
PDNet by Partial Deep Convolution: A Better Lightweight Detector

 ,
,
Abstract
1. Introduction
- In the process of feature map generation, this paper introduced a new idea: retaining only part of the redundant feature maps can achieve similar results as retaining all the redundant feature maps completely. This idea explores a new way of dealing with feature map redundancy, aiming to improve the efficiency of the model while maximising the retention of key information.
- This paper proposed a lightweight convolutional module, PDConv, which is designed to reduce the complexity of the model. PDConv is capable of removing part of the redundant feature maps, thus reducing the number of parameters and computational burden of the network while maintaining the model performance.
- Based on PDConv, this paper has designed a more suitable PDBottleneck and PDC2f structure to better exploit the characteristics of PDConv.
- This paper constructed a lightweight network structure, PDNet, which integrates PDConv, PDBottleneck, and PDC2f modules and achieves the goal of reducing model complexity while maintaining accuracy in feature extraction through well-designed connections and parameter settings.
2. Related Work
3. Principles and Methods
3.1. HOW PDConv
3.2. Computational Complexity
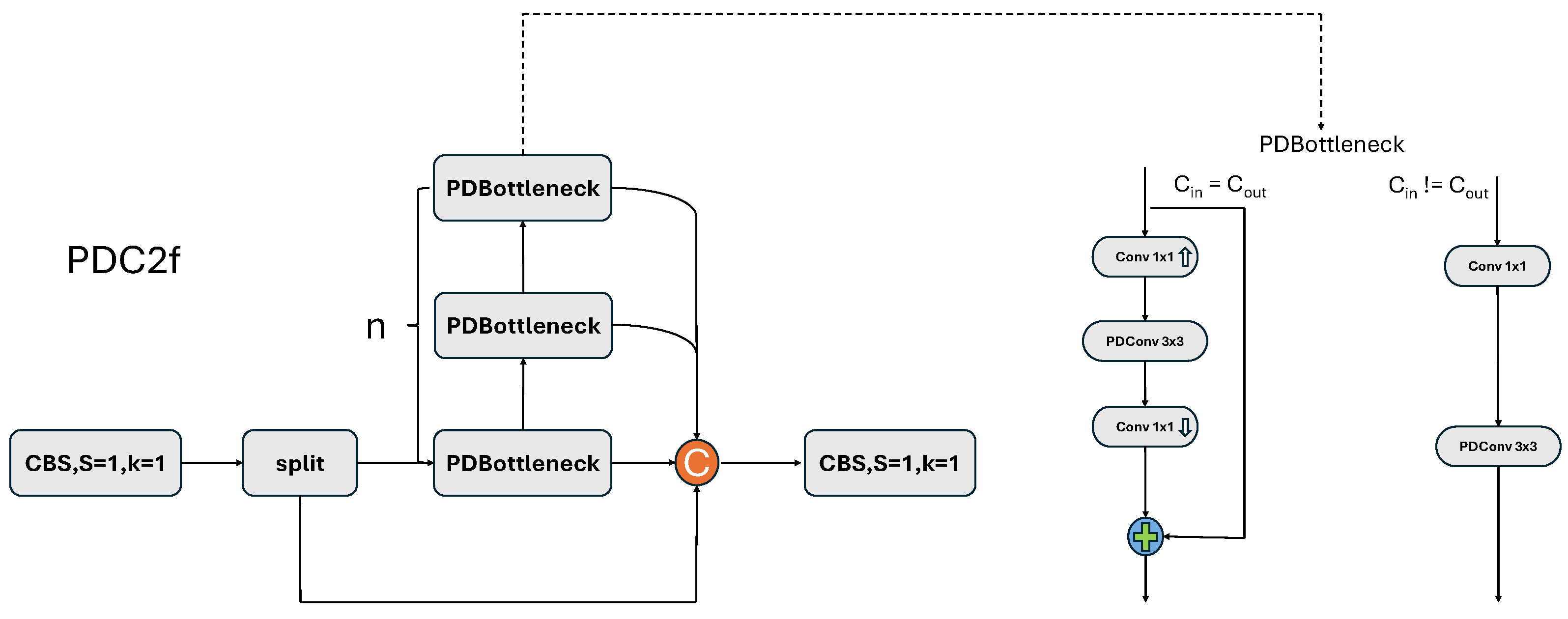
3.3. Building PDC2f
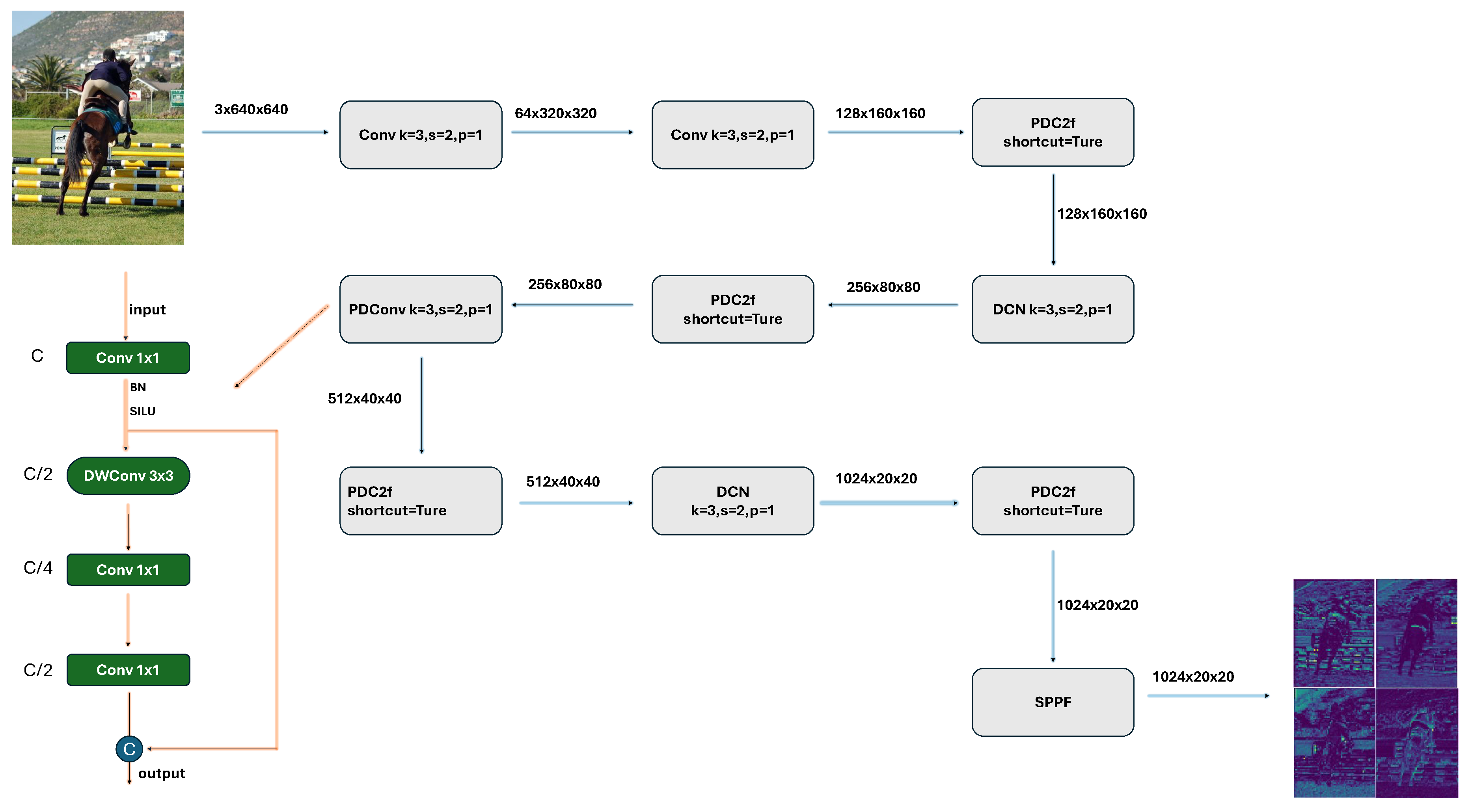
3.4. Building Efficient Net
4. Experiments
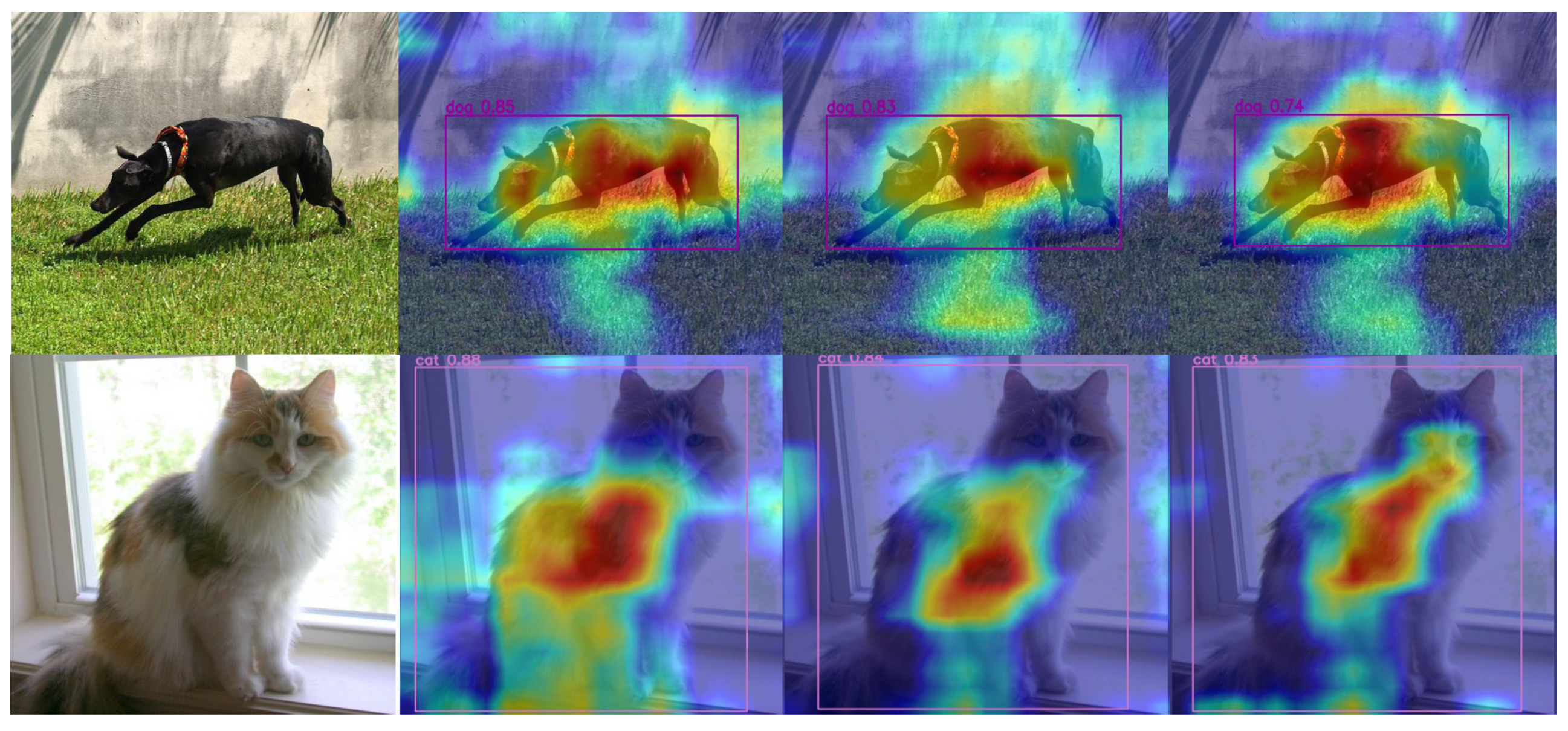
4.1. Experiment on PASCAL VOC
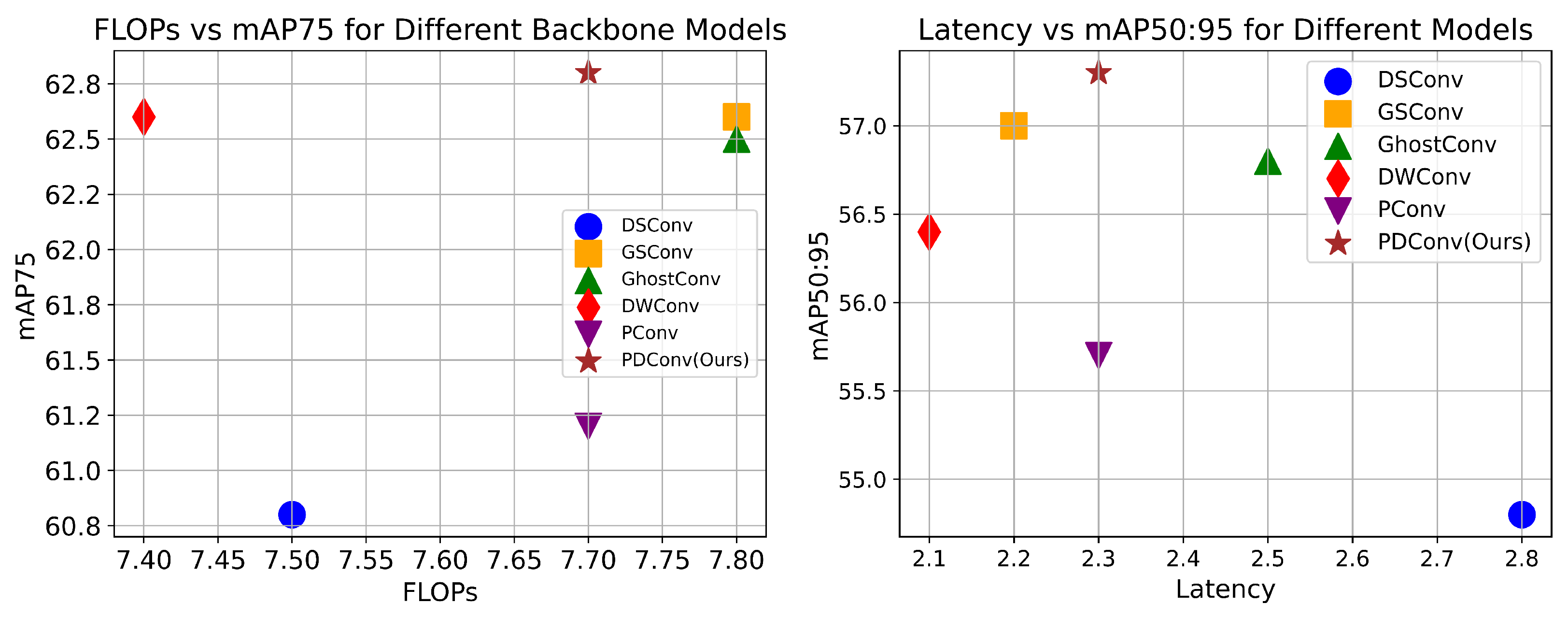
4.2. PDConv Is Low FLOPs
4.3. Experiment on CoCo2017
4.4. Ablation Experiment
