
Deployment of TinyML-Based Stress Classification Using Computational Constrained Health Wearable

 ,
,  ,
,  , , and
, , and
Abstract
1. Introduction
- Focus on Wrist-Worn Wearable Data: Unlike other datasets, such as the Wearable Stress and Affect Detection (WESAD) [12], which combine wrist-worn and chest-worn wearables, this study exclusively uses wrist-worn wearable data to reflect real-world use cases of compact, user-friendly devices. The dataset also features three stress levels, no stress, low stress, and high stress, providing a broader scope than binary classification datasets.
- Prediction from Multiple Physiological and Motion Features: This study incorporates six physiological and motion-based features collected from wrist-worn wearable sensors: heart rate (HR), electrodermal activity (EDA), body temperature (TEMP), and 3-axis accelerometer data (X, Y, Z). By leveraging these diverse features, the study achieves a comprehensive assessment of stress levels, capturing both physiological responses and physical activity patterns. This holistic approach enhances the robustness of stress predictions compared to systems relying on fewer features.
- Optimization for TinyML Deployment: Machine learning models, including XGBoost and Random Forest, were selected for deployment based on their compatibility with a micromlgen [13] library. Hyperparameter tuning ensured the models fit within the 2 MB memory of the Raspberry Pi RP2040 while maintaining competitive accuracy. The study demonstrates how resource constraints were balanced with model performance.
- Real-World Implications and Compact System Design: This study advances the integration of machine learning into TinyML devices by demonstrating the potential for real-time stress classification. The RP2040 controller serves as the central component of the system, showcasing the viability of deploying computationally efficient models in low-cost, embedded systems.
2. Related Works
2.1. Available Dataset for Stress Identification Using Health Wearable
2.2. Machine Learning-Based Techniques for Stress Prediction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Author | Features Selection | Devices | Best ML Model | Accuracy |
|---|---|---|---|---|---|
| WESAD | [17] | EDA, BVP, TEMP | Empatica E4 | Random Forest | 73.40% |
| [18] | EDA, ECG, TEMP | Empatica E4, RespiBAN | XGBoost | 96.83% | |
