
A Lightweight Network Based on YOLOv8 for Improving Detection Performance and the Speed of Thermal Image Processing


Abstract
1. Introduction
2. Related Work in Object Detection
2.1. Traditional Thermal Object Detection
2.2. Deep Learning-Based Object Detection
2.3. Lightweight Techniques
2.4. Attention Mechanism
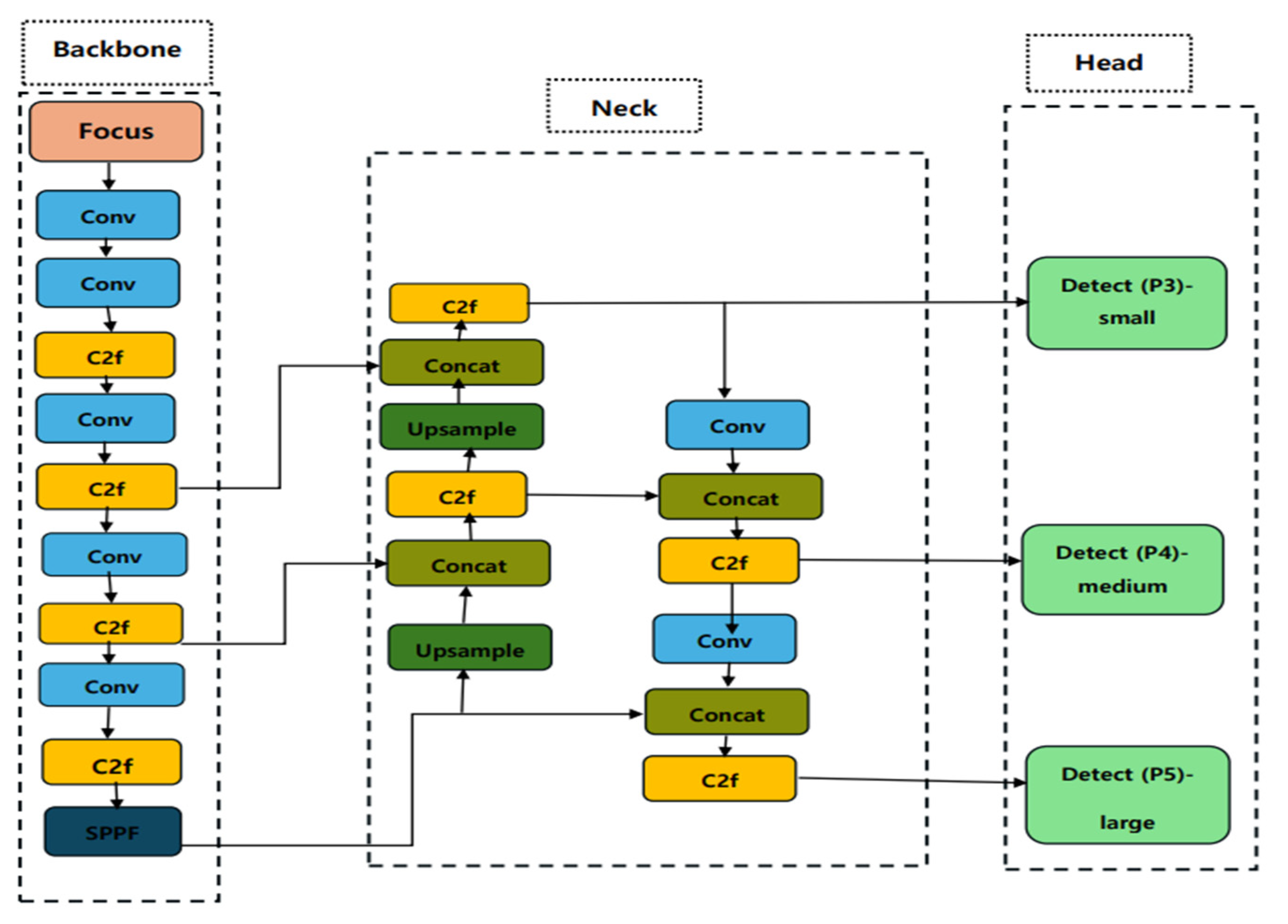
3. The Proposed System
4. Experiments and Results
4.1. Experiment Implementation Details
4.2. Evaluation Indicators and Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. R-CNN (Region-based Convolutional Neural Networks) Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 23 June 2014. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Diwan, T.; Anirudh, G.; Tembhurne, J.V. Object detection using YOLO: Challenges, architectural successors, datasets and applications. Multimed. Tools Appl. 2023, 82, 9243–9275. [Google Scholar] [CrossRef] [PubMed]
- Yoon, H.-S.; Kim, E.-T. YOLOv5-based Lightweight Methodology for Real-time Thermal Image Object Detection for Edge Devices. J. Broadcast Eng. 2024, 29, 703–712. [Google Scholar] [CrossRef]
- Chen, X.; Liu, L.; Zhang, J.; Shao, W. Infrared image denoising based on the variance-stabilizing transform and the dual-domain filter. Digit. Signal Process. 2021, 113, 103012. [Google Scholar] [CrossRef]
- Yang, H.; Tong, Y.; Cao, Z.; Chen, Z. Infrared image enhancement algorithm based on improved wavelet threshold function and weighted guided filtering. In Proceedings of the 2nd International Conference on Electronic Information and Communication Engineering (EICE 2023), Guangzhou, China, 13–15 January 2023. [Google Scholar]
- Zou, Y.; Zhang, L.; Liu, C.; Wang, B.; Hu, Y.; Chen, Q. Super-resolution reconstruction of infrared images based on a convolutional neural network with skip connections. Opt. Lasers Eng. 2021, 146, 106717. [Google Scholar] [CrossRef]
- Brehar, R.; Vancea, F.; Marita, T.; Vancea, C.; Nedevschi, S. Object Detection in Infrared Images with Different Spectra. In Proceedings of the IEEE 15th International Conference on Intelligent Computer Communication and Processing, Cluj-Napoca, Romania, 7–9 September 2019. [Google Scholar]
- Aboalia, H.; Hussein, S.; Mahmoud, A. Infrared Multi-Object Detection Using Deep Learning. In Proceedings of the 2024 14th International Conference on Electrical Engineering (ICEENG), Cairo, Egypt, 21–23 May 2024. [Google Scholar]
- Tsai, P.-F.; Liao, C.-H.; Yuan, S.-M. Using Deep Learning with Thermal Imaging for Human Detection in Heavy Smoke Scenarios. Sensors 2022, 22, 5351. [Google Scholar] [CrossRef] [PubMed]
- Park, J.; Chen, J.; Cho, Y.K.; Kang, D.Y.; Son, B.J. CNN-Based Person Detection Using Infrared Images for Night-Time Intrusion Warning Systems. Sensors 2020, 20, 34. [Google Scholar] [CrossRef] [PubMed]
- Banuls, A.; Mandow, A.; Vazquez-Martın, R.; Morales, J.; Garcıa-Cerezo, A. Object Detection from Thermal Infrared and Visible Light Cameras in Search and Rescue Scenes. In Proceedings of the 2020 IEEE International Symposium on Safety, Security, and Rescue Robotics (SSRR), Abu Dhabi, United Arab Emirates, 4–6 November 2020. [Google Scholar]
