
Methodology of an Energy Efficient-Embedded Self-Adaptive Software Design for Multi-Cores and Frequency-Scaling Processors Used in Real-Time Systems


Abstract
1. Introduction
2. Related Works
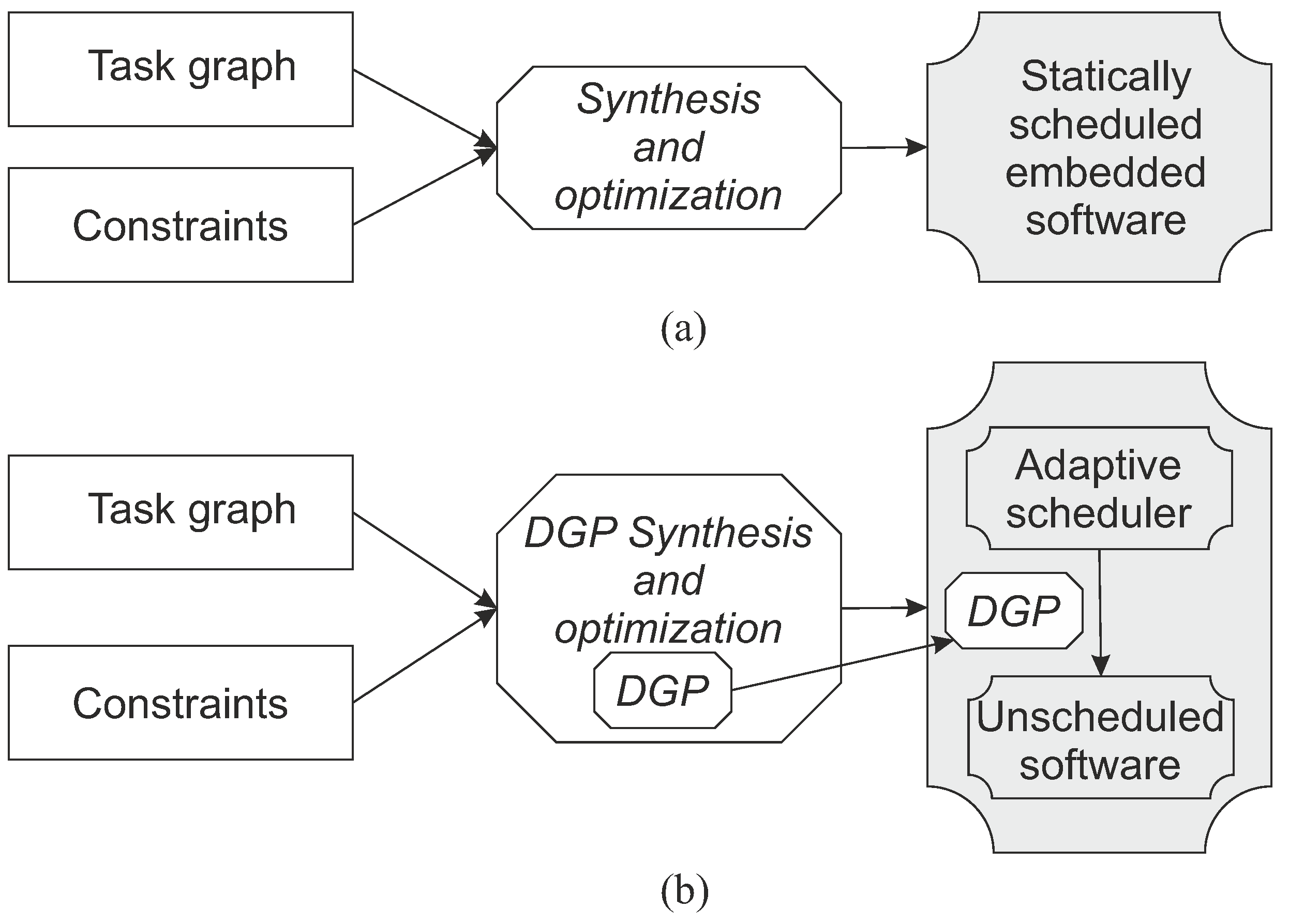
3. Developmental Genetic Programming
| Algorithm 1 A scheduler—Adaptive scheduling method. TG—task graph, TaskList—a list of tasks ordered according to their deadlines |
| procedure StaticSchedule(TG) for each task Ti from TG do Assign the strategy to the Ti Calculate the deadline to execute Ti and add Ti to TList end for Reschedule(TList) end procedure |
| procedure Reschedule(TaskList) for each task Ti from TaskList do ResList = Order all resources according to the best fitting to the strategy of Ti for each Rj from ResList do end_time ← max(Idle(Rj), Start(Ti)) + execution_time(Ti, Rj) if end_time ≤ deadline(Ti) then schedule(Ti, Rj) break end if end for end for end procedure |
4. Synthesis of Self-Adaptive Scheduler
4.1. System Specification
4.2. System Hardware
- Task—task identifier;
- t— estimated execution time;
- p—estimated power consumption;
- Min—shortest case;
- Avg—average case;
- Max—longest case.