5. Limition and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features From Cheap Operations. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 1577–1586. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, H.; Xu, B.; Yan, Z.; Kalantidis, Y.; Rohrbach, M.; Shuicheng, Y.; Feng, J. Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks With Octave Convolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3434–3443. [Google Scholar] [CrossRef]
- He, T.; Tan, J.; Zhuo, W.; Printz, M.; Chan, S.H.G. Tackling Multipath and Biased Training Data for IMU-Assisted BLE Proximity Detection. In Proceedings of the IEEE INFOCOM 2022—IEEE Conference on Computer Communications, Virtual, 2–5 May 2022; pp. 1259–1268. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Yuan, L.; Liu, Z.; Zhang, L.; Vasconcelos, N. MicroNet: Improving Image Recognition with Extremely Low FLOPs. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 458–467. [Google Scholar]
- Sifre, L.; Mallat, S. Rigid-Motion Scattering for Texture Classification. arXiv 2014, arXiv:1403.1687. [Google Scholar]
- Singh, P.; Verma, V.K.; Rai, P.; Namboodiri, V.P. HetConv: Heterogeneous Kernel-Based Convolutions for Deep CNNs. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 4830–4839. [Google Scholar]
- Zhang, T.; Qi, G.J.; Xiao, B.; Wang, J. Interleaved Group Convolutions for Deep Neural Networks. arXiv 2017, arXiv:1707.02725. [Google Scholar]
- Zhuo, W.; Chiu, K.; Chen, J.; Tan, J.; Sumpena, E.; Chan, S.H.G.; Ha, S.; Lee, C.H. Semi-supervised Learning with Network Embedding on Ambient RF Signals for Geofencing Services. In Proceedings of the 2023 IEEE 39th International Conference on Data Engineering (ICDE), Anaheim, CA, USA, 3–7 April 2023; pp. 2713–2726. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021. [Google Scholar]
- Han, K.; Wang, Y.; Zhang, Q.; Zhang, W.; Xu, C.; Zhang, T. Model Rubik’s Cube: Twisting Resolution, Depth and Width for TinyNets. arXiv 2020, arXiv:2010.14819. [Google Scholar]
