Abstract
Assessing the quality of multimodal posts is a challenging task that involves using multimodal data to evaluate the quality of posts’ responses to discussion topics. Providing evaluations and explanations plays a crucial role in promoting students’ individualized development. However, existing research on post quality faces the following challenges: (1) Most evaluation methods are classification tasks that lack explanations and guidance. (2) There is a lack of a fusion mechanism that focuses on each modality’s information, is multidimensional, and operates at multiple levels. Based on these challenges, we propose the task of multimodal post quality assessment and explanation (MPQAE), aiming to leverage multimodal data to accurately evaluate and explain the quality of posts. To address this task, we introduce a Multimodal multi-level fusion model for post quality assessment with explanations (MMFPQ). The model uses multimodal topic–post pair data for fusion across multiple scopes and levels, attending to the information from each modality during the fusion process, thereby acquiring multi-level relational information to promote the generation of post quality evaluations, explanations, and guidance. We conducted comparative experiments on two newly created datasets for post quality assessment and explanation, as well as on the public dataset. The results demonstrate that our model outperforms the baseline models used for comparison. Furthermore, our model exceeds the best-performing baseline model, TEAM(mulTisource sEmantic grAph-based Multimodal sarcasm explanation scheme), by 10.32% and 13.72% on the Art Literature dataset in terms of METEOR and BLEU-4, respectively.
1. Introduction
Post quality evaluation is a significant research direction in the field of personalized evaluation and analysis. It assesses the quality of a post by examining whether it comprehensively and accurately addresses the issue at the heart of the discussion topic. Evaluating the quality of a post is a complex process that requires analysis from multiple aspects, such as the relevance of the post content to the discussion topic, the comprehensiveness of the post’s response, and the clarity of the post’s language expression. However, many studies on posts only utilize textual data and evaluate post quality through classification [1], lacking explanations and interpretations of the evaluation. This makes their evaluation results unconvincing and unable to provide guidance during the learning process. Therefore, it is crucial to utilize multimodal data for a fine-grained and interpretable evaluation of post quality.
Due to the abundant data resources in discussion forums, many researchers have been attracted to study posts. Early research on posts usually required manual feature extraction, followed by the classification of posts using machine learning models [1]. In recent years, deep learning has gained favor among researchers for its ability to automatically extract features [2]. Nonetheless, these works have primarily relied on purely textual data. Using only unimodal data does not provide a comprehensive and accurate analysis of the relationship between posts and topics, which hinders the effective assessment of the quality of posts. As shown in Figure 1, a student responds to a topic question using a combination of text and images, with the text answering a part of the question and the images answering another part. Relying solely on textual data would not provide a comprehensive and accurate assessment of the post’s quality [3,4]. Utilizing multimodal data allows for a more comprehensive understanding of the post’s content, thereby enabling better evaluation of its quality. As illustrated in Figure 2, two different posts using multimodal data are presented under the same discussion topic. For the same question, the textual content of the two posts is similar, but they contain different image content, leading to vastly different evaluations of the posts’ quality. Therefore, each modality is crucial for assessing post quality. In most research on multimodal fusion, textual information is often treated as the primary modality, while other modalities are considered secondary, which dilutes the effective representation of other modalities’ information. Moreover, in multimodal fusion, the main features within the post and the topic as a whole are often ignored. Instead, only single-modality data from the post or the topic are fused with the input text, leading to the failure to capture key information and potentially yielding fusion results that are noisy or irrelevant. Furthermore, the fusion process often lacks the integration of modalities at different levels and scopes, which could provide a more comprehensive and thorough exploration of the relationships among multiple modalities. Based on these observations, we identify the following challenges in post quality evaluation methods: (1) Accurate and effective post quality evaluation should make full use of multimodal data to provide evaluations and relevant explanations. (2) In the process of multimodal fusion, attention should be given to the importance of each modality, rather than treating textual information as the primary modality. (3) Construct a multi-level multimodal fusion mechanism across diverse scopes to fully capture the relationship information among modalities at various levels and across multiple ranges, thereby facilitating the generation of accurate post quality evaluations and explanations.

Figure 1.
An example of a post based on the multimodal theme of “functional roles” demonstrates that using only text modality information is insufficient for accurately assessing the quality of the post.

Figure 2.
Multimode post examples under the topic “physical education classes”. Two posts utilizing multimodal data are presented under the same discussion topic. The text content of the two posts is similar, yet the image content differs, leading to vastly different evaluations of the posts’ quality.
To address the above challenges, we propose a new task of multimodal post quality evaluation and explanation, aimed at generating post quality evaluations and corresponding explanations through the comprehensive utilization of multimodal topic–post pair data, rather than simple categorical evaluations. We propose a model for multi-level multimodal fusion-focused post quality evaluation and explanation (MMFFPQ). This model integrates multimodal data across multiple levels and scopes, with attention to the information from each modality during the fusion process, thereby obtaining comprehensive topic–post relationship information and promoting the generation of accurate post quality evaluations and explanations. To validate the effectiveness of our model, we conducted experiments on both public datasets and two newly constructed datasets. The results demonstrate that our model outperforms all baseline models, achieving improvements of 8.58% and 13.87% over the best-performing baseline in terms of METEOR and BLEU-4 metrics, respectively, on the Art Literature dataset.
Our contributions are summarized as follows: (1) We propose a new task, post quality evaluation and explanation, which aims to generate evaluation scores, explanations, and guidance for post quality through the analysis of multimodal data.
(2) We propose a model for multimodal multi-level focused fusion for post quality evaluation and explanation (MMFFPQ). This model achieves deep multimodal fusion across multiple levels and scopes, with a focus on the information from each modality throughout the fusion process, thereby obtaining comprehensive information about the relationship between the topic and the post. It generates more accurate evaluations and explanations of post quality.
(3) We conduct extensive experiments on both newly constructed and publicly available datasets, and our model outperforms all baseline models, demonstrating the effectiveness of our approach.
