1. Introduction
Deep neural networks (DNNs) [
1] have demonstrated exceptional performance across a wide range of applications, including image classification [
2], speech recognition [
3], text classification [
4], and pattern recognition. These models, owing to their deep architectures and ability to capture complex data distributions, have driven significant advancements in machine learning. Their success has paved the way for breakthroughs in various fields, such as autonomous driving, healthcare diagnostics, and natural language processing. However, despite these remarkable achievements, deep neural networks remain highly vulnerable to adversarial examples [
5,
6].
Adversarial examples are carefully crafted perturbations that, when added to inputs, cause the model to misclassify them, even though the altered inputs appear normal to human observers. These examples pose serious threats to critical systems reliant on deep neural networks, such as self-driving cars, where misclassifications can lead to catastrophic consequences, and medical diagnostic tools, where errors in interpreting medical images can have life-altering implications. Consequently, the study of adversarial examples has become a key area of research aimed at understanding and mitigating the vulnerabilities of neural networks.
Adversarial examples are typically generated in two primary settings: white-box and black-box. In the white-box setting, where an attacker has access to the model’s parameters and gradients, adversarial examples are generated by optimizing a loss function designed to maximize the model’s misclassification probability. This is achieved through gradient-based methods, such as the Fast Gradient Sign Method (FGSM) [
7] or Projected Gradient Descent (PGD) [
8], which introduce small perturbations to the input sample to increase the loss. Conversely, in the black-box setting, where the attacker lacks access to the model’s internal parameters and relies only on its outputs (predictions), generating adversarial examples is considerably more challenging. Without access to the model’s gradients, the attacker cannot directly compute the optimal direction for perturbation. This limitation has led to the development of alternative methods, such as transfer-based attacks and decision boundary attacks, which exploit the decision boundaries of the model to craft adversarial examples.
In the black-box scenario, where no direct information about the model’s internal workings is available, decision boundary attacks have proven particularly effective. These approaches synthesize adversarial examples by gradually adjusting the interpolation rate between a target image and the original sample. By strategically positioning the adversarial example near the model’s decision boundary, attackers can induce misclassification. This method is especially useful when the input sample’s probability distribution under the target model is unknown, rendering traditional gradient-based approaches infeasible.
To enhance adversarial attack strategies in black-box environments, generative models—particularly Generative Adversarial Networks (GANs) [
9]—have shown significant promise. GANs, composed of a generator and a discriminator network, are widely used to create realistic data samples. In the context of adversarial attack generation, GANs can be utilized to produce adversarial examples that deceive the model while remaining visually indistinguishable from the original images to human observers. Notably, StyleGAN [
10] has demonstrated its capability to generate high-quality images by learning the latent structure of image data. StyleGAN’s fine-grained control over image generation enables the creation of adversarial examples that preserve the key features of the original image while subtly modifying its appearance, thereby fooling the model into making incorrect predictions.
In this paper, we propose a novel approach for generating untargeted adversarial examples in an unrestricted black-box environment using StyleGAN. The adversarial examples produced by the proposed method are classified as a random class different from the original sample, while appearing visually similar to the original image to human observers. The key contributions of this paper are as follows:
We introduce a method for generating untargeted adversarial examples in the black-box environment. Unlike traditional methods that require a specific target class, our approach generates adversarial examples that are classified into a random class, demonstrating the potential for broader applicability in real-world attack scenarios.
We provide a detailed analysis of the proposed method, evaluating its performance in terms of attack success rate, image distortion, and visual quality. We show how the method balances between adversarial effectiveness and perceptual similarity.
To demonstrate the efficacy of the proposed approach, we evaluate the method using the ResNet18 model [
11] as the target classifier and the CelebA-HQ dataset [
12] for image data. The experimental results showcase the method’s robustness in generating high-quality adversarial examples.
The remainder of this paper is organized as follows:
Section 2 describes the related work.
Section 3 describes the proposed method in detail. In
Section 4, we present the experimental setup and results of the proposed approach.
Section 5 provides a discussion on the effectiveness and limitations of the method. Finally,
Section 6 concludes the paper and discusses potential avenues for future research in adversarial attack generation.
