
Efficient Quantization and Data Access for Accelerating Homomorphic Encrypted CNNs
Abstract
1. Introduction
- An HE-friendly additive powers-of-two (APoT) quantization method is adopted and improved to reduce the multiplication operation of HCNN inference, which can achieve negligible accuracy loss compared with the floating-point CNNs.
- A corresponding multiplicationless modular multiplier–accumulator (M-MAC) unit is proposed to achieve area reduction compared to the standard M-MAC unit adopted by the latest FPGA accelerators [6].
- An HCNN accelerator with an M-MAC array is designed to implement the widely used CNNs with a moderate batch size. Repeated transmission of input and output polynomials is avoided based on our proposed data access strategy. When processing 8K images in the CIFAR-10 dataset, our FPGA design is and faster than recent batch-processing FPGA and GPU implementations, respectively.
2. Preliminaries
2.1. Homomorphic Encryption
2.2. Encrypted CNN Linear Layers
- Sparse representation: Each element in is represented by a message in which every coordinate is equal to .
- SIMD representation: The i-th item of multiple vectors is sequentially mapped to each item of a message.
- Convolution representation: The img2col technique [14] is introduced to flatten the input images. Each column after flattening is mapped to a message, which is multiplied by the same weight.
3. Efficient Modular Processing Element Based on APoT Quantization Method
3.1. Optimized APoT Quantization Method
3.2. Multiplicationless Modular Multiplier–Accumulator
4. Transmission-Efficient Homomorphic CNN Accelerator with M-MACs
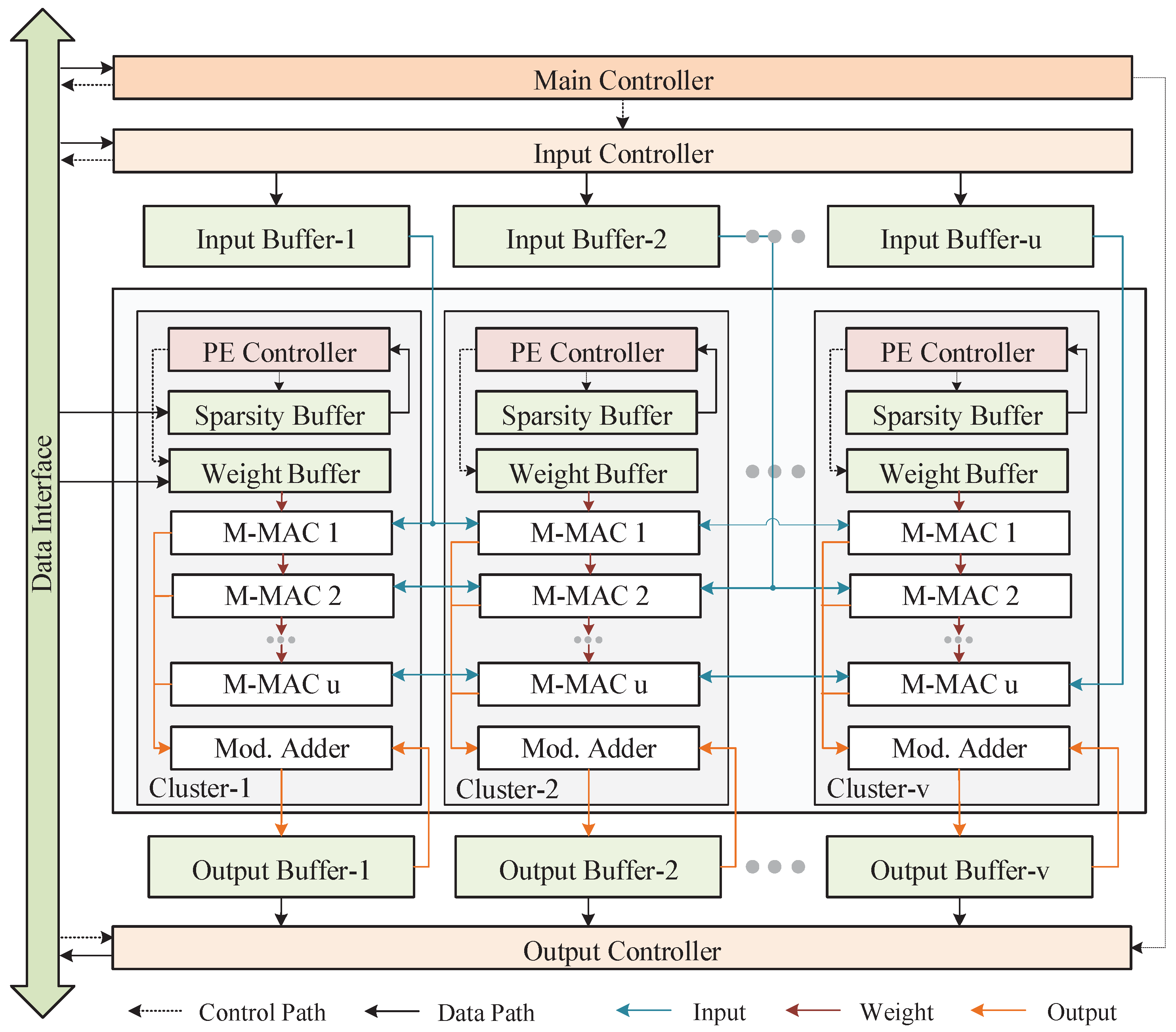
4.1. Overall Architecture
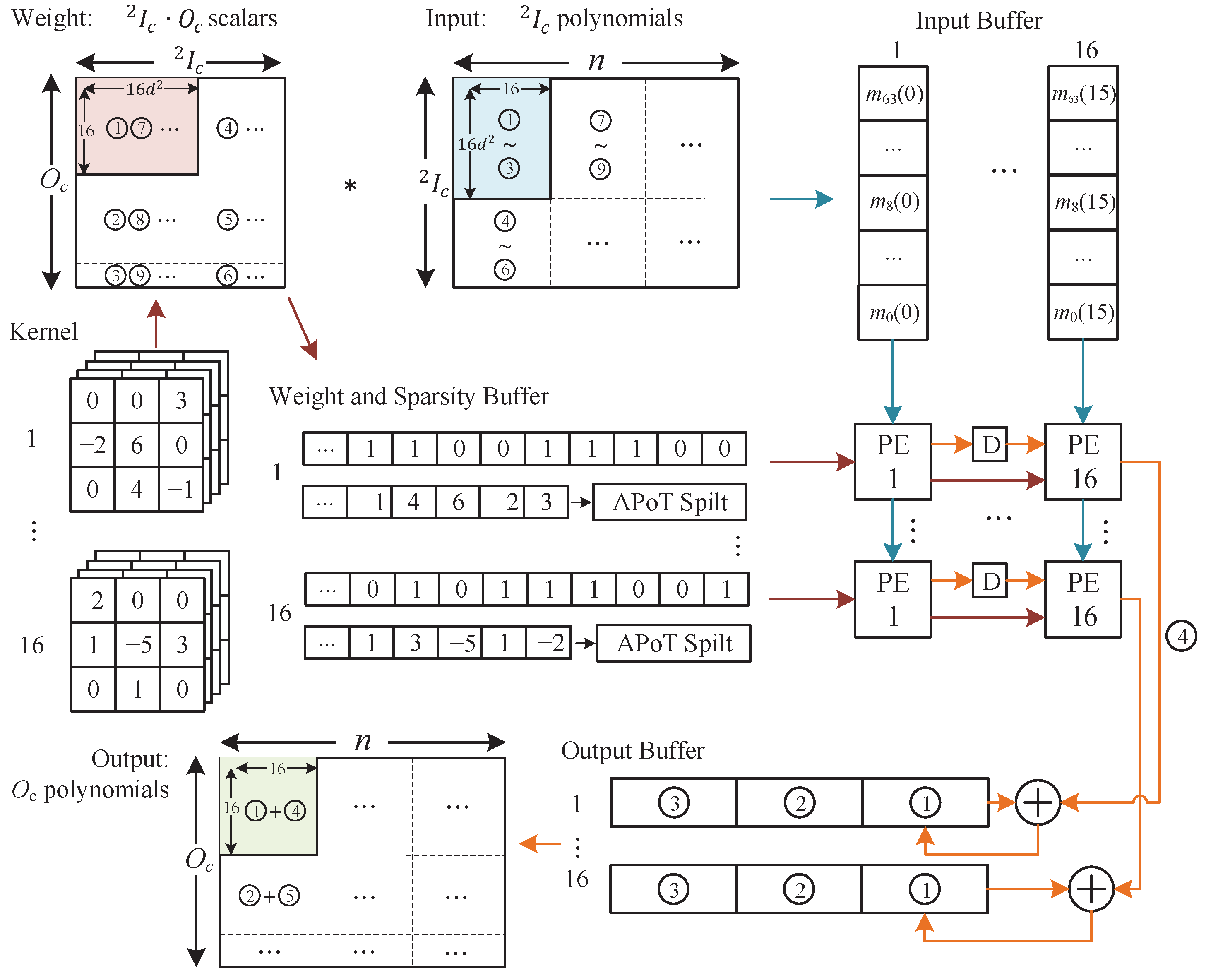
4.2. Implementation Details
5. Experimental Results
5.1. Experimental Setup
5.2. Network Accuracy
5.3. Implementation Results of Modular Multiplication
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the STOC ’09: Symposium on Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; pp. 169–178. [Google Scholar]