- Huang, G.; Liu, S.; Maaten, L.v.d.; Weinberger, K.Q. CondenseNet: An Efficient DenseNet Using Learned Group Convolutions. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2752–2761. [Google Scholar] [CrossRef]
- Yang, L.; Jiang, H.; Cai, R.; Wang, Y.; Song, S.; Huang, G.; Tian, Q. CondenseNet V2: Sparse Feature Reactivation for Deep Networks. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 3568–3577. [Google Scholar] [CrossRef]
- Chen, J.; He, T.; Zhuo, W.; Ma, L.; Ha, S.; Chan, S.G. TVConv: Efficient Translation Variant Convolution for Layout-aware Visual Processing. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 12538–12548. [Google Scholar] [CrossRef]
- Tan, M.; Chen, B.; Pang, R.; Vasudevan, V.; Sandler, M.; Howard, A.; Le, Q.V. MnasNet: Platform-Aware Neural Architecture Search for Mobile. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 2815–2823. [Google Scholar] [CrossRef]
- Wu, B.; Dai, X.; Zhang, P.; Wang, Y.; Sun, F.; Wu, Y.; Tian, Y.; Vajda, P.; Jia, Y.; Keutzer, K. FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 10726–10734. [Google Scholar] [CrossRef]
- Wan, A.; Dai, X.; Zhang, P.; He, Z.; Tian, Y.; Xie, S.; Wu, B.; Yu, M.; Xu, T.; Chen, K.; et al. FBNetV2: Differentiable Neural Architecture Search for Spatial and Channel Dimensions. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 12962–12971. [Google Scholar] [CrossRef]
- Dai, X.; Wan, A.; Zhang, P.; Wu, B.; He, Z.; Wei, Z.; Chen, K.; Tian, Y.; Yu, M.; Vajda, P.; et al. FBNetV3: Joint Architecture-Recipe Search using Neural Acquisition Function. arXiv 2020, arXiv:2006.02049. [Google Scholar]
- Wu, B.; Li, C.; Zhang, H.; Dai, X.; Zhang, P.; Yu, M.; Wang, J.; Lin, Y.; Vajda, P. FBNetV5: Neural Architecture Search for Multiple Tasks in One Run. arXiv 2021, arXiv:2111.10007. [Google Scholar]
