
Incremental Repair Feedback on Automated Assessment of Programming Assignments




Abstract
1. Introduction
- O1
- be nearly real-time, i.e., should be generated in less than one minute;
- O2
- be independent of the programming language in which students coded their solutions;
- O3
- be adjusted to the problem-solving (or algorithmic) strategy adopted by students;
- O4
- reveal details gradually as students repeat mistakes, similarly to human teaching assistants (i.e., starting by guiding the student to find the error in the code and ending by providing information on fixing the error);
- O5
- learn from submissions as they are processed.
2. Related Work
2.1. Program Clustering and Similarity
2.2. Automated Program Repair
2.3. Automated Feedback Generation vs. A Human Teaching Assistant
2.4. GenAI Feedback for Programming Assignments
2.5. Summary
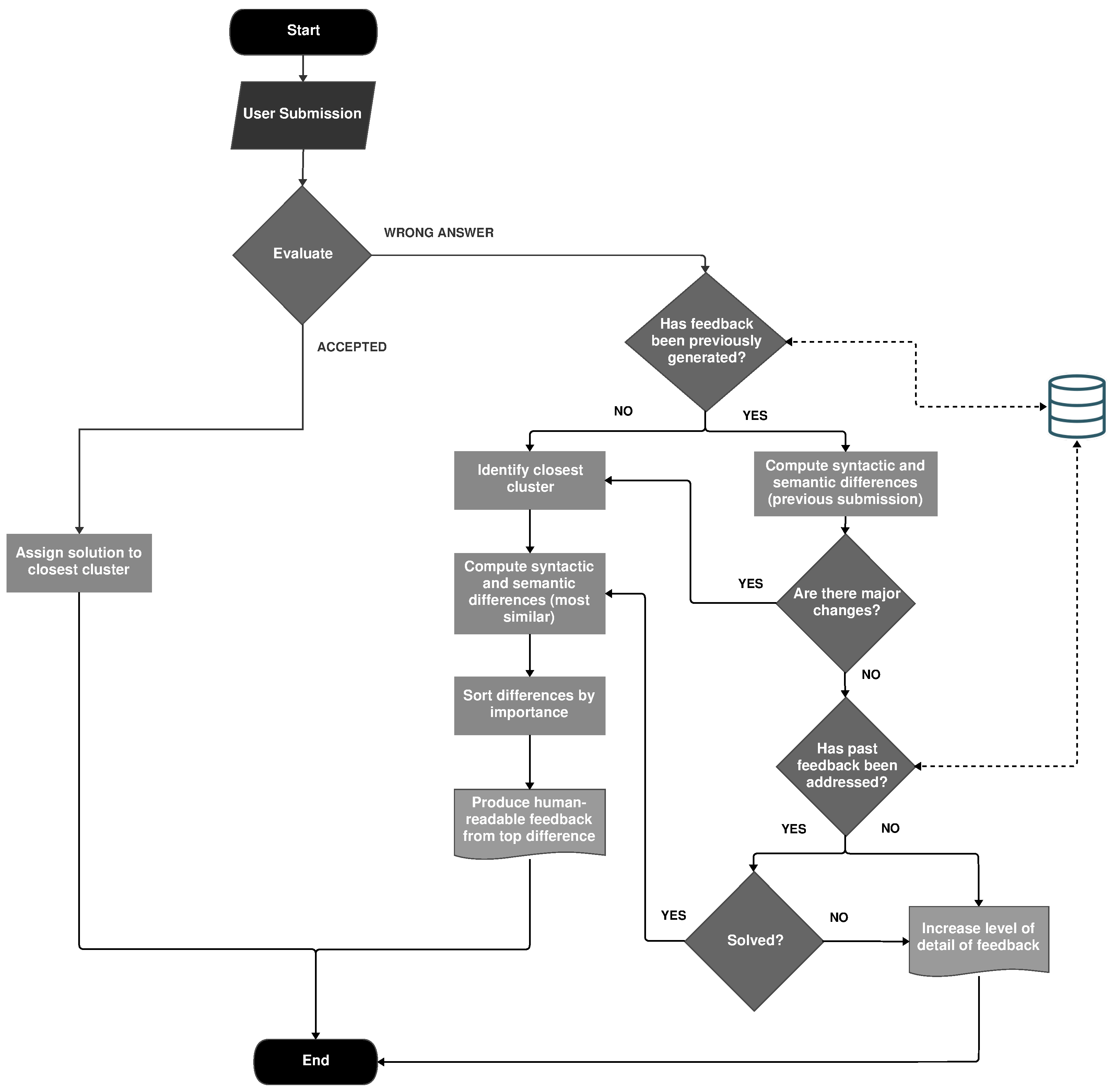
3. AsanasAssist
3.1. Program Clustering
3.2. Program Comparison
3.3. Feedback Generation
| Listing 1. Incorrect solution written in C++ to print the first N even numbers. | |
| #include <iostream> using namespace std; int main() { int N; cin >> N; for (int i = 1; i <= N; i++) { if (i == 0) cout << i << " "; } cout << endl; return 0; } | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
4. Evaluation
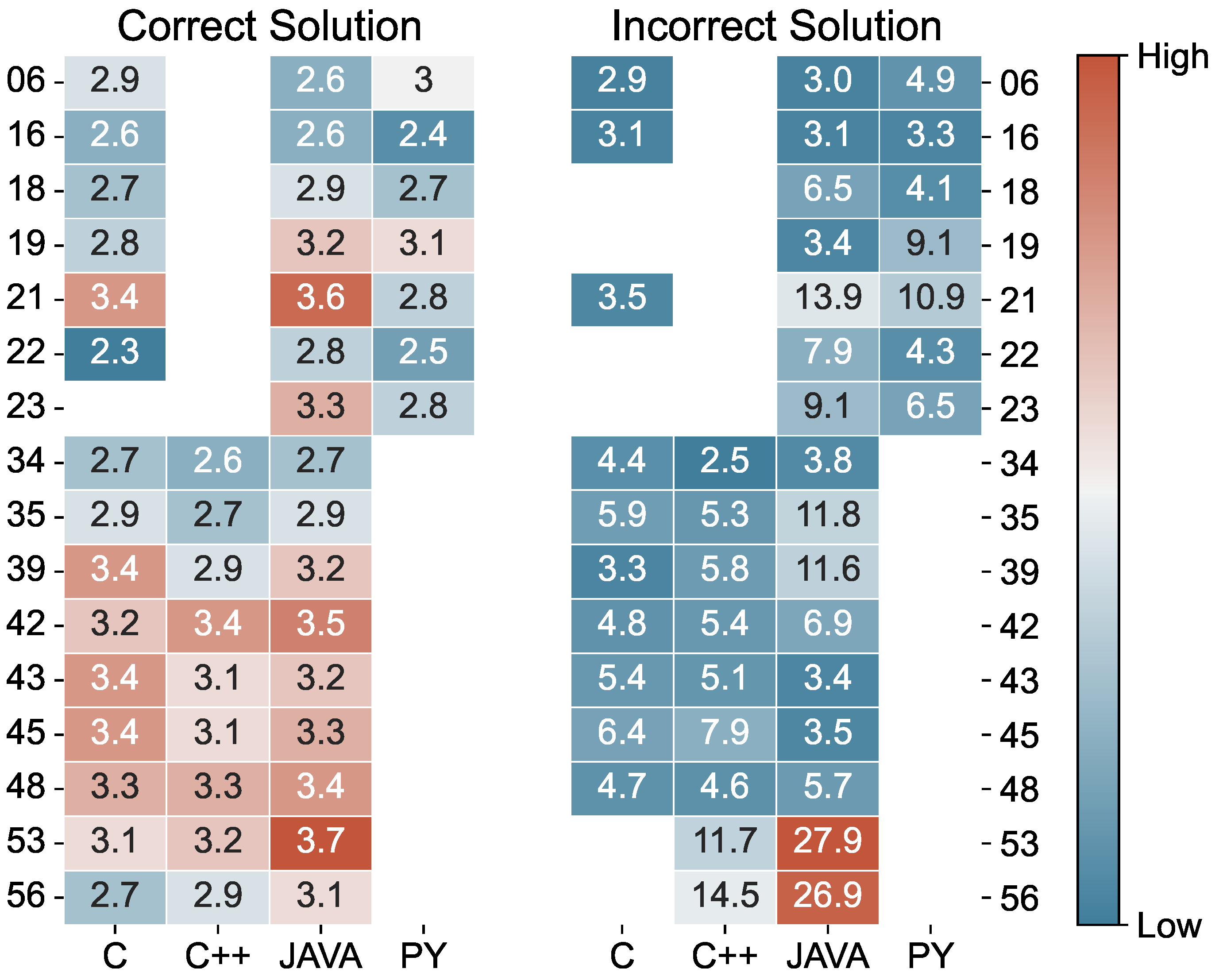
4.1. Run Time
4.2. AsanasAssist vs. Teaching Assistants
4.3. Discussion
4.4. Threats to Validity
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Paiva, J.C.; Leal, J.P.; Figueira, A. Automated Assessment in Computer Science Education: A State-of-the-Art Review. ACM Trans. Comput. Educ. 2022, 22, 1–40. [Google Scholar] [CrossRef]
- Ala-Mutka, K.; Uimonen, T.; Jarvinen, H.M. Supporting Students in C++ Programming Courses with Automatic Program Style Assessment. J. Inf. Technol. Educ. Res. 2004, 3, 245–262. [Google Scholar] [CrossRef] [PubMed]
- Souza, D.M.; Felizardo, K.R.; Barbosa, E.F. A Systematic Literature Review of Assessment Tools for Programming Assignments. In Proceedings of the 2016 IEEE 29th International Conference on Software Engineering Education and Training (CSEET), Dallas, TX, USA, 5–6 April 2016; pp. 147–156. [Google Scholar] [CrossRef]
- Keuning, H.; Jeuring, J.; Heeren, B. A Systematic Literature Review of Automated Feedback Generation for Programming Exercises. ACM Trans. Comput. Educ. 2019, 19, 1–43. [Google Scholar] [CrossRef]
