1. Introduction
Around 1.3 billion people, or 16% of the global population, are affected by disability [
1]. Therefore, traditional wheelchairs are important to disabled, elderly and sick people, because it can assist them with their mobility. With increasingly developing modern technology, many studies have been developing electric wheelchairs for supporting the movement of disabled and elderly people more safely and comfortably. Some input solutions such as joysticks, electronic controllers, and motors instead of using manual propulsion to easily enhance their movement. However, some people with severe disabilities cannot use such devices because they may have difficulty in controlling these types of wheelchairs. Thus, smart wheelchairs can be the better solution for them.
Human activity recognition is a matter of concern to be able to provide interactive services to disabled people in different environments. Furthermore, research on the recognition of different activities has emerged in recent years [
2,
3,
4]. By accurately identifying and analyzing body movements, this technology can assist individuals with mobility or communication limitations, providing them with greater autonomy and access to personalized support systems. These advancements have paved the way for groundbreaking applications in healthcare, smart homes, physical monitoring, and rehabilitation, enabling the development of increasingly adaptive and responsive systems that cater to user needs. The growing interest in this field underscores its immense potential to revolutionize human–computer interaction and enhance the quality of life for people across diverse contexts. In particular, disabled people have difficulty using traditional electric wheelchairs, because they lack motor skills, lack strength, or do not have the necessary vision. Therefore, the electric wheelchairs need function tools for performing movements such as automatic navigation, obstacle avoidance, control by hand gestures, or biological signals [
5,
6,
7]. Thus, this can make the movement easier for severely disabled people and the elderly in daily activities.
In recent years, many approaches have been proposed for improving from traditional wheelchairs to make smart ones safe and comfortable for disabled people. In particular, a number of systems in the smart wheelchairs have been developed with various control mechanisms or control models which could be controlled by head movements [
8]. In this study, an electric wheelchair was installed with a camera for taking pictures of the head movements and an Arduino Mega was used for processing and controlling on the robot operating system (ROS) platform. Using this model, the system attained an efficiency of over 76%. However, the cost of the system is still high. Another wheelchair system is that the wheelchair moved based on pupil tracking of human eyes [
9]. In particular, this system used a Philips microcontroller and the Viola–Jones algorithm for detecting human eyes based on RGB images collected from an RGB camera system. However, detecting the images and processing them for real-time applications is challenging and efficiency is achieved only at 70% to 90%. Therefore, this system can hardly be implemented in practice. Another study of electric wheelchairs tracked targets in front of the wheelchair using RGB images in [
10]. In this study, wheelchair motion control was performed based on person detection using the histogram of oriented gradients (HOG) algorithm [
11], person tracking using the continuously adaptive mean shift (CAMSHIFT) algorithm [
12], and motion detection. With this method, selecting a target from many human targets is a complex situation and the efficiency obtained is about 80%. With this solution, the system needs to improve much for real-time applications.
Furthermore, a solution for multimodal wheelchair control has been developed by Mahmud [
13]. The hardware system used an accelerometer for tracking head movements, a flexible glove sensor for tracking hands, and an RGB camera, a Raspberry Pi. Moreover, an improved VGG-8 model was proposed for eyes tracking and the efficiency of this system was about 90%. The limitation of this system is that it requires a tracking sensor to attach to the user’s body and designing the eye detection system is not user-friendly. Related to the electric wheelchair, a control system was developed based on iris movements [
14]. In this proposed system, the user can control wheelchair navigation by moving the iris in corresponding directions. In addition, the embedded programming language MATLAB was used to program the model, and the system responded control time longer than 5 s. Therefore, tracking iris movements can sometimes lead to false positives due to subconscious eye movements in real-life situations. Therefore, the system cannot perform navigation operations in real time and is difficult to apply in real situations. In another study, a wheelchair motion control system based on electrooculography (EOG) [
15], in which eye blinks and movements were recorded using simple electrodes placed closed to the eyes. Moreover, a controller and a threshold-based algorithm were applied for controlling the electric wheelchair. Therefore, the cost of the system is low, but placing the electrodes close to the eyes is a challenge for the user.
Table 1 describes studies that use deep learning for object detection and navigation in smart wheelchair applications, providing enhanced autonomy and perception for wheelchair users, improving navigation in both indoor and outdoor environments. In [
16,
17], they successfully integrated depth estimation and tracking, enabling better object detection and interaction with elements such as doors and handles. Similarly, some studies emphasize safety and obstacle avoidance, which are crucial for real-world deployment [
18,
19]. Other studies explore alternative control methods such as gaze tracking, which improves accessibility for users with severe disabilities [
20,
21,
22]. Despite these advantages, challenges remain in terms of real-time performance, cost, and environmental adaptability. Many approaches rely on computationally expensive deep learning models, which can limit implementation in low-power wheelchair systems. Studies such as [
19] attempt to improve efficiency, but real-time performance still requires optimization. Additionally, [
20] faces usability issues, such as unintended movements due to gaze control difficulties. In [
21], the limitation is by sensor constraints, as these rely on 2D range data or depth-based perception, which may not work well in crowded or dynamically changing environments. Moreover, the cost of integrating deep learning models, sensors, and computational hardware remains a major barrier, making widespread adoption challenging.
Recent advancements in YOLOv8n-based object detection have led to notable improvements across various domains. A study on small object detection in UAV images enhances the model with multi-scale feature fusion and a novel Wise-IoU loss function to improve the detection accuracy in complex environments. Meanwhile, an improved YOLOv8n algorithm integrates CARAFE, MultiSEAMHead, and TripleAttention mechanisms to refine feature extraction and detection precision. In autonomous driving, researchers developed SES-YOLOv8n, optimizing feature fusion with an SPPCSPC module for better real-time performance. Another work on smart indoor shopping environments enhances YOLOv8n’s accuracy, achieving a higher mean average precision (mAP) and F1 score compared to its baseline version. Lastly, an efficient optimized YOLOv8 model with extended vision (YOLO-EV) introduces a multi-branch group-enhanced fusion attention (MGEFA) module, significantly boosting feature extraction and detection capabilities. These innovations demonstrate the growing adaptability and effectiveness of YOLOv8n in object detection applications [
23,
24,
25,
26,
27].
Using hand gestures is one of the most popular means of human communication after spoken language, and we can say that hand gestures are meaningful or intentional movements of human hands and arms [
28,
29,
30]. Moreover, gesture recognition, a key technology in human–computer interaction, offers widespread applications in fields such as smart homes, healthcare, and sports training. Unlike traditional interaction methods using keyboards and mice, gesture-based interfaces provide a more natural, flexible, and intuitive way to transmit information, making them a focus of extensive research in recent times [
31]. Study [
32,
33] utilized a machine-based approach to identify hand gestures using surface electromyography (sEMG) signals recorded from forearm muscles. The research [
32] highlighted the necessity of selecting a subset of hand gestures to achieve accurate automated gesture recognition and proposed a method to optimize this selection for maximum sensitivity and specificity. A hand gesture-based control was proposed for electric wheelchairs [
34,
35]. In particular, an electric wheelchair was installed with an RGB depth camera to capture hand RGB images with depth information and a high-powered computer was used for detecting and track gestures [
34]. Therefore, the limitation of this proposed system is that the complexity of the environment can severely affect the performance of this system, and the cost of this system is a little bit high.