- Steiner, A.; Kolesnikov, A.; Zhai, X.; Wightman, R.; Uszkoreit, J.; Beyer, L. How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers. arXiv 2021, arXiv:2106.10270. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; J’egou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- Graham, B.; El-Nouby, A.; Touvron, H.; Stock, P.; Joulin, A.; Jégou, H.; Douze, M. LeViT: A Vision Transformer in ConvNet’s Clothing for Faster Inference. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 12239–12249. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin Transformer V2: Scaling Up Capacity and Resolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 11999–12009. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021; pp. 9992–10002. [Google Scholar] [CrossRef]
- El-Nouby, A.; Touvron, H.; Caron, M.; Bojanowski, P.; Douze, M.; Joulin, A.; Laptev, I.; Neverova, N.; Synnaeve, G.; Verbeek, J.; et al. XCiT: Cross-Covariance Image Transformers. In Proceedings of the Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Huang, T.; Huang, L.; You, S.; Wang, F.; Qian, C.; Xu, C. LightViT: Towards Light-Weight Convolution-Free Vision Transformers. arXiv 2022, arXiv:2207.05557. [Google Scholar]
- Lu, J.; Yao, J.; Zhang, J.; Zhu, X.; Xu, H.; Gao, W.; Xu, C.; Xiang, T.; Zhang, L. SOFT: Softmax-free Transformer with Linear Complexity. In Proceedings of the Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Chen, S.; Xie, E.; Ge, C.; Liang, D.; Luo, P. CycleMLP: A MLP-like Architecture for Dense Prediction. arXiv 2021, arXiv:2107.10224. [Google Scholar] [CrossRef] [PubMed]
- Lian, D.; Yu, Z.; Sun, X.; Gao, S. AS-MLP: An Axial Shifted MLP Architecture for Vision. arXiv 2021, arXiv:2107.08391. [Google Scholar]