- Agrawal, K.; Subramanian, A. Enhancing Object Detection in Adverse Conditions using Thermal Imaging. arXiv 2019, arXiv:1909.13551v1. [Google Scholar]
- Li, S.; Li, Y.; Li, Y.; Li, M.; Xu, X. YOLO-FIRI: Improved YOLOv5 for Infrared Image Object Detection. IEEE Access 2021, 9, 141861–141875. [Google Scholar] [CrossRef]
- Brehar, R.; Vancea, F.; Marita, T.; Vancea, C.; Nedevschi, S. Object Detection in Monocular Infrared Images Using Classification. In Proceedings of the 2019 IEEE 15th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 5–7 September 2019. [Google Scholar]
- Chen, Z.; Geng, A.; Jiang, J.; Lu, J.; Wu, D. Infra-YOLO: Efficient Neural Network Structure with Model Compression for Real-Time Infrared Small Object Detection. arXiv 2024, arXiv:2408.07455v1. [Google Scholar]
- Yoon, H.S.; Kim, E.T. Lightweight YOLOv5-based Attention Model for Real-Time Thermal Image Object Detection. In Proceedings of the Korea Institute of Communications and Information Sciences (KICS) Conference, Seoul, Republic of Korea, 6–8 September 2023; pp. 753–754. [Google Scholar]
- Shapiro, V.A.; Veleva, P.K.; Sgurev, V.S. An adaptive method for image thresholding. In Proceedings of the 11th IAPR International Conference on Pattern Recognition. Vol. III. Conference C: Image, Speech and Signal Analysis, Hague, The Netherlands, 30 August–1 September 1992. [Google Scholar]
- Jing, J.; Liu, S.; Wang, G.; Zhang, W.; Sun, C. Recent advances on image edge detection: A comprehensive review. Neurocomputing 2022, 503, 259–271. [Google Scholar] [CrossRef]
- Kutuk, Z.; Algan, G. Semantic Segmentation for Thermal Images: A Comparative Survey. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Girshick, R. Microsoft Research. Fast R-CNN. arXiv 2015, arXiv:1504.08083v2. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. arXiv 2018, arXiv:1703.06870v3. [Google Scholar]
- Li, Y.; Ren, F. Light-Weight RetinaNet for Object Detection. arXiv 2019, arXiv:1905.10011v1. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Google Research Brain Team. EfficientDet: Scalable and Efficient Object Detection. arXiv 2020, arXiv:1911.09070v7. [Google Scholar]
- Liao, K.-C.; Lau, J.; Hidayat, M. Aircraft Skin Damage Visual Testing System Using Lightweight Devices with YOLO: An Automated Real-Time Material Evaluation System. AI 2024, 5, 1793–1815. [Google Scholar] [CrossRef]
- YOLOv8. Available online: https://github.com/ultralytics/ultralytics (accessed on 6 February 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385v1. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L. Densely Connected Convolutional Networks. arXiv 2018, arXiv:1608.06993v5. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016, arXiv:1602.07360v4. [Google Scholar]
- Datta, S.K.; Shaikh, M.A.; Srihari, S.N.; Gao, M. Soft-Attention Improves Skin Cancer Classification Performance. arXiv 2021, arXiv:2105.03358v3. [Google Scholar]
