
Semantic Segmentation of Key Categories in Transmission Line Corridor Point Clouds Based on EMAFL-PTv3


Abstract
1. Introduction
- A novel end-to-end point cloud semantic segmentation model: The EMAFL-PTv3 model integrates the EMA module to enhance PTv3’s network architecture, improving its ability to extract multi-scale features from transmission line corridor point clouds. The incorporation of Focal Loss addresses class imbalance issues effectively.
- Application and validation: The proposed EMAFL-PTv3 model is applied to a transmission corridor point cloud dataset collected from real-world locations in Hubei and other regions. The model successfully segments the dataset into five categories: insulator strings, pylons, transmission lines, ground wires, and ground, demonstrating its effectiveness and precision. The detailed explanation of these categories can be found in Appendix A.
- Extensive comparison and ablation studies: Comprehensive comparison experiments are conducted between the proposed EMA module and other mainstream attention mechanisms. Additionally, ablation studies of the two proposed modifications are performed, demonstrating the superiority and effectiveness of the improvements introduced in this paper.
2. Methods
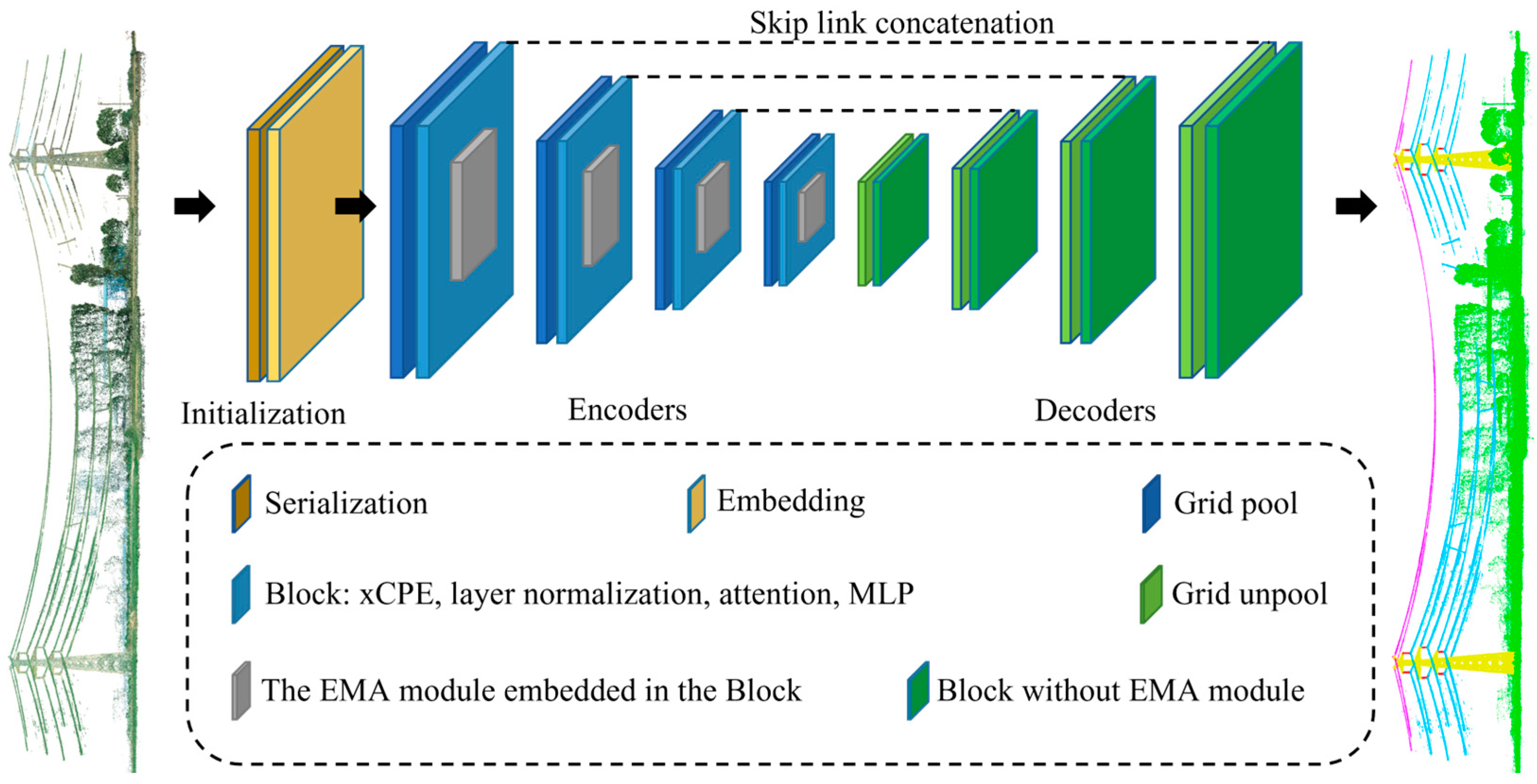
2.1. EMAFL-PTv3 Framework
2.2. EMA Module
2.3. Loss Function Improvement
3. Experiments and Results
3.1. Dataset
3.2. Experimental Environment and Parameter Settings
3.3. Evaluation Metrics
3.4. Results Analysis
4. Discussion
4.1. Performance of Models Integrating Different Attention Mechanisms
4.2. Ablation Study on the Contribution of Two Proposed Improvements to Model Performance
4.3. Impact of Different Channel Grouping Numbers in the EMA Module on Model Performance
4.4. Limitations and Potential Directions for Future Work
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| PTv3 | Point Transformer v3 |
| EMA | Efficient Multi-Scale Attention |
| IoU | Intersection over Union |
| mIoU | Mean Intersection over Union |
| mA | Mean Accuracy |
| OA | Overall Accuracy |
| LiDAR | Light Detection and Ranging |
| DBSCAN | Density-Based Spatial Clustering of Applications with Noise |
| SVM | Support Vector Machine |
| RF | Random Forest |
| MLP | Multilayer Perceptron |
| SE | Squeeze-and-Excitation Networks |
| CBAM | Convolutional Block Attention Module |
| ECA | Efficient Channel Attention |
| CA | Coordinate Attention |
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Technical Terms | Definition |
|---|---|
| Focal Loss [37] | A modified version of cross-entropy loss that reduces the impact of well-classified samples and focuses more on difficult-to-classify samples, improving performance on imbalanced datasets. |
