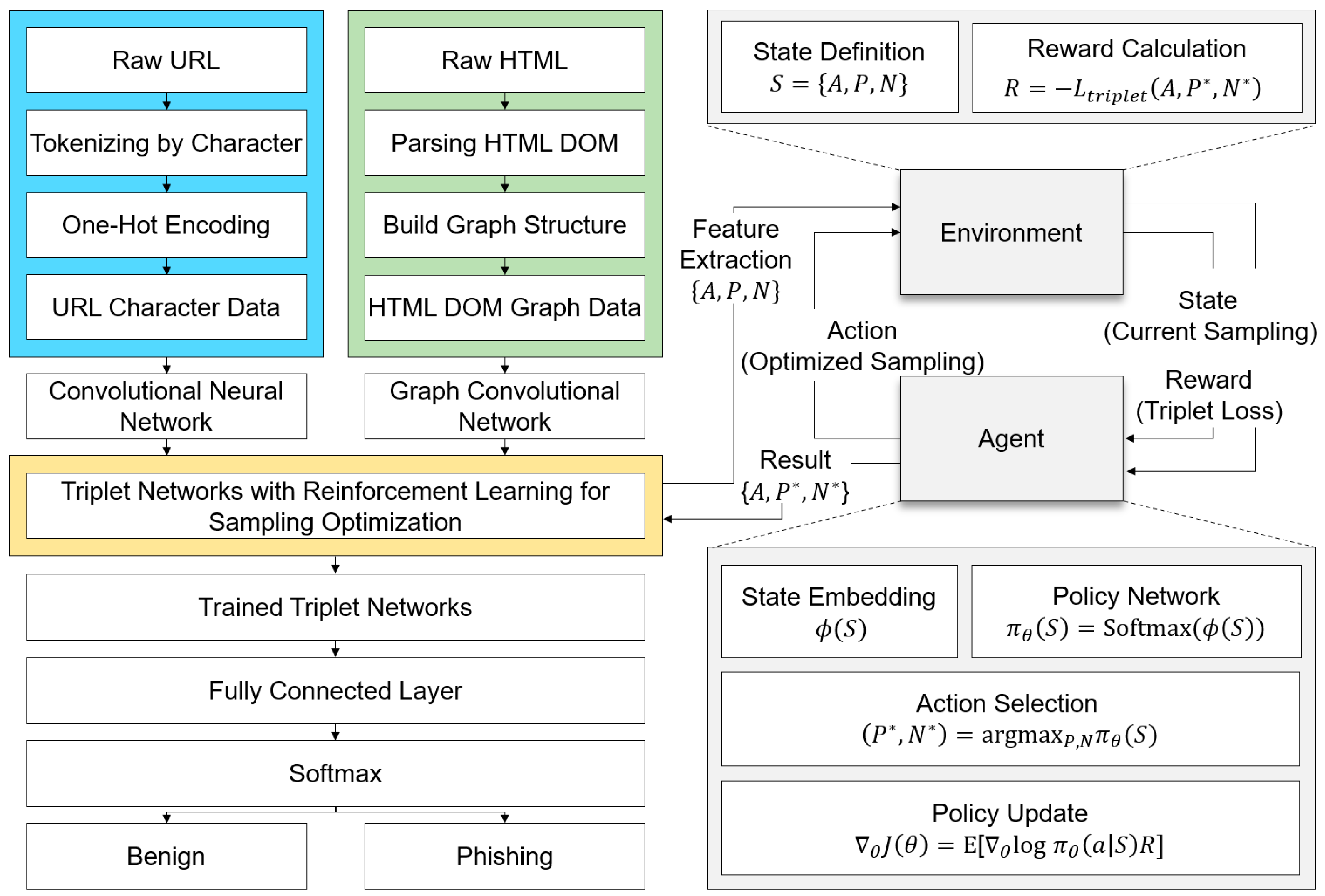
In this section, we present our phishing detection method, designed to construct a disentangled representation space for distinguishing phishing and benign webpages. It leverages reinforcement learning to optimize triplet sampling in Triplet Network training while integrating multimodal features from URLs and HTML DOM graphs to enhance representation quality. By dynamically selecting challenging samples, the approach effectively separates ambiguous features. Furthermore, combining URL lexical patterns with structural DOM graph information enables the model to capture subtle but critical distinctions, even in cases of significant feature overlap. The workflow of the proposed method is illustrated in
Figure 2.
3.1. Overview of the Proposed Method
Phishing detection presents unique challenges due to the deliberate mimicry of benign webpages by malicious actors. This mimicry creates systematic ambiguity in the feature space, where phishing and benign webpages share overlapping structural and textual patterns. To address this issue, the proposed method constructs a disentangled representation space to better separate these overlapping features. This is achieved through two complementary strategies: reinforcement learning-based triplet sampling and multimodal feature integration.
The first strategy employs reinforcement learning to optimize the selection of anchor-positive-negative triplets, which are crucial for training the Triplet Network. Traditional sampling techniques often fail to focus on challenging samples, resulting in suboptimal feature learning. By leveraging a reinforcement learning-based policy network, the proposed method dynamically identifies and selects hard positive and negative samples that maximize the discriminative capability of the Triplet Network. This approach refines the representation space by exposing the model to ambiguous and adversarial samples, thereby improving its ability to distinguish between phishing and benign data.
