
Bounded-Error LiDAR Compression for Bandwidth-Efficient Cloud-Edge In-Vehicle Data Transmission



Abstract
1. Introduction
2. Related Works
3. Proposed Bounded-Error Compression Methods
3.1. Bounded-Error Quantization and Error Metrics
3.2. Huffman Coding (Lossless Baseline)
3.3. EB-HC (Axis/L2)
| Algorithm 1. EB-HC |
| Require: A set of LiDAR points , user-specified threshold δ > 0, and mode ∈ {Axis, L2} |
| Ensure: A compressed bitstream |
|
3.4. EB-3D (Axis/L2)
| Algorithm 2. EB-3D |
| Require: A set of LiDAR points ; threshold ; mode |
| Ensure: An octree-based compressed representation |
|
3.5. EB-HC-3D (Axis/L2)
| Algorithm 3. EB-HC-3D |
| Require: A set of LiDAR points P; threshold ; mode ∈ {Axis, L2}; maximum depth Ensure: A final compressed bitstream
|
3.6. Summary of Proposed Methods
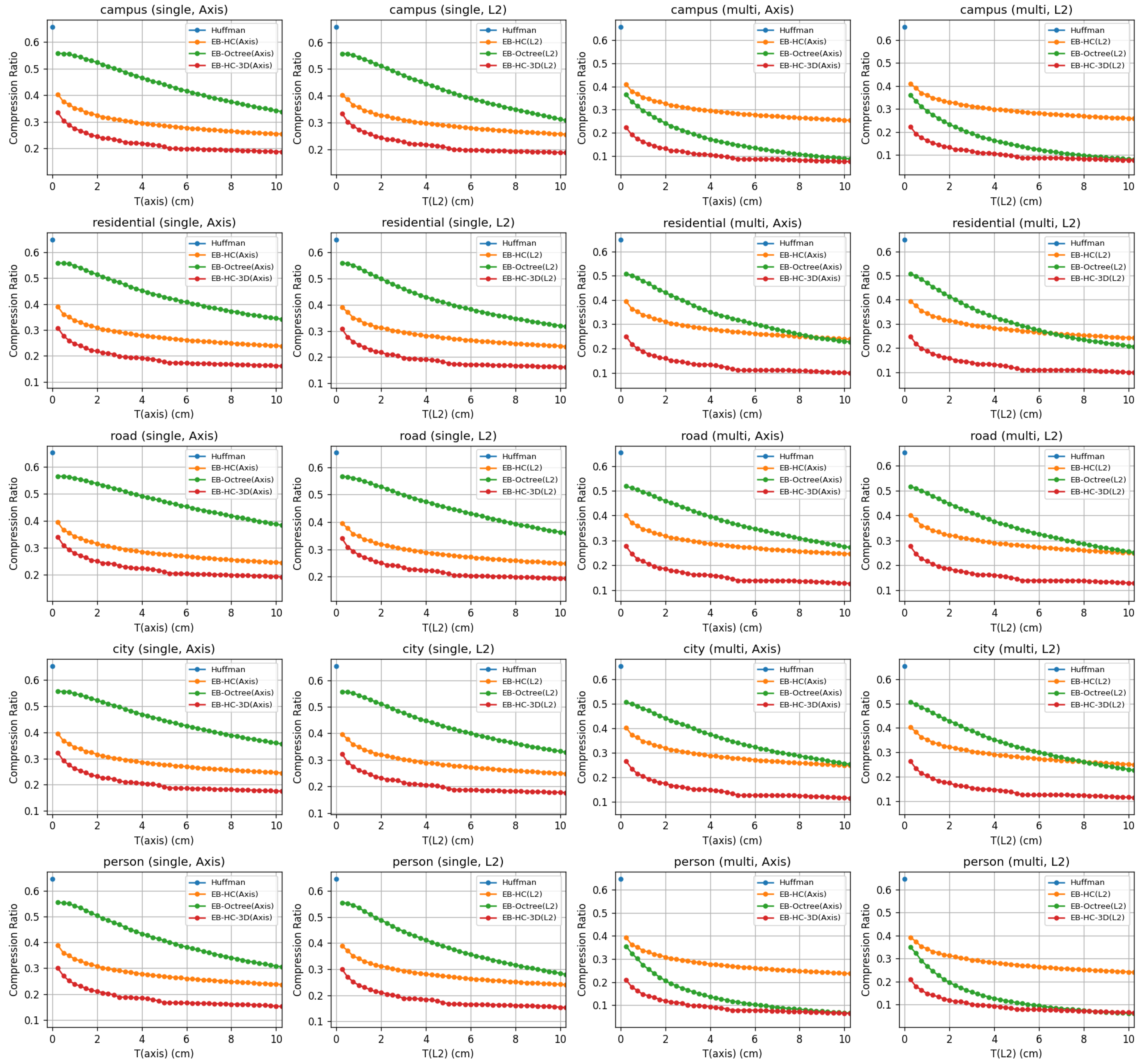
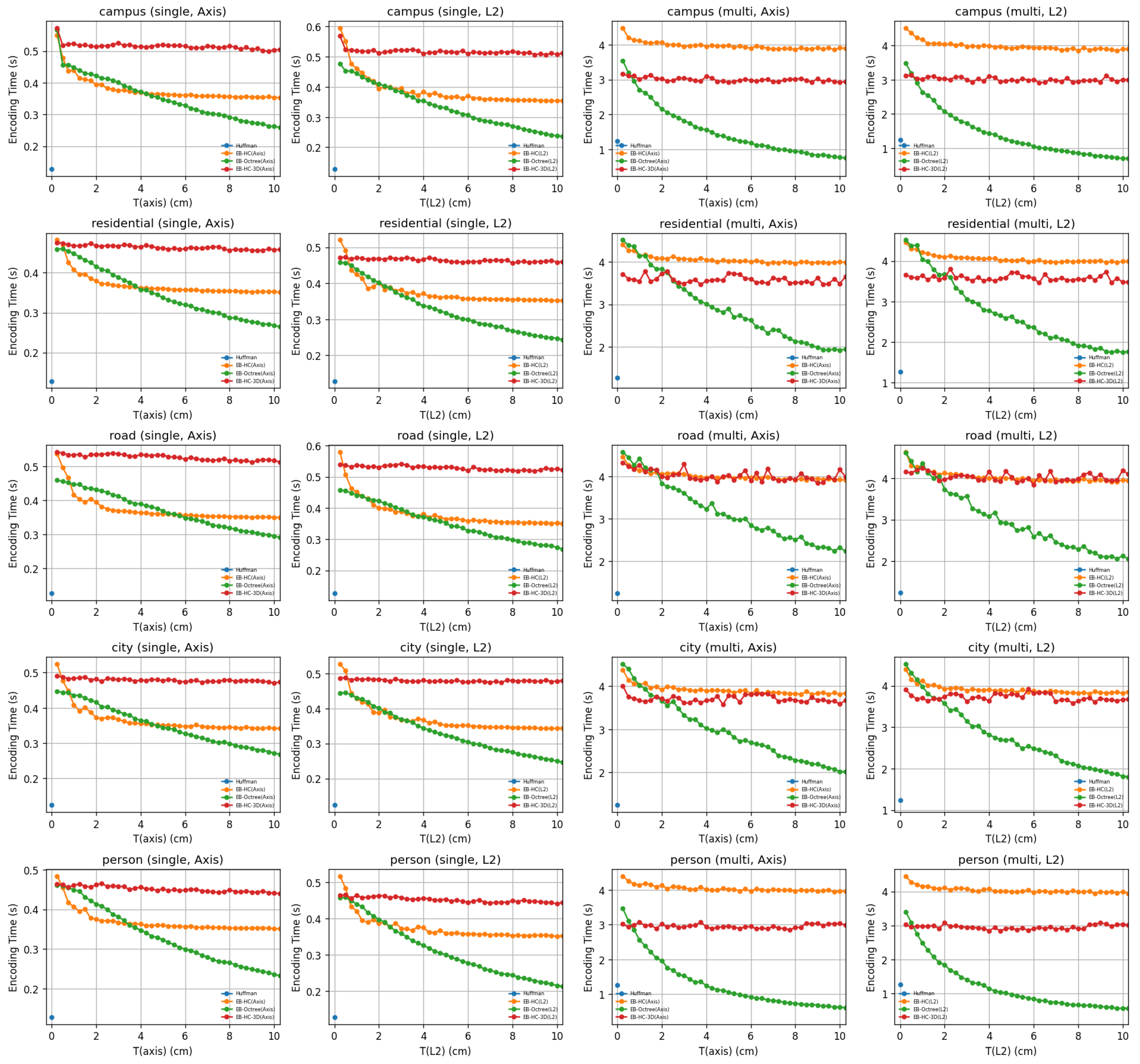
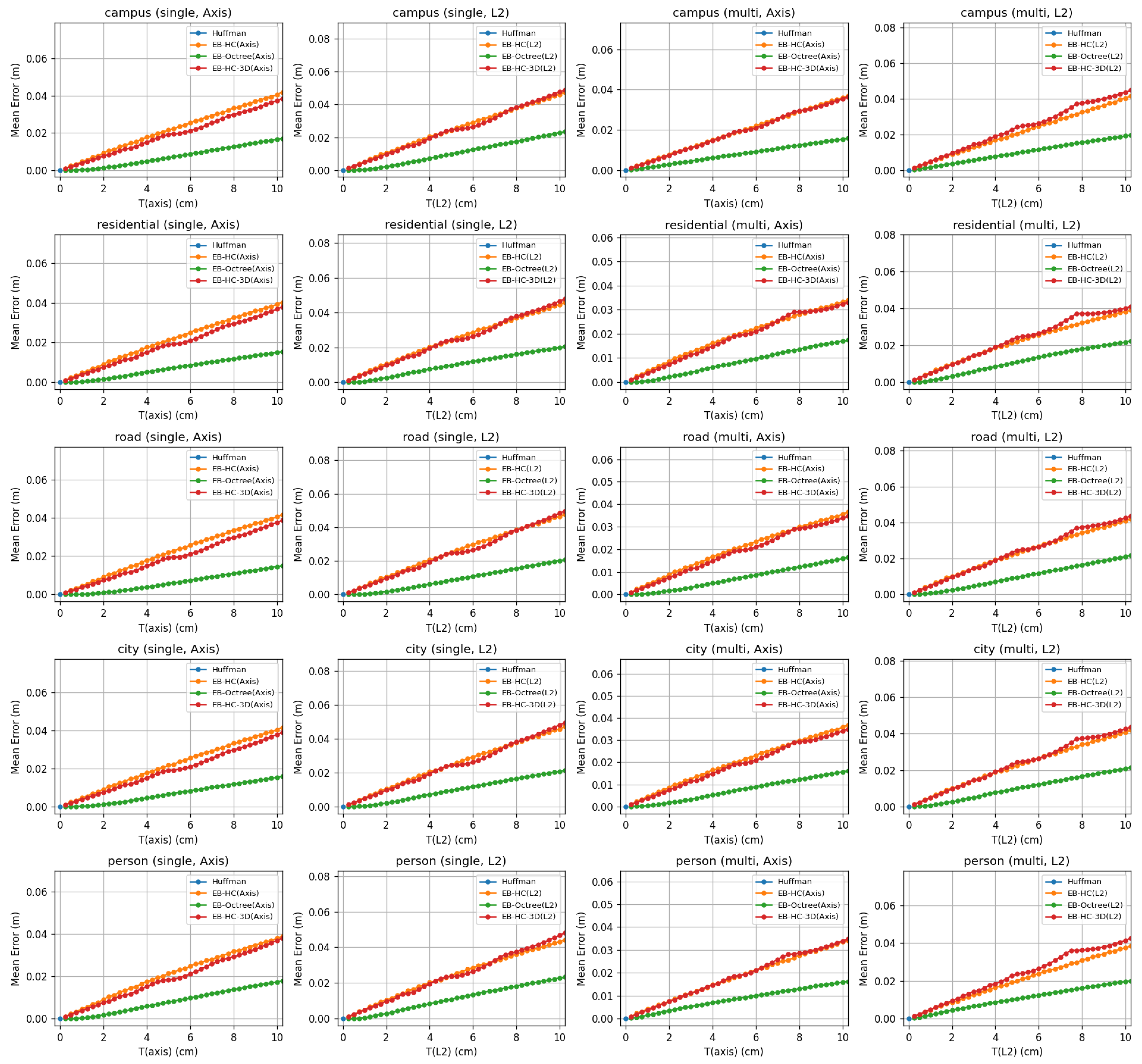
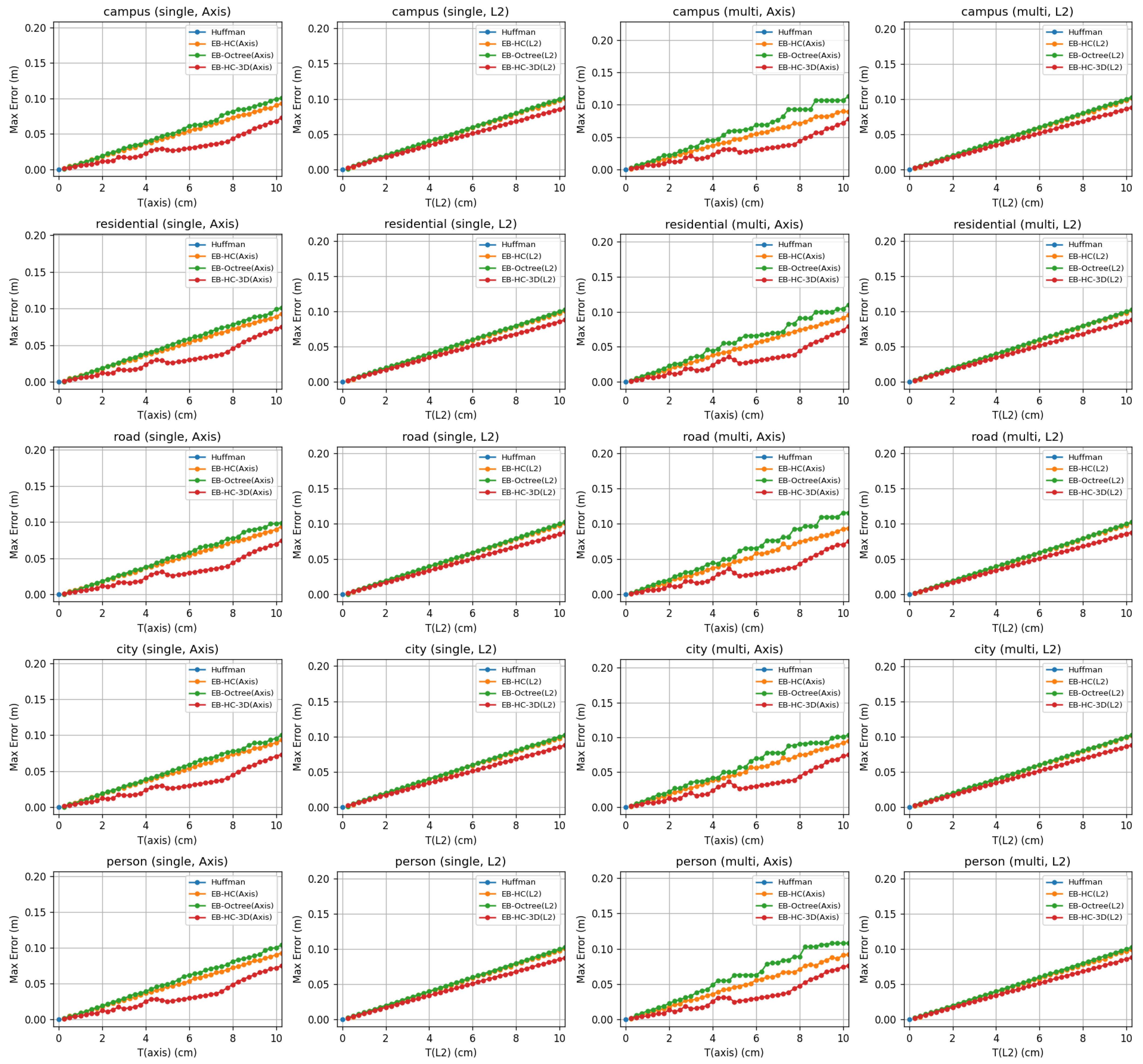
4. Evaluation
4.1. Dataset Introduction
4.2. Evaluation Metrics and Error Settings
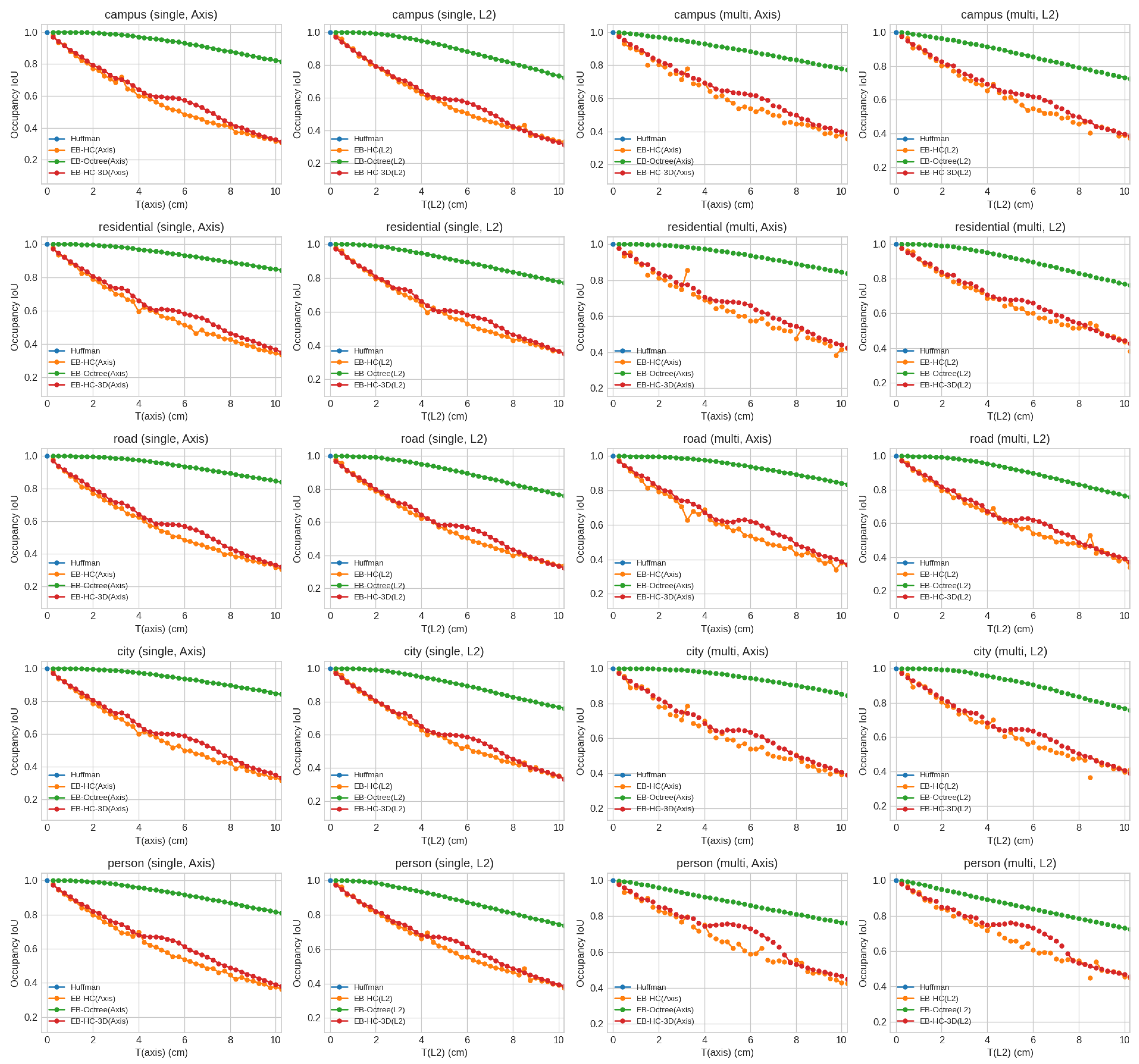