2. Related Work
2.1. Related Research on the Post
Most research on posts in discussion forums has relied solely on textual data to analyze the relationship between posts and topics. Based on the feature extraction methods, we classify these methods into three categories: statistical methods [5], traditional machine learning methods, and deep neural network methods. In the early stages, some researchers conducted quantitative analyses of the relationship between posts and topics using statistical knowledge. However, this process heavily depended on experienced experts. Subsequently, researchers employed machine learning methods for the classification posts, such as clustering, and decision trees. Nonetheless, these methods required manual feature extraction in the initial stages, making the process time-consuming and labor-intensive. For instance, Wenting Zou et al. [6] proposed a new machine learning approach to analyze posts in discussion forums for automatic assessment of students’ social indicators. Xiaohui Tao et al. [7] proposed a machine learning ensemble method that predicts students’ academic performance based on three features: participation, semantics, and emotions. Jiun-Yu Wu et al. used supervised machine learning methods to predict students’ risk of failing courses. Compared to the limitation of machine learning methods that require manual feature extraction, deep learning methods have attracted much attention from researchers due to their advantage of automatically extracting text-related features. Zhi Liu et al. [8] proposed the MOOC-BERT model based on neural networks to predict students’ cognitive levels by analyzing posts. Sannyuya Liu et al. [9] proposed a BERT-CNN bidirectional encoder model to automatically detect students’ emotions through the analysis of post texts. Purnachary Munigadiapa et al. [10] proposed a model combining LSTM architecture with Ax hyperparameter tuner to predict students’ sentiment status by analyzing posts. However, these methods only utilize textual data and fail to fully exploit the multimodal data available in discussion forums. Moreover, most of them are simple classification tasks and lack sufficient evaluation and interpretation. Some research in other fields only explains the processing procedure of the model, which is not comprehensive enough [11]. To address this, we propose a deep neural network model that thoroughly analyzes multimodal data to generate accurate post quality evaluations, interpretations, and guidance suggestions.
2.2. Multimodal Fusion
In recent years, numerous online learning platforms have provided various forms of interaction, generating a vast amount of multimodal data, which has sparked research into multimodal fusion in the field of education [12]. However, most studies have focused on specific areas such as teacher behavior analysis [13], student behavior analysis [14,15,16], and emotion recognition [17,18,19]. Research on multimodal fusion of discussion forum post data remains scarce. Regarding multimodal fusion, based on the stage of fusion, methods can be categorized into three types: early fusion, late fusion, and hybrid fusion. Early fusion involves directly concatenating different modal features at the feature extraction stage. Zhi Liu et al. [20] proposed the B-LIWC-UDA method, which fuses explicit and implicit features at the early stage and classifies student cognitive engagement through supervised learning. Wu, Dongli et al. [13] perform modal fusion of video and skeletal information at an early stage to achieve prediction of teacher rows. Late fusion involves processing different modalities using separate classifiers and combining them at the final decision stage of the model. Lingyun Song et al. [21] proposed a Deep Cross-Media Group Fusion Network (CMGFN) that separately processes text and image features and fuses them at the late stage to analyze multimedia content understanding. Xinyi Ding et al. [22] proposed Multimodal Fusion and Neural Architecture Search (MFNAS) to achieve better knowledge tracking by fusing multimodal features at a later stage. Hybrid fusion combines the approaches of early fusion and late fusion to process multimodal data. Wilson Chango et al. [23] utilized multimodal data in learning environments through hybrid fusion to predict student academic performance. However, these fusion studies focus on textual modalities and downplay other modal information, resulting in ignoring the key role of other modal information in fusion. Additionally, there is a lack of deep modal fusion across different scopes and multi-levels during the fusion process.
3. Proposed Method
In this paper, we formulate the task of multimodal post quality evaluation and explanation as a generation task, where the input data includes post text, post images, topic text, and topic images, denoted as . Specifically, represents the post text, which consists of a sequence of tokens, . Similarly, the topic text is denoted as . and represent the image inputs for the post and the topic, respectively. Assuming that each post-topic pair has a corresponding post quality evaluation and explanation, . Our objective is to construct a multimodal post evaluation and explanation model F, which is capable of generating comprehensive and accurate post quality evaluations and explanations using multimodal data, as denoted below:
where is the set of learnable parameters in model F. is the text generated by Model F for post quality evaluation and explanation.
3.1. Overview
Our proposed multimodal multi-level focused fusion for post quality evaluation and explanation (MMFFPQ) model comprises three main components: a feature encoder consisting of a text encoder and a visual encoder to process the textual and image data of posts and topics; a multi-level multimodal attention-based fusion module that focuses on each modality and fuses the multimodal data between posts and topics at different levels; and a multimodal decoder responsible for generating relevant post quality evaluations and explanations. Figure 3 illustrates the overall architecture of the MMFFPQ model. Figure 4 is the flowchart of the MMFFPQ model structure. Each module of the model will be described in detail below.
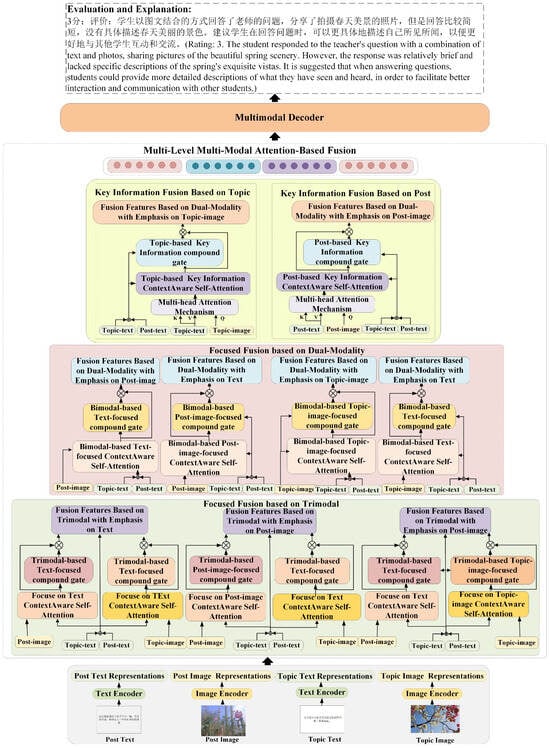
Figure 3.
The overall architecture of the MMFFPQ model, which consists of three main components: feature encoder, multi-level multimodal attention-based fusion module, and multimodal decoder.