The second strategy integrates multimodal features derived from URLs and HTML DOM graphs. URL data capture lexical patterns, such as character sequences and substrings, that may indicate phishing attempts. Meanwhile, HTML DOM graphs provide structural information about webpage layouts and elements. By combining these two modalities, the method creates a comprehensive representation of each webpage.Together, these strategies form a unified framework that directly addresses the systematic ambiguity in phishing detection. The proposed method mitigates the impact of overlapping features by leveraging reinforcement learning for triplet sampling and multimodal feature representations. This integration enables the framework to effectively capture subtle distinctions in phishing-related patterns.
3.2. Hard-Triplet Sampling Based on Reinforcement Learning
A significant challenge in phishing detection arises from the intentional mimicry between phishing and benign webpages, which creates ambiguity in the feature space. To address this, the proposed method employs reinforcement learning to optimize the selection of anchor-positive-negative (A, P, N) triplets. This approach focuses on identifying hard samples that contribute the most to improving the Triplet Network’s ability to disentangle phishing from benign data. The reinforcement learning framework models the triplet sampling process as an interaction between an environment and an agent. The environment generates candidate triplets, while the policy network (agent) selects the optimal positive and negative samples for a given anchor. Each triplet consists of embeddings for an anchor, a positive (same class), and a negative (different class). These embeddings are processed by the policy network, which computes logits and selects the samples that maximize the discriminative capacity of the learned representation space. The triplet loss function, which forms the basis of the reward, is defined as:
where
represents the embedding function, and
is the margin that enforces a minimum separation between positive and negative pairs.
The reward for the policy network is calculated as the negative of the triplet loss. The reward function for the RL agent is derived from the triplet loss, defined as:
where
and
are the positive and negative samples selected by the policy network. This reward function encourages the policy network to select triplets that maximize the separation between phishing and benign representations in the learned feature space.
The policy network is trained using a policy loss defined as:
where
is the probability distribution over the candidate triplets, as predicted by the policy network with parameters
, and
represents the current triplet state. This iterative process dynamically improves the sampling strategy, ensuring that hard samples are prioritized during training.
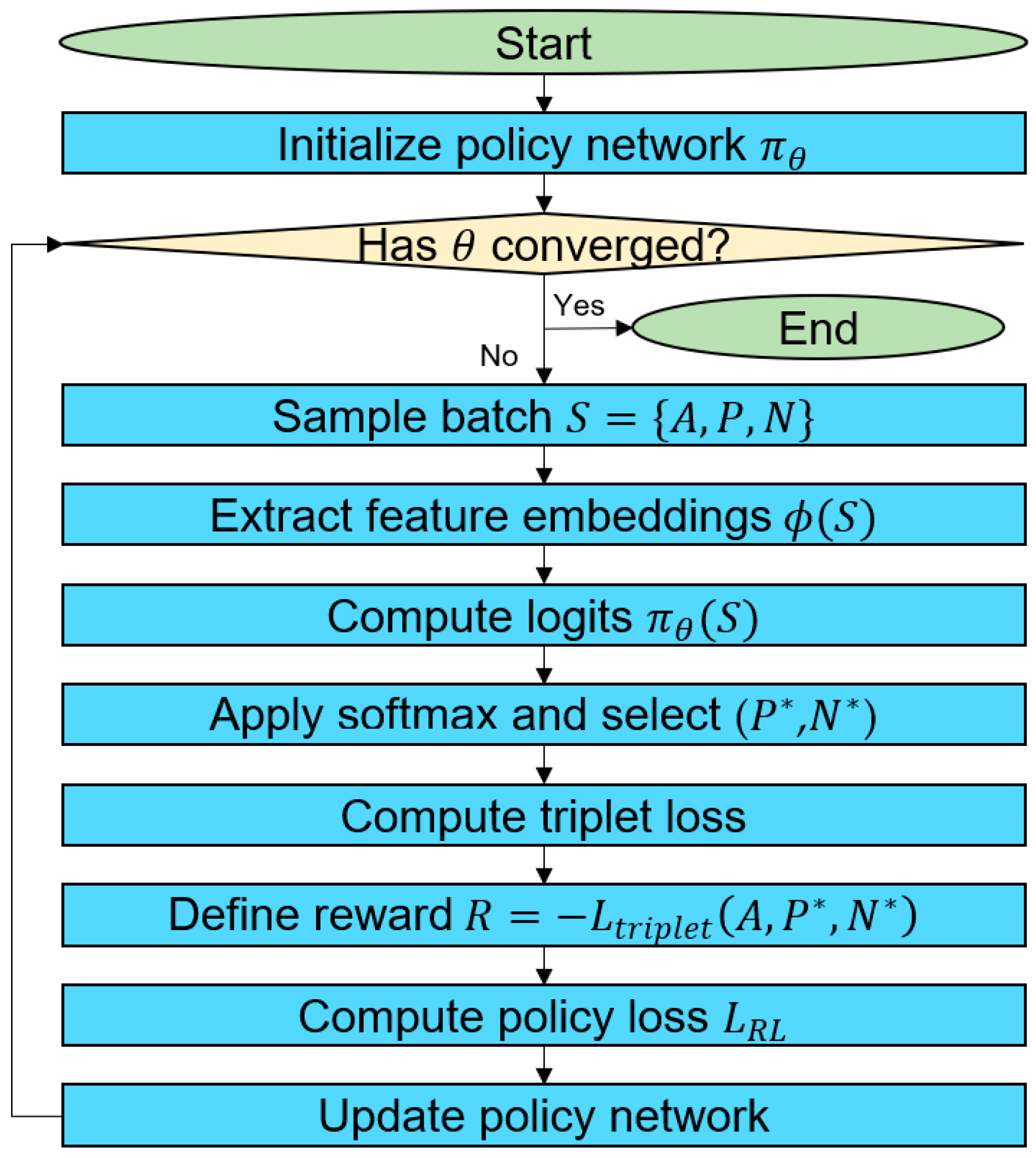
The reinforcement learning-based triplet sampling process, detailed in Algorithm 1, optimizes anchor-positive-negative selection to enhance the Triplet Network’s ability to disentangle overlapping features between phishing and benign data. By focusing on hard positives and negatives, it improves feature separation. Unlike conventional methods relying on random or semi-hard mining, this approach uses a policy network to select triplets that best refine the representation space. This enhances the Triplet Network’s robustness in distinguishing visually and structurally similar webpages, reducing misclassification errors and improving detection accuracy.