- Kristiansen, N.G.; Nicolajsen, S.M.; Brabrand, C. Feedback on Student Programming Assignments: Teaching Assistants vs Automated Assessment Tool. In Proceedings of the 23rd Koli Calling International Conference on Computing Education Research, New York, NY, USA, 12–17 November 2024. Koli Calling ’23. [Google Scholar] [CrossRef]
- Paiva, J.C.; Figueira, A.; Leal, J.P. Bibliometric Analysis of Automated Assessment in Programming Education: A Deeper Insight into Feedback. Electronics 2023, 12, 2254. [Google Scholar] [CrossRef]
- Gulwani, S.; Radiček, I.; Zuleger, F. Automated clustering and program repair for introductory programming assignments. In Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation, Philadelphia, PA, USA, 18–22 June 2018; PLDI 2018. pp. 465–480. [Google Scholar] [CrossRef]
- Perry, D.M.; Kim, D.; Samanta, R.; Zhang, X. SemCluster: Clustering of Imperative Programming Assignments Based on Quantitative Semantic Features. In Proceedings of the 40th ACM SIGPLAN Conference on Programming Language Design and Implementation, Phoenix, AZ, USA, 22–26 June 2019; PLDI 2019. pp. 860–873. [Google Scholar] [CrossRef]
- Gao, L.; Wan, B.; Fang, C.; Li, Y.; Chen, C. Automatic Clustering of Different Solutions to Programming Assignments in Computing Education. In Proceedings of the ACM Conference on Global Computing Education, Chengdu, China, 9–19 May 2019; CompEd ’19. pp. 164–170. [Google Scholar] [CrossRef]
- Koivisto, T.; Hellas, A. Evaluating CodeClusters for Effectively Providing Feedback on Code Submissions. In Proceedings of the 2022 IEEE Frontiers in Education Conference (FIE), Uppsala, Sweden, 8–11 October 2022; pp. 1–9. [Google Scholar] [CrossRef]
- Li, S.; Xiao, X.; Bassett, B.; Xie, T.; Tillmann, N. Measuring code behavioral similarity for programming and software engineering education. In Proceedings of the 38th International Conference on Software Engineering Companion, Austin, TX, USA, 14–22 May 2016; ICSE ’16. pp. 501–510. [Google Scholar] [CrossRef]
- Kaleeswaran, S.; Santhiar, A.; Kanade, A.; Gulwani, S. Semi-Supervised Verified Feedback Generation. In Proceedings of the 2016 24th ACM SIGSOFT International Symposium on Foundations of Software Engineering, Seattle, WA, USA, 13–18 November 2016; FSE 2016. pp. 739–750. [Google Scholar] [CrossRef]
- Head, A.; Glassman, E.; Soares, G.; Suzuki, R.; Figueredo, L.; D’Antoni, L.; Hartmann, B. Writing Reusable Code Feedback at Scale with Mixed-Initiative Program Synthesis. In Proceedings of the Fourth (2017) ACM Conference on Learning @ Scale, Cambridge, MA, USA, 20–21 April 2017; L@S ’17. pp. 89–98. [Google Scholar] [CrossRef]