| Hilbert Curve Serialization [35] | A space-filling curve that preserves spatial locality when mapping 3D points into a 1D sequence, ensuring that nearby points remain close in the serialized structure. |
| IoU (Intersection over Union) | A metric used to evaluate segmentation accuracy by measuring the overlap between predicted and ground truth regions. |
| mIoU (Mean Intersection over Union) | A metric used in segmentation tasks to measure the average overlap between predicted and ground truth regions across all categories. It provides a comprehensive assessment of model performance. |
| mA (Mean Accuracy) | The average per-class accuracy in a segmentation task calculated as the mean of the individual class accuracies. It evaluates how well the model classifies each category. |
| OA (Overall Accuracy) | The overall percentage of correctly classified points in the dataset, providing a general measure of segmentation performance. |
| Ground Truth | The manually labeled or verified data used as a reference for evaluating model predictions. In point cloud segmentation, it refers to the correct classification of each point. |
| Transmission Line Corridor | The designated space surrounding high-voltage power transmission lines, including pylons, conductors, ground wires, as well as the ground and surrounding objects beneath the transmission lines. Maintaining this corridor is essential for safety, operational efficiency, and vegetation management. |
| Ground | One of the segmentation categories in this study. Refers to the terrain or surface within the transmission line corridor. In this study, ground, vegetation, and buildings within the corridor are all classified under the “Ground” category. This classification simplifies the segmentation process while maintaining scene understanding. |
| Ground Wire | One of the segmentation categories in this study. A wire used in power transmission lines, typically positioned above conductors to protect against lightning strikes. |
| Insulator String | One of the segmentation categories in this study. A series of insulating components that suspend transmission lines from pylons while preventing electrical current from flowing through the supporting structures. |
| Pylon | One of the segmentation categories in this study. A tall tower-like structure that supports high-voltage power transmission lines, ensuring safe electrical clearance and mechanical stability. |
| Transmission Line | One of the segmentation categories in this study. The high-voltage conductors used to transport electricity over long distances within the transmission line corridor. |
References
- He, T.; Zeng, Y.; Hu, Z. Research of Multi-Rotor UAVs Detailed Autonomous Inspection Technology of Transmission Lines Based on Route Planning. IEEE Access 2019, 7, 114955–114965. [Google Scholar] [CrossRef]