The hand gesture can be used as non-verbal communication methods in everyday life for expressing meanings. With these hand gestures, disabled people can move easier and more effectively using a smart wheelchair installed with modern devices. This paper will present the development of a smart wheelchair in which the user can control the speed and steering of the wheelchair to reach the desired target using hand gestures. Furthermore, the user can select one of the control functions by changing hand gestures. Additionally, the wheelchair can automatically detect and avoid obstacles to increase user safety. This article consists of four sections: In
Section 2, a smart wheelchair is introduced, including a designed hardware system to connect with the wheelchair for movement control. In addition, the hand gesture images are collected from a camera installed with the wheelchair and they are processed to produce ROI with hand gestures using MediaPipe before input to a YOLOv8n model for hand gestures recognition.
Section 3 describes the experimental results related to controlling the movement wheelchair and the evaluation of the recognized model using the proposed method. Finally,
Section 4 presents the conclusions about this research.
2. Materials and Methods
This section describes the implementation of the smart electric wheelchair system controlled by hand gesture commands. First, the system architecture of the electric wheelchair is outlined to provide a clear understanding of its components. Then, the process of hand gesture image collection is presented, including the proposed preprocessing method for creating hand landmark images, removing the background, and extracting the ROI of hand gestures, which helps improve the accuracy of the classifier. Additionally, the hand gesture image classification model is presented along with a description of the electrical circuit used to control the electric wheelchair system.
2.1. Architecture of a Smart Wheelchair
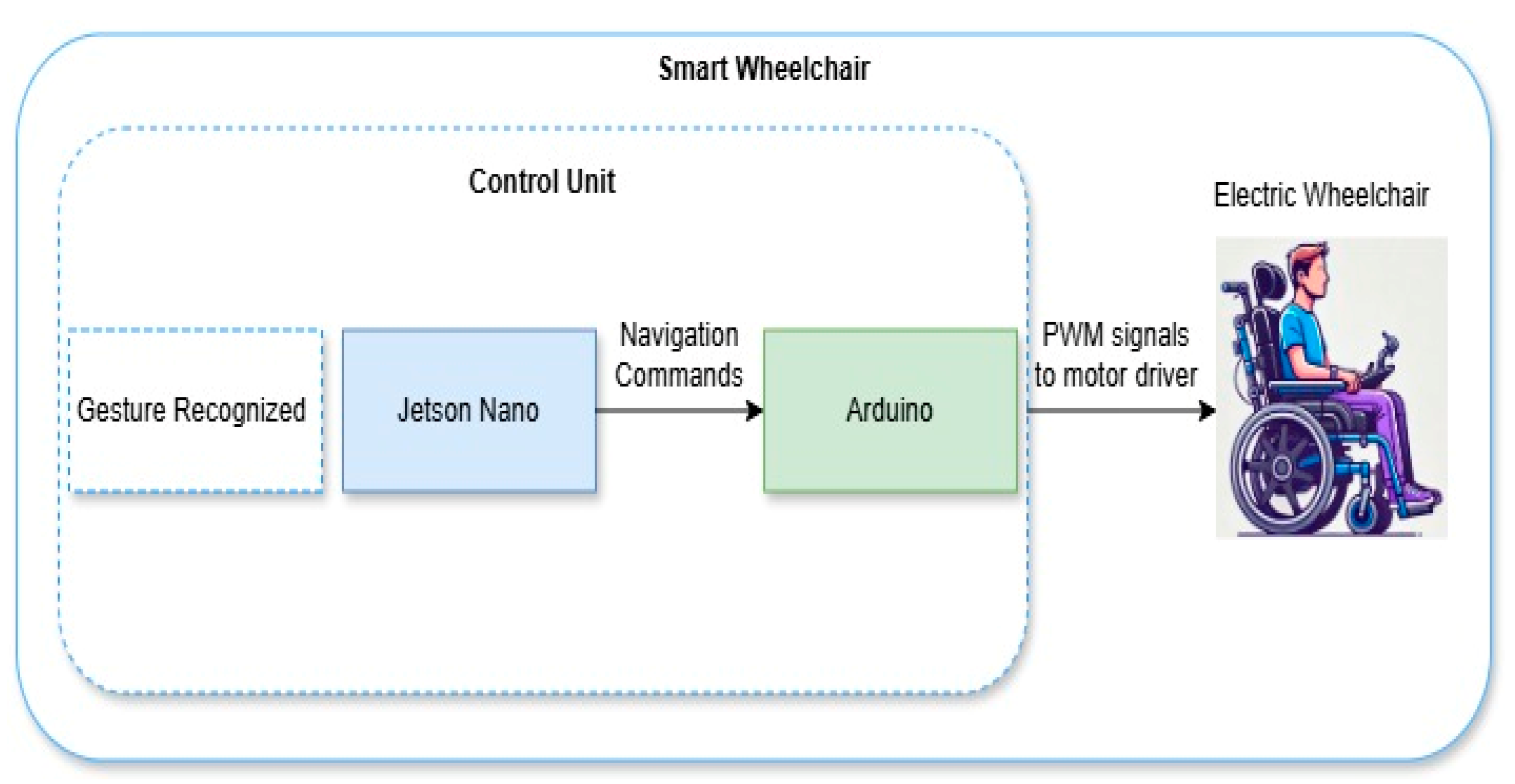
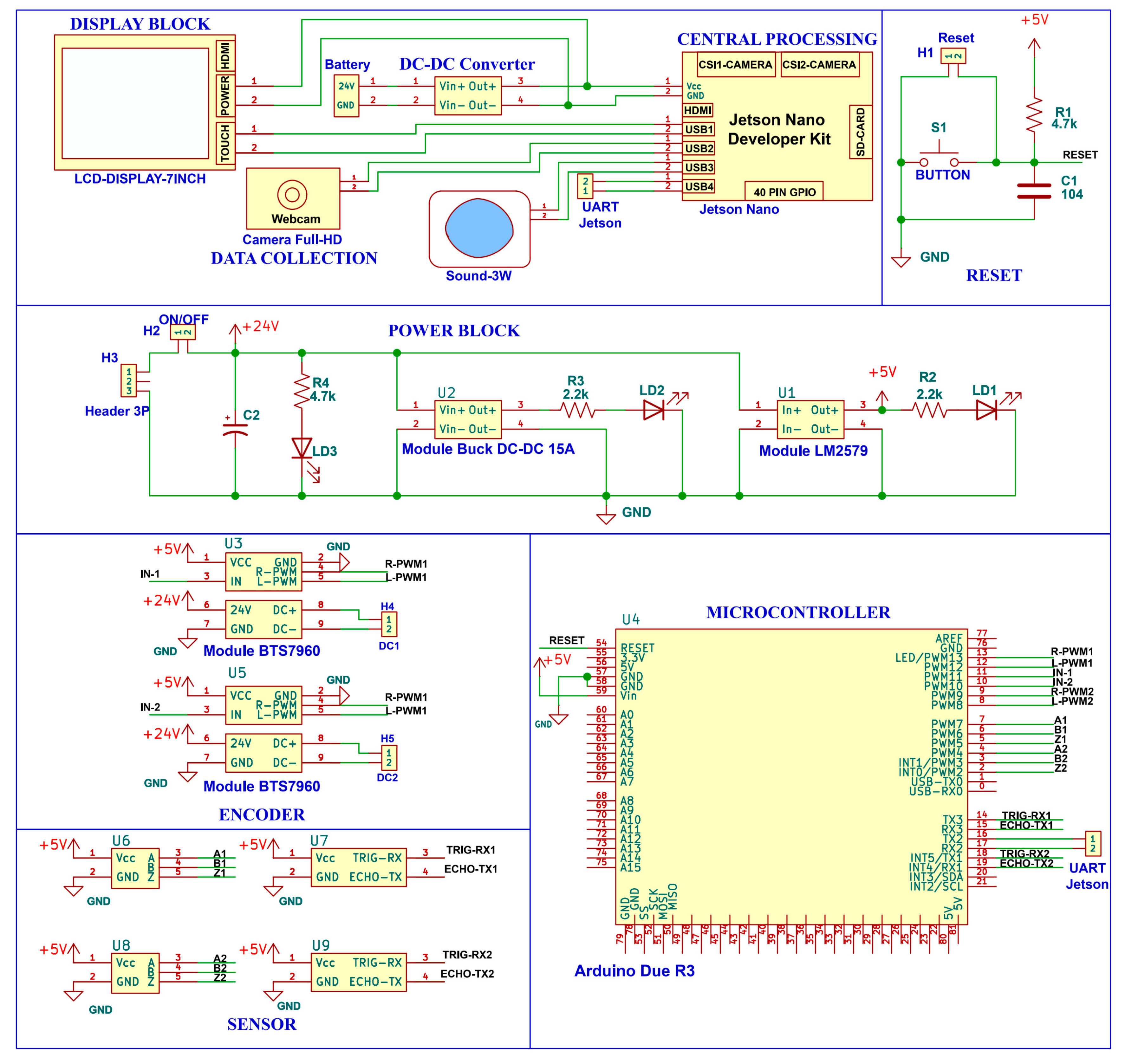
In this paper, we present a smart wheelchair system divided into two primary components: a controller, which includes a hand gesture recognition system connected to an Arduino Uno microcontroller and an NVIDIA Jetson Nano Developer Kit, and an electric wheelchair designed to interface with this controller to receive and execute control signals, as illustrated in
