
Feature Fusion Network with Local Information Exchange for Underwater Object Detection


Abstract
1. Introduction
- We propose the Feature Fusion Network with Local Information Exchange, named FFNLIE, which improves object detection efficiency by fusing raw image features with enhanced image features.
- We propose a local information exchange module that enhances the information exchange capability within the local region of Swin Transformer.
- We introduce a feature fusion module designed to extract both the discrepancy and common information between raw and enhanced underwater images, enabling effective feature integration.
- Comprehensive experiments validate the efficacy of the proposed method.
2. Related Work
2.1. Underwater Object Detection
2.2. Swin Transformer
2.3. Feature Fusion
3. The Proposed Method
3.1. Overview
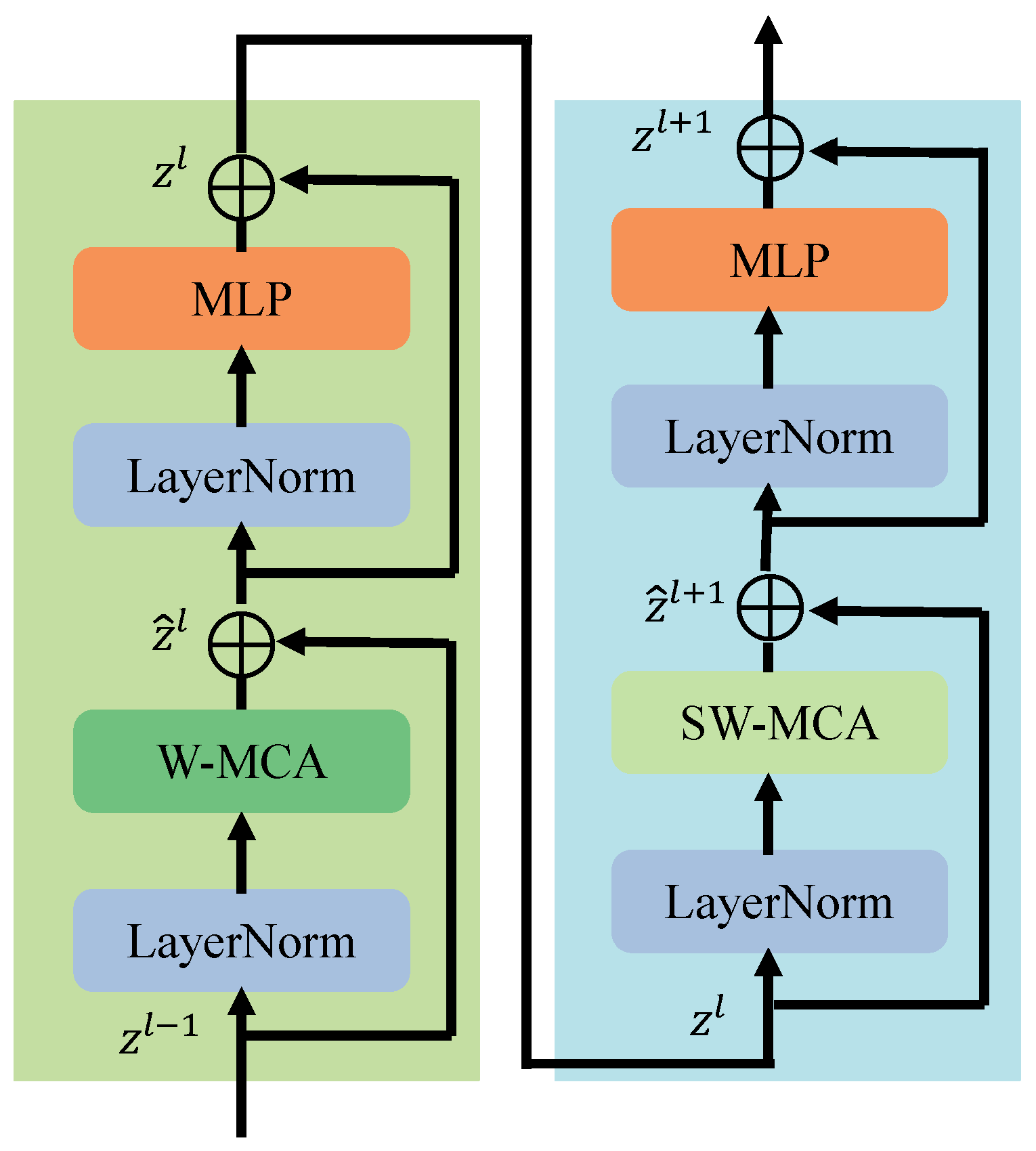
3.2. Swin Transformer
3.3. Local Information Exchange
3.4. Feature Fusion
4. Experiments
4.1. Implementation Details, Evaluation Metrics and Datasets
4.2. Quantitative Results
4.3. Ablation Studies
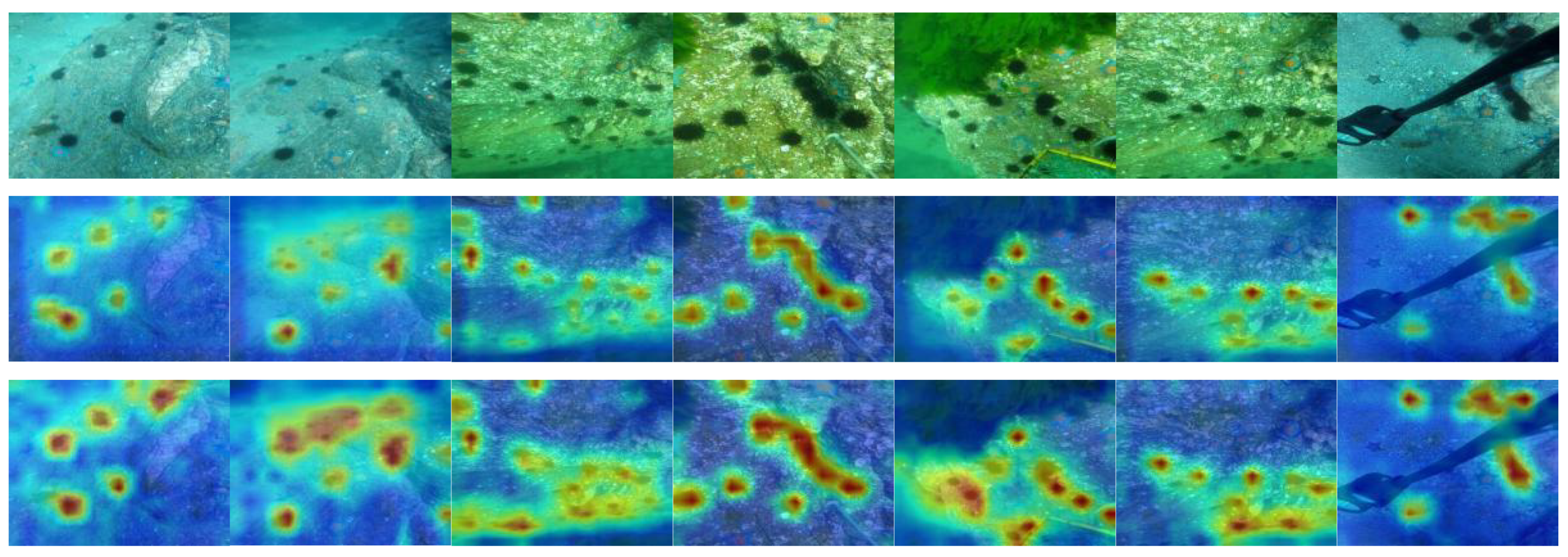
4.4. Qualitative Results
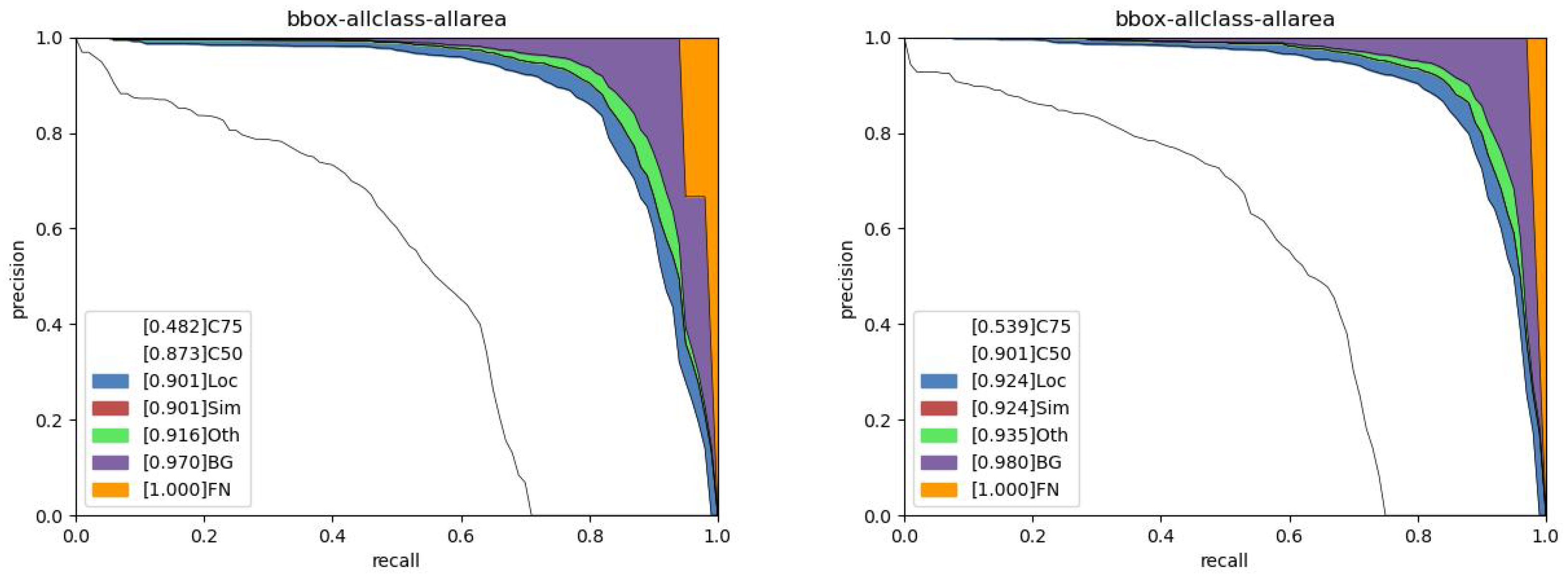
4.5. Error Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krishna, S.; Lemmen, C.; Örey, S.; Rehren, J.; Pane, J.D.; Mathis, M.; Püts, M.; Hokamp, S.; Pradhan, H.K.; Hasenbein, M.; et al. Interactive effects of multiple stressors in coastal ecosystems. Front. Mar. Sci. 2025, 11, 1481734. [Google Scholar] [CrossRef]
- Wu, D.; Luo, L. SVGS-DSGAT: An IoT-enabled innovation in underwater robotic object detection technology. Alex. Eng. J. 2024, 108, 694–705. [Google Scholar] [CrossRef]