2. Related Work
The study of adversarial examples has garnered significant attention in recent years, driven by the increasing deployment of deep neural networks (DNNs) in safety-critical applications. This section reviews key developments in adversarial attacks, defenses, and the use of generative models for adversarial example generation, with a focus on both white-box and black-box settings.
2.1. Adversarial Attack Techniques
Adversarial attack methods [
13,
14] can broadly be classified into white-box and black-box approaches based on the attacker’s knowledge of the target model. In the white-box setting, where the attacker has full access to the model’s architecture and parameters, gradient-based methods such as the Fast Gradient Sign Method (FGSM) [
7] and Projected Gradient Descent (PGD) [
8] have been extensively studied. These methods craft adversarial perturbations by leveraging the gradient of the model’s loss function with respect to the input data, ensuring a high probability of misclassification while keeping the perturbations imperceptible to human observers.
In contrast, black-box attacks operate under more restrictive conditions, where the attacker lacks access to the model’s internal parameters or gradients. Transfer-based attacks, such as those described in [
15], exploit the transferability property of adversarial examples, where examples crafted for one model are often effective against other models with similar architectures. Decision-based attacks, including the Boundary Attack [
16], iteratively refine the adversarial example by querying the target model and moving toward the decision boundary. These methods are particularly suited for scenarios where only the model’s output predictions are available.
2.2. Generative Models in Adversarial Attacks
Generative models, particularly Generative Adversarial Networks (GANs) [
17], have emerged as powerful tools for generating adversarial examples. GANs consist of a generator network that synthesizes realistic data samples and a discriminator network that distinguishes between real and generated samples. By leveraging GANs, researchers have demonstrated the ability to produce adversarial examples that not only deceive DNNs but also maintain high visual fidelity.
Among various GAN-based approaches, StyleGAN [
18] has gained prominence for its ability to generate high-quality images with fine-grained control over features. StyleGAN’s latent space allows for the manipulation of semantic attributes in images, enabling the creation of adversarial examples that preserve key characteristics of the original sample. In [
19], the authors employed GANs to craft adversarial examples by learning the distribution of clean and adversarial images, demonstrating the potential of generative models to generate diverse and effective attacks. Additionally, studies such as [
20] have explored conditional GANs to generate class-specific adversarial examples, showcasing the adaptability of generative approaches.
2.3. Adversarial Defenses and Limitations
To counteract adversarial attacks, various defense mechanisms have been proposed, ranging from adversarial training [
21] to input preprocessing techniques [
22]. Adversarial training augments the training dataset with adversarial examples, thereby improving the model’s robustness against such attacks. However, this approach is computationally expensive and often limited to specific attack types. Input preprocessing methods, such as image compression or denoising, aim to remove adversarial perturbations before feeding inputs into the model. While effective against certain attacks, these defenses are often circumvented by adaptive adversarial strategies.
Despite significant progress in adversarial defense, many approaches exhibit limitations, particularly in black-box settings where the attacker’s knowledge is restricted. The trade-off between robustness and generalization remains a key challenge, as overly robust models may suffer from degraded performance on clean data. Moreover, most defenses focus on white-box attacks, leaving black-box scenarios relatively underexplored.
2.4. Advances in Black-Box Adversarial Attacks
Recent research has highlighted the challenges of generating adversarial examples [
23,
24,
25,
26,
27] in black-box environments, where the attack relies on limited information about the target model. Query-efficient methods, such as the Natural Evolution Strategy (NES) [
28], optimize adversarial perturbations with a minimal number of queries, improving practicality in real-world scenarios. Additionally, methods like the Surrogate Model approach [
29] train a local model to approximate the target model’s decision boundaries, enabling effective adversarial example generation without direct access to the target.
Generative models have also been applied in black-box settings to enhance attack efficiency. In [
30], the authors introduced a generative framework for crafting adversarial examples by modeling the spatial transformations of images. These advancements underline the growing interest in designing attacks that are both effective and computationally feasible under constrained settings.
2.5. Motivation for the Proposed Method
While significant strides have been made in adversarial attack techniques, most existing methods either focus on targeted attacks or require substantial prior knowledge of the target model. The proposed method seeks to address these limitations by introducing an untargeted attack framework based on StyleGAN, tailored for black-box environments. By leveraging StyleGAN’s latent space, the method generates adversarial examples that are visually indistinguishable from the original samples, achieving high attack success rates with minimal distortion. This approach bridges the gap between traditional adversarial attacks and generative techniques, offering a robust solution for real-world adversarial scenarios.