4.3. Rating a Quality
- The sum of average execution times does not exceed the deadline;
- The frequency of the selected core is not changed during a task execution;
- During the scheduling, the core frequency can be freely selected for each task from the available options;
- The level of an energy consumption is as low as possible;
- The level of self-adaptation is maximized.
- The recently completed task exceeded its usual duration, which resulted in a violation of the time constraints for the next task.
- The most recently completed task was completed in a shorter time, which provides an opportunity to save energy by reallocating some tasks to low-power cores or reducing the frequency of occupied cores.
4.4. Genotype and Phenotype
- The highest performance core;
- The core that consumes the least energy during execution;
- The best ratio of time to energy consumption;
- The core that could start task execution first;
- Considering a start time, the core that finishes task execution first;
- The first available core from these ones that consumes the least energy during execution;
- The fixed assignment defined by the second chromosome.
4.5. Evolution
5. Experimental Results
5.1. Overview of Previous Research
5.2. Influence of Self-Adaptation on Energy Consumption
- Self-Adaptive Behavior and Energy Usage:Self-adaptive behavior was observed to lead to the highest energy consumption. This result is attributed to the system’s tendency to rely predominantly on the fastest resources available, which, while reducing task completion time, increases overall energy demand. The system’s prioritization of adaptability likely causes a shift towards higher-performance (and, thus, higher-energy) cores to maintain flexibility and responsiveness to changing workloads.
- Self-Optimization and Energy Efficiency:In contrast, self-optimization was found to facilitate a reduction in energy consumption. However, this approach does not inherently consider the potential benefits of rescheduling tasks across different resources. As a result, while self-optimization effectively reduces energy usage by optimizing resource allocation, it can miss opportunities to further minimize energy consumption by dynamically adjusting task scheduling.
- Energy-Only Evaluation and Resource Utilization:When the evaluation metric focused only on energy consumption, it was expected to produce the most energy efficient solution for the initial task scheduling. However, this approach exhibited a significant drawback. By greedily selecting the lowest-energy resources early in the scheduling process, the system was compelled to rely on more powerful and energy-consuming resources, especially at the end of the schedule. This behavior resulted in an overall increase in energy consumption, contrary to the intended goal of minimizing it.
- Balanced Multi-Criteria Evaluation:The most effective results were achieved when the evaluation uses all three criteria: self-adaptation, self-optimization, and energy consumption. This comprehensive approach allowed the algorithm to avoid local minima by considering the trade-offs between adaptability, optimization, and energy efficiency. In effect, the system was able to achieve a more balanced allocation of tasks across resources, leading to improved energy efficiency without sacrificing performance.
5.3. Implementing DVFS in the Presented Method
5.4. Effects of Introduced Improvements
- Figure 6 presents a schedule that does not consider time buffers or DVFS (dynamic voltage and frequency scaling). The behavior of the system here indicates an attempt to save energy, but this decreases flexibility and responsiveness to potential delays.
- Figure 7 displays a schedule that incorporates time buffers but not DVFS. This approach increases the time resistance of the system for time delays, but the initial scheduling consumes a little more energy, because there is a little more pressure to choose more performance-oriented cores.
- Speed-Oriented Strategies: Approaches focused basically on speed often yield suboptimal results, as they do not leverage energy-saving opportunities. In some optimistic scenarios, these strategies can even lead to worse results, as they may over-utilize high-performance resources, leading to unnecessary energy consumption.