- Hasan, M.J.; Kannan, S.; Rohan, A.; Shah, M.A. Exploring the Feasibility of Affordable Sonar Technology: Object Detection in Underwater Environments Using the Ping 360. arXiv 2024, arXiv:2411.05863. [Google Scholar]
- Zhou, J.; He, Z.; Lam, K.M.; Wang, Y.; Zhang, W.; Guo, C.; Li, C. AMSP-UOD: When vortex convolution and stochastic perturbation meet underwater object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 20–27 February 2024; Volume 38, pp. 7659–7667. [Google Scholar]
- Fu, C.; Fan, X.; Xiao, J.; Yuan, W.; Liu, R.; Luo, Z. Learning heavily-degraded prior for underwater object detection. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 6887–6896. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, Y.; Fang, L.; Kang, Y.; Li, S.; Zhu, X.X. DREB-Net: Dual-stream Restoration Embedding Blur-feature Fusion Network for High-mobility UAV Object Detection. arXiv 2024, arXiv:2410.17822. [Google Scholar]
- Wu, J.; Jin, Z. Unsupervised Variational Translator for Bridging Image Restoration and High-Level Vision Tasks. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2024; Springer: Berlin/Heidelberg, Germany, 2024; pp. 214–231. [Google Scholar]
- Zhang, Y.; Wu, Y.; Liu, Y.; Peng, X. CPA-Enhancer: Chain-of-Thought Prompted Adaptive Enhancer for Object Detection under Unknown Degradations. arXiv 2024, arXiv:2403.11220. [Google Scholar]
- Fan, Y.; Wang, Y.; Wei, M.; Wang, F.L.; Xie, H. FriendNet: Detection-Friendly Dehazing Network. arXiv 2024, arXiv:2403.04443. [Google Scholar]
- Wang, B.; Wang, Z.; Guo, W.; Wang, Y. A dual-branch joint learning network for underwater object detection. Knowl.-Based Syst. 2024, 293, 111672. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Pan, L.; Chen, G.; Liu, W.; Xu, L.; Liu, X.; Peng, S. LDCSF: Local depth convolution-based Swim framework for classifying multi-label histopathology images. In Proceedings of the 2023 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Istanbul, Turkey, 5–8 December 2023; pp. 1368–1373. [Google Scholar]