- Malinowski, M.; Doersch, C.; Santoro, A.; Battaglia, P. Learning Visual Question Answering by Bootstrapping Hard Attention. arXiv 2018, arXiv:1808.00300v1. [Google Scholar]
- Datta, S.K.; Shaikh, M.A.; Hu, S.N.S.J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. arXiv 2017, arXiv:1707.01083v2. [Google Scholar]
- Wang, C.; Chen, Y.; Wu, Z.; Liu, B.; Tian, H.; Jiang, D.; Sun, X. Line-YOLO: An Efficient Detection Algorithm for Power Line Angle. Sensors 2025, 25, 876. [Google Scholar] [CrossRef]
- Zhang, N.; Tan, J.; Yan, K.; Feng, S. Lightweight UAV Landing Model Based on Visual Positioning. Sensors 2025, 25, 884. [Google Scholar] [CrossRef] [PubMed]
- Google Developers. Classification: Accuracy, Recall, Precision, and Related Metrics|Machine Learning|Google for Developers. Available online: https://developers.google.com/machine-learning/crash-course/classification/accuracy-precision-recall?hl=zh-cn (accessed on 4 February 2025).
- Datadocs. Available online: https://polakowo.io/datadocs/docs/deep-learning/object-detection#yolov3 (accessed on 6 February 2025).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Description |
|---|---|
| AI Performance | 275 TOPS |
| GPU | NVIDIA Ampere architecture, with 2048 NVIDIA CUDA cores and 64 tensor cores |
| CPU | 12-core Arm Cortex-A78AE v8.2 64-bit CPU 3 MB L2 + 6 MB L3 |
| Memory | 32 GB 256-bit LPDDR5 204.8 GB/s |
| Usage | Edge device |
| Category | Description |
|---|---|
| Array Format | 275 TOPS |
| Resolution | 640 × 480 |
| Temperature Range | to ~500 °C |
| Usage | Dataset and test camera |
| Hyperparameters | Value |
|---|---|
| Input | 640 × 480 |
| Learning rate | 0.001 |
| Decay | 0.0005 |
| Channels | 1 |
| Epochs | 100 |
| Batch size | 4 |
| Optimizer | Adam |
| Model | Precision | mAP@0.5 | Parameters | GFLOPs | FPS |
|---|---|---|---|---|---|
| 1. Yolov8s | 94% | 97% | 10M | 27.9 | 49.5 |
| 2. Yolov8s + P5 removal | 88.2% | 95.9% | 2.66M | 37 | 52.35 |
| 3. Yolov8s + P5 removal + GAM | 93.3% | 96% | 2.91M | 41.2 | 52.08 |
| 4. Yolov8s + P5 removal + I_GAM | 95.3% | 96.1% | 2.91M | 41.2 | 54.05 |
| 5. Yolov8s + P5 removal + I_GAM + DW | 96% | 96.9% | 2.52M | 38.4 | 55.86 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dinh, H.T.; Kim, E.-T. A Lightweight Network Based on YOLOv8 for Improving Detection Performance and the Speed of Thermal Image Processing. Electronics 2025, 14, 783. https://doi.org/10.3390/electronics14040783
Dinh HT, Kim E-T. A Lightweight Network Based on YOLOv8 for Improving Detection Performance and the Speed of Thermal Image Processing. Electronics. 2025; 14(4):783. https://doi.org/10.3390/electronics14040783
Chicago/Turabian StyleDinh, Huyen Trang, and Eung-Tae Kim. 2025. "A Lightweight Network Based on YOLOv8 for Improving Detection Performance and the Speed of Thermal Image Processing" Electronics 14, no. 4: 783. https://doi.org/10.3390/electronics14040783
APA StyleDinh, H. T., & Kim, E.-T. (2025). A Lightweight Network Based on YOLOv8 for Improving Detection Performance and the Speed of Thermal Image Processing. Electronics, 14(4), 783. https://doi.org/10.3390/electronics14040783