| CLAS | [19] | EDA, ECG, PPG | Shimmer3 GSR+ | SVM | 66.70% |
| VerBIO | [20] | EDA, ECG, BVP | Empatica E4, Actiwave | Logistic Regression | 85.30% |
| Custom | [21] | EDA, ECG | Custom | KNN | 94.40% |
2.3. TinyML Optimization in Predicting Stress
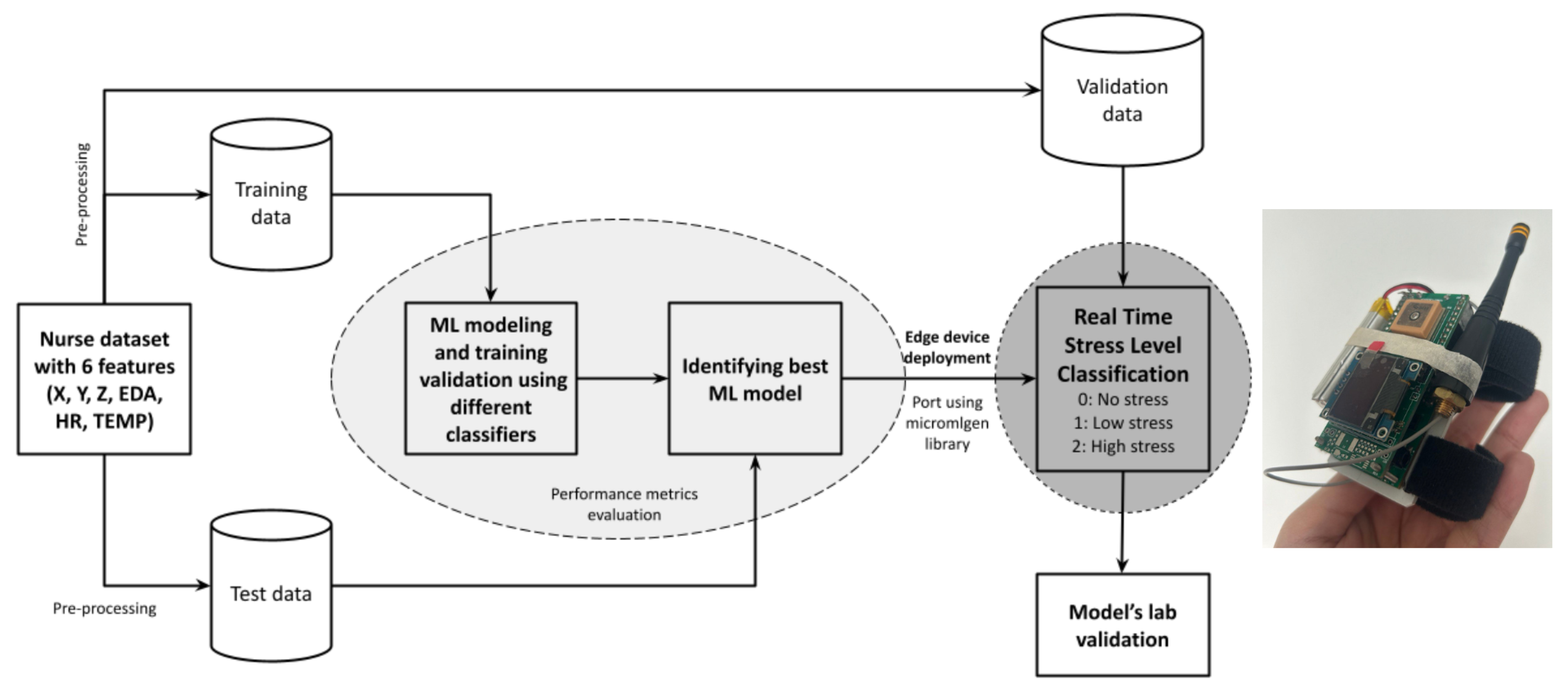
3. Methodology
3.1. Dataset for Modeling
| Data | X | Y | Z | EDA | HR | TEMP | id | Datetime | Label |
|---|---|---|---|---|---|---|---|---|---|
| 0 | −13.0 | −61.0 | 5.0 | 6.769995 | 99.43 | 31.17 | 15 | 8 July 2020 14:03:00.000 | 2.0 |
| . | |||||||||
| . | |||||||||
| . | |||||||||
| 11,509,050 | −22.0 | −24.0 | 29.0 | 3.374543 | 88.33 | 33.75 | F5 | 23 July 2020 17:29:00.000 | 2.0 |
| Skewness | 0.966240 | −0.206264 | −0.349053 | 0.814998 | 0.927843 | −0.282816 | - | 0.078673 | - |
| Kurtosis | 0.848937 | −0.067435 | 0.254031 | −0.014349 | 2.327563 | −1.088713 | - | −1.183099 | - |
3.2. Data Preprocessing and Feature Scaling
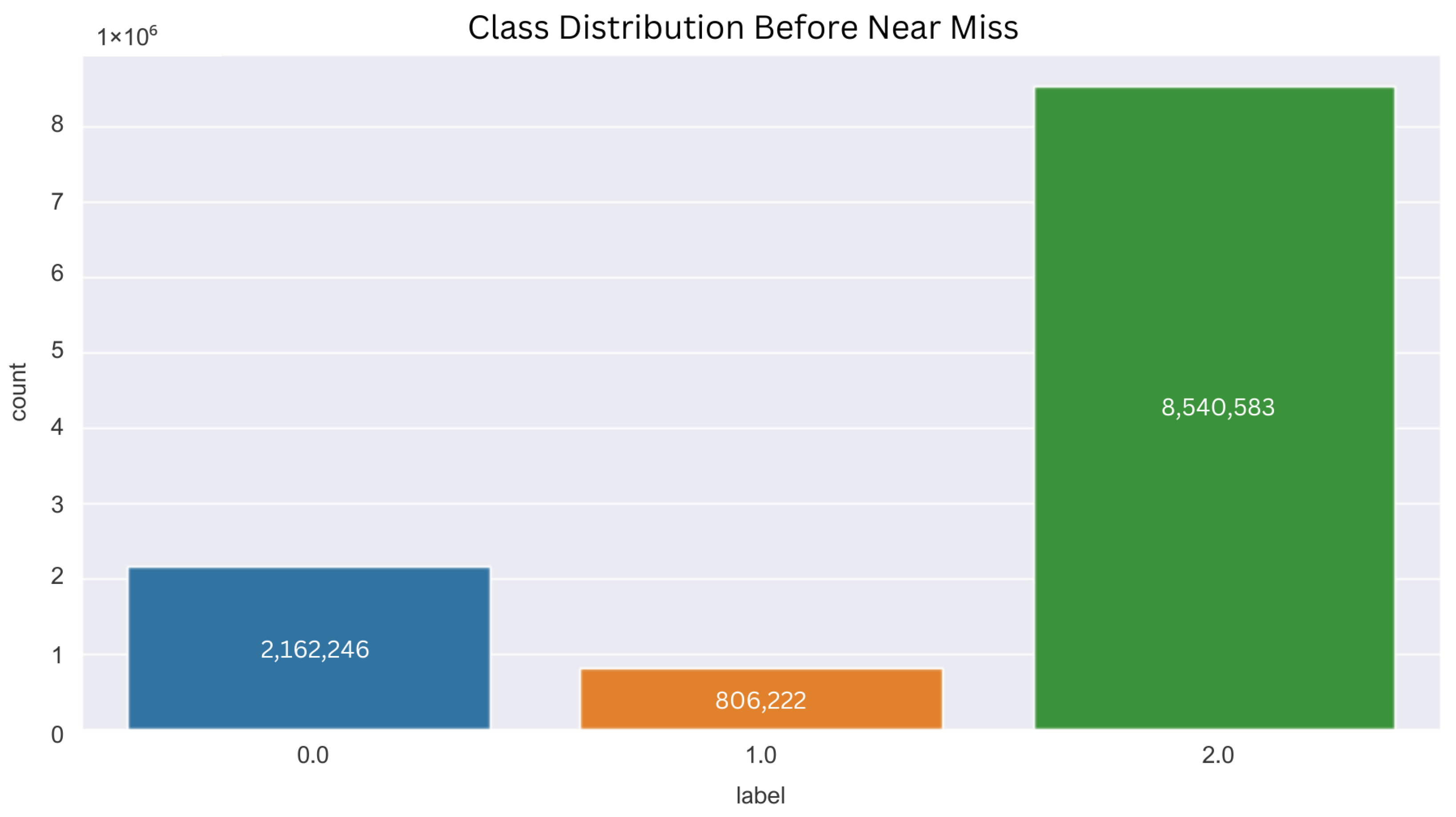
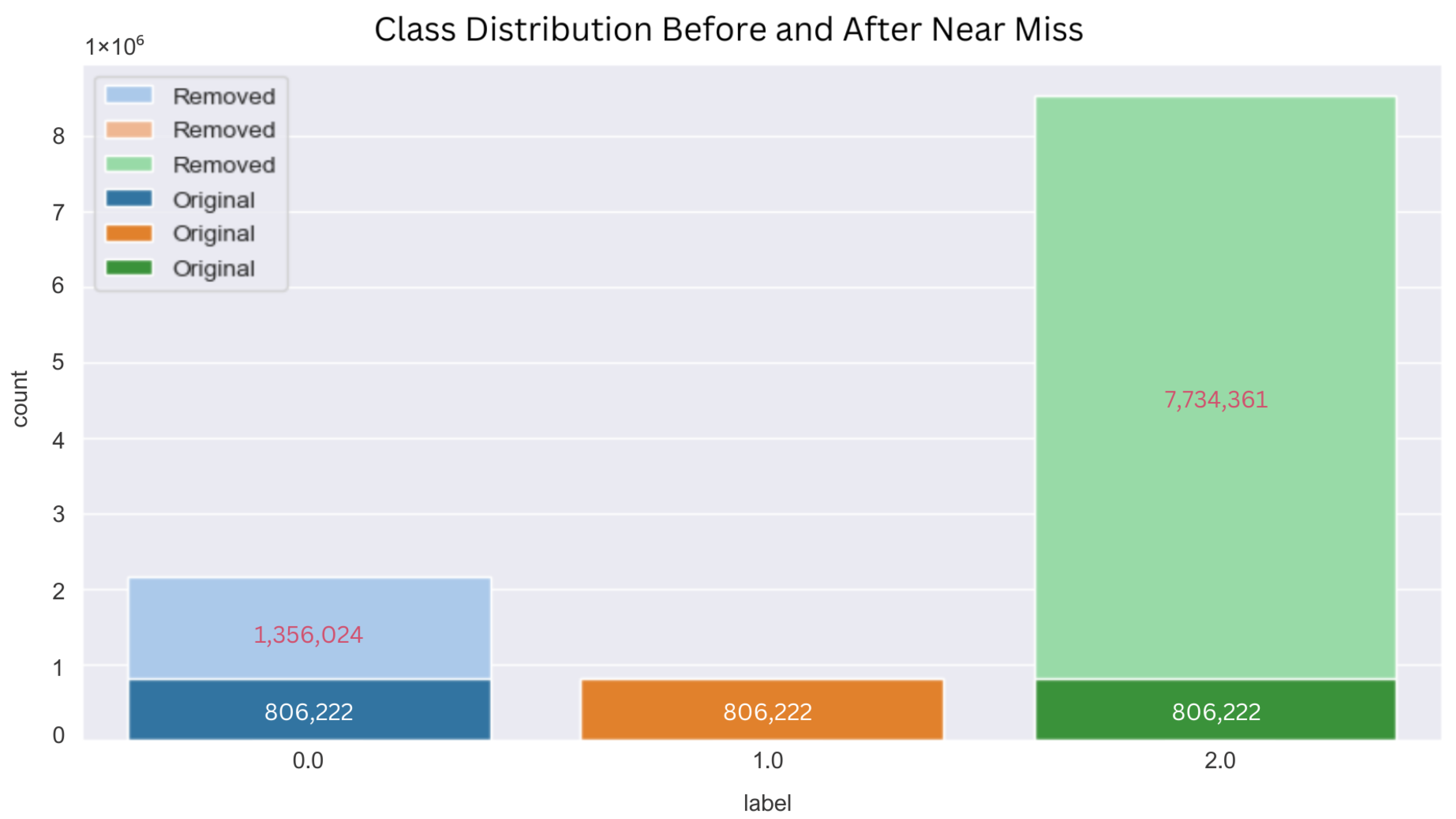
3.3. Dataset Resampling Using near Miss Undersampling
- NearMiss-1 picks samples from the majority class for which the mean distance to some closer neighbors, k is the smallest.