- Zhu, B.; Wang, J.; Jiang, Z.; Zong, F.; Liu, S.; Li, Z.; Sun, J. Autoassign: Differentiable label assignment for dense object detection. arXiv 2020. arXiv 2007, arXiv:2007.03496. [Google Scholar]
- Li, C.; Zhou, H.; Liu, Y.; Yang, C.; Xie, Y.; Li, Z.; Zhu, L. Detection-friendly dehazing: Object detection in real-world hazy scenes. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 8284–8295. [Google Scholar] [CrossRef]
- Gao, Z.; Hong, B.; Zhang, X.; Li, Y.; Jia, C.; Wu, J.; Wang, C.; Meng, D.; Li, C. Instance-based vision transformer for subtyping of papillary renal cell carcinoma in histopathological image. In Proceedings of the Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, 27 September–1 October 2021; Proceedings, Part VIII 24. Springer: Berlin/Heidelberg, Germany, 2021; pp. 299–308. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Dai, L.; Liu, H.; Song, P.; Liu, M. A gated cross-domain collaborative network for underwater object detection. Pattern Recognit. 2024, 149, 110222. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, T.; Li, C.; Zhou, X. A Novel Driver Distraction Behavior Detection Method Based on Self-Supervised Learning with Masked Image Modeling. IEEE Internet Things J. 2023, 11, 6056–6071. [Google Scholar] [CrossRef]
- Jian, L.; Xiong, S.; Yan, H.; Niu, X.; Wu, S.; Zhang, D. Rethinking Cross-Attention for Infrared and Visible Image Fusion. arXiv 2024, arXiv:2401.11675. [Google Scholar]