This study builds upon the foundational work in adversarial example generation and seeks to advance the field by combining the strengths of generative models with practical considerations for black-box settings. The proposed method contributes to a deeper understanding of neural network vulnerabilities and emphasizes the importance of developing more robust defense mechanisms.
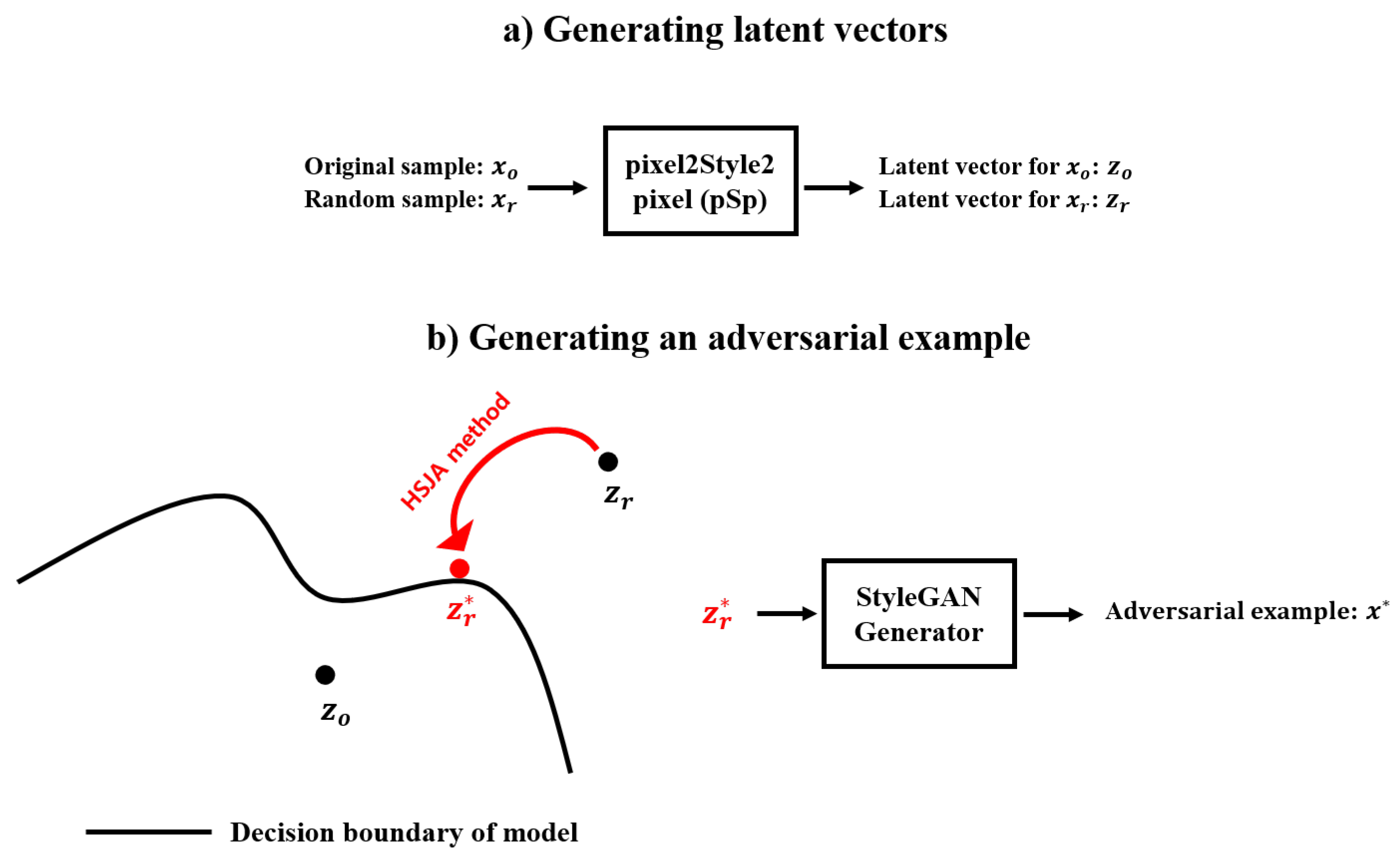
2.6. Proposed Method for Generating Adversarial Examples
The first step in the proposed scheme involves transforming both the original sample and a random sample into latent vectors. For this purpose, we employ the pixel2style2pixel (pSp) encoder [
31], which is a powerful framework designed to encode an image into a latent vector space. The pSp encoder leverages a pre-trained StyleGAN generator to extract features from images, mapping them into the extended latent space (
) of the generator. This process generates a set of latent vectors, one for each layer of the StyleGAN generator, allowing for multi-scale representation and fine-grained manipulation of image semantics.