- Tanuwidjaja, H.C.; Choi, R.; Baek, S.; Kim, K. Privacy-preserving deep learning on machine learning as a service—A comprehensive survey. IEEE Access 2020, 8, 167425–167447. [Google Scholar] [CrossRef]
- Aharoni, E.; Drucker, N.; Ezov, G.; Shaul, H.; Soceanu, O. Complex encoded tile tensors: Accelerating encrypted analytics. IEEE Secur. Priv. 2022, 20, 35–43. [Google Scholar] [CrossRef]
- Gilad-Bachrach, R.; Dowlin, N.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. In Proceedings of the 33rd International Conference on Machine Learning, PMLR 48, New York, NY, USA, 20–22 June 2016; pp. 201–210. [Google Scholar]
- Badawi, A.A.; Jin, C.; Lin, J.; Mun, C.F.; Jie, S.J.; Tan, B.H.M.; Nan, X.; Aung, K.M.M.; Chandrasekhar, V.R. Towards the AlexNet moment for homomorphic encryption: HCNN, the first homomorphic CNN on encrypted data with GPUs. IEEE Trans. Emerg. Topics Comput. 2020, 9, 1330–1343. [Google Scholar] [CrossRef]
- Yang, Y.; Kuppannagari, S.R.; Kannan, R.; Prasanna, V.K. FPGA accelerator for homomorphic encrypted sparse convolutional neural network inference. In Proceedings of the 2022 IEEE 30th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), New York, NY, USA, 15–18 May 2022; pp. 1–9. [Google Scholar]
- Juvekar, C.; Vaikuntanathan, V.; Chandrakasan, A. GAZELLE: A low latency framework for secure neural network inference. In Proceedings of the 27th USENIX Conference on Security Symposium, Baltimore, MD, USA, 15–17 August 2018; pp. 1651–1669. [Google Scholar]
- Brutzkus, A.; Gilad-Bachrach, R.; Elisha, O. Low latency privacy preserving inference. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; pp. 812–821. [Google Scholar]
- Reagen, B.; Choi, W.-S.; Ko, Y.; Lee, V.T.; Lee, H.-H.S.; Wei, G.-Y.; Brooks, D. Cheetah: Optimizing and accelerating homomorphic encryption for private inference. In Proceedings of the 2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA), Seoul, Republic of Korea, 27 February–3 March 2021; pp. 26–39. [Google Scholar]