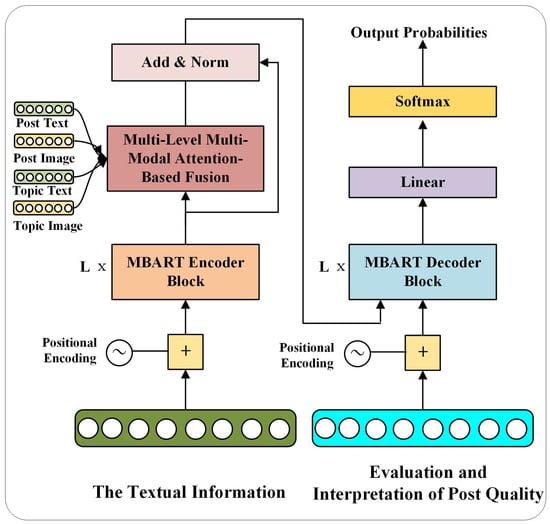
Figure 4.
Flowchart of the MMFFPQ model structure. The model is based on the mBART architecture and uses a multi-level multimodal attention-based fusion mechanism to perform multimodal fusion of posts and topics across multiple ranges and levels, with attention given to each modality during the fusion process. It obtains comprehensive topic–post relationship information and facilitates the generation of post quality evaluations and explanations.
3.2. Feature Encoder
3.2.1. Text Encoder
For the text of posts and topics, we use the encoder from the pre-trained mBERT model to extract textual features, which can be specifically represented as follows:
Post text features and topic text features are denoted as , , respectively.
3.2.2. Image Encoder
For the images in posts and topics, we employ the CLIP visual encoder to extract visual features. CLIP is a model pre-trained on 400 million image–text pairs sourced from the Internet. It adopts a contrastive learning framework, pre-trained by minimizing the cosine distance between encoded vectors of accurate image–text pairs while maximizing the cosine distance of mismatched pairs. As a result, CLIP learns a shared image–text embedding space that can effectively measure the semantic similarity between images and text. The features extracted by CLIP have the following advantages: (1) By learning a shared image–text embedding space, CLIP can effectively measure the semantic similarity between images and text [24]. (2) The visual features extracted by CLIP are unbiased and general. (3) Due to CLIP’s contrastive learning objective, its visual features are closer to the language embedding space, which facilitates better integration of visual and textual information. (4) When using the CLIP visual encoder to extract visual features, it offers faster processing speed and lower memory usage [25]. Therefore, we use a pre-trained CLIP visual encoder to extract visual features, which is represented as follows:
The image features of the post and the topic are represented as , , respectively.
3.3. Multi-Level Multimodal Attention-Based Fusion
To fully and effectively achieve multimodal key information fusion, we have developed a multi-level multimodal attention-based fusion module. This module focuses on the information from each modality during the multimodal fusion process and performs deep fusion of multimodal data at multiple levels and scopes. Specifically, it fully captures the comprehensive and focused multi-level relationship features between posts and topics from five levels fusion based on key information in posts, fusion based on key information in topics, fusion emphasizing bimodal data, and fusion emphasizing tri-modal data to facilitate the generation of post quality evaluation and explanation. In most research studies on multimodal fusion, the integration typically involves combining multiple modalities with the textual modality [26]. The text is taken as the primary form and other modalities are treated as secondary, which can dilute the intrinsic key information of these other modalities in the fusion process. Additionally, when exploring the relationship between posts and topics, it is essential to capture their internal core content to ensure that important relational information, rather than noise or irrelevant content, is extracted during the subsequent multimodal fusion. Therefore, the multi-level multimodal attention-based fusion mechanism deeply integrates multiple modalities from different ranges and levels while emphasizing the importance of each modality. Figure 3 illustrates the multi-level multimodal attention-based fusion mechanism, which consists of four components: fusion based on key information from posts, fusion based on key information from topics, dual-modal attention-based fusion, and tri-modal attention-based fusion. The fusion based on key post information aims to capture the relationship between the main and crucial content of the post and the input text information, ensuring that the key information of the post and its relationship with the input text are obtained during the fusion process, without introducing noise or irrelevant relationship information in the interaction between the post’s single modality and the input text. The fusion based on key topic information analyzes the relationship between the main issues in the topic and the input text information, effectively assessing whether the post content addresses the key questions of the topic, which is crucial for post quality evaluation. Complex and rich relationship information exists among different scopes and modalities, and this information needs to be fully considered to ensure the accuracy and completeness of post quality evaluation and explanation. Therefore, the fusion emphasizing dual-modality component analyzes the relationships between different modalities within the scope of two modalities, giving equal attention to each modality. The fusion emphasizing tri-modality explores the relationships among different modalities within the scope of three modalities, giving equal attention to each modality’s information, which enhances the depth and breadth of modal fusion. This multi-level fusion approach helps us to comprehensively understand the relationship between the post and the topic, thereby improving the accuracy of post quality evaluation and explanation. Each module of the model will be described in detail below.
3.3.1. Fusion Based on Key Information from Posts
In some research on post quality evaluation, intra-individual modal data in a post were considered, which may not adequately capture the key information in the post, resulting in a fused knot that may be dominated by noise. Therefore, we propose a post key information fusion module. Specifically, we first obtain the key information from both the post text and images through an attention mechanism. The attention mechanism is capable of dynamically focusing on and extracting the most crucial information for the current task when processing sequential data. This mechanism calculates relevance scores between each element in the input sequence and the current task. Then, it weights the input sequence based on these scores, thereby generating a representation that is more focused on the key information pertinent to the task. The mathematical expression of the attention mechanism is shown below:
Here, , , and denote the query, key, and value matrices, respectively. The query matrix represents the words of interest, the key matrix is used to compute the similarity (i.e., attention scores) between words, and the value matrix is utilized to calculate the final output based on these similarities. To mitigate issues arising from dimensions being too large or too small during the computation, the attention scores are scaled by the square root of the dimension of the key. Subsequently, the softmax function is applied to transform these scores into weights, which are then multiplied with the value matrix to yield the attention vector.
When viewing the text and images of a post, we are easily attracted by the objects in prominent positions in the image. Thus, we learn the key contents of the post. Hence, in this process, we use post images as the query, with the post text serving as key and value matrices, to extract key information from both the text and images of the post. Here, we employ a multi-head attention mechanism to extract key information from the post. Since each modality originates from a different embedding subspace, a direct interaction would fail to produce the desired interactive effect and could introduce noise. Therefore, we map the post image features and post text features into usable vectors separately. We compute the query vector , key vector , and value vector using Equations (5)–(7). Here, , , and are learnable parameter matrices. In this context, n represents the maximum sequence length, and d denotes the dimension of the vectors.