In our approach, the original image
and the random image
are passed through the encoder to obtain their corresponding latent vectors:
where each
represents a latent vector corresponding to a specific layer of the StyleGAN generator. The pSp encoder is particularly effective in this task because it generates a multi-scale feature pyramid from the StyleGAN latent space, which can capture different granularities of style information. By encoding both the original and random samples into the same latent space, we ensure that they share a common representation that allows for meaningful manipulations to be performed in the next step.
3. Proposed Scheme
In this section, we present the proposed method for generating adversarial examples by combining the HopSkipJumpAttack (HSJA) method [
32] with the StyleGAN model. The overall structure of the proposed scheme is illustrated in
Figure 1. The method consists of two main steps: first, the conversion of the original and random samples into latent vectors, and second, the generation of adversarial examples by manipulating these latent vectors.
The first step in the proposed scheme involves transforming both the original sample and a random sample into latent vectors. For this purpose, we employ the pixel2style2pixel (pSp) encoder [
31], which is a powerful framework designed to encode an image into a latent vector space. The pSp encoder leverages a pre-trained StyleGAN generator to extract features from images, mapping them into the extended latent space (
) of the generator. This latent space representation allows us to manipulate images at a semantic level, preserving high-level features such as facial structures, object types, or scene layouts, while providing flexibility to adjust the style or identity of the image.
In our approach, the original image
and the random image
are passed through the encoder to obtain their corresponding latent vectors:
where each
represents a latent vector corresponding to a specific layer of the StyleGAN generator. The pSp encoder generates a multi-scale feature pyramid from the StyleGAN latent space, capturing different granularities of style information. By encoding both the original and random samples into the same extended latent space, we ensure that they share a common representation that allows for meaningful manipulations to be performed in the next step.
The second step involves the generation of adversarial examples by modifying the latent vector of the random sample to make it classified as a different class by the target model, while ensuring that the generated adversarial example remains perceptually similar to the original sample. This is achieved by applying the HSJA method, a decision-based attack method that minimizes the distance between the latent vectors of the original and random samples.
Specifically, the HSJA algorithm performs iterative updates to the latent vector , moving it in such a way that the adversarial example generated from the new latent vector is misclassified by the target model. The updates to are guided by the norm, which measures the Euclidean distance between the latent vectors of the original and random samples. By minimizing this distance, we ensure that the latent vectors remain close to each other, thereby preserving the essential content of the original image.
Once the updated latent vector
is obtained, it is fed into the StyleGAN generator
to produce the final adversarial example
. The adversarial example
is semantically similar to the original image, as it is derived from a latent space that closely resembles that of the original image, but it is misclassified by the model as an arbitrary class other than the original class. The iterative process of latent vector updates and adversarial example generation is performed several times, allowing the algorithm to converge to a point where the adversarial example is highly effective in deceiving the model. The overall procedure for generating adversarial examples using the proposed scheme is summarized in Algorithm 1.
| Algorithm 1 Proposed adversarial example generation |
Input: Original sample , Random sample , StyleGAN generator , operation function of model . Output: Generated proposed adversarial example . procedure Adversarial Example Generation ← Encoder() ▹ Encode original sample into latent vector ← Encoder() ▹ Encode random sample into latent vector ← HSJA(, , , ) ▹ Apply HSJA to optimize latent vector ← ▹ Generate adversarial example from the modified latent vector Return ▹ Return the generated adversarial example end procedure
|
The proposed method offers several key advantages that distinguish it from traditional adversarial attack methods. First, by leveraging the power of StyleGAN and the pSp encoder, the generated adversarial examples retain high perceptual quality, making them indistinguishable from the original samples to human observers. This is critical in applications where the visual integrity of the adversarial examples is important, such as in image-based security systems or medical image analysis.