- Energy-Efficient Strategies: While energy-efficient strategies are effective in saving energy under optimistic conditions, they tend to result in higher initial energy usage. This is due to time constraints necessitating the use of more powerful, energy-intensive resources early in the scheduling process to meet deadlines.
- Multi-Criteria Evaluation: The best results were achieved using a multi-criteria fitness function, which balanced speed and energy efficiency. The optimal result was achieved when the parameters of the fitness function were set to and . This configuration favored the creation of time buffers that encouraged a more diversified use of resources, leading to a more balanced and efficient schedule. The schedule generated under these conditions is illustrated in Figure 10.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Individuals | Optimistic Case | The Most Expected Case | Pessimistic Case |
|---|---|---|---|
| Only the fastest | 2053 | 1890 | 1880 |
| Only the most energy efficient | 477 | 1699 | 1688 |
| Only the best ratio of time to energy consumption | 468 | 1570 | 1556 |
| Only determined by the alternative gene | 1661 | 1736 | 1696 |
| Only the fastest available core | 1903 | 1780 | 1880 |
| Only the fastest finishing core | 1868 | 1725 | 2047 |
| Only the most energy-efficient core that is available first | 1903 | 1780 | 1880 |
| The best one achieved when and (Figure 8) | 565 | 1501 | 1516 |
| The best one achieved when and Figure 9) | 562 | 1484 | 1503 |
| The best one achieved when and (Figure 10) | 572 | 1562 | 1590 |
| The best one achieved when and without DVFS | 981 | 1517 | 1532 |



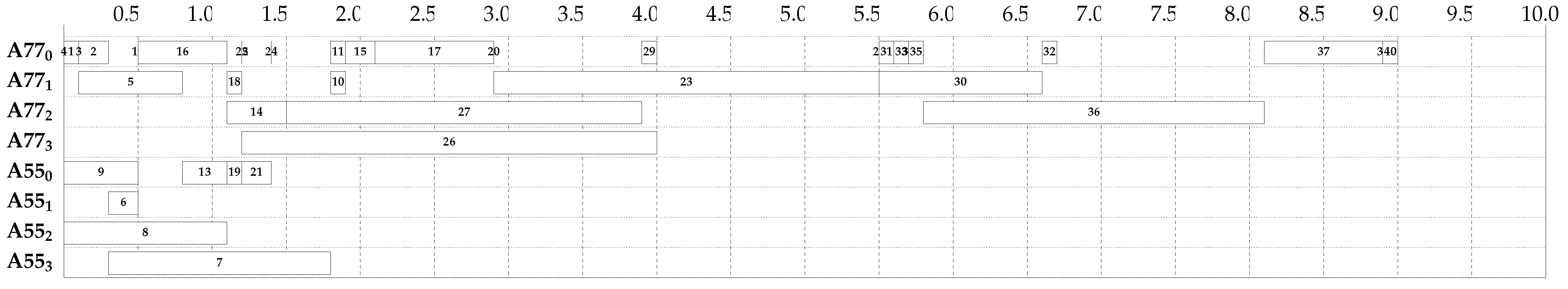

6. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yen, T.Y.; Wolf, W. Hardware-Software Co-Synthesis of Distributed Embedded Systems; Springer: Boston, MA, USA, 1996. [Google Scholar] [CrossRef]
- Humrick, M. Exploring DynamIQ and ARM’s New CPUs: Cortex-A75, Cortex-A55. 2017. Available online: https://www.anandtech.com/show/11441/dynamiq-and-arms-new-cpus-cortex-a75-a55 (accessed on 31 October 2023).