| Algorithm 1: Reinforcement Learning for Triplet Sampling Optimization |
| Input: Policy network with parameters , triplet margin , learning rate |
| Output: Trained policy network |
1: Initialize the policy network with parameters .
2: While has not converged:
3: Sample a batch of state from the environment.
4: Foreach anchor :
5: Extract feature embeddings:
6: Compute logits from the policy network:
7: Select optimized positive and negative : (,) =
8: Compute the triplet loss for the selected samples:
9: Define the reward: .
10: Compute policy loss: .
11: End for
12: Update the policy network parameters using gradient descent:
13: End while |
3.3. Multimodal Feature Integration
The proposed method integrates two distinct modalities—URL data and HTML DOM structures—to construct a comprehensive representation of webpages. This integration captures lexical and structural characteristics, allowing the model to distinguish between phishing and benign samples. By capturing these features, the method enables detection even when subtle differences occur in the URL and HTML DOM structures.
Phishing URLs often exploit lexical patterns such as typosquatting, obfuscation, and misleading keywords to deceive users. URLs are tokenized at the character level to capture subtle structural variations inherent to phishing attempts. The tokenized sequences are processed using a Convolutional Neural Network (CNN), which extracts features indicative of domain anomalies, repetitive patterns, and irregularities in URL length. This lexical analysis enables the detection of phishing attempts even when the differences from benign URLs are minor.
While URL analysis provides insights into lexical anomalies, structural relationships within HTML content offer complementary information critical for detecting phishing webpages. The raw HTML of each webpage is parsed into a Document Object Model (DOM) tree, where nodes represent HTML elements and edges denote their hierarchical relationships. This DOM tree is transformed into a graph representation, capturing both local and global dependencies between webpage elements. A Graph Convolutional Network (GCN) is employed to process the HTML DOM graph. The GCN identifies structural patterns, such as dense nesting or unusual element placements, which are often indicative of phishing. By aggregating relational information, the GCN effectively captures discrepancies that distinguish phishing webpages from their benign counterparts.
The extracted features from URLs and HTML DOM structures are concatenated to form a unified representation. This multimodal feature integration ensures that both lexical and structural distinctions are preserved, enabling the model to effectively separate phishing and benign data. By leveraging the complementary strengths of the two modalities, the method addresses cases where phishing attempts mimic benign webpages at both textual and structural levels. This integration forms the foundation of the proposed method’s disentangled representation space, which enhances the separation of overlapping features. Rigorous testing on a large-scale dataset of over one million samples demonstrates the effectiveness of this approach in improving phishing detection performance across key metrics such as accuracy, precision, and recall.
4. Experimental Results
4.1. Dataset and Preprocessing
The datasets used in this study include benign data from Common Crawl and phishing data from Phishtank and Mendeley Data, as summarized in
Table 3. The benign dataset, collected in February 2023, contains 1,048,575 instances, providing a broad and diverse representation of benign webpages. The phishing dataset includes 14,912 instances from Phishtank and 14,573 instances from Mendeley Data, covering a wide range of phishing techniques. To ensure high data quality, only HTML samples that passed parsing were included, while incomplete or poorly formatted content was excluded. These curated datasets offer a reliable foundation for evaluating the proposed method.
Preprocessing was conducted separately for URLs and HTML DOM graphs to construct a disentangled representation space for phishing detection. For URL preprocessing, raw URLs were tokenized at the character level to capture lexical patterns such as typosquatting, domain spoofing, and obfuscation. These tokenized URLs were then converted into one-hot encoded vectors and processed by a Convolutional Neural Network (CNN) to extract meaningful patterns, including irregular domain structures, suspicious substrings, and unconventional formatting. This approach enhances lexical feature representation, highlighting key phishing indicators.