- Chow, S.; Yacef, K.; Koprinska, I.; Curran, J. Automated Data-Driven Hints for Computer Programming Students. In Proceedings of the Adjunct Publication of the 25th Conference on User Modeling, Adaptation and Personalization, Bratislava, Slovakia, 9–12 July 2017; UMAP ’17. pp. 5–10. [Google Scholar] [CrossRef]
- Emerson, A.; Smith, A.; Rodriguez, F.J.; Wiebe, E.N.; Mott, B.W.; Boyer, K.E.; Lester, J.C. Cluster-Based Analysis of Novice Coding Misconceptions in Block-Based Programming. In Proceedings of the 51st ACM Technical Symposium on Computer Science Education, Portland, OR, USA, 11–14 March 2020; SIGCSE ’20. pp. 825–831. [Google Scholar] [CrossRef]
- Nguyen, A.; Piech, C.; Huang, J.; Guibas, L. Codewebs: Scalable homework search for massive open online programming courses. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Republic of Korea, 7–11 April 2014; WWW ’14. pp. 491–502. [Google Scholar] [CrossRef]
- Glassman, E.L.; Scott, J.; Singh, R.; Guo, P.J.; Miller, R.C. OverCode: Visualizing Variation in Student Solutions to Programming Problems at Scale. ACM Trans. Comput.-Hum. Interact. 2015, 22, 1–35. [Google Scholar] [CrossRef]
- Wang, K.; Singh, R.; Su, Z. Dynamic Neural Program Embedding for Program Repair. arXiv 2017, arXiv:1711.07163. [Google Scholar]
- Goues, C.L.; Pradel, M.; Roychoudhury, A. Automated program repair. Commun. ACM 2019, 62, 56–65. [Google Scholar] [CrossRef]
- Gazzola, L.; Micucci, D.; Mariani, L. Automatic Software Repair: A Survey. IEEE Trans. Softw. Eng. 2019, 45, 34–67. [Google Scholar] [CrossRef]
- Könighofer, R.; Bloem, R. Automated error localization and correction for imperative programs. In Proceedings of the International Conference on Formal Methods in Computer-Aided Design, Austin, TX, USA, 30 October–2 November 2011; FMCAD ’11. pp. 91–100. [Google Scholar]
- Nguyen, H.D.T.; Qi, D.; Roychoudhury, A.; Chandra, S. SemFix: Program repair via semantic analysis. In Proceedings of the 2013 International Conference on Software Engineering, San Francisco, CA, USA, 18–26 May 2013; ICSE ’13. pp. 772–781. [Google Scholar]
- Debroy, V.; Wong, W.E. Using Mutation to Automatically Suggest Fixes for Faulty Programs. In Proceedings of the 2010 Third International Conference on Software Testing, Verification and Validation, Paris, France, 6–10 April 2010; pp. 65–74. [Google Scholar] [CrossRef]
- Forrest, S.; Nguyen, T.; Weimer, W.; Le Goues, C. A genetic programming approach to automated software repair. In Proceedings of the 11th Annual Conference on Genetic and Evolutionary Computation, Montreal, QC, Canada, 8–12 July 2009; GECCO ’09. pp. 947–954. [Google Scholar] [CrossRef]