- Macías-Escrivá, F.D.; Haber, R.; del Toro, R.; Hernandez, V. Self-adaptive systems: A survey of current approaches, research challenges and applications. Expert Syst. Appl. 2013, 40, 7267–7279. [Google Scholar] [CrossRef]
- Deniziak, S.; Ciopiński, L. Synthesis of self-adaptable energy aware software for heterogeneous multicore embedded systems. Microelectron. Reliab. 2021, 123, 114184. [Google Scholar] [CrossRef]
- Deniziak, S.; Ciopiński, L. Synthesis of Power Aware Adaptive Embedded Software Using Developmental Genetic Programming. In Recent Advances in Computational Optimization: Results of the Workshop on Computational Optimization WCO 2015; Fidanova, S., Ed.; Springer International Publishing: Cham, Switzerland, 2016; pp. 97–121. [Google Scholar] [CrossRef]
- Salehie, M.; Tahvildari, L. Self-Adaptive Software: Landscape and Research Challenges. ACM Trans. Auton. Adapt. Syst. 2009, 4, 1–42. [Google Scholar] [CrossRef]
- Schmeck, H.; Müller-Schloer, C.; Çakar, E.; Mnif, M.; Richter, U. Adaptivity and Self-Organization in Organic Computing Systems. ACM Trans. Auton. Adapt. Syst. 2010, 5, 1–32. [Google Scholar] [CrossRef]
- Yeom, K.; Park, J.H. Morphological approach for autonomous and adaptive systems based on self-reconfigurable modular agents. Future Gener. Comput. Syst. 2012, 28, 533–543. [Google Scholar] [CrossRef]
- Vogel, T.; Neumann, S.; Hildebrandt, S.; Giese, H.; Becker, B. Model-Driven Architectural Monitoring and Adaptation for Autonomic Systems. In Proceedings of the 6th International Conference on Autonomic Computing, Barcelona, Spain, 15–19 June 2009; Association for Computing Machinery: New York, NY, USA, 2009. ICAC ’09. pp. 67–68. [Google Scholar] [CrossRef]
- Leitao, P. Holonic Rationale and Bio-inspiration on Design of Complex Emergent and Evolvable Systems. In Transactions on Large-Scale Data- and Knowledge-Centered Systems I; Hameurlain, A., Küng, J., Wagner, R., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 243–266. [Google Scholar] [CrossRef]
- Chen, T. A self-adaptive agent-based fuzzy-neural scheduling system for a wafer fabrication factory. Expert Syst. Appl. 2011, 38, 7158–7168. [Google Scholar] [CrossRef]
- Oreizy, P.; Gorlick, M.M.; Taylor, R.N.; Heimhigner, D.; Johnson, G.; Medvidovic, N.; Quilici, A.; Rosenblum, D.S.; Wolf, A.L. An architecture-based approach to self-adaptive software. IEEE Intell. Syst. Their Appl. 1999, 14, 54–62. [Google Scholar] [CrossRef]
- Higuera-Toledano, M.T.; Brinkschulte, U.; Rettberg, A. (Eds.) Self-Organization in Embedded Real-Time Systems; Springer Science+Business Media: New York, NY, USA, 2012. [Google Scholar] [CrossRef]
- Pułka, A.; Milik, A. Dynamic Rescheduling of Tasks in Time Predictable Embedded Systems. IFAC Proc. Vol. 2012, 45, 305–310. [Google Scholar] [CrossRef]
- Gharsellaoui, H.; Ktata, I.; Kharroubi, N.; Khalgui, M. Real-time reconfigurable scheduling of multiprocessor embedded systems using hybrid genetic based approach. In Proceedings of the 2015 IEEE/ACIS 14th International Conference on Computer and Information Science (ICIS), Las Vegas, NV, USA, 28 June–1 July 2015; pp. 605–609. [Google Scholar] [CrossRef]
- Calhoun, K.M.; Deckro, R.F.; Moore, J.T.; Chrissis, J.W.; Van Hove, J.C. Planning and re-planning in project and production scheduling. Omega 2002, 30, 155–170. [Google Scholar] [CrossRef]
- Van de Vonder, S.; Demeulemeester, E.; Herroelen, W. A classification of predictive-reactive project scheduling procedures. J. Sched. 2007, 10, 195–207. [Google Scholar] [CrossRef]