- NearMiss-2 picks samples from the majority class for which the mean distance to the farthest neighbors, k is the smallest.
- NearMiss-3 has two steps; first, a nearest-neighbors will short-listed samples from the majority class. Then, the sample with the highest mean distance to the k nearest-neighbors are picked.
3.4. Model Selection and Hyperparameters Tuning
3.4.1. Classification Model
| Model | Hyperparameters | Settings |
|---|---|---|
| KNN | n_neighbors | 3 |
| cv | 10 | |
| XGBoost | objective | ‘multi:softmax’ |
| max_depth | 15 | |
| n_estimators | 100 | |
| Random Forest | criterion | ‘entropy’ |
| max_depth | 15 | |
| n_estimators | 100 | |
| Decision Tree | criterion | ‘entropy’ |
| max_depth | 15 | |
| LightGBM | objective | ‘multiclass’ |
| Logistic Regression | solver | ‘newton-cg’ |
| penalty | ‘L2’ | |
| multi_class | ‘multinomial’ | |
| max_iter | 100 |
3.4.2. Performance Metrics
3.5. Deployment in Tiny Edge Device
3.5.1. System Design and Prototype Development
3.5.2. Porting the ML Model
3.5.3. Data Acquisition and Validation
4. Result and Discussion
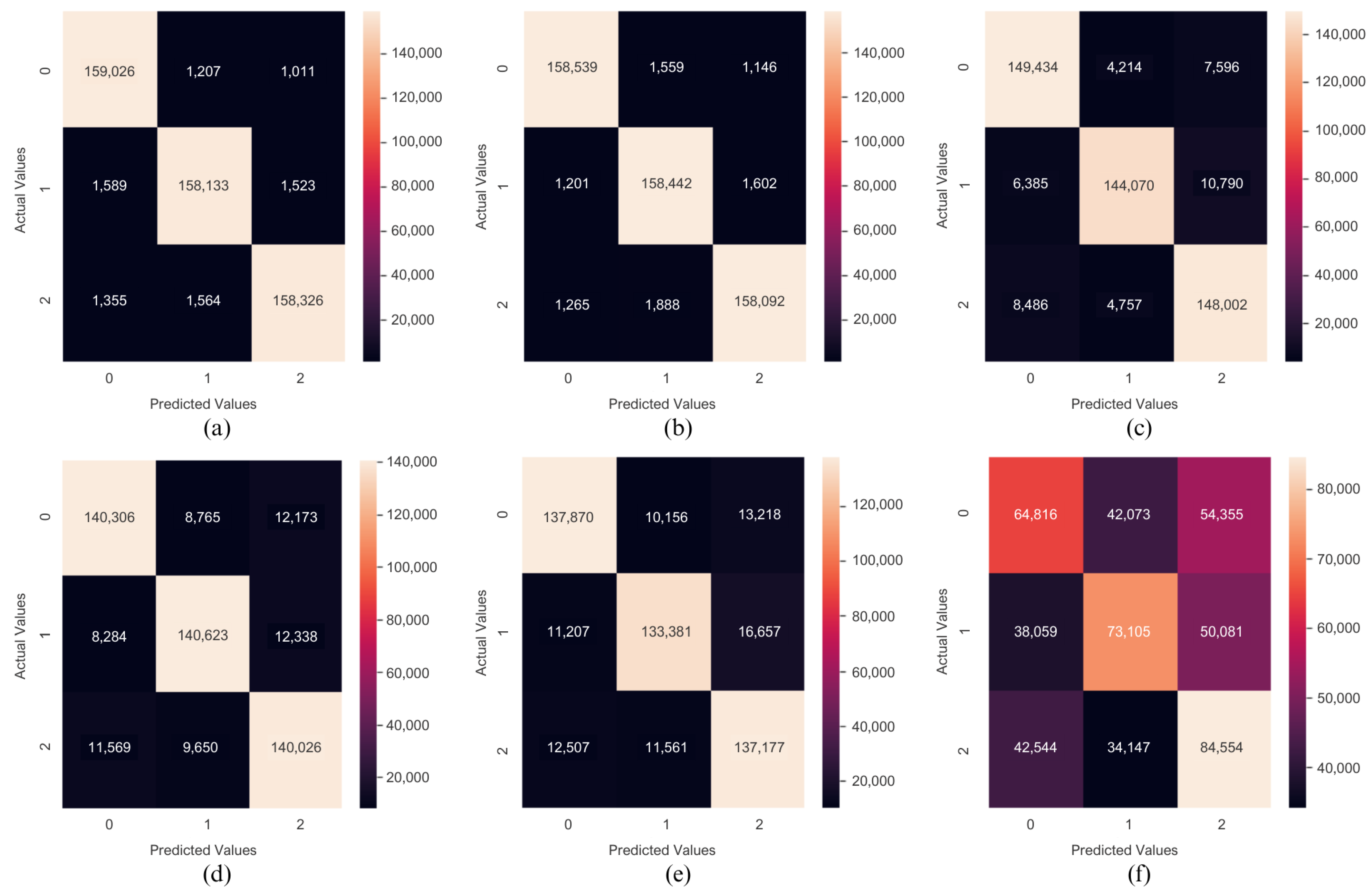
4.1. Classification Models Comparative Analysis
| Validation Set | Test Set | |||||||
|---|---|---|---|---|---|---|---|---|
| Classifier | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score |
| KNN | 0.9831 | 0.9831 | 0.9831 | 0.9831 | 0.9829 | 0.9829 | 0.9829 | 0.9829 |
| XGBoost | 0.9823 | 0.9823 | 0.9823 | 0.9823 | 0.9821 | 0.9821 | 0.9821 | 0.9821 |
| Random Forest | 0.9125 | 0.9133 | 0.9125 | 0.9126 | 0.9128 | 0.9136 | 0.9128 | 0.9129 |
| Decision Tree | 0.8708 | 0.8710 | 0.8708 | 0.8709 | 0.8702 | 0.8704 | 0.8702 | 0.8703 |
| LightGBM | 0.8439 | 0.8444 | 0.8439 | 0.8440 | 0.8443 | 0.8448 | 0.8443 | 0.8444 |
| Logistic Regression | 0.4586 | 0.4595 | 0.4586 | 0.4575 | 0.4599 | 0.4609 | 0.4599 | 0.4588 |
4.2. Deployment Classification Models Comparative Analysis
| Model | Hyperparameters | Settings | Model Accuracy | Size of Model |
|---|---|---|---|---|
| XGBoost(1) | objective | ‘multi:softmax’ | 98.2% | 226 MB |
| max_depth | 15 | |||
| n_estimators | 100 | |||
| XGBoost(2) | objective | ‘multi:softmax’ | 92.5% | 4.47 MB |
| learning_rate | 0.7 | |||
| max_depth | 7 | |||
| n_estimators | 50 | |||
| XGBoost(3) | objective | ‘multi:softmax’ | 86.0% | 1.12 MB |
| learning_rate | 0.7 | |||
| max_depth | 5 | |||
| n_estimators | 50 | |||
| Random Forest(1) | criterion | ‘gini’ | 92.3% | 213.7 MB |
| max_depth | 15 | |||
| n_estimators | 100 | |||
| Random Forest(2) | criterion | ‘entropy’ | 91.4% | 241 MB |
| max_depth | 15 | |||
| n_estimators | 100 | |||
| Random Forest(3) | criterion | ‘entropy’ | 73.2% | 1.5 MB |
| max_depth | 7 | |||
| n_estimators | 50 |
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BVP | Blood Volume Pulse |
| CLAS | Cognitive Load, Affect and Stress |
| CNN | Convolutional Neural Networks |