- Tang, M.; Cai, S.; Lau, V.K. Radix-partition-based over-the-air aggregation and low-complexity state estimation for IoT systems over wireless fading channels. IEEE Trans. Signal Process. 2022, 70, 1464–1477. [Google Scholar] [CrossRef]
- Zhu, J.; Shi, Y.; Zhou, Y.; Jiang, C.; Chen, W.; Letaief, K.B. Over-the-Air Federated Learning and Optimization. IEEE Internet Things J. 2024, 11, 16996–17020. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Xu, M.; Zhang, H.; Xiao, G. STDFusionNet: An infrared and visible image fusion network based on salient target detection. IEEE Trans. Instrum. Meas. 2021, 70, 1–13. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Li, Q.; Lu, L.; Li, Z.; Wu, W.; Liu, Z.; Jeon, G.; Yang, X. Coupled GAN with relativistic discriminators for infrared and visible images fusion. IEEE Sens. J. 2019, 21, 7458–7467. [Google Scholar] [CrossRef]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J.; et al. MMDetection: Open mmlab detection toolbox and benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Jiang, L.; Wang, Y.; Jia, Q.; Xu, S.; Liu, Y.; Fan, X.; Li, H.; Liu, R.; Xue, X.; Wang, R. Underwater species detection using channel sharpening attention. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 4259–4267. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Fu, C.; Liu, R.; Fan, X.; Chen, P.; Fu, H.; Yuan, W.; Zhu, M.; Luo, Z. Rethinking general underwater object detection: Datasets, challenges, and solutions. Neurocomputing 2023, 517, 243–256. [Google Scholar] [CrossRef]
- Liu, C.; Wang, Z.; Wang, S.; Tang, T.; Tao, Y.; Yang, C.; Li, H.; Liu, X.; Fan, X. A new dataset, Poisson GAN and AquaNet for underwater object grabbing. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 2831–2844. [Google Scholar] [CrossRef]