For HTML preprocessing, raw webpage content was parsed into Document Object Model (DOM) trees using Beautiful Soup. These DOM trees were transformed into graph structures, where HTML tags were mapped to nodes, and edges represented parent-child relationships. Additional attributes, such as tag names, classes, and IDs, were incorporated to enrich the structural representation. A Graph Convolutional Network (GCN) then processed these graphs to extract dependencies, layout patterns, and structural anomalies. This method effectively captured irregularities in phishing webpages, ensuring robust differentiation even in cases with significant structural overlap.
The proposed method leverages features extracted from URLs and HTML DOM graphs to construct a disentangled representation space specifically designed to address the complexities of phishing detection. By combining lexical and structural features, the model achieves effective separation of phishing and benign data, even in scenarios with significant feature overlap. This process is underpinned by a meticulously curated dataset and preprocessing pipeline, which forms a robust foundation for evaluating the method’s performance. Furthermore, the dataset will be released as an open-source benchmark to support future advancements in phishing detection research.
4.2. Implementation Details
To implement the proposed method, we utilized the unique characteristics of URLs and HTML DOM structures in phishing and benign data. This section provides an overview of how the data were processed and highlights structural differences between benign and phishing samples, which serve as key features for distinguishing the two classes.
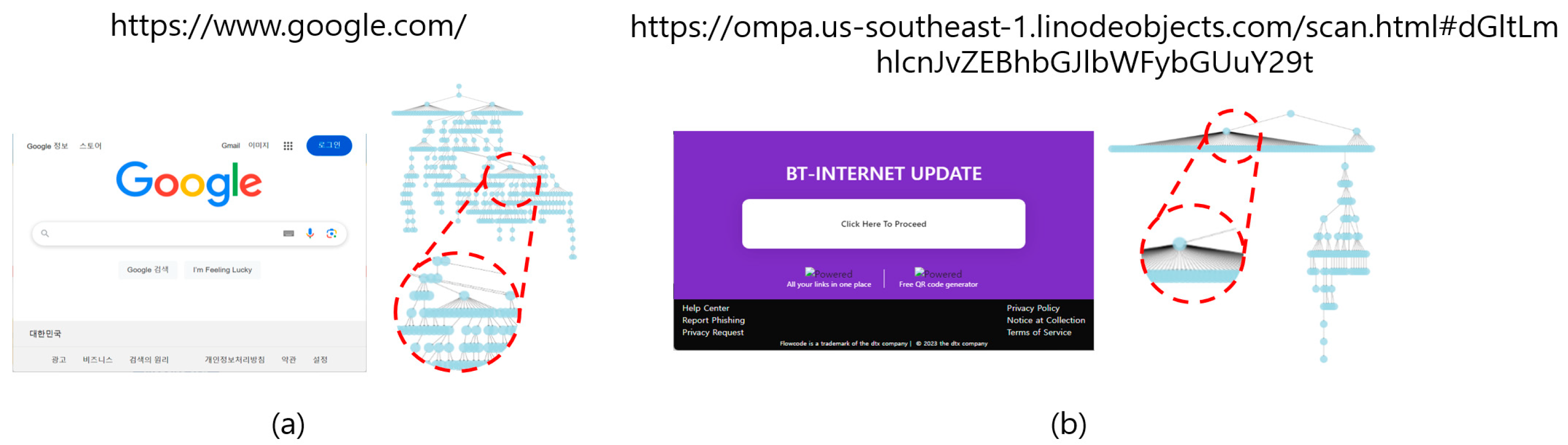
Figure 3 illustrates these differences using visualizations of their respective HTML DOM graphs. The discrepancies between these cases emphasize the importance of leveraging not only URL-based but also DOM-based features in phishing detection.
In case (a), the benign HTML DOM structure exhibits a well-distributed and organized hierarchy, with evenly distributed child nodes and no excessive nesting. The URL of the benign sample is also relatively simple, reflecting the minimalistic design and clarity often found in benign webpages. These characteristics allow the Graph Convolutional Network (GCN) to efficiently capture the hierarchical relationships among HTML elements and contribute to a clear, disentangled representation in the feature space. In contrast, case (b) showcases the characteristics of a phishing sample. The HTML DOM graph of the phishing webpage displays an imbalanced structure, with certain nodes containing a disproportionate number of child nodes, creating a visually dense and disorganized graph. Additionally, the URL of the phishing sample is highly obfuscated and complex, often including unnecessary parameters or deceptive keywords. These structural anomalies are effectively captured by the GCN, enabling the model to differentiate phishing samples from benign ones.
By processing both lexical patterns from URLs and structural relationships from HTML DOM graphs, the proposed method constructs a disentangled representation space optimized for phishing detection. The visualizations in
Figure 4 emphasize the importance of these features in creating a robust model capable of handling diverse phishing techniques.
4.3. Confusion Matrix Analysis
The performance of the proposed method was evaluated using a comprehensive test set, and the results are summarized in terms of standard classification metrics, including accuracy, precision, recall, F1 score, true positive rate (TPR), and false positive rate (FPR).