| DT | Decision Tree |
| ECG | Electrocardiogram |
| EDA | Electrodermal Activity |
| EMG | Electromyogram |
| FN | False Negative |
| FP | False Positive |
| GSR | Galvanic Skin Response |
| HR | Heart Rate |
| IPCA | Incremental Principal Component Analysis |
| LR | Logistic Regression |
| ML | Machine Learning |
| TEMP | Temperature |
| PPG | Photoplethysmogram |
| RF | Random Forest |
| SEL | Stacking Ensemble Learning |
| SF | Spreading Factor |
| SVM | Support Vector Machine |
| TN | True Negative |
| TP | True Positive |
| WESAD | Wearable Stress and Affect Detection |
Appendix A



References
- Anusha, A.; Sukumaran, P.; Sarveswaran, V.; Shyam, A.; Akl, T.J.; Preejith, S.; Sivaprakasam, M. Electrodermal activity based pre-surgery stress detection using a wrist wearable. IEEE J. Biomed. Health Inform. 2019, 24, 92–100. [Google Scholar]
- Gedam, S.; Paul, S. A review on mental stress detection using wearable sensors and machine learning techniques. IEEE Access 2021, 9, 84045–84066. [Google Scholar] [CrossRef]
- Angalakuditi, H.; Bhowmik, B. Impact of stress during covid-19 pandemic. In Proceedings of the 2023 9th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 17–18 March 2023; Volume 1, pp. 1719–1724. [Google Scholar]
- Nirjhar, E.H. Expression and Perception of Stress Through the Lens of Multimodal Signals: A Case Study in Interpersonal Communication Settings. In Proceedings of the 2023 11th International Conference on Affective Computing and Intelligent Interaction Workshops and Demos (ACIIW), Cambridge, MA, USA, 10–13 September 2023; pp. 1–5. [Google Scholar]
- Iqbal, T.; Simpkin, A.J.; Roshan, D.; Glynn, N.; Killilea, J.; Walsh, J.; Molloy, G.; Ganly, S.; Ryman, H.; Coen, E.; et al. Stress monitoring using wearable sensors: A pilot study and stress-predict dataset. Sensors 2022, 22, 8135. [Google Scholar] [CrossRef]
- Hosseini, S.; Gottumukkala, R.; Katragadda, S.; Bhupatiraju, R.T.; Ashkar, Z.; Borst, C.W.; Cochran, K. A multimodal sensor dataset for continuous stress detection of nurses in a hospital. Sci. Data 2022, 9, 255. [Google Scholar] [CrossRef]
- Rachakonda, L.; Mohanty, S.P.; Kougianos, E.; Sundaravadivel, P. Stress-Lysis: A DNN-integrated edge device for stress level detection in the IoMT. IEEE Trans. Consum. Electron. 2019, 65, 474–483. [Google Scholar] [CrossRef]
- Vela, L.M.; Crandall, H.; Lim, T.; Zhang, F.; Gibbs, A.; Mitchell, A.R.; Condon, A.; Diamond, L.M.; Zhang, H.; Sanchez, B. IoMT-enabled stress monitoring in a virtual reality environment and at home. IEEE Internet Things J. 2023, 10, 10649–10661. [Google Scholar] [CrossRef]
- Chen, J.; Abbod, M.; Shieh, J.S. Pain and stress detection using wearable sensors and devices—A review. Sensors 2021, 21, 1030. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Niu, X.; Wang, L.; Niu, J.; Zhu, X.; Dai, Z. Stress detection via multimodal multi-temporal-scale fusion: A hybrid of deep learning and handcrafted feature approach. IEEE Sens. J. 2023, 23, 27817–27827. [Google Scholar] [CrossRef]