Figure 1. The NVIDIA Jetson Nano Developer Kit processes gesture recognition images and sends corresponding control commands to the Arduino, such as “Forward 1”, “Forward 2”, “Backward”, “Left”, “Right”, and “Stop”, which are then used to operate the wheelchair’s motor controller. Specifically, these six commands allow for precise navigation: “Forward 1” for slow forward movement, “Forward 2” for faster forward movement, “Backward” for reversing, “Left” and “Right” for turning, and “Stop” to halt movement.
This paper presents the design of a smart wheelchair system controlled through hand gestures, consisting of several main components: data collection, central processing, control, motor, and display, described as follows:
Data collection: A FullHD webcam captures a dataset of the user’s hand gesture images, which is then transmitted to the central processing unit for image data processing and the generation of corresponding gesture signals.
Central processing: This block receives the image set from the data collection unit and uses an object recognition algorithm to identify hand gestures. The resulting gesture data are then transmitted wirelessly via Bluetooth to the control block.
Display block: The gesture data are sent to the display unit to show the user’s hand gestures and the wheelchair’s movement status.
Control block: This unit receives hand gesture signals via Bluetooth and controls the wheelchair’s motor accordingly.
Power block: Supplies various voltage levels to all components, including processing, control, and display units, ensuring sufficient current for prolonged operation of the wheelchair system.
2.2. Gesture Recognition
2.2.1. Data Acquisition
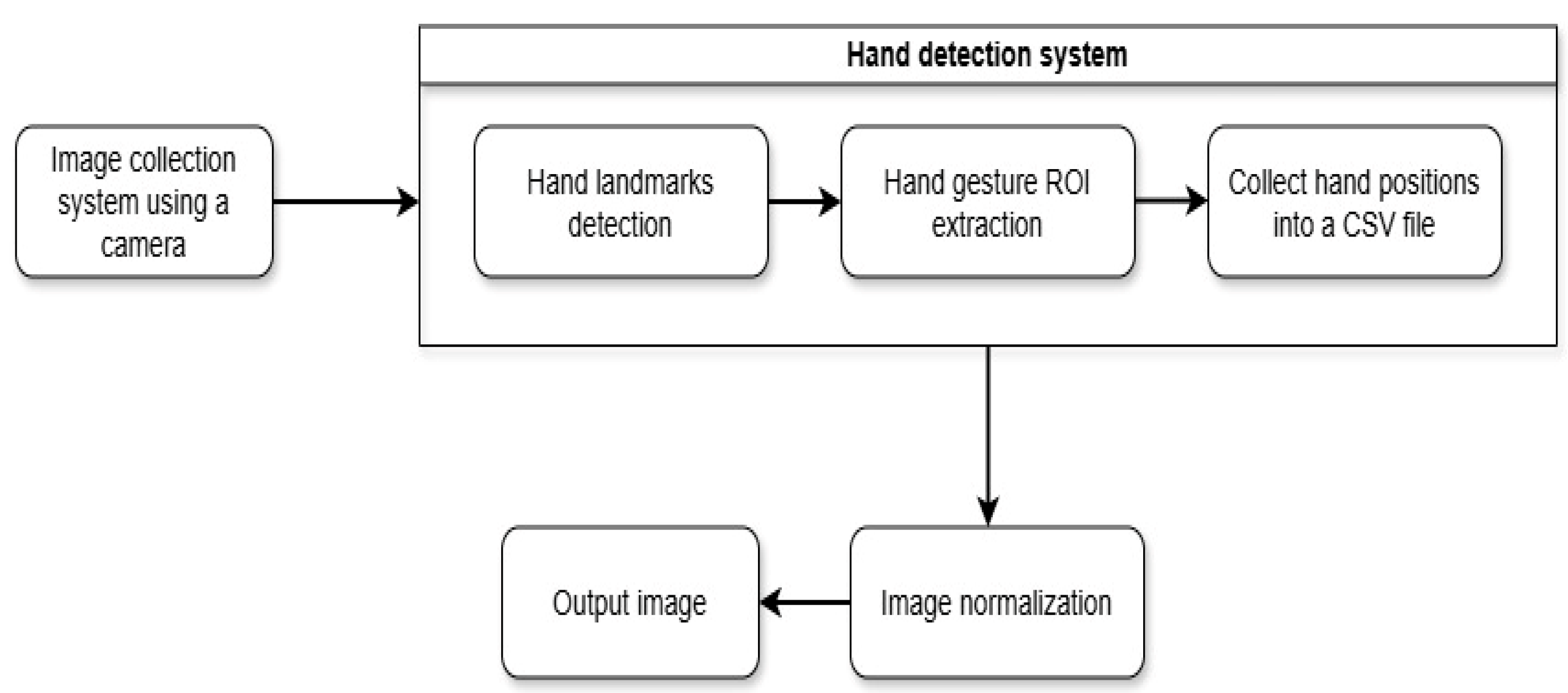
The data collection process is a critical component of the smart wheelchair system, as outlined in
Figure 2. This system is structured into four main blocks: a camera system for capturing hand gesture images, a hand tracking block, an image filtering and resizing block, and an output block. Specifically, the hand tracking block is responsible for distinguishing hand gestures by performing corner and line extraction, collecting hand position data, and storing this information. For gesture recognition, the processed image data are input into a YOLOv8n model, which is used for identifying hand gesture objects.