Second, the use of the HSJA method allows for decision-based attacks in black-box settings, where the attacker does not have access to the model’s internal parameters or gradients. The iterative process of minimizing the distance between the latent vectors of the original and random samples ensures that the adversarial examples are crafted in a way that optimally exploits the model’s decision boundaries, leading to high attack success rates.
Finally, the ability to generate untargeted adversarial examples, where the class label of the original sample is changed to a random class, opens up new possibilities for adversarial attacks in scenarios where the attacker does not know the target class in advance. This makes the method more versatile and applicable to a wide range of adversarial attack scenarios.
5. Discussion
5.1. Assumption
The proposed method is particularly advantageous in black-box attack scenarios, where the attacker only has access to the classification output of the target model, rather than the probability distribution over all classes. This is a realistic setting, especially in practical applications such as attacking commercial facial recognition systems. Unlike white-box attacks, which assume complete knowledge of the target model, the proposed method operates effectively with minimal prior information, demonstrating its practicality and adaptability in real-world situations.
5.2. Threat or Attack Model
The proposed attack method assumes a realistic and constrained black-box attack scenario, where the attacker has limited access to the internal parameters of the target system. In this scenario, the attacker can only query the system to obtain classification outputs, such as the predicted class, without having knowledge of the underlying model architecture, parameter values, or the probability distribution over all classes. This assumption reflects practical applications, including commercial facial recognition systems, where internal details of the models are typically inaccessible to attackers.
The attack leverages vulnerabilities in the decision boundary of the target model by applying subtle perturbations to input data, which mislead the model into making incorrect classifications. By utilizing a generative model such as StyleGAN, the proposed method identifies adversarial directions in the feature space. These directions enable the generation of adversarial examples that remain imperceptible to human observers and undetectable by automated defense mechanisms. This aspect is particularly significant in high-dimensional data domains, such as images, where exhaustive testing of all potential perturbations is infeasible for defenders.
The attacker in this scenario is assumed to have the capability to query the target model and observe its classification results. Additionally, the attacker is presumed to operate with minimal prior information, as they do not possess knowledge of the model’s architecture, training data, or parameter values. However, they are assumed to have access to a pretrained generative model, such as StyleGAN, which allows for the generation and modification of high-quality samples in the data domain of interest.
Executing the attack requires certain tools and resources. Specifically, the attacker needs access to the pretrained StyleGAN model to generate synthetic samples and the Hierarchical Joint Style-Attention (HJSA) method to effectively identify and apply adversarial perturbations. Furthermore, computational resources such as GPUs are necessary to perform iterative optimization, ensuring the efficiency of the attack process.
A potential attack scenario can be envisioned in the context of a commercial facial recognition system used for user authentication. In such a scenario, an attacker could collect publicly available images of the target individual and use StyleGAN to generate synthetic facial images that closely resemble the target. Subsequently, adversarial perturbations are applied iteratively until the generated images successfully deceive the recognition system without being detected by automated defenses. By detailing the system’s vulnerabilities, the attacker’s capabilities, and the required tools, this threat model illustrates the feasibility of the proposed attack.
5.3. Contribution
The proposed method introduces a novel approach for generating untargeted adversarial examples, aiming to create adversarial samples that are misclassified as any class other than the original class. This untargeted nature allows the method to achieve adversarial examples with less distortion and fewer iterations compared to targeted attacks, which require aligning the adversarial example with a specific class. By integrating advanced techniques such as StyleGAN and the Hierarchical Joint Style-Attention (HJSA) method, the proposed method effectively enhances both the efficiency and success rate of adversarial attacks, demonstrating the potential of combining generative models with adversarial methodologies.
5.4. Attack Success Rate
In our study, the attack success rate is defined as the proportion of adversarial examples that are misclassified as any class other than the original class. Specifically, for a given adversarial example, the attack is considered successful if the target model outputs a predicted label different from the original class label. This approach aligns with the definition of untargeted adversarial attacks, where the primary objective is to cause misclassification without targeting a specific alternative class.