Figure 5 illustrates the confusion matrix generated from the evaluation, providing a detailed breakdown of the model’s classification performance for both benign and phishing data. The proposed method achieved an overall accuracy of 99.97%, demonstrating its effectiveness in accurately classifying both benign and phishing samples. The precision was recorded at 1.000, indicating that all instances predicted as phishing were indeed phishing cases. Recall was measured at 0.9986, showing the model’s ability to correctly identify nearly all phishing instances. The resulting F1 score, which balances precision and recall, was calculated as 0.9993, highlighting the model’s robust performance. The true positive rate (TPR) reached 99.86%, signifying that most phishing instances were correctly identified. Moreover, the false positive rate (FPR) was 0%, indicating that no benign instances were misclassified as phishing. These results demonstrate the reliability of the proposed method, even in scenarios where phishing and benign features overlap.
The confusion matrix in
Table 4 provides further insight into the model’s performance. Out of 7492 total samples, 6058 benign instances were correctly classified with no false positives, while 1432 phishing instances were correctly identified with only two false negatives. This exceptional performance underscores the efficacy of the disentangled representation space created through the integration of URL and HTML DOM features, as well as the optimized triplet sampling via reinforcement learning. The combination of high accuracy, precision, and recall confirms the robustness of the proposed method in distinguishing phishing from benign data. These results highlight the model’s potential for real-world deployment in cybersecurity applications, where minimizing both false positives and false negatives is critical.
4.4. Comparative Analysis
To evaluate the performance of the proposed method, we conducted a comparative analysis against Base networks and Comparative studies using 10-fold cross-validation. The results of this evaluation are summarized in
Table 5.
Our method significantly outperforms existing approaches across all evaluation metrics. Notably, the integration of the Triplet Network and RL leads to substantial improvements. When compared to PhishDet [
12], which previously demonstrated state-of-the-art performance with an accuracy of 0.9853 ± 0.0058, our method with Triplet Network and RL achieves an accuracy of 0.9995 ± 0.0005, reducing misclassification errors even further. Compared to URLNet [
19], which focuses on URL-based phishing detection and achieves an accuracy of 0.9425 ± 0.0208, our approach demonstrates a 5.7% absolute improvement by leveraging HTML structural representations and advanced sampling strategies. Similarly, our model surpasses WebPhish [
13], which integrates various phishing features and achieves 0.9290 ± 0.0719 accuracy, highlighting the advantage of our disentangled representation learning. In terms of precision and recall, our proposed method also consistently outperforms existing approaches. While Texception [
20] achieves a high recall of 0.9714 ± 0.0286, its accuracy remains lower at 0.8534 ± 0.1308, indicating potential overfitting to phishing cases. In contrast, our approach maintains a balanced and robust performance across all metrics, achieving near-perfect precision (0.9995 ± 0.0005) and recall (0.9995 ± 0.0005) without sacrificing performance.
The ablation study further demonstrates the importance of the Triplet Network and RL. The model without the Triplet Network and RL achieves 0.9812 ± 0.0033 accuracy, whereas introducing the Triplet Network alone boosts the accuracy to 0.9937 ± 0.0024. Finally, with both the Triplet Network and RL, the model achieves the best performance, underscoring the effectiveness of our proposed enhancements.
4.5. Impact of Positive and Negative Sampling
The performance of the proposed method was evaluated under different configurations of positive and negative samples during training to understand their impact on the model’s effectiveness.
Table 6 summarizes the results of this analysis, providing insights into how varying the number of positive and negative samples influences the accuracy, precision, recall, and F1 score of the model.
The results demonstrate that the configuration with three positive samples and three negative samples yields the highest F1 score of 0.9993, along with an accuracy of 0.9997, a precision of 1.0000, and a recall of 0.9986. This configuration achieves an optimal balance between diversity and informativeness in the sampled data, which is critical for constructing a disentangled representation space. The model’s high precision across all configurations indicates its ability to avoid false positives consistently, regardless of the number of positive and negative samples.
Increasing the number of positive samples beyond three results in marginal declines in recall, which slightly reduces the F1 score in configurations with four or more positive samples. Similarly, while increasing the number of negative samples initially improves performance, configurations with more than three negative samples show diminishing returns. This effect is likely due to the decreasing informativeness of additional negative samples, which can lead to redundancy in the training process. These findings highlight the importance of carefully balancing the number of positive and negative samples to optimize the model’s performance. While the method is robust across a wide range of configurations, the best results are achieved with three positive samples and three negative samples. This configuration effectively supports the learning process of the Triplet Network and reinforces the importance of sampling strategies in enhancing phishing detection performance.