- Weimer, W.; Forrest, S.; Le Goues, C.; Nguyen, T. Automatic program repair with evolutionary computation. Commun. ACM 2010, 53, 109–116. [Google Scholar] [CrossRef]
- Zhang, Q.; Fang, C.; Ma, Y.; Sun, W.; Chen, Z. A Survey of Learning-based Automated Program Repair. ACM Trans. Softw. Eng. Methodol. 2023, 33, 1–69. [Google Scholar] [CrossRef]
- Yi, J.; Ahmed, U.Z.; Karkare, A.; Tan, S.H.; Roychoudhury, A. A feasibility study of using automated program repair for introductory programming assignments. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, Paderborn, Germany, 4–8 September 2017; ESEC/FSE 2017. pp. 740–751. [Google Scholar] [CrossRef]
- Le Goues, C.; Nguyen, T.; Forrest, S.; Weimer, W. GenProg: A Generic Method for Automatic Software Repair. IEEE Trans. Softw. Eng. 2012, 38, 54–72. [Google Scholar] [CrossRef]
- Weimer, W.; Fry, Z.P.; Forrest, S. Leveraging program equivalence for adaptive program repair: Models and first results. In Proceedings of the 28th IEEE/ACM International Conference on Automated Software Engineering, Silicon Valley, CA, USA, 11–15 November 2013; ASE ’13. pp. 356–366. [Google Scholar] [CrossRef]
- Long, F.; Rinard, M. Automatic patch generation by learning correct code. In Proceedings of the 43rd Annual ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, St. Petersburg, FL, USA, 20–22 January 2016; POPL ’16. pp. 298–312. [Google Scholar] [CrossRef]
- Mechtaev, S.; Yi, J.; Roychoudhury, A. Angelix: Scalable multiline program patch synthesis via symbolic analysis. In Proceedings of the 38th International Conference on Software Engineering, Austin, TX, USA, 14–22 May 2016; ICSE ’16. pp. 691–701. [Google Scholar] [CrossRef]
- Singh, R.; Gulwani, S.; Solar-Lezama, A. Automated feedback generation for introductory programming assignments. In Proceedings of the 34th ACM SIGPLAN Conference on Programming Language Design and Implementation, Seattle, WA, USA, 16–19 June 2013; PLDI ’13. pp. 15–26. [Google Scholar] [CrossRef]
- Rolim, R.; Soares, G.; D’Antoni, L.; Polozov, O.; Gulwani, S.; Gheyi, R.; Suzuki, R.; Hartmann, B. Learning syntactic program transformations from examples. In Proceedings of the 39th International Conference on Software Engineering, Buenos Aires, Argentina, 20–28 May 2017; ICSE ’17. pp. 404–415. [Google Scholar] [CrossRef]
- Rivers, K.; Koedinger, K.R. Data-Driven Hint Generation in Vast Solution Spaces: A Self-Improving Python Programming Tutor. Int. J. Artif. Intell. Educ. 2017, 27, 37–64. [Google Scholar] [CrossRef]