Next, we proceed to fuse textual information with the key information extracted from the post. Textual information, denoted as , is composed of topic text features and post text features . Given the distinct embedding spaces of different modalities and the possibility that a single fusion approach may fail to effectively integrate and fully capture the relational information, we are inspired by Yang et al. [27] to utilize context-aware attention for the fusion of the two features. For multimodal context-aware attention fusion, it is first necessary to generate query, key, and value vectors for the primary modality. Here, we consider the textual information as the primary modality and thus represent it as key, query, and value vectors through linear mappings, as shown in Equation (9). In this process, , , and are learnable parameters.
Next, we inject the post key information features into the key and value vectors just generated. Then, we use a gating mechanism to control the amount of post key information injected. Specifically, this is accomplished through Equation (8), where is a learnable parameter that determines the amount of post key information to be infused into the primary textual information.
The in the gating mechanism can be obtained with the following equation, where and are learnable parameters.
After obtaining the key and value vectors infused with the post key information through the aforementioned method, we employ the conventional dot-product attention mechanism to acquire the multimodal fusion vector based on post key information.
To ensure the retention of valid information while fully utilizing the relationship between post key information and primary textual information, we control the amount of information that is transmitted through a post relationship information fusion gate.
where and are trainable parameters. ⊕ denotes concatenation. represents the post key information gate, which controls the amount of information transmitted. Ultimately, the fused representation of the post’s key information, denoted as , is obtained as follows:
where ⊗ denotes matrix multiplication.
3.3.2. Fusion Based on Key Information from Topic
Similarly, we need to analyze the relationship between the input textual information, denoted as , and the key information of the topic. However, the single-modal information of the topic cannot accurately represent the key content it embodies, leading to poor fusion results. Therefore, we fully explore the relationship between the input textual information and the key information of the topic through this module. Firstly, we extract the key information of the topic from its textual features and image features using an attention mechanism, which can be specifically represented as follows:
Subsequently, we effectively fuse the topic key information with the textual information using a context-aware attention mechanism, analogous to our earlier fusion of post key information. Initially, we transform the input textual content into query, key, and value representations. Next, we integrate the topic key information into both the key and value. Ultimately, we obtain the fused features based on the topic’s key information through traditional dot-product attention, which can be specifically represented as follows:
Equation (20) supports the product based on the rules of matrix and vector operations in linear algebra. Specifically, this equation obtains matrix through a series of linear transformations and a nonlinear activation function . Equation represents the multiplication operation of two matrices: and . is the product of matrix multiplied by matrix , and then multiplied by matrix . Finally, a nonlinear activation function is applied to enable it to learn more complex relationships.
Finally, in order to ensure that the valid information of the input text and the relationship information between the topic key information and the input text are effectively preserved, we control the amount of information transferred through a gating mechanism:
3.3.3. Emphasis Fusion Based on Bimodality
In most multimodal fusion approaches, text information is treated as primary content while other modalities are considered secondary, which often reduces the importance of these other modalities as the fusion process deepens. To fully explore the useful information in different modalities and the relationships between them, we adopt a dual-modality emphasis fusion strategy. During the fusion stage of the two modalities, each modality is taken as the primary modality in turn, with the other serving as the context for fusion. Taking the fusion of text information and post image information as an example, we first consider text information as the primary modality and post image features as the secondary modality, and we obtain through a context-aware attention mechanism fusion. Then, a gating mechanism is employed to control the amount of fused relational information transmitted. Specifically, the process is shown as follows:
For the fusion between text information and topic image features, we denote the fusion that emphasizes text information as and the fusion that emphasizes topic image features as .
3.3.4. Emphasis-Based Fusion for Tri-Modal Data
To fully analyze the relationships among multimodal data within different scopes, we analyze the fusion relationship between the three modalities from a global perspective. Similarly, to ensure that the significance of each modality is preserved, we analyze their relationships by designating one as the primary modality and the other two as a context, thereby learning the relationship between the three modalities. Taking the example where post image features are the primary modality, with textual content and topic image features as secondary modalities, we illustrate the process. Initially, we employ a context-aware attention mechanism to fuse the post images (primary) with the textual content (secondary), yielding . Subsequently, we use the textual content as the primary modality and the topic image features as the secondary modality for another type of context-aware attention fusion, resulting in . Relationship information is then controlled via a gating mechanism. It is important to note that the reason we do not fuse post image features with topic image features to obtain during the second context-aware attention fusion is because our primary objective is to generate explanatory text. Finally, the features emphasizing post images in the tri-modal fusion are obtained through a gating mechanism. The specific representation is shown as follows:
In a similar manner, we obtain the tri-modal emphasis fusion feature with the topic image as the primary modality, denoted as . The acquisition of tri-modal fusion features with input textual information as the primary modality differs. First, we emphasize the textual input in the fusion between the input textual information and the topic image features, resulting in . Then, we perform fusion between the input text and the image features of the post, with text as the primary modality, denoted as . Finally, we integrate these two fusion results to obtain the tri-modal fusion features emphasizing textual information, denoted as .
Finally, we integrate fusion results from different levels to ensure the acquisition of optimal fused features. Specifically, we combine the post key information fusion , the topic key information fusion , the bimodal fusion emphasizing text information based on text and post image information , the bimodal fusion emphasizing post image information based on text and post image information , the bimodal fusion emphasizing text information based on text and topic image information , the bimodal fusion emphasizing topic image information based on text and topic image information , the tri-modal fusion emphasizing post image information , the tri-modal fusion emphasizing text information , and the tri-modal fusion emphasizing topic image information . These nine vectors are merged through a holistic gating mechanism, as described by the following equation:
3.4. Multimodal Decoder
We obtained extensive and multi-level relational information through the multi-level multimodal attention-based fusion module, which greatly facilitates the generation of evaluations and explanations for posts. In text generation tasks, residual connections have consistently demonstrated excellent performance. Therefore, we incorporate residual connections to concatenate the multi-level multimodal focused fusion features with the text input features , represented as
where G represents the final representation fed into the encoder. We input into the pre-trained decoder of mBART to generate the content of post evaluation and interpretation by autoregression, i.e., by considering the previously generated content to produce the next token.
where , represents the probability of predicting the z-th token in the target explanation. During training, we optimize the model using the standard cross-entropy loss function:
where is the element corresponding to the i-th token in the target explanation . is the total number of tokens in the target explanation Y.