4.6. t-SNE Visualization of Representation Spaces
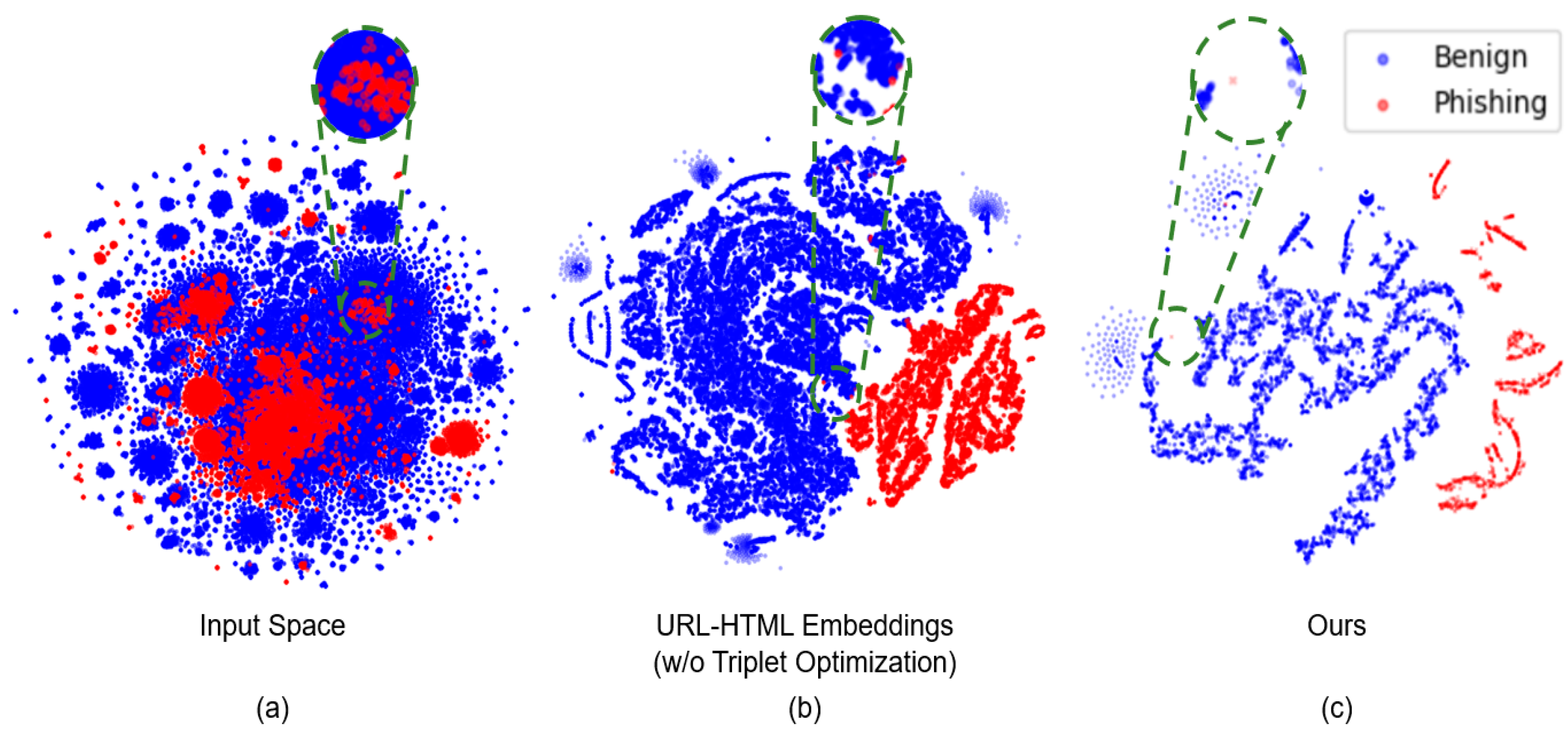
To evaluate the quality of the disentangled representation spaces produced by the proposed method, we utilized t-SNE visualization to project high-dimensional embeddings into a two-dimensional space.
Figure 4 illustrates the resulting distributions for three configurations: the original input space, embeddings generated from URL and HTML features without triplet optimization, and embeddings generated using the proposed method with triplet optimization.
In case (a), the input space demonstrates significant overlap between benign and phishing samples, indicated by the intermingling of blue and red clusters. This overlap highlights the inherent challenges in distinguishing benign from phishing data due to their structural and feature-based similarities. In case (b) presents the embeddings generated from URL and HTML features without triplet optimization. While some separation between the benign and phishing classes is evident, a notable degree of overlap persists, particularly in boundary regions. This result suggests that the integration of URL and HTML features alone is insufficient for achieving a highly discriminative representation space. In case (c) depicts the embeddings produced by the proposed method, which incorporates reinforcement learning for triplet optimization. The benign and phishing clusters are well separated, with minimal overlap, indicating the effectiveness of the proposed triplet optimization strategy. The disentangled representation space provides a clear boundary between the two classes, enabling the model to achieve superior performance in phishing detection tasks.
4.7. Confidence Level of the Proposed Solution
The confidence level of our solution is 95%, meaning that we can state with 95% certainty that our model’s accuracy falls within the given range. This is assessed using 10-fold cross-validation, ensuring robustness across different data splits. As shown in
Table 5, our method achieves 0.9995 ± 0.0005 accuracy, with low variance across precision, recall, and F1 score, indicating high stability. Based on this 95% confidence level, we compute the 95% Confidence Interval (CI) for accuracy as [0.9990, 1.0000], demonstrating our model’s consistent performance. However, real-world performance may vary due to factors such as dataset distribution shifts and adversarial phishing techniques, which are not fully captured in controlled cross-validation experiments.