4.3. Comparison Among Compression Methods
4.4. Cloud-Edge Application Analysis
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADASs | Advanced Driver-Assistance Systems |
| ECU | Electronic Control Unit |
| EB-HC | Error-Bounded Huffman Coding |
| EB-3D | Error-Bounded 3D Compression Method |
| EB-HC-3D | Error-Bounded Huffman Coding with 3D Integration |
| LiDAR | Light Detection and Ranging |
| T | Maximum Allowed Coordinate Deviation (Error Threshold) |
| V2X | Vehicle-to-Everything |
References
- Chen, S.; Liu, B.; Feng, C.; Vallespi-Gonzalez, C.; Wellington, C. 3D point cloud processing and learning for autonomous driving: Impacting map creation, localization, and perception. IEEE Signal Process. Mag. 2020, 38, 68–86. [Google Scholar] [CrossRef]
- Ayala, R.; Mohd, T.K. Sensors in autonomous vehicles: A survey. J. Auton. Veh. Syst. 2021, 1, 031003. [Google Scholar] [CrossRef]
- Lo Bello, L.; Patti, G.; Leonardi, L. A perspective on ethernet in automotive communications—Current status and future trends. Appl. Sci. 2023, 13, 1278. [Google Scholar] [CrossRef]
- Ahmed, M.; Mirza, M.A.; Raza, S.; Ahmad, H.; Xu, F.; Khan, W.U.; Lin, Q.; Han, Z. Vehicular communication network enabled CAV data offloading: A review. IEEE Trans. Intell. Transp. Syst. 2023, 24, 7869–7897. [Google Scholar] [CrossRef]
- Arthurs, P.; Gillam, L.; Krause, P.; Wang, N.; Halder, K.; Mouzakitis, A. A taxonomy and survey of edge cloud computing for intelligent transportation systems and connected vehicles. IEEE Trans. Intell. Transp. Syst. 2021, 23, 6206–6221. [Google Scholar] [CrossRef]
- Hasan, M.M.; Feng, H.; Hasan, M.T.; Gain, B.; Ullah, M.I.; Khan, S. Improved and Comparative End to End Delay Analysis in CBS and TAS using Data Compression for Time Sensitive Network. In Proceedings of the 2021 3rd International Conference on Applied Machine Learning (ICAML), Changsha, China, 23–25 July 2021; pp. 195–201. [Google Scholar]
- Bandi, V.; Mahajan, N. Implementation of Compressed Point Cloud Streams in ROS; Technical Report, University of Texas at Austin: Austin, TX, USA. Available online: https://www.nalinmahajan.com/proj2/FRI_Final_Paper.pdf (accessed on 21 February 2025).