4. Experiment, Results and Analysis
4.1. Dataset
High-quality datasets for post evaluation and explanation are crucial for the development of the field, with potential applications extending to areas such as short-answer analysis in education. However, existing research only relies on simple text-based classification to evaluate posts, lacking corresponding explanations, which severely limits the guiding and promotional roles of evaluations. To address this, we constructed two multimodal post quality evaluation and interpretation datasets, sourced from the MOOC (Massive Open Online Courses) platforms of Chinese universities. In the data collection process, we used course categories as the main thread and traversed all courses within specific categories. For each course, we iterated through all relevant discussion topics under that course. Based on these discussion topics, we obtained topic–post pairs for each topic. This established a corresponding relationship among course category, course, topic, and post. To ensure the proportion of multimodal data in the multimodal dataset, we automatically analyzed whether each topic–post pair was composed of multimodal data during the crawling process. Pairs that contained only plain text data were directly excluded. Subsequently, we preprocessed the data. Firstly, we filtered out topic–post pairs that contained empty topics or post content. Then, we used a program to remove duplicate topic–post pairs to ensure the quality of the dataset. Additionally, we filtered out certain special characters from the text to standardize the formatting. Ultimately, we obtained data comprising 15,537 multimodal topic–post pairs, of which the Art and Literature dataset contains 3466 pairs and the Education and Teaching dataset contains 12,071 pairs. The evaluation section of the dataset encompasses quality scores, evaluation explanations, and suggestions. The quality scores are divided into five levels, with higher scores indicating a better fit between the post content and the topic. Initially, we utilized deep models and GPT4 to pre-label the quality scores, followed by manual proofreading. For the evaluation explanations and guidance, we first guided the GPT4 API to annotate the data using five specific examples. Then, we conducted a two-person manual proofreading process. Erroneous interpretations were directly revised manually. Specifically, in the process of annotating the evaluation explanations and guidance section, we employed multi-example prompt engineering to guide the GPT4 API in generating evaluation explanations and guidance that conformed to our requirements. We provided five specific examples corresponding to the five evaluation levels for a discussion topic. For the example at level 0, the post’s response deviated from the topic. For the example at level 1, the post partially addressed the topic, but the response was incomplete and stated in a simplistic manner. The example at level 2 provided a response that addressed part of the topic with more detail compared to level 1. For the example at level 3, the post addressed most of the discussion topic, but there were some deficiencies in language expression and logic. For the example at level 4, the post’s content addressed all aspects of the topic but lacked in completeness and clarity. For the example at level 5, the post comprehensively addressed all aspects of the topic, with clear expression and logic. Subsequently, the manual proofreading process was conducted in a progressive manner. The first annotator completed proofreading based on the results generated by GPT4. Then, the second annotator completed proofreading based on the results from both GPT4 and the first annotator. During this process, if there were discrepancies between the annotations of the two annotators, they would discuss and determine the final annotation result. This effectively ensured the accuracy and consistency of the annotations. Figure 5 presents a specific example from the dataset. In our experiments, we divided the dataset into training, validation, and test sets in a ratio of 8:1:1, with the specific division being shown in Table 1.
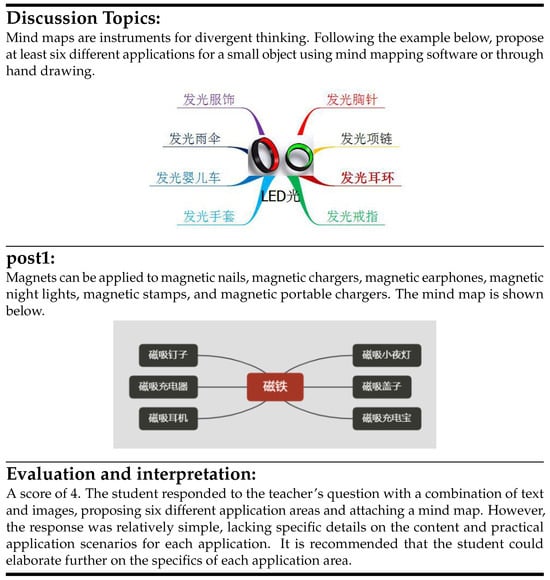
Figure 5.
An example of a multimodal topic post evaluation and interpretation dataset. It consists of discussion topic text, discussion topic image, post text, post image, and evaluation with explanation. The evaluation and explanation section comprises a quality score, an assessment of the comprehensiveness of the response, an overall evaluation of the response quality, and suggestions for improvement.

Table 1.
Overview of the two datasets.
4.2. Experimental Setup
We adopt mBART as the backbone of our model and set the maximum token length to 480. During this process, input tokens are unified to this value through padding or truncation operations. For image feature extraction, we use the CLIP visual encoder to extract visual features, with the dimension set to 4076. In the model training process, we use AdamW as the optimizer, with a learning rate of 5 . The batch size is set to 4, and the maximum number of epochs is set to 25. The experiments were conducted on two newly created datasets for post quality and evaluation, as well as on the publicly available MORE dataset. For model evaluation, we used BLEU-1, BLEU-2, BLEU-3, BLEU-4, ROUGE-1, ROUGE-2, ROUGE-L, and METEOR to assess the generated results.
4.3. Model Comparison
To validate the effectiveness of our model, we conducted comparisons with two types of models: a unimodal (text-only) model and a multimodal (text + image) model. Since there are currently no methods specifically designed for post quality evaluation and explanation generation, we selected models from similar tasks as comparison baselines. For the text-only baseline, we used PGN (the Pointer Generator Network) [28] and BART [29] to generate evaluations and explanations. For the multimodal comparison baseline models, we utilized [30], ExMore [31], and TEAM [32].
PGN enhances the sequence-to-sequence generation model through two forms of orthogonal approaches while tracking the generated content with high coverage to avoid repetition issues.
BART is a model that employs a standard Transformer-based neural machine translation architecture, featuring a bidirectional encoder and a denoising autoencoder.
effectively integrates multimodal data for sarcasm explanation generation through context-aware attention and a global fusion module.