- Tolstikhin, I.O.; Houlsby, N.; Kolesnikov, A.; Beyer, L.; Zhai, X.; Unterthiner, T.; Yung, J.; Keysers, D.; Uszkoreit, J.; Lucic, M.; et al. MLP-Mixer: An all-MLP Architecture for Vision. In Proceedings of the Neural Information Processing Systems, Online, 6–14 December 2021. [Google Scholar]
- Li, H.; Li, J.; Wei, H.; Liu, Z.; Zhan, Z.; Ren, Q. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. arXiv 2022, arXiv:2206.02424. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Yeh, I.H.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W. CSPNet: A New Backbone that can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Everingham, M.; Gool, L.V.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE: Content-Aware ReAssembly of FEatures. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3007–3016. [Google Scholar] [CrossRef]
- Li, C.; Zhou, A.; Yao, A. Omni-Dimensional Dynamic Convolution. arXiv 2022, arXiv:2209.07947. [Google Scholar]
- Li, D.; Hu, J.; Wang, C.; Li, X.; She, Q.; Zhu, L.; Zhang, T.; Chen, Q. Involution: Inverting the Inherence of Convolution for Visual Recognition. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 12316–12325. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar]
- Rao, Y.; Zhao, W.; Tang, Y.; Zhou, J.; Lim, S.N.; Lu, J. HorNet: Efficient High-Order Spatial Interactions with Recursive Gated Convolutions. arXiv 2022, arXiv:2207.14284. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, J.; Tao, D. VanillaNet: The Power of Minimalism in Deep Learning. arXiv 2023, arXiv:2305.12972. [Google Scholar]