- Abdelwahab, M.M.; El-Deeb, W.S.; Youssif, A.A. LiDAR data compression challenges and difficulties. In Proceedings of the 2019 5th International Conference on Frontiers of Signal Processing (ICFSP), Marseille, France, 18–20 September 2019; pp. 111–116. [Google Scholar]
- Sun, X.; Luo, Q. Density-Based Geometry Compression for LiDAR Point Clouds. In Proceedings of the EDBT, Ioannina, Greece, 28–31 March 2023; pp. 378–390. [Google Scholar]
- Liu, Y.; Tao, J.; He, B.; Zhang, Y.; Dai, W. Error analysis-based map compression for efficient 3-D lidar localization. IEEE Trans. Ind. Electron. 2022, 70, 10323–10332. [Google Scholar] [CrossRef]
- Yoo, H.W.; Druml, N.; Brunner, D.; Schwarzl, C.; Thurner, T.; Hennecke, M.; Schitter, G. MEMS-based lidar for autonomous driving. e & i Elektrotechnik und Informationstechnik 2018, 34, 373–379. [Google Scholar] [CrossRef]
- Dai, Z.; Li, Y.; Sundermeier, M.C.; Grabe, T.; Lachmayer, R. Lidars for Vehicles: From the Requirements to the Technical Evaluation; Institutionelles Repositorium der Leibniz Universität Hannover: Hannover, Germany, 2021. [Google Scholar]
- Carthen, C.; Zaremehrjardi, A.; Le, V.; Cardillo, C.; Strachan, S.; Tavakkoli, A.; Dascalu, S.M.; Harris, F.C. A Spatial Data Pipeline for Streaming Smart City Data. In Proceedings of the 2024 IEEE/ACIS 22nd International Conference on Software Engineering Research, Management and Applications (SERA), Honolulu, HI, USA, 30 May–1 June 2024; pp. 267–272. [Google Scholar]
- Yin, H.; Wang, Y.; Tang, L.; Ding, X.; Huang, S.; Xiong, R. 3d lidar map compression for efficient localization on resource constrained vehicles. IEEE Trans. Intell. Transp. Syst. 2020, 22, 837–852. [Google Scholar] [CrossRef]
- Anand, B.; Kambhampaty, H.R.; Rajalakshmi, P. A novel real-time lidar data streaming framework. IEEE Sens. J. 2022, 22, 23476–23485. [Google Scholar] [CrossRef]
- Mongus, D.; Žalik, B. Efficient method for lossless LIDAR data compression. Int. J. Remote Sens. 2011, 32, 2507–2518. [Google Scholar] [CrossRef]
- Isenburg, M. LASzip: Lossless compression of LiDAR data. Photogramm. Eng. Remote Sens. 2013, 79, 209–217. [Google Scholar] [CrossRef]
- Lipuš, B.; Žalik, B. Lossless progressive compression of LiDAR data using hierarchical grid level distribution. Remote Sens. Lett. 2015, 6, 190–198. [Google Scholar] [CrossRef]
- Tu, C.; Takeuchi, E.; Carballo, A.; Takeda, K. Point cloud compression for 3d lidar sensor using recurrent neural network with residual blocks. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 3274–3280. [Google Scholar]
- Zhou, X.; Qi, C.R.; Zhou, Y.; Anguelov, D. Riddle: Lidar data compression with range image deep delta encoding. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17212–17221. [Google Scholar]
- Anand, B.; Barsaiyan, V.; Senapati, M.; Rajalakshmi, P. Real time LiDAR point cloud compression and transmission for intelligent transportation system. In Proceedings of the 2019 IEEE 89th Vehicular Technology Conference (VTC2019-Spring), Kuala Lumpur, Malaysia, 28 April–1 May 2019; pp. 1–5. [Google Scholar]
- Huang, L.; Wang, S.; Wong, K.; Liu, J.; Urtasun, R. Octsqueeze: Octree-structured entropy model for lidar compression. In Proceedings of the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1313–1323. [Google Scholar]
- Biswas, S.; Liu, J.; Wong, K.; Wang, S.; Urtasun, R. Muscle: Multi sweep compression of lidar using deep entropy models. Adv. Neural Inf. Process. Syst. 2020, 33, 22170–22181. [Google Scholar]
- Wang, W.; Xu, Y.; Vishwanath, B.; Zhang, K.; Zhang, L. Improved Geometry Coding for Spinning LiDAR Point Cloud Compression. In Proceedings of the 2024 IEEE International Symposium on Circuits and Systems (ISCAS), Singapore, 19–22 May 2024; pp. 1–5. [Google Scholar]
- Li, L.; Li, Z.; Liu, S.; Li, H. Frame-level rate control for geometry-based LiDAR point cloud compression. IEEE Trans. Multimed. 2022, 25, 3855–3867. [Google Scholar] [CrossRef]