ExMore incorporates cross-modal attention based on the BART architecture to effectively fuse multimodal data for generating explanations.
TEAM leverages multimodal data while introducing external knowledge and combines multi-source semantic graphs to learn the relationships between multi-source information, thereby facilitating the generation of explanations.
To ensure the accuracy of the data results, we conducted three independent replicate experiments for each experimental condition to minimize the influence of random factors. Each experiment strictly followed the same operational procedures and standards to ensure consistency in experimental conditions. Then, we selected the experimental result that was closest to the mean of the three replicates.
We conducted comparative experiments on two newly created datasets, with the results presented in Table 2 and Table 3. Based on the data in the table, we can draw the following conclusions: (1) Our model significantly outperforms all baseline models across every metric. This demonstrates that our model can effectively extract more adequate relational information by focusing different levels of modal data in different ranges and focus on each modality, which in turn better helps to generate evaluations and interpretations. (2) In the comparison between models using unimodal data and those using multimodal data, it is evident that the baselines utilizing multimodal data perform significantly better than those using unimodal data. This further indicates that multimodal data can more comprehensively extract useful information for generative models. (3) For , ExMore, and TEAM, we find that TEAM performs the best. This may be attributed to its incorporation of external knowledge information and relationship information between multi-source data, in addition to using multimodal data. (4) In the comparison between ExMore and models, we observe that ExMore generally outperforms the model, although it slightly lags behind in BLEU-2 and BLEU-3 scores. This may be due to BLEU’s emphasis on word matching. Additionally, when generating explanations, ExMore focuses more on post information without utilizing topic-related information. Consequently, the generated explanations may lack relevance to the topic, resulting in less accurate word matching. (5) In the comparison between the TEAM and MMFFPQ models, we found that the MMFFPQ model significantly outperforms the TEAM model on both datasets. This may be attributed to the fact that the MMFFPQ model equally attends to each modality’s information and employs a multi-level fusion mechanism to conduct deeper and broader multimodal fusion, thereby obtaining more comprehensive information about the relationship between posts and topics. Consequently, the MMFFPQ model significantly surpasses the TEAM model. (6) Among the comparison models that use only text data, BRAT outperforms PGN across all metrics. This could be because BART is based on a Transformer encoder–decoder architecture, which has proven to be effective in numerous studies. Additionally, this model is pre-trained on a large-scale dataset, thus possessing superior performance. (7) When comparing the performance of all models across the two datasets, it can be observed that all models perform better on the large-scale dataset (Education Teaching dataset) than on the small-scale dataset (Art Literature dataset). This may be due to the fact that with sufficient data resources, models can learn more generalized features.
Table 2.
Comparative experimental results for the Art Literature evaluation explanation datasets.
Table 3.
Comparative experimental results for the Educational and Teaching evaluation interpretation dataset.
4.4. Model Comparison in Public Dataset
To further validate our model’s capability in analyzing complex relationships when utilizing multimodal data, we conducted comparative experiments using the publicly available multimodal satirical explanation dataset MORE. The MORE dataset comprises satirical posts with multimodal data sourced from various social media websites, each of which is accompanied by an explanatory annotation that elucidates the satire. Meanwhile, the multimodal satire explanation task involves generating explanations that uncover the satirical intent by analyzing inconsistent cues among the multimodal data. It bears a resemblance to our task in that both aim to explore the relational cues among multimodal data. The baseline models for comparison were categorized into two types: text-based models, which included Pointer-Generator Networks (PGNs) and Transformers, and multimodal-based models, for which we selected M-Transf, ExMore, and TEAM. Our experimental results are presented in Table 4.
Table 4.
Comparative experimental results for public dataset MORE.
By analyzing the data presented in Table 4, we can draw the following observations: (1) On the multimodal sarcasm dataset, it is evident that not all models utilizing multimodal data outperform those relying solely on textual data. This suggests that inappropriate use of visual information may hinder performance in the task of generating sarcasm explanations. (2) In the comparisons with all the models, our model significantly outperforms the other models. This indicates that our model can extract more adequate and multi-range relations to enhance the effectiveness of generative modeling through multimodal fusion with a focus on multiple scopes and levels. In the comparison between ExMore and the TEAM model, the performance of ExMore is significantly weaker than that of TEAM. This may be attributed to the fact that TEAM incorporates external knowledge and multi-source semantic graphs. External knowledge provides the model with additional information, while multi-source semantic graphs assist the model in capturing more relational information among multimodal data. Meanwhile, the ExMore model exhibits better performance on the ROUGE metric compared to the BLEU metric. This could be because BLEU emphasizes precision, whereas ROUGE focuses on recall. This indicates that the model demonstrates relatively better capability in information coverage.
4.5. Ablation Study
To further analyze the impact of each module on the model, we conducted extensive ablation experiments on the Art Literature and the Education and Teaching datasets. To evaluate the role of the key information fusion based on post (KIFBP) module in generating post quality evaluations, we removed this module from the model and denoted it as -w/o KIFBP. Similarly, to demonstrate the advantages of the key information fusion based on topic (KIFBT) module, we also removed this module in model and denoted as -w/o KIFBT. In the context of the emphasis fusion based on bimodality modules, we removed the bimodal focused fusion module that emphasizes text data from the fusion of text input and topic images, denoting it as -w/o BFF(I). Moreover, we removed the module that emphasizes topic images, denoting it as -w/o BFF(II). In the bimodal focused fusion between input text and post images, we removed the module that emphasizes text, denoting it as -w/o BFF(III), as well as the module that emphasizes post images, denoting as -w/o BFF(IV). Furthermore, we validated the roles of different fusion in the emphasis-based fusion for tri-modal data modules. We removed the module that emphasizes text in the tri-modal fusion, denoting it as -w/o FFBT(I); the module that emphasizes topic images, denoting it as -w/o FFBT(II); and the module that emphasizes post images, denoting it as -w/o FFBT(III).