- Islam, M.J.; Xia, Y.; Sattar, J. Fast underwater image enhancement for improved visual perception. IEEE Robot. Autom. Lett. 2020, 5, 3227–3234. [Google Scholar] [CrossRef]
- Song, H.; Chang, L.; Chen, Z.; Ren, P. Enhancement-registration-homogenization (ERH): A comprehensive underwater visual reconstruction paradigm. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 6953–6967. [Google Scholar] [CrossRef] [PubMed]
- Lu, X.; Li, B.; Yue, Y.; Li, Q.; Yan, J. Grid r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7363–7372. [Google Scholar]
- Kong, T.; Sun, F.; Liu, H.; Jiang, Y.; Li, L.; Shi, J. Foveabox: Beyound anchor-based object detection. IEEE Trans. Image Process. 2020, 29, 7389–7398. [Google Scholar] [CrossRef]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 568–578. [Google Scholar]
- Wang, W.; Xie, E.; Li, X.; Fan, D.P.; Song, K.; Liang, D.; Lu, T.; Luo, P.; Shao, L. Pvt v2: Improved baselines with pyramid vision transformer. Comput. Vis. Media 2022, 8, 415–424. [Google Scholar] [CrossRef]
- Qiao, S.; Chen, L.C.; Yuille, A. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 10213–10224. [Google Scholar]
- Dai, L.; Liu, H.; Song, P.; Tang, H.; Ding, R.; Li, S. Edge-guided representation learning for underwater object detection. CAAI Trans. Intell. Technol. 2024. [CrossRef]
- Cao, J.; Cholakkal, H.; Anwer, R.M.; Khan, F.S.; Pang, Y.; Shao, L. D2det: Towards high quality object detection and instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11485–11494. [Google Scholar]
- Wang, J.; Zhang, W.; Cao, Y.; Chen, K.; Pang, J.; Gong, T.; Shi, J.; Loy, C.C.; Lin, D. Side-aware boundary localization for more precise object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part IV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 403–419. [Google Scholar]