For instance, if the evaluation dataset contains 100 samples and 95 of these samples are misclassified into classes other than their respective original classes, the attack success rate is calculated as
In the experiments presented in the paper, no additional thresholding mechanism was applied beyond the fundamental condition of misclassification. The success rate is directly computed based on the aforementioned definition across all samples in the test dataset. This ensures that the reported metric accurately reflects the method’s ability to induce misclassification under realistic conditions.
5.5. Attack Behavior and Class Probability Fluctuations
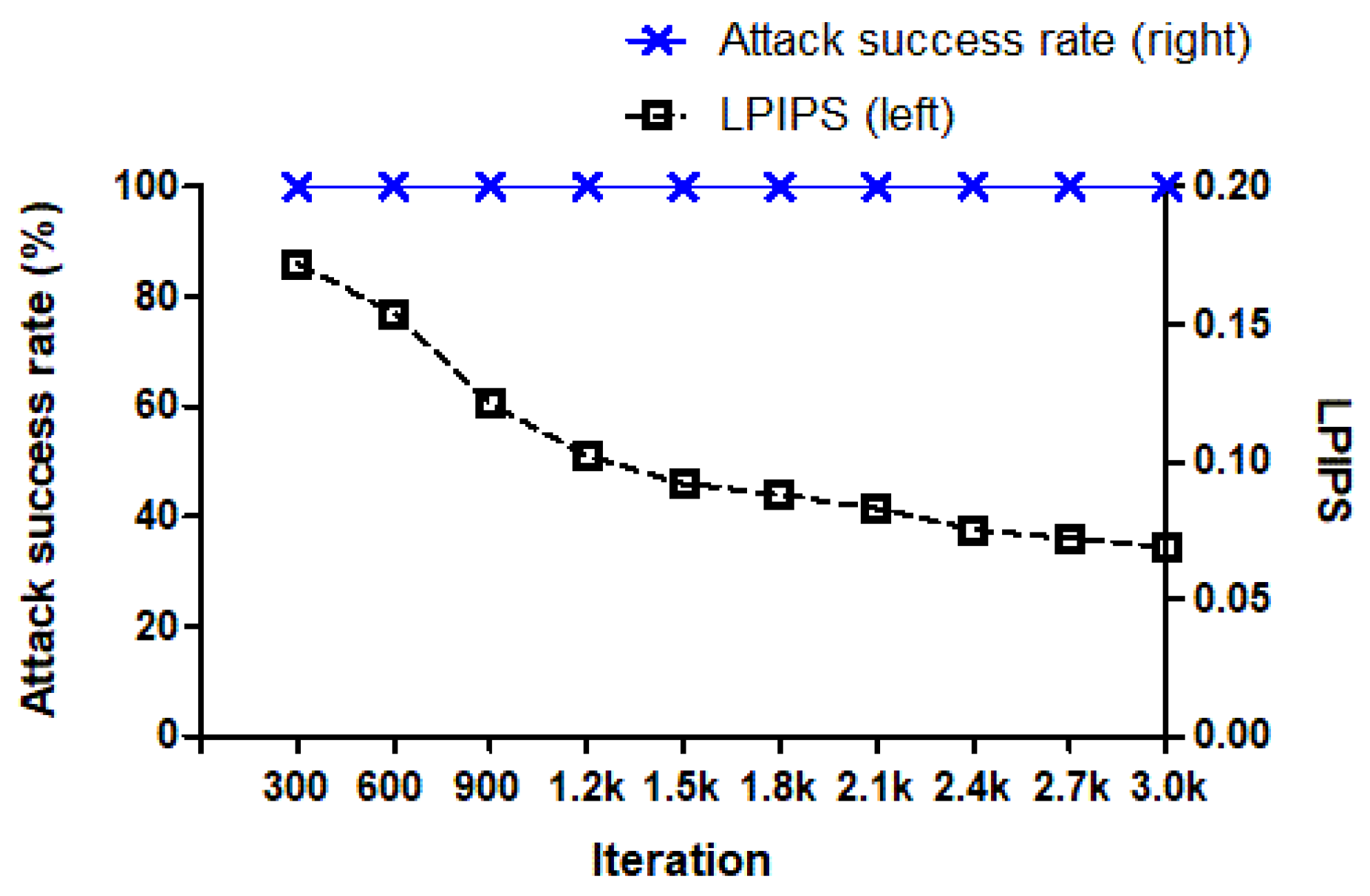
As the number of attack iterations increases, the perceptual image patch similarity (LPIPS) value decreases consistently, indicating that the generated adversarial examples become perceptually more similar to the original images. However, the attack success rate can exhibit irregular fluctuations across different iteration counts. This irregularity in the predicted class probability can be attributed to the nature of the adversarial perturbations generated during the optimization process.