- Hosseini, E.; Fang, R.; Zhang, R.; Parenteau, A.; Hang, S.; Rafatirad, S.; Hostinar, C.; Orooji, M.; Homayoun, H. A low cost eda-based stress detection using machine learning. In Proceedings of the 2022 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Las Vegas, NV, USA, 6–8 December 2022; pp. 2619–2623. [Google Scholar]
- Schmidt, P.; Reiss, A.; Duerichen, R.; Marberger, C.; Van Laerhoven, K. Introducing WESAD, a Multimodal Dataset for Wearable Stress and Affect Detection. In Proceedings of the 20th ACM International Conference on Multimodal Interaction, New York, NY, USA, 16–20 October 2018; ICMI ’18. pp. 400–408. [Google Scholar]
- MicroML. Available online: https://github.com/eloquentarduino/micromlgen/tree/master (accessed on 4 September 2024).
- Markova, V.; Ganchev, T.; Kalinkov, K. Clas: A database for cognitive load, affect and stress recognition. In Proceedings of the 2019 International Conference on Biomedical Innovations and Applications (BIA), Varna, Bulgaria, 8–9 November 2019; pp. 1–4. [Google Scholar]
- Yadav, M.; Sakib, M.N.; Nirjhar, E.H.; Feng, K.; Behzadan, A.H.; Chaspari, T. Exploring Individual Differences of Public Speaking Anxiety in Real-Life and Virtual Presentations. IEEE Trans. Affect. Comput. 2022, 13, 1168–1182. [Google Scholar] [CrossRef]
- Mohd, T.M.A.A.T.; Samah, A.A.; Cruz, J.C.D.; Ghaffa, D.; Nordin, R.; Abdullah, N.F. Classification of Stress using Machine Learning Based on Physiological and Psychological Data from Wearables. In Proceedings of the 2023 IEEE 15th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Coron, Philippines, 19–23 November 2023; pp. 1–6. [Google Scholar]
- Shedage, P.S.; Pouriyeh, S.; Parizi, R.M.; Han, M.; Sannino, G.; Dehbozorgi, N. Stress Detection Using Multimodal Physiological Signals With Machine Learning From Wearable Devices. In Proceedings of the 2024 IEEE Symposium on Computers and Communications (ISCC), Paris, France, 26–29 June 2024; pp. 1–6. [Google Scholar]
- Narwat, N.; Kumar, H.; Jadon, J.S.; Singh, A. Multi-Sensory Stress Detection System. In Proceedings of the 2024 14th International Conference on Cloud Computing, Data Science & Engineering (Confluence), Noida, India, 18–19 January 2024; pp. 685–689. [Google Scholar]
- Zhu, L.; Spachos, P.; Gregori, S. Multimodal physiological signals and machine learning for stress detection by wearable devices. In Proceedings of the 2022 IEEE International Symposium on Medical Measurements and Applications (MeMeA), Messina, Italy, 22–24 June 2022; pp. 1–6. [Google Scholar]
- Zhu, L.; Ng, P.C.; Yu, Y.; Wang, Y.; Spachos, P.; Hatzinakos, D.; Plataniotis, K.N. Feasibility study of stress detection with machine learning through eda from wearable devices. In Proceedings of the ICC 2022-IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 4800–4805. [Google Scholar]