- Wang, A.; Chen, H.; Lin, Z.; Pu, H.; Ding, G. RepViT: Revisiting Mobile CNN From ViT Perspective. arXiv 2023, arXiv:2307.09283. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Yu, W.; Luo, M.; Zhou, P.; Si, C.; Zhou, Y.; Wang, X.; Feng, J.; Yan, S. MetaFormer is Actually What You Need for Vision. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 10809–10819. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 548–558. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Backbone | FLOPs | mAP50 | mAP75 | mAP50:95 | P | R | F1 |
|---|---|---|---|---|---|---|---|---|
| baseline | CSPDarkNet | 8.1 | 76.1 | 62.5 | 56.9 | 0.782 | 0.683 | 68.5 |
| DWConv | CSPDarkNet | 7.9 | 75.3 | 62.2 | 56.0 | 0.787 | 0.668 | 68.7 |
| GSConv | CSPDarkNet | 7.7 | 75.7 | 62.1 | 56.7 | 0.793 | 0.672 | 68.9 |
| CARAFE [39] | CSPDarkNet | 12.8 | 75.4 | 61.0 | 55.1 | 0.783 | 0.67 | 67.7 |
| ODConv [40] | CSPDarkNet | 8.1 | 76.2 | 62.6 | 57.1 | 0.792 | 0.678 | 69.4 |
| Involution [41] | CSPDarkNet | 21.3 | 75.5 | 60.1 | 55.7 | 0.790 | 0.672 | 67.3 |
| CBAM [42] | CSPDarkNet | 8.1 | 76.2 | 62.6 | 57.0 | 0.787 | 0.683 | 69.4 |
| SwinT [29] | CSPDarkNet | 9.0 | 75.6 | 62.1 | 56.4 | 0.785 | 0.671 | 68.8 |
| PDConv (ours) | CSPDarkNet | 7.7 | 76.0 | 62.8 | 57.3 | 0.790 | 0.689 | 69.4 |
| GhostNet | GhostNet | 7.7 | 75.6 | 62.2 | 56.7 | 0.795 | 0.677 | 69.9 |
| HorNet [43] | HorNet | 8.8 | 75.6 | 61.5 | 56.0 | 0.805 | 0.657 | 67.9 |
| VanilaNet [44] | VanilaNet | 5.0 | 62.4 | 46.7 | 41.6 | 0.699 | 0.547 | 53.4 |
| RepVit [45] | RepVit | 8.1 | 77.3 | 63.5 | 57.5 | 0.789 | 0.702 | 69.9 |
| PDNet (ours) | PDNet | 7.0 | 77.2 | 63.8 | 57.8 | 0.792 | 0.691 | 70.4 |
| Operator | Feature Map | Params | Memory (M) | FLOPs (M) |
|---|---|---|---|---|
| PDConv 3 × 3 | 16 × 320 × 320 | 198 | 75 | 90 |
| 32 × 160 × 160 | 712 | 37.5 | 79 | |
| 64 × 80 × 80 | 2448 | 18.7 | 65 | |
| 128 × 40 × 40 | 8992 | 9.3 | 59 | |
| 256 × 20 × 20 | 34,368 | 4.7 | 56 | |
| Total | 46,718 | 145.2 | 349 | |