- Singh, G.; Stefenon, S.F.; Yow, K.-C. Interpretable Visual Transmission Lines Inspections Using Pseudo-Prototypical Part Network. Mach. Vis. Appl. 2023, 34, 41. [Google Scholar] [CrossRef]
- Xu, C.; Li, Q.; Zhou, Q.; Zhang, S.; Yu, D.; Ma, Y. Power Line-Guided Automatic Electric Transmission Line Inspection System. IEEE Trans. Instrum. Meas. 2022, 71, 3512118. [Google Scholar] [CrossRef]
- Li, X.; Li, Z.; Wang, H.; Li, W. Unmanned Aerial Vehicle for Transmission Line Inspection: Status, Standardization, and Perspectives. Front. Energy Res. 2021, 9, 713634. [Google Scholar] [CrossRef]
- Luo, Y.; Yu, X.; Yang, D.; Zhou, B. A Survey of Intelligent Transmission Line Inspection Based on Unmanned Aerial Vehicle. Artif. Intell. Rev. 2023, 56, 173–201. [Google Scholar] [CrossRef]
- Qin, X.; Wu, G.; Lei, J.; Fan, F.; Ye, X.; Mei, Q. A Novel Method of Autonomous Inspection for Transmission Line Based on Cable Inspection Robot LiDAR Data. Sensors 2018, 18, 596. [Google Scholar] [CrossRef]
- Tang, J.; Tan, J.; Du, Y.; Zhao, H.; Li, S.; Yang, R.; Zhang, T.; Li, Q. Quantifying Multi-Scale Performance of Geometric Features for Efficient Extraction of Insulators from Point Clouds. Remote Sens. 2023, 15, 3339. [Google Scholar] [CrossRef]
- Zengin, A.T.; Erdemir, G.; Akinci, T.C.; Seker, S. Measurement of Power Line Sagging Using Sensor Data of a Power Line Inspection Robot. IEEE Access 2020, 8, 99198–99204. [Google Scholar] [CrossRef]
- Huang, J.; Shen, Y.; Wang, J.; Ferreira, V. Automatic Pylon Extraction Using Color-Aided Classification from UAV LiDAR Point Cloud Data. IEEE Trans. Instrum. Meas. 2023, 72, 2520611. [Google Scholar] [CrossRef]
- Zu, S.; Wang, L.; Wu, S.; Wang, G.; Song, B. Power Pylon Type Identification and Characteristic Parameter Calculation from Airborne LiDAR Data. Electronics 2024, 13, 3032. [Google Scholar] [CrossRef]
- Huang, Y.; Du, Y.; Shi, W. Fast and Accurate Power Line Corridor Survey Using Spatial Line Clustering of Point Cloud. Remote Sens. 2021, 13, 1571. [Google Scholar] [CrossRef]
- Xie, Y.; Tian, J.; Zhu, X.X. Linking Points with Labels in 3D: A Review of Point Cloud Semantic Segmentation. IEEE Geosci. Remote Sens. Mag. 2020, 8, 38–59. [Google Scholar] [CrossRef]
- McLaughlin, R.A. Extracting Transmission Lines from Airborne LIDAR Data. IEEE Geosci. Remote Sens. Lett. 2006, 3, 222–226. [Google Scholar] [CrossRef]
- Liu, Y.; Li, Z.; Hayward, R.; Walker, R.; Jin, H. Classification of Airborne LIDAR Intensity Data Using Statistical Analysis and Hough Transform with Application to Power Line Corridors. In Proceedings of the 2009 Digital Image Computing: Techniques and Applications (DICTA 2009), Melbourne, Australia, 1–3 December 2009; Shi, H., Zhang, Y.C., Bottema, M.J., Lovell, B.C., Maeder, A.J., Eds.; IEEE: New York, NY, USA, 2009; p. 462. [Google Scholar]