- He, Y.; Li, G.; Shao, Y.; Wang, J.; Chen, Y.; Liu, S. A point cloud compression framework via spherical projection. In Proceedings of the 2020 IEEE International Conference on Visual Communications and Image Processing (VCIP), Macau, China, 1–4 December 2020; pp. 62–65. [Google Scholar]
- Varischio, A.; Mandruzzato, F.; Bullo, M.; Giordani, M.; Testolina, P.; Zorzi, M. Hybrid point cloud semantic compression for automotive sensors: A performance evaluation. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Chang, R.-I.; Chu, Y.-H.; Wei, L.-C.; Wang, C.-H. Bounded-error-pruned sensor data compression for energy-efficient IoT of environmental intelligence. Appl. Sci. 2020, 10, 6512. [Google Scholar] [CrossRef]
- Chang, R.-I.; Li, M.-H.; Chuang, P.; Lin, J.-W. Bounded error data compression and aggregation in wireless sensor networks. In Smart Sensors Networks; Elsevier: Amsterdam, The Netherlands, 2017; pp. 143–157. [Google Scholar]
- Chang, R.-I.; Tsai, J.-H.; Wang, C.-H. Edge computing of online bounded-error query for energy-efficient IoT sensors. Sensors 2022, 22, 4799. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Fan, H.; Su, H.; Guibas, L.J. A point set generation network for 3D object reconstruction from a single image. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 605–613. [Google Scholar]
- Mescheder, L.; Oechsle, M.; Niemeyer, M.; Nowozin, S.; Geiger, A. Occupancy Networks: Learning 3D Reconstruction in Function Space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 4460–4470. [Google Scholar]
- He, Y.; Ren, X.; Tang, D.; Zhang, Y.; Xue, X.; Fu, Y. Density-preserving deep point cloud compression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 843–852. [Google Scholar]
- Remelli, E.; Gojcic, Z.; Ortner, T.; Wieser, A.; Guibas, L.J.; Varanasi, K. Deep Implicit Moving Least-Squares Functions for 3D Reconstruction. arXiv 2021, arXiv:2103.12391. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Key Idea | Time Complexity |
|---|---|---|
| Huffman | Frequency-based byte encoding (baseline) | |
| EB-HC (Axis) | Merge integer coords along x, y, z + Huffman | |
| EB-HC (L2) | Merge integer coords in 3D distance + Huffman | |
| EB-3D (Axis) | Octree subdivision (per dimension) | |
| EB-3D (L2) | Octree subdivision (radial check) | |
| EB-HC-3D (Axis) | Combine octree + Huffman (axis-based) | |
| EB-HC-3D (L2) | Combine octree + Huffman (L2-based) |
| Symbol | Definition |
|---|---|
| CR | Compression ratio, defined as the ratio of the number of bits in the compressed bitstream to that of the raw quantized data. |
| Encoding time, measured in seconds. This is the time required to compress a point cloud. | |
| Decoding time, measured in seconds. This is the time required to decompress the data. | |
| Axis-wise error, defined as the maximum absolute deviation along any coordinate between an original point and its reconstruction . | |
| Euclidean (L2) error, defined as the Euclidean distance between the original point and its reconstruction . | |
| CD | A local geometric completeness metric: A lower CD indicates fewer small-scale errors. |
| Occupancy IoU | A global volumetric completeness metric: . A higher IoU indicates better overall coverage |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, R.-I.; Hsu, T.-W.; Yang, C.; Chen, Y.-T. Bounded-Error LiDAR Compression for Bandwidth-Efficient Cloud-Edge In-Vehicle Data Transmission. Electronics 2025, 14, 908. https://doi.org/10.3390/electronics14050908
Chang R-I, Hsu T-W, Yang C, Chen Y-T. Bounded-Error LiDAR Compression for Bandwidth-Efficient Cloud-Edge In-Vehicle Data Transmission. Electronics. 2025; 14(5):908. https://doi.org/10.3390/electronics14050908
Chicago/Turabian StyleChang, Ray-I, Ting-Wei Hsu, Chih Yang, and Yen-Ting Chen. 2025. "Bounded-Error LiDAR Compression for Bandwidth-Efficient Cloud-Edge In-Vehicle Data Transmission" Electronics 14, no. 5: 908. https://doi.org/10.3390/electronics14050908
APA StyleChang, R.-I., Hsu, T.-W., Yang, C., & Chen, Y.-T. (2025). Bounded-Error LiDAR Compression for Bandwidth-Efficient Cloud-Edge In-Vehicle Data Transmission. Electronics, 14(5), 908. https://doi.org/10.3390/electronics14050908