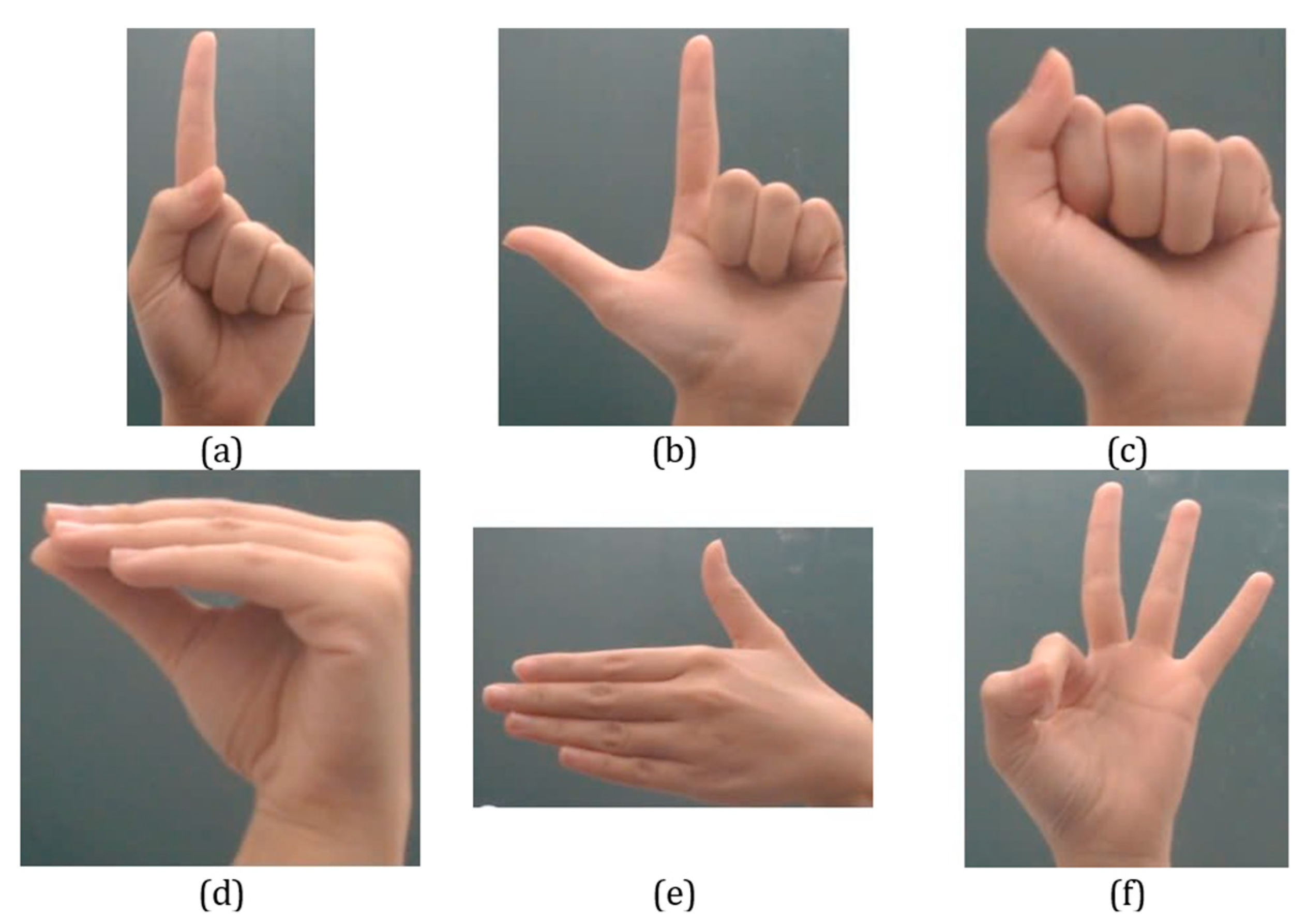
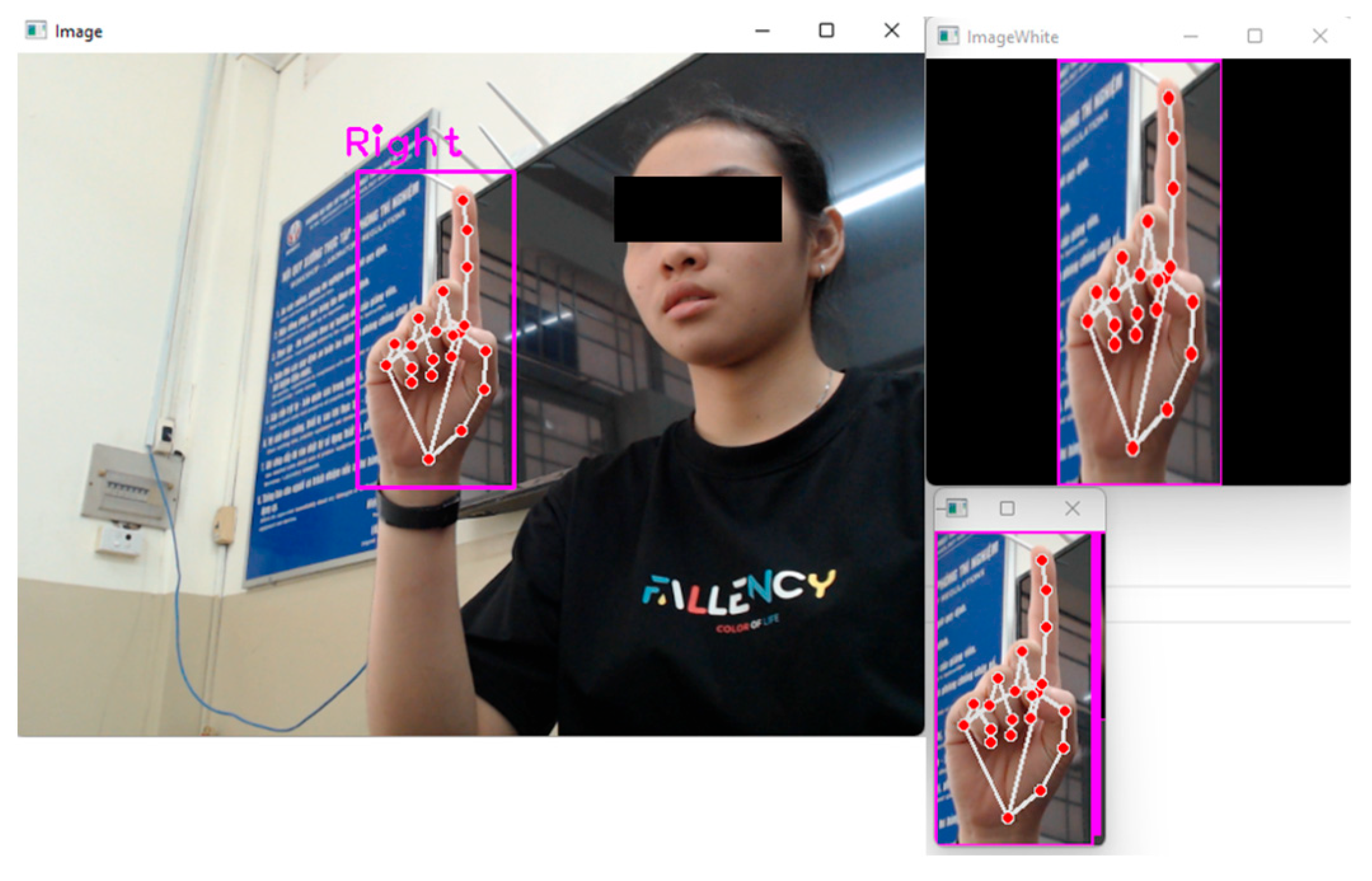
To collect hand gesture image sets, a FullHD webcam is installed on the wheelchair to capture hand gesture images, as shown in
Figure 3. Landmarks for these gestures are identified using MediaPipe. To enhance training accuracy, the images are processed to retain only the hand area, with the fingers defined as the ROI and the background removed. The processed images are then filtered and resized to ensure consistency across all gesture image sets before being input into the YOLOv8n model for training. The datasets comprise six gestures used for wheelchair control: “Forward 1”, “Forward 2”, “Backward”, “Left”, “Right”, and “Stop”.