- Wang, K.; Singh, R.; Su, Z. Search, align, and repair: Data-driven feedback generation for introductory programming exercises. In Proceedings of the 39th ACM SIGPLAN Conference on Programming Language Design and Implementation, Philadelphia, PA, USA, 18–22 June 2018; PLDI 2018. pp. 481–495. [Google Scholar] [CrossRef]
- Ihantola, P.; Ahoniemi, T.; Karavirta, V.; Seppälä, O. Review of recent systems for automatic assessment of programming assignments. In Proceedings of the 10th Koli Calling International Conference on Computing Education Research, Koli, Finland, 28–31 October 2010; Koli Calling ’10. pp. 86–93. [Google Scholar] [CrossRef]
- Messer, M.; Brown, N.C.C.; Kölling, M.; Shi, M. Automated Grading and Feedback Tools for Programming Education: A Systematic Review. ACM Trans. Comput. Educ. 2024, 24, 1–43. [Google Scholar] [CrossRef]
- Leite, A.; Blanco, S.A. Effects of Human vs. Automatic Feedback on Students’ Understanding of AI Concepts and Programming Style. In Proceedings of the 51st ACM Technical Symposium on Computer Science Education, Portland, OR, USA, 11–14 March 2020; SIGCSE ’20. pp. 44–50. [Google Scholar] [CrossRef]
- Feldman, M.Q.; Wang, Y.; Byrd, W.E.; Guimbretière, F.; Andersen, E. Towards answering “Am I on the right track?” automatically using program synthesis. In Proceedings of the 2019 ACM SIGPLAN Symposium on SPLASH-E, New York, NY, USA, 25 October 2019; SPLASH-E 2019. pp. 13–24. [Google Scholar] [CrossRef]
- Ahmed, U.Z.; Sindhgatta, R.; Srivastava, N.; Karkare, A. Targeted example generation for compilation errors. In Proceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering, San Diego, CA, USA, 11–15 November 2020; ASE ’19. pp. 327–338. [Google Scholar] [CrossRef]
- Finnie-Ansley, J.; Denny, P.; Luxton-Reilly, A.; Santos, E.A.; Prather, J.; Becker, B.A. My AI Wants to Know if This Will Be on the Exam: Testing OpenAI’s Codex on CS2 Programming Exercises. In Proceedings of the 25th Australasian Computing Education Conference, Melbourne, Australia, 30 January–3 February 2023; ACE ’23. pp. 97–104. [Google Scholar] [CrossRef]
- Denny, P.; Kumar, V.; Giacaman, N. Conversing with Copilot: Exploring Prompt Engineering for Solving CS1 Problems Using Natural Language. In Proceedings of the 54th ACM Technical Symposium on Computer Science Education V. 1, Toronto, ON, Canada, 15–18 March 2023; SIGCSE 2023. pp. 1136–1142. [Google Scholar] [CrossRef]