During the attack, the adversarial perturbations are continuously adjusted in an attempt to mislead the classifier. The method operates in a high-dimensional space, where multiple local minima may exist. This can lead to variations in the class probabilities across iterations, causing the class probability to deviate and fluctuate even as the LPIPS value steadily decreases, indicating improved perceptual similarity. Ultimately, while the attack success rate stabilizes and reaches 100% around 300 iterations, the fluctuations in the class probabilities reflect the complexity and sensitivity of the classifier to adversarial perturbations at various stages of the attack process.
5.6. Attack Effectiveness
In terms of attack effectiveness, the method achieves a high success rate in misleading facial recognition models while preserving the perceptual similarity of adversarial examples to the original images. This is particularly important in practical scenarios, where subtle perturbations that remain undetectable to human observers and automated defenses are critical. The iterative optimization process employed in the method achieves a 100% attack success rate within 300 iterations, highlighting the robustness of the approach. Furthermore, the use of StyleGAN enables the generation of adversarial examples with high visual fidelity, ensuring that the perturbations are imperceptible while maintaining the intended adversarial effects.
5.7. Class-Wise Distribution of Misclassified Images
The proposed method generates untargeted adversarial examples by explicitly introducing random values to determine the target classes for misclassification. This ensures that no specific bias is introduced during the attack process, resulting in a random and uniform distribution of misclassified classes across all available categories. An analysis of the class-wise distribution of misclassified images was conducted to validate the randomness of the method. The results confirm that the misclassified examples are evenly distributed among the classes, demonstrating that the attack method induces random misclassification as intended. This characteristic underscores the untargeted nature of the proposed approach, ensuring that the adversarial perturbations effectively push the input data beyond the decision boundary of the original class without favoring any specific alternative class.
5.8. Domain-Specific Application of StyleGAN
The StyleGAN model employed in this study was trained using the CelebA-HQ dataset [
12], a high-quality dataset comprising 30,000 high-resolution facial images with dimensions of 1024 × 1024 pixels. The dataset includes 6217 distinct identities, with each image annotated with 40 attribute labels. For our experiments, a publicly available pre-trained StyleGAN2 model, designed to generate high-fidelity facial images, was utilized. This model, which served as the foundation for generating adversarial examples, is available at the following repository (accessed on 1 January 2025):
https://github.com/justinpinkney/awesome-pretrained-stylegan2.
In this study, adversarial examples were generated to attack a facial gender classification model trained on the CelebA-HQ dataset. The classification model utilized a ResNet18 architecture, initialized with pre-trained weights from PyTorch’s model zoo. The model was fine-tuned using the CelebA-HQ dataset to achieve optimal performance on the gender classification task.
The domain-specific nature of StyleGAN plays a critical role in its application. Since the latent space representations of StyleGAN are inherently tied to the dataset used for training, the generated adversarial examples remain within the domain of the training data. For instance, a StyleGAN model trained to generate images of cats would produce adversarial examples specific to the domain of cat images. Consequently, using a StyleGAN trained on a different domain, such as cats, would not effectively generate adversarial examples for a classifier trained on an unrelated domain, such as traffic signs. Furthermore, the proposed method is tailored to targeted adversarial attacks within the classification classes provided by the dataset used in the experiments. The adversarial examples leverage the latent space of the StyleGAN model, which is specific to the dataset used for training. As a result, misclassifications are induced within the classes of the corresponding dataset. Extending the method to other domains or datasets would require training or fine-tuning the StyleGAN model on datasets relevant to those specific domains.
5.9. Perceptual Quality
The perceptual quality of the generated adversarial examples is quantified using the Learned Perceptual Image Patch Similarity (LPIPS) metric, which measures the perceptual difference between two images. A lower LPIPS score indicates greater similarity to the original sample. The proposed method achieves an LPIPS score of 0.069 after 3000 iterations, which demonstrates that the adversarial examples are nearly indistinguishable from the original images in terms of visual appearance. This low level of distortion ensures the effectiveness of the attack while minimizing artifacts that might otherwise alert detection mechanisms. In addition, based on our experimental setup, it takes approximately 4 min and 20 s to complete 3000 iterations.