2.2.2. Hand Landmarks Detection
To process the hand gesture image set and determine the coordinates of the hand, MediaPipe is utilized [
36]. Specifically, when a palm is detected in the image, the system localizes the palm area and designates it as the ROI to extract hand landmarks using MediaPipe. This approach enables the extraction of 21 keypoints per hand and supports the detection of multiple hands simultaneously.
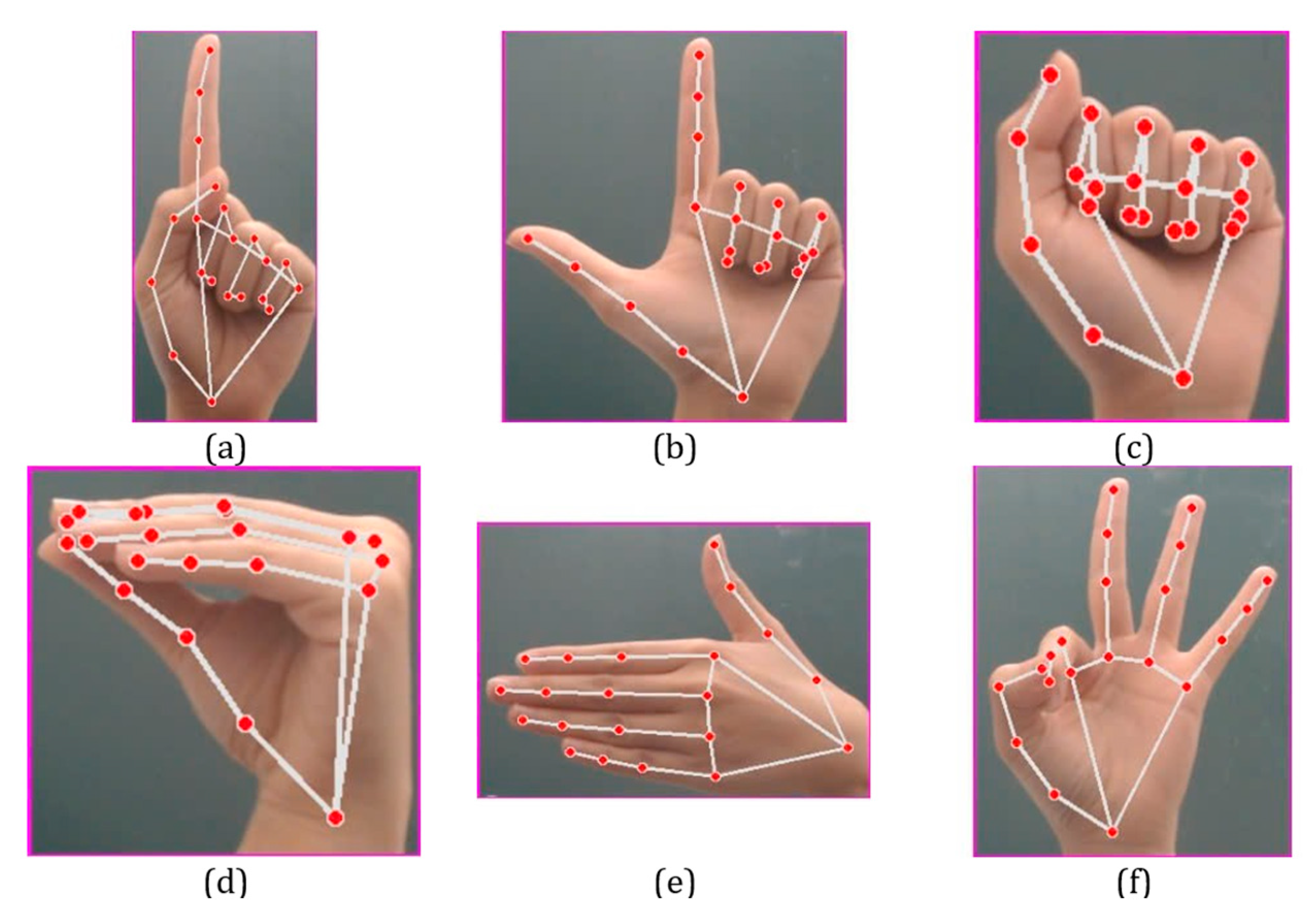
Figure 4 illustrates the 21 extracted hand landmarks using MediaPipe, where 21 named points are identified on the hand.
In the ROI containing these landmarks, the hand and fingers are redrawn as straight white lines based on the red landmark points, as shown in
Figure 5. These images with the extracted landmarks are then used to train a network model for classifying hand gestures.
2.2.3. Hand Gesture ROI Extraction
For optimal training performance, dataset optimization through ROI extraction and background removal is crucial. In this study, hand gesture images, after being detected by the MediaPipe algorithm, are placed into rectangular frames with appropriate sizes for each gesture type. Specifically, hand images are captured directly from the FullHD Webcam system and processed using MediaPipe to generate parameters, including the (x, y) coordinates of the top-left corner and the width and height (w, h) of the bounding box.
The size of a captured image is important for training a network with high-performance and a real-time response for wheelchair movement. Therefore, the hand image sets should be calculated to suit the wheelchair system for increasing recognition performance. In particular, the size of a captured image is calculated and set to 300 × 300 pixel. In addition, the display resolution is selected, particularly
Offset = 20, so that the image is visible more clearly. With the initial parameters, creating an original image (
) with the hand gestures is cropped to produce a desired image (
) using the following formula:
The frame ratio
is the value related to the frame of the obtained hand and is calculated according to the following formula:
Depending on the value of the frame ratio is larger or smaller than 1, we can know the frame of one image is too wide or too long for adjustment. In particular, if the frame is too long, meaning the value of
is more than 1, the
width is adjusted according to the following formula:
Conversely, if the frame is too short, where
is smaller than 1, the length
hc is adjusted using the following formula:
To create a hand dataset with the desired gestures, all images are standardized to a uniform size, and unnecessary background elements are removed.