- Yermo, M.; Laso, R.; Lorenzo, O.G.; Pena, T.F.; Cabaleiro, J.C.; Rivera, F.F.; Vilariño, D.L. Powerline Detection and Characterization in General-Purpose Airborne LiDAR Surveys. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2024, 17, 10137–10157. [Google Scholar] [CrossRef]
- Shan, L.; Yue, J. Automatic Extraction Algorithm of High Voltage Pylon Based on LiDAR Point Cloud. Laser Optoelectron. Prog. 2021, 58, 2428009. [Google Scholar] [CrossRef]
- Ortega, S.; Trujillo, A.; Santana, J.M.; Suárez, J.P.; Santana, J. Characterization and Modeling of Power Line Corridor Elements from LiDAR Point Clouds. ISPRS J. Photogramm. Remote Sens. 2019, 152, 24–33. [Google Scholar] [CrossRef]
- Chen, M.; Li, J.; Pan, J.; Ji, C.; Ma, W. Insulator Extraction from UAV LiDAR Point Cloud Based on Multi-Type and Multi-Scale Feature Histogram. Drones 2024, 8, 241. [Google Scholar] [CrossRef]
- Pan, Y.-R.; Xia, Y.-H.; Long, L.-J.; Yang, M. Power-Line Extraction and Modelling from 3D Point Clouds Data Based on K-D Tree DBSCAN Algorithm. J. Electr. Eng. Technol. 2024, 19, 3587–3597. [Google Scholar] [CrossRef]
- Awrangjeb, M.; Islam, M.K. Classifier-Free Detection of Power Line Pylons from Point Cloud Data. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 4, 81–87. [Google Scholar] [CrossRef]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic Point Cloud Interpretation Based on Optimal Neighborhoods, Relevant Features and Efficient Classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual Classification of Lidar Data and Building Object Detection in Urban Areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X.; Ning, X. SVM-Based Classification of Segmented Airborne LiDAR Point Clouds in Urban Areas. Remote Sens. 2013, 5, 3749–3775. [Google Scholar] [CrossRef]
- Tang, Q.; Zhang, L.; Lan, G.; Shi, X.; Duanmu, X.; Chen, K. A Classification Method of Point Clouds of Transmission Line Corridor Based on Improved Random Forest and Multi-Scale Features. Sensors 2023, 23, 1320. [Google Scholar] [CrossRef]
- Charles, R.Q.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, California, USA, 4–9 December 2017; Curran Associates Inc.: Red Hook, NY, USA, 2017; pp. 5105–5114. [Google Scholar]
- Caros, M.; Just, A.; Segui, S.; Vitria, J. Object Segmentation of Cluttered Airborne LiDAR Point Clouds. In Artificial Intelligence Research and Development; Cortes, A., Grimaldo, F., Flaminio, T., Eds.; Ios Press: Amsterdam, The Netherlands, 2022; Volume 356, pp. 259–268. [Google Scholar]
- Yin, Z.; Ji, S.; Zhang, X.; Dai, J.; Yu, W.; Wu, S. Classification Model of Point Cloud Along Transmission Line Based on Group Normalization. Front. Energy Res. 2022, 10, 839273. [Google Scholar] [CrossRef]