- Fan, J.; Vercauteren, F. Somewhat Practical Fully Homomorphic Encryption. Cryptol. ePrint Arch. 2012. Available online: https://eprint.iacr.org/2012/144 (accessed on 22 March 2012).
- Chou, E.; Beal, J.; Levy, D.; Yeung, S.; Haque, A.; Fei-Fei, L. Faster cryptonets: Leveraging sparsity for real-world encrypted inference. arXiv 2018, arXiv:1811.09953. [Google Scholar]
- Cai, Y.; Zhang, Q.; Ning, R.; Xin, C.; Wu, H. Hunter: HE-friendly structured pruning for efficient privacy-preserving deep learning. In Proceedings of the ASIA CCS ’22: Proceedings of the 2022 ACM on Asia Conference on Computer and Communications Security, Nagasaki, Japan,, 30 May–3 June 2022; pp. 931–945. [Google Scholar]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic encryption for arithmetic of approximate numbers. In Proceedings of the 23rd International Conference on the Theory and Applications of Cryptology and Information Security (ASIACRYPT), Hong Kong, China, 3–7 December 2017; pp. 409–437. [Google Scholar]
- Chellapilla, K.; Puri, S.; Simard, P. High performance convolutional neural networks for document processing. In Proceedings of the 10th International Workshop on Frontiers in Handwriting Recognition (IWFHR), La Baule, France, 23–26 October 2006. [Google Scholar]
- Li, Y.; Dong, X.; Wang, W. Additive powers-of-two quantization: An efficient non-uniform discretization for neural networks. arXiv 2019, arXiv:1909.13144. [Google Scholar]
- Yin, P.; Lyu, J.; Zhang, S.; Osher, S.; Qi, Y.; Xin, J. Understanding straight-through estimator in training activation quantized neural nets. In Proceedings of the International Conference on Learning Representations (ICLR), New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Kong, Y. Optimizing the improved Barrett modular multipliers for public-key cryptography. In Proceedings of the International Conference on Computational Intelligence and Software Engineering (CiSE), Wuhan, China, 10–12 December 2010. pp. 1–4.