- El Sakkout, H.; Wallace, M. Probe backtrack search for minimal perturbation in dynamic scheduling. Constraints 2000, 5, 359–388. [Google Scholar] [CrossRef]
- Al-Fawzan, M.; Haouari, M. A bi-objective model for robust resource-constrained project scheduling. Int. J. Prod. Econ. 2005, 96, 175–187. [Google Scholar] [CrossRef]
- Bambagini, M.; Marinoni, M.; Aydin, H.; Buttazzo, G. Energy-Aware Scheduling for Real-Time Systems: A Survey. ACM Trans. Embed. Comput. Syst. 2016, 15, 1–34. [Google Scholar] [CrossRef]
- Scordino, C.; Abeni, L.; Lelli, J. Energy-Aware Real-Time Scheduling in the Linux Kernel. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing, Pau, France, 9–13 April 2018; Association for Computing Machinery: New York, NY, USA, 2018. SAC ’18. pp. 601–608. [Google Scholar] [CrossRef]
- Zeng, G.; Yokoyama, T.; Tomiyama, H.; Takada, H. Practical Energy-Aware Scheduling for Real-Time Multiprocessor Systems. In Proceedings of the 2009 15th IEEE International Conference on Embedded and Real-Time Computing Systems and Applications, Beijing, China, 24–26 August 2009; pp. 383–392. [Google Scholar] [CrossRef]
- Deniziak, S.; Ciopinski, L. Design for Self-Adaptivity of Real-Time Embedded Systems Using Developmental Genetic Programming. In Proceedings of the 2018 Conference on Electrotechnology: Processes, Models, Control and Computer Science (EPMCCS), Kielce, Poland, 12–14 November 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Li, X.; Mo, L.; Kritikakou, A.; Sentieys, O. Approximation-Aware Task Deployment on Heterogeneous Multicore Platforms with DVFS. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2022, 42, 2108–2121. [Google Scholar] [CrossRef]
- Shukla, S.K.; Pant, B.; Viriyasitavat, W.; Verma, D.; Kautish, S.; Dhiman, G.; Kaur, A.; Srihari, K.; Mohanty, S.N. An integration of autonomic computing with multicore systems for performance optimization in Industrial Internet of Things. IET Commun. 2022. [Google Scholar] [CrossRef]
- Deniziak, S.; Płaza, M.; Arcab, L. Approach for Designing Real-Time IoT Systems. Electronics 2022, 11, 4120. [Google Scholar] [CrossRef]
- Koza, J.; Poli, R. Genetic Programming. In Search Methodologies; Burke, E., Kendall, G., Eds.; Springer: Boston, MA, USA, 2005; pp. 127–164. [Google Scholar] [CrossRef]
- Koza, J.R.; Bennett, F.H., III; Andre, D.; Keane, M.A. Evolutionary design of analog electrical circuits using genetic programming. In Proceedings of the Adaptive Computing in Design and Manufacture; Springer: London, UK, 1998; pp. 177–192. [Google Scholar] [CrossRef]
- Deniziak, S.; Ciopiński, L. Synthesis of power aware adaptive schedulers for embedded systems using developmental genetic programming. In Proceedings of the Federated Conference on Computer Science and Information Systems (FedCSIS), Lodz, Poland, 13–16 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 449–459. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, H.; Liu, D.; Qin, Z.; Shao, Z.; Sha, E.H.M. Overhead-aware energy optimization for real-time streaming applications on multiprocessor System-on-Chip. ACM Trans. Des. Autom. Electron. Syst. 2011, 16, 1–32. [Google Scholar] [CrossRef]
- Fornaciari, W.; Gubian, P.; Sciuto, D.; Silvano, C. Power estimation of embedded systems: A hardware/software codesign approach. IEEE Trans. Very Large Scale Integr. (VLSI) Syst. 1998, 6, 266–275. [Google Scholar] [CrossRef]