- Mohammadi, A.; Fakharzadeh, M.; Baraeinejad, B. An integrated human stress detection sensor using supervised algorithms. IEEE Sens. J. 2022, 22, 8216–8223. [Google Scholar] [CrossRef]
- Elhanashi, A.; Dini, P.; Saponara, S.; Zheng, Q. Advancements in TinyML: Applications, Limitations, and Impact on IoT Devices. Electronics 2024, 13, 3562. [Google Scholar] [CrossRef]
- Rostami, A.; Tarvirdizadeh, B.; Alipour, K.; Ghamari, M. Real-Time Stress Detection from Raw Noisy PPG Signals Using LSTM Model Leveraging TinyML. Arab. J. Sci. Eng. 2024, 1–23. [Google Scholar] [CrossRef]
- Srivastava, P.; Shah, N.; Jaiswal, K. Microcontroller-Based EdgeML: Health Monitoring for Stress and Sleep via HRV. Eng. Proc. 2024, 78, 3. [Google Scholar] [CrossRef]
- Nurse Stress Prediction Wearable Sensors. Available online: https://www.kaggle.com/datasets/priyankraval/nurse-stress-prediction-wearable-sensors/data (accessed on 16 June 2023).
- Hosseini, S.; Katragadda, S.; Bhupatiraju, R.T.; Ashkar, Z.; Borst, C.; Cochran, K.; Gottumukkala, R. A Multi-Modal Sensor Dataset for Continuous Stress Detection of Nurses in a Hospital [Dataset]. 2021. Dryad. Available online: https://doi.org/10.5061/dryad.5hqbzkh6f (accessed on 24 September 2023).
- Rehman, A.; Khan, A.; Ali, M.A.; Khan, M.U.; Khan, S.U.; Ali, L. Performance analysis of pca, sparse pca, kernel pca and incremental pca algorithms for heart failure prediction. In Proceedings of the 2020 International Conference on Electrical, Communication, and Computer Engineering (ICECCE), Istanbul, Turkey, 12–13 June 2020; pp. 1–5. [Google Scholar]
- Haouij, N.E.; Poggi, J.M.; Sevestre-Ghalila, S.; Ghozi, R.; Jaïdane, M. AffectiveROAD system and database to assess driver’s attention. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018; pp. 800–803. [Google Scholar]
- Mohammed, R.; Rawashdeh, J.; Abdullah, M. Machine Learning with Oversampling and Undersampling Techniques: Overview Study and Experimental Results. In Proceedings of the 2020 11th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 7–9 April 2020; pp. 243–248. [Google Scholar]
- Hasanin, T.; Khoshgoftaar, T.M.; Leevy, J.L.; Bauder, R.A. Severely imbalanced big data challenges: Investigating data sampling approaches. J. Big Data 2019, 6, 107. [Google Scholar] [CrossRef]
- Hancock, J.T.; Khoshgoftaar, T.M.; Johnson, J.M. Evaluating classifier performance with highly imbalanced big data. J. Big Data 2023, 10, 42. [Google Scholar] [CrossRef]
- Mqadi, N.M.; Naicker, N.; Adeliyi, T. Solving misclassification of the credit card imbalance problem using near miss. Math. Probl. Eng. 2021, 2021, 7194728. [Google Scholar] [CrossRef]
- Sample Selection in NearMiss. Available online: https://imbalanced-learn.org/stable/auto_examples/under-sampling/plot_illustration_nearmiss.html#sample-selection-in-nearmiss (accessed on 1 December 2024).