- Barke, S.; James, M.B.; Polikarpova, N. Grounded Copilot: How Programmers Interact with Code-Generating Models. Proc. ACM Program. Lang. 2023, 7, 85–111. [Google Scholar] [CrossRef]
- Prather, J.; Reeves, B.N.; Denny, P.; Becker, B.A.; Leinonen, J.; Luxton-Reilly, A.; Powell, G.; Finnie-Ansley, J.; Santos, E.A. “It’s Weird That it Knows What I Want”: Usability and Interactions with Copilot for Novice Programmers. ACM Trans. Comput.-Hum. Interact. 2023, 31, 1–31. [Google Scholar] [CrossRef]
- Zastudil, C.; Rogalska, M.; Kapp, C.; Vaughn, J.; MacNeil, S. Generative AI in Computing Education: Perspectives of Students and Instructors. arXiv 2023. [Google Scholar] [CrossRef]
- Dunder, N.; Lundborg, S.; Wong, J.; Viberg, O. Kattis vs ChatGPT: Assessment and Evaluation of Programming Tasks in the Age of Artificial Intelligence. In Proceedings of the 14th Learning Analytics and Knowledge Conference, Kyoto, Japan, 18–22 March 2024; LAK ’24. pp. 821–827. [Google Scholar] [CrossRef]
- Prather, J.; Reeves, B.N.; Leinonen, J.; MacNeil, S.; Randrianasolo, A.S.; Becker, B.A.; Kimmel, B.; Wright, J.; Briggs, B. The Widening Gap: The Benefits and Harms of Generative AI for Novice Programmers. In Proceedings of the 2024 ACM Conference on International Computing Education Research—Volume 1, Melbourne, Australia, 13–15 August 2024; ICER ’24. pp. 469–486. [Google Scholar] [CrossRef]
- Paiva, J.C.; Leal, J.P.; Figueira, Á. Clustering source code from automated assessment of programming assignments. Int. J. Data Sci. Anal. 2024. [Google Scholar] [CrossRef]
- Weiss, K.; Banse, C. A Language-Independent Analysis Platform for Source Code. arXiv 2022. [Google Scholar] [CrossRef]
- Fraunhofer AISEC. Code Property Graph. 2023. Available online: https://fraunhofer-aisec.github.io/cpg/ (accessed on 20 May 2023).
- Yamaguchi, F.; Golde, N.; Arp, D.; Rieck, K. Modeling and Discovering Vulnerabilities with Code Property Graphs. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 18–21 May 2014; pp. 590–604. [Google Scholar] [CrossRef]
- Sculley, D. Web-Scale k-Means Clustering. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 29–30 April 2010; WWW ’10. pp. 1177–1178. [Google Scholar] [CrossRef]
- Falleri, J.R.; Morandat, F.; Blanc, X.; Martinez, M.; Monperrus, M. Fine-grained and accurate source code differencing. In Proceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering, Vasteras, Sweden, 15–19 September 2014; ASE ’14. pp. 313–324. [Google Scholar] [CrossRef]
- Falleri, J.-R. GumTree Languages. 2023. Available online: https://github.com/GumTreeDiff/gumtree/wiki/Languages (accessed on 17 February 2025).