- Zhu, C.; He, Y.; Savvides, M. Feature selective anchor-free module for single-shot object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 840–849. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Wang, N.; Gao, Y.; Chen, H.; Wang, P.; Tian, Z.; Shen, C.; Zhang, Y. NAS-FCOS: Fast neural architecture search for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11943–11951. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, W.H.; Zhong, J.X.; Liu, S.; Li, T.; Li, G. Roimix: Proposal-fusion among multiple images for underwater object detection. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2588–2592. [Google Scholar]
- Song, P.; Li, P.; Dai, L.; Wang, T.; Chen, Z. Boosting R-CNN: Reweighting R-CNN samples by RPN’s error for underwater object detection. Neurocomputing 2023, 530, 150–164. [Google Scholar] [CrossRef]
- Liang, X.; Song, P. Excavating roi attention for underwater object detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 2651–2655. [Google Scholar]
- Peng, Y.T.; Cao, K.; Cosman, P.C. Generalization of the dark channel prior for single image restoration. IEEE Trans. Image Process. 2018, 27, 2856–2868. [Google Scholar] [CrossRef]
- Jiang, J.; Ye, T.; Bai, J.; Chen, S.; Chai, W.; Jun, S.; Liu, Y.; Chen, E. Five A + Network: You Only Need 9K Parameters for Underwater Image Enhancement. arXiv 2023, arXiv:2305.08824. [Google Scholar]
- Wen, J.; Cui, J.; Zhao, Z.; Yan, R.; Gao, Z.; Dou, L.; Chen, B.M. Syreanet: A physically guided underwater image enhancement framework integrating synthetic and real images. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 5177–5183. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]





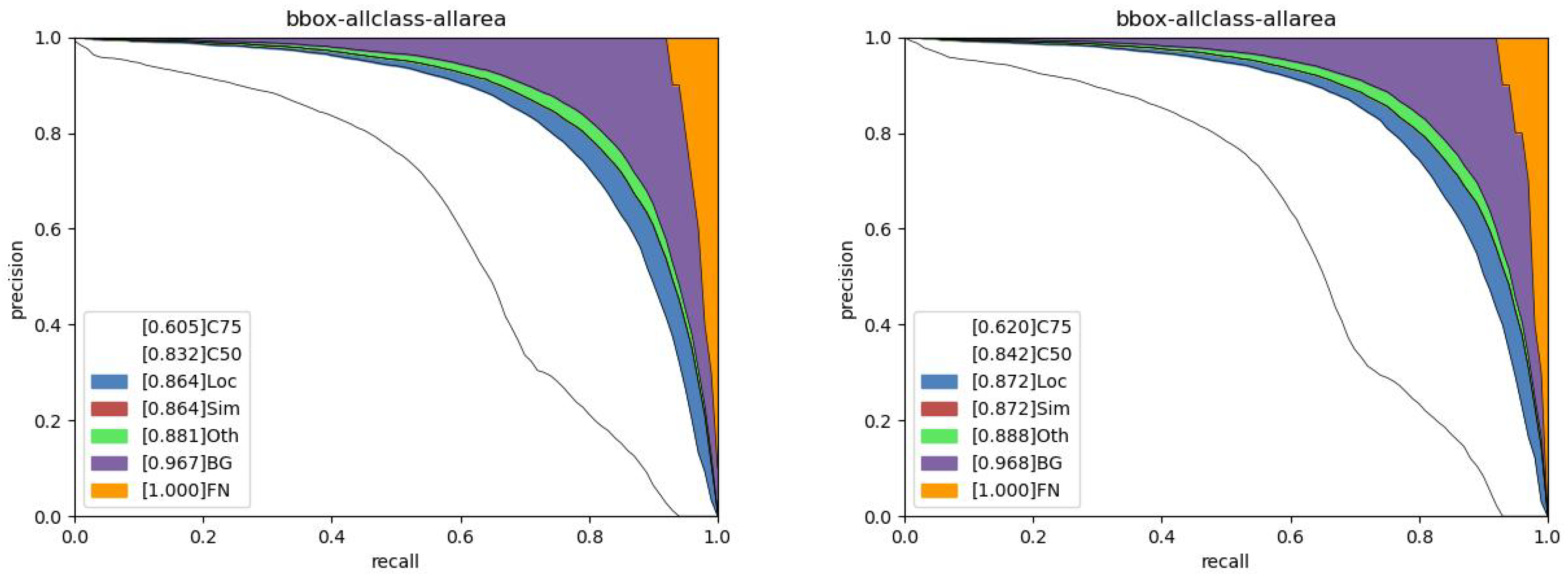

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Backbone | ||||||