- Banerjee, U.; Ukyab, T.S.; Chandrakasan, A.P. Sapphire: A configurable crypto-processor for post-quantum lattice-based protocols. In Proceedings of the IACR Transactions on Cryptographic Hardware and Embedded Systems, Atlanta, GA, USA, 25–28 August 2019; pp. 17–61. [Google Scholar]
- Microsoft SEAL (Release 3.2); Microsoft Research: Redmond, WA, USA, 2019; Available online: https://github.com/Microsoft/SEAL (accessed on 16 January 2020).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN-6 | Input Size | Description |
|---|---|---|
| Conv-1 | filter: , stride: 2, activ | |
| Conv-2 | filter: , stride: 2, activ | |
| Fc-1 | filter: | |
| Fc-2 | filter: | |
| CNN-11 | Input Size | Description |
| Conv-1 | filter: , stride: 1 | |
| Pool-1 | average, , stride: 2, activ | |
| Conv-2 | filter: , stride: 1 | |
| Pool-2 | average, , stride: 2, activ | |
| Conv-3 | filter: , stride: 1 | |
| Pool-3 | average, , stride: 2, activ | |
| Fc-1 | filter: | |
| Fc-2 | filter: |
| Model | Quant. Method | δ+ | Accuracy | |
|---|---|---|---|---|
| ReLU | Poly | |||
| CNN-6 | Float | 32 | 98.94% | 98.99% |
| Uniform | 4 | 98.83% | 98.8% | |
| Ours (APoT) | 4 | 98.93% | 98.85% | |
| CNN-11 | Float | 32 | 82.74% | 78.49% |
| Uniform | 8 | 82.37% | ||
| Ours (APoT) | 8 | 82.15% | 78.36% | |
| Design | Accel-L [6] | Our Design |
|---|---|---|
| FPGA Device | Xilinx U200 | Xilinx XCVU440 |
| Frequency (MHz) | 175 | |
| LUT/FF/DSP | 360K/424K/2320 | 194K/158K/768 |
| BRAM/URAM | ||
| Inference Latency (s) of CNN-6 (8K images) | ||
| CPU to FPGA | 0.462 ⋄ | |
| Linear | ||
| Activ. Layers | 2.706 ≀ | |
| Total | ||
| Inference Latency (s) of CNN-11 (8K images) | ||
| CPU to FPGA | 15.323 ⋄ | |
| Linear | ||
| Activ. Layers | 80.131 ≀ | |
| Total | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, K.; Wang, X.; Fu, Y.; Li, L. Efficient Quantization and Data Access for Accelerating Homomorphic Encrypted CNNs. Electronics 2025, 14, 464. https://doi.org/10.3390/electronics14030464
Chen K, Wang X, Fu Y, Li L. Efficient Quantization and Data Access for Accelerating Homomorphic Encrypted CNNs. Electronics. 2025; 14(3):464. https://doi.org/10.3390/electronics14030464
Chicago/Turabian StyleChen, Kai, Xinyu Wang, Yuxiang Fu, and Li Li. 2025. "Efficient Quantization and Data Access for Accelerating Homomorphic Encrypted CNNs" Electronics 14, no. 3: 464. https://doi.org/10.3390/electronics14030464
APA StyleChen, K., Wang, X., Fu, Y., & Li, L. (2025). Efficient Quantization and Data Access for Accelerating Homomorphic Encrypted CNNs. Electronics, 14(3), 464. https://doi.org/10.3390/electronics14030464