- Paiva, J.C.; Leal, J.P.; Figueira, Á. PROGpedia: Collection of source-code submitted to introductory programming assignments. Data Brief 2023, 46, 108887. [Google Scholar] [CrossRef]
- Parihar, S.; Dadachanji, Z.; Singh, P.K.; Das, R.; Karkare, A.; Bhattacharya, A. Automatic Grading and Feedback using Program Repair for Introductory Programming Courses. In Proceedings of the 2017 ACM Conference on Innovation and Technology in Computer Science Education, Bologna, Italy, 3–5 July 2017; ITiCSE ’17. pp. 92–97. [Google Scholar] [CrossRef]
- Yusoff, M.S.B. ABC of Response Process Validation and Face Validity Index Calculation. Educ. Med. J. 2019, 11, 55–61. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool | O1 | O2 | O3 | O4 | O5 |
|---|---|---|---|---|---|
| CLARA [7] | ✓ | ✓ | |||
| Overcode [17] | ✓ | ||||
| SemCluster [8] | ✓ | ✓ | |||
| Sarfgen [35] | ✓ | ✓ | ✓ |
| Feature | Description | Origin |
|---|---|---|
| connected_components | Number of connected components in the intra-procedural control flow graph. | CFG |
| loop_statements | Number of loop statements. | CFG |
| conditional_statements | Number of conditional statements. | CFG |
| cycles | Number of cycles in the control flow graph. | CFG |
| paths | Number of different paths in the control flow graph. | CFG |
| cyclomatic_complexity | Quantitative measure of the number of possible execution paths. | CFG |
| variable_count | Number of used variables in the program. | DFG |
| total_reads | Total number of read operations on variables. | DFG |
| total_writes | Total number of write operations on variables. | DFG |
| max_reads | Maximum number of read operations on a single variable. | DFG |
| max_writes | Maximum number of write operations on a single variable. | DFG |
| Level | Message |
|---|---|
| Localization | Some code is missing at or near the if block. |
| Some code is missing at or near line 11. | |
| Some code is missing at or near line 11 column 10. | |
| Repair | A binary operation is missing in the if condition at or near line 11 column 10. |
| A binary operation (%) is missing in the if condition at or near line 11 column 10. | |
| The if condition must be ’i % 2 == 0’ at or near line 11. |
| ID | # of Submissions | Avg. LoC | Nr. of Clusters | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| C | C++ | J | PY | C | C++ | J | PY | C | C++ | J | PY | |