- Li, X.; Li, Y.; Chen, Y.; Zhang, G.; Liu, Z. Deep Learning-Based Target Point Localization for UAV Inspection of Point Cloud Transmission Towers. Remote Sens. 2024, 16, 817. [Google Scholar] [CrossRef]
- Wang, G.; Wang, L.; Wu, S.; Zu, S.; Song, B. Semantic Segmentation of Transmission Corridor 3D Point Clouds Based on CA-PointNet++. Electronics 2023, 12, 2829. [Google Scholar] [CrossRef]
- Zhou, Y.; Feng, Z.; Chen, C.; Yu, F. Bilinear Distance Feature Network for Semantic Segmentation in PowerLine Corridor Point Clouds. Sensors 2024, 24, 5021. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11105–11114. [Google Scholar]
- Zhao, H.; Jiang, L.; Jia, J.; Torr, P.; Koltun, V. Point Transformer. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 16239–16248. [Google Scholar]
- Wu, X.; Lao, Y.; Jiang, L.; Liu, X.; Zhao, H. Point Transformer V2: Grouped Vector Attention and Partition-Based Pooling. In Proceedings of the 36th International Conference on Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022; Curran Associates Inc.: Red Hook, NY, USA, 2024; pp. 33330–33342. [Google Scholar]
- Wu, X.; Jiang, L.; Wang, P.-S.; Liu, Z.; Liu, X.; Qiao, Y.; Ouyang, W.; He, T.; Zhao, H. Point Transformer V3: Simpler, Faster, Stronger. In Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 11–15 June 2024; pp. 4840–4851. [Google Scholar]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2025; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The Lovasz-Softmax Loss: A Tractable Surrogate for the Optimization of the Intersection-Over-Union Measure in Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 4413–4421. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision–ECCV 2018, Munich, Germany, 8–14 September 2018; Springer: Cham, Switzerland, 2018; pp. 3–19. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 13708–13717. [Google Scholar]


| Model | IoU (%) | mIoU (%) | mA (%) | OA (%) | ||||
|---|---|---|---|---|---|---|---|---|
| Ground | Ground Wire | Insulator String | Pylon | Transmission Line | ||||
| EMAFL-PTv3 (ours) | 97.34 | 97.00 | 67.25 | 91.77 | 98.97 | 90.46 | 92.86 | 98.07 |
| PTv3 (baseline) | 93.99 | 91.91 | 60.19 | 80.38 | 98.39 | 84.97 | 90.11 | 95.63 |
| PTv2 | 97.20 | 92.69 | 20.38 | 87.68 | 95.84 | 78.74 | 84.66 | 96.82 |
| PTv1 | 95.36 | 95.08 | 16.19 | 79.03 | 94.49 | 76.03 | 82.65 | 95.03 |
| PointNet++ | 86.70 | 39.70 | 0 | 0.20 | 55.50 | 36.42 | 55.84 | 76.01 |
| PointNet | 93.10 | 43.50 | 3.70 | 34.00 | 66.30 | 48.11 | 63.75 | 84.35 |
| Categories | Ground # | Ground Wire # | Insulator String # | Pylon # | Transmission Line # | OA (%) |
|---|---|---|---|---|---|---|
| Ground * | 1,127,555 | 0 | 0 | 48,126 | 23 | 95.90% |
| Ground wire * | 0 | 59,239 | 0 | 881 | 0 | 98.53% |
| Insulator string * | 0 | 145 | 8430 | 538 | 345 | 89.13% |
| Pylon * | 0 | 523 | 979 | 288,061 | 3 | 99.48% |