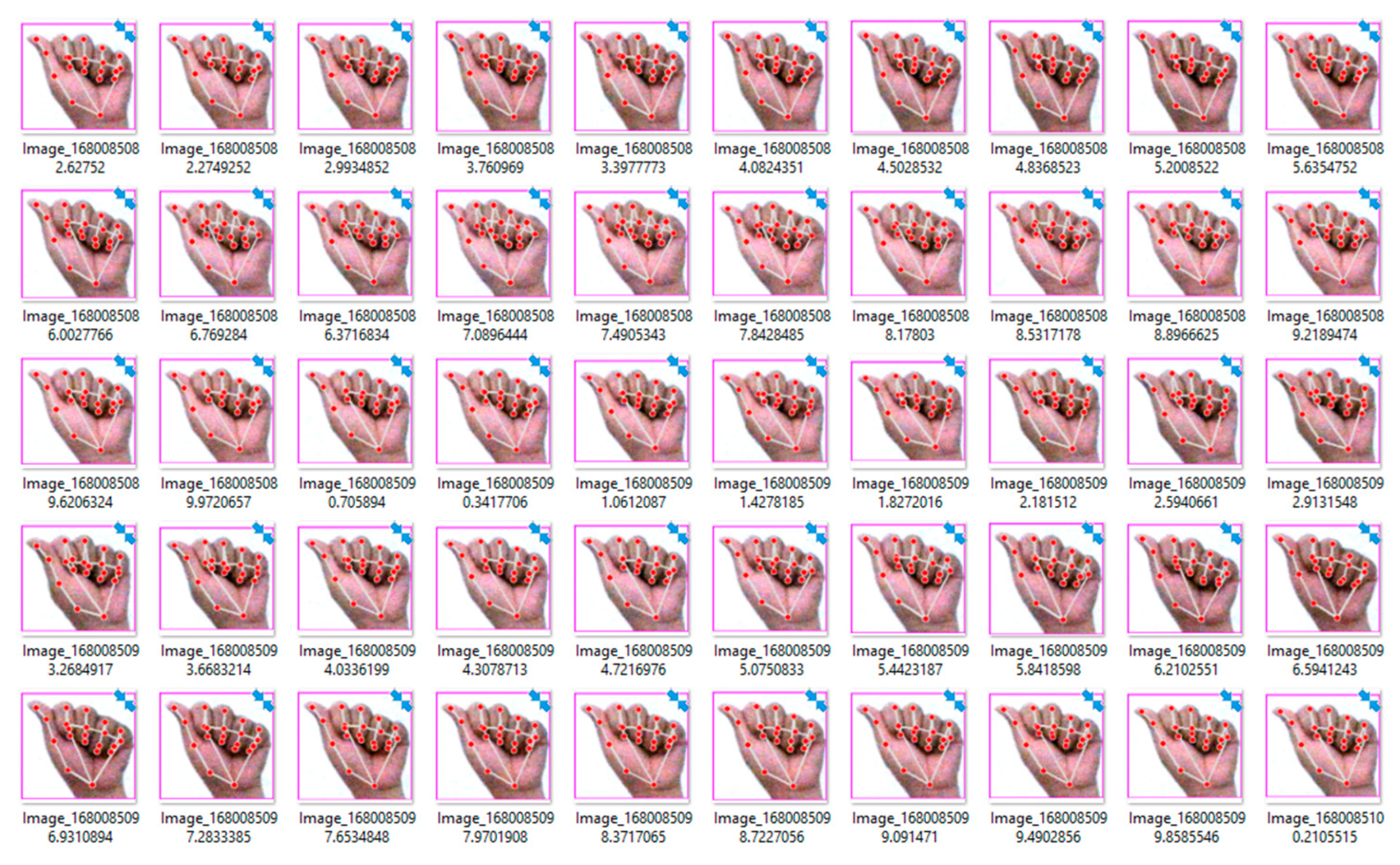
Figure 6 shows a typical image with the background components removed and the framed ROI displaying the landmarks. The frames clearly adjust according to the hand’s gestures as it moves in different directions.
In this research, the wheelchair system is equipped with a FullHD webcam to collect gesture image sets, resulting in images of varying sizes. This variation impacts the time required by the control system to process each image, which can, in turn, affect the speed of gesture recognition and wheelchair movement. To enhance the image processing speed and recognition performance, all images are resized to a uniform 300 × 300 resolution before being fed into the YOLOv8n classifier, as shown in
Figure 7.
2.3. YOLOv8n Model for Hand Gesture Recognition
YOLOv8 is a CNN model often applied for fast and accurate object recognition [
25]. Furthermore, this model has convolutional layers for feature extraction and fully connected layers for predicting probabilities and object coordinates for recognition and can also determine the positions of the input image. Furthermore, the advantage of YOLOv8 is to use the darknet-53 network for feature extraction and apply object recognition algorithm on those extracted features. The YOLOv8 architecture maintains the traditional division of its structure into three main components: the backbone, the neck, and the head, as illustrated in
Figure 8. Nevertheless, it introduces several modifications that set it apart from earlier versions. In this design, the Conv layer functions as a standard convolutional layer responsible for generating feature maps for the output layers. The C2f (convolutional to focus) layer combines convolutional operations with a focusing mechanism to enhance feature representation while simultaneously reducing the image dimensions compared to the input. This design facilitates a more effective gradient flow. Furthermore, the architecture incorporates the SPPF (spatial pyramid pooling feature) module, which is specifically optimized to manage object scaling. This module is essential for capturing multi-scale information, enabling the model to accurately detect and recognize objects of varying sizes and proportions within an image.
When training YOLOv8, each image from the input dataset is processed sequentially and iteratively to optimize the loss function, with the aim of finding the optimal set of weights for the network to achieve high recognition accuracy. Depending on the network’s depth and width, YOLOv8 can be divided into versions YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x. The YOLOv8n model was chosen for this purpose as it is the smallest version, featuring 3.2 million parameters and 8.7 billion FLOPS, with a mAP of 37.3% on the COCO dataset [
37]. This compact version is ideal for the wheelchair control system, which requires fast processing times for effective operation. Although the base YOLOv8n model may not reach the same accuracy levels as larger models with more parameters, its performance can be enhanced through the additional feature extraction of hand gestures. Specifically, combining a feature extraction algorithm applied to input images of hand landmarks with YOLOv8n can further improve accuracy.
2.4. Hardware Design
To transform a basic electric wheelchair into a smart wheelchair controlled by hand gestures, a control hardware system composed of various devices is installed.
Table 2 outlines the hardware system, which includes components such as a Logitech FullHD Webcam C920, a screen, and a power supply, all connected through USB, HDMI, and DC jack ports on the Jetson Nano. The central processing unit consists of a Jetson Nano equipped with an Intel Wireless AC8265 Card, while the data collection unit includes a FullHD webcam connected via a USB port. The display unit is a Waveshare 7-inch HD touchscreen connected to the Jetson Nano through an HDMI cable and powered by a Ugreen micro-USB cable that also connects to the Jetson. The control unit, based on an Arduino Due, features peripheral devices including a HiLetgo HC-05 Bluetooth module and a HiLetgo BTS7960 motor control module. The wheelchair is powered by Topmedi 240 W DC motors. Additionally, the wheelchair is equipped with GalaxyElec HC-SR04M ultrasonic sensors at the front and rear to detect obstacles, ensuring safety for the operator.