| 06 | 40 | - | 100 | 64 | 30 | - | 36 | 22 | 4 | - | 5 | 4 |
| 16 | 20 | - | 105 | 30 | 32 | - | 45 | 17 | 4 | - | 4 | 4 |
| 18 | 1 | - | 61 | 5 | 73 | - | 166 | 57 | 1 | - | 3 | 1 |
| 19 | 2 | - | 66 | 139 | 88 | - | 141 | 98 | 1 | - | 2 | 1 |
| 21 | 2 | - | 21 | 112 | 137 | - | 227 | 89 | 1 | - | 3 | 3 |
| 22 | 3 | - | 52 | 60 | 55 | - | 90 | 28 | 3 | - | 7 | 5 |
| 23 | - | - | 71 | 38 | 141 | - | 189 | 63 | 1 | - | 3 | 1 |
| 34 | 172 | 26 | 205 | - | 50 | 34 | 31 | - | 7 | 4 | 5 | - |
| 35 | 76 | 24 | 140 | - | 60 | 60 | 60 | - | 4 | 3 | 4 | - |
| 39 | 75 | 25 | 154 | - | 96 | 77 | 88 | - | 7 | 4 | 8 | - |
| 42 | 58 | 26 | 138 | - | 67 | 66 | 65 | - | 9 | 4 | 4 | - |
| 43 | 77 | 32 | 178 | - | 52 | 49 | 52 | - | 6 | 2 | 3 | - |
| 45 | 54 | 21 | 148 | - | 49 | 50 | 51 | - | 8 | 2 | 5 | - |
| 48 | 29 | 24 | 136 | - | 49 | 49 | 56 | - | 2 | 3 | 3 | - |
| 53 | 1 | 43 | 152 | - | 110 | 119 | 148 | - | 1 | 4 | 3 | - |
| 56 | 1 | 22 | 85 | - | 76 | 95 | 110 | - | 1 | 4 | 4 | - |
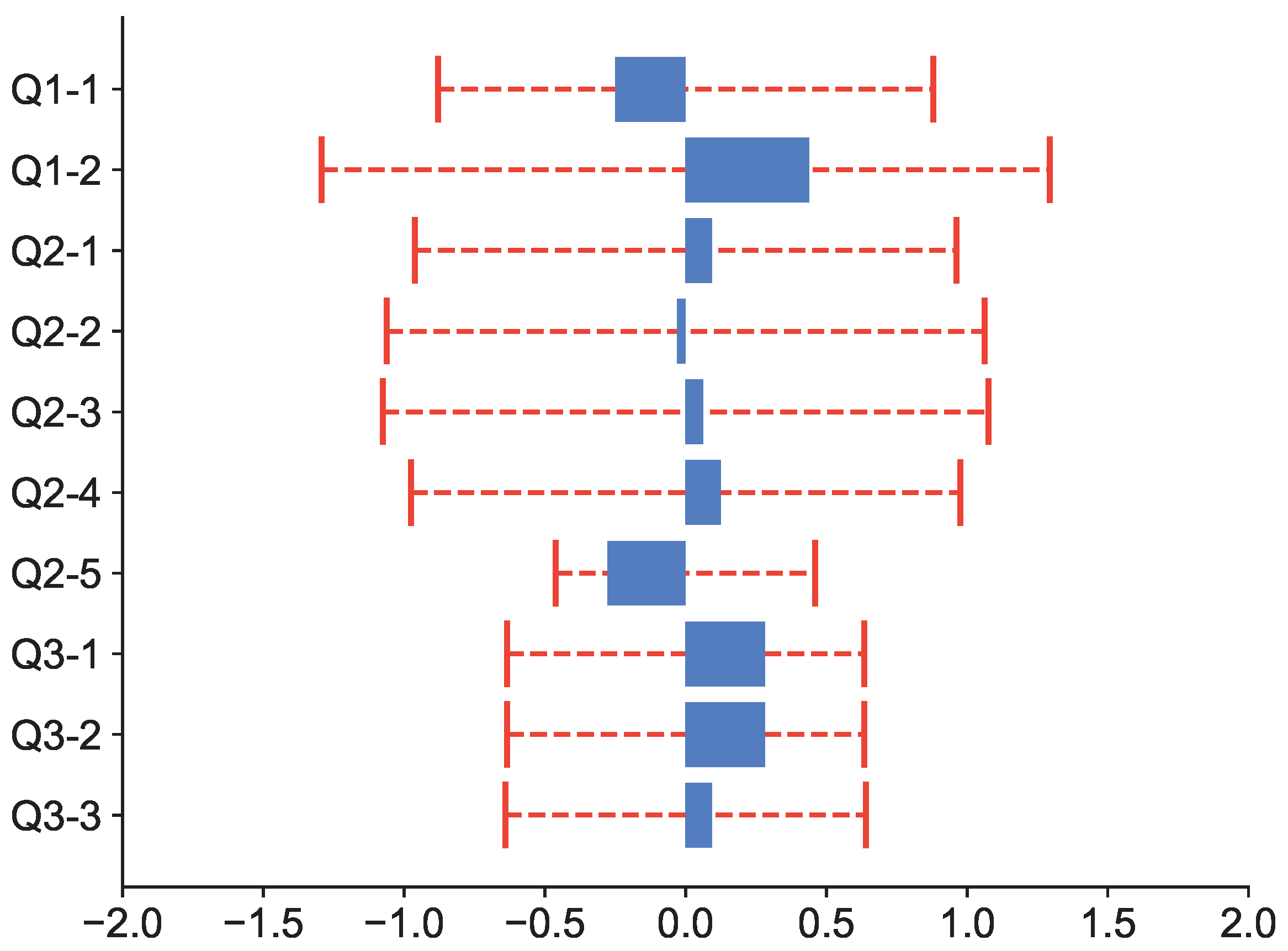
| Item | Gender () | Experience () | ||
|---|---|---|---|---|
| () | () | |||
| Q1-1 | 7.815 | 3.581 | 21.026 | 10.240 |
| Q1-2 | 9.488 | 4.707 | 21.026 | 13.030 |
| Q2-1 | 9.488 | 2.402 | 21.026 | 17.410 |
| Q2-2 | 7.815 | 4.258 | 16.919 | 7.978 |
| Q2-3 | 9.488 | 0.922 | 16.919 | 17.005 |
| Q2-4 | 7.815 | 4.080 | 12.592 | 3.413 |
| Q2-5 | 5.991 | 1.974 | 12.592 | 7.858 |
| Q3-1 | 5.991 | 0.922 | 12.592 | 2.453 |
| Q3-2 | 5.991 | 0.922 | 7.815 | 3.467 |
| Q3-3 | 7.815 | 3.898 | 16.919 | 8.583 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paiva, J.C.; Leal, J.P.; Figueira, Á. Incremental Repair Feedback on Automated Assessment of Programming Assignments. Electronics 2025, 14, 819. https://doi.org/10.3390/electronics14040819
Paiva JC, Leal JP, Figueira Á. Incremental Repair Feedback on Automated Assessment of Programming Assignments. Electronics. 2025; 14(4):819. https://doi.org/10.3390/electronics14040819
Chicago/Turabian StylePaiva, José Carlos, José Paulo Leal, and Álvaro Figueira. 2025. "Incremental Repair Feedback on Automated Assessment of Programming Assignments" Electronics 14, no. 4: 819. https://doi.org/10.3390/electronics14040819
APA StylePaiva, J. C., Leal, J. P., & Figueira, Á. (2025). Incremental Repair Feedback on Automated Assessment of Programming Assignments. Electronics, 14(4), 819. https://doi.org/10.3390/electronics14040819