From Table 5 and Table 6, we have the following observations: (1) In multi-level fusion, we find that BFF(I) has the greatest impact on the model, which may be that the content relevance of the answer to the topic is an important direction of influence on the accuracy of the answer. Textual information also plays a primary role in generating evaluations and explanations. (2) In ablation experiments conducted on different modules, we find that each module contributes positively to the model’s performance. (3) When comparing the fusion of key information based on posts and topics, we find that the difference in their impact on the model is not significant. However, the fusion of key information based on topics may have a slightly greater influence on model performance, possibly due to the closer alignment between the topic content and the accuracy of the response. (4) In the two modal feature fusion modules of input text and post images, BFF(IV), which focuses on the fusion of post images, has a relatively greater impact on the model. This may be because the post image is more capable of capturing the salient information of the post, thus helping the model to analyze the relationship between the topic text and the post image feature and the relationship information between the post text and the post image feature, which in turn effectively helps to generate the ability to evaluate and interpret. (5) In the focused fusion based on three modalities, it is found that the fusion that emphasizes the topic image as the primary information plays a relatively more significant role. This may be because it thoroughly analyzes the relationships between the prominent content of the theme and other modalities, which better guides the model to generate evaluations and explanations that are more closely related to the topic.
Table 5.
Results of ablation experiments on the Art Literature evaluation explanation datasets.
Table 6.
Results of ablation experiments on the Education evaluation explanation datasets.
4.6. Case Study
To provide a more intuitive understanding of how our model generates accurate post quality evaluations through deep, focused multimodal fusion across various ranges, Figure 6 presents a specific example from the test set. It is evident that models relying solely on textual modal data do not provide accurate evaluations. This underscores the limitation of using unimodal data in comprehensively analyzing the relationship between posts and topics. When compared to the results of other models utilizing multimodal data, they do not generate more accurate and comprehensive evaluations or explanations. This demonstrates that our model, by integrating multiple ranges and levels of modalities while giving attention to each modality, can more fully capture the complex relational information between posts and topics, enabling the model to generate more accurate evaluations and explanations.

Figure 6.
An example from the test set. It demonstrates that analyzing the relationship between posts and topics across multiple scales and levels is necessary to provide more accurate evaluations and explanations of post quality.
5. Conclusions
In this work, we propose a novel task, namely multimodal post quality assessment and explanation, which aims to generate post quality evaluations and explanations by leveraging multimodal data to analyze the relationship between posts and topics. To address this task, we introduce a model for post quality assessment and explanation based on multimodal multi-level fusion. This model focuses on each modality during the fusion process and comprehensively captures the complex associative information between posts and topics through a multi-level, multi-scope fusion mechanism, thereby generating accurate post quality evaluations and explanations. Experiments are conducted on two newly collected datasets and one public dataset, MORE. The experimental results demonstrate that our model outperforms all baseline models across various evaluation metrics. Specifically, on the Literature and Art dataset, our model achieves improvements of 10.32% and 13.72% in METEOR and BLEU-4 scores, respectively, compared to the best-performing baseline model, TEAM. In the ablation study, we observe that each fusion module has a positive impact on the model’s performance. Among them, the module emphasizing text in the bimodal fusion of text input and topic images has the most significant impact on the model, with a 12.35% influence on the ROUGE-L.
6. Future Work
We will analyze how we should approach a future work and challenges from the following aspects: (1) Incorporating text extraction from images. Textual information within images can provide valuable cues for post evaluation and explanation generation. In the future, we will integrate this information. (2) Integrating external knowledge resources, such as knowledge graphs or external knowledge bases, to provide the generation model with more effective resources to enhance its performance. However, constructing and maintaining a knowledge graph pertinent to educational evaluation entails considerable effort, such as extracting information from the literature, verifying it, and rectifying errors. Furthermore, knowledge graphs are heterogeneous, exhibiting various schemas, which complicates the process of aligning and integrating data from multiple sources. (3) Building a framework that combines evaluations with recommendations, which not only effectively analyzes and evaluates students’ performance while providing relevant evaluations and explanations but also recommends learning resources based on each student’s learning weaknesses to improve their abilities. This approach enables a closed loop between evaluation and learning.
Author Contributions
Methodology, X.G. and H.C.; software, X.G.; writing—original draft preparation, X.G.; data collection and revision, X.G., Y.C. and H.Z.; writing—review and editing, X.G. and H.C.; funding acquisition, H.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Humanities and Social Sciences Planning Fund of the Ministry of Education of China (No. 24YJA880002) and the National Social Science Fund of China (No. 24CTQ016).
Data Availability Statement
All data are open public data and able to be downloaded free of charge.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Ntourmas, A.; Daskalaki, S.; Dimitriadis, Y.; Avouris, N. Classifying MOOC forum posts using corpora semantic similarities: A study on transferability across different courses. Neural Comput. Appl. 2023, 35, 161–175. [Google Scholar] [CrossRef]
- El-Rashidy, M.A.; Khodeir, N.A.; Farouk, A.; Aslan, H.K.; El-Fishawy, N.A. Attention-based contextual local and global features for urgent posts classification in MOOCs discussion forums. Ain Shams Eng. J. 2024, 15, 102605. [Google Scholar] [CrossRef]