- Ermedahl, A.; Engblom, J. Execution Time Analysis for Embedded Real-Time Systems. In Handbook of Real-Time and Embedded Systems; Lee, I., Joseph, Y.-T., Leung, S.H.S., Eds.; Chapman & Hall/CRC: New York, NY, USA, 2008; pp. 437–455. [Google Scholar]
- Noghin, V.D. Linear scalarization in multi-criterion optimization. Sci. Tech. Inf. Process. 2015, 42, 463–469. [Google Scholar] [CrossRef]
- Michalewicz, Z. Genetic Algorithms+ Data Structures= Evolution Programs; Springer: Berlin/Heidelberg, Germany, 1996. [Google Scholar] [CrossRef]
- Sapiecha, K.; Ciopiński, L.; Deniziak, S. An application of developmental genetic programming for automatic creation of supervisors of multi-task real-time object-oriented systems. In Proceedings of the 2014 Federated Conference on Computer Science and Information Systems (FedCSIS), Warsaw, Poland, 7–10 September 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 501–509. [Google Scholar] [CrossRef]
- Hu, J.; Marculescu, R. Energy-and performance-aware mapping for regular NoC architectures. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2005, 24, 551–562. [Google Scholar] [CrossRef]
- Ara, G.; Cucinotta, T.; Mascitti, A. Simulating execution time and power consumption of real-time tasks on embedded platforms. In Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing, Virtual Event, 25–29 April 2022; Association for Computing Machinery: New York, NY, USA, 2022. SAC ’22. pp. 491–500. [Google Scholar] [CrossRef]




| Attribute | GA | DGP |
|---|---|---|
| Representation | Genotype describes a solution. | Genotype describes a procedure of building a solution. |
| Aim of optimization | A solution directly. | A procedure of building a solution. |
| Search space | Some individuals could be eliminated, because they violate a limitation. | Every genotype is mapped into valid phenotype; thus, all individuals are considered during evolution. |
| Mapping function | Not used | Must be used. |
| Rescheduling | Requires running the evolution again. | Requires using mapping function only. |
| Task | A55 | A77 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| min | avg | max | min | avg | max | |||||||
| t | p | t | p | t | p | t | p | t | p | t | p | |
| T1 | 3 | 6 | 4 | 9 | 10 | 17 | 1 | 9 | 4 | 22 | 6 | 41 |
| T2 | 4 | 7 | 8 | 14 | 13 | 24 | 3 | 14 | 7 | 30 | 10 | 37 |
| T3 | 3 | 5 | 7 | 14 | 11 | 21 | 1 | 6 | 4 | 23 | 9 | 34 |
| T4 | 2 | 4 | 5 | 11 | 10 | 18 | 2 | 8 | 5 | 27 | 7 | 31 |
| T5 | 5 | 9 | 13 | 23 | 16 | 27 | 3 | 19 | 8 | 38 | 12 | 51 |
| T6 | 4 | 6 | 7 | 11 | 9 | 16 | 5 | 12 | 7 | 21 | 9 | 29 |
| 1.0 | 1715.00 | ||||||
| 0.8 | 1552.00 | 1578.00 | |||||
| 0.6 | 1550.00 | 1565.00 | 1556.00 | ||||
| 0.4 | 1529.00 | 1517.00 | 1549.00 | 1566.00 | |||
| 0.2 | 1527.00 | 1532.00 | 1554.00 | 1557.00 | 1570.00 | ||
| 0 | 1532.00 | 1534.00 | 1560.00 | 1566.00 | 1534.00 | 1566.00 | |
| 0 | 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||
| The best individuals | |||||||
| 1.0 | 1713.16 | ||||||
| 0.8 | 1571.93 | 1592.60 | |||||
| 0.6 | 1572.91 | 1585.76 | 1564.83 | ||||
| 0.4 | 1559.89 | 1541.70 | 1572.34 | 1577.15 | |||
| 0.2 | 1544.66 | 1557.80 | 1567.73 | 1571.50 | 1615.88 | ||
| 0 | 1555.25 | 1558.48 | 1580.86 | 1585.56 | 1562.16 | 1577.58 | |
| 0 | 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||
| Average of the population | |||||||
| 1.0 | 1705.000 | ||||||
| 0.8 | 968.000 | 972.000 | |||||
| 0.6 | 1011.000 | 1000.000 | 980.000 | ||||
| 0.4 | 975.000 | 981.000 | 975.000 | 996.000 | |||
| 0.2 | 967.000 | 978.000 | 1005.000 | 990.000 | 1022.000 | ||