4.8. Justification for the Technique, Pros, and Cons
The proposed method employs a Triplet Network combined with RL for sample selection optimization. This technique was chosen to address key limitations of conventional phishing detection methods, which often rely on handcrafted features or static heuristics, making them less adaptable to evolving phishing techniques.
Traditional triplet loss methods struggle with inefficient sampling, which can degrade model performance. By incorporating RL, our approach optimizes the selection of anchor, positive, and negative samples, improving feature disentanglement and overall model accuracy.
Pros:
Enhanced Disentangled Representation Learning: The Triplet Network helps separate phishing and benign samples more effectively, improving classification accuracy.
Adaptive Sample Selection: RL dynamically selects the most informative triplets, reducing the impact of redundant or low-quality samples.
Improved Generalization: Unlike rule-based systems, our model generalizes better to unseen phishing attacks.
Cons:
Increased Computational Cost: The integration of RL adds additional training complexity and requires more computing resources compared to traditional triplet loss.
Hyperparameter Sensitivity: RL-based optimization requires careful tuning of hyperparameters (e.g., reward function, learning rate) to ensure stable training.
Longer Training Time: Due to sample selection learning, training takes longer compared to conventional deep learning models without RL.
4.9. Metrics for Evaluating Reinforcement Learning
The RL component in our model is responsible for optimizing sample selection in the triplet network. To evaluate the effectiveness of this process, we employ the following RL-specific metrics:
Cumulative Reward: The total reward accumulated over training episodes, which indicates how well the policy improves triplet selection. A higher cumulative reward suggests better sample selection. In our setting, the reward is defined as the negative triplet loss (-triplet_loss), ensuring that the RL agent minimizes the margin-based loss while selecting optimal triplets.
Average Reward per Episode: This metric tracks the mean reward obtained in each episode, providing insight into the learning stability of the policy. Initially, the reward is low due to random selection, but as training progresses, the reward increases as the policy learns to select more informative triplets. This trend helps assess how consistently the model improves sample selection across different training phases.
Loss Function Trends: The policy network’s loss function is monitored to ensure stable optimization. A decreasing loss trend indicates effective learning, while instability may suggest suboptimal policy updates.
Convergence Rate: We analyze how quickly the policy stabilizes in terms of reward accumulation. Faster convergence suggests that the RL agent efficiently learns a robust sample selection strategy.
Throughout training, we observed a steady increase in cumulative reward, indicating that the RL agent effectively learns to select hard-positive and hard-negative samples. These RL-specific metrics complement traditional classification metrics (accuracy, precision, recall, and F1 score), ensuring that RL contributes effectively to the overall model performance.
4.10. Algorithm Complexity Analysis
The proposed method integrates CNN, GCN, and RL-based triplet sampling to enhance phishing detection performance by leveraging multimodal feature extraction and optimized sample selection. Each component was chosen to address specific challenges in phishing detection: CNN extracts lexical patterns from URLs, GCN captures structural relationships in HTML, and RL refines sample selection to improve feature separation and classification accuracy.
The CNN processes character-based URL representations using convolutional layers with a complexity of , where is the batch size, and are the feature map dimensions, is the number of filters, and is the kernel size. CNN was selected because phishing URLs often exploit lexical similarities to deceive users, and convolutional layers are effective in capturing such patterns.
The GCN extracts structural relationships in HTML DOM graphs, where nodes represent HTML elements and edges define their relationships. The computational complexity is , where is the number of nodes, is the number of edges, and is the embedding dimension. GCN was incorporated to exploit the structural differences between benign and phishing webpages, which may not be apparent in raw text features.
Reinforcement learning optimizes triplet selection, with the sampling step having a complexity of due to distance computations and selection operations. The policy network further introduces a complexity of , where is the hidden layer size. Traditional triplet sampling methods often fail to focus on truly challenging examples, leading to suboptimal feature separation. By using RL, the proposed method prioritizes the most informative samples, enhancing the training process and leading to higher phishing detection accuracy.
The overall model complexity combines CNN, GCN, and RL contributions. The computational cost varies depending on dataset characteristics: CNN is dominant when handling long URLs, while GCN computation is heavier for complex webpage structures. RL introduces additional processing overhead but significantly improves triplet sampling effectiveness, resulting in enhanced phishing detection performance.