- Urvi, S.; Rambhia, R.; Kothari, P.; Ramesh, R.; Banerjee, G. Automatic Classification of MOOC Forum Messages to Measure the Quality of Peer Interaction. In Proceedings of the International Conference on Computers in Education, Online, 22–26 November 2021. [Google Scholar]
- Yang, B.; Tang, H.; Hao, L.; Rose, J.R. Untangling chaos in discussion forums: A temporal analysis of topic-relevant forum posts in MOOCs. Comput. Educ. 2022, 178, 104402. [Google Scholar] [CrossRef]
- Huang, C.Q.; Han, Z.M.; Li, M.X.; Jong, M.S.y.; Tsai, C.C. Investigating students’ interaction patterns and dynamic learning sentiments in online discussions. Comput. Educ. 2019, 140, 103589. [Google Scholar] [CrossRef]
- Zou, W.; Hu, X.; Pan, Z.; Li, C.; Cai, Y.; Liu, M. Exploring the relationship between social presence and learners’ prestige in MOOC discussion forums using automated content analysis and social network analysis. Comput. Hum. Behav. 2021, 115, 106582. [Google Scholar] [CrossRef]
- Tao, X.; Shannon-Honson, A.; Delaney, P.; Dann, C.; Xie, H.; Li, Y.; O’Neill, S. Towards an understanding of the engagement and emotional behaviour of MOOC students using sentiment and semantic features. Comput. Educ. Artif. Intell. 2023, 4, 100116. [Google Scholar] [CrossRef]
- Liu, Z.; Kong, X.; Chen, H.; Liu, S.; Yang, Z. MOOC-BERT: Automatically identifying learner cognitive presence from MOOC discussion data. IEEE Trans. Learn. Technol. 2023, 16, 528–542. [Google Scholar] [CrossRef]
- Liu, S.; Liu, S.; Liu, Z.; Peng, X.; Yang, Z. Automated detection of emotional and cognitive engagement in MOOC discussions to predict learning achievement. Comput. Educ. 2022, 181, 104461. [Google Scholar] [CrossRef]
- Munigadiapa, P.; Adilakshmi, T. MOOC-LSTM: The LSTM architecture for sentiment analysis on MOOCs forum posts. In Computational Intelligence and Data Analytics: Proceedings of ICCIDA 2022; Springer: Singapore, 2022; pp. 283–293. [Google Scholar]
- del Águila Escobar, R.A.; Suárez-Figueroa, M.C.; Fernández-López, M. OBOE: An Explainable Text Classification Framework. Int. J. Interact. Multimed. Artif. Intell. 2024, 8, 24–37. [Google Scholar] [CrossRef]
- Ouhaichi, H.; Spikol, D.; Vogel, B. Research trends in multimodal learning analytics: A systematic mapping study. Comput. Educ. Artif. Intell. 2023, 4, 100136. [Google Scholar] [CrossRef]
- Wu, D.; Chen, J.; Deng, W.; Wei, Y.; Luo, H.; Wei, Y. The recognition of teacher behavior based on multimodal information fusion. Math. Probl. Eng. 2020, 2020, 8269683. [Google Scholar] [CrossRef]
- Bhattacharjee, S.D.; Gokaraju, J.S.A.V.; Yuan, J.; Kalwa, A. Multi-view knowledge graph for explainable course content recommendation in course discussion posts. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2785–2791. [Google Scholar]
- Li, M.; Zhuang, X.; Bai, L.; Ding, W. Multimodal graph learning based on 3D Haar semi-tight framelet for student engagement prediction. Inf. Fusion 2024, 105, 102224. [Google Scholar] [CrossRef]
- Verma, N.; Getenet, S.; Dann, C.; Shaik, T. Designing an artificial intelligence tool to understand student engagement based on teacher’s behaviours and movements in video conferencing. Comput. Educ. Artif. Intell. 2023, 5, 100187. [Google Scholar] [CrossRef]
- Wang, Y.; He, J.; Wang, D.; Wang, Q.; Wan, B.; Luo, X. Multimodal transformer with adaptive modality weighting for multimodal sentiment analysis. Neurocomputing 2024, 572, 127181. [Google Scholar] [CrossRef]
- Zhao, G.; Zhang, Y.; Chu, J. A multimodal teacher speech emotion recognition method in the smart classroom. Internet Things 2024, 25, 101069. [Google Scholar] [CrossRef]
- Nandi, A.; Xhafa, F.; Subirats, L.; Fort, S. A survey on multimodal data stream mining for e-learner’s emotion recognition. In Proceedings of the 2020 International Conference on Omni-Layer Intelligent Systems (COINS), Barcelona, Spain, 31 August–2 September 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Liu, Z.; Kong, W.; Peng, X.; Yang, Z.; Liu, S.; Liu, S.; Wen, C. Dual-feature-embeddings-based semi-supervised learning for cognitive engagement classification in online course discussions. Knowl.-Based Syst. 2023, 259, 110053. [Google Scholar] [CrossRef]
- Song, L.; Yu, M.; Shang, X.; Lu, Y.; Liu, J.; Zhang, Y.; Li, Z. A deep grouping fusion neural network for multimedia content understanding. IET Image Process. 2022, 16, 2398–2411. [Google Scholar] [CrossRef]
- Ding, X.; Han, T.; Fang, Y.; Larson, E. An approach for combining multimodal fusion and neural architecture search applied to knowledge tracing. Appl. Intell. 2023, 53, 11092–11103. [Google Scholar] [CrossRef]
- Chango, W.; Silva, G.; Sanchez, H.; Logrono, S. Predicting academic performance of undergraduate students in blended learning. In Proceedings of the 2024 IEEE Colombian Conference on Communications and Computing (COLCOM), Dubai, United Arab Emirates, 2–5 December 2019; IEEE: Piscataway, NJ, USA, 2024; pp. 1–6. [Google Scholar]
- Wei, T.; Chen, D.; Zhou, W.; Liao, J.; Tan, Z.; Yuan, L.; Zhang, W.; Yu, N. Hairclip: Design your hair by text and reference image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 18072–18081. [Google Scholar]
- Sammani, F.; Mukherjee, T.; Deligiannis, N. Nlx-gpt: A model for natural language explanations in vision and vision-language tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 8322–8332. [Google Scholar]
- Song, J.; Chen, H.; Li, C.; Xie, K. MIFM: Multimodal Information Fusion Model for Educational Exercises. Electronics 2023, 12, 3909. [Google Scholar] [CrossRef]
- Yang, B.; Li, J.; Wong, D.F.; Chao, L.S.; Wang, X.; Tu, Z. Context-aware self-attention networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 387–394. [Google Scholar]
- See, A.; Liu, P.J.; Manning, C.D. Get to the point: Summarization with pointer-generator networks. arXiv 2017, arXiv:1704.04368. [Google Scholar]
- Lewis, M. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv 2019, arXiv:1910.13461. [Google Scholar]
- Kumar, S.; Kulkarni, A.; Akhtar, M.S.; Chakraborty, T. When did you become so smart, oh wise one?! Sarcasm explanation in multi-modal multi-party dialogues. arXiv 2022, arXiv:2203.06419. [Google Scholar]
- Desai, P.; Chakraborty, T.; Akhtar, M.S. Nice perfume. How long did you marinate in it? Multimodal sarcasm explanation. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual Event, 22 February–1 March 2022; Volume 36, pp. 10563–10571. [Google Scholar]
- Jing, L.; Song, X.; Ouyang, K.; Jia, M.; Nie, L. Multi-source semantic graph-based multimodal sarcasm explanation generation. arXiv 2023, arXiv:2306.16650. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).