|---|---|---|---|---|---|---|---|
| UIE+UOD: | |||||||
| FunIE+Grid RCNN | ResNetXT101 | 36.2 | 73.1 | 31.7 | 18.4 | 35.5 | 55.6 |
| FunIE+CSAM | DarkNet-53 | 45.3 | 80.4 | 47.8 | 32.2 | 45.6 | 54.3 |
| FunIE+Swin | Swin-B | 48.3 | 85.1 | 49.7 | 32.2 | 45.2 | 58.2 |
| ERH+Swin | Swin-B | 48.8 | 86.0 | 48.5 | 30.6 | 48.6 | 61.3 |
| CNN: | |||||||
| FoveaBox | ResNet101 | 45.6 | 85.1 | 43.5 | 32.4 | 45.5 | 57.2 |
| CSAM | DarkNet-53 | 49.1 | 88.4 | 48.3 | 34.0 | 49.9 | 61.2 |
| AquaNet | MNet | 45.2 | 84.3 | 44.0 | 30.5 | 44.2 | 55.2 |
| RFTM | ResNet50 | 50.8 | 89.0 | 53.6 | 33.6 | 50.9 | 62.8 |
| Transformer: | |||||||
| PVTv1 | PVT-Medium | 45.8 | 85.4 | 43.6 | 32.0 | 45.8 | 56.9 |
| PVTv2 | PVTv2-B4 | 47.5 | 88.1 | 46.6 | 31.6 | 48.1 | 54.5 |
| GCC-Net | Swin-B | 48.9 | 88.8 | 48.1 | 35.1 | 48.8 | 58.6 |
| Ours: | |||||||
| FFNLIE | Swin-B | 51.0 | 90.1 | 53.9 | 36.9 | 50.6 | 61.4 |
| Methods | ||||||
|---|---|---|---|---|---|---|
| Two-Stage Detector: | ||||||
| DetectoRS | 46.5 | 81.7 | 49.0 | 22.6 | 41.0 | 52.5 |
| ERL | 48.3 | 83.2 | 51.3 | 25.1 | 43.0 | 54.2 |
| D2Det | 43.5 | 80.2 | 42.6 | 18.3 | 37.8 | 49.5 |
| SABL | 47.8 | 81.4 | 50.7 | 21.4 | 41.5 | 54.4 |
| Single-Stage Detector: | ||||||
| RetinaNet | 41.4 | 76.6 | 39.6 | 16.9 | 34.8 | 48.0 |
| SSD | 40.0 | 77.5 | 36.5 | 14.7 | 36.1 | 45.1 |
| FSAF | 39.7 | 75.8 | 37.9 | 16.8 | 33.6 | 46.4 |
| NAS-FCOS | 45.8 | 82.8 | 46.1 | 21.7 | 40.1 | 52.4 |
| Ours: | ||||||
| FFNLIE | 48.7 | 84.8 | 51.5 | 19.9 | 43.2 | 55.2 |
| Methods | UDD | RUOD | ||||
|---|---|---|---|---|---|---|
| RoIMix | 28.0 | 64.9 | 18.8 | 54.6 | 81.3 | 60.3 |
| Boosting | 28.4 | 64.3 | 18.8 | 53.9 | 80.6 | 59.5 |
| ERL | 29.6 | 67.4 | 20.1 | 54.8 | 83.1 | 60.9 |