- Bajpai, D.; He, L. Evaluating KNN performance on WESAD dataset. In Proceedings of the 2020 12th International Conference on Computational Intelligence and Communication Networks (CICN), Los Alamitos, CA, USA, 25–26 September 2020; pp. 60–62. [Google Scholar]
- Lu, Y.; Fu, X.; Guo, E.; Tang, F. XGBoost algorithm-based monitoring model for urban driving stress: Combining driving behaviour, driving environment, and route familiarity. IEEE Access 2021, 9, 21921–21938. [Google Scholar] [CrossRef]
- Erkal, B.; Başak, S.; Çiloğlu, A.; Şener, D.D. Multiclass classification of brain cancer with machine learning algorithms. In Proceedings of the 2020 Medical Technologies Congress (TIPTEKNO), Antalya, Turkey, 19–20 November 2020; pp. 1–4. [Google Scholar]
- Bhattacharya, M.; Datta, D. Diabetes Prediction using Logistic Regression and Rule Extraction from Decision Tree and Random Forest Classifiers. In Proceedings of the 2023 4th International Conference for Emerging Technology (INCET), Belgaum, India, 26–28 May 2023; pp. 1–7. [Google Scholar]
- Xu, Y.; Cai, W.; Wang, L.; Xie, T. Intelligent diagnosis of rolling bearing fault based on improved convolutional neural network and LightGBM. Shock Vib. 2021, 2021, 1205473. [Google Scholar] [CrossRef]
- Khan, M.S.; Nath, T.D.; Hossain, M.M.; Mukherjee, A.; Hasnath, H.B.; Meem, T.M.; Khan, U. Comparison of multiclass classification techniques using dry bean dataset. Int. J. Cogn. Comput. Eng. 2023, 4, 6–20. [Google Scholar]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for multi-class classification: An overview. arXiv 2020, arXiv:2008.05756. [Google Scholar]
- Raspberry Pi Pico W Datasheet: An RP2040-Based Microcontroller Board with Wireless. Available online: https://datasheets.raspberrypi.com/picow/pico-w-datasheet.pdf (accessed on 13 November 2024).
- Belatik, A.; Sabri, M.A.; El Khoukhi, H.; Aarab, A. A Comparative Review of Microcontroller Architectures in Embedded Machine Learning: The Raspberry Pi Pico (RP2040) and Arduino Nano 33 IoT (SAMD21). In Proceedings of the International Conference on Digital Technologies and Applications, Benguerir, Morocco, 10–11 May 2024; pp. 446–456. [Google Scholar]
- M2cgen. Available online: https://github.com/BayesWitnesses/m2cgen (accessed on 4 September 2024).
- EverywhereML. Available online: https://github.com/eloquentarduino/everywhereml/tree/master (accessed on 4 September 2024).
- Datta, A.; Pal, A.; Marandi, R.; Chattaraj, N.; Nandi, S.; Saha, S. Efficient Air Quality Index Prediction on Resource-Constrained Devices using TinyML: Design, Implementation, and Evaluation. In Proceedings of the 25th International Conference on Distributed Computing and Networking, Chennai, India, 4–7 January 2024; pp. 304–309. [Google Scholar]

| (a) | (b) | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Predicted | Predicted | ||||||||||||
| Class | C1 | C2 | C3 | Class | C1 | C2 | C3 | ||||||
| Actual | C1 | T1 | F12 | F13 | Actual | C1 | TN | TN | FP | ||||
| C2 | F21 | T2 | F23 | C2 | TN | TN | FP | ||||||
| C3 | F31 | F32 | T3 | C3 | FN | FN | TP | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abu-Samah, A.; Ghaffa, D.; Abdullah, N.F.; Kamal, N.; Nordin, R.; Dela Cruz, J.C.; Magwili, G.V.; Mercado, R.J. Deployment of TinyML-Based Stress Classification Using Computational Constrained Health Wearable. Electronics 2025, 14, 687. https://doi.org/10.3390/electronics14040687
Abu-Samah A, Ghaffa D, Abdullah NF, Kamal N, Nordin R, Dela Cruz JC, Magwili GV, Mercado RJ. Deployment of TinyML-Based Stress Classification Using Computational Constrained Health Wearable. Electronics. 2025; 14(4):687. https://doi.org/10.3390/electronics14040687
Chicago/Turabian StyleAbu-Samah, Asma, Dalilah Ghaffa, Nor Fadzilah Abdullah, Noorfazila Kamal, Rosdiadee Nordin, Jennifer C. Dela Cruz, Glenn V. Magwili, and Reginald Juan Mercado. 2025. "Deployment of TinyML-Based Stress Classification Using Computational Constrained Health Wearable" Electronics 14, no. 4: 687. https://doi.org/10.3390/electronics14040687
APA StyleAbu-Samah, A., Ghaffa, D., Abdullah, N. F., Kamal, N., Nordin, R., Dela Cruz, J. C., Magwili, G. V., & Mercado, R. J. (2025). Deployment of TinyML-Based Stress Classification Using Computational Constrained Health Wearable. Electronics, 14(4), 687. https://doi.org/10.3390/electronics14040687