| 0 | 983.000 | 977.000 | 1015.000 | 1002.000 | 988.000 | 975.000 | |
| 0 | 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||
| The best individuals | |||||||
| 1.0 | 1890.117 | ||||||
| 0.8 | 968.06 | 971.961 | |||||
| 0.6 | 1011.000 | 1000.000 | 980.000 | ||||
| 0.4 | 971.039 | 981.000 | 983.164 | 996.000 | |||
| 0.2 | 969.922 | 978.000 | 970.000 | 990.000 | 1021.844 | ||
| 0 | 983.063 | 977.016 | 1015.000 | 1002.000 | 988.000 | 975.000 | |
| 0 | 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||
| Average of the population | |||||||
| 1.0 | 1803.00 | ||||||
| 0.8 | 1557.00 | 1584.00 | |||||
| 0.6 | 1554.00 | 1592.00 | 1577.00 | ||||
| 0.4 | 1556.00 | 1532.00 | 1579.00 | 1579.00 | |||
| 0. | 1539.00 | 1615.00 | 1574,00 | 1573.00 | 1591.00 | ||
| 0 | 1541.00 | 1539.00 | 1591.00 | 1566.00 | 1613.00 | 1577.00 | |
| 0 | 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||
| The best individuals | |||||||
| 1.0 | 1808.70 | ||||||
| 0.8 | 1557.00 | 1584.00 | |||||
| 0.6 | 1554.00 | 1592.00 | 1577.00 | ||||
| 0.4 | 1555.39 | 1532.00 | 1579.00 | 1579.00 | |||
| 0.2 | 1539.00 | 1615.00 | 1583,00 | 1573.00 | 1591.00 | ||
| 0 | 1541.00 | 1539.02 | 1591.00 | 1571.72 | 1613.00 | 1577.00 | |
| 0 | 0.2 | 0.4 | 0.6 | 0.8 | 1.0 | ||
| Average of the population | |||||||
| Frequency [GHz] | In Relation to the Highest Frequency | |
| Time | Energy Consumption | |
| 0.2 | 918.29% | 2.87% |
| 0.3 | 681.34% | 6.17% |
| 0.4 | 512.71% | 9.71% |
| 0.5 | 392.69% | 13.53% |
| 0.6 | 307.28% | 17.64% |
| 0.7 | 246.49% | 22.06% |
| 0.8 | 203.23% | 26.83% |
| 0.9 | 172.44% | 31.96% |
| 1.0 | 150.53% | 37.49% |
| 1.1 | 134.94% | 43.44% |
| 1.2 | 123.84% | 49.84% |
| 1.3 | 115.94% | 56.74% |
| 1.4 | 110.32% | 64.17% |
| 1.5 | 106.32% | 72.17% |
| 1.6 | 103.47% | 80.78% |
| 1.7 | 101.44% | 90.05% |
| 1.8 | 100.00% | 100.00% |
| Frequency [GHz] | In Relation to the Highest Frequency | |
| Time | Energy Consumption | |
| 0.2 | 1341.30% | 3.78% |
| 0.3 | 1018.50% | 5.24% |
| 0.4 | 779.44% | 6.87% |
| 0.5 | 602.40% | 8.69% |
| 0.6 | 471.28% | 10.71% |
| 0.7 | 374.17% | 12.97% |
| 0.8 | 302.25% | 15.48% |
| 0.9 | 248.99% | 18.28% |
| 1.0 | 209.55% | 21.40% |
| 1.1 | 180.34% | 24.88% |
| 1.2 | 158.70% | 28.76% |
| 1.3 | 142.68% | 33.08% |
| 1.4 | 130.81% | 37.90% |
| 1.5 | 122.02% | 43.26% |
| 1.6 | 115.52% | 49.24% |
| 1.7 | 110.70% | 55.91% |
| 1.8 | 107.13% | 63.33% |
| 1.9 | 104.48% | 71.61% |
| 2.0 | 102.52% | 80.83% |
| 2.1 | 101.07% | 91.11% |
| 2.2 | 100.00% | 100.00% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ciopiński, L. Methodology of an Energy Efficient-Embedded Self-Adaptive Software Design for Multi-Cores and Frequency-Scaling Processors Used in Real-Time Systems. Electronics 2025, 14, 556. https://doi.org/10.3390/electronics14030556
Ciopiński L. Methodology of an Energy Efficient-Embedded Self-Adaptive Software Design for Multi-Cores and Frequency-Scaling Processors Used in Real-Time Systems. Electronics. 2025; 14(3):556. https://doi.org/10.3390/electronics14030556
Chicago/Turabian StyleCiopiński, Leszek. 2025. "Methodology of an Energy Efficient-Embedded Self-Adaptive Software Design for Multi-Cores and Frequency-Scaling Processors Used in Real-Time Systems" Electronics 14, no. 3: 556. https://doi.org/10.3390/electronics14030556
APA StyleCiopiński, L. (2025). Methodology of an Energy Efficient-Embedded Self-Adaptive Software Design for Multi-Cores and Frequency-Scaling Processors Used in Real-Time Systems. Electronics, 14(3), 556. https://doi.org/10.3390/electronics14030556