| Transmission line * | 4 | 0 | 1681 | 0 | 289,754 | 99.42% |
| Attention Mechanism | IoU (%) | mIoU (%) | mA (%) | OA (%) | ||||
|---|---|---|---|---|---|---|---|---|
| Ground | Ground Wire | Insulator String | Pylon | Transmission Line | ||||
| - | 95.01 | 88.40 | 65.74 | 87.04 | 96.71 | 86.76 | 91.33 | 96.76 |
| SE | 94.98 | 93.88 | 61.73 | 83.99 | 98.85 | 86.69 | 91.06 | 96.42 |
| CBAM | 97.15 | 95.80 | 63.06 | 90.62 | 98.68 | 89.06 | 92.76 | 97.82 |
| ECA | 97.12 | 89.32 | 56.84 | 89.51 | 98.51 | 86.26 | 90.37 | 97.53 |
| CA | 96.52 | 92.05 | 58.86 | 88.48 | 98.96 | 86.92 | 91.08 | 97.32 |
| EMA (ours) | 97.34 | 97.00 | 67.25 | 91.77 | 98.97 | 90.46 | 92.86 | 98.07 |
| Model | IoU (%) | mIoU (%) | mA (%) | OA (%) | ||||
|---|---|---|---|---|---|---|---|---|
| Ground | Ground Wire | Insulator String | Pylon | Transmission Line | ||||
| PTv3 (baseline) | 93.99 | 91.91 | 60.19 | 80.38 | 98.39 | 84.97 | 90.11 | 95.63 |
| PTv3 + EMA | 96.93 | 96.75 | 63.25 | 90.49 | 98.58 | 89.20 | 91.95 | 97.75 |
| PTv3 + Focal Loss | 95.01 | 88.40 | 65.74 | 87.04 | 96.71 | 86.76 | 91.33 | 96.76 |
| PTv3 + EMA + Focal Loss (ours) | 97.34 | 97.00 | 67.25 | 91.77 | 98.97 | 90.46 | 92.86 | 98.07 |
| G | IoU (%) | mIoU (%) | mA (%) | OA (%) | ||||
|---|---|---|---|---|---|---|---|---|
| Ground | Ground Wire | Insulator String | Pylon | Transmission Line | ||||
| 1 | 97.34 | 97.00 | 67.25 | 91.77 | 98.97 | 90.46 | 92.86 | 98.07 |
| 2 | 96.95 | 93.94 | 61.20 | 90.13 | 98.79 | 88.20 | 91.19 | 97.68 |
| 4 | 96.88 | 90.75 | 62.96 | 89.15 | 98.56 | 87.66 | 91.26 | 97.48 |
| 8 | 97.05 | 91.38 | 66.51 | 89.90 | 98.76 | 88.70 | 92.61 | 97.65 |
| 16 | 96.66 | 96.79 | 57.99 | 88.98 | 98.28 | 87.74 | 90.97 | 97.46 |
| 32 | 97.47 | 95.42 | 65.66 | 91.78 | 99.01 | 89.97 | 92.69 | 98.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, L.; Wang, L.; Wu, S.; Zu, S.; Ai, Y.; Song, B. Semantic Segmentation of Key Categories in Transmission Line Corridor Point Clouds Based on EMAFL-PTv3. Electronics 2025, 14, 650. https://doi.org/10.3390/electronics14040650
Lu L, Wang L, Wu S, Zu S, Ai Y, Song B. Semantic Segmentation of Key Categories in Transmission Line Corridor Point Clouds Based on EMAFL-PTv3. Electronics. 2025; 14(4):650. https://doi.org/10.3390/electronics14040650
Chicago/Turabian StyleLu, Li, Linong Wang, Shaocheng Wu, Shengxuan Zu, Yuhao Ai, and Bin Song. 2025. "Semantic Segmentation of Key Categories in Transmission Line Corridor Point Clouds Based on EMAFL-PTv3" Electronics 14, no. 4: 650. https://doi.org/10.3390/electronics14040650
APA StyleLu, L., Wang, L., Wu, S., Zu, S., Ai, Y., & Song, B. (2025). Semantic Segmentation of Key Categories in Transmission Line Corridor Point Clouds Based on EMAFL-PTv3. Electronics, 14(4), 650. https://doi.org/10.3390/electronics14040650