| RoIAttn | 28.3 | 64.5 | 16.9 | 52.9 | 81.7 | 57.3 |
| GCC-Net | 26.3 | 64.6 | 14.1 | 56.1 | 83.2 | 60.5 |
| RFTM | 28.8 | 66.1 | 19.4 | 53.3 | 80.2 | 57.7 |
| FFNLIE | 29.7 | 70.8 | 19.2 | 56.7 | 84.2 | 62.0 |
| Domain 1 | Domain 2 | |||
|---|---|---|---|---|
| Raw | Null | 48.9 | 88.2 | 49.1 |
| Raw | Raw | 49.1 | 88.6 | 49.5 |
| Raw | Water-MSR | 51.0 | 90.1 | 53.9 |
| Domain 1 | Domain 2 | |||
|---|---|---|---|---|
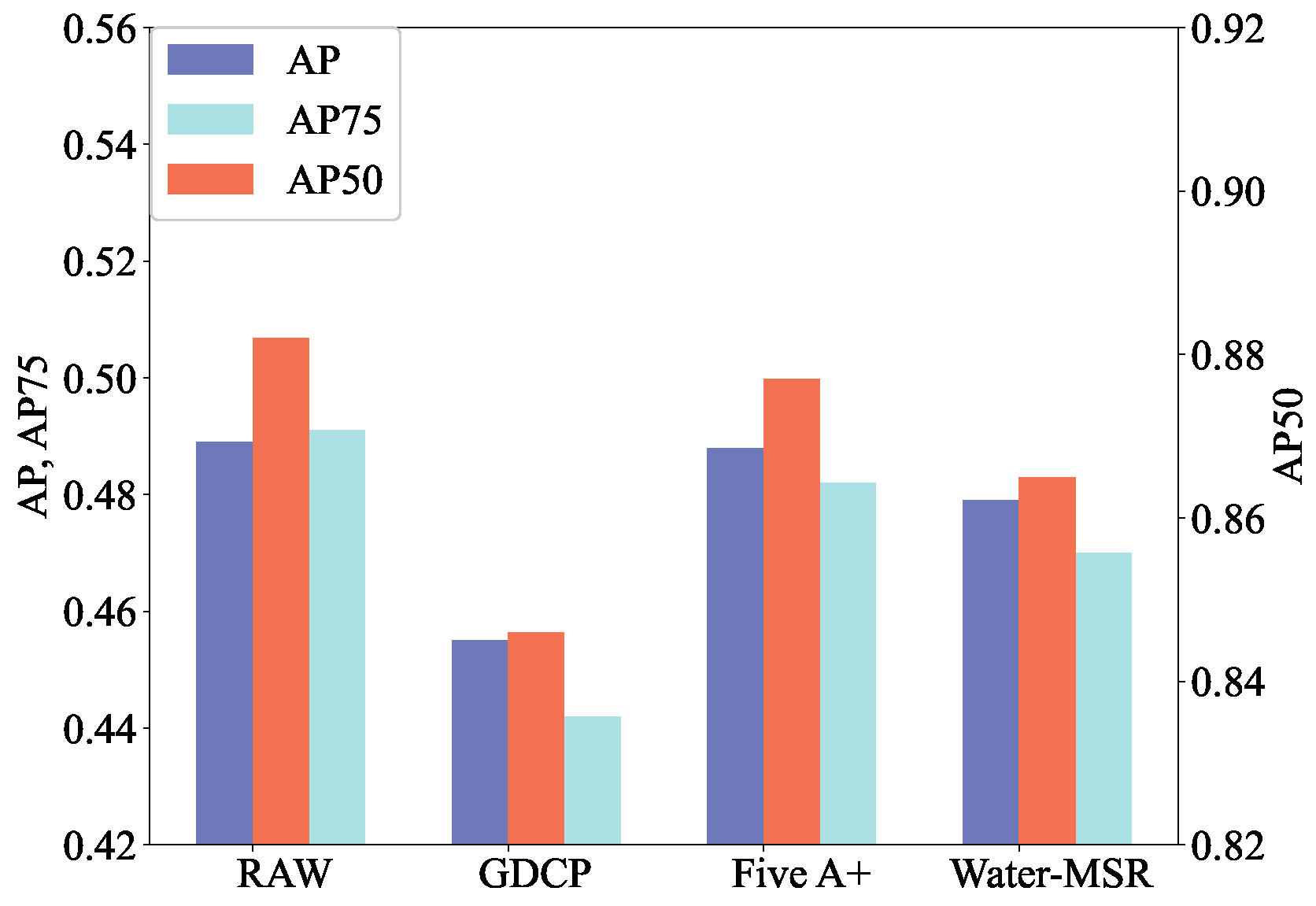
| Raw | GDCP | 49.8 | 89.0 | 50.9 |
| Raw | Five A+ | 51.1 | 90.0 | 53.1 |
| Raw | SyreaNet | 50.0 | 88.7 | 51.1 |
| Raw | Water-MSR | 51.0 | 90.1 | 53.9 |
| Base | FF | LIE | ||||
|---|---|---|---|---|---|---|
| DIAB | CIAB | |||||
| ✓ | 48.2 | 87.3 | 48.2 | |||
| ✓ | ✓ | 50.0 | 89.3 | 50.3 | ||
| ✓ | ✓ | 49.1 | 88.6 | 48.6 | ||
| ✓ | ✓ | ✓ | 50.6 | 90.0 | 51.8 | |
| ✓ | ✓ | 50.0 | 89.4 | 50.9 | ||
| ✓ | ✓ | ✓ | ✓ | 51.0 | 90.1 | 53.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Ma, P.; Chen, L. Feature Fusion Network with Local Information Exchange for Underwater Object Detection. Electronics 2025, 14, 587. https://doi.org/10.3390/electronics14030587
Liu X, Ma P, Chen L. Feature Fusion Network with Local Information Exchange for Underwater Object Detection. Electronics. 2025; 14(3):587. https://doi.org/10.3390/electronics14030587
Chicago/Turabian StyleLiu, Xiaopeng, Pengwei Ma, and Long Chen. 2025. "Feature Fusion Network with Local Information Exchange for Underwater Object Detection" Electronics 14, no. 3: 587. https://doi.org/10.3390/electronics14030587
APA StyleLiu, X., Ma, P., & Chen, L. (2025). Feature Fusion Network with Local Information Exchange for Underwater Object Detection. Electronics, 14(3), 587. https://doi.org/10.3390/electronics14030587