4.11. Discussion: Case Study on Misclassified Instances
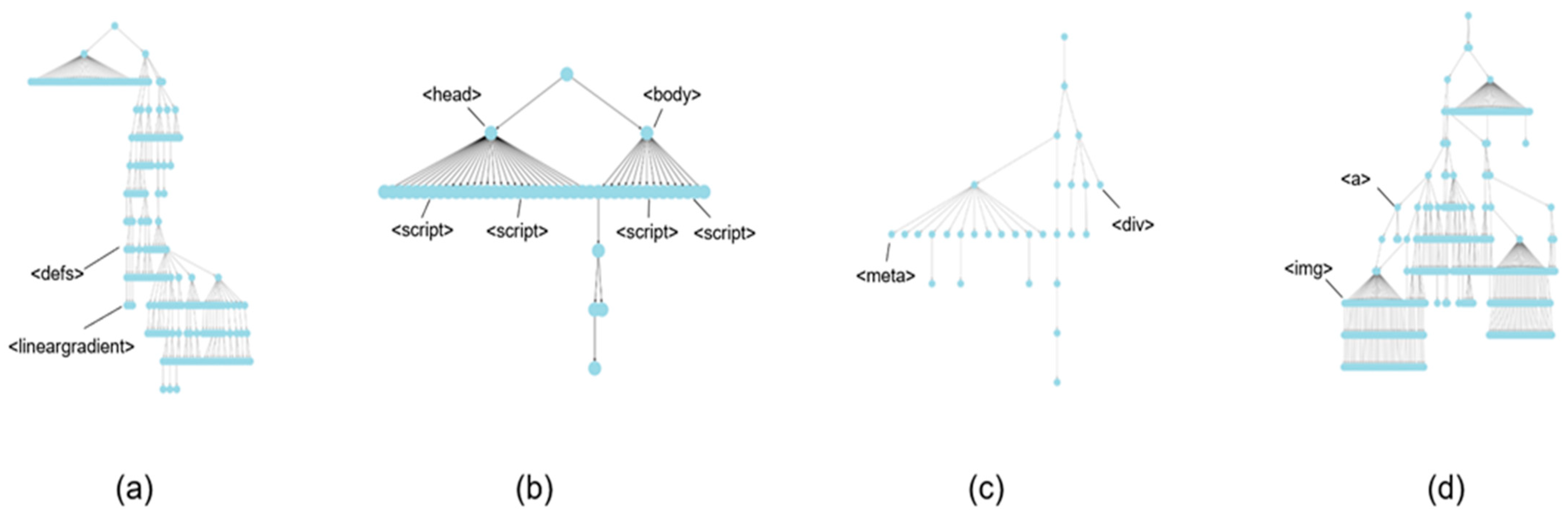
To further evaluate the limitations of the proposed method, a case study was conducted on misclassified instances.
Table 7 presents four representative cases where the model failed to correctly distinguish between benign and phishing samples. These cases were selected to analyze the inherent challenges posed by structural similarities and overlapping features between benign and phishing webpages, which significantly impact classification accuracy. The corresponding HTML DOM structures for each case are illustrated in
Figure 6, while the URLs, providing additional context, are presented in
Table 7.
Cases (a) and (b) represent phishing URLs that were erroneously classified as benign. Both cases exhibit simple and sparse HTML DOM structures, closely resembling the characteristics of benign webpages. This similarity in structure led to the model’s misclassification. Moreover, the URLs of these phishing instances mimic benign patterns, making detection more challenging.
Conversely, cases (c) and (d) involve benign URLs that were incorrectly identified as phishing. These benign samples demonstrate highly complex and dense HTML DOM structures, mimicking the structural attributes often observed in phishing webpages. The unusual URL patterns and structural intricacies in these instances likely influenced the model to classify them as phishing.
The HTML DOM visualizations in
Figure 5 illustrate the challenges posed by structural and feature-based similarities between phishing and benign webpages. While the proposed method demonstrates strong performance in most cases, the misclassified instances reveal limitations in effectively capturing subtle feature ambiguities and structural inconsistencies. These findings highlight the need for refining the representation space to better address such edge cases. Future work could focus on developing more targeted sampling strategies or incorporating additional features specifically tailored to improve phishing detection accuracy.
5. Conclusions
This study presented a method for phishing webpage detection that addresses key challenges in feature disentanglement and class overlap between phishing and benign data. The proposed approach utilizes reinforcement learning to optimize triplet sampling, ensuring the model effectively focuses on hard samples to improve the discriminative power of the representation space. Additionally, the integration of multimodal features from URLs and HTML DOM structures provides a comprehensive representation of webpages, capturing both lexical and structural characteristics critical for accurate phishing detection.
The method was evaluated on a large-scale dataset consisting of over one million benign and phishing webpages, demonstrating its effectiveness and scalability across diverse scenarios. The results highlight its superior performance across all evaluation metrics, including an accuracy of 99.97%, a precision of 1.000, and an F1 score of 0.9993. The confusion matrix analysis further confirmed the method’s ability to minimize both false positives and false negatives, emphasizing its suitability for real-world applications requiring high reliability. The t-SNE visualizations illustrated the quality of the disentangled representation space achieved by the proposed method, showcasing a clear separation between phishing and benign samples. This underscores the importance of optimized triplet sampling and multimodal feature integration in enhancing model performance. Additionally, the case study on misclassified instances provided insights into remaining challenges, such as adversarial mimicry and structural ambiguities, offering guidance for future improvements. This work contributes to phishing detection by demonstrating the utility of reinforcement learning in optimizing triplet networks and emphasizing the critical role of integrating multimodal features. The findings underscore the potential of the proposed method for deployment in practical cybersecurity systems, where accurate and scalable phishing detection is essential.
Future work will focus on refining the disentangled representation space to better handle edge cases, as identified in the misclassification analysis. Moreover, the exploration of additional modalities, such as visual elements or user interaction data, may further enhance the robustness of phishing detection systems. By addressing these challenges, we aim to advance the effectiveness of phishing detection technologies and contribute to creating safer online environments.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}