| StandrdConv 3 × 3 | 16 × 320 × 320 | 464 | 82.8 | 204 |
| 32 × 160 × 160 | 4672 | 40.6 | 485 | |
| 64 × 80 × 80 | 18,560 | 20.3 | 478 | |
| 128 × 40 × 40 | 73,984 | 10.1 | 475 | |
| 256 × 20 × 20 | 295,424 | 5.1 | 473 | |
| Total | 393,104 | 158.9 | 2115 | |
| DWConv 3 × 3 | 16 × 320 × 320 | 94 | 60.9 | 52 |
| 32 × 160 × 160 | 704 | 34.4 | 79 | |
| 64 × 80 × 80 | 2432 | 17.2 | 66 | |
| 128 × 40 × 40 | 8960 | 8.6 | 59 | |
| 256 × 20 × 20 | 34,304 | 4.3 | 56 | |
| Total | 46,494 | 125.4 | 312 | |
| GConv 3 × 3 (g = 16) | 16 × 320 × 320 | 464 | 82.9 | 203 |
| 32 × 160 × 160 | 352 | 40.1 | 43 | |
| 64 × 80 × 80 | 1280 | 20.3 | 36 | |
| 128 × 40 × 40 | 4864 | 6.9 | 33 | |
| 256 × 20 × 20 | 18,944 | 5.1 | 31 | |
| Total | 25,904 | 155.3 | 346 |
| Backbone | mAP50 | mAP75 | FLOPs |
|---|---|---|---|
| Two Stage | |||
| ResNet50 | 55.1 | 36.7 | 253 |
| PoolFormer-S24 [48] | 59.1 | 39.6 | 233 |
| PVT-Small [49] | 60.1 | 40.3 | 238 |
| FasterNet-S | 58.1 | 39.7 | 258 |
| FasterNet-PDConv(ours) | 58.0 | 39.4 | 243 |
| ResNet101 | 57.7 | 38.8 | 329 |
| ResNeXt101-32x4d | 59.4 | 40.2 | 333 |
| PoolFormer-S36 | 60.1 | 40.0 | 266 |
| PVT-Medium | 61.6 | 42.1 | 295 |
| FasterNet-M | 61.5 | 42.3 | 344 |
| FasterNet-PDConv(ours) | 61.8 | 42.4 | 325 |
| ResNeXt101-64x4d | 60.6 | 41.3 | 487 |
| PVT-Large | 61.9 | 42.5 | 358 |
| FasterNet-L | 62.3 | 43.0 | 484 |
| FasterNet-PDConv(ours) | 62.0 | 43.1 | 450 |
| One Stage | |||
| YOLOv8-S | 47.2 | 35.8 | 28.7 |
| RepVit-S | 47.5 | 36.6 | 29 |
| PDNet-S(ours) | 47.6 | 36.9 | 27 |
| YOLOv8-M | 53.2 | 42.1 | 79.1 |
| EfficientNetV2 | 41.8 | 31.2 | 23.1 |
| RepVit-M | 54.2 | 42.7 | 79 |
| PDNet-M(ours) | 53.5 | 42.4 | 76 |
| YOLOv8-L | 56.4 | 45.2 | 166 |
| RepVit-L | 57.1 | 45.8 | 166 |
| HorNet | 54.7 | 43.7 | 188 |