Figure 9 depicts the scheme of the whole system, including the Jetson Nano central processing block powered by 5 V and 4 A through the low-voltage module. The data collection block is the FullHD Webcam connected to Jetson Nano via USB 3.0 port. The display unit is the 7-inch HD touch screen connected to Jetson Nano via the HDMI port and powered via USB 3.0 port to display system results. Finally, the Arduino Due control block is connected to receive control data from the Jetson Nano via the HC-05 Bluetooth module, which connects the VCC, GND, RXD, TXD pins to the 5 V, GND, TX3, RX3 pins on Arduino Due, respectively. With the BTS7960 motor control module, the VCC, GND, R_EN, L_EN pins are connected to pins of 5 V, GND, 10, 11 on the Arduino Due; the RPWM of the left and right BTS7960 module are connected to pins 8, 13 on the Arduino Due, the LPWM of the left and right BTS7960 modules are connected to pins 9, 12 on the Arduino Due, respectively. Moreover, the output of the BTS7960 module has B+ and B−, respectively, connected to the (+) and (−) terminals of the 24 V source from the battery and M+ and M− to the (+) and (−) terminals of the wheelchair motors.
4. Conclusions
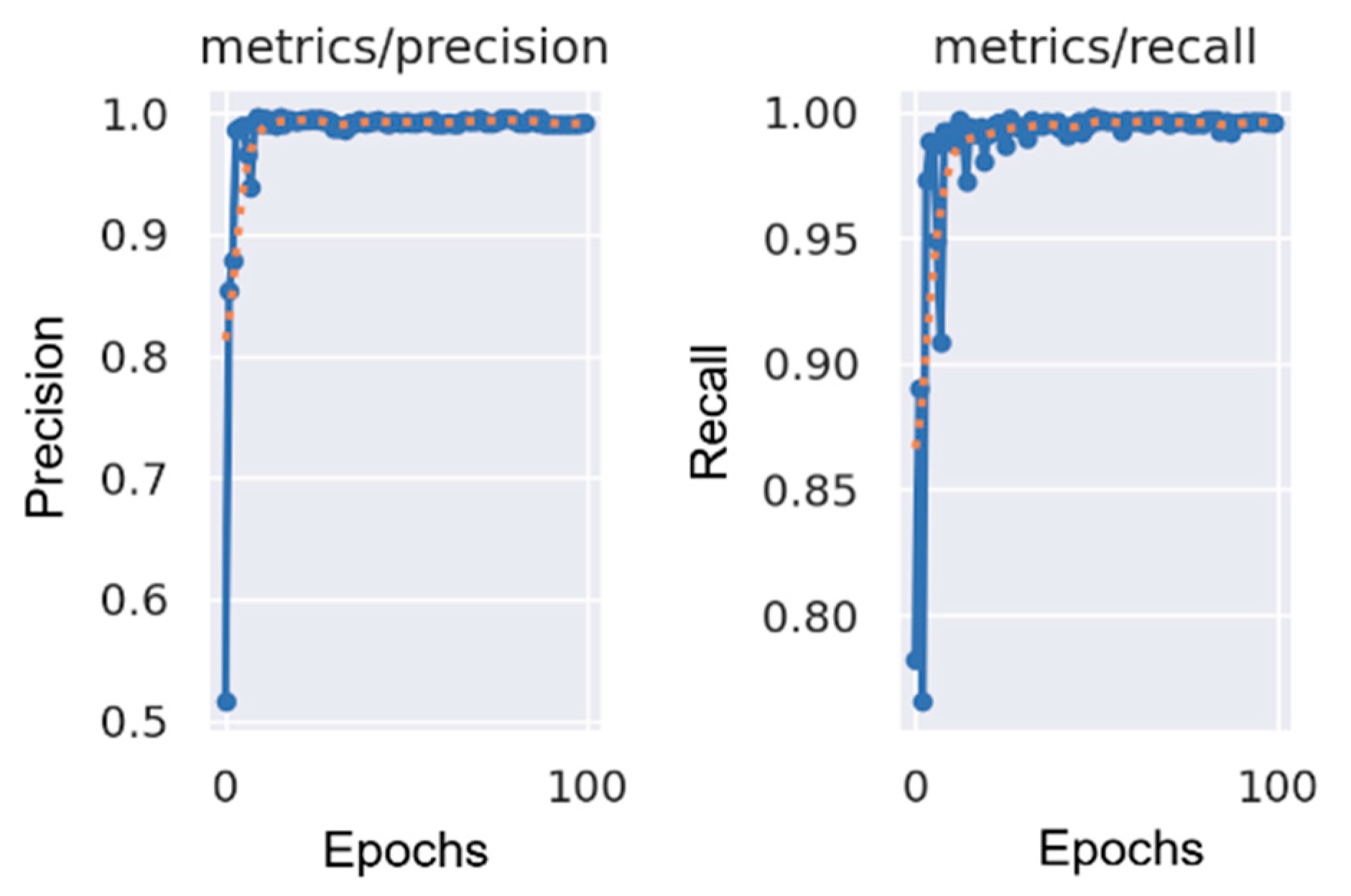
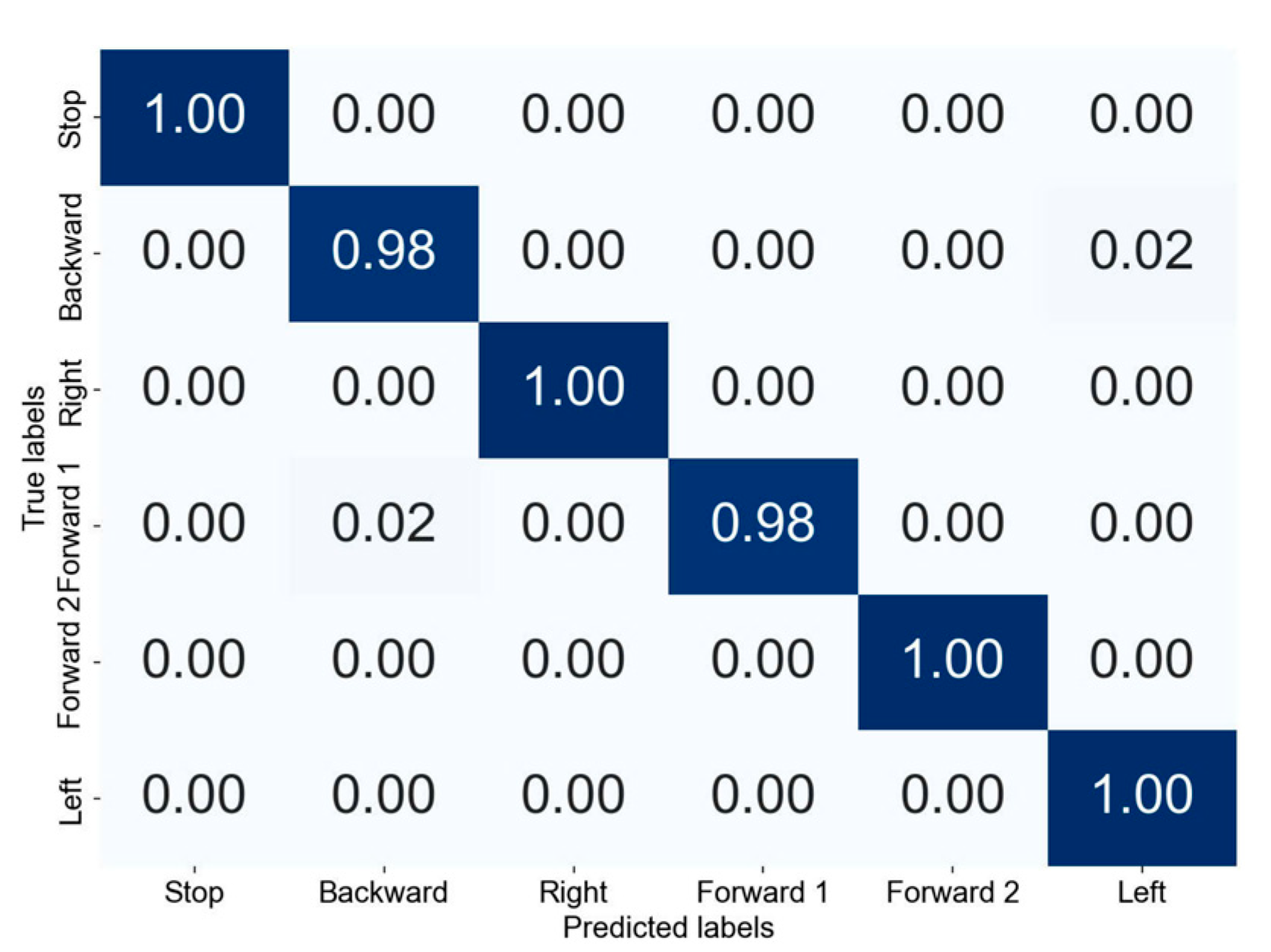
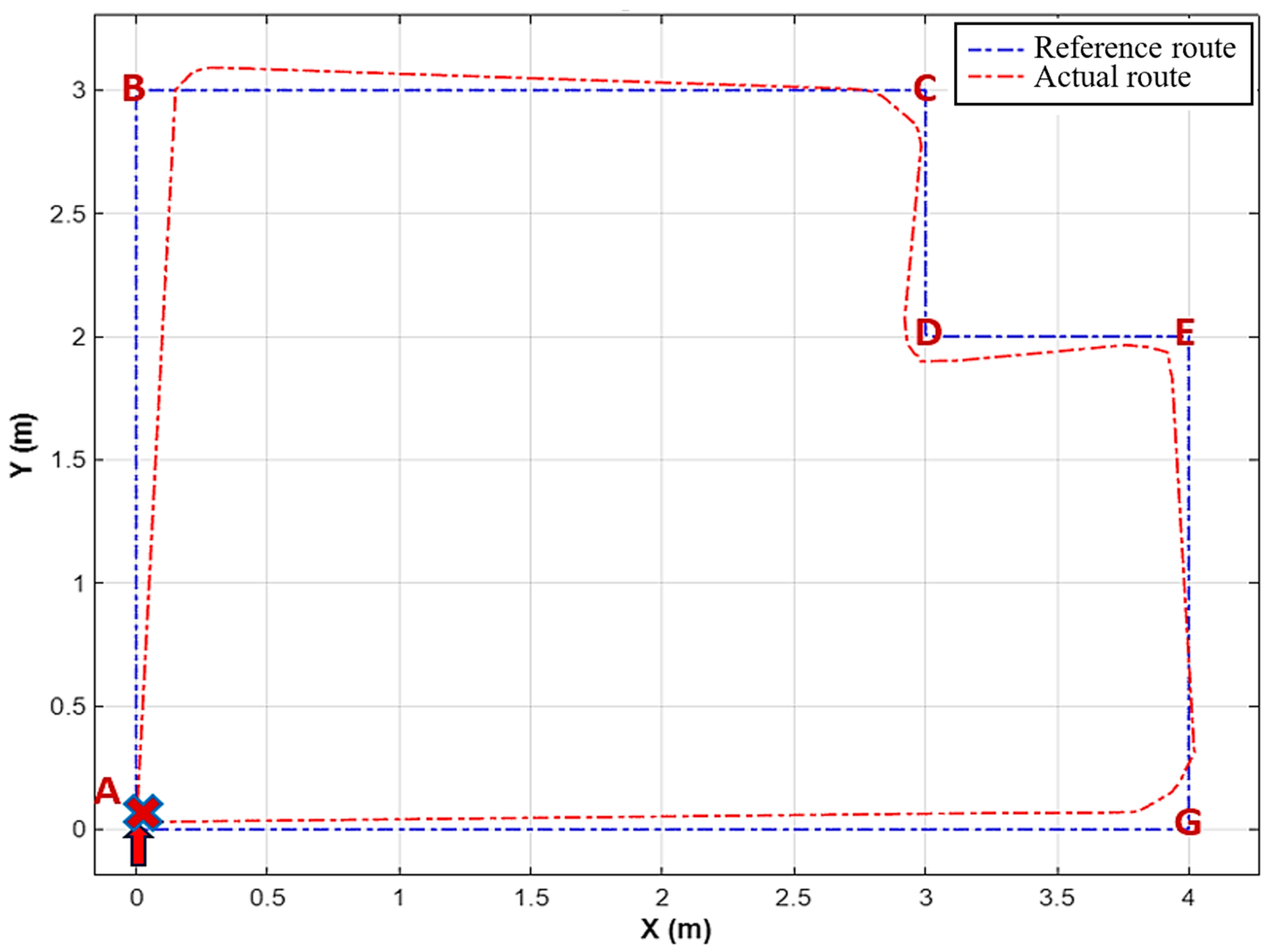
This article proposes a smart wheelchair model that utilizes the YOLOv8n model for recognizing six hand gestures, each corresponding to a control command. The hand gesture datasets were collected from student volunteers, including both male and female participants, under various conditions. These gestures are processed using MediaPipe to extract ROI, enhancing recognition capability. The highest accuracy achieved during model training is 99.3%, while the average accuracy during testing in real-world environments is 93.8%. The six gestures—“Forward 1”, “Forward 2”, “Left”, “Right”, “Stop”, and “Backward”—were assigned to their respective control commands. The recognition of these gestures achieved average accuracies of 90%, 95%, 97%, 95%, 94%, and 92% under appropriate lighting conditions. The processing time for each gesture is between 57 ms and 62 ms, allowing wheelchair movement at speeds ranging from 0.3 m/s to 0.5 m/s. The study also includes experiments assessing the stability of the wheelchair’s movement, comparing the actual and desired routes. The deviation between the two routes was minimal, showing an acceptable performance for indoor environments. Additionally, the research involved designing hardware using the Jetson Nano Developer Kit to process hand gesture images for controlling the wheelchair. The proposed model offers a feasible solution for creating smart wheelchairs for severely disabled individuals, suitable for practical use in indoor settings.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}