5.10. Limitation and Future Research
Certain limitations of the proposed method must be acknowledged. One notable limitation is the reliance on multiple queries to the target model during the adversarial example generation process. Although the method achieves high attack success rates with 300 iterations, the iterative nature of the process could be computationally expensive in scenarios with strict query limits or time constraints. Additionally, subtle changes in attributes such as position, expression, or color of the adversarial examples may occur compared to the original images. While these changes are generally imperceptible to the human eye, they could pose challenges under specific conditions, such as variations in lighting or pose, which may slightly affect the robustness of the attack.
These findings emphasize the importance of developing robust defense mechanisms against adversarial attacks, particularly for facial recognition systems. The demonstrated success of the proposed method, even with minimal perceptual distortion, highlights the need for proactive measures such as adversarial training and model enhancement. The use of generative models like StyleGAN for adversarial purposes also suggests the necessity of future research into model interpretability and robustness to address vulnerabilities exposed by such advanced attack techniques.
In addition, the proposed method leverages iterative optimization and multiple queries to the target model, which results in considerable computational overhead. Future work will explore more efficient optimization strategies to mitigate the computational cost, enabling faster and more practical applications in resource-constrained environments. Furthermore, the current approach is heavily dependent on the capabilities of StyleGAN, which may limit its generalizability to other generative models. Future research will investigate the adaptability of the proposed method to different generative models. By exploring various alternatives, this approach aims to improve robustness and versatility, enhancing applicability to a broader range of tasks.
The current experimental evaluation primarily focuses on the CelebA-HQ dataset and FFHQ dataset. To ensure broader generalizability, future research will include datasets with distinct class variations, such as cat vs. dog, which represent a fundamentally different data distribution. Expanding the scope of experiments in this way will provide deeper insights into the method’s performance across diverse scenarios.
In conclusion, the proposed method offers an effective and practical approach for generating untargeted adversarial examples in black-box environments. While there are limitations related to query efficiency and minor perceptual changes, the method’s strengths, including its high success rate, low distortion, and applicability in real-world scenarios, underscore its significance in advancing the field of adversarial machine learning. Future research will focus on optimizing the query process, addressing the observed limitations, and expanding the experimental scope to improve the practicality and robustness of the method.
6. Conclusions
This paper presents a novel approach for generating untargeted adversarial examples in an unrestricted environment, addressing the challenges of creating adversarial samples that are effective, minimally distorted, and applicable in realistic black-box scenarios. The proposed method focuses on generating adversarial examples that are misclassified as arbitrary classes, rather than the original class, thus reducing the need for excessive perturbations. By incorporating StyleGAN, the method ensures that the generated adversarial examples maintain high visual fidelity, minimizing distortions to a level imperceptible to human observers.
The experimental results demonstrate the effectiveness of the proposed approach. In a black-box setting, where only the classification outcome of the target model is known, the method achieves a 100% attack success rate within 3000 iterations. This high success rate underscores the robustness of the attack, even in scenarios with limited information about the target model. Furthermore, the perceptual similarity between the original and adversarial samples, quantified using the Learned Perceptual Image Patch Similarity (LPIPS) metric, is measured at 0.069. This value indicates that the adversarial examples are almost indistinguishable from the original samples, highlighting the minimal distortion introduced by the proposed method.
The unrestricted nature of the proposed approach allows for greater flexibility in generating adversarial examples, making it a valuable contribution to the field of adversarial machine learning. Unlike targeted attacks, which require the adversarial example to be misclassified into a specific target class, this untargeted approach focuses on any misclassification other than the original class, significantly simplifying the optimization process while maintaining high attack success rates.
Despite its strengths, this study acknowledges several areas for future exploration. One potential direction is the application of the proposed method to other datasets, expanding its generalizability across diverse domains and use cases. Additionally, advancements in generative modeling, such as diffusion models, present a promising avenue for further research. These models could be explored as alternative mechanisms for generating adversarial examples, potentially improving both efficiency and effectiveness.




{kind=link}
{kind=link}

