| PDNet-L(ours) | 57.5 | 46.3 | 160 |
| Methods | FLOPs | Param | Latency | mAP75 | mAP50:95 |
|---|---|---|---|---|---|
| DSConv | 7.5 | 2.7 | 2.8 ms | 60.8 | 54.8 |
| GSConv | 7.8 | 2.8 | 2.2 ms | 62.6 | 57.0 |
| Ghost Conv | 7.8 | 2.8 | 2.5 ms | 62.5 | 56.8 |
| DWConv | 7.4 | 2.6 | 2.1 ms | 62.6 | 56.4 |
| PConv | 7.8 | 2.7 | 2.3 ms | 61.2 | 55.7 |
| PDConv(Ours) | 7.7 | 2.8 | 2.3 ms | 62.8 | 57.3 |
| Methods | mAP50 | mAP75 | mAP50:95 | Param | FLOPs |
|---|---|---|---|---|---|
| PDConv 1× | 72.7 | 58.3 | 53.1 | 2.93 M | 7.9 G |
| PDConv 2× | 73.0 | 59.1 | 53.3 | 2.90 M | 7.8 G |
| PDConv 3× | 72.4 | 59.0 | 53.0 | 2.77 M | 7.7 G |
| Methods | mAP50 | mAP75 | mAP50:95 |
|---|---|---|---|
| Baseline | 72.3 | 58.8 | 52.9 |
| Baseline+PDConv | 72.7 | 58.3 | 53.1 |
| Baseline+PDConv+PDC2f | 72.7 | 59.0 | 52.9 |
| Baseline+PDConv+PDC2f+DCN | 73.8 | 59.2 | 53.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, W.; Meng, Y.; Li, H.; Li, S.; Zhang, C.; Zhang, G.; Lei, W. PDNet by Partial Deep Convolution: A Better Lightweight Detector. Electronics 2025, 14, 591. https://doi.org/10.3390/electronics14030591
Wang W, Meng Y, Li H, Li S, Zhang C, Zhang G, Lei W. PDNet by Partial Deep Convolution: A Better Lightweight Detector. Electronics. 2025; 14(3):591. https://doi.org/10.3390/electronics14030591
Chicago/Turabian StyleWang, Wei, Yuanze Meng, Han Li, Shun Li, Chenghong Zhang, Guanghui Zhang, and Weimin Lei. 2025. "PDNet by Partial Deep Convolution: A Better Lightweight Detector" Electronics 14, no. 3: 591. https://doi.org/10.3390/electronics14030591
APA StyleWang, W., Meng, Y., Li, H., Li, S., Zhang, C., Zhang, G., & Lei, W. (2025). PDNet by Partial Deep Convolution: A Better Lightweight Detector. Electronics, 14(3), 591. https://doi.org/10.3390/electronics14030591